
基于深度残差网络的接转站工艺流程异常工况诊断
2024-01-06 03:08张蕊侯磊刘珈铨孙省身张坤杜鑫李兴涛
石油科学通报 2023年6期
张蕊 ,侯磊,刘珈铨,孙省身,张坤,杜鑫,李兴涛
1 中国石油大学(北京)机械与储运工程学院,北京 102249
2 中国石油长庆油田分公司长庆工程设计有限公司,西安 710021
3 中国石油长庆油田分公司第十二采油厂,合水 745000
4 中国石油国际勘探开发有限公司,北京 102249
0 引言
接转站作为油气田地面集输系统的关键节点,既有设备集中、运行连续性强的生产特点[1],还容易出现来流比例剧烈波动和设备运行故障等工况异常[2]。目前油田生产现场对接转站场的工况诊断主要依靠操作员工经验。对于简单设备的异常数据,操作员工尚能进行初步诊断,但对整个站场的大量SCADA实时监测数据,仅靠经验和知识难以实现快速分析处理[3]。阈值报警系统本应及时准确地反馈异常信号[4],但实际应用中其对多模态过程适应性差,“假报警”“不报警”问题突出,亟待发展适用于接转站场的智能诊断方法。
油气处理工艺流程的诊断方法包括基于知识的方法、基于模型的方法及数据驱动方法[5]。目前站场应用较多的是基于知识的方法。赵自愿[6]利用模糊故障树分析法对原油集输系统关键设备进行异常分析,用CAFTA软件对现场集输流程进行仿真,求取关键设备在一定工作时间内的可靠度。方一宇[7]采用QRA法对接转站中的压力容器进行风险评价,对接转站系统的危害因素进行有效识别,量化了接转站系统风险等级。
上述基于知识的方法虽能用于对油气站场的异常模式及危害度进行定量分析,但难以在系统输入与输出之间建立精确数学模型。数据驱动方法只需建立具有分类功能的数学模型[8],就能直接对SCADA数据进行处理,以实现站场状态的实时诊断与评估。
在数据驱动方法中,异常工况诊断被视为时间序列数据的分类[9],具体包括统计分析方法、浅层学习方法和深度学习方法。统计分析方法、浅层学习方法均需要丰富的专业领域知识来确定时频域特征[10],在复杂学习任务中的信息表征能力存在局限性[11],不适用于具有非高斯分布、非线性特性的储运站场过程数据。深度学习方法是一种用多个隐含层对特征数据进行逐层非线性转换从而实现数据特征抽象提取的算法[12],适于处理高维海量数据,能够自动提取非线性数据特征,通过组合足够多的变化,理论上可以无限逼近任意复杂函数。
Zhao[13]利用基于批归一化(BN)的长短时记忆神经网络(LSTM),自适应学习原始数据的时间动态信息。Xie[14]利用阶层深度神经网络(HDNN)对田纳西-伊斯曼过程(TE过程)进行故障诊断。Chao等[15]利用改进的贝叶斯优化和DRN的异常诊断模型,对变电站的热异常进行诊断。Jiang[16]将堆栈式稀疏自编码器(SSAE)用于故障诊断,实现了半监督学习策略。
从网络架构角度而言,针对其他分类任务设计的高深度模型[13-16]直接应用于接转站场数据时,易出现在训练集表现良好但验证集精度降低的过拟合现象。从数据特性角度而言,接转站场收集数据相比公开时间序列数据集,样本量小且维度高,模型存在学习不足,难以训练风险。从训练成本角度而言,高深度且多核的模型在学习过程中耗时长,硬件要求高,训练难度加剧。
深度残差网络(DRN)[17]于2015年被首次提出,是一种先进的深度学习模型,它在卷积神经网络(CNN)结构中加入恒等映射快捷连接,解决了深层网络梯度弥散和精度下降的问题,缓解了训练困难,使网络在加深过程中既保证精度,又控制速度[18]。
本文以某油田接转站流程为例,将多元时间序列数据(MTS)分类方法[19]融入异常诊断体系中,提出一种基于DRN的接转站异常工况诊断方法,能够自动提取异常特征,实现高精度异常诊断,通过油田生产现场SCADA数据对该方法进行有效性验证。
1 基于DRN 的异常工况诊断方法
1.1 卷积层
卷积层的主要作用是从输入数据中提取特征,对一个有M个特征映射的作为输入的卷积层,当有N个过滤器时,按下式计算第K层的输出特征[20]:
如图1 所示,卷积层的局部感知能够提取监测变量的局部特征,接转站过程数据中不同时间点,不同变量间的相同变化特性能够被卷积的权值共享模式捕获[21]。

图1 卷积核示意图Fig. 1 diagram of convolution kernel
1.2 激活层
激活层通过对加权输入进行非线性组合以产生非线性决策边界,非线性变换能够使网络存储信息量大大增加[20]。如图2 所示,常见激活函数包括逻辑函数(Sigmoid)、双曲正切函数(tanh)、线性校正单元(ReLU)等。
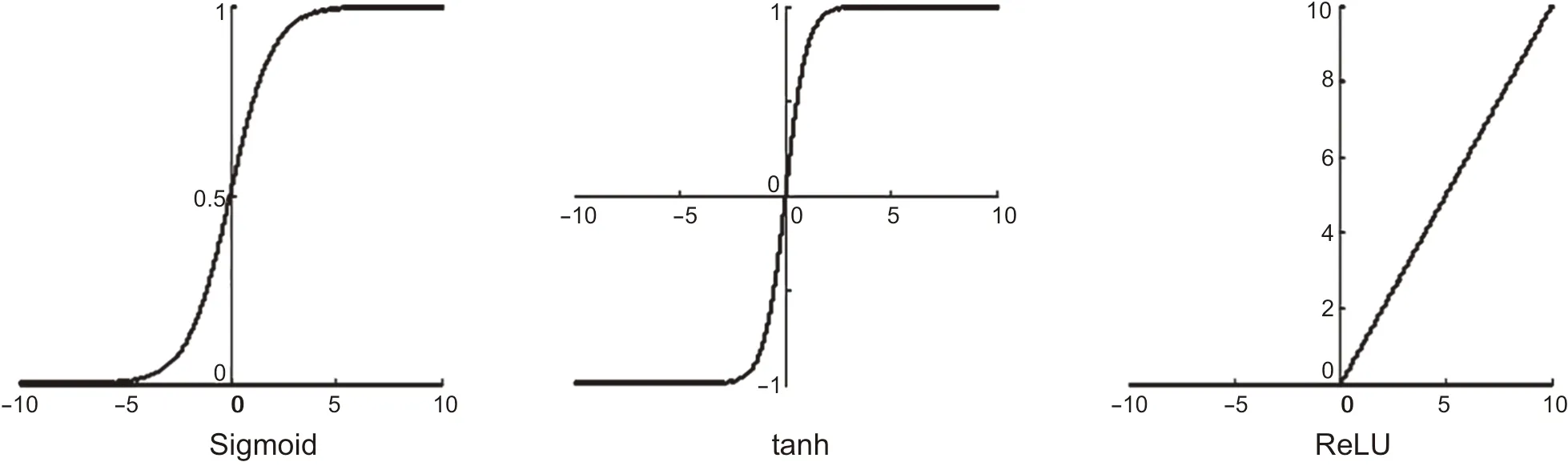
图2 激活函数示意图Fig. 2 Schematic diagram of activation function
Sigmoid型函数定义见下式,它是两端饱和的S型曲线函数。
Sigmoid型激活函数的优点是神经元输出可以直接看作概率分布,神经网络可以更好地和统计学习模型相结合,并且它将不同尺度的特征挤压到一个受限空间[20],适应于特征相差较复杂的场景,本文采用Sigmoid作为激活函数。
1.3 残差连接
残差连接是DRN的核心部分。残差结构如图3 所示,DRN在卷积神经网络(CNN)的基础上通过卷积层之间的残差连接实现多层网络的直接输出,避免了卷积神经网络的梯度消失问题。
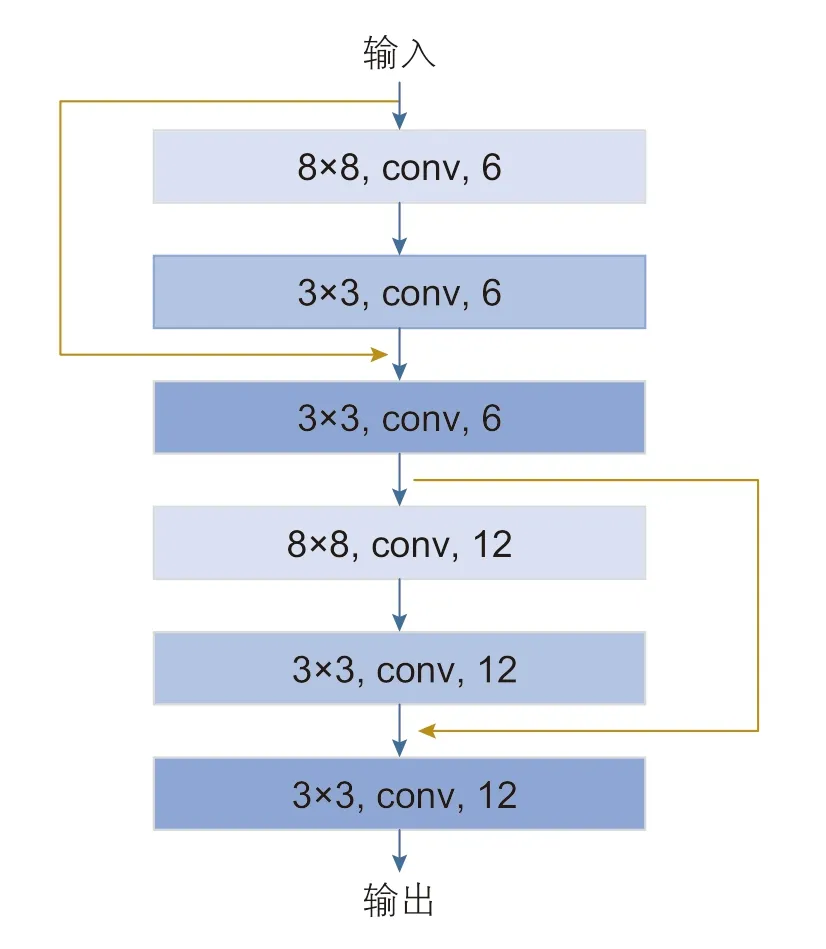
图3 残差结构示意图Fig. 3 Diagram of residual structure
假设多个残差块堆叠,则从第i个残差块到第j个残差块的信息向前传递如下式[17]:
在误差反向传播过程中,网络优化的梯度见下式[18]:
式中,L为损失函数,项保证了底层网络都能接收到这个梯度,缓解训练困难问题。
1.4 全局平均池化层
GAP层(Global Average Pooling)对最后一层卷积的特征图进行平均池化操作。如图4,当有K个特征图时,池化结果为K个1×1 的特征图,这些特征图直接输入Softmax层后产生K个类别的置信度,起到取代传统全连接层的效果[22]。
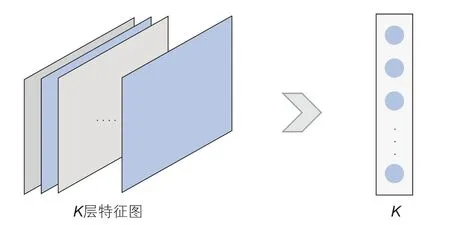
图4 GAP示意图Fig. 4 Schematic diagram of GAP
全局平均池化层能够简化模型训练参数,避免传统全连接层过拟合风险,提高模型泛化能力。
1.5 批量归一化层
批量归一化(BN)层对模型上一层进行归一化操作,通过特征映射将输出数据转化为具有相同尺度的标准正态分布,保证样本特征在同一量纲范围,缓解模型内部协方差偏移问题[20],可表示为
式中,第l层的经过BN操作后的输入为BN(z(l)),a(l)为神经元的输出,f()为激活函数。BN(z(l))为净输入z(l)的标准正态分布。
2 接转站工艺流程数据集
2.1 接转站工艺流程
某油田转接站位于甘肃区块,于2015年建成投运,设计年处理原油20×104t。主要功能包括原油加热、油气分离、原油脱水、净化油外输、污水处理及回注等。接转站接收上游5 个输油点来流,来流通过加热炉加热后分别进入溢流沉降罐和三相分离器进行分离。分离油经加压、加热达到外输压力温度要求,过滤计量后输往下站。沉降罐和三相分离器的分离水输往水处理模块。各设备分离出的气体与井场采出气经过气液分离后作为燃料输往加热炉,剩余气体通过火炬燃烧。
2.2 数据集
由接转站自动化监控终端采集原始参数,调取2020年7月至10月的2001 组数据,整套流程共采集到36 个参数,采集间隔1 h。去除采集异常后形成有5 种工况的36×1800 组数据。所有工况如表1 所示。

表1 接转站流程工况列表Table 1 List of operation conditions for block process
接转站流程的36 个监测变量如表2 所示。
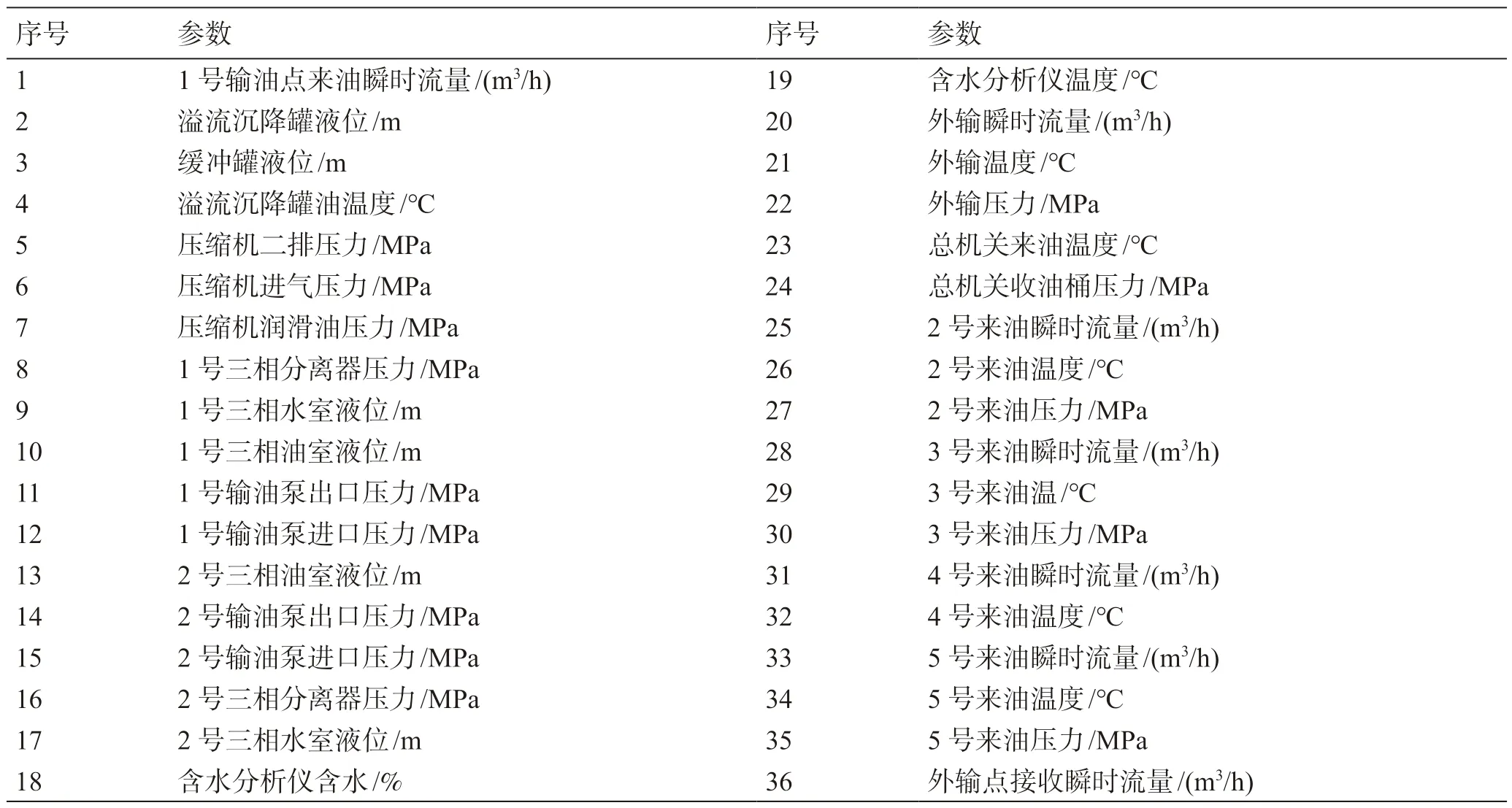
表2 接转站流程监测参数Table 2 Block station process monitoring parameters
3 基于DRN 的接转站工艺流程异常工况诊断
基于深度残差网络的接转站流程异常工况诊断流程如图5 所示,具体步骤如下:

图5 接转站异常工况诊断流程Fig. 5 Abnormal operation condition diagnosis process of block station
(1) 数据降噪:对原始数据进行逐维离散小波降噪。
(2) 入模前处理:重采样扩容数据集形成时间序列样本,通过正则化手段均衡数据分布,划分训练集和验证集。
(3) 入模诊断:建立基于DRN的接转站流程诊断模型,根据诊断评价指标进行模型优化,得出最优模型。
3.1 数据降噪
由于现场信号采集器性能不稳定或工况波动,SCADA数据往往存在强噪声。数据噪声会掩盖监测变量的真实波动,降低模型对少数类样本的识别能力,模型存在同时学习噪声和少数类的风险[23]。由此,需要对数据进行降噪处理,减弱采集干扰,增强模型诊断性能。
常用去噪方法有高斯滤波、中值滤波、傅里叶变换等,但它们不能区分有效信号的高频部分和噪声引起的高频干扰。小波变换的时频局部化特性能够保留信号尖峰和信号突变,将高频信息和高频噪声区分开来并抑制高频噪声的干扰[24],适于转油流程的数据降噪。
小波变换的时频局部化特性可以线性表示如下式[25]:
Wx表示含噪混合信号,Wf代表纯净信号,We表示噪声信号。
采用一维小波离散去噪(DTW1),得到细节分量(高频)与近似分量(低频),对细节分量进行阈值处理,用处理后的各分量进行小波重构,得到去噪后的信号。降噪处理前后数据变化如图6 所示。

图6 降噪处理前后数据Fig. 6 Data before and after noise reduction
图7 表示同一网络架构下数据降噪对诊断准确率和模型损失的影响。未降噪数据在训练时,随着叠代次数增加,噪声特征被模型学习并不断扩大,模型准确率出现剧烈扰动,并出现过拟合现象。数据降噪后模型准确率提升2.1%,损失下降0.03,过拟合得到纠正,稳定性大幅提升。

图7 降噪对模型准确率、损失的影响Fig. 7 Influence of noise reduction on model accuracy and loss
3.2 重采样与正则化
接转站工艺流程的数据采集间隔为1 小时,设定1 个样本包含10 个数据点,共形成180 个样本。但样本量少易导致模型训练不足,由此本研究采用朴素重采样方法,朴素重采样以一定的采样间隔在时间序列上移动,读取数据形成多个样本。采样间隔越小则样本相似度越高,模型越容易出现过拟合现象;采样间隔越大则样本扩容幅度越小,对模型训练能力提升有限。经实验确定最佳采样间隔为3 个时间点,最终形成大小为10×36 的630 个样本,如图8 所示。
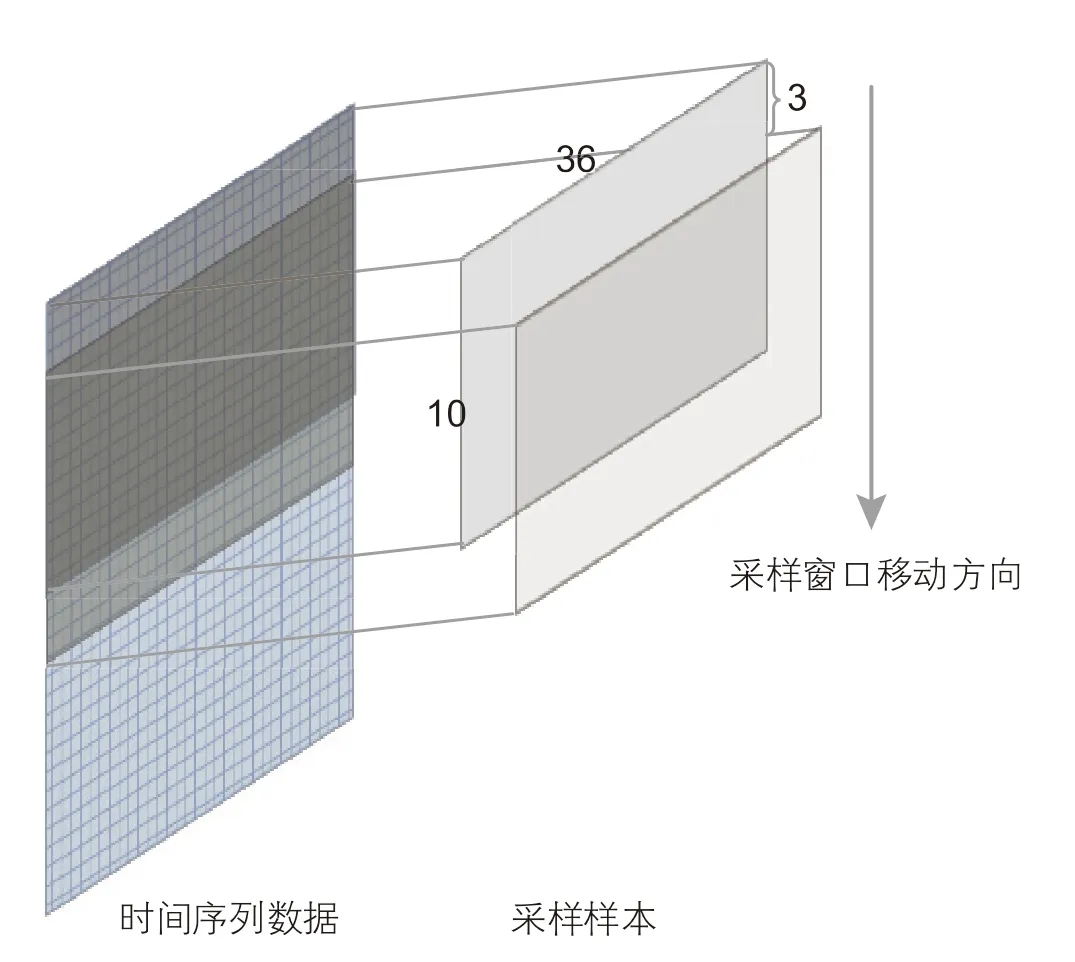
图8 朴素重采样原理Fig. 8 The principle of naive resampling
L2 正则化通过对大数值的权重向量进行惩罚,使模型倾向于使用所有输入特征,而不是依赖输入特征中的小部分特征[20]。L2 正则化可表示为:
其中L()为损失函数,N为训练样本数量,f( )为待学习的神经网络,θ为参数,e2为L2范数函数,λ为正则化系数。
如图9 所示,对转油流程数据集,36 维数据单位、幅值均不一致,L2 正则化通过权重惩罚,能够有效均衡数据分布,避免模型对个别维度的依赖,增强模型特征利用率,提高模型泛化能力,降低过拟合风险。

图9 正则化对模型准确率的影响Fig. 9 Influence of regularization on model accuracy
重采样与正则化后以7:3 的比例将数据集划分为训练集和验证集,训练集用于模型学习,验证集用于验证模型诊断性能。训练集、验证集样本数分别为441、189。
3.3 DRN诊断模型
为探索适宜接转站流程特点的诊断模型,设计8种DRN模型架构,见表3,调整参数包括卷积层层数、卷积核数量、激活函数类型、分类层类型,以训练集数据对模型进行训练。
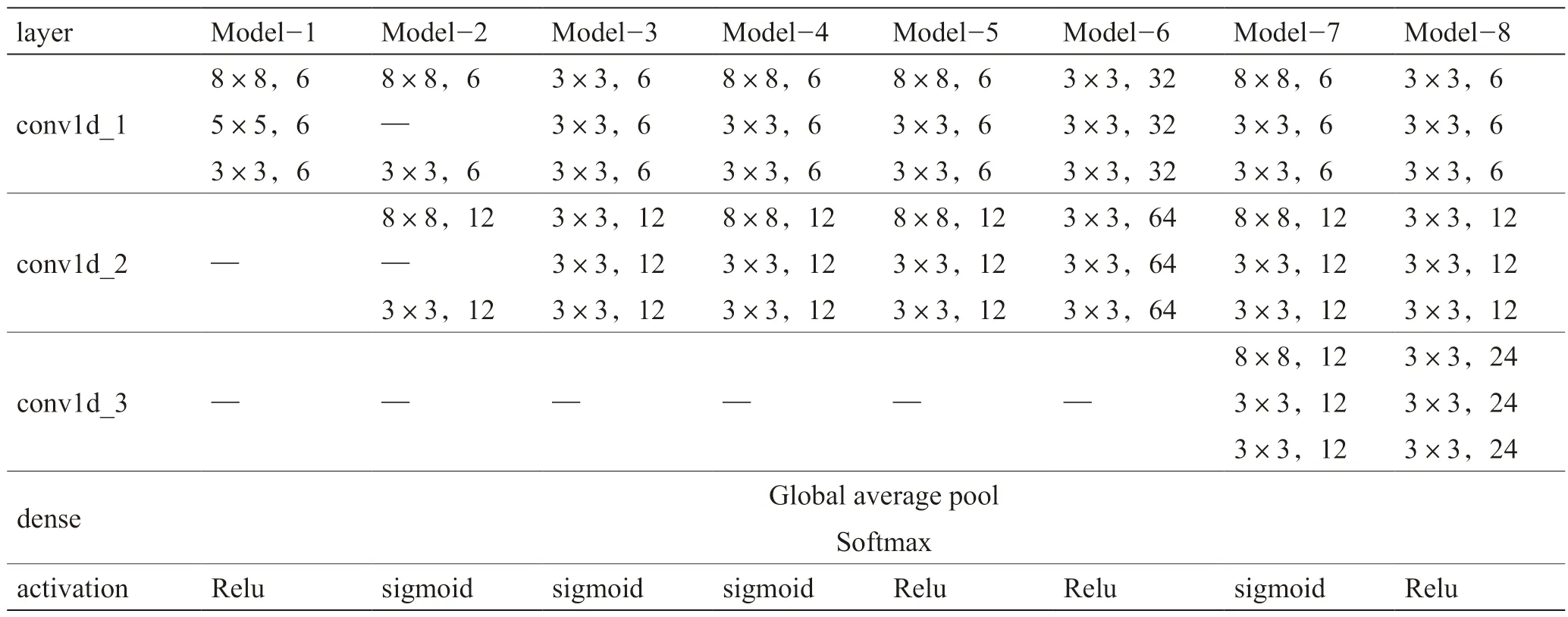
表3 DRN诊断模型Table 3 DRN diagnosed model
以模型4 为例进行说明。1 个样本矩阵的输入大小为10×36,其中“10”代表样本时间长度,即系统运行10 h进行1 次诊断;“36”表示过程变量的数量,对应为转油流程的36 个监测变量。模型4 的网络架构为2 个残差块,1 个全局平均池化层和1 个全连接层,每个残差块包含3 个卷积层,3 个标准化层和1 个残差连接结构。残差块中的卷积层卷积核大小分别为8×8,3×3,3×3,步幅设为1;第1 个残差块中的卷积层包含6 个过滤器,第2 个包含12 个过滤器。通过全局平均池化层输出大小为1×12 的样本,使用“Softmax”的全连接层将输出转化为1×5向量。
Softmax函数即归一化指数函数,能将任意K维向量Z转换为0 至1 范围内的实数,K维向量σ(Z)总和为1[21],Softmax函数定义见下式。
Softmax函数使模型输出一个长度为5 的向量,其每个值代表对应类别的可能性,其中可能性最高的值即为诊断结果。
3.4 诊断结果分析
完成DRN模型构建后,在以下开发环境中实现诊断过程:Windows10 操作系统,软件平台Python 3.6。硬件开发环境为:PC机一台,Intel(R)Core(TM)I7-6700HQ-CPU- 2.60GHz,8G的DDR3 内存、英伟达NVIDIA-GeForce-GTX-960M显卡。
用准确率(ACC)、精确率(PRE)和敏感性(TPR)3个指标来评价模型诊断性能。表4 为定义的总体工况混淆矩阵。

表4 工况的混淆矩阵Table 4 Confusion matrix of working conditions
准确率(ACC)评估模型的全局准确程度;精确率(PPV)表示模型对异常数据识别的准确程度;敏感性(TPR)表示模型对异常数据的敏感程度,敏感性越高,漏诊概率越低。ACC、PPV和TPR可定义为:
每次诊断导入一个样本矩阵,每个样本矩阵包含从时刻t-1 到时刻t的36 个变量的时间序列数据,以诊断t时刻的转油流程的运行状态。
表5 中列出了表4 中各模型的验证集总准确率、敏感性和精确率。模型4 具有最高的验证集总准确率和敏感性,为最佳模型。模型4 的完整网络参数如表6 所示,网络结构如图10 所示。

表5 测试集诊断结果Table 5 Diagnostic result on testing set
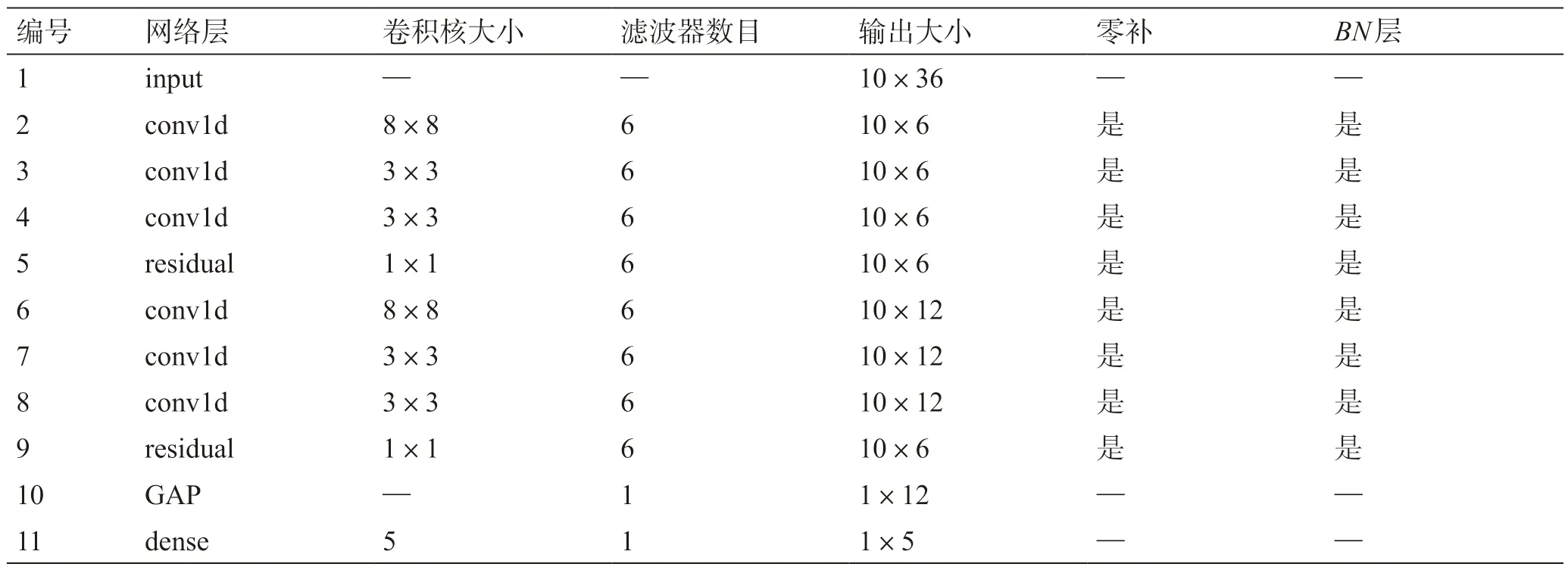
表6 模型4 完整架构参数(输入大小为一个样本矩阵)Table 6 Model 4 complete architecture parameters (input size is a sample matrix)

图10 模型4 结构示意图Fig. 10 Model 4 structure diagram
图11 为模型4 训练和验证阶段的准确率曲线及损失曲线。在441 个训练样本矩阵中,训练数据集的准确率为97.50%,模型损失为0.113。对于包含189 个样本矩阵的验证数据集,模型准确率为97.35%,模型损失为0.139。

图11 模型损失和准确率图Fig. 11 Model loss and accuracy diagrams
所有5 类工况的诊断结果混淆矩阵如图12 所示。5 类工况分别取得了99.2%、100%、85.7%、100%、92.3%的精确率。其中,第3 类工况的诊断精度最低,在14 个测试样本中2 个样本被划分为第1 类工况;第5 类工况的13 个测试样本中1 个样本被划分为第1 类工况。
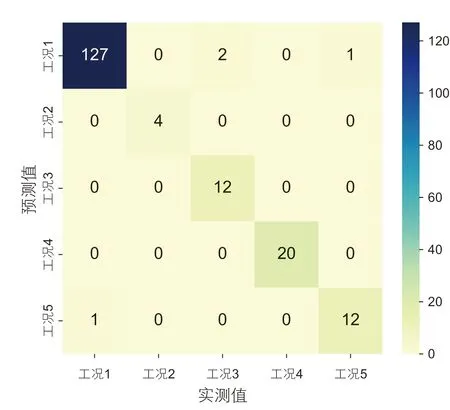
图12 验证集诊断结果混淆矩阵图Fig. 12 confusion matrix of test diagnostic result
3.5 工况相关性分析
多元互信息值可以反映两个矩阵之间共享信息量的大小,定义如下[26]:
其中,Y是有k个可能值的多项式随机变量,P(y)是它对应值的概率分布,X是一个多元随机变量。在Y=y条件下,X遵循参数为µy和∑c的多元正态密度分布。
为量化接转站各工况间的相关性大小[27],计算工况间的多元互信息值,如图13 所示。工况1 与工况3及工况5 的相关程度最低,证明其在网络诊断过程中最易发生误诊。工况2 与其他工况间的相关程度最高,证明其在网络诊断过程中最易于识别,这验证了上述DRN的诊断结果。同时,模型对样本量最少的工况2达到了100%的准确率,证明本模型有效避免了各类样本的不均衡性限制。

图13 各工况间的多元互信息值Fig. 13 Mutual information values among different conditions of samples
3.6 与其他模型的对比
为验证所提出模型在接转站的应用优势,分别采用支持向量机(SVC)、卷积神经网络(CNN)、全卷积神经网络FCN)、多层感知机(MLP)与残差神经网络(DRN)进行比较。最终诊断结果为各模型参数调整后的最优结果,诊断结果见表7。

表7 机器学习算法诊断结果对比Table 7 Comparison of diagnostic results of machine learning algorithms
与浅层模型SVC及MLP相比,所提出的DRN模型的总精确率有显著提升,表明模型能够有效学习小样本工况的特征;与深度模型CNN及FCN相比,所提出的DRN模型在测试集中未出现过拟合现象,表明模型泛化能力较强。
4 结论
(1)针对接转站数据噪声强、干扰大、数据量小的问题,采用小波方法进行降噪,根据重采样方法进行样本扩容,通过正则化手段均衡各维数据分布,有效提升了模型准确率和泛化能力。
(2)提出8 种不同的DRN架构,以测试集ACC、PRE与TPR作为评价指标,确定适用于接转站流程的最佳DRN诊断模型,实现对异常工况97.35%的诊断精度,证明了诊断模型的准确性。
(3)通过基于多元互信息值的相关性分析方法,量化5 类样本间的相关程度,表明互信息值的大小能够反映诊断难易程度,证明了诊断结果的可靠性。
(4)与经典机器学习模型SVC、CNN、FCN及MLP对比,DRN模型精确率分别提升4%、17%、10%、32%,表明模型能够对小样本工况的特征进行有效学习,诊断模型的泛化性显著提升,该方法对其他油气站场的异常诊断具有一定意义。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
