
基于观测与视频数据的机场能见度预测研究
2024-01-13 08:36王新龙梁艳玲刘雪宇
长治学院学报 2023年5期
王新龙,梁艳玲,刘雪宇
(1.长治学院 计算机系,山西 长治 046011;2.山西旅游职业学院 计算机科学系,山西 太原 030031;3.太原理工大学 计算机科学与技术学院(大数据学院),山西 太原 030024)
1 引言
在实践中,我们通常以能见度作为在气象、公路行车、飞机飞行中等领域中衡量大气透明程度和空气质量好坏的一个重要指标。在航空领域,习惯用跑道能见度反映机场附近雾和霾的大小,它被定义为从跑道的一端到目标物体的最大距离。一般情况下,当机场能见度只有400 m 左右时,会禁止航班起降。当机场能见度只有600-800 m 左右时,航班虽然可以正常起降,但出于安全考虑,机场会采取临时控制航班流量的措施,拉大航班起飞间隔,但容易造成航班延误。因此,能见度预测将直接影响交通运输的安全和效率,成为交通管理部门和航空公司十分关注的问题[1,2]。
目前,已经有学者基于AMOS(Aerodome Meteorological Observation System)观测数据对能见度进行预测,例如,李俊敏等[3]利用BP 神经网络,通过选取气压、风速等特征对能见度进行预测;王雅雪等[4]利用主成分分析、多分类多元回归模型等方法对能见度进行预测。然而,目前基于AMOS 观测数据对能见度进行预测仅仅考虑了特征变量对能见度的影响,并无考虑特征之间的相关性并融合相关特征,因此准确率较低,难以满足实际需求。
另一方面,测量能见度需要大量设备仪器进行测算,例如激光能见度仪等,若使用仪器测算对机场进行全覆盖将耗资巨大,同时仪器还存在对团雾检测精度不高、探测的范围很小以及维护成本高等问题,从而在无设备区域易出现安全隐患,可能导致严重后果。近年来,基于视频进行能见度的测量引起广泛研究,宋梓庚等[5]提出了利用VGG 深度学习模型对能见度进行预测,RMSE 达到了14.5 km;千月欣等人[6]利用Squeezeenet 迁移学习模型对能见度进行预测,RMSE 达到85.012 m。然而,目前基于深度学习的视频能见度预测方法中,尽管可以对视频中每秒的能见度进行预测,但是由于这些方法大多数只选取少量数据中某些固有的特征,没有很好地利用无监督的数据,估计精度不高,难以实际使用。
基于上述问题,文章通过机场观测、机场监控视频两类数据,利用数据分析方法、深度学习算法和机器学习算法等技术构建模型,对机场的可见度进行预测。具体分为两部分:(1)地面的气象因素往往能反映出雾的大小,根据AMOS 机场观测数据,选取合适的特征建立能见度与地面气象观测(温度、湿度和风速等)之间的关系并导出关系式。(2)大部分现实场景中,地面的气象因素信息往往很难获得,通过机场监控视频数据和能见度数据,构建基于视频数据的能见度估计深度学习模型,并对估计的能见度进行精度评估。
2 基于AMOS 观测数据的能见度预测模型
AMOS 观测数据涵盖气压、灯光、温度和湿度等特征以及相应的能见度信息,通过该数据类型建立预测模型来描述能见度与地面气象观测之间的关系,并导出具体的关系式。由于筛选与问题目标具有强相关的输入变量对于建立模型和解决实际问题非常重要,且原始的机场AMOS 观测数据(HIS 格式)包含很多特征,所以需要对特征进行筛选。文章首先将数据进行标准化,随后通过分析各变量之间的相关性,筛选出与能见度相关的特征,同时利用因子分析使得各特征之间的相关性变低。最后利用回归分析方法,探寻能见度与地面气象之间的关系。
2.1 数据预处理
数据标准化(归一化)处理是数据挖掘的一项基础工作。不同评价指标往往具有不同的量纲,数值间的差别可能很大,不进行预处理可能会影响数据分析的结果。为了消除指标之间量纲和取值范围差异的影响,需要进行标准化处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析。文章采用了Z-score 标准化方式对数据进行了处理。Z-score 是对某一原始数据进行转换,成为一个标准数据,该标准处理的数据均值为0,标准差为1。Z-score 标准化的计算公式如下:
2.2 特征筛选
在机场能见度预测的研究中,有多个环境因素可能影响机场的能见度。基于气象学知识,文章选取了2019 年12 月16 日以及2020 年3 月13日两天的数据作为实验对象,初步筛选出与能见度相关的10 个特征,包括本站气压、飞机着陆地区最高点气压、修正海平面气压、温度、相对湿度、露点温度、灯光数据、2 分钟平均风速、2 分钟平均风向、2 分钟平均垂直风速。表1 给出了10 个属性及其对应的英文缩写。
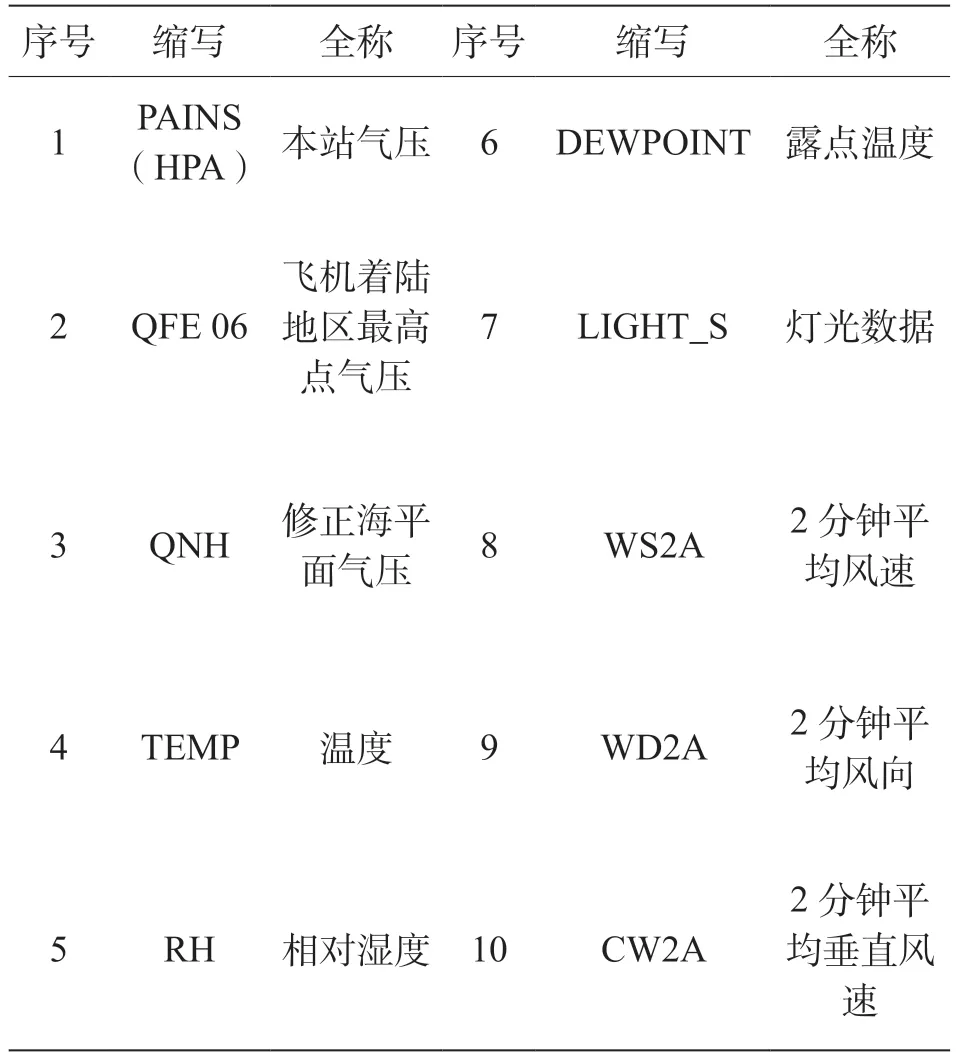
表1 初步筛选后与能见度相关数据属性及其对应的英文缩写
基于协方差矩阵的特征进行筛选。在统计学中,方差是用来度量单个随机变量的离散程度,而协方差则一般用来刻画两个随机变量的相似程度。通常,方差的计算公式为:
协方差的计算公式为:
根据方差的定义,给定多个随机变量,计算随机变量的方差和两两之间的协方差。利用以上方法,文章首先构建上述10 个特征变量。由式(3)和(4)可得,各变量之间的协方差矩阵为:
通过协方差矩阵可分析各变量与能见度之间的相关性,进而得到如下结论。
PAINS(本站气压)、QFE(飞机着陆地区最高点气压)和QNH(修正海平面气压)之间的协方差均为1,故根据实际意义可仅保留QNH(修正海平面气压)。露点温度与MOR 协方差小于0.1,即露点温度与能见度之间的相关性较弱,故不做考虑。
因此,通过协方差矩阵的分析可得,与能见度相关性较强的有7 个变量,包括修正海平面气压、温度、相对湿度、灯光数据、2 分钟平均风速、2 分钟平均风向和2 分钟平均垂直风速。表2 展示了气象光学视程(MOR)、跑道视程(RVR)和筛选后的7 个变量的部分数据。
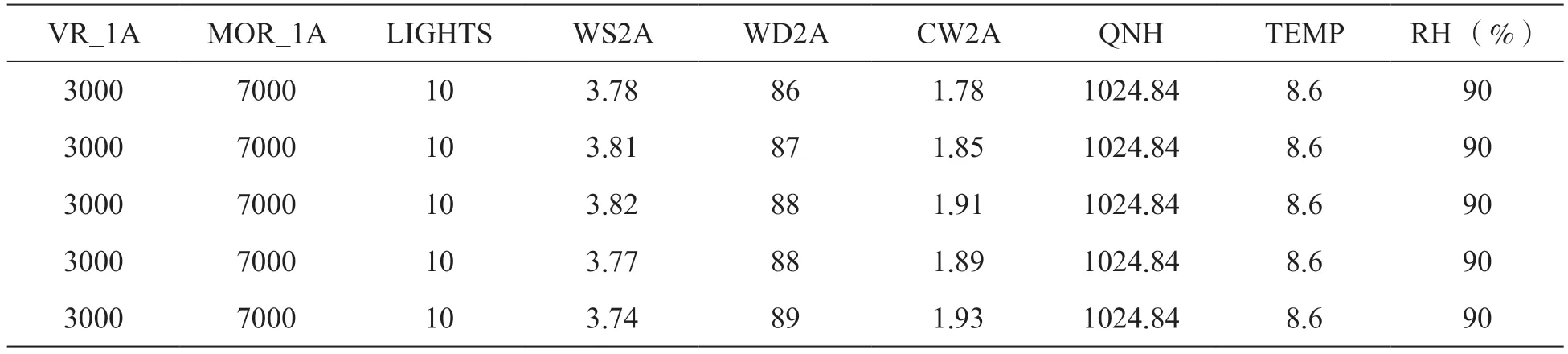
表2 气象光学视程(MOR)、跑道视程(RVR)和筛选后的的7 个变量的部分数据
2.3 因子分析
本小节主要考虑各变量之间的相关性。由图1 中的协方差矩阵可得,WS2A(2 分钟平均风速)、WD2A(2 分钟平均风向)和CW2A(2分钟平均垂直风速)的相关性较高,通过降维的方法进一步减少变量。本小节采用因子分析方法[7]对三个变量进行降维,得到了两个相对独立的变量。
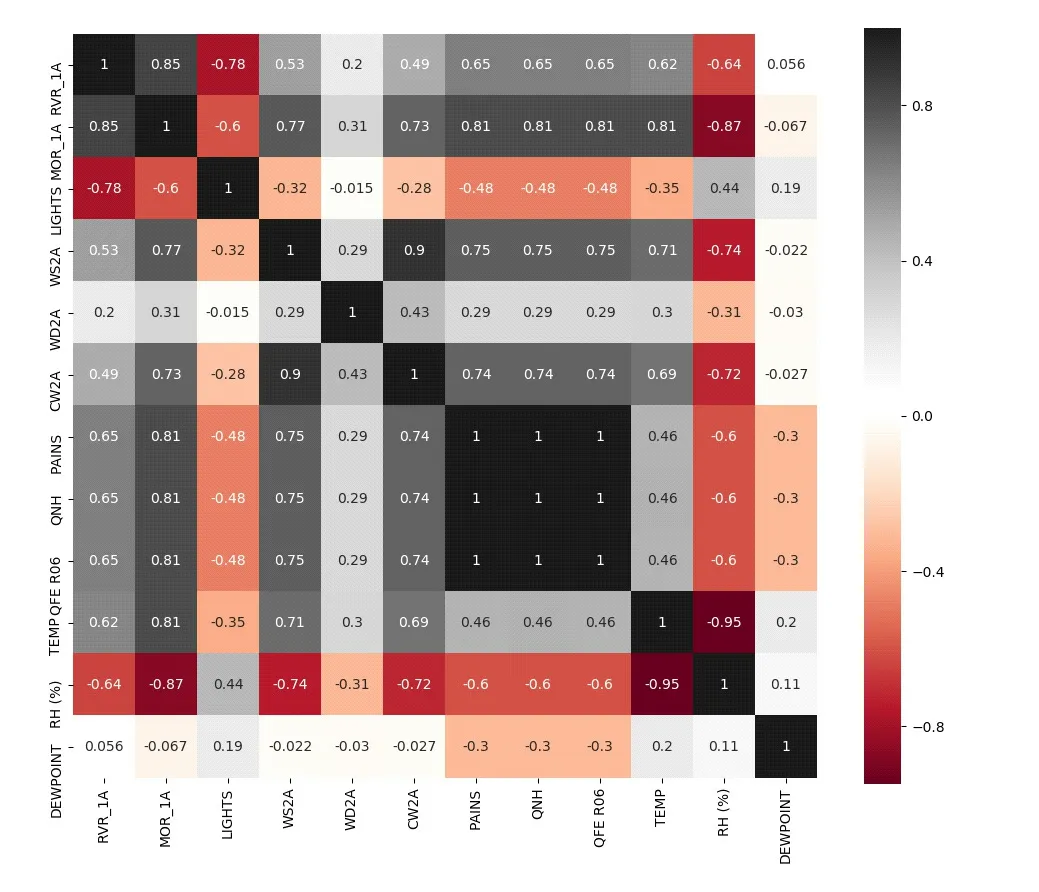
图1 协方差矩阵图
因子分析的思想是通过变量的相关系数矩阵,获得能控制所有变量的少数几个随机变量,并能用其描述多个变量间的相关关系。该方法要求原有变量之间要具有比较强的相关性。由于WS2A、WD2A、CW2A 三个变量之间的相关性很高,可以采用该方法进行降维。文章采用R 型因子分析进行分析,该因子模型为:
其中F1,F2,…,Fm为公共因子,ε 为Xi的特殊因子。其矩阵形式可表示为:
下面对WS2A、WD2A、CW2A 三个变量进行因子分析。假设其公因子为风速和风向,然后对三个变量进行Z-score 标准化处理,最后利用因子分析模型可得两个公因子与三个变量之间的关系。根据因子分析,两个公因子可表示为标准化后变量的线性组合:
2.4 回归分析
利用上述筛选好的特征变量,构建最终针对能见度的预测模型。回归分析可以对各变量进行拟合,主要用于预测输入变量(自变量)和输出变量(因变量)之间的关系[8]。回归模型表示从输入变量到输出变量之间映射的函数[9]。因此,回归问题的学习等价于函数拟合,是监督学习的一个重要问题。回归问题可以分为学习和预测两个过程(如图2 所示)。首先给定一个训练数据集:
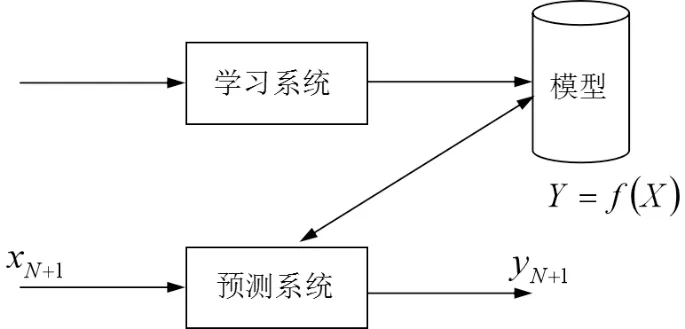
图2 回归问题示意图
Xi∈Rn,i=1,2,…,N是输入,yi∈R是对应的输出。学习系统基于训练数据构建一个模型,即函数Yi=F(Xi)。根据新的输入XN+1,预测系统所依据的学习模型Yi=F(Xi)。
依据上述模型可确定相应的预测值yN+1。文章采用线性回归的方法对数据进行拟合,其线性回归模型定义为:
其中W 是所要求的参数,X 是输入的数据矩阵,Y 为数据集标签,具体公式为:
这里Xi(j)表示数据集第i个样本的第j个属性值,数据集一共有N个数据,n个属性。因为考虑常数项,所以在数据矩阵X的第一列全为1。线性回归模型的目标是寻找一组参数W,使得Y=XW尽可能地逼近真实值。
下面对能见度进行回归分析,构建能见度与各特征变量之间的关系。首先对6 个自变量和一个因变量组成的数据集进行Z-score 标准化处理;然后采用均方误差作为损失函数进行线性回归。根据实验可得,各变量的回归系数分别为-0.164,0.569,0.609,0.031,-0.838 和0.796,且 常 数 项为-0.001。因此能见度与各地面气象观测之间的关系可表示:
由表3 可得,该回归模型预测能力良好,均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)分别达到了0.0685、0.2617、0.2172。三种反应预测值误差实际情况的指标均证明了该回归模型具有良好的预测能力。另外拟合优度R2为0.934。拟合优度是指回归直线对观测值的拟合程度。R2最大值为1,R2的值越接近1,说明回归模型对观测值的拟合程度越好,反之,R2的值越小,说明回归模型对观测值的拟合程度越差。因此,实验结果表明回归模型(12)的预测与拟合程度良好。

表3 线性回归模型性能
虽然拟合优度R2度量了回归模型与样本观察值之间拟合程度,但是R2本身却不能反映回归系数是否在统计上是显著的。因此,需要对该模型回归系数的显著性进行检验。文章采用了验证模型显著性的F检验。假设模型为:
原假设和备择假设分别为:
这里ESS、RSS 分别为回归平方和、残差平方和。自由度为k,n-k-1,其中为自变量个数,为样本数。Yi,表Y^i示,Y第 个因变量表示i=1,2,…,n回归模型对应的预测值,Y所有因变量的平均值。给定显著性水平α=0.01,n=5755,k=6,将相关数值对应临界值表可以得到临界值Fα(k,n-k-1)=2.805。
由计算得知F统计量为20.739,F>Fα(k,n-k-1),拒绝原假设,因此原方程总体上的线性关系显著成立。
3 基于视频数据的能见度预测模型
3.1 视频数据预处理
为了采用深度学习模型对视频数据进行分析,需要进行如下的数据预处理:(1)缺失值、异常值等处理;(2)将视频数据转化为图片数据;(3)给图片数据赋予相应的能见度MOR 值,将其作为标签。具体步骤如下。
文章选取2020 年3 月13 日从00:00 到11:48时间段的两个场景的视频数据。图3(a)是场景一的截取图片,图3(b)是场景二的截取图片,其中00:00 到08:00 时段具有能见度标签。将此部分作为强监督数据集,其他部分作为无监督数据集。通过Python 将视频数据转换为图片数据。对视频进行分帧,按照每秒一张截取图片,将图片保存备用。

图3 不同场景下的视频图片
给定图片对应的能见度值。机场AMOS 观测数据中每隔15 秒记录一个能见度MOR 值,但是图片按照每秒进行截取,因此将强监督数据集中每15 张图赋予一个MOR 值作为15 张图片的能见度值,如30-44 秒间的15 张图片的MOR 值均为3000(30 秒时的MOR 观测数据)。这种方法不仅利用了大量无标签数据,同时考虑了时间关系,便于网络收敛与提高精度。
考虑到能见度MOR 的增量以最少50 为量级,为方便计算将MOR 值都除以50,并将其作为标签。同时,在预测时得到的值也需乘以50 作为最终的预测值。在增快了网络收敛速度的同时增加了回归的精度。
确定标签后,将数据集以一定比例分为训练集、验证集和测试集。
3.2 深度残差回归网络架构设计
在深度学习中,一般神经网络的每一层都用来提取特征,深度越深,在不同层次上提取的信息就越多。但网络的深化通常会出现梯度消失和梯度爆炸,使得深化网络性能会变得更差。残差网络(Resnet)是何凯明在2015 年提出的一种网络结构,它由多个残差块组成,且残差块使用跳跃连接。残差网络通过残差设计解决了网络深化带来的性能下降和梯度问题[10]。图4 展示了一个残差块结构,其中x表示输入,F(x)表示残差块在第二层激活函数之前的输出,即F(x)=W2σ(W1x),其中W1和W2表示卷积层1和卷积层2 的权重,σ表示 ReLU 激活函数。最后残差块的输出是σ(F(x)+x)。
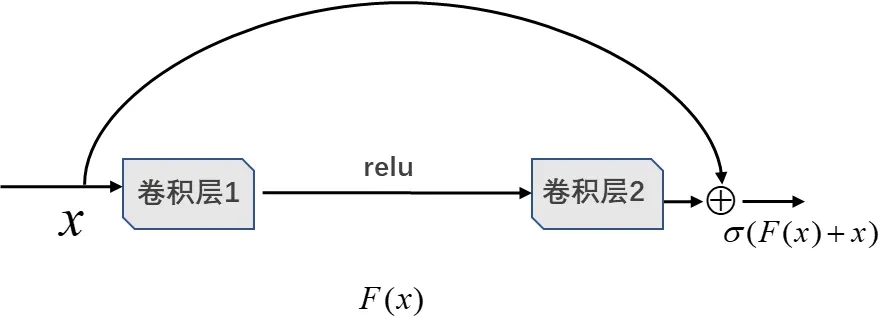
图4 残差块
文章的深度学习模型主干选择Resnet50。该网络包括 50 个卷积层,每一个卷积层后接一个ReLU 和 池化层。每三个卷积层之间接一个跳跃连接。Resnet50 经过了4 个残差块,每一个残差块中分别有3、4、6、3 个Bottleneck。
在该深度学习模型中,采用随机梯度下降法(SGD)进行更新。SGD 算法是从样本中随机抽取一组数据,训练后按梯度更新一次权重,然后再抽取一组数据,再更新一次权重。假设模型函数与目标函数分别为:
令一个样本的目标函数为:
则目标函数的偏导为:
参数更新为:
其中x(i)表示第i个样本,y(i)为x(i)对应的函数值,i=1,2,…,m,θj为参数,xj是样本的第j个分量,j=0,1,…,n,α为学习率。
由于Resnet50 最后一层Softmax 用来做分类,利用Softmax 层之前的框架来提取图像特征,把提取到的特征值作为输入向量,能见度作为输出。对特征值进行线性回归,得到能见度MOR 的预测结果。应用此手段,深度残差回归网络利用Resnet50 网络架构提取图像特征,利用回归作为预测输出,将单一的分类结果替换为线性预测值,达到能见度预测的目的。
3.3 基于视频数据能见度预测的实验及结果
在训练模型方面,为了验证标签和模型的准确性,挑选具有真实观测的MOR 值的图像作为测试集。表4 给出了文章所采用数据集的划分方式。
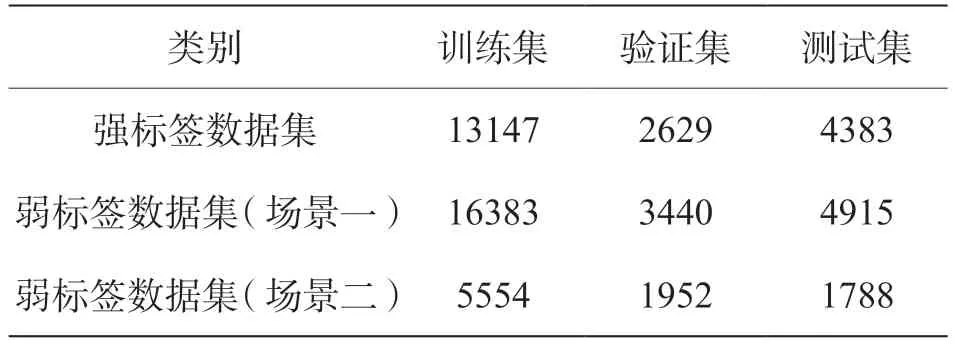
表4 数据集概况
本实验采用搭载了4 个NVIDIA Tesla V100 GPU 的服务器,在PyTorch1.1.0 框架下搭建神经网络进行训练。使用SGD 梯度下降方法,学习率为0.001。图片压缩到224*224,衰减率为0.2,且衰减间隔为20。以batch size 为128 训练了80个epoch。具体训练步骤如下。
(1)在强监督数据集上以上述参数进行训练,得到初步能见度预测模型;
(2)将弱标签数据集中的图片放到初步能见度预测模型进行预测,得到弱标签。混合两种数据集,重新以8∶1 ∶1 的比例划分训练集验证集与测试集进行训练,得到最终模型。
(3)在模型评估阶段,本小节采用MAE 误差作为评价指标,表5 描述了测试集的具体评价情况。
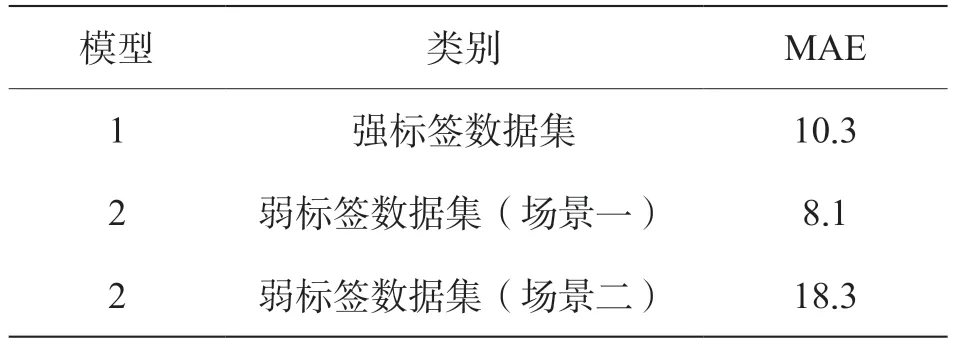
表5 模型评价结果
从表5 可以看出:(1)对于强监督模型来说,本模型通过引入上下帧数据的标签信息作为参考,在增大数据量的同时修正了标签,在测试集上使平均绝对误差达到了10.3 m,具有优秀的性能。(2)对于弱标签图像来说,通过加入伪标签,大幅度增大训练数据量,在与强监督模型相同的场景1 中将平均绝对误差降低2.2 m。在场景2 中也具有较好的表现。(3)文章同时将两种模型对部分测试集的预测和真实值的结果进行可视化用于定性判断,如图5 所示。笔者将强标签训练集训练得到的模型定义为模型1,将弱标签训练集训练得到的模型定义为模型2。从图5 中可以直观的看出深度学习模型在测试集中的预测结果与真实值极为接近,预测效果良好,模型性能优越。
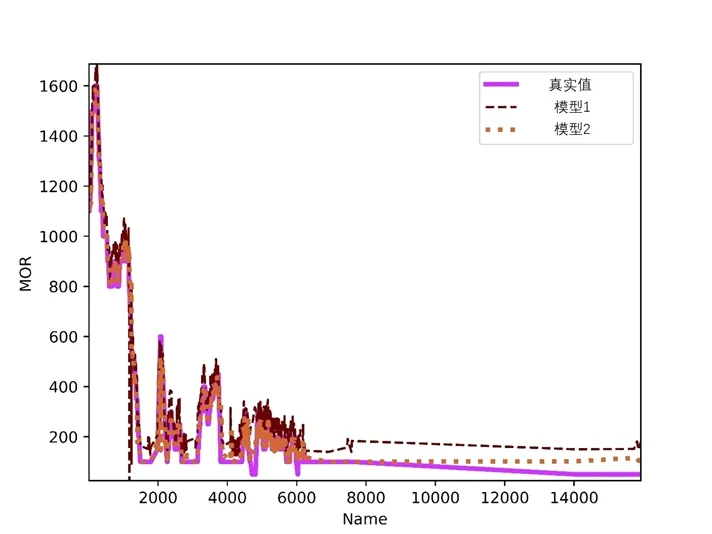
图5 深度学习模型预测能见度与真实值比较
4 讨论与结论
文章针对机场能见度预测困难、设备成本高等问题,分别通过AMOS 观测数据以及监控视频数据两种方式,构建模型对能见度进行预测。
首先,文章对AMOS 数据进行整合与分析,自主创建了两项指标,并结合已有指标进行多项式回归得到表达式。该表达式通过假设检验证明了有效性,线性回归精度已经达到一个可观值在实际应用中可以对能见度进行可靠的预测。但是由于缺乏特征之间更具体的关系,只能进行线性拟合,未考虑表达式的真实结构,未来尝试对表达式进行基于真实现实意义的解析。
其次,文章通过对机场监控视频进行创新性的处理,按照每秒对视频进行画面抽取并赋予标签后,结合前一秒图像与后一秒图像对标签进行调整。将单个视频扩增到万级图像数据量的同时保留了视频连续信息。提出了深度残差回归网络提取特征并回归预测,突破了传统方法提取固有特征的限制,将平均绝对误差(MAE)降低至10.22 m。同时将视频中没有标签的部分进行预测,并与有标签数据混合重新划分训练集测试集进行再训练,进一步提升模型性能,将平均绝对误差降低至8.11 m。该模型以极低的平均绝对误差证明了该模型对视频数据中变化的场景均有较好的能见度预测能力。但是由于文章采用数据的时间段为凌晨零点至早上八点,可见度范围在50 m至1100 m,数据跨度较低,只能对未给标签的数据近似预测,无法完整的对各种情况下(如雾气较小的中午时间段等)的能见度进行准确的预测。未来尝试搜集全时间段数据,构建完整的能见度预测模型。
综上所述,文章在两种数据下构建的模型均对能见度具有较好的预测效果,并对未来机场能见度预测的实际应用有着重大意义。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
华东师范大学学报(自然科学版)(2017年1期)2017-02-27
考试周刊(2016年54期)2016-07-18
中国交通信息化(2016年6期)2016-06-06
自动化学报(2016年8期)2016-04-16
海洋气象学报(2016年3期)2016-02-28
气象研究与应用(2016年4期)2016-02-27
