
基于CEEMDAN-GAN的金融时间序列预测建模研究
2024-01-25 09:35王认真邱凤鸣
淮南师范学院学报 2023年6期
王认真,陈 尹,邱凤鸣
(1.合肥大学 经济与管理学院,安徽 合肥 230601;2.安徽农业大学 财务处,安徽 合肥 230601)
一、引 言
金融市场因具有较高的投资回报率吸引了大量的投资人士和学者对金融产品价格走势进行预测研究,但金融市场受市场情绪、政策等多种复杂因素影响,使其走势包含大量噪声。最早学者们使用传统统计学方法如ARIMA等模型用来研究各因素对于金融产品价格走势的影响,但金融时间序列多具有非线性、不平稳的特性,传统模型的预测表现并不理想[1]。近几年飞速发展的机器学习方法如支持向量机(SVM)等模型通过引入核技巧来对模型输入特征进行非线性映射,从而能较好地处理非线性时间序列数据。深度学习是机器学习研究的一个新领域,模型构建更为复杂,对数据特征之间的关系着力更多,它能够从训练数据包含的有限特征中推断出新的特征,在噪音中提取信号。基于这些优点,深度学习方法广泛应用在金融时间序列的预测建模中[2]。
长短期神经网络(LSTM)作为一种改进之后的递归神经网络(RNN),具有长时记忆功能,在时间序列预测建模上相较传统神经网络有很大优势。薛涛等提出一种基于经验模态分解(EMD)和多分支长短期神经网络的预测模型对欧元兑美元汇率进行预测,发现结合EMD的组合模型可以提高传统模型的预测准确率和模型稳定性[3]。贺毅岳等将CEEMDAN引入到股市指数预测建模中,对指数进行分解与重构,实验结果表明CEEMDAN结合LSTM的预测性能优于传统建模方法,具有更低的预测误差和滞后性[4]。作为新一代RNN,门控制循环单元网络(GRU)具有结构简单、不易过拟合等优点而广泛应用于时间序列预测建模中[5]。黎镭等使用GRU对上证中18支股票的日收盘价数据进行测试,证明了GRU具有的强大学习和泛化能力[6]。刘宁宁等将主成分分析和GRU相结合对上证综指进行预测,通过构建主成分分析与RNN、LSTM、GRU的融合模型,发现两层GRU模型取得了最好的预测效果[7]。近年来学术界热议的GAN是深度学习未来的研究重点之一,GAN能够学习和探索真实样本的分布与结构,同强化学习比,其更贴近人类的学习模式,具有更强大的性能。GAN在金融时间序列预测的研究尚处于探索阶段,王静等提出了一种基于经验模态分解生成对抗网络(EMD-WGAN)模型对沪深300指数进行预测,通过与传统金融时间序列预测方法对比,证明了该模型具有更好的性能[8]。
随机森林(Random forest)是一种集成机器学习方法,其特征重要性评分(VIM)可作为高维数据降维的方法,已被广泛应用于金融等领域的各种特征选择问题上[9-11]。为进一步提升GAN对于高频金融时间序列预测的准确率和稳定性,本文提出基于CEEMDAN的GAN模型,该模型使用CEEMDAN算法对金融时间序列进行分解,将分解得到的内涵模态分量(IMF)和残差作为GAN的输入。为防止模型过度复杂,使用随机森林算法对IMF和残差进行了特征重要性评估和对IMF分量进行了均值为0的t检验来对输入进行降维和重组,进一步提高模型准确性和稳定性。本文可能的创新包括以下几个方面:一是将图像信号处理领域广泛应用的GAN模型引入到金融领域时间序列的预测;二是将CEEMDAN算法引入到汇率的预测建模过程中,分解获得波动相对简单的相互独立的子序列,便于研究其波动规律;三是利用随机森林算法,对各子序列进行重组降维,减少模型复杂度,降低模型误差。
本文使用美元兑人民币汇率(USDCNY)作为实验数据,对所提出的模型性能进行评估和分析。使用另外两种时序预测建模常见的深度学习方法LSTM、GRU和两种信号处理方法经验模态分解、总体平均经验模态分解构建组合模型作为对比模型。实验结果表明,CEEMDAN-GAN模型在金融时间序列预测上的表现优于现有常见模型,证实了基于CEEMDAN的GAN模型对复杂时间序列信息的有效预测与应用。
二、建模的理论基础
(一) CEEMADN
EMD是处理非平稳信号的方法Hilbert-Huang变换的重要组成部分,如今广泛应用在很多领域[12],但EMD方法存在一些缺陷,比如脉冲干扰和噪声等会导致分解结果出现模态混淆[13]。很多学者就这一问题提出了解决方法,Wu等通过研究白噪声信号的统计特征,提出了总体平均经验模态分解( EEMD),EEMD对原始信号多次加入不同的白噪声进行EMD分解,对多次分解结果进行平均得到最终的IMF[14]。Yeh等提出了补充的总体平均经验模态分解 (CEEMD),CEEMD通过向待分解信号中添加两个相反的白噪声,分别进行EMD分解[15]。但经过EEMD和CEEMD分解得到的IMF中会残留一定的白噪声,增加了后续分析处理的难度和误差,CEEMDAN算法则较好的解决了这个问题,该算法有效阻止了白噪声从高频到低频的转移传递[16],具体过程如下。

步骤1 将高斯白噪声vj加入到y(t)得到y(t)+(-1)qεvj(t),其中q=1,2。对其进行EMD分解就得到了第一阶本征模态分量C1:
(1)
步骤2 对分解得到的N个模态分量进行总体平均就得到CEEMDAN分解的第1个本征模态分量:
(2)
步骤3 将信号y(t)减去第1个本征模态分量得到残差r1(t):
(3)

(4)
步骤5 将残差r1(t)减去第2个本征模态分量得到残差r2(t):
(5)
步骤6 重复上述步骤,直到得到的残差为单调函数,无法进一步分解,整个算法过程结束。若分解获得的本征模态分量数量为K,则原y(t)经CEEMDAN分解结果如下:
(6)
CEEMDAN可以有效地将原始信号分离为具有不同频率尺度的不同本征模分量,相较于EEMD等方法,CEEMDAN可以提高重构精度,减少迭代次数,解决模态混合问题。
(二) GRU
人们做大多数决定时,不仅要了解当前信息,还需要参考之前的信息,如汇率、股指等都是连续的序列数据。RNN专门用来处理具有时间依赖的序列数据,在RNN中,每个输出由当前输入和之前的信息共同决定,但也带来一个新的问题,有时我们需要大量之前的信息,当之前的信息距离当前预测目标太远时,RNN可能会出现梯度消失的问题,之前的信息会呈指数级丢失,由此出现了一种新的网络LSTM。LSTM较好的解决梯度消失等问题,但它引入了3个门结构来控制输入和输出,参数较多,训练起来难度比较大。GRU模型与LSTM类似,不过它只有两个门结构:更新门和重置门,结构更为简单、更容易实现,性能也更为稳定。GRU模型结构如图1所示:其中t为时刻,xt为当前时刻网络的输入,ht为上一时刻的记忆,σ代表sigmoid函数,⊗表示向量元素乘,⊕表示向量和。

图1 GRU模型示意图
GRU首先会分析在当前时刻,根据当前的输入,我们需要用到记忆中的哪些部分:
rt=σ(Wr·[ht-1,xt])
(7)
用rt(重置门)乘以ht-1就得到了可利用的记忆信息,然后和当前时刻的信息xt合并在一起输入到tanh网络中:
(8)
接着通过当前时刻的输出去更新记忆,先计算更新程度:
zt=σ(Wz·[ht-1,xt])
(9)
再利用zt(更新门)对上一时刻的记忆和当前的输出进行加权结合得到当前时刻记忆:
(10)
GRU比LSTM模型更简单,训练速度也更快,预测性能可以达到和LSTM相同的效果甚至更好[17]。
(三) GAN
常见的机器学习模型大致可以分为“判别式”和“生成式”,生成模型由于能够学习数据的隐含特征表示,近些年发展迅速。GAN是一种基于对抗学习的深度生成模型,广泛应用在图像信号等领域。

图2 GAN模型示意图
如图2所示,GAN的主体包括一个生成器G(Generator)和一个判别器D(Discriminator),当输入真实数据x时,期待判别器D输出真(接近1);当生成器G的输入随机变量z,输出是与x相近的生成样本G(z)时,将G(z)输入到D,这时期待D输出假(接近0)。整个训练过程中G的目标就是尽量欺骗D,使D输出真(把G(z)误判为x),相对应D的目标就是可以正确区分x(输出1)和G(z)(输出0),就这样G和D不断的进行对抗训练,最后无论是x还是G(z),D的正确判别概率是稳定的。GAN的对抗训练本质上是一个求minmax问题的解,目标函数如下:
Εz~pz(z)[log(1-D(G(z)))]
(11)
三、实证分析
(一)建模分析
美元兑人民币汇率经CEEMDAN分解产生的IMF和残差波动特征相对简单,可充分提取分析汇率的波动特征。将CEEMDAN的时序分解与GRU的时序预测和GAN强大的特征学习能力的3个优势功能进行结合,GRU作为GAN模型的生成器,CEEMDAN分解得到的IMF分量进行重组作为输入,提出一个高准确性的汇率预测模型CEEMDAN-GAN。
(二)数据的选取
汇率是非常重要的经济指标,可以直接反映一个国家的宏观经济情况,是经济领域中最具有研究意义的数据之一。本文从Wind平台提取了2012年7月17日至2022年7月8日之间近十年美元兑人民币汇率的收盘价,共计2 494个数据作为金融时间序列预测建模的原始数据,数据走势如图3所示。
(三)数据的检验
对美元兑人民币汇率数据进行ADF检验,结果显示在1%显著性水平下序列非平稳;对汇率序列进行Jarque-Bera检验,偏度为0.294 72,峰度为1.867 8,P值近似为0,汇率序列分布显著非正态。可以看出美元兑人民币汇率序列非平稳且包含大量噪声,因此本文使用CEEMDAN对汇率序列进行分解、重组,运用非线性时序建模方法GAN进行预测建模。
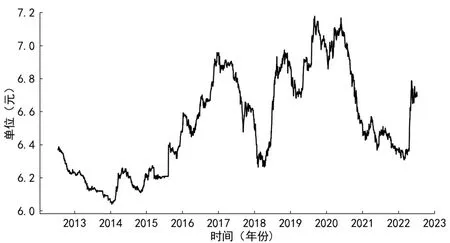
图3 美元兑人民币汇率
(四)数据CEEMDAN分解
按照前文所述CEEMDAN计算方法,对原始数据进行分解,共得到7个IMF和残差(图4)。由图4可以发现,从IMF1—IMF7到残差频率逐渐降低,各子序列变化也较原始数据更简单。

图4 美元兑人民币汇率CEEMDAN分解结果
(五)模型调优及效果评价
参考杨青等[18]的模型构建方法,使用前30个交易日的数值为输入来预测下一交易日的数值,选用R-squared(决定系数)、MAE(平均绝对误差)、MSE(均方误差)和RMSE(均方根误差)4个评价指标对模型性能进行评估。
1.使用全部子序列GAN建模
使用全部子序列当做模型输入,参考刘宁宁等[7]对GRU的研究,本文使用2层GRU作为GAN的生成器。根据高昆仑等[19]的研究,一维卷积神经网络可以很好地应用于时间序列分析和具有固定长度周期的信号数据,故使用4层Conv1D作为GAN的判别器,对数据进行训练与测试,结果如图5和表1所示。研究发现模型在训练集上的表现出色,R2达到了0.997以上,但预测集上R2只有0.982 85,说明模型存在过拟合问题,表明模型输入过于复杂,需要对输入特征进行降维处理。

图5 使用全部子序列建模预测结果
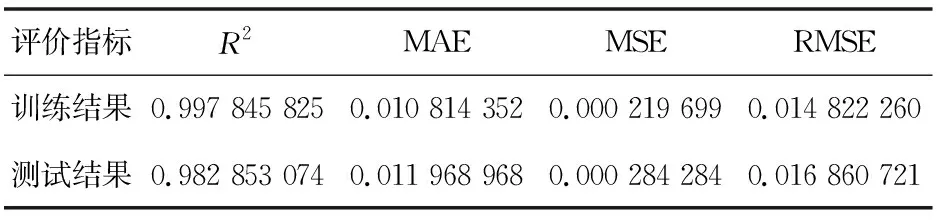
表1 使用全部子序列建模评估效果
2. 随机森林降维GAN建模及效果评价
为适当降低GAN预测建模的复杂度和避免模型过拟合,使用随机森林算法对所有序列重要性评估,表2呈现了归一化处理后的评估结果和相关系数。研究发现IMF1—IMF4的随机森林重要性评分(VIM)分别为0.000 455、0.000 469、0.000 764和0.001 321,可以看出信号频率逐渐降低但是重要性程度逐渐增加。从图4可以发现,高频信号围绕0均值值上下波动剧烈,几乎没有规律性,因为高频信号表示的是汇率短期的波动,这种短期波动主要受短期外汇储备变动、市场预期和噪声的影响和长期趋势的影响,使得高频信号VIM总体低于低频信号。IMF5—IMF7、残差的相关系数也明显大于IMF1—IMF4。因此,通过保留超过0.99的重要性对全部子序列进行降维,剔除相关系数较低的IMF1—IMF4共4个IMF信号来对模型进行训练和预测。

表2 子序列重要性评分与相关系数
实验结果(图6和表3)显示,相较于使用全部子序列作为模型输入,剔除4个高频IMF信号的预测模型的训练集RMSE增加了59.21%,训练误差显著放大。预测集的R2降到了0.915 944 333,RMSE增加了121.4%,模型解释能力不足,误差增大。虽然训练集的R2大于0.99拟合效果较好,但是从图6可以看出,剔除高频IMF信号作为输入后,模型无法预测短期波动的影响,整体预测值为一条平滑的曲线,表明高频IMF信号虽然包含噪声,和实际汇率走势相关性较低,但是其中包含了大量的有用信息如外汇储备变动、市场预期等,因此采用直接剔除VIM较低的IMF信号来降维的方式无法构建一个有效的美元兑人民币汇率预测模型,需要采用IMF信号重组方式进行降维处理。

图6 剔除高频子序列建模预测结果
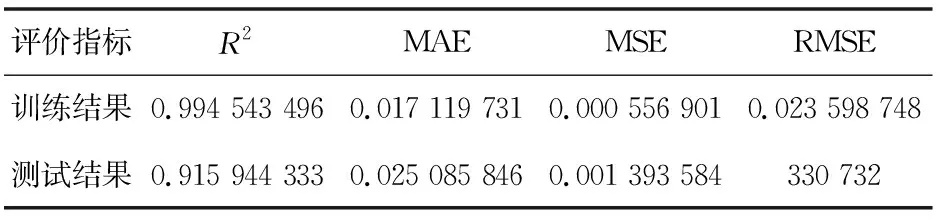
表3 剔除高频子序列建模评估效果
3. 所有子序列重组GAN建模及效果评价
参考李合龙等[20]的研究,对分解所产生的7个IMF分量进行重组。首先对所有IMF分量进行均值为0的t检验,其中IMF1—IMF4的P值分别为0.968 34、0.306 33、0.356 15和0.912 21,没有显著性差异。IMF5—IMF7的P值分别为0.007 20、1.321 17e-13和0.00673,均值显著不等于0。其中IMF5是首个P值小于0.05的本征模态分量,因此将IMF1—IMF4重组成为美元兑人民币汇率的高频分量,IMF5—IMF7重组为低频分量,将残差作为趋势项,具体如图7所示。重组后的子序列较为简单,有利于模型学习美元兑人民币汇率的长期趋势和短期波动特征。

图7 所有子序列重组
接下来使用高频、低频和趋势3个分量作为模型的输入进行训练和预测,预测结果如图8所示。由表4中的各项指标评估结果,可以看出子序列重组GAN模型训练和预测结果的RMSE差异不大,R2均大于0.99,解释能力较强,较好地解决了使用全部子序列GAN建模的模型过拟合问题。输入子序列从8个减少到了3个,简化了模型同时大幅提升了训练速度,相比较下,本模型训练结果的RMSE降低1.28%,差异不明显,但测试结果的RMSE降低了8.47%,模型预测准确性得到了进一步的提升。但IMF5—IMF7的VIM和相关系数均较高,重组为低频序列降低了模型复杂度的同时也损失大量中长期趋势信息。

图8 所有子序列重组建模预测结果

表4 所有子序列重组建模评估效果
4. 仅高频重组GAN建模及效果评价
研究发现IMF5—IMF7信号频率较低,与原始信号走势相似,包含的更多的是美元兑人民币汇率中长期趋势,较少受情绪波动、投机活动、突发事件等噪声影响,所以可以直接作为模型的输入,保留完整的趋势信息来对预测模型进行优化。现在仅将包含较多噪声的IMF1—IMF4重组为高频信号,IMF5—IMF7、残差直接作为信号进行输入,预测结果如图9所示。实验所得模型的评价指标结果(表5)显示训练和测试结果的R2均大于0.99,模型解释能力较强。相较于全部子序列重组建模,本模型训练、测试结果的RMSE分别降低了46.62%和44.64%。虽然输入子序列从3个增加到了5个复杂度有所提升,但是预测模型预的性能有了较大提高。
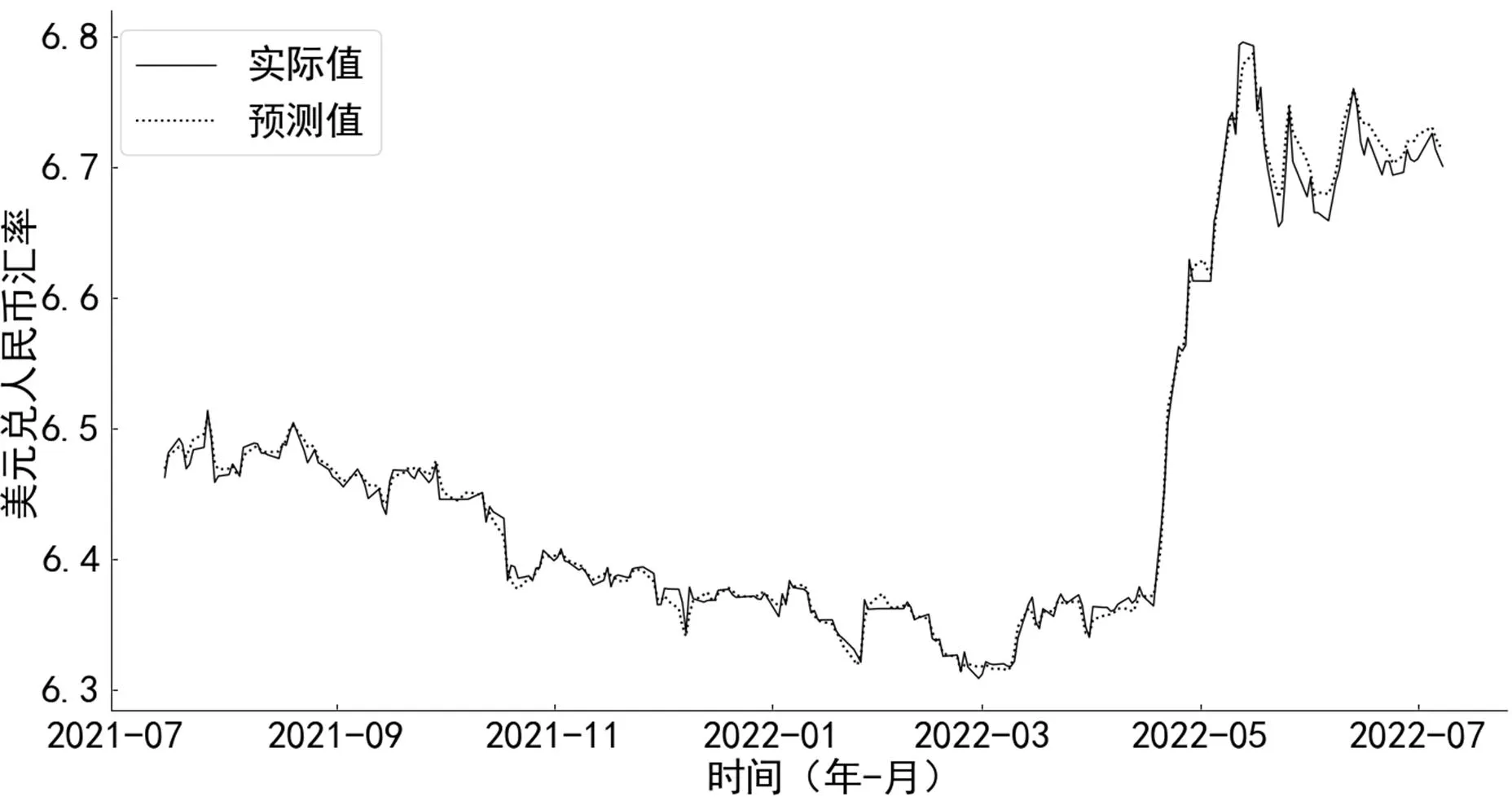
图9 仅高频子序列重组建模预测结果

表5 仅高频子序列重组建模评估效果
四、CEEMDAN-GAN模型预测效果的对比验证分析
本文以美元兑人民币汇率为实验数据,利用一些经研究证实性能比较突出的时间序列预测建模方法[3-8],包括LSTM、GRU、GAN直接进行预测和结合EMD、EEMD、CEEMDAN的组合模型进行预测,作为实验的对比方法,对CEEMDAN-GAN模型的预测有效性、适应性进行评估。表6给出了各模型的预测结果的各项评估指标,结果显示在不对汇率数据进行分解的情况下,3个机器学习模型预测结果的R2均小于0.99,模型解释能力较差。RMSE的结果也比较接近,GNA模型仅比LSTM、GRU模型提升了6.36%和4.32%,说明仅使用原始序列来构建预测模型时输入特征过于简单,训练效果不佳,误差较大,GAN也无法发挥强大的学习真实样本分布优势。在组合模型方面,本文比较了相同分解方法下不同深度学习模型的表现,从图10中可以看出EMD、EEMD和CEEMDAN 3种分解方法下LSTM测试结果RMSE最大,EMD-GRU模型略低于EMD-GAN模型,EEMD、CEEMDAN组合模型中GAN性能明显优于LSTM、GRU,且CEEMDAN-GAN模型取得了最好表现,R2大于0.995,RMSE降至了0.008 543,较之其他预测模型准确度有了较大提升。当使用相同深度学习模型和不同分解方法时,从图11可以看出,在预测性能上,EMD-LSTM和EEMD-LSTM表现几乎一致,CEEMDAN-LSTM优于其他两种分解组合模型;EEMD-GRU测试误差大于EMD-GRU,EEMD-GAN测试误差小于EMD-GAN,说明两种分解方法各有优劣。与前面两种分解组合模型相比,CEEMDAN-GRU和CEEMDAN-GAN均取得了最好的表现。

表6 不同建模方法预测效果对比分析结果

图10 不同深度学习模型性能比较

图11 不同分解方法性能比较
五、结论及展望
本文运用CEEMDAN将金融时间序列分解为不同频率与波动特征的子序列,再进一步对子序列进行降维与重组处理,同时使用在时序预测上有显著优势的GRU作为GAN模型的生成器,依据随机森林重要性评估和相关系数大小对所有子序列进行降维重组,最后对不同重组方法进行性能评估,提出了一种CEEMDAN和GAN相结合的汇率预测模型CEEMDAN-GAN。选取了金融市场具有代表性的美元对人民币汇率为实验数据,并对数据进行详细的实证分析。实验结果证明,本文所提出的CEEMDAN分解、重组方法可以有效地将单一汇率数据重构为保留信息相对完整、结构简单的子序列,提高了建模的效率与性能,所提出的CEEMDAN-GAN模型预测的具有误差小、拟合度高等优点,同时也为构建其他金融时间序列预测模型提供了参考。另外,本文也有不足之处,如GAN训练时G和D容易出现一方强大一方弱小的问题,若不及时平衡就会导致梯度消失(D强G弱)和模式奔溃(G强D弱)问题。后续考虑采用修正的损失函数Wessertein距离代替JS散度,Wessertein距离没有上界,不会出现梯度消失的情况;同时,金融产品价格走势受宏观经济环境和市场参与者情绪波动影响较大,后续研究拟将宏观经济指标与市场恐慌系数纳入预测模型,进一步提升预测模型可解释性与性能。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
中国外汇(2019年17期)2019-11-16
中国外汇(2019年13期)2019-10-10
中国外汇(2019年11期)2019-08-27
自动化学报(2019年6期)2019-07-23
中国外汇(2019年21期)2019-05-21
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
河南科技(2015年8期)2015-03-11
上海电机学院学报(2015年4期)2015-02-28
