
船载投料系统饲料颗粒流落点预测
2024-01-26 08:19俞国燕郭国全刘皞春
广东海洋大学学报 2024年1期
俞国燕,王 涛,郭国全,刘皞春,3
(1.广东海洋大学机械工程学院,广东 湛江 524088;2.广东省海洋装备及制造工程技术研究中心,广东 湛江 524088;3.广东省南海海洋牧场智能装备重点实验室,广东 湛江 524088)
自动化投喂系统在深海少人化、无人化养殖中不可或缺。本研究关注饲料颗粒流落点问题,旨在提供优化投喂系统参数,为全自主投料系统奠定基础[1-2]。
饲料颗粒流落点预测研究尚未见报道,现有研究侧重于弹道和消防水射流。魏五洲等[3]利用外弹道学理论构建质点弹道数学模型,通过多传感器融合提高了落点预测精度;Song 等[4]通过考虑多因素建立了二次修正模型,提高了弹丸落点预测准确性;吴朝峰等[5]结合遗传算法和BP 神经网络,提升了预测精度;Zhang等[6]采用双向长短期记忆网络提高了预测的实时性。相对于炮弹,饲料颗粒微小,颗粒间存在相互作用力导致饲料颗粒流形态不固定,使其初速度难以准确测量,运动模型更为复杂。因此,将弹道落点预测方法直接用于饲料颗粒流的落点预测具有一定困难。
此外,消防水炮水射流落点预测研究大多通过受力分析、质点运动学和外弹道学理论等原理建立水射流运动模型[7-11]。部分研究采用图像处理方法分割水射流轨迹并预测落点。例如,Zhu 等[12]通过图像处理算法成功分割了水射流轨迹并预测其落点;Zhu 等[13]利用混合高斯背景算法克服了复杂场景中提取水射流轨迹的挑战,从而提高了预测稳定性;周俊杰等[14]则采用深度学习方法进行水射流轨迹分割及落点识别。饲料颗粒流虽与水射流的落点预测相似,但水射流的动力学特性相对稳定,易于建模[15-16]。传统图像处理方法用于水射流轨迹分割的稳定性较差,不及深度学习方法在复杂场景中的出色表现,然而在实际生产中,水面情况复杂落点难以识别。
为此,本研究提出一种结合混合网络模型与BP 神经网络的饲料颗粒流落点预测方法(MLBP),根据饲料颗粒流特点及传统图像分割方法的局限性,利用混合网络模型对饲料颗粒流轨迹进行分割,并提取关键轨迹参数信息,作为BP 神经网络的输入,实现对饲料颗粒流落点的精准预测,并搭建实验样机验证该模型在预测精度和实时性方面的优势。
1 数据准备
1.1 数据获取
为构建数据集,在广东海洋大学工程训练基地搭建实验平台(图1)。该平台由气力输送动力源(罗茨鼓风机)、下料机、变频器、高速相机、钢丝软管和喷嘴构成。为降低成本和避免饲料颗粒浪费,本研究采用常见塑料颗粒作为饲料的模拟物(以下简称为饲料),其粒径为4 mm。实验平台的设备型号、参数和功能详见表1。

表1 实验装置及相关参数Table 1 Experimental setup and specific parameters

图1 实验平台及主要设备Fig.1 Schematic Diagram of Main Components and Experimental Equipment
在饲料颗粒流轨迹图像分割中,须尽可能获取高质量轨迹图像。为此,本研究采用文献[12]提到的近场视觉(near-field computer vision,NFCV)传感器装置(图2)。该装置由视觉传感器装置和计算机组成。视觉传感器装置包括高速相机和支架,其中高速相机被固定于支架。由于饲料颗粒流的喷射距离较远,饲料颗粒流下落位置远离投料口,难以在投料口拍摄到完整的轨迹图像,且利用远离投料装置的视觉传感器来捕获轨迹图像也不现实,导致完全捕获轨迹图像难度极高。经测试,本研究将高速工业相机安装在距离投料口1.5 m 处,并倾斜25°拍摄饲料颗粒流轨迹来解决此问题。
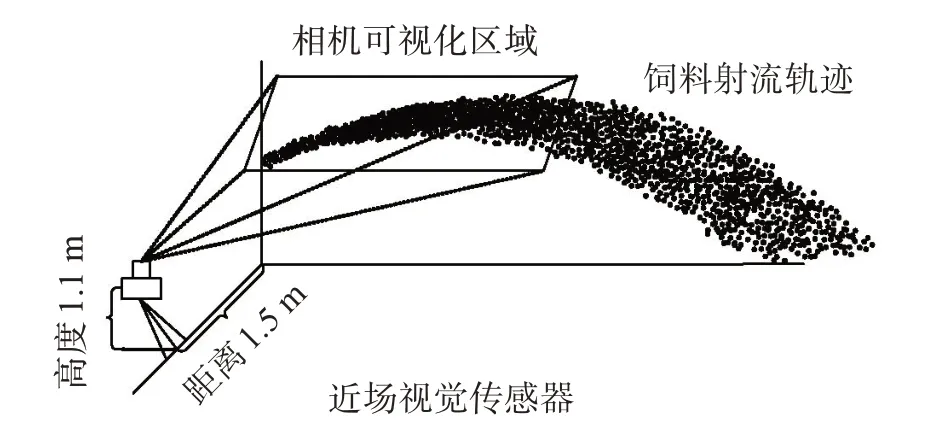
图2 近场视觉结构示意Fig.2 Schematic diagram of near-field vision structure
此外,本研究利用计算机采集软件获取高速相机捕捉的轨迹图像,记录饲料颗粒流落点中心位置距离饲料喷嘴正下方的直线距离,将数据保存至计算机硬盘。实验共采集3 750 张轨迹图像,将其统一处理为384像素×384像素。将3 750张轨迹图像按照8∶1∶1 的比例[17]划分为卷积网络模型训练数据集(3 000 张)、验证数据集(325 张)和测试数据集(325张)。
1.2 数据集构建
数据集构建流程如图3。首先,对原始图像进行透视变换[18-19],校正采用图3 方法获取的轨迹图像与相机成像平面之间的夹角,将轨迹图像转换到前视图平面。其次,利用labelme[20]软件对获取的3 750 张轨迹图像打标签,得到初步的标签图像。最后,为解决实验中发现轨迹边缘的像素更易出现错误预测,使用距离变换(DT)算法对标签进行处理[21-22]。通过DT算法将轨迹图像的标签进行解耦,得到主体标签图(BLI)和细节标签图(DLI)。
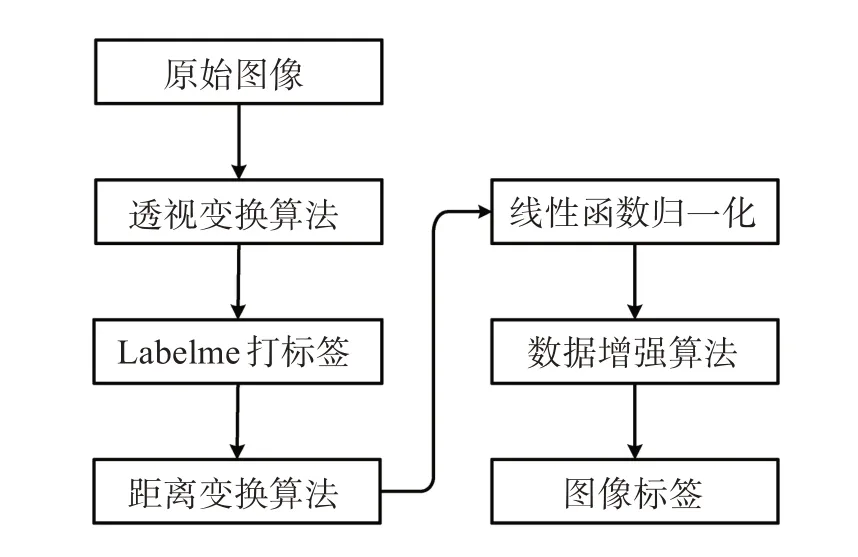
图3 数据集构架流程Fig.3 Flowchart of dataset construction process
将得到的二值标签图像I划分为前景Ifg和背景Ibg,对每个像素p,假设I(p)是其对应像素值,那么p∈Ifg,则I(p)等于1;p∈Ibg,则I(p)等于0。为使用DT 算法,采用欧氏距离计算像素之间的距离。如果像素p属于前景,DT 将首先在背景中查找最近的像素q,使用欧氏距离来计算像素p和q之间的距离;如果像素p属于背景,则它们的最小距离被设置为零,以便生成新图像I′的像素。距离变换后,原图像I被变换成I′,其中像素值I′(p)不再等于0 或1。故采用离差标准化算法将I′像素值映射到[0,1]区间。与原图像I相比,I′的像素不仅取决于前景或背景,也与其在轨迹图像中的相对位置有关。此时轨迹图像的中心像素值最大,远离轨迹中心的像素值较小,故可将I′作为主体图,则I′去除主体图后将得到细节图。此外,为消除背景带来的干扰,将新生成的标签与原图像I相乘,如此便得到主体标签图BLI和细节标签图DLI(公式1)。最终经过DT 算法处理轨迹图像的结果如图4所示。

图4 距离变换算法处理结果Fig.4 DT(Distance transform)algorithm processing result
另外,本研究还采用图像标准化、随机反转和随机裁剪以扩充训练数据集,增强模型的泛化性能,并提升对不确定性的处理能力,从而提高模型的鲁棒性[23]。
2 MLBP算法
2.1 饲料颗粒流轨迹分割模型
本研究基于标签解耦框架(LDF)[24]模型(图5),提出一种改进的LDF 模型(混合标签解耦框架,Mix-LDF),用于饲料颗粒流的轨迹分割。

图5 LDF网络结构Fig.5 LDF(Label decoupling framework)Network Architecture
2.1.1 轻量化LDF 模型 LDF 模型由主干网络、主体解码网络、细节解码网络和融合编码网络组成,通过各分支间的信息交流,以更好的促进特征表达,提高分割精度。然而,其自身参数量较大,难以满足实时系统(尤其是嵌入式系统)的快速响应需求。为解决此问题,本研究选取MobileNetV3[25]结构中的倒残差结构,用于改进LDF 模型的主干网络。由于倒残差结构具有更少的参数和计算量,故其推理速度更快。且在满足需求的前提下,可在计算资源受限的嵌入式设备中运行。
此外,为提高网络对于重要特征的关注度,本研究在LDF 模型主干网络的后四个卷积层之后均引入了通道注意力挤压-激励(SE)模块[27]。这样的设计有助于网络在学习过程中更加聚焦于关键特征,从而提升整体性能。为减少网络的计算参数使其更轻量化,本研究将LDF 模型中所有使用3 × 3卷积核的操作均替换为深度可分离卷积,进一步提高模型的运行速度,有效降低资源消耗,使网络更适用于计算资源有限的环境。
2.1.2 视觉多头自注意力模块 通过2.1.1节的改进有效改善系统运行的实时性,但也导致系统的分割性能略微下降。为提高模型的分割性能,本研究提出利用自注意力机制在特征间交互作用的能力,以十字交叉注意力模块[28](CCAM)为基础构建一种视觉多头自注意力模块(MHSA)。与自然语言中的自注意力机制相比,MHSA 可有效降低参数量,从而能更好适用于嵌入式系统。同时,MHSA 模块能对图像中不同特征子空间进行建模,并在解码阶段融合这些不同的特征表示,从而更好捕捉图像中不同尺度和语义层次的信息,提升分割网络的表达能力和分割精度[29-31]。
以CCAM 为基础构建的MHSA 模块(图6),用其捕捉图像中的长程依赖关系,扩展解码器的感知范围,以解决分割任务中上下文信息不足的问题。MHSA 设计允许信息的非局部传播,从而一定程度上减少网络的参数量和计算量,提高训练和推理速度。因此,选用视觉多头自注意力机制替换LDF 模型中的主体解码网络和细节解码网络部分。考虑到主体解码网络和细节解码网络的结构相同,本研究仅展示改进后的主体解码器网络结构(图6(a))。图6(b)显示每个多头自注意力结构的具体形式,其中输入经过三个CCAM 模块以增强不同子空间的特征表示及模型的表达能力,随后将这些输出沿通道维度进行拼接操作,最终通过一个卷积操作输出。改进后的Mix-LDF网络结构见图7。
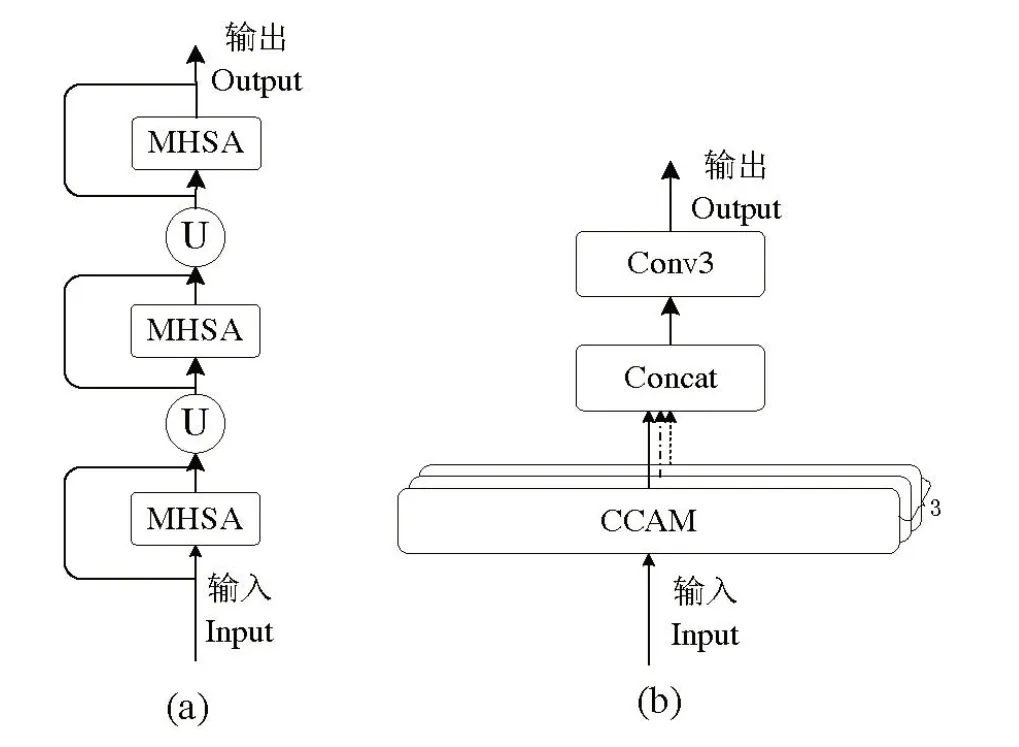
图6 多头自注意力架构Fig.6 Proposed multi-head self-attention architecture
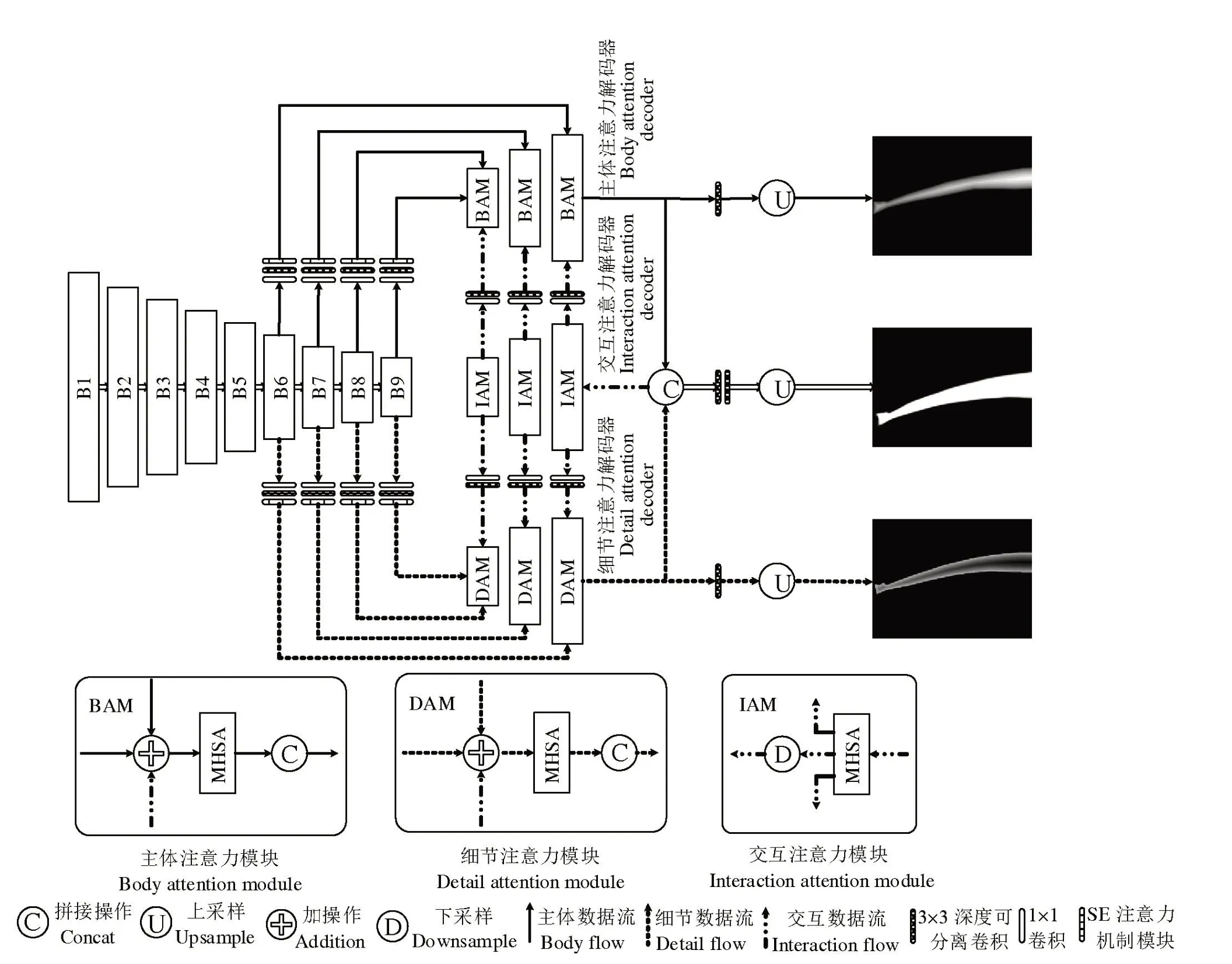
图7 Mix-LDF框架Fig.7 Mix-LDF framework
2.2 饲料颗粒流落点预测方法
采用经2.1 节改进后的Mix-LDF 网络分割饲料颗粒流轨迹图像后。在预测饲料颗粒流落点时,仍需计算轨迹信息以预测最终的落点位置。鉴于BP神经网络[32-33]的多层结构和激活函数能够更好地适应数据的复杂模式和关系,且在处理复杂数据模式和关系时表现更出色,因此,本研究构建一个四层BP 神经网络结构来进行落点预测。其结构包括:4个输入层节点变量、两个隐藏层(分别为16 个节点和8 个节点),以及输出层的2 个节点(用于表示落点的二维坐标点)。
2.2.1 轨迹信息提取 饲料颗粒流轨迹信息是预测落点基础。为解决随机噪声对轨迹信息提取的干扰,本研究采用平均位置法[12]来处理数据,达到在真实信号部分保持稳定的前提下,使随机噪声带来的偏差趋于平衡。平均位置法的具体计算方法如下:
其中,n代表在图像列方向上属于轨迹的像素点数目,yi代表列方向上属于轨迹像素点的列坐标值。比较基于平均位置法的射流轨迹曲线与同一坐标系下的二值图像射流轨迹,显示基于平均位值法的轨迹曲线基本上位于二值图中的射流轨迹中间(图8),且两者基本彼此重叠,从侧面说明该方法的有效性和准确性。
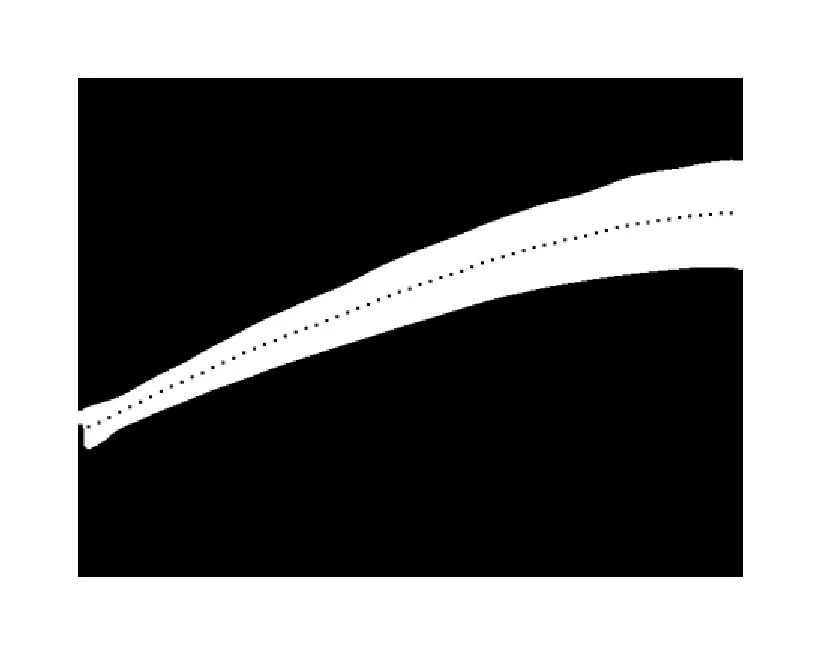
图8 饲料颗粒流轨迹曲线Fig.8 Feed flow trajectory curve
基于平均位值法获得了符合轨迹图像的曲线走势。为了预测饲料颗粒流落点位置,需计算轨迹整体斜率Sot、轨迹初始抛射斜率Sit和轨迹末端斜率Set参数作为落点预测BP 网络输入,Sot、Sit和Set计算公式分别如下:
其中,n代表选取的点数,x0和x1分别代表轨迹中点的起始点和终点,ym和xm分别代表轨迹终点的y轴坐标和x轴坐标,yn和xn分别表示计算过程中所选点y轴坐标和x轴坐标。
此外,投料口高度也是落点预测的重要参数,其通过测量获取,并与Sot、Sit和Set共同作为预测网络的输入参数。经实验,本研究选择n=5。此外,当Sit=0.56 时,计算得到的射流轨迹初始角度为29.24°。其与测量得到的初始角度30°,误差仅为2.5%,表明其可行。
3 实验环境及评价指标
3.1 实验环境
本研究训练模型在服务器中运行,其配置为128 GB 运行内存以及两块i7 CPU,基于Windows Server 2019 操作系统,软件为VsCode,编程语言为Python 3.10,深度学习框架为Pytorch 1.13.0。
3.2 评价指标
为评估Mix-LDF 模型在轨迹分割方面的性能。本研究使用F度量值(F-measure,Fm)、平均绝对误差(Mean absolute error,MAE)以及结构度量值(Structure measure,Sm)来评估该模型在分割饲料颗粒流轨迹方面的准确性及结构相似性。同时,为评估模型的检测速度、计算复杂度以及大小,本研究还使用单位时间图像检测数量(Frames per second,FPS)、浮点数计算量(Floating point operations,FLOPs)以及模型参数量。
另外,为验证饲料颗粒流落点预测的准确性,本研究使用平均误差范围(Average error margin,AEM)、平均绝对百分比误差(Average absolute percentage error,MAPE)及残差图来评估预测准确性。这些评价指标从多个不同方面评估了模型的性能,从而全面展示了MLBP 方法预测饲料颗粒流落点的效果。
4 结果与分析
4.1 饲料颗粒流轨迹分割
为评估改进Mix-LDF 模型在饲料颗粒流轨迹分割的性能,本研究通过消融实验及对比实验进行分析。
4.1.1 消融实验分析 为评估和验证改进Mix-LDF模型中各个组件对性能的贡献。以LDF 模型为基础,在实验中逐步移除或添加不同的组件,并通过不同的组件组合进行4 组实验,分析各个组件对性能的影响。实验结果见表2。
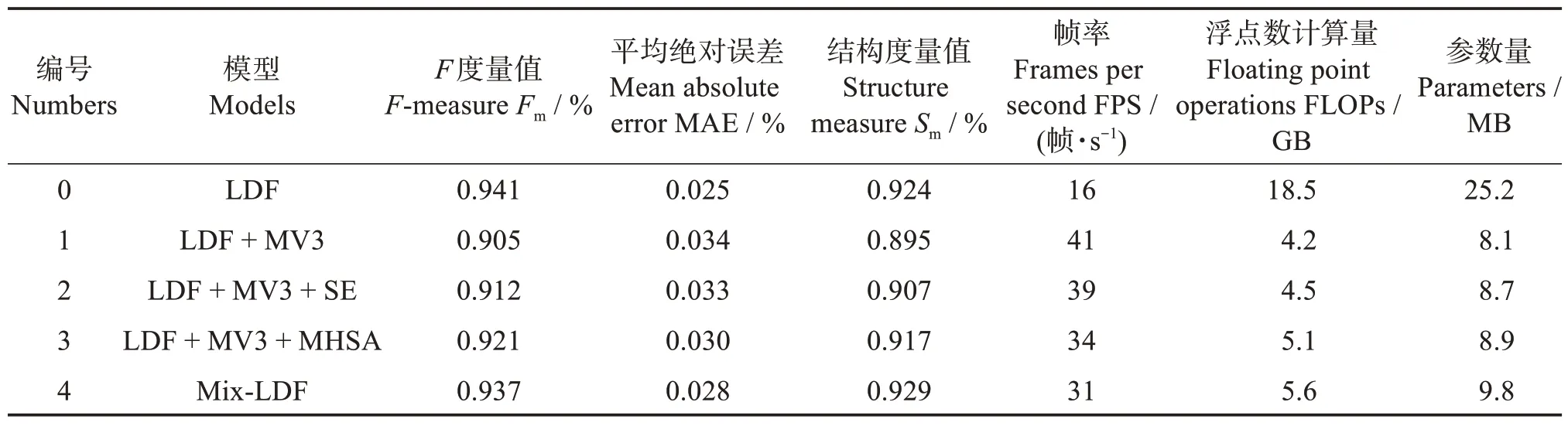
表2 不同算法的性能比较Table 2 Performance comparison of different algorithms
由表2 可知,组1 在LDF 模型引入MV3 网络,使得FLOPs 及参数量分别降低77%、67%,FPS 达到41 帧/s。虽其分割性能略微降低,但模型的复杂度和计算负载都得到有效改善,其参数量和计算量减少对提高算法的效率和工程实践应用具有重要意义。为改善轻量化LDF 模型后分割性能下降的问题,在组1 的基础上分别引入SE 注意力机制及MHSA 模块作为组2 和组3。组2 引入SE 注意力机制模块后,加强了输入细节解码器和主干解码器特征图的表达性和区分度,其Fm和Sm分别提高0.7%和1.3%,MAE 降低2.9%。与组1 相比,组3 引入MHSA 模块,Fm和Sm分别提高1.7%和2.4%,MAE降低11.8%,这证明了将MHSA 作为解码器的混合网络模型能够有效融合不同特征的表示,提升分割网络的表达能力,从而改善分割精度。组4 将所有改进整合在一起,其Fm相较于基础模型LDF 下降0.4%,但具有较高的帧率及较小的参数量,故在满足系统需求的前提下,仍能实现实时运行。综上所述,消融实验结果证明Mix-LDF 网络中各组件的有效性,也验证本实验方案的可行性。
4.1.2 不同模型分割模型的性能对比 为评估及验证Mix-LDF 模型的有效性,将分割性能较好的显著性检测模型EDN[34]、SelfReformer[35]、U2-Net[36]和F3Net[37]进行对比实验。为确保公平,实验均使用相关作者发布的原代码。通过消除数据差异的影响,以准确评估算法性能。实验结果见表3。
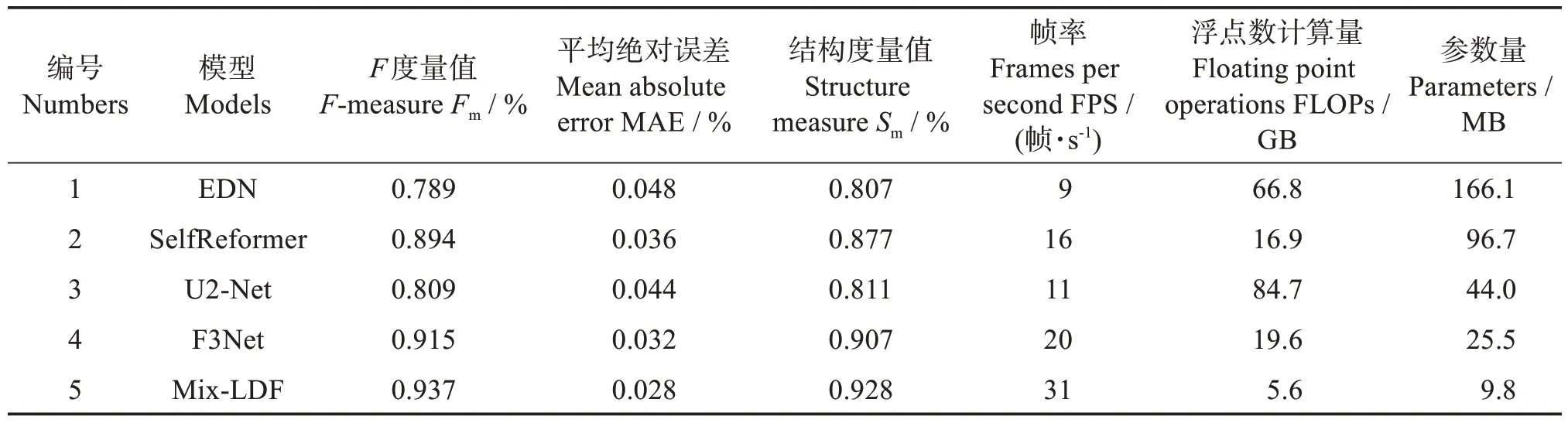
表3 定量分析不同模型Table 3 Quantitative analysis of different models
由表3 可知,Mix-LDF 模型在所有实验组中,Fm和Sm评价指标最高,显示出其在轨迹分割任务中,具有较高的准确性及更好的提取细节信息的能力。通过MAE 指标对比,可观察到Mix-LDF 模型具有最低的MAE 值(0.028),表明其在预测显著性时具有更小的平均误差。同时,Mix-LDF 模型还具有最少的浮点数计算量(5.6)、参数量(9.8)和最大的帧率(31),这意味着Mix-LDF 模型在运行过程中所需的计算资源更少,具有更快的推理速度。故本研究所提改进Mix-LDF 更适合饲料颗粒流轨迹分割。
5 种模型在不同阈值下的准确率和召回率之间的关系,即PR 曲线(图9),这有助于进一步对比算法的鲁棒性和稳定性。可见,Mix-LDF 模型的PR曲线几乎完全包围其他4 个模型的曲线,表明在分割饲料颗粒流轨迹方面,其具有更高的准确性和召回率。通过对PR 曲线的观察和分析,证明Mix-LDF 模型在不同阈值下表现出一定的优势,这对于需要准确检测和分割轨迹的工程实践应用具有重要意义。
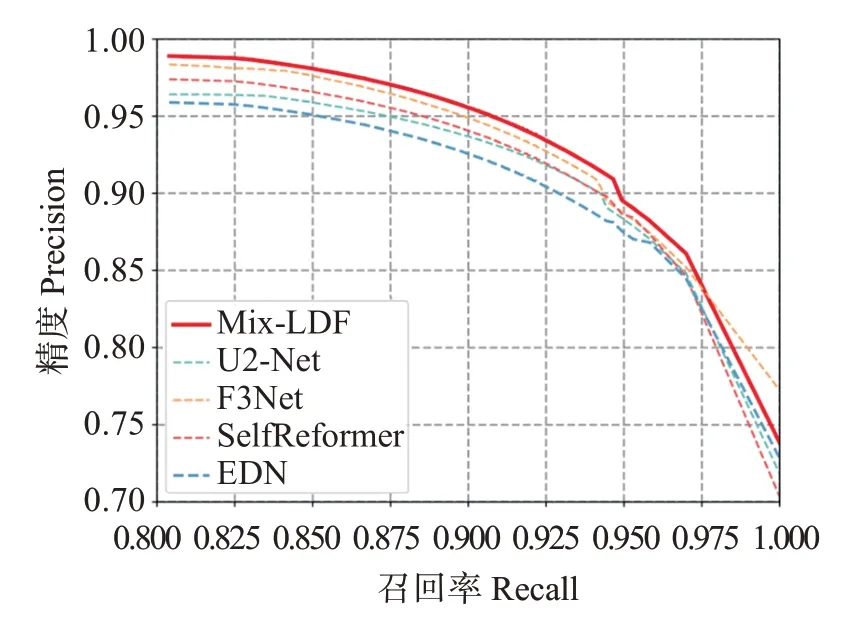
图9 5种方法的精度-召回率曲线Fig.9 Precision-Recall curve plots for five models
不同模型分割饲料颗粒流轨迹的可视化结果见图10,可见,Mix-LDF 模型不仅正确分割饲料颗粒流轨迹,还呈现出更清晰的边界和连贯轨迹。与之相比,EDN、SelfReformer、U2-Net和F3Net模型存在不同程度的边缘模糊和轨迹不连贯等问题,这会导致轨迹参数的准确性受到影响,从而影响饲料颗粒流落点的预测精度。故Mix-LDF 模型在轨迹分割方面表现最佳。

图10 不同模型分割饲料颗粒流轨迹结果Fig.10 Segmented feed flow trajectory results of different models
4.2 不同方法的饲料颗粒流落点对比
为评估MLBP 方法在饲料颗粒流落点预测中的有效性,将其与NFCV方法在预测误差范围、样本数量和平均误差等方面进行对比,实验结果见表4。
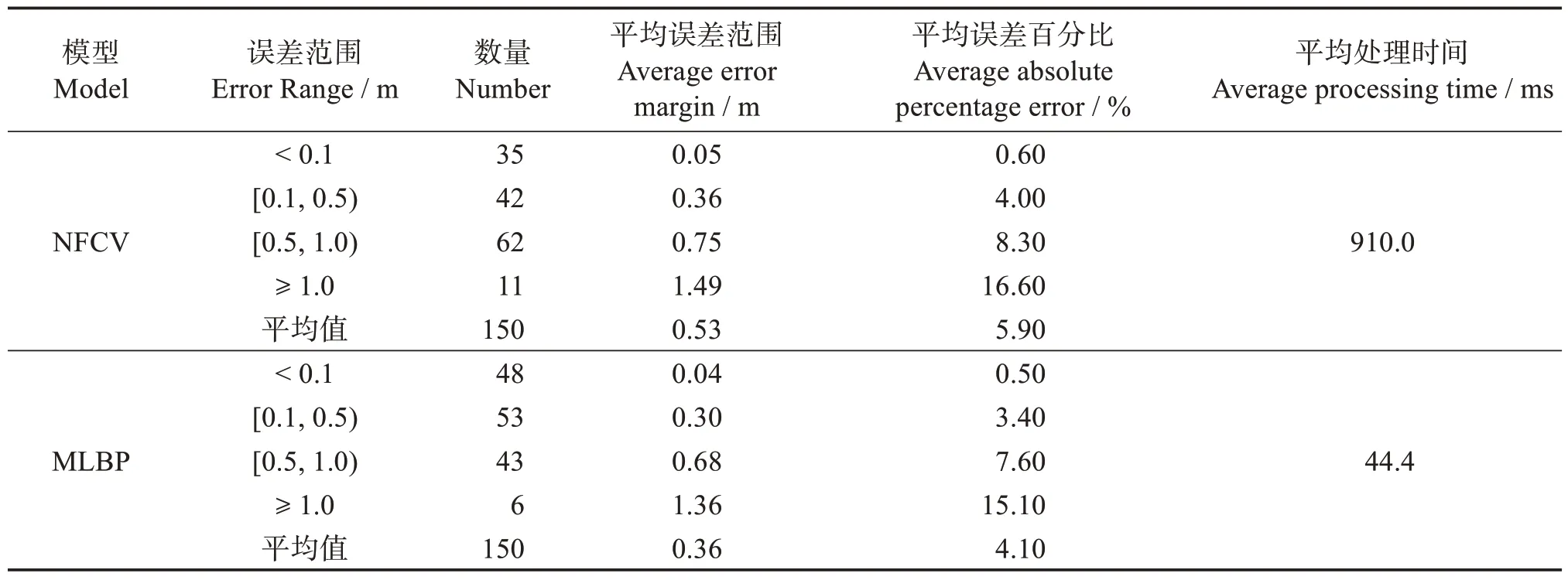
表4 预测饲料颗粒流轨迹着陆点的两种方法比较Table 4 Comparison of two methods for predicting the impact points of jet trajectories
由表4 可知,NFCV 方法误差范围小于0.1 m时,共有35 个样本,平均误差为0.05 m,平均绝对百分比误差为0.6%,平均处理时间为910.0 ms,但误差范围大于0.5 m的样本占比近50%,表明NFCV方法预测落点的不稳定性较高,且无法实时预测。相比之下,MLBP 方法在误差范围小于0.1 m 时,有48个样本,平均误差为0.04 m,平均绝对百分比误差为0.50%,平均处理时间为44.4 ms,此外,误差范围大于0.5 m 的样本数仅为不到33%,表明MLBP 方法相较于NFCV 方法更稳定且具有更高的实时性,更能符合对实时性有要求的系统。故MLBP 方法在所有误差范围内均表现出更低的平均误差和平均绝对百分比误差,显示出其具有较高的稳定性。MLBP 方法平均处理时间仅为44.4 ms,表明其可用于实时的轨迹分析和落点预测。
NFCV 与MLBP 两种方法的残差分布对比(图11)显示,采用MLBP 方法的残差主要集中在± 0.3 之间,而NFCV 的残差则主要集中在± 0.5 范围内,这表明采用MLBP 方法在残差方面更加稳定,且残差的整体离散程度较小,相对接近真实值。相比之下,NFCV 方法残差整体离散程度较大,相对较远离真实值。综上所述,MLBP 方法在误差控制方面表现出更好的效果,其残差更为集中且离散程度较小,与真实值更为接近。这些结果进一步验证MLBP方法在本研究中的有效性。
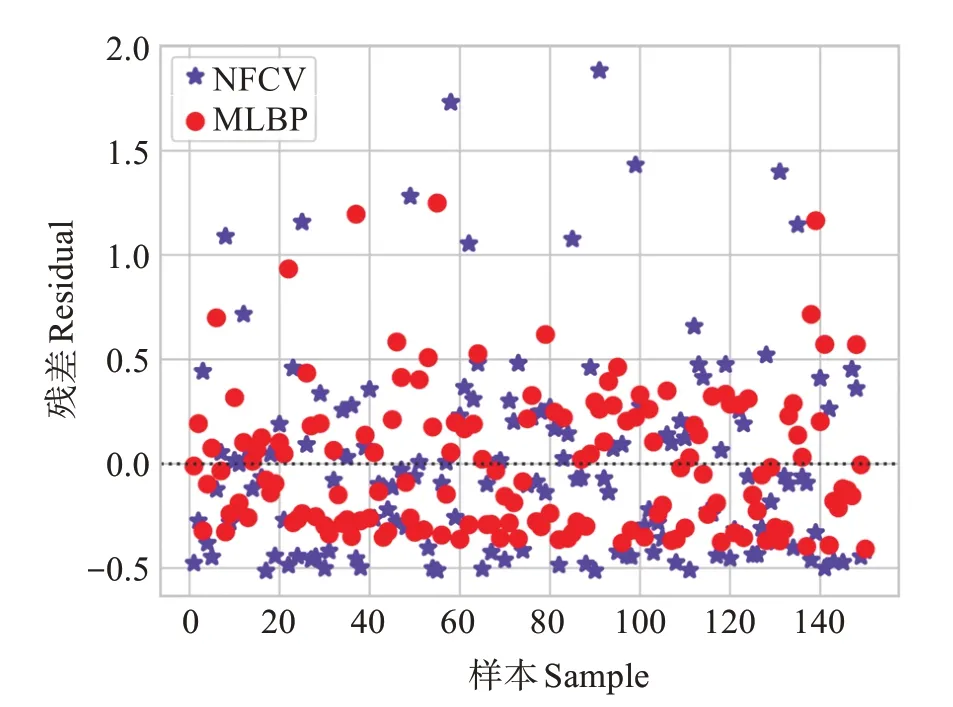
图11 残差分布Fig.11 Residual Plot
5 结论
饲料颗粒流落点的反馈是实现饲料投喂系统的精准自主控制的作为控制决策的关键,本研究提出一种MLBP 方法。该方法通过相机捕获饲料颗粒流轨迹,并利用本研究改进的Mix-LDF 网络模型对饲料颗粒流轨迹进行分割。通过深入分析并计算了影响落点的相关参数,作为落点预测模型BP神经网络的输入,从而实现对饲料颗粒流落点位置的精准预测,解决了饲料颗粒流落点难以获取的问题,为饲料颗粒流落点的精准控制提供参考。得到如下结论:
1)本研究基于LDF 模型,采用MobileNetV3 网络的基础组件,实现LDF 模型主干网络的轻量化,使其容易在资源受限的嵌入式设备上进行部署;为缓解改进主干网络带来的分割精度略微下降的问题,针对主干网络的后四个卷积层输出,引入SE 注意力机制模块,以增强特征图的表达能力,从而提高分割精度;为更好地理解全局上下文信息,提高分割精度,采用CCAM 构建一个轻量级的视觉多头自注意力解码器模块,并将其与卷积网络构成的主干网络相结合,形成混合网络模型(Mix-LDF),其融合卷积网络的局部特征提取能力和多头自注意力的全局上下文理解能力,从而提高模型的表现能力,使其能够更好地分割饲料射流轨迹。
2)在成功利用Mix-LDF 模型准确分割饲料颗粒流轨迹后,采用平均位置法计算轨迹曲线,并利用BP 神经网络的优势拟合轨迹曲线并预测落点。将轨迹曲线中的整体斜率Sot、初始抛射斜率Sit、末端斜率Set及投料口高度作为BP 神经网络的输入,用于预测饲料颗粒流的落点,即MLBP 方法。与NFCV 方法相比,MLBP 方法的准确率提高3%,达到96%。同时,残差图也表明MLBP方法更为稳定。
本研究集中关注MLBP 方法的开发和性能评估,主要解决饲料颗粒流落点预测的关键问题,故当前仅在陆地环境进行模拟。未来的研究将重点关注相关干扰因素(如风速、风向)以及在海洋中的海浪等问题,这将有助于提高MLBP 方法的鲁棒性,使其更好地适应多样化的海洋环境。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
空间科学学报(2021年6期)2021-03-09
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
红领巾·萌芽(2019年8期)2019-08-27
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
太空探索(2016年12期)2016-07-18
新闻传播(2016年4期)2016-07-18
