
智能辅听系统对改善人工耳蜗植入者听声效果的研究△
2024-01-29 08:30项丽阳李娟娟韩彦王金剑杨典杨婷君银力黄穗
听力学及言语疾病杂志 2024年1期
项丽阳 李娟娟 韩彦 王金剑 杨典 杨婷君 银力 黄穗
当前主流的多通道人工耳蜗产品均能让大部分植入者在安静环境下听清和交流,但在噪声或混响环境中,植入者的言语识别能力下降,因此提高植入者在噪声环境下的言语可懂度依旧是人工耳蜗研究领域的一大挑战。一个重要解决方式是引入或改进声音信号处理技术,尤其是音频降噪算法。然而,单一的声音处理策略难以应对现实复杂的使用环境,较为理想的做法是针对不同的环境噪声特点开启特异性降噪算法。传统的实现方式是让植入者在使用过程中根据所处场景手动选择合适的听声程序,但绝大部分的植入者因为怕麻烦或不够专业而始终使用标准程序[1]。为此,声音场景识别算法被引入到人工耳蜗等辅听设备中[2,3],搭载此算法模块的智能辅听系统能够自动识别所处场景,并开启合适的声音处理策略,从而避免手动切换听声程序,方便植入者自如应对复杂环境。诺尔康智能辅听系统主要分为三大模块(图1):声音场景识别模块、策略配置模块以及语音增强模块。声音场景识别技术从声音信号中识别出所处的场景环境后,由策略配置模块根据场景对语音增强模块的各个算法策略进行统筹配置,选择最适合当前场景的处理策略。语音增强模块中包含诸多声音处理策略,供策略配置模块调用,通过对声音数字信号进行算法处理,提升语音的舒适度、清晰度和可懂度。其中搭载了自动增益控制、单麦降噪技术“EVoice”、双麦降噪技术“ABeam”以及增强音调感知的“CTone”策略等。EVoice降噪技术基于单通道信噪比估算联合使用改进的维纳滤波法进行降噪,在相对较低的信噪比下且背景噪声较稳定时具有明显的降噪效果,能够使语谱噪声下的言语接受阈(speech reception threshold,SRT)降低2.2 dB[4]。CTone策略通过加强与基频(F0)变化相关的时域振幅包络而增强植入者对音调的感知,能够在安静环境下改善植入者对声调、单音节以及双音节的识别准确度,提高汉语的可懂度[5]。ABeam是一种基于延时相加、差分麦克风阵列以及维纳滤波的自适应双麦降噪技术,可动态追踪信号源和噪声源的来源方向,自适应控制算法参数, 整体算法复杂度适中,降噪效果较好。本文将介绍ABeam策略的临床实验方案及结果。
1 资料与方法
1.1声音场景识别模块构建
1.1.1模型数据库构建 声音场景识别支持5个分类:语音、噪声、带噪语音、音乐和安静。其中安静的识别是通过检测输入声音的能量是否超过阈值来实现,而其余四类则是通过场景识别分类器进行判别。用于声音场景识别模型训练的音频样本主要来源于网络公开的声音样本库下载和实地场景采集,将搜集到的声音样本进行人工分类和筛选。带噪语音样本来源于实地采集和后期合成。将音频统一预处理成单声道16 kHz采样率的wav格式,并按照1 s时长进行裁切,之后设置合适的阈值线删去声压级较低的样本。最终获得的数据库样本包括59 138 s的语音、71 395 s的噪声、39 607 s的音乐以及59 387 s的带噪语音。为使类别平衡,随机选取每个类别39 000个样本(10.8 h)用于模型构建,其余样本部分用于后续的实时声音场景识别性能评估。
1.1.2声音场景识别模型构建
1.1.2.1特征筛选 前期实验通过递归特征消除(recursive feature elimination)、随机森林(random forest,RF)和极限树(extra-trees,ET)等特征选择法,依据重要度排序,从大量音频特征中筛选出了16个对场景识别较为重要的特征,包括基于频域的6个特征和基于倒谱域的10个梅尔倒谱系数(mel-frequency cepstral coefficients,MFCC)。频域的6个特征包括3个带通能量率(band energy ratio)相关的特征[直流分量比值、低频(0~1 000 Hz)能量比值以及高频(4 500~7 750 Hz)能量比值]、谱熵(spectral entropy)、谱通量(spectral flux)以及谱互相关系数(spectral cross-correlation coefficient)。
1.1.2.2分类模型筛选 在上述大数据集中每个分类随机选取3 000个样本构建一个较小的数据集,其中,80%作为训练集,20%作为测试集。对每个样本提取上述16个特征值构建特征值库。之后,构建和训练不同的模型学习特征值输入到场景输出的映射。这些机器学习模型包括支持向量机(support vector machine,SVM)、随机森林(random forest,RF)、极限树(extra-trees,ET)、全连接神经网络(fully-connected neural network,FC)、长短时记忆网络(long short term memory networks,LSTM)、门控循环网络(gated recurrent unit,GRU)以及卷积神经网络(convolutional neural networks,CNN)。训练每种模型时,调节模型的参数设置,使得模型在测试集上的预测准确度尽可能高。
1.1.2.3场景识别模型构建与性能评估 确定模型架构后,在前述较大的数据集上进行模型训练和性能评估。通过10次五折交叉验证的方法,将数据集分成5份,轮流用其中4份做训练集剩余1份做测试集,记录训练好的模型在测试集上的识别结果,上述过程重复10次,以50个预测结果的均值来评估模型的预测性能。
1.1.3声音场景识别综合决策模块 在模型预测后加入一个场景综合决策模块,该模块基于动态累积投票积分,综合考虑历史场景识别结果,只有在系统稳定识别为某个场景的情况下才会发生场景切换,如此便可以尽量保证场景切换的稳定性,防止声音处理策略频繁更换给植入者带来不良的听声体验。
1.1.4实时声音场景预测性能测试 将上述包括综合决策模块在内的整个声音场景识别系统在人工耳蜗数字信号处理器(DSP)上实现,通过蓝牙传输方式,将预测结果显示在手机应用程序界面。随机挑选一些不在模型训练库中的测试声音样本,拼接成5 min的测试文件,每个测试文件中的样本来源于同一类声音场景。音乐测试文件包括纯音乐和带人声音乐两类。测试文件数分别为语音9个,噪声8个,带噪语音8个,纯音乐7个,带人声音乐6个。用扬声器(Edifier R1600TIII)播放测试文件,人工耳蜗麦克风距离扬声器0.5 m,播放白噪声,调节扬声器音量使人工耳蜗麦克风处的声压级达到75 dB SPL。测试过程中人工记录app界面每次场景变化时的音频播放时间以及预测结果。
1.2策略配置模块 声音处理策略配置模块根据场景识别结果,自动配置合适的策略,改善植入者在各场景下的听声体验。诺尔康的策略配置模块见图1,横向箭头指代特定场景下开启哪种策略,例如:安静场景下开启自动增益,噪声场景下开启单/双麦降噪算法。
1.3语音增强模块
1.3.1研究对象 为评估语音增强模块中的ABeam技术的降噪效果,招募13例人工耳蜗植入者(6男7女),年龄18~50岁(中位年龄46岁)。所有受试者均为成年语后聋植入者,母语均为汉语,单耳植入诺尔康人工耳蜗(植入体为CS-10A),测试时植入者的体外机换为三代机声音处理器Voyager,并将其调试图下载到处理器中声音编码策略为高级峰值选择(advanced peak selection,APS),对应下文所述的“OFF”程序。受试者均可在安静环境下进行有效交流,并在测试前签订知情同意书。
1.3.2临床实验流程 实验过程中首先评估植入者在相对安静情况下对开启“ABeam”的主观听声反馈。植入者被邀请至一间较为安静(本底噪低于40 dB A)的房间进行面对面的交流,先测试“ON”后测试“OFF”程序,每个程序试听时长为0.5~1 h,询问并记录受试者的主观听声感受反馈。之后在环形声场中进行噪声环境下的言语识别率(speech recognition score,SRS)测试,测试的两个程序分别为ABeam开启“ON”和关闭“OFF”。“ON”时Abeam策略作为一个预处理步骤整合到APS策略中(通道峰值选择之前)。测试的噪声源角度包括90°、180°和270°三个角度,噪声类别为语谱噪声(speech shaped noise,SSN),目标语音来自中文言语评估测试短句(Mandarin speech perception test-sentences,MSP)[6],包含10个句表,每个句表包含10个短句,每句有7个字。实验测试条件为组合3个播放角度、2个程序共计6种,为每位受试者无重复伪随机选择其中6个句表的目标语音对应6种实验条件(受试者、测试语句的组别选择与测试条件的对应均做了一定的平衡考虑,尽可能做到各个情况出现的概率均等)。
1.3.3环形声场及控制平台 实验在隔声室(本底噪声低于30 dB A)进行,内置环形声场,12个扬声器以30°的角度等间隔环形排列,半径为1 m,每个扬声器距离地面高度为1 m(图2)。使用基于Matlab软件开发的声场控制实验平台的控制扬声器播放。实验前在扬声器阵列的圆心位置放置一个全向麦克风接收声音输入用于反馈调整扬声器的输出声压级,用于自动校准扬声器,实验时移走。
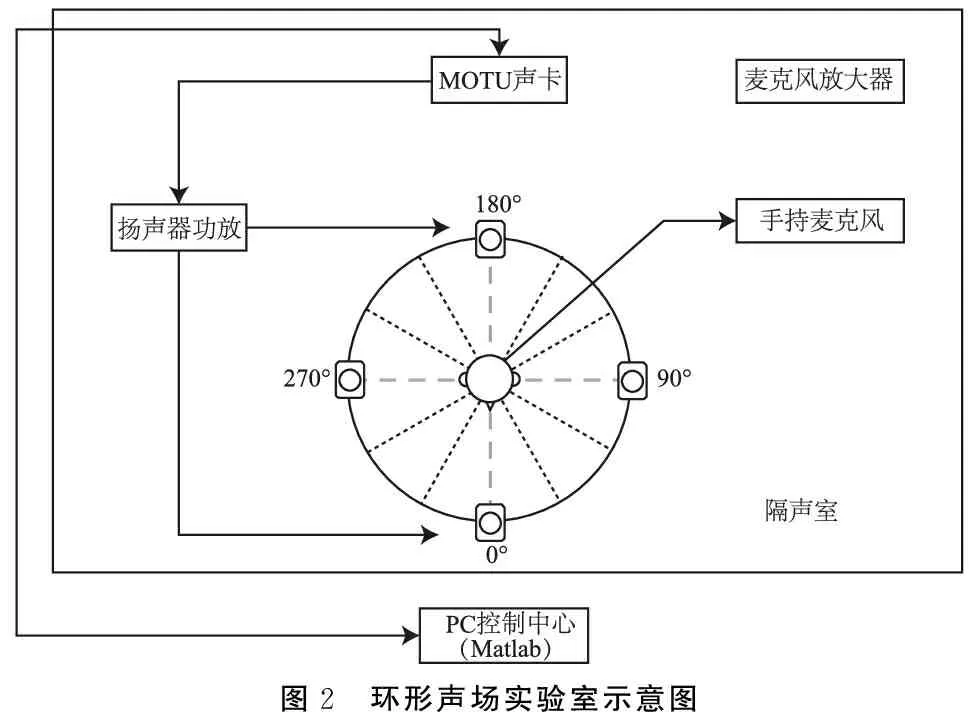
图2 环形声场实验室示意图
1.4测试指标
1.4.1场景识别系统的预测性能
1.4.1.1不同种类模型在较小数据集测试集上的预测准确率 将训练优化好的各模型在小数据集测试集上的预测结果与相应的人工标注结果进行比较,如果两者相符,记为识别正确,计算每个模型预测正确的概率,即正确预测总数占整体测试样本数的百分比。
1.4.1.2全连接神经网络模型在较大数据集测试集上的预测准确率 每次训练完毕,将在大数据集上训练好的神经网络模型预测结果与人工标注结果进行比较,如果两者相符,记为识别正确,计算模型在整个测试集上预测正确的概率,即正确预测总数占整体测试样本数的百分比作为该次模型的整体预测准确率。类似的,对于每个分类而言,统计每类真实标签的样本中被正确识别的总数占该类样本总数的百分比作为模型对该类模型的预测准确率。之后,计算10次五折交叉验证结果的整体预测准确率以及各分类的预测准确率。
1.4.1.3DSP实时场景识别准确率 对于每个测试文件,根据手动记录的手机app界面显示的场景切换时刻以及场景预测结果,分析每个预测分类的显示时间占比,以正确分类的时间占比作为场景识别系统对该文件的识别准确率。之后,计算系统对每个分类下各个测试文件的识别准确率。
1.4.1.4DSP实时场景识别切换次数 对于每个测试文件,根据手动记录的app界面显示的场景切换时刻以及场景预测结果,获得场景切换次数的结果。之后,计算系统对每个分类下各个测试文件的识别结果的切换次数。
1.4.2ABeam主观听声效果VAS评估 使用视觉模拟评分法(visual analogue scale,VAS)量化受试者各个维度的主观听声感受(表1),分别给两个程序的使用感受进行评分。主观评价指标主要包括背景噪声、语音清晰度、听声舒适度、语音失真情况以及听声响度。

表1 听声效果VAS评估
1.4.3ABeam言语识别率评估 固定目标语音的播放角度为0°(受试者正对面方向),声压级为70 dB SPL;噪声播放声压级由声场控制实验平台程序自动根据设定的信噪比决定,本实验中设定信噪比为5 dB。每组语料中的一句话播放结束时,要求受试者复述所听内容,通过麦克风传达给隔声室外的测试者,由测试者操作程序界面选择受试者正确复述出的字词,之后进入该组下一句的播放,一组10句话测试完毕,程序自动统计受试者对整组语料的言语识别率。
1.5统计学方法 采用Matlab 2016a软件对数据进行统计分析。组间比较采用配对t检验,检验水平α=0.05。P<0.05为差异有统计学意义。
2 结果
2.1模型筛选实验结果 在小数据集上的模型筛选实验结果表明在特征输入保持一致的情况下,使用若干机器学习模型所能达到的预测准确度差异不大(表2)。从计算量、模型性能以及在DSP上的实现容易度等多方面综合考虑,选择使用人工神经网络模型。通过调整模型架构(包括网络层数和每层的节点数量),发现双隐含层(每个隐含层包括10个神经元节点)的神经网络模型(图3)已经能获得预期性能(在此小数据集上达到95%以上的预测准确率)。

表2 不同种类模型的场景识别预测性能评估
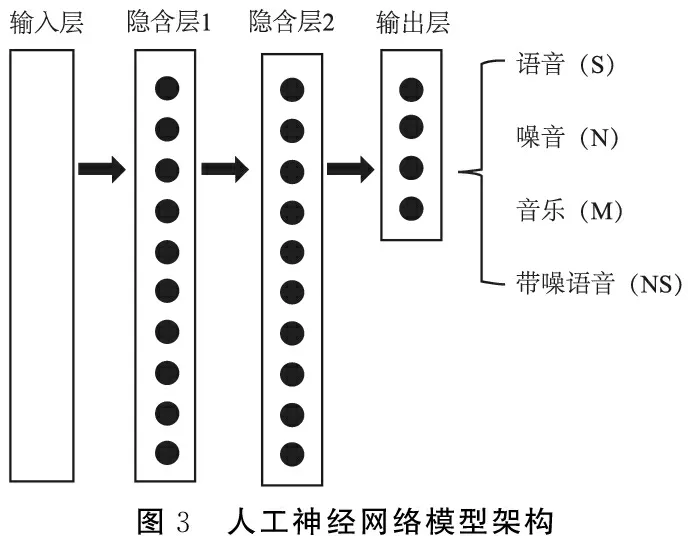
图3 人工神经网络模型架构
2.2场景识别系统模型性能评估结果
2.2.1模型在测试集上的预测性能 通过10次五折交叉验证的方法统计模型在较大数据集上的预测性能,整体识别准确率为(90±0.5)%,其中语音98%±0.3%,噪声92%±0.8%,音乐81%±1%,带噪语音88%±2%。
2.2.2DSP实时场景预测性能 实时场景预测系统对各个测试文件的识别准确率以及场景切换次数统计结果见表3。可见,本系统对每个分类的识别准确度均可达90%以上,在5 min的测试过程中平均场景切换次数少于两次。

表3 声音场景识别系统对各个测试文件在人工耳蜗上的实时预测性能
2.3ABeam临床测试结果
2.3.1听声效果VAS评估结果 13例受试者中有2例主观反馈结果(VAS评估结果)遗失(言语识别率结果并未遗失),表4统计了剩余11例的听声效果VAS评估结果,可见,是否开启ABeam对背景噪声强度、语音清晰度、听声舒适度以及听声响度有显著影响(P<0.05),而对语音失真并无显著影响(P>0.05)。

表4 不同程序下听声效果VAS统计结果(分,
2.3.2言语识别率统计结果 各噪声源角度下,13例受试者在开启(“ON”)和关闭(“OFF”)ABeam算法时的SRS统计结果见表5。可见,在5 dB信噪比下,开启ABeam算法受试者的SRS结果与不开启有极显著差异(t=4.23,μ=38,P<0.001)。当噪声源位于180°时,开启ABeam算法能显著提升SRS(t=3.80,μ=12,P<0.01);而其它角度下,尽管是否开启ABeam算法对SRS结果无显著影响(P>0.05),但从均值上可以看出开启后受试者SRS有上升趋势。综合三个噪声源角度的测试结果,开启ABeam后SRS平均可提升15.92%。
表5 不同程序下不同噪声源角度言语识别率统计结果
3 讨论
本文重点介绍了诺尔康人工耳蜗智能辅听系统的声音场景识别模块以及双麦降噪算法ABeam的临床测试结果。前者在各个测试场景下的识别准确度均可达到较高水平,且识别较为稳定。但当前支持的场景数量较少,仅有语言、噪声、带噪语音、音乐和安静5种,分类不够细致,尤其是噪声类别,这会限制声音处理策略的优化配置,未来将增设常见的特定噪声种类的识别,如风噪、车噪等。其他产品当前所支持的场景识别数量都与本研究所用的诺尔康产品相差不大,如Cochlear人工耳蜗的Smart Sound iQ技术支持6种场景识别[3],Med-EL人工耳蜗支持5个场景,Advanced Bionics人工耳蜗支持场景数稍多,为7个。因此,人工耳蜗上搭载的场景识别技术普遍还有较大的改进空间。然而,人工耳蜗设备的实时性和低功耗要求在一定程度上限制了较复杂的场景识别算法的应用,如何在较低的算力资源下改进声音场景识别的预测性能成为这一研究领域的挑战。此外,不止场景识别模块,其他各声音处理策略的开发也都需要兼顾算力和算法性能。
当前的策略配置模块采用固定的场景-策略搭配模式,这种搭配方式,尽管开发者认为较为优化,但其实并未顾及到每个人的听声需求,更为合理的一种做法是获取植入者的使用习惯和偏好,并对策略配置进行个体化的调控,这也是未来智能辅听系统的一个发展方向。
在噪声源和信号源空间分离的情况下,相较使用单麦降噪算法,基于双麦克风输入信号的方向性麦克风技术能更加有效地提高输出信号的信噪比,显著提升植入者的听声感受[7,8]。本文对ABeam策略的临床使用性能做了一个初步探索,结果表明开启ABeam(“ON”)较不开启(“OFF”)能够有效改善受试者的主观听声效果,且能在一定程度上抑制来自侧后方的背景噪声,提升植入者的语音可懂度。但本研究受试者数量及实验条件组合较少,未来将增设更多情况下的测试,如改变信噪比、噪声种类、噪声源方向、噪声源数量、室内存在回声和使用移动噪声源方式(噪声源位置在测试中随时间发生变化)等,还将增加受试植入者数量及加入儿童人工耳蜗植入者,对ABeam算法在更多情况下的表现性能做评估。
本文仅对整个智能辅听系统的性能进行了初步研究,选用的研究方法是从各个子模块各自的实现性能上来间接反应整个系统的实现性能;更直接的方式是招募更多植入者,设计安静和不同噪声环境的测试情景,以植入者自身作为对照,对比使用智能辅听系统和各自平时所用的标准程序这两种情况下的听声效果。
人工耳蜗从最初的单电极刺激方式发展到如今的多通道刺激,植入者的听声效果在不断改善,而与此同时,植入者对产品的期待也越来越高,希望能获得与正常听力者相近甚至赶超的听声效果。智能辅听系统的出现和应用是人工耳蜗发展与成熟的必经之路,如何在有限的计算资源前提下提高可识别场景的种类以及识别准确度,并根据声音场景特点开发和配置合适的声音处理策略是该领域的研究重点和难点。
猜你喜欢
中国心血管杂志(2022年2期)2022-11-25
中国心血管杂志(2022年4期)2022-11-25
中国听力语言康复科学杂志(2021年6期)2021-12-21
中国心血管杂志(2021年6期)2021-01-02
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
中国心血管杂志(2019年3期)2019-01-04
小说界(2018年5期)2018-11-26
海南医学(2016年8期)2016-06-08
