
深圳市宝安区土地利用遥感分类方法对比分析
2024-01-29 14:42刘宇承罗芳杜清运黄文丽石仪玮
地理信息世界 2023年4期
刘宇承,罗芳,杜清运,黄文丽,石仪玮
1. 自然资源部城市国土资源监测与仿真重点实验室,深圳 518034;
2. 深圳市规划和自然资源调查测绘中心,深圳 518034;
3. 武汉大学 资源与环境科学学院,武汉 430079
1 引 言
明确土地利用类型是城市进行土地生产利用与规划管理的前提,有利于城市进行合理的土地配置,维护生态环境与自然资源,促进经济发展,保障人民健康生活(张增祥等,2016)。遥感技术是获取空间地理信息的重要方式,海量的高分辨率和多时相遥感数据,为土地利用监管提供了充足的信息来源。
遥感影像解译是遥感应用的基础任务。早期解译主要依靠人工目视和基于统计聚类思想的计算机辅助分类;其后,发展出了基于超平面分割思想的支持向量机(support vector machine,SVM)、基于树状结构的决策树、基于集成多分类器思想的随机森林(random forest,RF),以及从高分辨率获取更多几何与纹理特征的面向对象分类方法;目前,主流的遥感影像解译方法以深度学习模型为代表(张继贤等,2021)。总体而言,解译单元经历了像素、对象和场景等语义单元的发展阶段,解译方法从人工和简单分类器逐渐发展成基于集成学习和深度神经网络的方法(周培诚等,2021)。
围绕土地覆盖/土地利用分类方法,学者们展开了许多研究。季顺平等(2020)利用全空洞卷积神经网络,基于高分辨率影像对武汉市进行了城市土地覆盖类型分类。王协等(2020)设计了多尺度特征学习的神经网络,并与全卷积神经网络(fully convolutional network,FCN)和支持向量机的分类结果进行了比较。王俊强等(2021)结合改进的金字塔场景解析网络和全连接条件随机场提升了遥感影像分割精度。任向宇等(2021)研究了多端元混合像素分解与面向对象分类结合的分类方法。许泽宇等(2022)、邵振峰等(2022)分别对DeepLab模型和U-Net 模型两种主流语义分割进行了智能优化改进。徐进勇等(2022)提出了对中国土地资源多尺度遥感智能解译分类体系。
在区域实际生产中,还需考虑不同方法精度、效率与可操作性。当前将第三次全国国土调查(简称国土“三调”)成果和0.2 m 超高分辨率影像用于解译土地利用类型的研究还较少。本文结合这两类数据,参考土地利用分类国家标准,构建面向深圳市土地分类样本库;实验比较了传统机器学习模型和深度学习模型中分类效果最好的模型、比较了在数据量较少或充足的不同情况下适用的分类方法,以及分类单位为像素或对象时分类结果的差异;最终得出在深圳市宝安区大范围实际生产场景中,应用效果较好的土地利用智能分类方法。
2 研究区域与数据源
2.1 研究区概况
广东省深圳市是沿海城市,经济发展迅速,城市化程度高,地处亚热带季风气候区,自然资源类型多样,有着“花园城市”之称。宝安区(113° 90′E,22° 57′ N),位于深圳市西北部沿海地区,土地面积397 km2,占全市的19.9%。宝安区属低山丘陵滨海区,地貌类型多样全年温暖湿润,平均气温为22℃,年降水量为1926 mm。
2.2 实验数据
本文以2019 年深圳市宝安区超高分辨率RGB三通道光学航空遥感影像(0.2 m)、国土“三调”地理信息系统矢量成果为数据源。
首先结合国家标准《土地利用现状分类》(GB/T 21010—2017)和《第三次全国国土调查技术规程》(TD/T 1055—2019)确定分类体系。在国土“三调”数据基础上人工修正部分标签,构建宝安区地表自然资源丰富区域的样本库。每张图片尺寸为1024像素×1024 像素,标签包含林地、建设用地、水域、草地、湿地、耕地、园地及无数据的背景类8 个类别。样本库主要有三部分:①大容量样本a,含训练样本2499 张、验证样本92 张、测试样本894 张;②小容量样本b,在大容量样本a 中选取部分影像,含训练样本44 张、测试样本15 张,用于比较传统机器学习与深度学习模型;③人工选取样本c,含各类别样本数较均衡的12 张,用于测试各模型最终分类效果。样本位置分布与示例,如图1 所示。
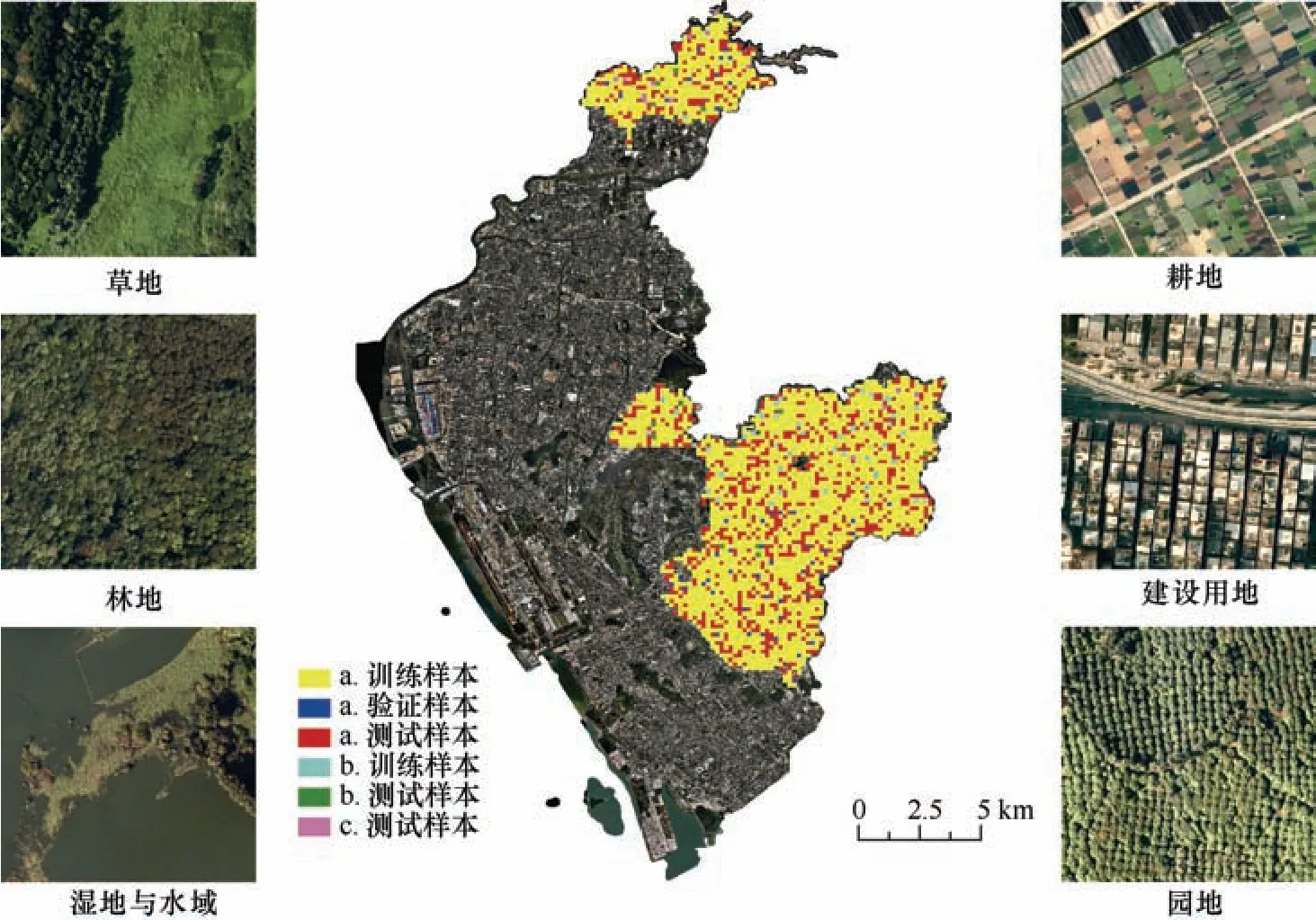
图1 样本分布Fig.1 Overview of the data sample
3 城市土地利用分类方法
3.1 传统机器学习分类
早期遥感影像解译,以像素为最小分类单元。同类地物在不同波段中的光谱亮度、空间纹理结构和其他相关信息,会在特征空间中构成集群。通过选取特征和样本,再训练分类器,可将像素预测为所属的地物类别。随着遥感技术发展,高空间分辨率遥感影像成像波段普遍较少,光谱信息减少的同时,空间细节信息大幅增多。面向对象分类方法以影像分割后的对象为最小分类单元,其提取几何和纹理特征的能力更强。
3.1.1 特征选择
传统机器学习分类器对输入特征有强依赖性。基于像素分类时常用光谱特征,如各波段光谱值、归一化植被指数(normalized difference vegetation index,NDVI)和归一化水体指数(normalized difference water index,NDWI)等,影像纹理特征,即经局部二值模式(local binary pattern,LBP)、Gabor 滤波等方法提取,并通过多项式的方式交互光谱和纹理特征;利用面向对象思想分类时,进一步选择以对象为最小分类单元的特征,如对象位置、与邻域对象关系、长度等形状因子,灰度共生矩阵等纹理特征,使目标地物分类更准确。
3.1.2 分类器
1)K 近邻
K 近邻(k-nearest neighbour,KNN)是Cover和Hart(1967)提出的分类算法。K值选取较为重要,以样本在特征空间中最邻近K个样本类别判断该样本类别。KNN 算法原理成熟且易于理解,模型训练时间快,需要调整的参数少,本文选为基线模型进行参考。
2)支持向量机
支持向量机是Cortes 和Vapnik(1995)提出的经典机器学习模型。其通过在特征空间中建立间隔最大的超平面进行二分类,使用核方法进行非线性分类,并构建多个二分类模型来执行多分类任务。
3)随机森林
Breiman(2001)在决策树算法的基础上,结合Bagging 集成学习与随机子空间方法,提出了随机森林。决策树依照最优分裂特征不断递归迭代,将数据集分为不同特征的部分。随机森林模型则集成多个互不关联决策树,预测时每棵决策树分别判断,最终通过统计所有树的判断投票产生结果。
4)梯度提升决策树
梯度提升决策树(gradient boosting decision tree,GBDT)采用Boosting 集成学习方法,依据错误率来取样,通常比随机森林有更高准确度(Friedman,2001)。本文采用的GBDT 模型,集成决策树类型回归树,在预测分类时,通过累加所有结果,将概率最高的类作为预测结果。
3.2 深度学习分类
在当今大数据和高算力背景下,深度学习相较传统机器学习方法,能从海量数据中学习更多特征,在遥感影像分类任务中有显著优势。其应用于遥感影像分类主要分为对切片的对象识别、基于对象的分类和端对端的语义分割(周培诚等,2021)。
3.2.1 语义分割
语义分割是在像素级别上的分类,如全卷积神经网络将卷积神经网络中全连接层替换为卷积层,实现端到端像素级分类(Long 等,2015)。常用语义分割模型有U-Net(Ronneberger 等,2015)、DeepLab(Chen 等,2018a)、DeepLabV3(Chen 等,2017)和DeepLabV3+模型(Chen 等,2018b)等。
本文选取DeepLabV3+、Resnet50-unet 和U-Net三种深度学习语义分割模型进行测试。在大容量样本集a 上进行测试,损失函数选择焦点损失,其中,超参数γ表示难分类样本的权重。采用总体精度(overall accuracy,OA)和语义分割常用评价指标平均交并比(mean intersection over union,MIoU)进行精度评价,结果如表1 所示。使用焦点损(γ=5)的DeepLabV3+模型在深圳市宝安区样本库中的分类效果最佳(总体精度0.83,平均交并比0.61),因此,本文将其作为深度学习方法的代表。

表1 深度学习语义分割模型分类结果Tab.1 Classification results of deep learning semantic segmentation model
3.2.2 DeepLabV3+模型
DeepLabV3+网络结构,如图2 所示,其整体使用编码器解码器结构。首先,通过编码器卷积和下采样方式,减少特征图尺寸,获取更多低级特征和更高级语义信息;通过解码器融合,提取特征并上采样恢复到输入影像空间维度进行预测。其次,影像输入模型中,通过带有空洞卷积的深度卷积神经网络(deep convolutional neural network,DCNN)分别输出高级特征和低级特征。高级特征在空间金字塔池化后连接,经过1×1 卷积融合后进行4 倍上采样,再与经过1×1 卷积进行降维的低级特征连接。最后,采用3×3 卷积进一步融合特征,4 倍上采样还原成原始空间大小进行语义分割。
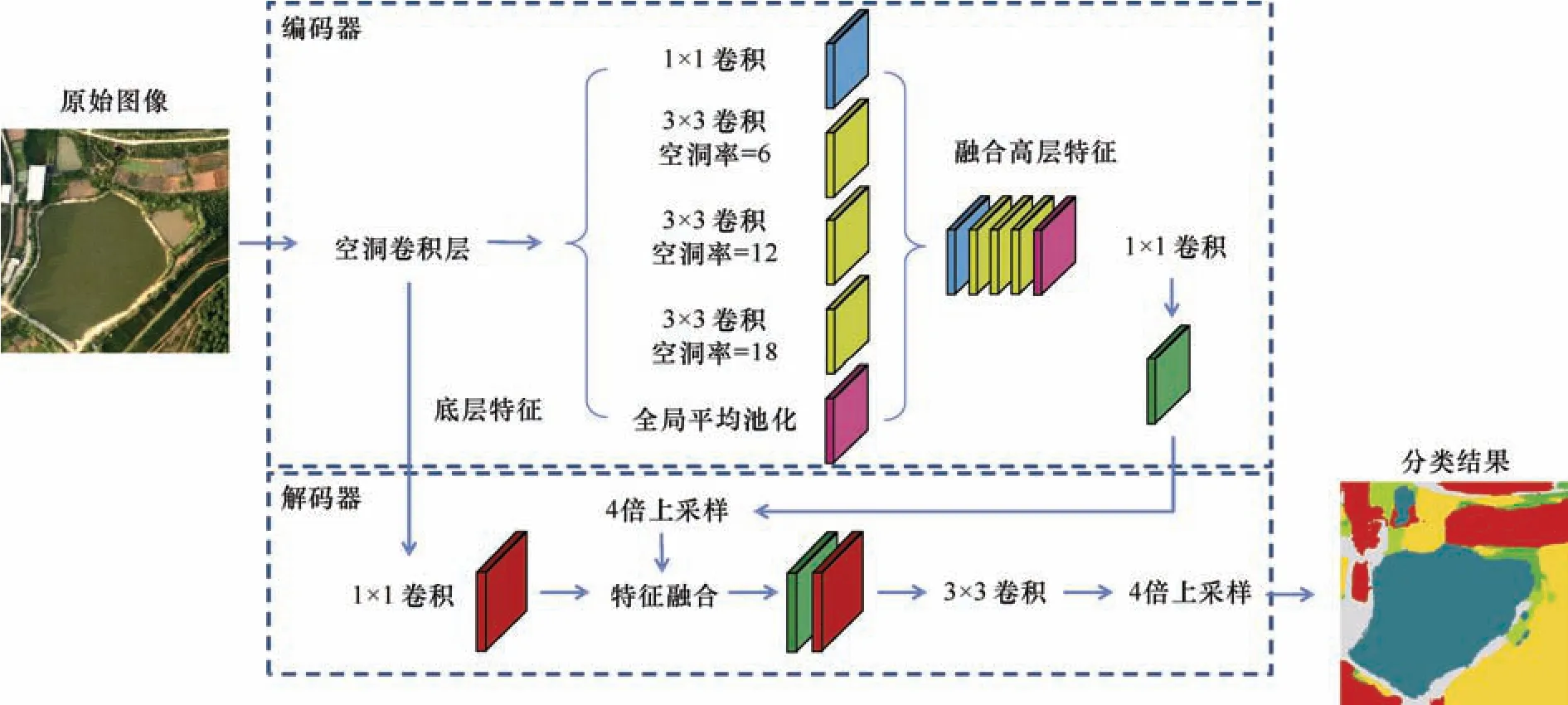
图2 DeepLabV3+网络结构示意Fig.2 Structure of DeepLabV3+
DeepLabV3+ 模型中, DCNN 是改进的Xception。与DeepLabV3 的模型骨干网络ResNet(He 等,2016)相比,改进的Xception 使用了深度可分离卷积,通过逐个通道卷积和逐点卷积方式,减少计算量的同时提升了网格分割效果。
4 实验与分析
基于前述构建的宝安区样本库,本研究设计了三组实验,如表2 所示:①在对大容量样本a 随机抽样的情况下,KNN、SVM、RF 与GBDT 四种传统机器学习模型的比较;②在小容量样本b 下,传统机器学习模型GBDT 和深度学习模型DeepLabV3+的比较;③在大容量样本a 下,传统机器学习模型RF 与深度学习模型DeepLabV3+的比较。三组实验采用OA、Kappa 系数、F1 分数(F1-score)和MIoU进行精度评价。

表2 实验使用的数据集与模型Tab.2 Data sets and models selected for the experiments
基于Scikit Learn与LightGBM库构建传统机器学习模型,在像素分类时选择的特征为RGB 值、LBP、Gabor 滤波提取的纹理特征。
面向对象分类使用eCognition 实现。以尺度参数为100,形状因子为0.3,紧致度因子为0.5 进行多尺度分割,在RF 分类器中输入特征包含RGB 三波段均值、亮度值、对象长宽比、灰度共生矩阵0°、45°、90°和135°方向的均值与对比度、对象密度指数。基于TensorFlow 构建DeepLabV3+模型,损失函数设为焦点损失(γ=5),初始学习率设为0.00005。操作系统为Ubuntu 20.04.3 LTS,GPU 硬件配置为NVIDIA 3090 Ti,通过CUDA 进行加速。
4.1 传统机器学习模型比较
以像素作为最小分类单元进行比较,使用大容量样本a 中的训练样本,对每张1024 像素×1024 像素尺寸的影像随机抽取1000 个点,按6∶4 随机分成训练集与测试集。
由表3 知,RF 模型相较KNN、SVM 与GBDT模型,有更高的OA(0.64)、Kappa 系数(0.49)、F1 分数(0.67)和MIoU(0.37)。由于训练样本林地和建设用地两类数目较多,分类器存在过拟合现象,即倾向将测试样本分成该两类别。SVM 模型的过拟合现象尤为明显,分类结果较低。
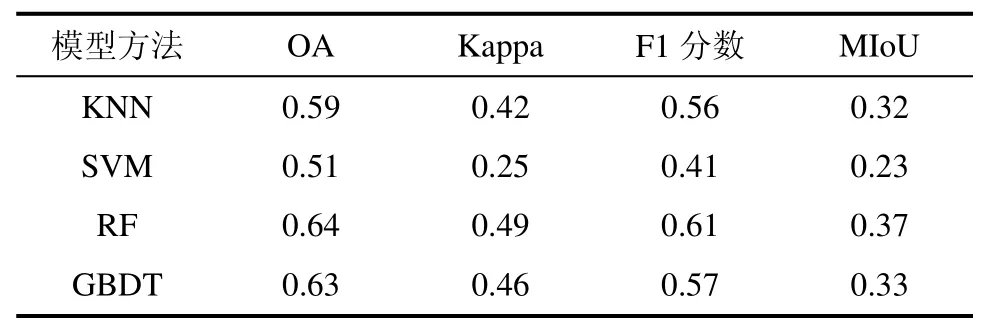
表3 传统机器学习模型的分类结果Tab.3 Classification results of the traditional machine learning model
4.2 少样本的传统机器学习与深度学习模型比较
比较传统机器学习与深度学习模型时,以相同训练集作为前提。深度学习模型训练需以整张影像方式进行输入,单张影像尺寸较大。传统机器学习模型,过大数据量会导致模型难拟合。经测试得到,满足模型拟合且训练数据量最多的传统机器学习模型为GBDT。在小容量样本b 下,本文选择对GBDT 模型与DeepLabV3+模型进行比较。
由表4 知,DeepLabV3+模型的OA(0.68)、Kappa 系数(0.55)、F1 分数(0.62)和MIoU(0.34)均优于GBDT 模型;但由于训练样本量不足,难以发挥出深度学习复杂的模型的优势,其解译结果存在意义不明的问题,如图3(Ⅰ)、(Ⅲ)所示,有大面积的错误。GBDT 模型的优势在于训练对硬件条件的要求低,所需人工标注数据也较少,且训练和预测时间耗时均较短;同时,解译结果边界清晰,可解释性强,但“椒盐噪声”问题严重,如图3 所示。
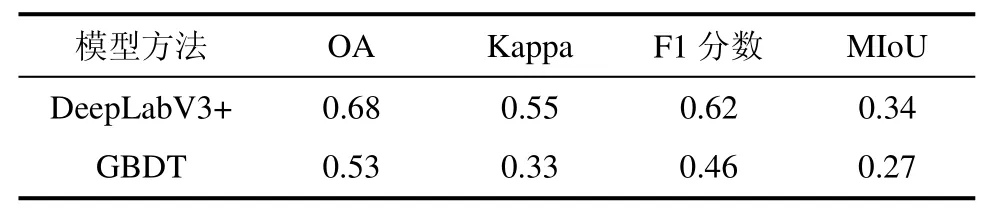
表4 GBDT 与DeepLabV3+模型的分类结果Tab.4 Classification results of GBDT and DeepLabV3+
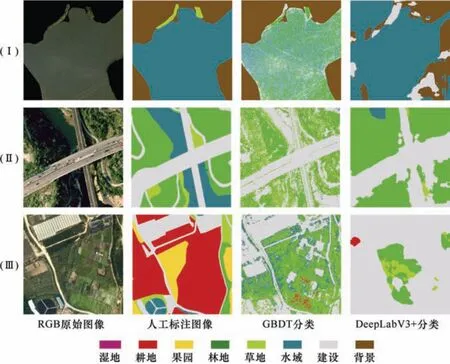
图3 GBDT 与DeepLabV3+分类结果示例Fig.3 Classification samples of GBDT and DeepLabV3+
4.3 充足样本的传统机器学习与深度学习模型比较
深度学习相较于传统机器学习方法,能从更多数据中学习特征,在大容量样本a 上训练后,能充分发挥出DeepLabV3+模型的优势。作为比对,选择随机森林作为基于像素分类的传统机器学习分类器。此外,面向对象分类在高分辨率影像应用中能获取更多的空间细节特征,也作为一种分类方式进行比较,在多尺度分割的影像上,对中心区域周围八邻域1024 像素×1024 像素的影像进行对象级的标注后,也输入随机森林分类器中。
在各类别像素数目较为均衡的测试集(c.测试样本)上的分类结果,如表5 所示,DeepLabV3+分类方法有最高的OA(0.86)、Kappa 系数(0.83)、F1 分数(0.85)和MIoU(0.63),如图4 所示,除湿地外,各类别准确度都较高。随机森林(基于像素)分类精度最低,其主要原因包括:分类任务相对复杂,超高分影像空间分辨率高(0.2 m)但光谱分辨率低;宝安区样本库中仍存在类别不均衡现象,导致RF(基于像素)模型出现过拟合。另外,RF(面向对象)的方法以影像分割后对象为最小分类单元,获取了高分辨率影像中较多空间特征,其分类结果优于RF(基于像素)的分类方法。
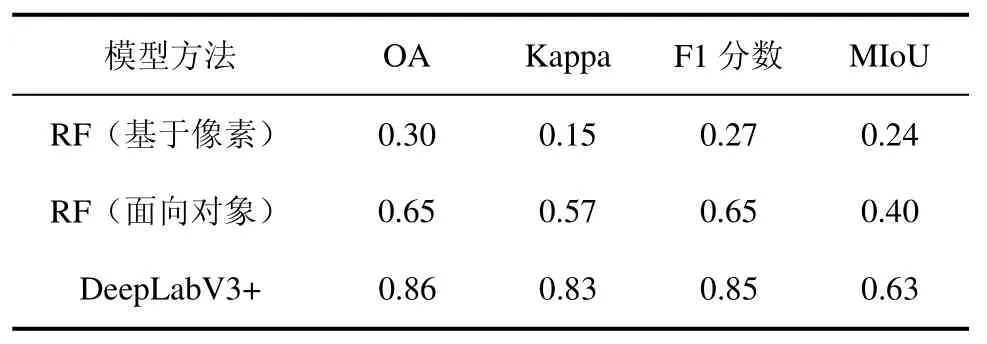
表5 RF(基于像素)、RF(面向对象)与DeepLabV3+模型的分类结果Tab.5 Classification results of RF (pixel-based), RF(object-oriented) and DeepLabV3+

图4 RF(基于像素)、RF(面向对象)与DeepLabV3+模型的混淆矩阵Fig.4 Confusion matrices of RF (pixel-based), RF (object-oriented), and DeepLabV3+
局部解译结果示例,如图5 所示。RF(基于像素)分类方法解译结果错误最多,预测多为水域、林地和建设用地,难以细分出其他类别,且“椒盐噪声”问题严重。RF(面向对象)分类方法基本解决了“椒盐噪声”问题,解译结果整体性较强,但存在特征相近的类别难以区分的问题,如园地类型预测为林地和草地(图5(Ⅱ)),以及耕地与湿地类别解译错误较多(图5(Ⅲ)~(Ⅴ))。DeepLabV3+分类方法的结果整体准确较好,解译结果与真实标签基本相同,轮廓清晰,内部较为完整,如图5(Ⅰ)、(Ⅱ)、(Ⅳ)、(Ⅴ)所示。

图5 RF(基于像素)、RF(面向对象)与DeepLabV3+分类结果示例Fig.5 Classification samples of RF (pixel-based), RF (object-oriented), and DeepLabV3+
最后,本文以DeepLabV3+模型作为土地利用遥感分类方法,应用在宝安区整体区域得到宝安区土地利用分类图,如图6 所示。结果表明,深圳市宝安区的北部与东部林地、草地、水域、耕地与园地等自然资源较为丰富,西部沿海建设用地面积广且集中,城市化水平较高,符合国土“三调”情况。对比分析结果表明,对于超高分辨率遥感影像多类别土地利用分类,在具备深度学习模型训练环境和充足数据量情况下,DeepLabV3+模型分类精度远高于传统机器学习模型,解译结果与实际情况相近,且能应用于大范围区域。
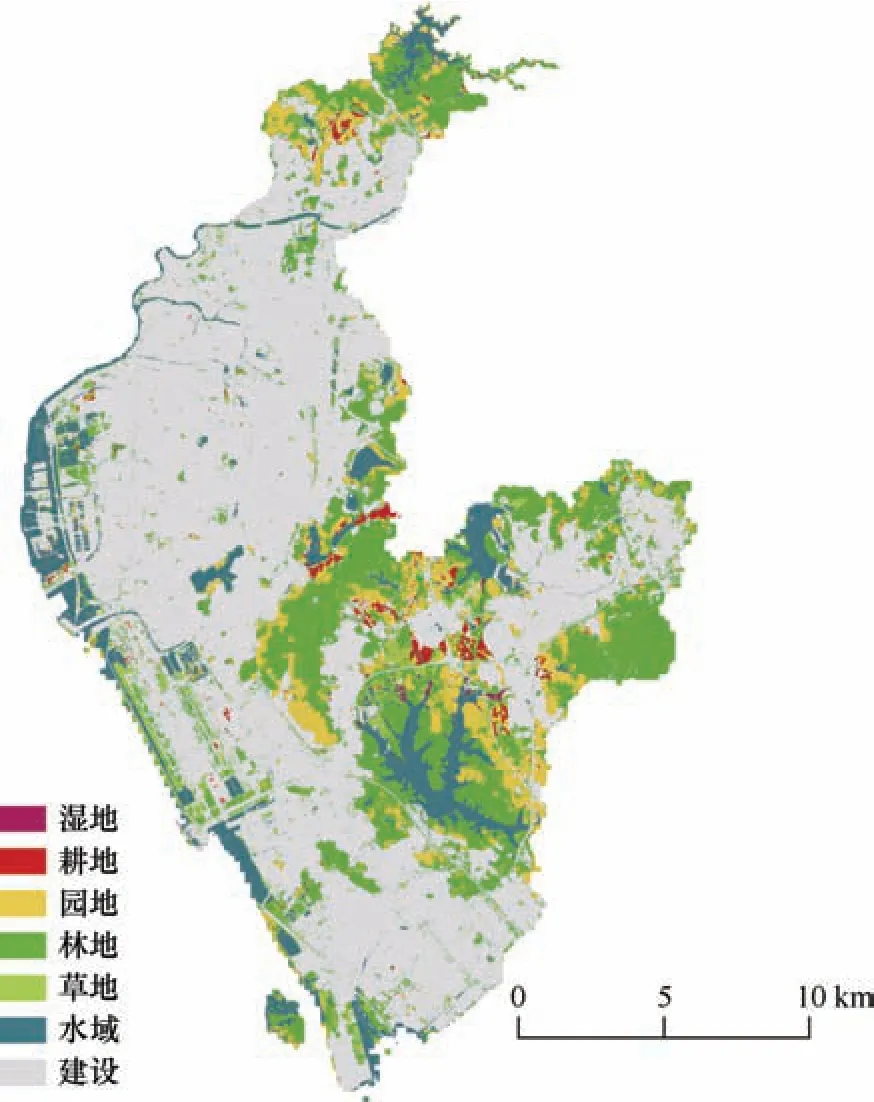
图6 基于DeepLabV3+模型的宝安区分类Fig.6 Classification map of Bao’an District based on DeepLabV3+
5 结 论
本文参考超高分辨率航拍影像和经人工修正的国土“三调”数据,构建面向深圳市宝安区的土地利用分类样本库,针对城市自然资源和土地现代化监管精度与效率需求,比较了有代表性的传统机器学习和深度学习分类方法,得到以下主要结论。
(1) 传统机器学习方法难以适用于大范围超高分辨率航拍影像土地利用类型分类。基于像元的分类结果存在较严重的“椒盐噪声”问题。面向对象分类方法,将影像分割后对象作为最小分类单元,有效解决了“椒盐噪声”问题,可较好地区分超高分影像中不同土地利用类型,但在大范围应用时仍存在效率较低的问题。
(2) 样本量和算力对分类方法选取起重要作用。训练样本容量较小时,传统机器学习分类结果可解释性较强,比深度学习方法算力要求低。较充足样本量情况下,传统机器学习方法仅用RGB 影像难以区分多种土地利用类型;以DeepLabV3+为代表的深度学习方法,能兼顾大范围区域土地利用类型数据生产的精度和效率要求。
本文还存在一些不足。一是使用的遥感影像虽然空间分辨率较高(0.2 m)但只含RGB 波段影响了分类精度,后续研究将以数据融合方式加入对于植被信息更为敏感的红外波段特征,以提升分类精度。二是本文实验比较不同方法分类结果时,以保证采用相同的训练集和测试集为前提,但模型结构不同导致训练方式存在一定差别,为了提升结果可比性以支撑结论,实验设计仍需进一步优化。
猜你喜欢
艺术家(2023年8期)2023-11-02
环球时报(2022-07-13)2022-07-13
小哥白尼(军事科学)(2022年2期)2022-05-25
环球时报(2022-03-14)2022-03-14
北京航空航天大学学报(2021年9期)2021-11-02
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
电影(2018年8期)2018-09-21
北京航空航天大学学报(2018年1期)2018-04-20
CHIP新电脑(2016年3期)2016-03-10
