
作者学术经验与被引频次的关系探讨
2024-01-29 08:43张丽华姚长青
情报工程 2023年5期
张丽华 姚长青
1. 中国科学技术信息研究所 北京 100038;
2. 山西财经大学 太原 030006
引言
论文被引频次预测是科学计量学的热门研究话题。面向预测的论文被引频次影响因素研究已积累了丰富的研究成果。这些影响因素大致4 类:(1)论文相关因素。包括标题长度、论文长度、论文主题、参考文献数量、文献类型、参考文献多样性、是否受基金资助、是否开放获取等。(2)作者相关因素。包括学术经验、性别、年龄、国籍、隶属机构、作者人数、合作、h 指数、累积被引量、作者发文量等。(3)期刊相关因素。包括期刊影响因子、期刊发文量、期刊总被引量、期刊语言等。(4)其它。包括出版时间、论文下载量、社交媒体转发、评论等。
本研究主要关注作者相关因素中的“作者学术经验”。由于研究人员之间的天赋存在较大差异,导致学术经验和论文被引频次之间的关系并不十分密切,但仍然存在这样的共识:作者学术经验很重要[1]。Sun 等[2]发现作者对研究工作的影响比机构更大。作为一个预测论文被引频次的关键因素,作者学术经验测度指标主要包括4 种:(1)发文量指标。如作者在目标论文之前已发表的论文数量。(2)引用数指标。如作者在目标论文之前已经获得的总被引次数、作者在目标论文之前已发表论文的平均被引频次。(3)学术年龄指标。学术年龄等于学者最新论文的发表年份减去第一篇论文的年份之差加1。(4)作者状态指标。如作者是否为高被引学者。(5)综合指标。如作者在目标论文之前的H 指数、第一作者的H 指数等。
已有部分研究从论文产出角度探索了学术经验与论文被引频次之间的关系。Hanssen 等[1]使用作者发文量测度学术经验,发现学术经验对论文被引频次有显著的正向影响,但是这种影响会随着经验水平的提高而迅速减弱。也就是说,年轻的研究人员能够相对较快地学会高水平研究所需的技能与知识。有经验的研究人员将产出更高质量的研究,并最终导致该研究被更频繁地引用。Walters[3]使用第一作者在2001—2002 年的发文量、第一作者在2001—2002 年发文量的被引用次数,以及第一作者2001—2002 年论文被引用次数除以发文量3 个指标测度作者的学术经验,并探讨学术经验与论文被引频次的关系,结果表明第3 个指标对因变量论文被引用次数具有显著影响。Peng 和Zhu[4]发现第一作者发文史是论文被引频次的重要预测因素,其中发文史是指论文发表年与数据检索年之间的时间差。相反,Ruan 等[5]认为第一作者发文史对单篇论文发表5 年后的被引频次预测贡献很小。
还有些学者从论文被引角度分析作者经验与论文被引频次的关系。Dalen 等[6]使用作者累积被引频次来表示作者学术经验,结果发现作者学术经验是论文被引用次数的最佳预测因素。Bornmann 和Daniel[7]研究了作者状态(author’s status,即作者是否为ISIHighlyCited.com 收录的高被引学者)对论文被引频次的影响,结果发现,作者中高被引学者越多,则论文的被引频次越高。Fu 和Aliferis[8]在测度学术经验时使用了第一作者的发文数、第一作者的累积被引用次数、末位作者的发文数和末位作者的累积被引用次数4 项指标,分析其与论文被引频次的关系,结果表明末位作者的累积被引用次数与第一作者的累积被引用次数指标对论文被引用频次有显著正向影响。程子轩等[9]在构建学术论文被引频次预测模型时,选择了作者数量、作者h 指数、作者发文量、作者论文的被引频次4 类10 个作者特征指标,经过相关分析与逐步回归发现,代表作者学术经验的第一作者发表论文的篇均被引量指标能够很好地预测论文被引频次。Wang 等[10-11]发现,第一作者在目标论文之前的h 指数是影响引用的关键因素。Abramo 等[12]分析了高产作者与高被引作者之间的关系,发现两者中度相关,高产作者与生产高被引论文的概率存在一定相关性。同时,大约一半高被引论文的作者是发文量排名前10%的作者。Danell[13]使用作者已发表论文数和已发表论文的引用率定量测度作者过往记录,分析这两个指标能否预测论文的影响力。结果表明,已发表论文的引用率是论文影响力的重要预测因素。相反,已发表论文数反而不重要。Ruan 等[5]发现第一作者的总被引频次、篇均被引频次、H 指数均不是预测论文被引频次的重要指标。
实际上,在分析作者学术经验与论文被引频次关系时,不同学者得出了不同的结论。Onodera 和Yoshikane[14]总结了影响论文被引频次的不同因素,本文截取了与作者学术经验相关的因素(表1),从表1 中可以看到,作者发文量、作者被引量、作者状态这3 个表示作者经验的指标与论文被引频次的关系在不同的研究中得出不同的结论。这一方面表明当同一主题的不同研究结论存在差异时,应关注不同研究对象、视角与方法的差异,另一方面也表明本文能够在现有研究基础上丰富作者经验与论文被引频次之间的关系研究。

表1 影响论文被引频次的作者相关因素
同时,在现有的作者学术经验指标中,除了第一作者,较少考虑其他作者角色,如末位作者、单一论文作者以及第一作者与单一作者论文分别对应的论文数与被引用次数。此外,已有研究多是从单篇论文层面关注作者学术经验与论文被引频次之间的关系,这表现为被解释变量通常是单篇论文的被引频次,解释变量则为该篇论文所对应的特征,如作者人数、期刊影响因子、作者在这篇论文之前的发文量等。较少从作者层面,尤其是作者整个职业生涯所有学术论文的汇聚层面探讨学术经验与论文被引频次之间的关系。
因此本研究旨在从作者层面探讨作者学术经验与论文被引频次的关系。我们选择斯坦福大学John P. A. Ioannidis 教授团队发布的“高被引科学家数据库”中的194439 名科学家为研究对象,主要解决以下2 个问题:(1)当作者担任不同角色时,学术经验与论文被引频次之间的关系是否存在差异?(2)作者层面作者经验与论文被引频次呈现出怎样的关系?通过对这2 个问题的回答,有助于更深入地探讨学术经验与论文被引频次的关系,使研究机构在聘用、晋升科研人员时合理考虑科研人员的学术经验。
1 数据来源与方法
2022 年11 月3 日,斯坦福大学John P.A. Ioannidis 教授团队发布开放获取的2022 年“高被引科学家数据库”(第五版,https://elsevier.digitalcommonsdata.com/datasets/btchxktzyw/5)。该数据库2019 年7 月6 日发布了第1 版,每年更新1 版,第2 版和第3 版的发布时间分别是2020 年10 月8 日和2021 年10 月19 日。2022 年的情况较特殊,分别于10 月10日和11 月3 日更新了第4 版和第5 版。这两版的主要区别在于研究子领域的划分方法与数量,其余计量指标没有发生变化。该团队指出,第5 版更合适,应该取代第4 版。
“高被引科学家数据库”包括“年度影响力数据集”(single recent year dataset)和“职业生涯影响力数据集(1960—2022)”(career-long database)两个排名。通过遴选出基于c 值(c-score)或子领域排名前2%的前10 万名科学家,来自22 个学科领域及174 个子领域的200196 名科学家入选“2022 年度影响力数据集”,194983名科学家入选“职业生涯数据集”。本研究通过对数据集的清洗,最终选择第5 版“职业生涯数据集”中的194439 名科学家为研究对象。数据集中包括丰富的计量指标信息,包括科学家姓名、机构、国家、发表第一篇论文年份、最近一篇论文年份、总被引频次、h指数、hm指数、作者排名最高的领域、子领域等。
本研究拟解决的第1 个问题是当作者担任不同角色时,论文被引频次是否存在差异。根据署名位置,作者角色可以划分为独著、第一作者、末位作者以及除此之外的其他作者。其中,独著作者说明研究工作的构思、设计、分析与论文撰写全部由作者一人完成,作者是论文的全部贡献者。第一作者是合著论文的主要贡献者,他/她不仅应该是课题主要观点的拥有者,而且除特殊情况外还必须是科研课题的具体操作者和文章的主要执笔者[19]。末位作者一般是高级作者[20],为“指导、监督和保证所报道作品的真实性”以及“对作品的科学准确性、有效方法、分析和结论承担责任”的个人[21]。当然,在论文作者署名完全按照贡献度大小排序时,末位作者也可能对论文的贡献度最小。其他作者是指非独著、非第一、非末位作者的其他作者。其他作者的贡献度一般按照署名位次依次减小。本研究选择对论文做出重要贡献的独著作者、第一作者和末位作者进行研究。
我们采用方差分析方法观察同一作者扮演不同角色时被引频次是否存在差异。首先为194439 名科研人员根据角色不同建立3 组数据,分别是独著作者组、第一作者组和末位作者组。接下来依次进行不同组及组与组之间的正态性、方差齐性检验,根据检验结果选择合适的假设检验方法,本文中选择Kruskal-Wallis 秩和检验方法进行单因素方差分析,最后根据分析结果得出不同组被引频次是否存在差异的结论。
本研究拟解决的第2 个问题是探讨作者层面学术经验与被引频次的关系。论文被引频次服从偏态分布,泊松回归和负二项回归是针对偏态分布的常用模型。但泊松分布要求数据的总体方差等于均值,一般现实世界的数据较难满足这一要求。因此,本研究采用负二项回归分析作者经验与论文被引频次的关系。同时,负二项回归也是其他学者研究这两个变量关系的常用方法[6-7,14,22]。本研究在使用负二项回归模型时采用了马萨诸塞大学阿默斯特分校(University of Massachusetts, Amherst)Sachin Date 的 研 究:https://timeseriesreasoning.com/contents/negative-binomial-regression-model/。负二项回归的基本操作步骤为:(1)对数据集进行泊松回归拟合,获得拟合率向量λ;(2)对数据集进行aus OLS 回归拟合,获得α 的值;(3)使用第2 步中获得的α 对数据集进行负二项回归拟合;(4)使用拟合的负二项回归模型进行预测;(5)检验负二项回归模型的拟合优度。
进行负二项回归分析采用的指标见表2。学术经验我们选择了3 个指标,学术年龄、h指数和hm指数。学术年龄和h 指数是经典的用于衡量作者经验的指标。hm指数[23]主要用于h 指数在多作者论文中存在不公平的问题,是利用论文平均作者数量标准化之后的指标。其计算方式类似于h 指数,科学家的hm篇论文至少被引用了hm次,其他论文的被引次数都少于hm。只不过在计算论文数量时,将论文数量除以该篇论文的作者人数。例如一篇论文有3 名作者,则对每名作者来说,其发文量等于1/3。此外,在作者层面,计算引用影响指标时排除自引更合理[24]。因此本研究中涉及的所有引用指标均排除了作者自引。

表2 学术经验与论文被引频次指标
选择控制变量时主要考虑了以下方面:(1)作者发文量。一般来说,作者发表的论文数量越多,则其总被引频次可能越高。发文量是影响作者经验与被引频次关系的重要因素。(2)作者角色的差异。当作者处于不同角色时,其对研究的贡献也存在很大的差异。如第一作者是研究的最大贡献者,而末位作者可能是论文的通讯作者,也可能对研究的贡献最小。根据署名位置,作者角色可以划分为独著、第一作者、末位作者、其他作者(指除独著、第一作者、末位作者之外处于其他署名位置的作者)。本研究考察了作者在其职业生涯中,处于第一作者、末位作者等不同角色时的发文量与被引频次的关系。(3)研究的多样性。本研究主要从施引文献的角度考虑研究的多样性,不同的施引文献数量越多,可以认为该研究涉及的主题越多样。多样的研究主题可能为研究带来更多的引文。(4)Scopus 停止收录的论文数量与引用频次。期刊会因不当出版行为被Scopus 停止收录。停止收录可能说明期刊中的论文存在质量问题。通过停止收录论文与引文分析,可以清楚地了解作者被引用频次的来源。
由于自变量和控制变量之间的原始数据差别较大,因此对其进行标准化处理。标准化方法采用最大最小标准化方法(min-max normalization)。这种方法简单易理解,不改变数据分布,采用的公式为
其中,Y是指标的标准化值;X为指标的原始值;X_max 与X_min 分别对应指标的最大值和最小值[25]。
本研究中所使用的数据分析工具为EXCEL,SPSS 和Python。
2 研究结果
2.1 变量描述性统计
对本研究中涉及的15 个变量进行描述性统计分析,见表3。从表3 中可以看出,tct 的离散程度较高,说明不同作者在1960-2021 年发表论文的总被引频次差别较大。3 个自变量中,aa 主要考查科研人员的职业生涯长度,均值为35,最长的职业生涯与最短的职业生涯相差68年。hm指数与h 指数相比,其均值与方差都更小,这与hm指数的计算方法有关,其是在h 指数的基础上对论文平均作者人数的标准化。

表3 变量的描述性统计
在控制变量中,第一作者(fp,fpc)、末位作者(lp,lpc)的发文量和被引量均值高于独著作者(sp,spc)。这与研究中合作现象越来越普遍的趋势一致。Dr 是研究的多样性指标,也是一个均值和方差都很大的指标。ncp 是未被引用的论文数量,其均值是总发文量均值的15.9%。这说明从平均水平来看,相比于至少被引用1 次的论文而言,高被引科学家群体未被引用的论文数量在职业生涯的总发文量中占少数。Stp,stpc 是从未被Scopus 数据库停止收录的角度考察其对被引频次的影响,总体来看,论文被Scopus 停止收录现象较不常见,但可以从另一个独特视角考察科学家的影响力情况。
2.2 方差分析结果
方差分析用于解决不同角色的作者发文量和被引频次是否存在差异的问题。应用方差分析需要满足3 个条件:(1)各样本相互独立;(2)各对比组资料服从正态分布;(3)各总体方差相等,即方差齐[26]。高被引科学家数据集中各个科学家个体相互独立,满足条件1。我们使用Q-Q 图来检验sp,fp,lp,spc,fpc 和lpc 指标是否服从正态分布(图1、图2)。Q-Q 图是根据样本数据的分位数与理论分布(如正态分布)的分位数的符合程度绘制的。如果实际数据服从正态分布,则所有分位数应该落在截距为样本均值,斜率为样本标准差的直线上。从图1、图2 可以看出,不同作者角色的发文量与被引频次指标并不服从正态分布。
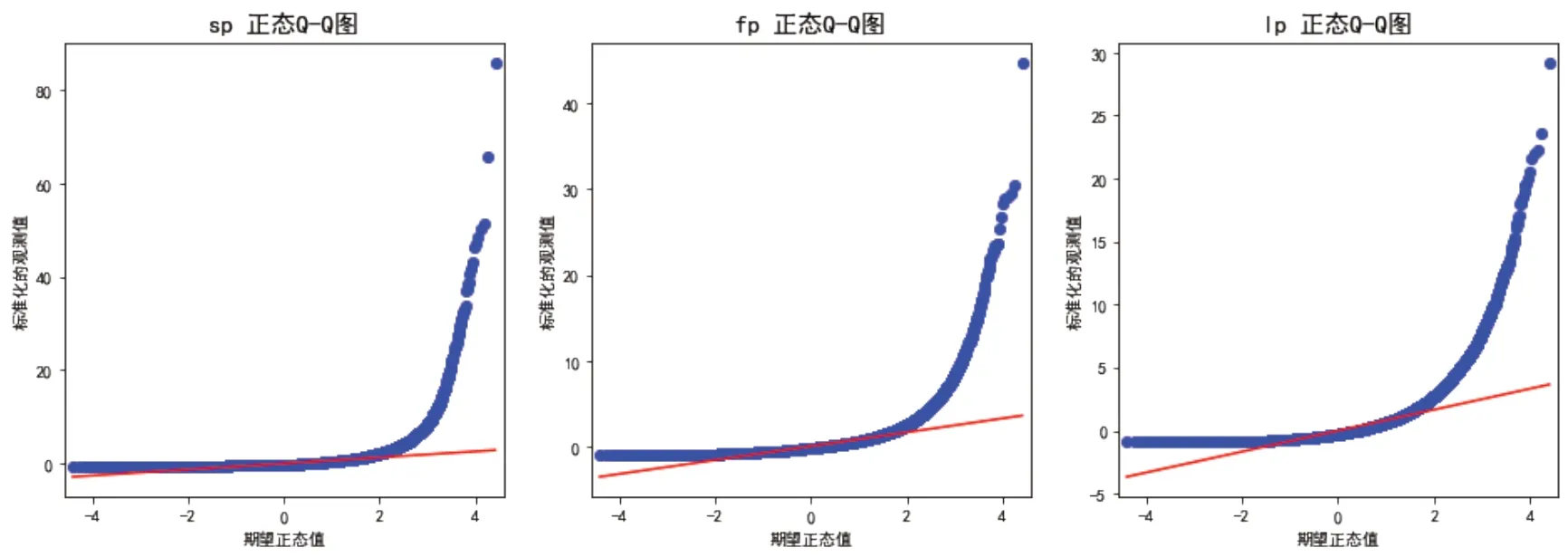
图1 作者角色发文量指标Q-Q 图

图2 作者角色被引量指标Q-Q 图
本研究通过绘制残差图来检验方差齐性(图3、图4)。如果拟合值和残差的散点随机分布在一个水平带之内,没有离群点,而且其离散程度基本上一样,表示满足方差齐性的要求。从图3、图4 中可以看出,作者角色的发文量和被引频次指标不满足方差齐性的前提要求。

图3 作者角色发文量指标的残差图

图4 作者角色被引频次指标的残差图
因作者角色相关的6 个指标不满足正态性和方差齐性的前提条件,本研究选择Kruskal-Wallis 秩和检验进行单因素方差分析。经过计算,sp,lp 和fp 的统计量H 等于196993.5,p值为0.0,说明不同作者角色发文量不全相等。为了找出sp 与lp、sp 与fp、lp 与fp 之间究竟是哪两个均值不相等,我们采用Tukey HSD 方法进行多重比较。结果表明,sp,lp 与fp 的均值两两之间均存在显著差异。由此我们可以得出结论:同一作者在扮演不同角色时其发文量存在显著差异。采用相同的方法,我们对spc,lpc和fpc 进行Kruskal-Wallis 检验,统计量H 等于179298.9,p 值为0.0。多重比较也显示其均值两两之间存在显著差异。因此,同一作者在扮演不同角色时其发表论文的被引量也存在显著差异。
2.3 负二项回归结果
建立负二项回归模型之前需要判断自变量、控制变量之间是否存在共线性问题。因多数变量不满足正态性要求,此处选择spearman 相关系数。11 个控制变量、3 个自变量两两之间的相关系数见表4—表7。相关系数大于0.6 以蓝色底纹表示。从表4 中可以看出,除fp,fpc,stp指标之外,其余控制变量均存在与其他变量相关系数较高的情况。自变量aa 与所有控制变量均不相关。H 指数与np,lpc,dr 存在相关关系。而hm指数与np,lp,lpc,dr 存在相关关系。多个变量之间存在较高相关系数,提示由这些变量建立的回归模型可能存在共线性问题。
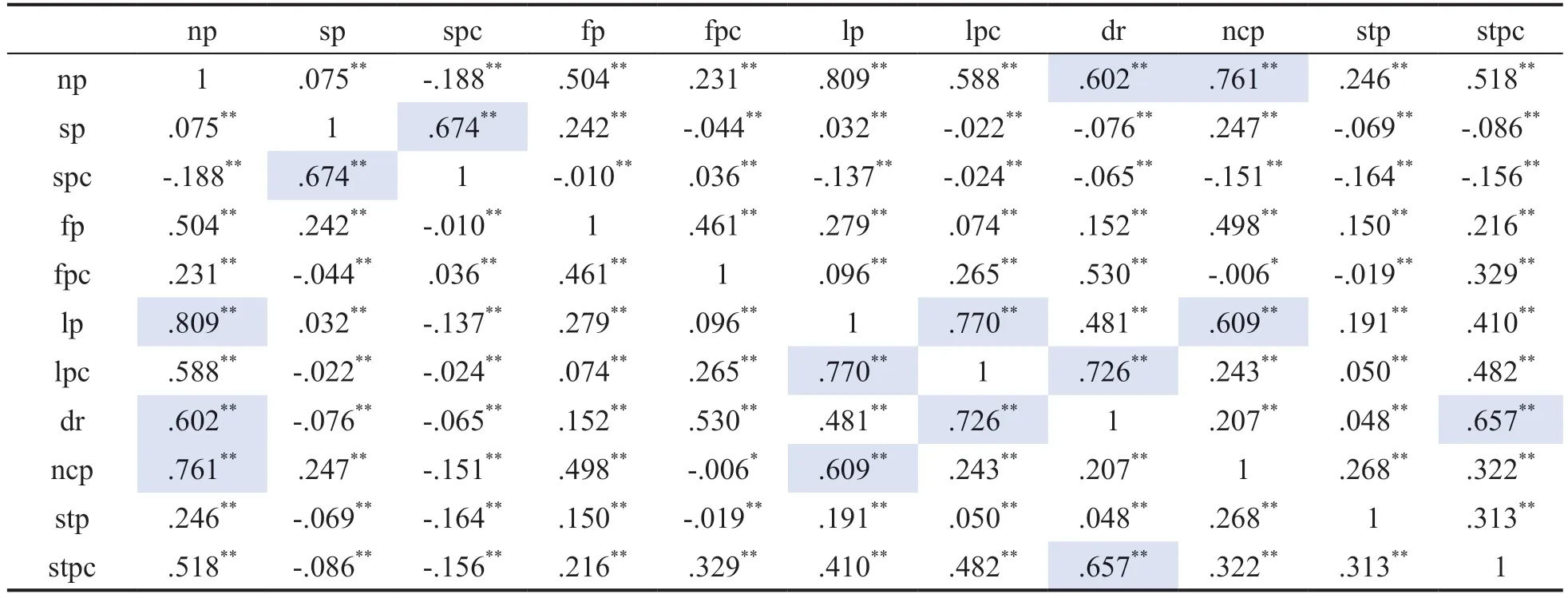
表4 控制变量之间的spearman 相关系数

表5 自变量aa 与控制变量之间的spearman 相关系数

表6 自变量h 与控制变量之间的spearman 相关系数

表7 自变量hm 与控制变量之间的spearman 相关系数
为了解决共线性问题,采用逐步回归进行变量筛选。逐步回归的基本思想将全部自变量按其对因变量的影响程度大小,从大到小地依次把自变量引入方程。每引入一个自变量,就要对它作检验,有统计学意义才引入。当新的自变量进入方程后,就对方程中当时所含有的全部自变量进行检验,一旦发现不具有统计学意义的自变量就立即剔除[26]。经过回归分析并结合变量的实际意义,本文最后选择如下变量加入负二项回归模型:(1)在以aa 为自变量的模型中,包括所有控制变量;(2)在以h 指数为自变量的模型中,控制变量包括dr,lpc,fpc,lp,np,fp,spc,ncp,stpc;(3) 在以hm指数为自变量的模型中,控制变量包括dr,lpc,fpc,np,lp,ncp,fp,spc,sp。
各模型的回归结果见表8—表10。我们为每个自变量构建了两个模型,模型1 中只包括控制变量,模型2 中包括控制变量与自变量。分别对两个模型进行检验,并计算其对数似然值。接下来检验2 个模型对数似然比,χ2 统计量等于模型1 和模型2 对数似然值差值的2 倍。若则拒绝原假设,说明作者经验显著影响被引频次,反之,则说明不存在显著影响。

表8 作者学术经验aa 与被引频次负二项回归结果

表10 作者学术经验hm 与被引频次负二项回归结果
从表8—表10 中我们可以看出:
(1)采用3 个自变量时,模型2 的拟合度均优于模型1。这表现为当自变量为aa、h 指数和hm指数时,模型1 与模型2 对数似然比说明作者学术经验对论文被引频次存在影响。
(2)当自变量为aa 时,其回归系数为0.7839,自变量为h 指数时,其回归系数为9.9299,而自变量为hm指数时,回归系数为4.2814。说明作者学术经验与论文被引频次均为正向关系。即作者学术经验越多,则其论文被引频次越高。其次,采用不同指标衡量作者学术经验时,学术经验与论文被引频次呈现的量化关系密切程度有所不同。
(3)在控制变量中,dr 的回归系数在模型中均大于14,是回归系数的最大值,说明研究的多样性是学术经验与论文被引频次之间关系的最大影响因素。回归系数第二大的指标为fpc,其值均大于8,说明其对论文被引频次为正向影响,即第一作者发文量的被引频次指标越大,论文被引频次越高。当自变量使用不同指标时,np 对论文被引频次的影响情况有所不同,当使用aa 指标与hm指标时,作者总发文量对论文被引频次有正向影响,而使用h 指数时,则对论文被引频次有负向影响。除此之外,当自变量为aa 时,第一作者论文数量(fp)和未被引用的论文数量(ncp)对论文被引频次有显著负向影响。当自变量为h 指数时,独著论文被引频次(spc)对论文被引频次有显著正向影响,而末位论文作者被引频次(lpc)则有显著负向影响。当自变量为hm指数时,独著论文数量(sp),独著论文被引频次(spc)以及第一作者论文数量(fp)越大,则论文被引频次越低。
3 总结与讨论
本文以高影响力科学家为研究对象,从科研人员整体职业生涯的视角探讨作者学术经验与论文被引频次的关系。主要结论如下:
(1)当作者担任独著作者、第一作者和末位作者等不同角色时,论文被引频次之间存在显著差异。从方差分析结果来看,sp,lp 与fp的均值两两之间、spc,lpc 和fpc 均值两两之间均通过了显著性检验。从表3 中也可以看出,spc、fpc 和lpc 的均值分别为401.07、1384.95和2376.42。可见末位作者的论文被引用频次更高,其次为第一作者,最后为独著作者。末位作者一般为资历更高的学者。这也验证了“资历更高的学者其论文被引频次更高”的结论[4]。
(2)使用负二项回归分析作者学术经验与被引频次关系时发现,无论自变量采用学术年龄、h 指数还是hm指数,其回归系数均是一个较大的正数,说明作者学术经验确实对论文被引频次产生了积极的影响。作者学术经验积累得越多,其论文被引频次值越大。也就是说,我们从高影响力科学家数据集的角度再次验证了两者之间的正向影响关系。这与Hanssen 等[27]的研究结论一致。
(3)研究多样性是影响论文被引用频次的最主要因素。本文中研究多样性是指作者在1960—2021 年论文的不同施引论文的数量。研究多样性对应着科学计量学中更泛化的概念“学科多样性”。最常用的学科多样性指标包括跨领域引用指数、信息熵、布里渊指数和Rao-Stirling 等[28]。目前学科多样性与论文被引频次的关系尚未有明确结论,仍需进一步深入研究[29]。本文经过分析发现,不论使用哪个自变量,研究多样性dr 的回归系数在所有自变量和控制变量中均为最大值,说明研究多样性是影响论文被引用频次的最主要因素,该结论进一步丰富了学科多样性与论文被引频次关系理论。
(4)作者学术经验与论文被引频次的量化关系受数据集选择、学术经验计算方法的影响。我们通过负二项回归分析发现,作者学术经验与论文被引频次之间确实存在影响关系。但这种影响关系到底有多大,在使用不同的学术经验指标时呈现出了不同的结果。同时,本研究选择的高影响力科学家数据集,与使用其他数据集分析二者关系时呈现出的结果也不完全相同。因此,我们在分析此类研究主题时,务必仔细选择数据、指标、方法,若要进行对比分析,则应注意数据集、指标、方法的可比性。
未来我们将从以下方面继续开展学术经验与论文被引频次的关系研究:第一,本文研究对象仅涉及高影响力科学家,未来我们将选择其他科研人员群体与高影响力科学家进行对比分析;第二,本文中作者角色涉及独著作者、第一作者和末位作者,并未涉及除这三种角色之外的其他作者,如在研究中起领导与协调作用的通讯作者,以及人数众多的中间作者,未来将开展作者角色的更细致分析;第三,本文只是从定量的角度分析二者关系,对于二者背后的相互影响机制及深层次原因还需要通过个案分析、定性分析来实现,未来可将定性与定量方法结合以获得更客观的分析结论。
猜你喜欢
护理与康复(2022年6期)2022-11-25
党课参考(2021年20期)2021-11-04
今日农业(2020年14期)2020-08-14
小哥白尼(军事科学)(2019年6期)2019-03-14
党课参考(2018年20期)2018-11-09
阅读(低年级)(2018年10期)2018-05-14
阅读(低年级)(2018年11期)2018-05-14
阅读(低年级)(2018年12期)2018-03-23
小学生学习指导(中年级)(2017年4期)2017-03-20
初中生世界·七年级(2016年4期)2016-04-21
