
基于Spark技术的大数据智能分析平台构建
2024-01-30 01:31贾淑滟
滨州学院学报 2023年6期
贾淑滟
(山西旅游职业学院 计算机科学系,山西 太原 030031)
0 引言
用户在云端输入检索信令获取目标信息时,往往由于云端数据量过于庞大而导致目标信息检索超时[1]。考虑到这种负面因素影响,以云环境下大数据为支撑的企业开始致力于开发适用于自身的大数据智能分析平台。通过分散业务流程,实现大数据资源多层级管理,不仅能梳理杂乱无序的网络数据,还能缩短目标信息的检索时长,达到改善用户操作体验、拉近用户合作关系、增加企业用户流量的目的。汪杰等[2]通过B/S结构设计数据分析平台的基本框架,但该方法存在平台运行时间过长的问题。孟光伟[3]通过Kafka分布式函数将待处理数据划分成权重系数不同的多组Kafka集群,并将多组Kafka集群依次输入由Spark Structured Streaming网络引擎组成的后台运算程序,实现大数据智能分析平台的构建,该方法存在平台运行效率低、平均绝对误差较大的问题。张波等[4]采用云环境下大数据开源工具Docker建立基于业务管控系统的数据分析平台,并在实际应用中结合运营统计装置,实现大数据智能分析平台的构建。Ogiela等[5]提出了基于人本分析的数据分析技术,为了充分解释所有可能发生的偏好,并对其在产品评估、促销阶段的意义和有用性进行了分析,但这两种方法存在平均绝对误差较大的问题。Abukmeil等[6]从盲源分离、流形学习和神经网络架构了用于数据分析的无监督生成学习模型,但是该方法存在平台运行效率低的问题。李娟等[7]利用映射-归约(MapReduce,MR)和Hadoop构建了Hadoop云平台,在云平台中实现了分布式计算、数据挖掘、业务响应以及用户交互。虽然,MR技术具有高效性、可扩展性、容错性和灵活性优势,但是MR需要进行数据划分、映射、归约等多个步骤,存在复杂性、数据倾斜、数据运算成本增加等问题。刘仁芬等[8]在筛选分布空间高维数据特征并进行降维的基础上,利用改进Spark技术,设计了高维数据增量式聚类算法,该方法降低了存储空间的占用率,可完成高维数据的有效、可靠聚类。
在构建大数据智能分析平台时,需要综合考虑性能、可扩展性、易用性等因素。Spark技术和MR技术都是用于大数据处理的分布式计算框架,也是构建时选择的主要方法。其中,Spark技术是兼具Scala语义开发模式和分级式数据处理系统的新型平台开发技术,其对数据的存储和运行迭代均以云端为主,这使得最终构建的平台运行空间较大,不易出现由于数据量过大而导致的平台运行卡顿的问题。MR技术[9]对数据的存储和运行迭代均以本地磁盘为主,这使得最终构建的平台运行空间较小,除运行卡顿外,还易发生平台崩溃和数据丢失的情况。在数据审核的过程中,Spark技术采用循环审核的方式,最大限度过滤干扰数据,使平台接收到的数据信息优化效果明显,且平台负载率明显下降。MR技术采用非循环审核的方式,易出现干扰数据扰乱平台数据库的现象,使平台负载率上升,数据运算成本增加。因此,本文提出基于Spark技术的大数据智能分析平台构建方法,以优化数据分析质量。
1 基于局部约束学习方法的大数据降维
局部约束学习方法作为一种数据降维方法,主要通过低维空间嵌入技术解决大数据的高维问题[10]。以高维数据集S为例,局部约束学习方法想要获取基于高维数据集S的低维映射指征,需通过组合相关函数[11]将数据集转化成流形函数曲线上的一组分布式高维数据标志点,达到约束标志点领域内映射的目的。组合相关函数为

流形函数曲线为

距离差分原理公式为
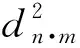
微分同胚映射原理公式为

2 大数据智能分析平台构建
2.1 大数据智能分析平台的架构
要建立非专业用户数据便捷检索的大数据智能分析平台,需从研发体系、数据分析流程、用户接口服务等多个角度分析,同时考虑应用服务层、权限管理层、中间服务层和基础资源层,共同组建基于繁杂数据业务的平台分层架构图(图1)。各层框架的功能:(1)应用服务层。应用服务层主要采用Web Service系统设计,该系统操作界面简便,方便用户下载数据、查看数据展示图、修改数据参数设定,对外接口服务内部信息系统不限制用户登录地址,即用户可以在任意地点登录并使用该平台。(2)权限管理层。权限管理层加入Java服务器约束数据集操作对象[13],即每次平台操作任务仅能登记在一位用户名下,并保存该用户近三天内全部检索数据,方便用户重复审阅。(3)中间服务层。中间服务层包括主题数据服务模块和数据自动化汇聚模块,其中,主题数据服务模块又被细分为数据监控状态、数据资源目录、数据链接和数据主题库,这些分支将主题数据服务模块进一步细化,不但增加了数据信息配置的精确性,还为开发人员调试服务器提供可靠依据。(4)基础资源层。基础资源层是指企业上传的相关数据。以大数据智能分析平台为例,该平台需要上传的资源信息是经过降维处理的大数据信息[14-15],在上传过程中,平台会根据Map对应映射表检测数据维度,达到整体数据维度无误的目的。

图1 平台分层架构
2.2 后台数据分析服务设计
在利用Spark技术成功建立平台框架的基础上,为了进一步提高任务执行效率,参考MR数据网络质量分析系统,结合数据分析编排器,对MR数据网络进行优化,实现大数据智能分析平台的后台分析服务设计。MR数据网络质量分析系统是由RESTful API开源包,通过对网络覆盖范围内多角度信息解码而获取的以JSON为标准格式的多节点分析系统。MR数据网络质量分析系统的节点功能如图2所示。

图2 MR数据网络质量分析系统的节点功能
数据分析编排器的整体框架借助上述MR数据网络质量分析系统,在节点功能不变的前提下,加入Parquet运算公式,获取基于可视化组件的数据源算子,为后续数据分析工作做好充足准备。Parquet运算公式为
式中,cosε表示Parquet运算常数,f(x2)表示Parquet运算公式与MR数据网络质量分析系统的结合紧密度[16],f(xest)表示数据源算子的获取率,Dwt表示数据源算子的获取误差。数据分析编排器的整体框架如图3所示。数据源算子不仅能够实现多主题数据交叉编排分析,还能将输入数据与执行计划直接挂钩,为用户提供数据驱动检索服务的同时,达到后台数据定位追踪的效果。

图3 数据分析编排器的整体框架
3 实验与结果
3.1 实验方法


3.2 结果与分析
为了验证基于Spark技术的大数据智能分析平台构建的整体有效性,需要对其进行测试。选择规模不同的三组数据库,a组数据库内存量为1×106bit,b组数据库内存量为1×1011bit,c组数据库内存量为1×1016bit:分别采用不同方法建立基于三组实验数据库的智能分析平台,根据不同方法的平台运行时间、平台运行效率和数据分析平均绝对误差,推测不同方法的平台分析性能。
(1) 平台运行时间。分别采用Spark技术、文献[2]方法和文献[3]方法建立基于三组实验数据库的智能分析平台,并计算各平台的加速比参数(图4),进而判断不同方法的平台运行时间。由图4可知,采用Spark技术基于三组规模不同的数据库所建立的智能分析平台的加速比参数均不低9,相较文献[2]方法提升了4,相较于文献[3]方法提升了2,说明Spark技术针对任意规模的数据库所建立的智能分析平台,其运行时间均较短,即Spark技术构建的平台数据处理性能较强。这是因为Spark技术在建立大数据智能分析平台前,首先对平台所需要的大数据降维,即将高维数据标志点嵌入低维空间,实现高维数据的低维映射,使最终构建的大数据智能分析平台运算时间下降。
(2) 平台运行效率。以三组数据库为例,规定平台运行时间不得超过30 min,观察固定时间向量时,平台内的数据处理情况。不同方法在固定时间向量下的数据处理情况如图5所示。由图5可知,Spark技术在时间向量固定的情况下,基于a组数据库的智能分析平台数据处理率接近100%,这说明Spark技术所建立的大数据智能分析平台数据处理效率较高。文献[2]方法和文献[3]方法在时间向量固定的情况下,基于a组数据库的智能分析平台数据处理率分别不超过80%和70%,Spark技术比文献[2]方法和文献[3]方法所建立的大数据智能分析平台数据处理效率高出20%~30%。综上所述,Spark技术具有更高的数据处理效率。
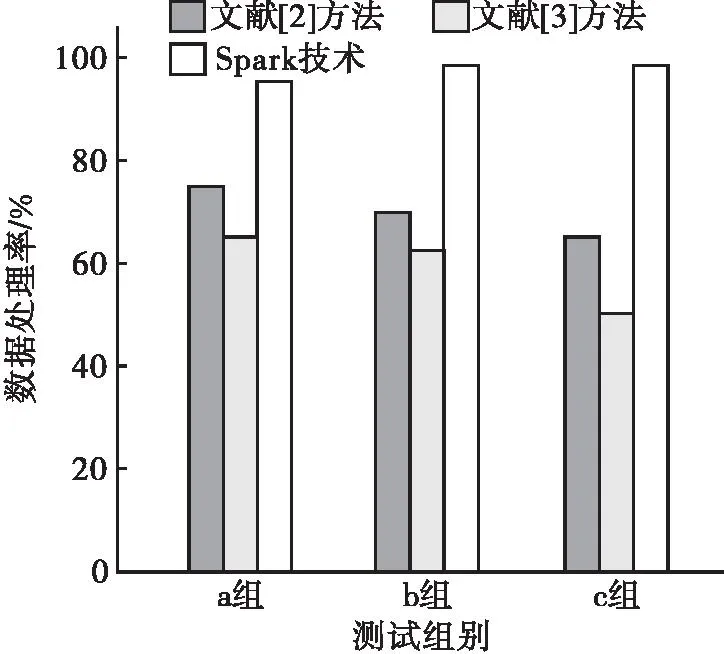
图5 固定时间向量时的数据处理情况
(3) 数据分析平均绝对误差。采用Spark技术、文献[2]方法和文献[3]方法建立基于三组实验数据库的智能分析平台,并计算各平台的数据分析平均绝对误差。不同方法的数据分析平均绝对误差如图6所示。采用Spark技术基于三组规模不同的数据库所建立的智能分析平台的数据分析平均绝对误差最大值为0.8%,说明Spark技术构建的智能分析平台在数据处理过程中发生错误的概率较小。文献[2]方法和文献[3]方法基于三组规模不同的数据库所建立的智能分析平台的数据分析平均绝对误差最小值分别为1.6%和2.2%,Spark技术比文献[2]方法和文献[3]方法构建的智能分析平台在数据处理过程中发生错误的概率低,由此证明了基于Spark技术的大数据智能分析平台具有更低的数据分析平均绝对误差。

图6 不同方法的数据分析平均绝对误差
4 结论
为了解决数据分析过程中平台运行时间较长、平台运行效率较低和数据分析平均绝对误差高的问题,提出基于Spark技术的大数据智能分析平台构建的方法。结果表明,所设计平台的运行时间短、平台运行效率高、平台数据分析平均绝对误差低。如何在保证大数据智能分析平台高效性的同时,对数据智能分析过程实施全程监控,是下一步研究人员需要努力的重点。
猜你喜欢
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
测控技术(2018年4期)2018-11-25
电信科学(2017年6期)2017-07-01
财经(2017年2期)2017-03-10
财经(2016年15期)2016-06-03
财经(2016年3期)2016-03-07
财经(2016年6期)2016-02-24
中国惯性技术学报(2015年1期)2015-12-19
数学年刊A辑(中文版)(2015年3期)2015-10-30
