
异构计算系统中能量感知利润最大化在线算法
2024-02-18 10:40张庆辉李伟东张学杰
郑州大学学报(理学版) 2024年1期
张庆辉, 李伟东, 张学杰
(1.云南大学 信息学院 云南 昆明 650500;2.云南大学 数学与统计学院 云南 昆明 650500)
0 引言
随着数据中心能耗的快速增长,异构计算系统中关注于能效的任务调度越来越重要。最近学界提出了一种名为任务包(bag-of-tasks)的静态调度模型[1]。与以往的经典调度模型相比,某台机器上的固定执行时间(estimated time to compute,ETC)取决于任务类型与机器类型。通过这一概念,能把异构计算系统中心成千上万的任务进行分类,而分类后的类型数量相对较少。如果单独地为每一个任务进行决策,那将要耗费难以接受的时间。而任务包的调度模型很好地限制了问题规模,这也使得为该问题设计一种能得到拟最优调度的高效算法成为可能[2-3]。
经典的能量感知调度模型旨在最小化任务包所消耗的能量或最大完工时间。然而,对于异构计算系统中心运营商而言,将每个单位时间的运行利润最大化会带来更多的经济收益,其中利润等于用户为一个任务包支付的费用减去执行该任务包消耗的电力成本。通过综合考虑能源成本和最大完工时间,实现单位时间利润最大化的目标,即考虑任务包的能量感知利润最大化(energy-aware profit maximizing, EAPM)问题。Tarplee等以此为目标提出了一种新的异构计算系统调度模型,该模型具有机器类型数与任务数都十分有限的特征[3]。通过使用一种新颖的基于线性规划(linear programming, LP)的舍入算法,设计了一个能够得到接近最优调度的高效算法。
Tarplee等用一个最大完工时间下界代替了原本的最大完工时间[3]。最大完工时间下界是将任务平均分配给所有机器时的完工时间。这个下界与真实的最大完工时间是有一定差距的。因此,该数学模型是不准确的,而且在基于LP的舍入步骤过程中,能耗成本可能会增加。这导致即便可以通过使用基于匹配的舍入技术来改善,但执行时间会随着问题规模的扩大而急剧上升,使该算法在大型数据中心无法有很好的表现。
本文的主要贡献如下:1) 为EAPM问题建立了一个准确的数学模型,该模型能精确计算每到达一个用户并分配其任务包后系统的最大完工时间;2) 提出了一个时间复杂度为O(nm4)的在线算法,该算法在每个用户到达时构造多个线性方程组,这些线性方程组中最好的结果,便是当前针对该用户任务包的调度结果;3) 通过对比实验,说明了本文提出算法的优越性。
1 相关工作
最近几十年有大量关于异构计算系统中任务调度模型的研究。Braun等比较了11种静态启发式算法,他们将一类互相独立的任务映射到异构分布式计算系统,来最小化最大完工时间[4]。Dai等在包含两台平行机的系统中,设计了一种半在线算法,能很好地限制机器的最大完工时间[5]。针对考虑任务包的调度模型,Tarplee 等提出了一种基于线性规划的资源分配算法,能高效地给出最小化最大完工时间的调度方案[2]。胡逸騉针对面向异构计算集群的任务调度和能量消耗问题,提出一种面向异构计算系统的能量感知任务调度算法[6]。
Friese 等针对任务包这种情形提出了一种改进的多目标遗传算法来生成多个不同的调度方案,能很好地平衡能源消耗和最大完工时间之间的得失[1,7]。他们还创建了一个工具,该工具能帮助系统管理员对系统性能和系统能量分配进行权衡[8]。Zhang等设计了一个整数线性双目标优化模型,并提出了两阶段的启发式分配算法以找到高质量的可行解决方案[9]。除此之外,追求能量感知利润最大化的目标也能很好地平衡最大完工时间和能耗。Li等针对考虑任务包的能量感知利润最大化问题,设计了一个最坏情况即近似比接近2的近似算法[10]。随后又提出了一个针对该问题的多项式时间近似算法,该算法同样能在某些情况下有接近2的近似比效果[11]。
在云计算环境中,云资源管理同样是云供应商的一个重要内容。Khemka 等为能源受限的环境设计了四种能量感知的资源分配启发式方法,目的是使系统获得的总效用最大化[12]。姜春茂等提出面向实时云任务的细粒度任务合并调度算法,在满足用户SLA的前提下,能够有效降低云能耗[13]。Zhang等通过拍卖机制对云计算虚拟资源进行分配和定价,以提升资源提供商的社会福利[14]。
2 在线调度模型
在一个异构计算机系统中包含了m种不同的机器类型和n种不同类型的用户。用户i提交的任务包中的任务相互独立,数量为ai[4],执行这类任务能产生的收益为pi。ETC=(ETCij)是一个n×m维矩阵,ETCij是用户i的任务在机器j上执行所需的固定执行时间;APC=(APCij)同样是一个n×m维矩阵,其中APCij是用户i的任务在机器j上执行所需要的平均功率消耗(average power consumption,APC)[3]。xij表示用户i的任务分配给机器j执行的任务数。对于一个可行解x=(xij),机器j的负载可以定义为
(1)
所有机器的最大完工时间MS(x)为
(2)
相应的,n个用户的能量消耗为
(3)
用c表示每个单位能耗的成本,EAPM问题可以用非线性整数规划表示:
(4)
(5)
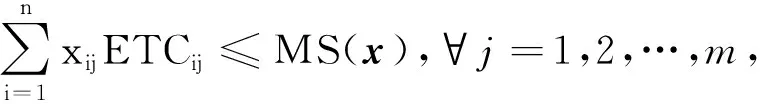
(6)
xij∈N,∀i,j。
(7)
目标函数(4)要最大化单位时间的收益,x是决策向量。约束(5)确保了每一个用户的每一个任务都被分配给某个机器。由于最大化单位时间收益的目标等价于最小化最大完工时间,约束(6)确保了MS(x)是所有机器的最大完工时间。
然而在实际场景中,当某个用户到达时就需要在机器不知道未到达用户的信息的情况下分配该用户的所有任务。因此,研究考虑任务包的EAPM问题的在线算法是很有必要的。该在线算法考虑用户i的任务会在用户i+1到达之前就被分配,i=1,2,…,n-1。但是,当用户i提交的任务数非常大时,不能逐个分配这些任务。因此,为考虑任务包的EAPM问题设计一个高效的在线算法是很有必要的。
3 在线算法
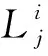
(8)
(9)
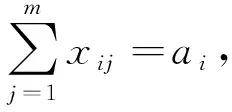
(10)
其中:
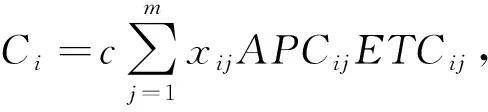
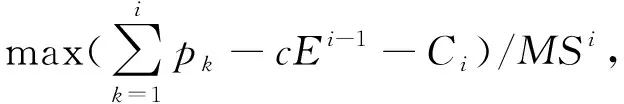
(11)
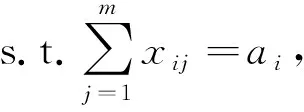
(12)
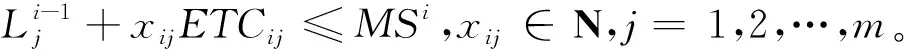
(13)
为了便于操作,将服务于用户i的任务的机器按照APCijETCij降序排序。不失一般性,假设
APCi1ETCi1≥APCi2ETCi2≥…≥APCimETCim,
(14)
我们的算法是基于引理1实现的。
引理1存在一个最优解,该最优解符合
其中:τ∈{1,2,…,m}。
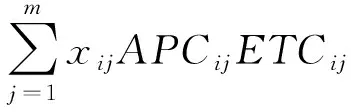
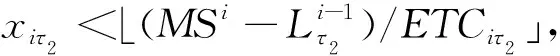
(15)
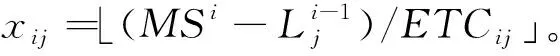
因此,该引理成立。
对于每个τ=1,2,…,m,只需要考虑部分的决策变量xij(j=τ,…,m)。此时想要得到用户i到达时的所有xij值以及MSi的值,通过计算可得预期结果:
(16)
式(16)共有m-τ+2个等式和m-τ+2个未知数,未知数为MSi和xij(j=τ,…,m)。因此,在多项式时间内对式(16)进行求解。对于每一个τ=1,2,…,m,得到一组xij的值。比较这m组可行解的目标值,便能得到当前的最优调度。将「xij⎤个用户i的任务分配给机器j,直到所有任务都被分配。
算法1在线算法
输入:m,n,ETC,APC以及用户到达序列。
输出:x。
1) fori=1,2,…,n
2) 重索引下标使得APCi1ETCi1≥…≥APCimETCim
3) forτ=1,2,…,m
5) 比较这m个解,找到使得公式(11)的值最大的xij
6) forj=1,2,…,m
7) 将「xij⎤个用户i的任务分配给机器j,直到所有任务都被分配
8) 更新机器j对应的Lj
接下来计算在线算法的时间复杂度。该算法中最主要耗费时间的是步骤4)中的解线性方程组。通过矩阵运算来对该方程组进行求解,花费的时间为(m-τ+2)3。对于每个到达用户,需要求解m个线性方程组,共有n个用户到达。因此,此算法的时间复杂度为O(nm4)。
4 实验评估
4.1 实验环境
为了进行对比,除了本文提出的在线方法(Online),我们还使用了贪心算法(Greedy)和平均分配算法(Average)来解决EAPM问题。Greedy算法将会在一个用户到达时,将该用户的整个任务包分配给能使ETC·APC值最小的那台机器,而Average将会把该用户的整包任务平均分配给每台机器。使用C++编程语言实现上述算法,并在以下硬件配置环境中进行了实验:CPU为Intel i7-10700,8核16线程2.9 GHz,16 GB内存及1 TB硬盘。实验的部分数据源于Tarplee在OpenBenchmark基础上进行了扩充的数据集,共有包含9种机器类型与30种任务类型[15]。
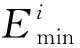
4.2 不同γ值对系统的影响
本实验是在上述9种机器类型和30种任务类型的基准上进行的。考虑30个用户按任意顺序提交类型各不相同的任务包,用户i的任务包中的任务数ai∈[200,1 000]。随着γ的变化,三种方法得到的目标值(式(4))变化如表1所示。为了减小随机性带来的影响,每次γ取值后重复100次实验并将结果取平均值,结果见表1。从表1可以看到本文提出的Online方法在所有情况下都优于另外两种方法。当γ较小时,Online方法与Greedy方法得到的目标值差距并不大,但当γ逐渐增大后Online方法便体现了其优越性。Average方法与另外两种方法得到的目标值有着较大差距。它虽然能使得系统的最大完工时间最小,但是由于并未考虑成本的原因,会使得最终的目标值变得很差。
4.3 不同用户数对系统的影响
本实验研究了用户数(n)从30逐渐增长到2 000时对系统最终目标值的影响。为了更全面地评估n的增长带来的影响,取γ=1.2、1.3和1.5进行对比。用户i提交的任务包中的任务数ai∈[200,1 000]。
从图1中可以看到当用户数较小时,Online方法得到的目标值更大,当用户数不断增加,Online方法与Greedy方法得到的目标值几乎变得相等。这是由于当n变得足够大时,总的任务数也会增加,这会使得两种方法给出的调度方案产生的最大完工时间逐渐靠近最优调度所产生的最大完工时间。
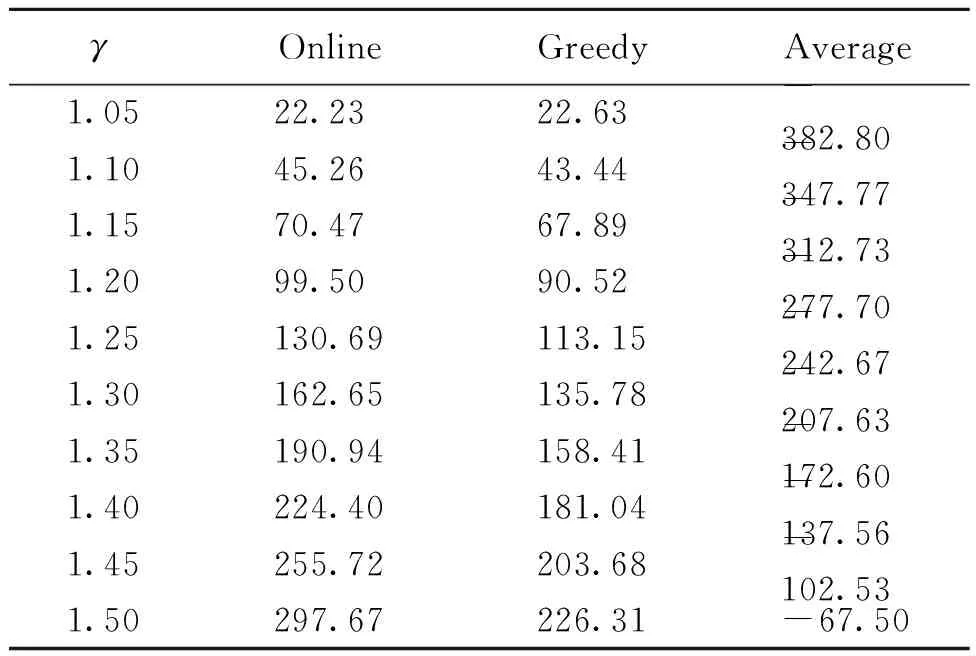
表1 不同γ值对目标值的影响Table 1 The object value was effected by different γ values
从图2可以看出三种方法的执行时间都在随着用户数的增加而增加。虽然Online方法的执行时间最长,但它得到的目标值也是最大的,即使在n=2 000时其执行时间也是ms级的。
4.4 用户到达顺序对系统的影响
在实际场景中,用户到达后所提交的任务数是无法预知的。为了评估用户到达顺序对系统的影响,令用户数n=30,类型为随机。如果用户i提交的任务包中的任务数ai>500,则为大任务包;若用户i提交的任务包中的任务数ai<200,则为小任务包。对比四种到达顺序对应的目标值,“BaS”为前一半的用户提交大任务包,后一半用户提交小任务包;“SaB”为前一半的用户提交小任务包,后一半用户提交大任务包;“Rand”为提交大任务包与小任务包的用户随机到达;“Equal”为所有用户提交的任务包任务数相同,为400。
从图3可以看到,在所有情况下Online方法都能得到最好的目标值结果。此外,用户到达的顺序并未对目标值造成明显的影响,只有当SaB情形时Online方法与Greedy得到的目标值会稍微降低。这是由于先将小任务包分配之后,为了不引起最大完工时间的快速增长,大包任务到达时有较小可能被分配给成本更大的机器进行执行。
5 总结
我们提出的Online的方法,通过新颖的方法构造线性方程组得到最终的分配结果,其执行时间依赖用户数以及机器种类数,并通过实验证明此方法能得到令人满意的结果。

图1 三种方法的目标值随着n增长的变化Figure 1 Objective values of three methods with varying n
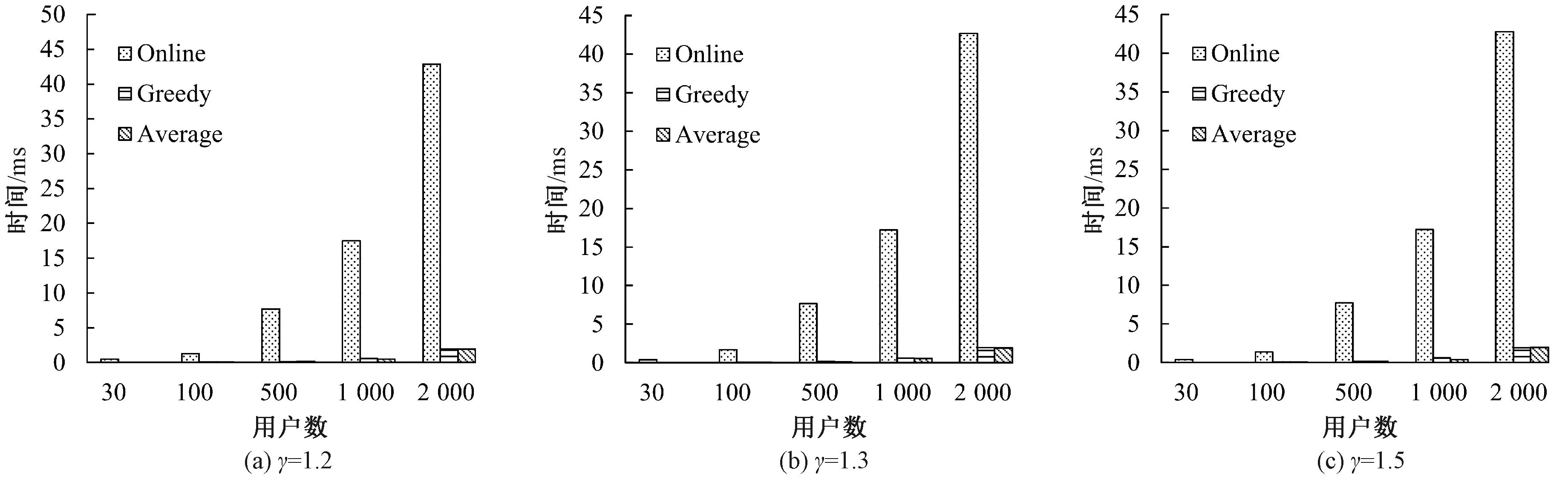
图2 三种方法的执行时间随着n增长的变化Figure 2 Execution time of three methods with varying n
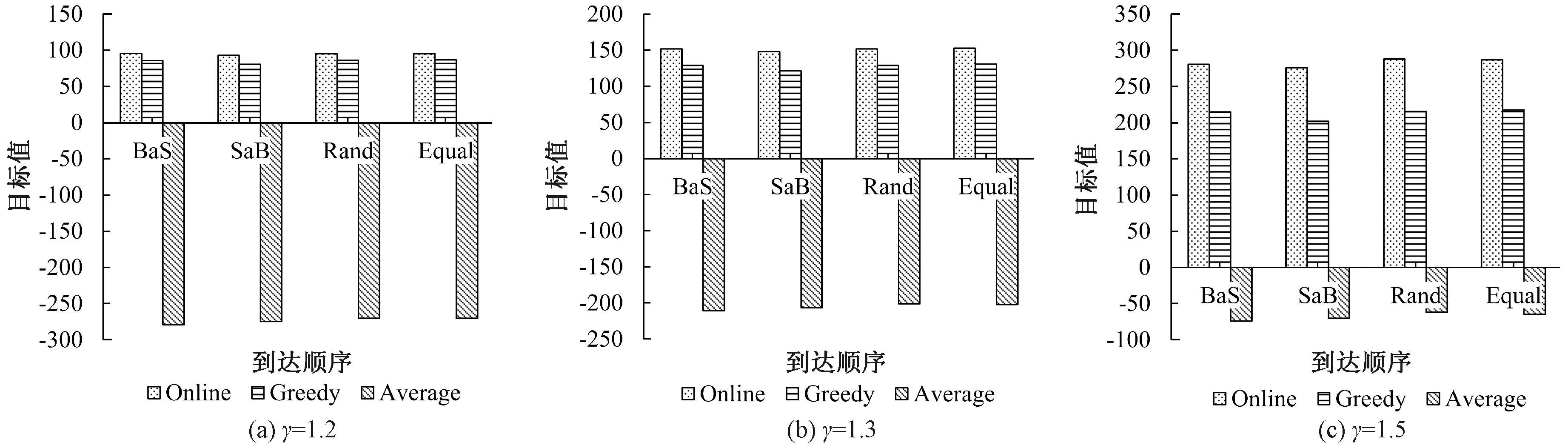
图3 不同用户到达顺序对目标值的影响Figure 3 The impact of different user arrival sequences on the objective value
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
电子产品世界(2021年5期)2021-02-09
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
经济技术协作信息(2018年30期)2018-11-22
电影(2018年8期)2018-09-21
浙江中西医结合杂志(2013年4期)2013-11-08
