
基于Transformer的陶瓷轴承表面缺陷检测方法*
2024-03-01 00:38胡荣华王丽艳李新然刘则通
组合机床与自动化加工技术 2024年2期
安 冬,胡荣华,王丽艳,邵 萌,李新然,刘则通
(沈阳建筑大学机械工程学院,沈阳 110168)
0 引言
Si3N4轴承滚子具有硬度高、热膨胀系数低、自润滑等优良性能。广泛应用于军事、航空航天等领域的关键动力设备[1]。Si3N4轴承滚子易碎,在生产过程中容易产生缺陷,如划痕和凹坑。随着基于人工智能技术的缺陷检测系统的大规模应用[2],深度学习方法在缺陷检测任务上取得了较为高效准确的检测精度[3]。但由于轴承滚子表面曲率与检测设备限制,当轴承滚珠尺寸较小时往往会导致表面缺陷特征模糊不清,从而影响检测精度。因此,从低分辨率图像恢复高分辨率表面图像,对提高缺陷检测精度具有重要意义。
图像超分辨率是旨在从单幅低分辨率(low resolution,LR)输入图像生成高分辨率(high resolution,HR)图像的基本任务[4]。最近的研究中,基于卷积神经网络网络(convolutional neural network,CNN)的超分辨率方法的效果尤其突出[5]。但CNN单纯使用滑动卷积窗口作为特征提取方式,单一窗口的感受野有限,只注重提取局部信息,而忽略特征之间的关系,既全局信息[6]。在实际的工业生产环境中,由于缺陷样本的出现伴随着随机性,且同一缺陷类型的缺陷尺度大小并不一致。CNN有限的感受野将不可避免地影响全局特征结构的恢复,导致重建特征产生模糊效果[7]。
DOSOVITSKIY等[8]开创性地提出了一种以编码器和解码器为主要网络结构的深度学习模型,并将其命名为ViT(Vision Transformer)。YANG等[9]最早将Transformer结构引入超分辨率任务中,提出了一种针对图像纹理恢复的超分辨率方法。LU等[10]发现,相比于CNN网络,ViT拥有更加优秀的上下文信息建模能力,并提出了一种可以捕获长距离上下文相关性的神经网络。
本文提出了一种结合全局自注意力模块与残差学习函数的残差ViT超分辨率模型。具体来说,受残差学习思想的启发,本文提出了一种集合CBAM模块[11]的局部自注意力模块改善Transformer对边缘特征的提取能力。同时使用残差学习策略改善网络模型对边缘特征的重建精度,并改进了残差学习函数以提高重建精度。
1 相关理论
1.1 残差学习

LRi=I(D(HRi))∈H×W
(1)
式中:D(·)是下采样算子,I(·)是具有相同比例因子的相应插值算子。
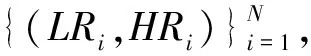
(2)
在最近的研究,残差学习方法相比于其他方法表现出了更好的优化特性,并且可以通过端到端的信息传递大大增加在深度网络中的准确性。如式(3)~式(5)所示,对于双三次插值方法,从插值的LR图像到图像的映射接近于一个相同的映射,特别是当D(·)和I(·)的比例系数较小时。因此,本文所提出模型,设计为学习残差图像R,预测图像为SR。
R=HR-LR
(3)

(4)

(5)
1.2 Transformer
Transformer是一种新型神经网络结构,通过若干个带有自注意力模块的编码器与解码器的堆叠,神经网络可以像人类的视觉系统一样,在众多信息中将注意力集中在重要的目标上,将权重分配给关键信息,而忽略其他不重要的信息。ViT(vision transformer)首次将Transformer用于图像领域的网络模型。它仅使用了Transformer的编码器部分,通过将一系列经过位置编码后的图像子块作为网络输入,实现了图像分类任务。
ViT的自注意力机制使得它能够准确地捕获像素之间的长期相关性。且全局计算特征使得它能够很好地对远程上下文信息进行建模。虽然ViT在提取图像的全局表示方面有很大优势,但仅依赖图像级的自注意机制仍然会导致局部细粒度细节的丢失。因此,如何有效地结合图像的全局信息和局部特征,对于高质量的图像重建非常重要[12]。
2 改进超分辨率ViT网络
本文将ViT网络引入图像超分辨率任务中,提出了一种超分辨率ViT网络,在传统ViT网络的基础上,加强网络表面细节特征提取能力,设计了一种增强局部特征注意力的局部自注意力模块,网络结构如图1所示。

图1 超分辨率ViT网络结构
2.1 基于CBAM的特征提取模块
CBAM是一个轻量级通用模块,如图2所示。CBAM模块由通道注意模块(channel attention module,CAM)和空间注意模块(spatial attention module,SAM)组成,可以分别学习要注意的语义信息和位置信息,使神经网络更加关注目标区域,抑制无关信息,提高缺陷边缘的重建精度。首先,对给定中间特征图m的输入,通过通道注意力模块获得通道注意力图MC(m)。然后将其与m相乘以获得通道细化特征m′。同样,以m′为输入,将空间注意力模块输出的空间注意力图MS(m′)乘以m′,得到最终细化输出m″。整个过程可以总结为:

图2 CBAM注意力模块
m′=MC(m)⊗m
(6)
m″=MC(m′)⊗m′
(7)
2.2 L2多头自注意力模块
在深度学习中,利普希茨连续条件[13]作为常用神经网络的约束,以控制网络输出相对于输入的变化程度。利普希茨约束可以赋予模型对抗扰动的稳健性,并保证泛化边界。利普希茨约束可以用于稳定训练,例如谱归一化。利普希茨常数L由下式给出:
(8)
然而,KIM等[14]的研究中发现,使用传统点积多头自注意力模块的利普希茨常数可以是无界的,从而导致网络梯度爆炸使训练失效。为改进这个问题,本文提出了一种L2多头自注意力模块(LMA),如式(9)所示。如式(10)所示,将点积运算替换为欧几里德距离,通过计算投影矩阵WQ和WK之间的矢量化L2距离消除梯度爆炸:
LMA(X)=concat[Attentionh(X)]W+b
(9)
(10)
最终本文提出的超分辨率编码器结构如图3所示。网络结构如式(11)~式(14),对于输入二维图像x∈H×W×C在输入时被分割为子块序列,单个图像子块记为xp∈N×(P2·C),其中N=(H×W)/p2为序列长度。
(11)
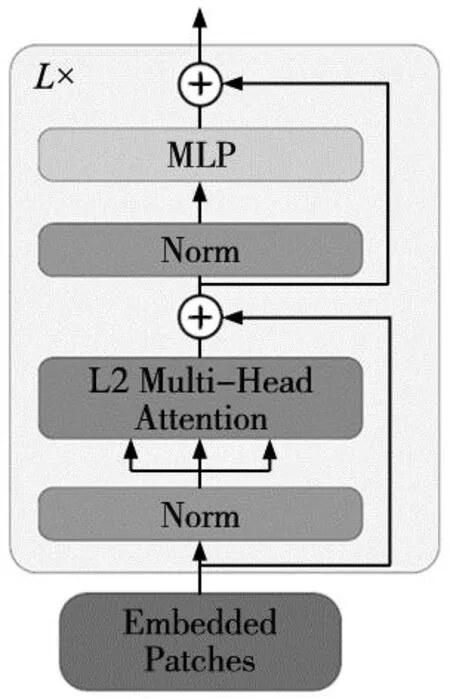
图3 局部多头自注意力模块

图4 Si3N4轴承滚动体表面缺陷
(12)
(13)
y=LN(zn)=[y1,…,yN]
(14)
式中:LMA(·)为本文提出的L2自注意力模块,LN为LayerNorm模块。
在超分辨率ViT网络中,本文使用逐像素MSE与MAE联合损失作为损失函数。MSE定义为误差平方的平均数,因此当误差大于1时,MSE损失会更加敏感,网络权重将以较快速度收敛。然而由于MSE中平方项的过度惩罚,MSE优化问题的解决方案通常缺乏高频内容,这会导致在生成图片中产生过于平滑的纹理。
为解决此问题,本文提出一种MSE与MAE联合损失函数。首先,通过具有较大学习率的MSE损失函数训练网络,然后通过具有较小学习率的 MAE损失函数对网络进行微调,这样可以在加速训练的同时略微提高准确率,联合损失函数标识为:
(15)
(16)
3 实验结果及分析
3.1 数据集建立
本节主要介绍了自制的Si3N4陶瓷滚珠表面缺陷数据集,并在此基础上进行了表面图像超分辨率实验。该数据集是由60个失效6204陶瓷滚珠组成。包含4种常见的表面缺陷类型:划痕、凹坑、磨损、雪花。使用Keyence VHX-1000超景深显微镜采集,如图5所示。数据集共1312张显微图像,包含1096张缺陷图像,分辨率为1600×1200。

图5 超景深显微镜
3.2 评价指标
本文通过客观评价与主观评价对比本文所提出方法与其余方法的重建精度。客观评价指标方面,本文通过广泛使用的峰值信噪比(PSNR)和结构相似度(SSIM)对重建图像进行客观评价。PSNR值越高,代表网络重建精度约高。PSNR如式(17)所示。SSIM从包括亮度、对比度和结构等多个指标衡量图像的相似度,SSIM值越接近1,说明两者之间的相似度越大。SSIM如式(18)所示。
(17)
式中:MAX(SR)为图像SR的最大像素值,一般取255。MSE(HR,SR)为真实图像HR与超分辨率图像SR的均方误差。
(18)

同时,相对平均光谱误差(RASE)[15]和视觉信息保真度(VIF)[16]也被用于对超分辨率ViT网络的重建精度进行定量分析。相对平均光谱误差(RASE)作为图像融合领域中常用的评价指标。它表征了该方法在所考虑的光谱带中的平均性能。VIF通过计算重建图像和参考图像之间的相互信息来预测主观图像质量。
3.3 实验设置
本节将介绍超分辨率ViT的训练策略与细节。在训练过程中,在每个时期随机裁剪16个大小为32×32的灰度图像块作为输入,超分辨缩放因子设置为×4。网络编码器数量设置为4,所有Transformer块的输入和输出特征维度为1024,MLP隐藏层维度为4096。模型使用Adam优化器训练,动量等于0.9。
本文采用残差学习策略,并对模型进行两阶段训练,总迭代次数设置为2×105次。前90%次迭代使用MSE损失函数训练网络,初始学习率设置为2×10-4,每5×104次迭代后学习率减半。后10%次迭代使用MAE损失函数微调网络权重,初始学习率设置为1×10-4,每2×103次迭代后学习率减半。训练过程中使用平移、旋转、拼接、缩放等数据增强手段,应用概率为0.8。
3.4 实验结果分析
在实验中,本文使用自建陶瓷球表面缺陷数据集中的10张图像进行测试。超分辨率ViT与近年来几种先进的超分辨率方法进行了比较。包括MESRGAN、SRCNN、SRGAN、VDSR。
定量分析实验结果如表1所示,显然超分辨率ViT在所有评价指标下都取得了最好的结果。在SSIM与PSNR上,与性能最接近的VDSR相比,本文方法的PSNR提高了1.11 dB,SSIM提高了0.008 7。这主要是由于本文在训练前段使用MSE损失函数训练网络,因此在峰值信噪比上得到了较为显著的提升。在VIF和RASE指标上,与Bicubic相比,本文方法的VIF提高0.029 4,RASE降低了0.023%。

表1 自建数据集上各算法的评价指标对比
如图6所示,实验还设置了超分辨率ViT与其他超分辨率模型在×4缩放因子下的直观视觉比较。如图所示,传统重建方法无法兼顾纹理信息与边缘信息。如SRGAN较好地处理了缺陷的纹理细节,但却错误地平滑了梯度变化明显的缺陷边缘,从而导致边缘模糊。相反,SRCNN对于高频信息更加敏感,重建图像获得了更加锐利的边缘特征,纹理细节却过于平滑,导致图像信息丢失。显然,本文提出的超分辨率ViT网络重建的图像包含更准确的纹理细节。并且在在边缘和线条特征中,本文提出的方法也获得了与表现最好方法相当的重建性能。这得益于增加的CBAM特征提取模块增强了对局部细节的感知,使模型可以从特定的区域学习更多信息。
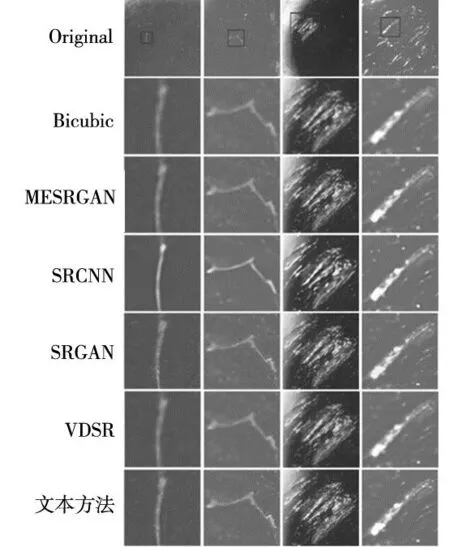
图6 在自建表面缺陷数据集上的对比实验
4 结论
为了实时、准确地检测氮化硅陶瓷滚动体的表面缺陷,本文提出了一种基于Transformer的超分辨率重建网络。主要方法包括以下几点:①针对Transformer对图像细节特征提取能力差的问题,在网络中插入混合域CBAM注意力模块,提高网络对图像纹理与细粒度特征提取能力。②改进传统ViT模型中的自注意力模块,提出了一种改进L2自注意力模块。③为获得真实可靠的实验数据集,本文使用超景深显微镜构建了氮化硅陶瓷球表面缺陷数据集。实验结果证明,本文提出算法在峰值信噪比与视觉信息保真度上均获得较大提升,有效解决了表面缺陷边缘模糊,提高后续检测精度。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学物理学报(2019年3期)2019-07-23
家庭影院技术(2018年9期)2018-11-02
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
第二课堂(课外活动版)(2016年2期)2016-10-21
