
基于语义分割和光流加速的动态场景ORB-SLAM算法
2024-03-01 04:04赵健,李虹
太原科技大学学报 2024年1期
赵 健,李 虹
(太原科技大学 电子信息工程学院,太原 030024)
同步定位与地图建立(simultaneous localization and mapping,SLAM)算法,是在未知环境下,利用传感器采集周围环境信息定位自身位置和位姿的同时增量式的构建地图,分为VSLAM和激光SLAM.由于相机相对激光传感器价格比较低、携带方便并且可以获得语义信息,所以VSLAM受到了广泛的关注。
如今,VSLAM算法发展飞快,其中最具有代表性的就是以提取特征点法为基础的ORB-SLAM[1](Orient FAST and Rotated BRIEF SLAM)系列和以直接法为基础的LSD-SLAM[2](Large Scale Direct monocular SLAM),但其在动态环境下的建图误差较大。
Fang[3]等利用改进的光流法与卡尔曼滤波相结合用于检测动态物体,Kunde[4]等利用改进的极平面约束方法检测运动物体,Lim[5]等利用稠密光流对前后景分离检测动态物体。如今因为深度学习在图片处理方面的优越性,很多人都将其加入算法中,大大提高了SLAM系统的性能。Zhong[6]等在SLAM系统中增加SSD语义检测模块用于检测动态物体,增加算法在动态环境的鲁棒性,Yu[7]等提出DS-SLAM,利用SegNet语义分割网络加RANSAC运动一致性检测剔除特征点。文献[8]利用YOLOv4网络对图片分割并剔除动态点,剔除策略将所有的动态框特征点剔除,但同时也会剔除大量的非动态点,从而导致系统性能下降。Bescos[9]等提出Dyna-SLAM,使用MASK R-CNN分割图片并且利用多视图几何方法剔除动点,由于网络本身的运行速率低下很难实现实时性。文献[10]使用DeepLabv3语义分割网络,再利用稠密光流约束计算每个点运动概率,但因为采用稠密光流剔除动态物体,计算时间偏长,运行实时性得不到保障。文献[11]利用Light Weight RefineNet轻量级网络用于语义分割,在对极约束的基础上增加深度约束用以检测动态特征点。文献[12]并没有使用原有传统的特征点提取,使用GCNv2网络提取特征点,使用ESPNetV2进行语义分割,并利用改进的运动一致性剔除动态点,其在一定程度上可以解决弱纹理情况下无法提取特征点的情况,但很有可能出现误匹配,导致系统精度下降。
本文针对动态场景下运行精度差、不满足实时性,做出了以下的工作:
在ORB-SLAM2系统增加语义分割线程,并针对高、中、低动态物体设定不同的运动检测阈值,实现了对动态物体上的特征点剔除又不至于剔除动态框内的静态物体,保留更多的静态点实现追踪。
增加LK光流法追踪,利用LK光流法追踪上一帧关键帧,加快了Tracking线程,节省了大量提取特征点的时间。
设计以下两个对比实验:
1.在TUM数据集上,将增加YOLOv5的ORB-SLAM2系统与ORB-SLAM2、DS-SLAM系统对比,通过结果评价增加YOLOv5的ORB-SLAM2系统的可行性。
2.在TUM数据集上,在增加YOLOv5的ORB-SLAM2系统上对比增加光流的结果和不增加光流的结果,查看其运行时间与RMSE误差的变化。
1 系统设计
在ORB-SLAM2中并没有专门的进行动态点的检测,在特征匹配后直接进行Tracking线程,虽然在追踪中利用RANSAC剔除了外点,但是对于存在大量动态点的时候,追踪效果会非常差。如今深度学习网络是重要的目标检测的方法,并且它可以对图片进行语义分割。这对SLAM算法会有一个极大的提升,但算法时实性也很重要,所以速度较慢的RCNN系列不予以考虑,在one-stage的深度学习模型中常用于SLAM的是YOLO[13]和SSD[14],最新的YOLOv5-s模型在速度非常快,并且YOLOv5推出了4种检测模型,灵活的配置参数,可得到不同的复杂度的模型,所以使用YOLOv5深度学习网络。
算法模型如图1所示,在进行特征点提取的同时对图片语义分割,为每个检测到的目标标注信息,包括检测框信息(x、y、w、h、label)与检测框类别(所属为高、中、低检测框)。系统判断是否需要插入关键帧,继而选择不同的追踪模式,如果插入关键帧,则利用ORB-SLAM2原本的Tracking追踪,如果不插入关键帧,利用LK光流追踪加快运行速度。在追踪成功后利用运动一致性算法剔除动态特征点。

图1 算法框架图
2 语义分割
对图片进行语义分割可以带来3点好处,如下:
一是语义信息可以在特征点提取时,对图片的前后背景分离,将一个一个点变为一块一块的检测物体;
二是语义信息可以在建图时,将标签带入地图中,便于其更好的理解周围的环境,更好的人机交互;
三是语义信息也可以在回环检测或者Bundle Adjustment中带来更多的优化条件,提升系统的精度。
YOLO模型是由Joseph Redmon在2015年提出,为深度学习网络带来了新方法,不同于当时的两阶段目标检测,例如RCNN、Fast-RCNN,YOLO是端到端的目标检测模型,大大缩小目标检测的运行时间。YOLOv5虽然不是原作者提出,但其性能十分突出,使用也相当广泛,模型有三个部分,分别为Backbone、Neck、Output.
Backbone:采用CSPDarknet,在不同图像细粒度上聚合并形成图像特征的卷积神经网络,在传入图像上提取大量的特征信息,网络不断地向下个阶段发送副本,在这方面类似ResNet,有效防止梯度消失问题。
Neck:采用PANet,一系列混合和组合图像特征的网络层,并将图像特征传递到预测层,生成特征金字塔对不同缩放对象检测,利用准确的低层特征自下而上的增强整个特征层次,缩短低层与顶层特征之间的信息路径。
Output:对图像特征进行预测,生成边界框和并预测类别,在特征图上应用锚定框得到最终输出。
YOLOv5模型结构图如图2所示。

图2 YOLOv5网络模型结构示意图

图3 对极约束

图4 检测框剔除特征点

图5 ORB-SLAM_YOLOv5的轨迹误差热力图和APE误差
YOLOv5原生模型可以识别80种类别,在TUM数据集上将“人”“车”等列为高运动物体,“椅子”“杯子”等列为中运动物体,“电视”“电脑“列为低运动物体,其级别越高那么运动的概率就越大。
3 特征点剔除策略
在ORB-SLAM2中Tracking线程读入图片,采用四叉数的方法均匀提取特征点用于后续追踪。在其内部采用RANSAC来剔除外点,这种方法如果在静态场景或者低动态场景可以有效的运行,但若在动态物体上存在大量的特征点,那么动态点也会被记入内点中,严重影响结果。
3.1 特征点剔除原理
利用基础矩阵的性质p2F21p1=0,判断特征点是否为动态点。并根据动态点数量阈值判断是否需要剔除动态点。
空间点P=[X,Y,Z]T,它投影在两个相机的归一化平面满足
x2=R21x1+t

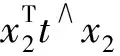
将x1=K-1p1,x2=K-1p2带入,得:

可以将F21看为Op1到极线l2的投影矩阵,所以Fp1可以得到l2在O2坐标系下的三个直线系数,将三个系数记为a,b,c.
由点到直线的距离公式
将p2记为[u2v21]T
得到匹配点p2距离极线l2的距离
若距离远大于0,认为其为动态特征点。
3.2 动态点数量阈值设定
考虑不同物体的潜在运动概率不同,高、中、低动态物体的动态点数量阈值应该不同。
若图片经过深度学习网络,检测出“人”这个所属类别,属于高运动物体,需判断这个物体目前是否处于运动状态,由于本身具有高运动概率,所以需要更严格的判断。设定物体上的特征点超过70%的点为静态点,那么认为其目前是静止的,换而言之,若30%以上的点为动态点,那么认为其是运动的。中运动物体的阈值为40%,低运动物体的阈值为50%.
如上图所示,可以看到人体上的特征点已经剔除,而在后面电脑上的特征点保留。说明算法在剔除动态点时可以对检测框中静态点分辨保留,增加特征点数量使算法更精确,在存在大量动态点时仍旧保持比较好的鲁棒性。
4 加入LK光流法
Tracking之后的线程都是针对关键帧运行,所以普通帧在后续线程中的作用较小,而在系统的运行过程中的特征点提取花费了大量的时间,导致系统运行时间过长。本文将普通帧的特征提取改为利用相邻帧的光流追踪,以加快系统的运行。
在Tracking线程中,经过以下四种判断标准决定是否插入关键帧,其满足(c1||c2||c3)&&c4
c1:系统长时间没有插入关键帧,默认经过30帧仍旧没插入关键帧;
c2:满足插入关键帧的最小间隔并且局部地图空闲,插入关键帧最小间隔默认设置为0,若局部地图空闲会返回一个标志位;
c3:在双目或RGBD情况下满足当前帧跟踪到的地图点数量和关键帧踪到的地图点数量相比比例少于0.25或者追踪到的近点数量较少远点数量较多;
c4:当前帧跟踪到的地图点数量和关键帧踪到的地图点数量相比比例少于0.75或者追踪到的近点数量较少远点数量较多并且匹配的内点数量大于15.
4.1 LK光流原理
LK光流法基于三个条件下使用:
(1)灰度不变性假设;(2)相邻空间一致性原则;(3)小运动原则。
灰度不变性假设,是一个很强的假设,也是光流法最基本的一个假设,在实际应用中往往会造成很大的问题,对光线变换敏感,但在本文中光流追踪关键帧,关键帧与普通帧之间的时间相隔非常小,可以保证灰度不变性,增加了LK光流法的可用性,也加快了算法运行。
灰度一致性公式:
I(x,y,t)=I(x+∂x,y+∂y,t+∂t)
对公式右侧泰勒展开得到:
I(x+∂x,y+∂y,t+∂t)=
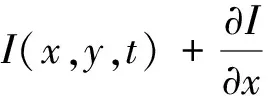
根据上面两式,可得到下式,

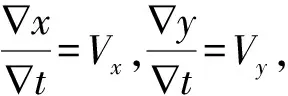

IxVx+IyVy=-It
取特征点3×3窗口内9个像素点联立,使其成为超定方程组,再求解Vx、Vy.
4.2 求解位姿
光流法得到的特征点,利用PnPRansac计算位姿。
在PnPRansac中,使用PnP算法求单应矩阵H的同时利用RANSAC算法剔除误匹配,以此来提高变换矩阵T的精度。其具体原理如下:
单应矩阵H是一个3×3满足尺度不变性的矩阵,所以它的自由度为8.匹配的两个点满足p1=H12p2.
上述式子,可以展开得到两个约束关系,如下
每一个匹配点可得到两个方程,所以最少需要4个匹配点来计算H.
再利用RANSAC算法剔除外点,通过迭代筛选内点,算法的精度会随着迭代的次数提升,设定迭代50次。
5 实验结果与分析
本次实验在TUM数据集进行两次对比,如下。
(1)由于算法在ORB-SLAM2系统上增加YOLOv5,所以命名为ORB-SLAM_YOLOv5,分别与ORB-SLAM2、DS-SLAM算法对比绝对轨迹误差,查看算法可行性。
(2)在ORB-SLAM_YOLOv5算法上增加LK算法,将其命名为ORB-SLAM_YOLOv5_with_LK,对比ORB-SLAM_YOLOv5与ORB-SLAM_YOLOv5_with_LK两算法的运行时间。
本次实验配置,CPU为英特尔i7-8565U,显卡为Nvidia GeForce MX230,内存为12GB,Ubuntu20.04系统下运行。
5.1 ORB-SLAM_YOLOv5对比
表1所示结果,ORB-SLAM_YOLOv5在TUM数据集(fr3_walking_xyz、fr3_walking_half、fr3_walking_rpy、fr3_walking_static、fr2_desk_with_people)上与DS-SLAM、ORB-SLAM2进行绝对误差对比。

表1 绝对轨迹误差ATE
表2所示结果,ORB-SLAM2、DS-SLAM分别与ORB-SLAM_YOLOv5提升率计算。
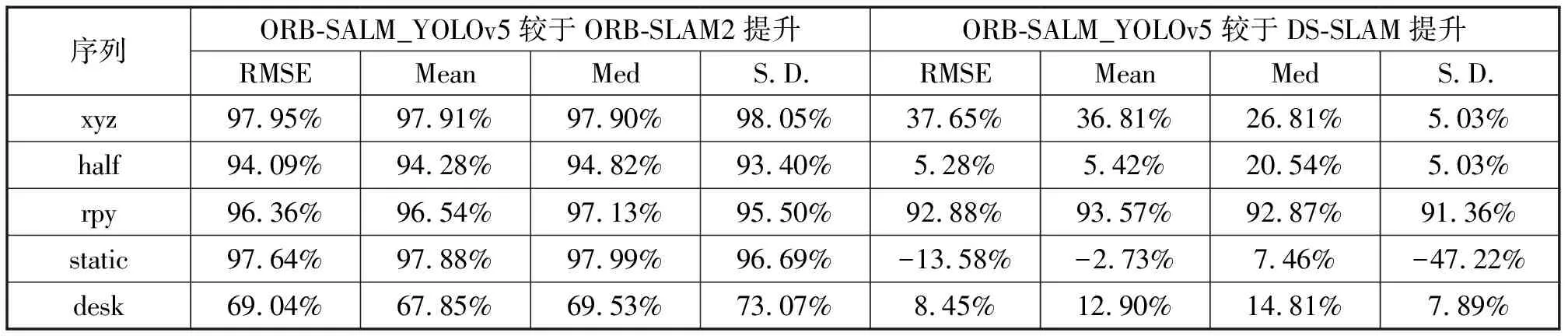
表2 绝对轨迹误差提升率
表1与表2中数据集序列分别简写为xyz、half、rpy、static、desk.RMSE为均方根误差,是重要的评分标准,Mean为均值,Med为中值数,S.D.为标准差。
表2提升率公式:
从上述表格中的DS-SLAM数据采用其论文中的数据,可以看出本算法对于ORB-SLAM2系统的提升比较大,除了在低运动场景下的fr2_desk_with_person数据集提升率为70%左右,其余数据集提升率均为95%左右。对于DS-SLAM,在高动态fr3_walking_rpy数据集上DS-SLAM误差达到0.444 2,不能满足使用要求,本文提出的算法误差为0.031 6,提升率在92.88%,本文算法在其它数据集上也表现良好,这与采用不同阈值的动态点剔除和使用YOLOv5模型有很大的关系,虽然在fr3_walking_static下误差与DS-SLAM有所提升,但其RMSE在提升后仍旧为0.009 2,依旧满足可用性。
总体来说ORB-SLAM_YOLOv5系统在TUM数据集上的效果整体要强于ORB-SLAM2和DS-SLAM.
5.2 增加LK光流实验结果
由于fr2_desk_with_people属于低动态场景并且ORB-SLAM2的效果已经很好了,没有动态场景下的代表性,所以在以下4个数据集对比ORB-SLAM_YOLOv5增加LK光流和不加LK光流的情况。
下述时间的计算公式:
Total Tracking Time是追踪线程总的运行时间,n是运行的图片的总数,Mean Tracking Time是每一张图片平均运行时间。
图6可以看出增加LK光流后运行时间均有减少,而RMSE则有升高有降低,基本平稳,在误差变动不大的情况下,大大的缩少了时间,例如,fr3_walking_static数据集有910张图片,每一张图片缩少0.017 3 s,总体缩小时间在15.743 s,大大缩小了运行时间。由于LK光流只是加在在关键帧之间的普通帧,若一个数据集频繁的插入关键帧,那么本算法减少的时间并没有那么可观,所以对于关键帧插入的条件要求较高,需要在不影响误差的情况下,加快运行速度。从以上4个数据集中可以看出误差变化并不大,甚至在fr3_walking_rpy与fr3_walking_static还略有下降,说明了增加LK算法的可取性。
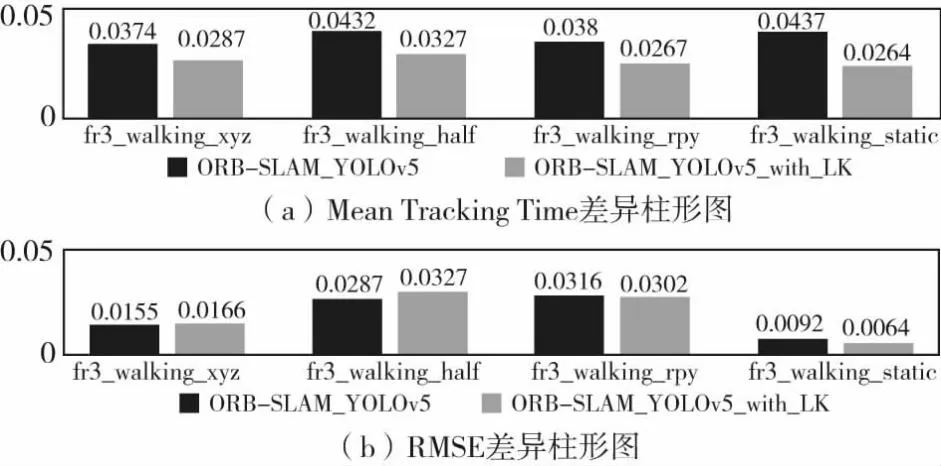
图6 增加LK光流后的误差与时间对比
6 结论
为了增加在高动态环境中SLAM系统的鲁棒性,本文在ORB-SLAM2系统的基础上增加了语义分割模型与LK光流,语义信息将图片中的点与点的关系变为检测框与检测框的关系,利用对极约束的运动一致性检测剔除动态框的特征点,保留静态点。在关键帧与关键帧之间使用LK光流追踪普通帧,省去提取特征点的时间,大大的加快运行速度。LK光流追踪中使用RansacPnP计算位姿,误差与不加光流的情况保持平稳。本文在TUM数据集上对算法验证,在高动态场景数据集下与ORB-SLAM2对比普遍优化在90%以上,与DS-SLAM对比,在fr2_walking_rpy数据集下优化90%以上。
但是算法依旧有不足,深度学习网络在标注与训练时会花费大量时间,时间效率不能与传统方法相比,另外由于检测框采用矩形,在剔除特征点时会剔除过多特征点,之后可以采用显著性区域设置掩码图以减少特征点剔除。在后续的研究中考虑增加IMU传感器,使其在无纹理、光照条件差等情况下增加算法适用性与鲁棒性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
开放教育研究(2020年2期)2020-03-31
电光与控制(2018年10期)2018-10-13
大连理工大学学报(2017年4期)2017-08-07
现代语文(2016年21期)2016-05-25
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
西北工业大学学报(2015年3期)2015-12-14
大连民族大学学报(2015年2期)2015-02-27
中国铁道科学(2014年6期)2014-06-21
郑州大学学报(理学版)(2013年3期)2013-03-11
