
基于可分离残差网络的车辆图像语义分割算法
2024-03-01 04:04谭睿俊赵志诚谢新林张大珩
太原科技大学学报 2024年1期
谭睿俊,赵志诚,谢新林,张大珩
(1.太原科技大学 电子信息工程学院,太原 030024;2.先进控制与装备智能化山西省重点实验室,太原 030024)
图像语义分割在人脸识别、图像检索、物体检测等视觉任务中有着重要的作用[1-2],通过对图像进行分割,提取语义信息,从而进一步理解图像的内容,再以此为基础应用到实际生活中。然而,实现更高精度的图像语义分割仍存在很多的问题[3-4],深度学习能提取到传统方法提取不到的抽象特征,对复杂场景有很好的解析能力,因此结合深度学习解决复杂交通场景中语义分割问题具有现实的意义[5-6]。
2015年,由Jonathan Long等人提出以卷积神经网络(Convolutional Neural Network,CNN)[7]为基础的全卷积神经网络(Fully Convolutional Networks,FCN)[8],该网络利用VGG-16网络作为主网络,将网络的全连接层替换为卷积层,利用转置卷积进行上采样操作恢复特征图的尺寸,首次实现了端到端的图像像素级别的语义分割。但FCN网络利用一系列的卷积操作、池化操作对输入图像进行下采样操作,导致预测特征图的分辨率大大降低且分割边缘模糊。He等人于2016年提出残差学习网络架构,该网络主要由残差块堆叠而成的。残差学习网络架构的提出,可以解决由神经网络层数加深引起的梯度消失、梯度爆炸等问题[9-11]。
基于此,本文在全卷积FCN深度神经网络模型的基础上,提出了一种基于可分离卷积残差网络、融合深层跳跃连接的车辆图像语义分割方法。首先利用一系列的可分离卷积残差网络块取代FCN网络中的VGG-16网络,降低网络结构的复杂性,得到更高的网络分割精度;其次,融合更深层次的跳跃连接将深层的语义特征信息与浅层的细节特征信息相结合,最后采用网络分支丢弃的训练方法对网络进行训练,实现更高精度的车辆语义分割。该方法在下采样阶段提高了网络特征提取的能力,在上采样阶段加强了不同特征信息的融合,产生更准确分割结果。
1 Resnet残差网络块
为解决由网络深度引起的梯度消失、梯度爆炸问题,本文引入了残差学习(Residual Learning).深度残差网络由一系列的残差块构建而成的,将传统神经网络的学习过程视作一个恒等映射(Identity Mapping)的过程,将原输出函数H(x)=x映射到函数H(x)=F(x)+x,其中x为输入,F(x)为原函数的输出,H(x)为映射函数的输出。残差网络结构通过残差学习,把一个恒等映射的过程转化为拟合残差函数的过程,最终的拟合结果是使残差F(x)趋向于0.
深度残差网络可直接将输入参数连接到输出位置,有效地减少网络的参数计算量,同时缓解了梯度消失等问题,具体的残差块结构如图1所示。

图1 残差网络块
2 可分离卷积残差网络
可分离卷积包括空间可分离卷积(Spatially Separable Convolutions)和深度可分离卷积(depthwise separable convolution).其中,空间可分离卷积就是对高度、宽度两个维度进行分离,即将n*n的卷积分为1*n与n*1两部分。可分离卷积的具体结构如图2所示,原卷积方法通过对输入图像进行3*3的卷积操作,利用可分离卷积将原卷积过程分为两步,首先对输入图像进行一个1*3的卷积操作,在其基础上再进行3*1的卷积操作。利用可分离卷积可以降低整体网络结构的复杂性,提高网络的整体运行速度。本文提出的可分离卷积残差网络块,通过利用可分离卷积1*3与3*1卷积层取代原残差块的3*3卷积层,具体的网络结构如图3所示。
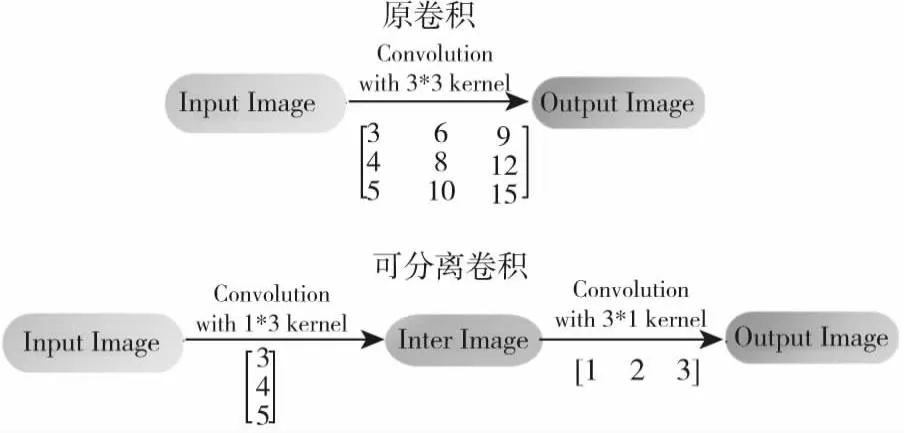
图2 可分离卷积结构
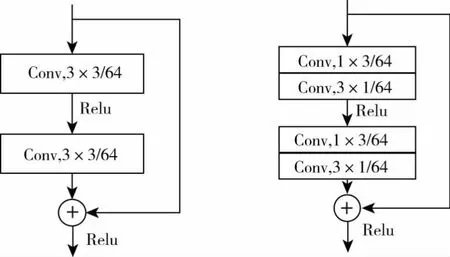
图3 可分离残差网络块
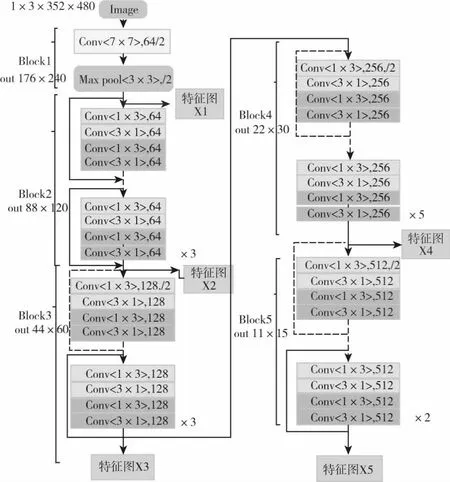
图4 可分离残差下采样网络
3 融合跳跃连接的可分离卷积残差网络
跳跃连接能够将深层的语义特征信息与浅层的细节特征信息相融合,实现更高精度的分割结果,考虑到原FCN网络通过一系列的卷积与池化操作进行特征提取,在提取过程中,底层网络易丢失部分细节信息,导致整体分割中感知细节部分的能力大大减弱,于是在Layer1块开始进行特征融合。目的在于弥补部分细节信息丢失对分割精度的影响,同时提高了网络对细节部分的感知能力。
融合跳跃连接的可分离卷积残差网络,其中可分离卷积残差网络用于图像的特征提取,该网络输入大小为352×480的三维数组,第一个Layer1卷积块为单独的一个卷积层操作,由64个大小为7×7,步长S为2的卷积核卷积,输出的特征图尺寸为原输入的1/2,大小为176×240,卷积之后进行批量归一化(BatchNormalization)处理以及Relu函数激活以及最大池化下采样操作,池化窗口为3×3,步长为2,接着是基于可分离卷积残差网络块的卷积操作,可分离卷积残差模块包括Conv x_1[1×3]、Conv x_2[3×1],Conv x_3[1×3],Conv x_4[1×3]四个可分离卷积层以及残差网络的跳跃连接结构。其中Layer2包括3个可分离卷积残差块,输出的特征图尺寸为原输入的1/4,Layer3包括8个可分离卷积残差块,输出的特征图尺寸为原输入的1/8,Layer4包括36个可分离卷积残差块,输出的特征图尺寸为原输入的1/16,Layer5包括3个可分离卷积残差块,经过多次卷积操作,Layer5输出的特征图大小为11×15,为原图大小的1/32,同时减低图像的分辨率。
为了使输出的图像与原图像尺寸大小相同,本文利用跳跃连接的方法,将Layer5输出的特征图X5进行2倍反卷积操作,将其大小恢复至22×30,与Layer4输出的特征图X4进行叠加,再对其进行2倍反卷积操作,将其大小恢复至44×60,与Layer3输出的特征图X3进行叠加,再对其进行2倍反卷积操作,将其大小恢复88×120,与Layer2输出的特征图X2进行叠加,再进行2倍反卷积操作,将图像恢复至176×240,与Layer1输出的特征图进行叠加,最后进行2倍反卷积操作,得到与输入相同尺寸的图像,通过多层跳跃连接,将高层的语义信息与浅层的特征信息相结合,减少了由上采样操作所带来的部分损失特征,提高了网络的分割精度。
4 实验
4.1 实验设计
针对本文提出的网络模型进行实验,本实验基于Pytorch 1.7.1学习框架,在Ubuntu 16.04系统下进行实验,使用的GPU为GeForce RTX 2080 Ti,Python版本为3.8,具体实验环境配置如表1所示。

表1 实验环境配置
为验证本文改进网络的有效性,在交通场景数据集Camvid上进行了训练以及测试,Camvid数据集,是目前常用的交通场景数据集之一。其中主要包括701张的逐像素语义分割的图像、高分辨率的彩色视频图像等内容,原数据库提供了32个类别语义标签,将每个像素点与每类语义分类一一对应,本实验选取其中的车辆、道路以及背景3类作为本实验的分割类别,该数据集主要包括701张图片,421张训练图像,168张测试图像,112张验证图像,其中标签由每个像素标记类别的类分割。
在实验中,对训练的图像进行预处理操作,原图像的尺寸为720×960,考虑到GPU硬件原因,对其进行中心裁剪,缩小为352×480,为了解决优化问题,采用随机梯度下降法SGD进行优化,将训练批次Batchsize设置为4,初始学习率设置为0.000 1,每经过10次迭代后,对应的学习率减半。
在图像语义分割中,通常采用像素的平均交并比(Mean intersection over union,Miou)、平均像素准确率(Mean Pixel Accuracy,MPA)、像素准确率(Pixel Accuracy,PA)作为图像语义分割结果的评价指标。其中,Miou是度量准确率的常用指标;PA是正确分类的像素点与像素点总和的比值;MPA是对像素准确率的改进。具体公式见式(1)、式(2)、式(3).
(1)
(2)
(3)
式中:k为图像的总类别数(不包括背景类);Pii为真像素类别为i被预测为像素为i的数量,被对分成类别i的像素数量;Pij为真实像素类别为i被预测为像素为j的数量,被错分成类别j的像素数量。
4.2 实验结果分析
为了得到车辆分割较好结果的网络,本文进行了不同深度的可分离卷积残差特征提取网络的替换、不同的特征融合方法以及训练参数相关的实验,具体的实验结果如下:
(1)利用可分离卷积残差网络替换原FCN的VGG特征提取网络,得到如下测试结果,具体如表2所示,从表2可以看出,相比于FCN网络,本文所提出的改进网络在PA、Miou、MPA上分别提升了2.4%、7.4%、1.4%.

表2 改进网络与FCN在Camvid上的结果对比
(2)验证不同深度的可分离卷积残差网络对测试结果的影响。通过改变可分离卷积残差块的个数,提升整体网络的深度,可以有效地提高网络的分割精度,其中SResnet_2352表示Layer2层到Layer5层分别由2个、3个、5个、2个可分离卷积残差块组成,以此类推SResnet_38363表示Layer2层到Layer5层分别由3个、8个、36个、3个可分离卷积残差块组成。
从表3可以看出,通过不断增加残差块的数目,网络的整体分割精度出现了提升,但考虑网络模型太深可能出现的过拟合现象以及显存有限的原因,本文选SResnet_38363网络作为图像语义分割的骨干特征提取网络。
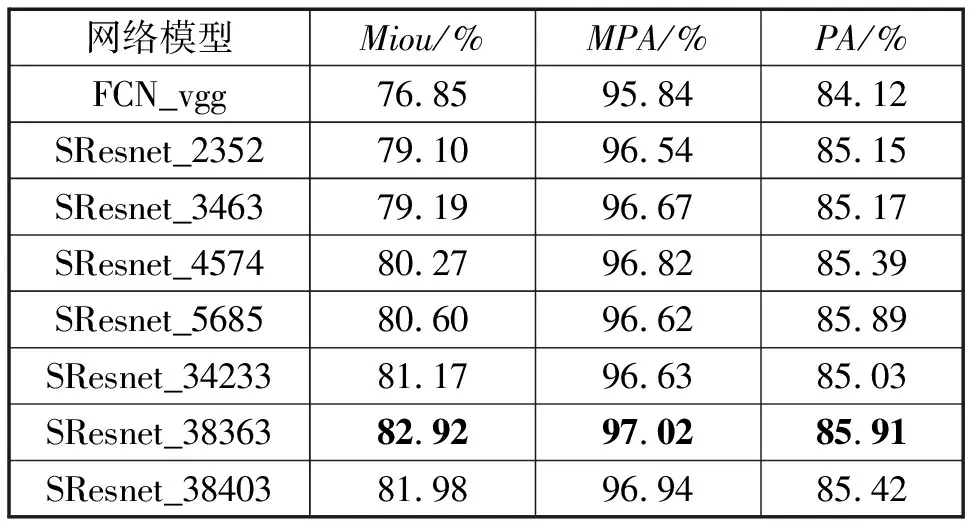
表3 不同深度的网络在Camvid上的结果对比
(3)在一定范围内,随着Batchsize的增加,网络的训练速度加快,当Batchsize增大到一定范围时,网络的最终收敛精度陷入不同的局部极值,导致网络的分割精度降低。不同Batchsize下的网络测试结果如表4所示,可以看出,随着批量大小的增加,对网络整体分割性能在取值为4时达到峰值,网络的Miou达到82.92%,MPA为97.02%,PA为85.91%,故将训练批次的大小设置为4.

表4 不同训练批次大小对应的测试结果
(4)本文首先对图像中各目标的边缘轮廓进行训练;其次,在此基础上对各目标的细节特征进行训练由于底层Layer1与Layer2块提取到更多的是图像的表面信息,而高层的Layer3、Layer4、Layer5块提取到更多的是图像的语义信息,所以先对输出融合特征图X2与X1进行训练,再对所有的特征图进行训练。
新训练方法更强调对小目标的细节特征训练,可有效地提高网络整体的分割精度。验证不同训练方法下的测试结果,具体如表5所示。从表5可以看出,新训练方法的平均交并比较原训练方法提高了1.33%.

表5 不同训练方法的测试结果对比
本文选取了部分测试图像的分割结果进行分析,如图5所示,为部分测试集的图像在数据集Camvid的分割预测结果。其中,第一列为测试集部分原始输入图像,第二列为测试集原图所对应的标签,第三列为FCN网络的分割预测结果图,第四列为改进网络SResnet输出的语义分割结果图。

图5 在数据集Camvid下的预测结果
由图5可以看出,本文所提出的改进方法较原FCN网络相比,可以得到更加准确、分割精度更高的小目标车辆,如第一张、第三张、第五张图像,改进网络的车辆整体分割内容更加完整,整体的识别区域更加清楚。第四张、第五张车辆的分割边缘轮廓更精细准确,说明改进方法明显地提升了车辆等小目标的识别精度,对车辆等小目标物体具有更好的识别准确性,整体上提高了网络的预测分割精度。
5 结束语
本文提出一种基于可分离卷积残差网络、融合更底层特征的跳跃连接的车辆场景图像语义分割方法,能够提高车辆等小尺度目标的感知能力。首先利用可分离卷积残差网络取代原FCN网络中的VGG-16网络对图像进行特征提取,以获得过更全面的图像细节特征信息,再在Layer1与Layer2融合跳跃连接实现图片像素级别的语义分割。通过Camvid数据集上的实验表明,本文所改进的网络模型提高了图像的特征提取能力,在上采样过程中综合地考虑了各像素之间的关系,融合了更底层的细节特征信息,可以有效地提高车辆等小目标物体的边缘分割精度。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
开放教育研究(2020年2期)2020-03-31
自动化学报(2019年6期)2019-07-23
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
现代语文(2016年21期)2016-05-25
河南科技(2015年8期)2015-03-11
大连民族大学学报(2015年2期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
