
面向工业过程的图像生成及其应用研究综述
2024-03-04 02:04郭海涛乔俊飞
自动化学报 2024年2期
汤 健 郭海涛 夏 恒 王 鼎 乔俊飞
工业物联网、大数据、人工智能、云计算等新一代信息技术的发展,使得工业过程能够在传统的控制与决策基础上融入视觉感知信息[1].目前,计算机视觉模型已能够依据工业图像建立运行工况识别模型、产品质量检测模型和难测参数量化模型[2-4],这些模型对复杂工业环境适应能力的强弱通常是决定其能否实际应用的关键[5].
基于深度学习(Deep learning,DL)的视觉感知模型已在诸多领域得到广泛应用[6-9],其具有以下优势: 1)能够自动学习特征;2)能够获得具有完备性和非冗余性、强于人工获取方式的特征;3)能够学习复杂问题的非线性可分“分界面”;4)具有通用的问题解决思路和技术框架.复杂工业过程中的图像存在可解释性差、干扰性强、标记成本高等问题,这导致大量数据难以有效使用[10],使得视觉感知模型在应用中存在识别精度低、鲁棒性差等现状[11].以城市固废焚烧(Municipal solid wastes incineration,MSWI) 过程[12]为例,存在的问题包括[13]:1)燃烧过程中固有的飞灰、高温等因素使得火焰图像清晰度差;2)在炉排前端和后端进行燃烧的极端异常火焰图像稀缺;3)物料组分的不可控性和控制参数的波动性导致火焰图像的可解释性差;4)火焰图像难以标记.因此,该领域对视觉信息的处理依然依靠运行专家,存在难以避免的主观性和随意性[14].可见,因存在异常图像稀缺、图像对比度低和噪声干扰大等问题,常用视觉模型难以适用于具有强污染、多噪声和图像类别不完备等特性的工业过程.显然,实际训练集的分布不符合期望全集分布已成为制约计算机视觉应用和发展的主要因素之一.
如何获取符合期望分布的训练图像集仍是一个开放性的难题.图像生成[15]是解决该难题的方法之一.目前,已有的相关研究包括: 文献[16-17]阐述玻尔兹曼机研究进展,包括亥姆霍兹机、深度玻尔兹曼机(Deep Boltzmann machines,DBM)和深度置信网络(Deep belief network,DBN)等;文献[18]梳理传统自编码器(Auto-encoder,AE)模型及其衍生变体模型的研究现状、分析其存在的问题与挑战和展望未来的发展趋势;文献[19-21]概述生成对抗网络(Generative adversarial networks,GAN)的基本思想、梳理相关理论与应用研究;文献[22]根据似然函数处理方法对深度生成模型进行分类,包括基于受限玻尔兹曼机(Restricted Boltzmann machines,RBM)、变分AE (Variational AE,VAE)的近似方法[23]、能够避免求极大似然过程的诸如GAN的隐式方法、对似然函数进行适当变形的流模型和自回归模型;文献[24]介绍基于去噪扩散概率模型(Denoising diffusion probabilistic models,DDPMs)[25-26]、噪声条件分数网络(Noise conditioned score networks,NCSNs)[27]和随机微分方程(Stochastic differential equations,SDEs)[28]3 种通用扩散模型框架,并讨论与其他深度生成模型的关系.但是,这些文献综述主要聚焦于图像生成在计算机领域的应用,其核心问题是如何更好地拟合训练集的概率密度分布.因工业过程具有强污染、多噪声和不确定等特性而使得图像生成更加复杂,其核心在于: 如何结合过程机理,借助小样本集“创造”出期望的图像集.因此,有必要结合工业过程的实际特性,针对性地对工业图像生成及其应用研究进行综述.
本文面向实际需求,对工业过程图像生成、生成图像评估与应用进行综述,主要贡献包括: 1)梳理面向工业过程的图像生成技术和工业领域潜在图像生成技术;2)结合图像生成领域的研究成果,面向实际工业过程需求,依据流程将现有算法从工业图像生成、生成图像评估和应用3 个方面进行综述;3)提出面向工业过程图像生成及其应用的未来研究方向与挑战.
1 面向工业过程的图像生成技术
1.1 图像生成的定义与分类
图像生成的目标函数如下
式中,G*表示最优生成模型,pG和pdata表示生成数据和真实数据的概率分布,Div(·) 表示散度.
由式(1)可知,图像生成的定义为: 寻找生成模型参数,使生成的数据与真实的数据概率分布的散度最小.本文给出如图1 所示的深度生成模型分类框架.
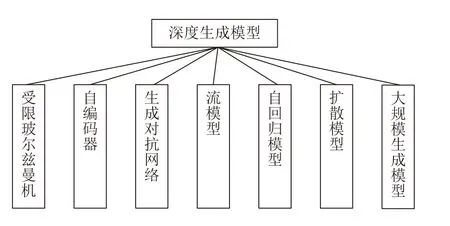
图1 深度生成模型分类Fig.1 Classification of deep generation model
由图1 可知,深度生成模型包括: 1)受限玻尔兹曼机[29]及以其为基础模块的深度置信网络[30]、深度玻尔兹曼机[31]等模型;2)自编码器及其改进模型;3)生成对抗网络[32]以及改进模型;4)以非线性独立分布估计(Non-linear independent components estimation,NICE)为基础的常规流(Normalizing flow)模型[33]及其改进模型;5)包括神经自回归密度估计(Neural autoregressive distribution estimation,NADE)[34]、像素循环神经网络(Pixel recurrent neural network,PixelRNN)[35]、掩码AE 分布估计(Masked AE for distribution estimation,MADE)[36]以及WaveNet[37]等在内的自回归模型;6)扩散模型以及其改进模型;7)以ChatGPT 和GPT-4 为代表的大规模生成模型.
在上述模型中,用于图像生成的GAN、AE、流模型和扩散模型的论文出版情况如图2~5 所示.

图2 GAN 模型论文出版情况Fig.2 Publication status of GAN model

图3 AE 模型论文出版情况Fig.3 Publication status of AE model

图4 流模型论文出版情况Fig.4 Publication status of flow-based model
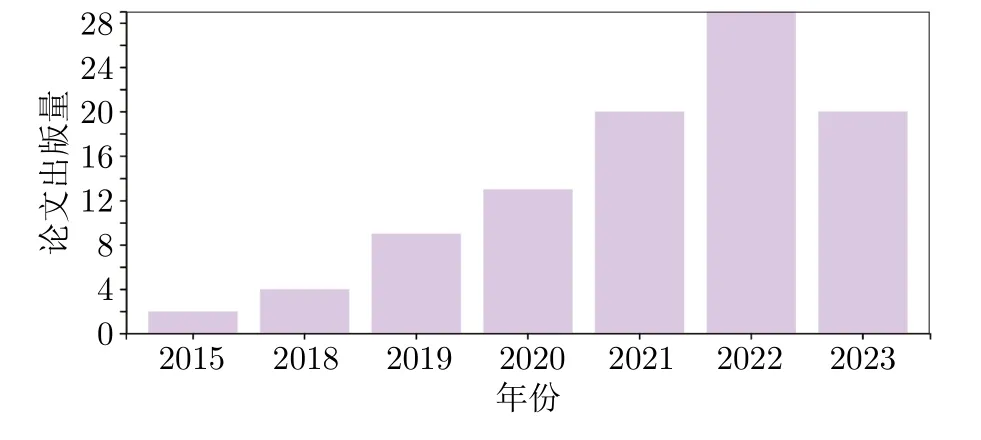
图5 扩散模型论文出版情况Fig.5 Publication status of diffusion model
1.2 面向工业过程的图像生成定义
面向工业过程的图像生成任务可表示为
式中,Gind*表示最优的生成模型,表示工业过程生成数据的概率分布,表示真实数据的概率分布.
1.3 面向工业过程的图像生成及应用流程
面向复杂工业过程的图像生成及其应用流程如图6 所示.
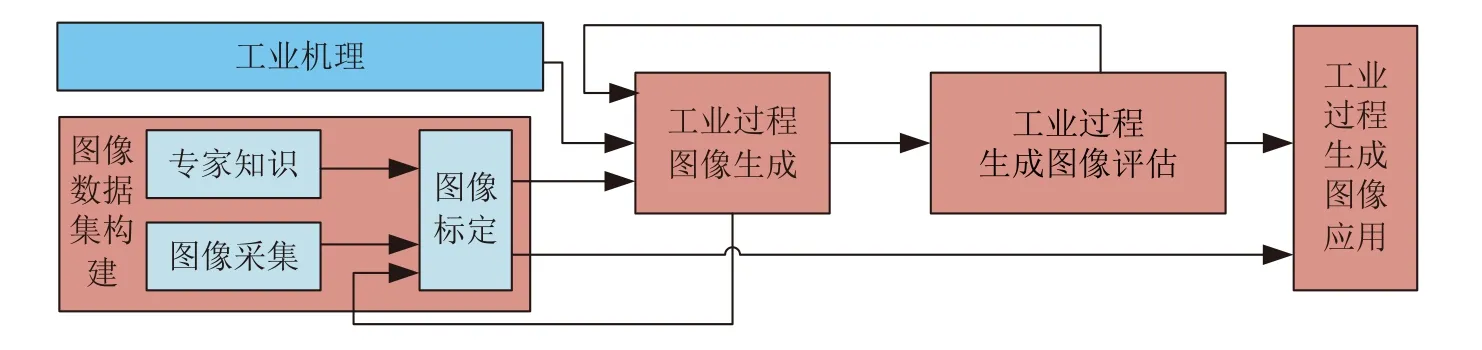
图6 面向工业过程的图像生成及应用流程Fig.6 Image generation and application process for industrial process
由图6 可知,具体流程为: 首先,构建图像数据集,主要包括图像采集和基于专家知识的图像标定;然后,针对真实图像数据存在的问题,结合工业机理构建图像生成模型;接着,定性或定量评估生成图像的质量和多样性并选择合格图像,若再次进行图像生成仍不满足要求,重新通过图像采集和图像标定构建图像数据集;最后,构建基于生成和真实图像的数据集以进行生成图像应用.
本文重点关注工业过程图像的生成模型构建、生成图像评估和应用等方面.
1.4 面向工业过程的生成图像评估框架
虽然生成模型,特别是GAN,得到了广泛的关注,但如何对所生成的图像进行评估和选择仍然是待解决的开放性问题.面向生成图像的评估模型架构[38]如图7 所示.

图7 对生成图像的评估架构Fig.7 Evaluation architecture for generated images
传统生成图像的评估框架为: 先将真实图像集和生成图像集进行特征提取,再对所提取的特征向量进行度量计算.该评估框架涉及多种不同的特征提取网络和度量准则.以真实图像集Xr、生成图像集Xg和特征提取器为输入,以度量准则FID (Fréchet inception distance)值为输出的评估过程为: 首先,加载特征提取器提取两个图像集的特征矩阵zr与zg;然后,计算特征矩阵的多元正态分布均值μr与μg以及协方差矩阵Covr与Covg;接着,计算矩阵的迹 Tr(·);最后,根据式(3)计算FID 值
这类算法旨在度量生成数据集与真实数据集之间的相似度.
1.5 面向工业过程的图像生成应用需求
目前,卷积神经网络(Convolutional neural network,CNN)是视觉领域的主要研究方向.例如,文献[39]结合CNN 和图像分割定位变压器内部热缺陷的故障;文献[40]改进CNN 以预测设备部件的坐标、方向角和类别类型;文献[41]在CNN 中引入局部聚集描述符向量以增加特征表示的鲁棒性和增强识别模型的精度.但是,以CNN 为代表的监督网络模型的准确率常取决于训练样本标签的质量与规模.
工业过程的图像采集设备长期处于强干扰环境中,这导致图像的获取和标定存在困难[14];此外,数据的不均衡分布也是工业过程中的常见问题[42-43].诸多研究表明,在数据分布不平衡的情况下,数据增强处理有助于提高模型性能[44-46].传统数据增强是通过几何变换(如平移、缩放和旋转)和通道变换合成图像[47],其局限性在于无法真实地创建新的样本,所生成的样本仍然受限于原始数据的范围和特征.图像生成技术采用GANs、VAEs 或DDPMs 等生成模型,能够更加逼真地生成新样本,结合工业领域特有的机理知识,理论上能够创造出更丰富、更贴近真实的数据样本,能够扩展数据的多样性和覆盖范围,进而能够在训练过程中更好地捕捉数据分布的细微特征以提升模型的泛化能力.
针对复杂工业过程中的图像存在可解释性差、干扰性强、标记成本高等问题,其图像生成方法可从以下角度进行分析研究: 1)样本分布不均问题,正常和异常数据分布存在严重偏差[48];2)样本多样性问题,极端异常的图像缺失;3)样本可解释性问题,特定图像在不同程度上与工业机理相关.
2 工业领域潜在图像生成相关技术
GAN、VAE、流模型、PixelRNN 和扩散模型等算法及其变体在工业领域的图像生成中均具有潜在应用前景.
2.1 GAN
GAN 由生成器G和判别器D组成,前者通过随机噪声z生成图像,后者判断输入图像为真的概率.具体而言,G与D是相互竞争的判别过程和欺骗过程,前者为D判别图像真假时的参数更新过程,后者为G企图欺骗D时通过D的损失更新G的过程.GAN 的目标函数如下
式中,V(D,G) 表示真实数据与生成数据的差异程度,下标 r 表示真实数据,pr和pz表示真实数据的概率分布和z服从的高斯分布.
为便于GAN 的数学描述,采用下标 g 表示生成数据的概率分布.假设真实数据和生成数据的概率分布pr和pg为定值,D可拟合任意函数.
首先,考虑任何给定G,求解最佳D,即D*.训练D时,固定G的参数,在 m axD V(D,G) 的过程中,D*表示如下
然后,假设每轮D均是最优的且G可拟合任意函数.此时,固定判别网络参数,更新生成网络参数,m inG V(D,G) 的结果如下
式中,DJS为JS (Jensen-Shannon)散度.由式(6)可得pg=pr为最优解,即生成器能够拟合真实数据的概率分布.
最后,G根据其学习到的概率分布生成符合真实数据概率分布的新样本.
GAN 利用判别器的特性避开了求解似然函数的复杂过程,这使得GAN 非常灵活且适用性强,其代表模型包括DCGAN、WGAN 和BigGAN 等.GAN 的变体模型如表1 所示.

表1 基于GAN 的变体Table 1 Variants based on GAN
2.2 VAE
VAE 由编码器和解码器组成,其核心理念是学习潜在的空间.理论上,空间中的每个点均对应着数据的一个潜在表示,进而可在空间中进行数据的插值、生成和探索.VAE 的简要过程为: 首先,编码器将输入数据映射到潜在空间中的概率分布,即将输入数据转换为潜在变量的均值μ和标准差σ以表征该分布;然后,采用重参数化技巧对该分布进行可微分采样以获得潜在变量;最后,解码器接收在潜在空间采样的潜在变量并将其映射回原始数据空间,进而生成一个与原始输入数据相似的样本.
VAE 采用变分下界作为其优化目标函数,如下
式中,Lrecon表示重构损失,其常采用均方差(Mean squared error,MSE)或交叉熵(Cross-entropy)作为度量准则以衡量生成样本与原始输入数据间的差异;设x为输入数据,为重构数据,则重构损失可表示为 M SE(x,) 或Cross-entropy (x,).
在式(7)中,Lreg表示正则化项,通常是通过最小化KL (Kullback-Leibler)散度DKL约束潜在变量分布与预定义先验分布间的相似性,进而使得潜在空间具有平滑性.设q(z|x) 是给定输入数据x时潜在变量z的后验分布,p(z) 是预定义的先验分布,则Lreg表示如下
式中,σi和μi分别表示编码器输出的第i个潜在变量的均值和标准差.
VAE 的训练过程旨在学习适当的潜在表示和解码器,进而使得样本能够在潜在空间中平滑地插值并进行生成,其代表模型包括重要性加权自编码器和辅助深度生成模型等.VAE 的变体类型如表2所示.
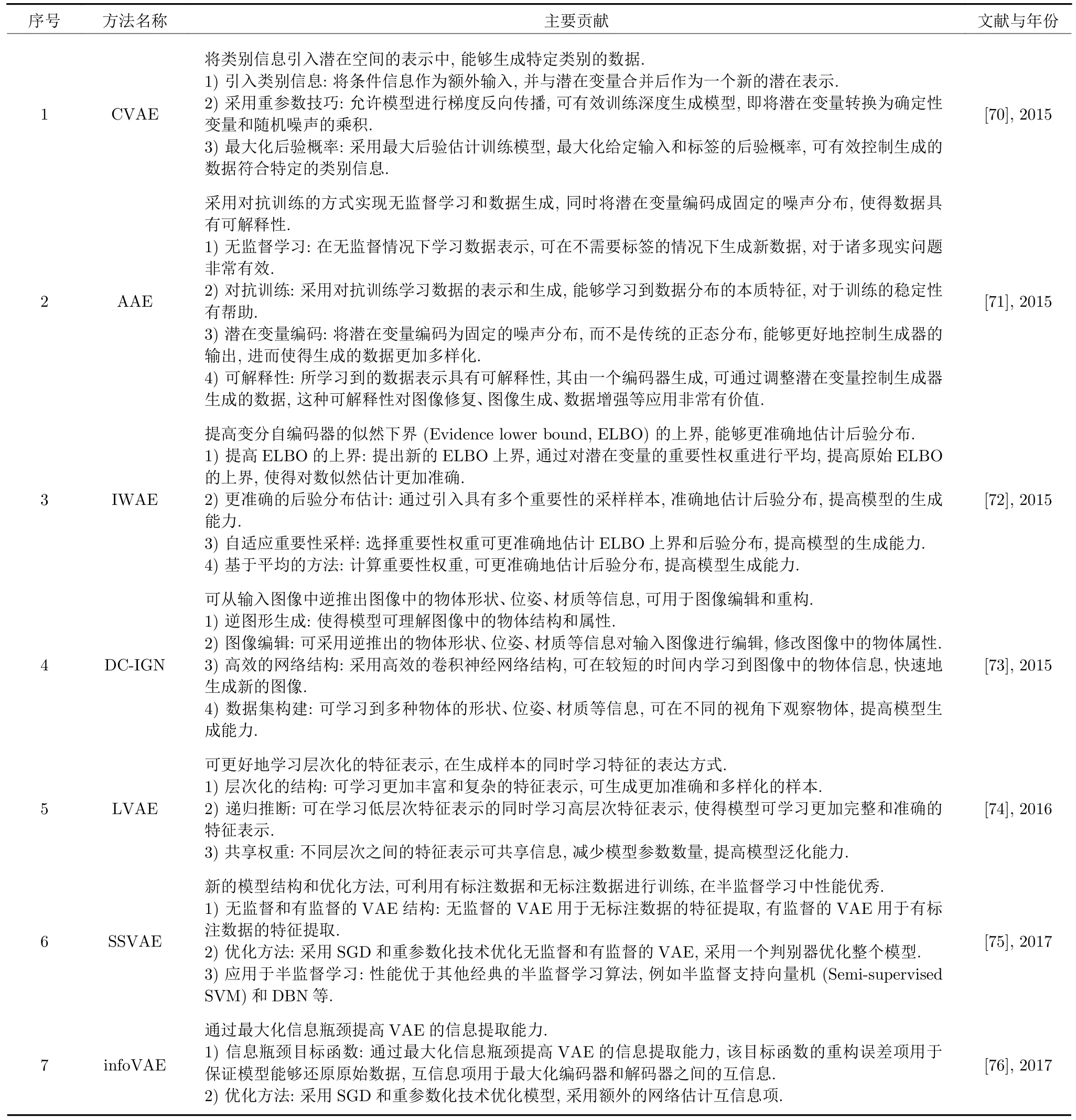
表2 基于VAE 的变体Table 2 Variants based on VAE
2.3 流模型
流模型通常由多个能够进行可逆变换的耦合层组成,其核心理念是通过逐层的可逆变换将简单的先验分布映射为复杂的数据分布,进而实现对数据分布的建模.耦合层由变换层(Transform layer)和标量变换层(Scalar transform layer)组成,前者对部分的潜在变量进行非线性变换,后者对另外部分的潜在变量进行可逆的线性变换,进而在保持模型可逆性的同时引入复杂的非线性.由于变换是可逆的,流模型可实现从数据空间到潜在空间的反向映射,因此其具有计算潜在变量和生成样本的能力.
流模型的训练目标是最大似然估计,即最大化训练数据在流模型下的概率.由于流模型结构的可逆性,可通过变量变换法计算样本的概率密度函数,其目标函数可表示为如下式所示的负对数似然(Negative log-likelihood,NLL)损失
式中,LFlow表示负对数似然损失,xi表示第i个样本,N表示输入样本的总数.根据变量变换法,p(xi)可表示为,zi表示xi的潜在变量,表示潜在变量与数据样本间的雅可比矩阵.式(9)可进一步展开,如下式所示
式中,第一项表示zi在模型先验分布下的负对数似然,通常假设zi服从多维高斯分布;第二项为雅可比行列式的负对数,用于考虑变换从潜在空间到数据空间的缩放.
在实际流模型的训练中,可采用SGD 等优化算法最小化负对数似然损失.
综上,流模型将真实数据分布通过转换函数映射到给定的简单分布,是一种采用可逆函数构造似然函数、直接优化模型参数和利用可逆结构的特性生成图像的精确模型,其代表模型是常规流模型、变分流模型和可逆残差网络.流模型类型如表3 所示.
2.4 PixelRNN
PixelRNN 采用循环神经网络(Recurrent neural network,RNN)建模像素间的条件概率分布生成图像,能够实现逐像素的生成,其关键是捕获了像素之间的横向和纵向依赖关系,后者能够通过循环神经网络或其他序列模型建模.在生成某个像素值时,PixelRNN 考虑了该像素的左边和上边的像素值以及已经生成的像素值.
PixelRNN 通常可采用交叉熵最小化负对数似然损失,其目标函数如下式所示
式中,qi表示第i个像素值,N表示像素的总数,P(qi|q1,q2,···,qi-1)表示在给定生成的像素值情况下预测当前像素值的条件概率.
由于每个像素的生成均依赖于已生成的像素,所以PixelRNN 的生成速度慢.PixelCNN 通过像素生成过程的并行化能够同时生成一个像素位置的所有通道值,进而提高了生成速度.
综上,PixelRNN 是将图片的像素作为循环神经网络的输入,在本质上是自回归神经网络在图片处理上的应用,其代表模型是Row LSTM 和Diagonal BiLSTM 等.PixelRNN 技术及其变体类型如表4 所示.

表4 PixelRNN 模型Table 4 PixelRNN model
2.5 扩散模型
扩散模型由逆流模型和生成模型组成,训练过程涉及逆扩散和正扩散阶段.其中,前者通过逆流模型将真实数据样本逐步转化为噪声样本,进而使转化后的噪声样本尽可能接近噪声分布;后者通过生成模型将噪声样本逐步转化为真实数据样本,进而使转化后的噪声样本逐步逼近真实数据分布.在生成过程中,从初始噪声样本开始,通过多次迭代正向扩散将噪声样本逐步转化为逼真的数据样本,其每个迭代步骤均涉及逆流模型和生成模型的操作.
在本质上,扩散模型的训练过程是通过最大似然估计获取生成数据的概率分布,如下式所示
式中,xt表示在时间步t时的数据样本,T表示总时间步数,p(xt|xt-1,···,x1) 表示在给定时间步的数据样本下预测当前时间步数据样本的条件概率分布.通常,扩散模型的目标函数会被分解为每个时间步的预测误差,进而保证可采用诸如均方差或交叉熵等标准的损失函数.
综上,扩散模型通过控制噪声信号的逐步变化生成数据样本,并且支持逆向过程和条件生成,能够产生高质量的样本且具有较高的灵活性和可解释性.代表性的扩散模型如表5 所示.

表5 扩散模型和Visual ChatGPT 大规模模型Table 5 Diffusion model and Visual ChatGPT large-scale model
2.6 Visual ChatGPT 大规模模型
将ChatGPT 和多个SOTA 视觉基础模型连接,能够实现在对话系统中理解和生成图片的Visual ChatGPT 大规模模型,其详细描述如表5 所示.
3 工业过程图像生成及其评估与应用研究现状
结合本文第1.3 节给出的流程,本节将从面向工业过程的图像生成、生成图像评估和生成图像应用共3 个方面进行研究现状的综述(如图8 所示),并展开叙述每个方向的子类.

图8 面向工业过程的图像生成及其应用研究现状结构图Fig.8 Structure diagram of the current research status of image generation and its application on industrial process
3.1 工业过程图像生成研究现状
本文从复杂工业过程图像生成存在问题的视角出发,将工业过程图像生成从面向样本分布不均、面向多样性不足和面向噪声干扰大等3 个方向进行综述.
3.1.1 面向样本分布不均的图像生成现状
针对工业过程样本分布不均的问题,可采用生成器拟合小样本分布以扩充样本数据的策略,主要包括VAE、GAN 和混合VAE 与GAN 模型等策略.
1) VAE 模型: 通过将原始数据映射至低维表示空间进而有效地捕捉数据特征.由于在低维空间中表征的数据分布可能会更加的均匀,VAE 有助于减少样本分布不均所导致的问题,从而有效地提高生成器的性能.相关的研究包括: 文献[96]采用卷积编码器(Convolution encoder,CE)进行数据增强和文献[97]采用卷积自编码器(Convolution autoencoder,CAE)进行数据扩充.
2) GAN 模型: 通过改进GAN 模型的策略控制样本数量的均衡,进而实现更好的数据生成效果.相关研究如下文所示.
文献[98]提出了自适应平衡生成网络(Adaptive balance GAN,AdaBalGAN),其创新点包括:改进条件GAN (Condition GAN,cGAN)以生成高保真度的模拟晶圆图并对缺陷类别进行分类,设计自适应生成控制器后根据分类准确性平衡每种缺陷类型的样本数量.该对抗过程分为两个阶段: 训练生成器和判别器用来生成指定类别的高保真晶圆图;训练分类器用来准确识别真实或合成晶圆图的缺陷模式,其结构图如图9 所示.
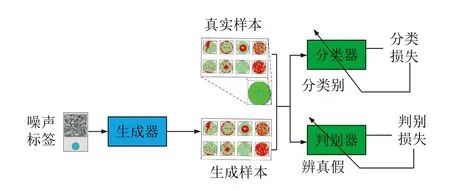
图9 AdaBalGAN 结构图[98]Fig.9 Structure of AdaBalGAN[98]
文献[99]开发了面向边缘的GAN (Edge-oriented GAN,EOGAN)以创建逼真的红外图像,核心是将所提取的边缘特征作为先验知识指导红外图像生成,其训练和测试过程如图10 所示.

图10 EOGAN 训练和测试过程[99]Fig.10 Training and testing process of EOGAN[99]
文献[100]提出了旨在增强漏磁信息有效性的改进cGAN,在轴向-径向-轴向空间处理融合后的漏磁信息,利用生成器的损失函数构建多传感器信息进而增强漏磁信息,提高模型在缺陷生成方面的效果.
文献[101]提出将生成样本与实际样本按比例混合后替代生成样本的方式增强模型生成能力的改进GAN (Improving GAN,IGAN),能够在一定程度上避免模态崩溃,其结构如图11 所示,其中随机噪声z服从高斯分布,α是取值区间在(0,1)内的混合比例系数.
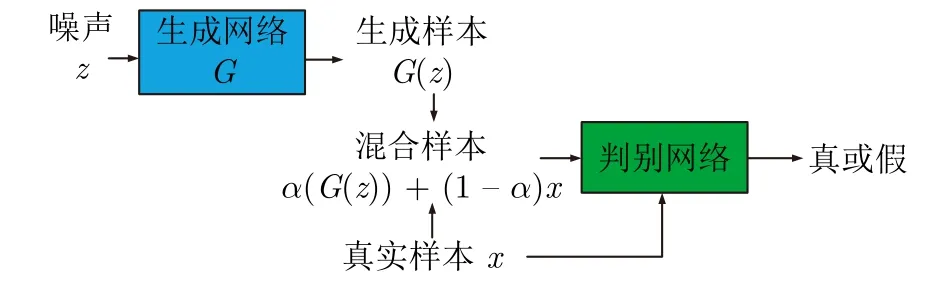
图11 IGAN 结构[100]Fig.11 Structure of IGAN[100]
3)混合VAE 与GAN 模型: 通过结合VAE 的潜在变量建模和GAN 的数据生成优点,期望实现更好的数据分布捕捉和生成效果.
面向自动缺陷检测过程,文献[102]提出基于GAN 的缺陷样本生成框架,其贡献体现在: 1)提出区域训练策略,即在图像局部区域建立损失函数以适用于局部图像到图像的转换任务;2)设计编码器-解码器的图像生成器,能够结合不同尺度的图像特征生成局部缺陷,同时保持无缺陷区域基本不变;3)引入小波对生成图像进行细化,恢复高频信息,避免图像模糊.
综上,上述方法均是通过生成稀缺区域的图像以达到弥补样本分布不平衡的目的,其难点在于如何设计合适的模型结构、网络结构和学习算法等.
3.1.2 面向样本多样性不足的图像生成现状
多采用图像到图像的转换,即通过源域特征丰富目标域特征的方式解决此处的样本多样性不足的问题,其核心是基于GAN 的循环一致性网络.为进一步增加样本的多样性,针对不同问题采取以下方法.
1)增加对抗损失: 引入能够增加多样性的对抗损失.文献[103] 提出用于图像生成的表面检测GAN (Surface defect-GAN,SDGAN),通过引入D2 对抗损失[104]增加多样性,通过采用循环一致损失生成模型学习少量的缺陷样本和大量的无缺陷样本以获得更全面的特征,其结构如图12 所示.

图12 SDGAN 结构[103]Fig.12 Structure of SDGAN[103]
2) 改进判别器: 增加对细节特征的学习.文献[105]针对基于GAN 的循环一致性结构难以学习到更为丰富的图像特征问题,提出引入胶囊网络作为判别器以学习细节特征的DuCaGAN,其结构如图13 所示.

图13 DuCaGAN 结构[105]Fig.13 Structure of DuCaGAN[105]
3)组合多种GAN: 针对不同的工业需求特点采用不同的GAN 网络.针对自动缺陷检测系统的图像分割任务,文献[106]提出采用DCGAN 和CycleGAN 生成缺陷图像、采用PatchMatch 和周期性空间GAN (Periodic space GAN,PSGAN)生成无缺陷合成图像的策略,如图14 所示.

图14 周期性纹理图像的数据增强过程[106]Fig.14 Data enhancement process for periodic texture image[106]
4)基于样式转换: 通过不同部件或背景的转换实现主体特征保留和复杂场景处理.
面向焊接过程中的对接板形变预测,文献 [107]提出基于 cGAN 产生焊接参数和形变数据以获得新样式.面向夜间环境中的目标检测任务,针对背景模糊和光线暗淡导致检测困难的问题,文献[108]提出将不易检测的夜间图像转换成易检测的白天图像的策略,其首先以夜间图像为输入,基于GAN 生成与白天环境相似的虚拟目标场景,再通过深度卷积特征融合和多尺度ROI (Region of interest)池化构建基于Faster R-CNN (Region-convolution neural networks)目标检测系统.
虽然上述方法能够增加样本的多样性,但面向工业领域而言,如何生成符合期望的样本集仍是有待解决的开放性问题,原因在于特定的工业图像特征通常是与特定的工业机理相关联的.显然,为更好地生成工业图像样本,需要更为深入地了解相关机理并将其融入到图像生成过程中.这需要与特定行业的领域专家进行密切合作,以便更好地生成符合实际需求的样本集.由上述研究现状可知,此类算法的研究关键点之一是式(1)中的pdata难以表征真实数据的概率分布preal,即如何表征preal为新增的难点.
3.1.3 面向样本噪声干扰大的图像生成现状
噪声干扰大的样本采用图像采样和转换方法进行处理,即将强噪声转化为弱噪声或无噪声,主要包括基于cGAN、WGAN (Wasserstein GAN)和CycleGAN 的方法.
1)基于cGAN 的去噪: 模型通过学习从带有噪声的图像到干净图像的映射,实现图像的噪声去除,同时利用额外的条件信息,有助于模型更好地理解噪声的性质,从而能够更准确地去除噪声.
文献[109]采用由生成器和判别器组成的基于cGAN 的图像到图像转换模型pix2pix[110]去除光反射噪声.其中,原始噪声图像作为输入,手动去噪图像作为判别器和生成器的训练目标,去噪示意如图15所示.

图15 焊接点去噪示意图[111]Fig.15 Schematic diagram of welding point denoising[111]
文献[111] 提出了基于cGAN 的印刷电路板(Printed circuit boards,PCBs)图像去噪策略,其生成器与判别器之间通过对抗性训练的迭代优化提高生成图像的质量.
2)基于WGAN 的去噪: 本质上是采用Wasserstein 距离量化生成图像与真实图像之间的分布差异,以减少训练中的模式崩溃和梯度消失问题,从而能够更准确地衡量生成图像的质量,促使生成器产生更真实干净的图像.
医疗领域,为了解决细胞图像的模糊性问题,文献[112]提出基于WGAN 的图像去噪训练框架,包括生成子网络、基于MSE 的学习和对抗学习3个模块.其中,生成子网络模块用于学习噪声图像与去噪图像之间的映射关系,基于MSE 的学习模型用于指导生成子网络快速学习映射关系,对抗学习子模块用于帮助生成子网络学习真实干净图像的分布空间.
3)基于CycleGAN 的去噪: 针对具有噪声的原始图像领域和去除噪声后的图像领域,目标是通过CycleGAN 的生成器和判别器将噪声图像映射至干净图像领域,进而实现噪声的去除.
面向无人机航空摄影任务,文献[113] 针对因天气原因导致的照片噪声问题,提出了SlimRGBD (Slim reCNN-GAN)去噪系统;针对沙漠地震数据中噪声强且与有效信号的频带存在严重重叠的问题,文献[114]引入CycleGAN 进行去噪;针对单幅图像去雾,文献[115]提出基于CycleGAN 的端到端注意力网络,其生成器设计除包括注意力模块、编码器-解码器结构和密集块外,引入了诸如暗通道、颜色衰减和最大对比度等多个先验以获取注意力图,同时提出颜色损失补偿机制以避免颜色失真.
针对医疗领域,面向低剂量计算机断层扫描(Low-dose computed tomography,LDCT)图像存在的高噪声问题,文献[116]提出了基于CycleGAN的图像域去噪;面向原始光学相干层析成像(Optical coherence tomography,OCT)图像的质量问题,文献[117]提出了能够实现视网膜OCT 图像的端到端散斑抑制和对比度增强的cGAN 框架,以解决散斑噪声会模糊视网膜结构、影响视觉质量以及降低后续图像分析任务性能等问题;进一步,文献[118]提出基于风格转换和cGAN 的OCT 图像斑点噪声抑制模型,其包括: a) 采用CycleGAN 学习两个OCT 图像数据集间的样式转移以获得真值数据集;b)基于PatchGAN 机制采用小型cGAN 模型抑制OCT 图像中的斑点噪声.可见,与处理样本噪声相关的技术已在医疗等领域得到广泛应用.
上述研究将强噪声转化为弱噪声或零噪声以提升图像质量和进行信息还原.在工业实际应用中,在选择适当的方法时还需要考虑噪声的类型、数据分布和任务需求.
综上可知,针对上述3 类工业过程图像生成问题,所采用的解决策略在本质上是不同的,对应的数学视角分析如表6 所示.

表6 工业过程图像生成问题的本质Table 6 The essence of image generation problems in industrial process
面向样本分布不均的问题,其生成模型和下游任务模型可表示为fG1(Xtraining) 和fDT1(fG1(Xtraining),Xtraining),对应的不采用fG1(·) 的下游任务直接模型可表示为,此时fG1(·) 的目的是使fDT1(·) 模型不会因为样本的分布不均而产生过拟合现象.假设能够拟合任意函数,那么对于任意的fG1(·) 和fDT1(·),则一定存在使得下式成立
由式(13)可得,受限于样本分布不均,下游任务模型性能的提升必然是有限的.当Xtraining不服从XReal分布时,在借助领域知识的情况下,必然存在fG1(Xtraining) 也无法服从XReal分布的现象.此时,虽然fDT1(fG1(Xtraining),Xtraining) 在Xtraining上的测试准确率可能会得到提升,但在面对XReal时,其准确率会较低.
面向样本多样性不足的问题,其生成模型和下游任务模型可表示为fG2(Xtraining,Xno_label) 和fDT2(fG2(Xtraining,Xno_label),Xtraining),对应的不采用fG2(·) 下游任务直接模型可表示为此时fG2(·) 的目的是要获取符合全局分布的数据集以使得下游模型的鲁棒性更强.当Xtraining的分布不服从XReal分布、而Xno_label的分布却能够很接近XReal分布时,下游模型fDT2(·) 的性能相对于是能够得到显著提升的.
面向样本噪声干扰大问题,其生成模型和下游任务模型可表示为fG3(Xtraining) 和fDT3(fG3(Xtraining)),对应的不采用fG3(·) 的下游任务直接模型可表示为,此时fG3(·) 的目的是使下游模型能够更好“理解”工业图像.当是具有自适应去噪能力的端到端模型时,则对于任意的fG3(·) 和fDT3(·),一定会存在使得下式成立
由式(14)可得,受限于样本中的噪声干扰,下游任务模型性能的提升有限.
综上可知,针对样本分布不均和噪声干扰大问题,已有生成模型难以有效表征preal;针对多样性不足问题而言,已有生成模型通过对Xno_label数据的学习能够尝试获得足以表征preal的图像集.由于涉及数据采集与标定时的场景缺失和知识缺乏等因素,此类研究在工业领域现场中的应用较少.因此,如何更有效地生成具有较强表征性的工业图像集,仍需结合工业机理和领域知识进行深入研究.
3.2 工业过程生成图像评估研究现状
通常,生成图像的评估指标应该满足以下标准:1)能够检测生成图像的生成质量;2)能够检测生成图像集的多样性;3)能够检测生成图像的可理解性或可控性;4)评价指标具备有界性;5)不可承受过高计算复杂度;6)能够检测生成图像的语义不变性;7)能够检测图像细微的形变和瑕疵.
因缺乏明确的似然概率度量[119],早期研究采用具有主观性的视觉方式对GANs 所生成的图像进行评价.之后,文献[68]提出GAN-train 策略,通过对比基于cifar100 数据集和基于合成图像训练的CNN 判别器性能进行生成图像评估.进一步,文献[120]提出了同时进行GAN-train 和GAN-test的评估策略,具体为: GAN-train 采用GAN 生成的图像训练判别器并测量其在真实测试图像上的性能,进而评价GAN 图像的多样性和真实感;GAN-test采用真实图像训练判别器并基于GAN 生成的图像进行评估,进而衡量GAN 图像的真实感.此外,初始得分(Inception score,IS)[121]和FID[122-123]也常被用作评估生成图像质量的指标.
本文将文献[124-125]所综述的定量和定性的生成图像评价指标进行整理,如表7 所示.

表7 生成图像评估指标Table 7 Evaluation index for generated image
在面向样本多样性不足的研究中,期望的生成样本需要服从全局分布,而不是仅拟合训练样本的概率分布.以MSWI 过程为例,燃烧线极端异常的火焰图像不存在于通常所获取的训练样本集中,因此,通常的评估方法不适用于这种情况.如何结合特定行业图像固有关键特征对应的机理知识对其进行综合评估和筛选,是工业生成图像评估算法研究的难点之一.
3.3 工业过程生成图像应用研究现状
当前针对工业过程图像生成的研究主要聚焦于故障识别和工况监测等任务,基于工业图像进行反馈控制和关键参数量化等方面的研究较为缺乏.以MSWI 过程为例,构建完备的火焰图像模板库可用于量化燃烧线,从而支撑基于图像的实时燃烧控制.但是在数据分析中发现,燃烧线异常的火焰图像稀缺[14],极端异常的火焰图像缺失.因此,如何基于真实图像和生成图像构建完备模板库是实现上述目标的关键[13].图像生成技术在基于模板匹配的目标跟踪领域具有广泛的应用潜力.具体来说,模板匹配是指采用预定义的图像模板与实际场景中的图像进行匹配,以达到目标检测和识别的目的.在进行燃烧线量化时,首先采用图像生成技术获取系列的火焰图像,然后构建完备模板库,最后采用模板匹配技术实现图像量化.这种方法可代替传统的基于经验的燃烧线控制方法,进而提升智能化水平.
综上,本节从面向识别任务和面向以目标跟踪任务为代表的关键参数量化两个方面进行研究现状的分析.
3.3.1 面向识别/检测任务的生成图像应用现状
在实际生产线上,因缺陷图像不足和标注成本过高等原因,很难获得具有足够多样性的缺陷样本数据.文献[98,102,105]均基于GAN 提出面向特定工业行业的图像生成策略,构建缺陷识别模型.文献[103]提出基于SDGAN 提升缺陷识别准确率,其首先采用循环损失和D2 对抗损失训练SDGAN,然后采用FID 评估缺陷图片质量,最后构建缺陷识别CNN 模型,结构如图16 所示.
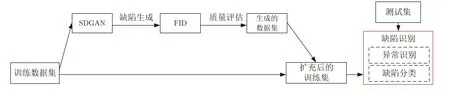
图16 基于SDGAN 数据增强的检测过程[103]Fig.16 Detection process based on data enhancement of SDGAN[103]
文献[96]提出基于CE 增强和深度可分卷积构建缺陷分类模型,采用mobilenet V1 和V2 训练两个模型,表明轻量化的深度卷积可减少模型参数和计算量.文献[97]提出基于CAE 数据增强的缺陷检测模型,采用Xception 进行晶圆缺陷检测和分类.
面向自动缺陷检测系统中的缺陷图像分割任务,文献[106]提出采用DCGAN 和CycleGAN 生成缺陷图像、采用PatchMatch 和PSGAN 生成无缺陷合成图像的策略,其在数据增强基础上提出基于CycleGAN 的周期性纹理缺陷分割框架,表明该框架优于现有的弱监督分割方法,结构如图17 所示.
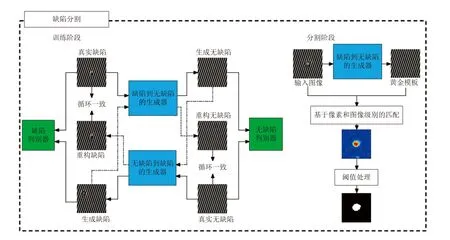
图17 周期性纹理图像的缺陷分割过程[106]Fig.17 Defect segmentation process of periodic texture image[106]
以GAN 为代表的图像生成算法已应用于工业缺陷检测领域,因其具有更佳的数据增强、特征提取、样本平衡能力而备受关注.然而,由于训练过程不稳定、生成数据存在噪声等问题,其性能和稳定性仍需进一步研究.因此,在采用GAN 进行工业缺陷检测时,需要进行充分的实验和评估,以验证其应用效果并对其优化方法进行探讨,从而提高工业应用中的实用性.
下面综述在电气设备识别、管道漏磁检测和焊接头检测等过程中的应用现状.
3.3.1.1 电气设备识别过程
该过程存在的问题包括工业过程温度分布过于集中、设备形状尺寸不确定以及识别背景复杂等.文献[99]提出基于EOGAN 生成数据的电气设备识别框架,首先采用预处理和分割技术提取边缘信息,然后在训练阶段将图像数据与边缘特征进行匹配以生成红外图像,最后在基于边缘特征的图像生成阶段构建识别模型,其策略如图18 所示.

图18 电气设备识别方法的结构[99]Fig.18 Architecture of identification method for electrical equipment[99]
上述研究存在的局限性在于: 1)采用的数据集规模相对较小,所提方法的适用性和鲁棒性有待采用更为广泛和多样化的数据集进行验证;2)未考虑在实际应用中可能存在的不确定性因素,如设备老化、环境变化等因素可能会导致生成的合成数据与真实数据存在差异;3)数据需要进行后续处理才能用于设备识别,在实际应用中需要考虑更快速和实时的识别方法.
3.3.1.2 管道漏磁检测过程
存在的问题是检测环境不稳定和设备异常会导致信息不完整.文献[100]提出基于多传感器融合的方法,用于处理信息不完整情况下的缺陷表征问题.基于3 种不同类型的传感器信号(磁场强度、相位和高斯噪声)并采用改进的cGAN 生成缺陷信号样本,以弥补传感器数据缺失的情况.研究表明,该方法可显著提高缺陷表征的准确性和鲁棒性,降低传感器数据缺失造成的影响,其策略如图19 所示.

图19 信息不完全下漏磁缺陷表征的多传感器融合框架[100]Fig.19 Multi-sensor fusion framework for magnetic flux leakage defect characterization under incomplete information[100]
值得注意的是,该研究仅基于模拟的信号数据集进行,并未在实际漏磁检测场景中进行验证.此外,该方法可能会受到缺失数据位置和数量等因素的影响,因此其应用范围具有局限性.
3.3.1.3 焊接头检测过程
该过程存在问题是: 1)不合格焊接点的样本稀缺;2)焊点具有纹理弱、对比度弱和存在腐蚀等复杂特性;3)噪声干扰大.
文献[101]通过集成GAN 和AE 构建了具有图像数据生成、特征提取和模式识别功能的网络结构,首先采用改进GAN 扩展不合格点焊接头的图像数据集,然后结合专家经验通过AE 选择图像的特征向量,最后利用隐马尔科夫模型判断点焊质量.该方法能够解决标准GAN 中生成的图像样本分布不均和多样性不足的问题.
文献[176]采用CycleGAN 实现工件与焊缝之间的样式转换,进而实现数据集的扩展,其应用过程如图20 所示.

图20 焊接头检测与识别框架[176]Fig.20 Welded joint inspection and identification framework[176]
首先,针对训练样本不足的问题,结合图像处理和GAN 生成高质量的训练样本;然后,建立训练样本的更新机制以保证深度神经网络模型能够覆盖所有样本;最后,利用深度神经网络实现焊接头的检测与识别.实验表明,该方法能够快速高效地完成焊接头的检测与识别.
文献[109]应用pix2pix[110]消除焊接图像中的噪声以实现图像增强,提出基于多源传感图像进行熔透检测的新框架,其能够同步分析多种类型的光学传感图像,包括图像预处理、图像选择和焊缝熔透分类3 个采用深度学习进行增强的阶段.
综上,基于GAN 的图像增强在焊接头检测中应用广泛.该技术通过学习原始图像中的信息生成高质量图像,能够提高焊接头缺陷、几何形状、尺寸和质量检测的准确性与可靠性.通过增强图像的细节、清晰度和纹理等特征,可显著提高焊接头检测的效果.
3.3.2 面向目标跟踪任务的生成图像应用现状
3.3.2.1 工业领域
近年来,孪生网络(Siamese network)的突出精度和速度使其在目标跟踪研究中广受关注,尤其是在视频监控和自动驾驶等领域[177-178],但其在复杂工业过程中的应用仍需要进一步深入.
以对MSWI 过程的燃烧火焰进行跟踪为例,目前还存在如下开放性问题: 1)生成虚假火焰图像以增强数据集的数量和质量,提高火焰目标跟踪算法的鲁棒性和泛化能力;2)生成虚拟火焰图像用于训练火焰边界检测模型,以便能够更准确地检测火焰的位置和形态;3)火焰的形态和颜色等信息会不断发生变化,而成像设备故障、物质遮挡等因素可能会导致火焰图像中出现缺失区域,这需要采用图像生成技术进行填充,从而更好地进行燃烧火焰的跟踪;4)火焰的形态和颜色等信息能够反映炉膛内的燃烧状态,生成虚拟火焰图像可用于训练模型预测火焰状态的变化趋势,从而更好地控制和优化炉内燃烧过程.
因此,面向目标跟踪的图像生成技术在工业领域具有广泛的应用前景,如在MSWI 过程中,其可用于增强数据集的数量和质量、检测火焰边界、填充缺失数据和预测火焰状态的变化趋势等.
3.3.2.2 其他领域
SINT (Siamese instance search tracker)算法[179]是基于孪生网络的跟踪算法的代表之一,其采用孪生网络训练识别与初始目标外观相匹配的候选图像位置,进而将目标跟踪问题转化为匹配问题.相比之下,SiamFC 算法[180]在初始阶段训练全卷积网络用于解决相似性学习问题,在推理期间对学习到的匹配函数进行在线评估,能够以超实时速度运行.SiamRPN 算法[181]将RPN (Region proposal network)网络应用于目标跟踪任务,用锚框替代多尺度卷积过程,进一步提升了跟踪速度和精度.
尽管上述跟踪算法表现出色,但均采用固定模板进行跟踪,在目标出现旋转、形变和运动模糊等外观变化时容易出现模板匹配错误,进而导致目标跟踪失败.为此,CFNet 算法[182]在SiamFC 算法框架中引入可微相关滤波器,采用岭回归微调初始模板,从而可在跟踪过程中更新模板.另外,文献[183]提出了动态Siamese 网络,通过快速转换学习模型,能够有效地从历史帧中在线学习目标外观变化.此外,文献[184]在目标跟踪过程中采用GAN 生成所需要的模板.
以上算法在一定程度上提高了跟踪性能,但在目标外观发生变化时,会存在跟踪失败的情况.由于图像生成算法能够在目标跟踪中生成跟踪目标的模板、学习目标的潜在表示、进行数据的增强更新以适应变化[184],因此应用前景广阔.
4 讨论与分析
4.1 方法比较
面向工业过程的图像生成、生成图像评估和生成图像应用共3 个视角的相关研究统计结果详见表8.
由表8 可知:
1)工业过程图像生成.从问题角度分析,其主要能够解决样本分布不均、多样性不足和噪声干扰大3 类问题.具体而言,从解决问题的视角出发,针对不同的类别应采用不同的策略: 面向样本分布不均,主要采用通过生成样本拟合小样本分布的方式,主要度量指标为样本稀疏度和样本相似度,该策略能够有效提高下游识别模型的泛化性能;面向样本多样性不足,主要采用图像到图像的转换方式,借助源域特征扩充目标域特征,相较于原始目标域图像集,目标域特征更加丰富,能够在一定程度上解决目标域图像缺失问题,该策略能够有效提高下游识别模型的鲁棒性;面向样本噪声干扰大,主要采用图像到图像的转换方式,借助清晰图像集的概率分布修正噪声干扰大图像集的概率分布,进而去除噪声,该策略能够有效提高图像的可解释性.
2)工业过程生成图像评估.生成图像评估模型的架构涵盖了输入图像与生成图像之间的比较和分析过程,用于确定两者之间的相似性和差异,其流程通常包括预处理、特征提取、相似性度量和评估指标计算等步骤.定量指标虽然能够提供客观的数值结果,但在极端异常工业过程图像的评估方面可能存在一定困难,无法准确反映生成图像的真实质量和特殊特征.定性指标主要是指基于人工方式的主观评估,包括专家评审、用户调查和视觉感知实验等方法,尽管该指标主要依赖于经验和主观判断,但在评估特殊生成图像时却具有一定优势,能够更全面、准确地评估图像的视觉质量、真实性和感知一致性.在未来研究中,需要改进和发展更为准确可靠的定量指标,需要在评估中融入更多的工业特征和领域知识.此外,还可以探索基于深度学习的生成图像质量评估算法,以提高评估的自动化程度和准确性.
3)工业过程生成图像应用.目前,对于工业过程生成图像应用的研究主要侧重于故障识别和工况监测等任务,面向工业生成图像进行反馈控制和关键参数量化等方面的相关研究相对较少.本文将生成图像应用划分为面向识别/检测任务和面向目标跟踪任务两类.针对识别/检测任务,主要集中在电气设备识别、漏磁检测和焊接检测等方面,研究者采用不同的图像生成方式获取具有特定目标的图像,以便进行算法的训练和性能的评估.针对目标跟踪任务,目前的研究主要涉及其他非工业过程领域,能够生成具有已知运动轨迹和特征的目标,进而提供训练数据或进行算法测试.未来研究中,工业生成图像还可以用于过程难测参数的检测和控制,模拟在不同参数条件下的系统性能和响应,进而拓宽其在工业领域中的潜在应用价值.
4.2 讨论与分析
结合以上分析,本文总结了面向工业过程的图像生成及其应用的未来研究方向,如下所示.
1)结合工业背景知识增加生成图像的多样性.目前的生成研究主要采取拟合已有真实小样本数据和使用图像到图像转换的策略,通过将大量无标签样本融入生成过程以增加样本多样性[103,105-107].然而,在工业环境中,如何生成同时具有全局分布特征和强解释性的样本仍然是一个挑战.笔者认为,解决方案之一是引入工业机理知识和领域专家知识约束,进而生成符合工业过程实际物理规律的工业图像,以提高生成结果的可靠性和可控性.此外,也可以考虑将不同类型的工业过程数据(如传感器数据、文本数据等)与工业图像相结合,实现基于多模态的工业过程图像生成.
2)结合扩散模型、Prompt learning 和大型生成模型的图像生成.笔者认为,在面向工业过程图像生成及其应用的未来研究中,结合扩散模型、Prompt learning 和大型生成模型将具有里程碑式的重要意义.扩散模型能够通过控制噪声信号的逐步变化生成数据样本,支持逆向过程和条件生成,可产生与GAN 方法相媲美的高质量样本.通过改进和扩展扩散模型应对不同工业领域的特定挑战,显然能够提高视觉感知模型的准确性和泛化能力.基于Prompt learning 技术,理论上是能够通过设计适当的提示信息引导生成模型输出符合工业过程特征的图像;如何设计提示信息,如何在生成过程中引入领域专家知识与物理约束信息,是提高生成结果可控性和准确性的关键之一.大型生成模型能够学习大规模数据集的知识,通过文本描述能够生成高质量、可解释的图像,但受限于缺乏可训练样本和领域知识等因素,如何生成工业领域性强的图像还有待解决.因此,结合扩散模型、Prompt learning 和大型生成模型的图像生成技术将能够为工业过程图像生成的未来研究提供新的契机.
3)对图像去噪与图像生成进行协同优化的图像生成.受传感器噪声、光照变化或物体振动等多种因素的影响,工业过程图像常常包含噪声和伪影[109,111],过度拟合噪声数据会导致模型记忆随机噪声的模式,进而影响模型的泛化能力[189].因此,需要研究如何设计能够同时学习图像去噪和图像生成任务的一体化模型,通过共享特征表示和参数,使得去噪和生成过程能够相互促进,进而提高生成结果的质量和准确性.此外,针对具体的工业过程,其噪声结构往往具有独特性,例如在MSWI 过程中,噪声主要源自飞灰、杂质以及高温对摄像头的影响.笔者认为,未来研究需要根据噪声结构中所存在的先验信息选择或改进更为适合的算法,这将有助于提高工业图像去噪效果.
4)基于生成图像的工业模板库构建与更新及在下游应用.通常的工业图像模板库因存在异常样本分布不均和极端异常样本缺失等问题,导致难测参数和控制模型的泛化性能和鲁棒性能受到限制[190].从模板库的构建和更新视角而言,简单的线性更新策略显然难以满足工业现场的所有可能情况;此外,该更新策略在空间维度上是恒定的,无法实现局部更新.因此,有必要采用基于生成图像的策略构建完备的工业图像模板库以解决上述问题.从难测参数检测的角度分析,基于图像生成的模板库能够提供完备的图像特征,能够涵盖各种可能的异常情况,从而提高难测参数的检测能力.从基于图像进行控制[191]的角度分析,基于图像生成的模板库的数据具有完备性,能够与控制策略建立较为完整的映射,进而支撑实现更为准确和精细的工业过程控制.此外,生成模型还可以根据不同的控制策略生成相应的图像样本,用于评估控制系统的性能.因此,通过构建和更新完备的工业图像模板库并将其应用于难测参数检测和控制优化,在未来有望提升工业过程控制系统的性能.
5)基于生成图像与过程参数工业模板库的产品质量优化研究.本文认为,通过利用模板库中的图像样本和相关参数信息,进行基于生成图像与过程参数工业模板库的产品质量优化将是未来的重要研究领域.首先,需要收集、整理和标注大量的样本数据,即构建的模板库应包含不同工业产品的图像样本以及与其相关的质量参数,以支持后续的产品质量优化研究.然后,利用生成模型技术扩充样本库中的样本数量,即通过生成图像模拟不同参数和条件下的产品.最后,结合图像处理和机器学习方法,通过分析生成的图像样本和与之相关的参数信息,建立预测模型以优化产品质量.显然,上述研究将会推动工业领域质量管理和控制技术的发展,实现对产品质量的优化和改进,提高工业生产的效率和竞争力.
6)基于生成图像跟踪特征目标的工业过程控制和优化.本文认为,基于生成图像跟踪特征目标在助力工业过程的控制和优化方面具有较大的应用潜力,具体表现在: 可用于工业过程目标的感知和识别,目标位置、状态和运动轨迹的实时监测;基于跟踪信息实现自适应的控制和优化策略,进行更高效、精确和可靠的工业生产过程跟踪控制;通过比较生成图像与预期目标图像的差异进行异常检测和故障诊断,及时检测和识别工业过程中的异常行为或故障情况,支撑容错控制算法的设计与实现;通过实时监测目标的位置和状态对资源进行优化分配和利用,进而提高生产效率和资源利用率;通过自动化的生成图像分析和目标跟踪,促进工业过程的智能化和无人化,减少对人力资源的依赖,提高对生产过程的可控性和安全性.未来的研究方向包括提高生成图像跟踪的精度和稳定性,探索更为有效的目标识别和跟踪算法以及将其与工业过程的控制和优化相结合,提高工业过程的智慧化水平,实现更为高效、可持续和安全的工业生产.
5 总结与展望
本文首先概述了图像生成研究现状,阐释了工业过程图像生成的定义、流程、评估和应用需求;然后,简要分析了在工业领域具有潜在应用价值的图像生成算法;接着,依据图像生成流程,从图像生成、生成图像评估和应用3 个视角进行详细综述;最后,讨论了这些算法的技术特点和研究难点.笔者认为,为获得具有全局分布特性的工业过程生成图像样本集,未来的研究主要面临着以下挑战:
1)大规模模型的融入: 随着深度学习的快速发展,大规模模型在图像生成任务中已经展现出巨大潜力.考虑到将大规模模型应用于工业过程中需要解决计算资源消耗、模型复杂度和训练效率等问题,未来的挑战应致力于如何通过高效地融入大规模模型以提升特定行业的生成图像的质量和效率.
2)多模态场景的生成: 工业过程涉及多种场景和特征,单一的生成模型难以覆盖所有工况下的图像生成需求.研究人员可探索设计具有多模态特性的生成模型,通过将每个模态专注于特定的工业场景或特征等方式提高生成图像的逼真度和多样性,包括考虑但不限于在光照、材质、形状等方面的变化.
3)基于生成图像的关键参数检测和工业过程控制: 在工业过程中,生成的图像中不仅包含视觉信息,其还蕴含关键过程参数和控制信息.研究如何准确提取生成图像中的关键过程参数并将其应用于工业过程的控制和优化是一个重要的开放性问题.未来的研究可探索基于生成图像的关键过程参数检测和工业过程优化控制策略,进而实现工业过程的智慧运行.
综上所述,面向工业过程的图像生成及其应用研究面临着大规模模型的融入、多模态场景的生成和基于生成图像的关键参数检测和工业过程控制等挑战.解决这些挑战将为工业领域提供更高质量、多样化和可控的图像生成技术,并推动工业过程的创新和进步.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
数学年刊A辑(中文版)(2020年3期)2020-10-27
知识经济·中国直销(2018年8期)2018-08-23
黄河之声(2018年5期)2018-05-17
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
数学学习与研究(2017年3期)2017-03-09
中国老区建设(2016年1期)2016-02-28
Coco薇(2015年10期)2015-10-19
噪声与振动控制(2015年4期)2015-01-01
机械制造文摘(焊接分册)(2014年6期)2014-03-20
