
基于双向稀疏Transformer的多变量时序分类模型
2024-03-05 01:41王慧强陈楚皓吕宏武米海林
小型微型计算机系统 2024年3期
王慧强,陈楚皓,吕宏武,米海林
(哈尔滨工程大学 计算机科学与技术学院,哈尔滨 150001)
0 引 言
多变量时间序列(Multivariate Time Series,MTS)是按时序获取的事件序列,其中每个事件由多个属性的观测值构成[1].MTS的分析评估有助于从更多维度上掌握事物的实时发展演化趋势,在生理健康、运动识别、金融行情评估[2]、交通流量预测[3]等领域发挥着重要作用.
与单变量时间序列(Time Series,TS)相比,MTS具有两个显著特征.一方面,由于真实场景中的时序数据种类多、样本数量量级差距大、时序长度不一、特征个数不同,数据往往具有差异化的分布特征和统计信息,这对MTS分类模型提出了巨大的挑战.另一方面,来自不同领域的时序数据的时序波动程度差异巨大(如图1(a)、图1(b)所示),加剧了时序分类问题的复杂性,制约了分类准确度的提升.

图1 呈现周期性的时序数据Fig.1 Time series data with periodicity
针对第一方面,目前诸多学者对多变量时序分类问题已经进行了诸多研究.例如文献[4,5]基于动态时间归整(Dynamic Time Warping,DTW),通过寻找两个长度不同的多变量时间序列的最佳对齐方式,计算对齐后两序列间的距离来完成时序分类任务.文献[6,7]等通过选择最具代表性的子序列获取序列特征完成分类.这些方法需要时间序列数据中的领域知识,还会产生巨大的特征空间,使得后续特征选择变得困难,并且在多变量时序分类场景下的准确度较低.
针对第2个方面,越来越多的学者将CNN、RNN、LSTM等深度学习模型引入多变量时序分类领域.基于深度学习的方法可借助端到端的训练,不需要了解数据领域知识,可以避免巨大特征空间的产生,但存在历史数据的周期性捕获能力不足的问题.
与传统深度学习模型相比,Transformer模型凭借着自注意力(self-attention)机制[8],具备更强的长期依赖性捕获能力,在长时序问题上表现出巨大的潜力.但是,self-attention机制中使用的标准点积运算的时间复杂度均为O(L2)(L为时间序列长度),随着L的增长运算成本会呈指数级增加,同时,文献[9]提出Transformer存在长输入堆叠层的内存瓶颈,J层编码器/解码器的堆栈使总内存使用量到达O(J×L2),这限制了Transformer模型在接受长序列输入时的可扩展性.此外,self-attention机制没有对输入进行偏置假设,甚至训练数据的顺序信息都要通过训练学习.因此,没有经过预训练的Transformer模型很容易在小、中规模数据集上过拟合.这些问题极大限制了Transformer模型在多变量时序分类领域的应用.
为了减小Transformer的时间复杂度,大量学者进行了探索.文献[9]认为Transformer中学习到的self-attention矩阵的数据存在长尾分布,注意力数据在大多数数据点上通常非常稀疏.受此启发,本文注意到self-attention机制具有双向稀疏性,提出基于双向稀疏选择Transformer的时序分类模型(Bidirectional Sparse Transformer,BST),将self-attention机制时间复杂度降至O((lnL)2).本文的主要贡献有以下3点:
1)本文提出了一种时间复杂度为O((lnL)2)的双向稀疏注意机制,有效地提高了self-attention机制的效率.
2)基于KL散度构建活跃度评价函数,并将评价函数的非对称问题转变为对称权重问题,得到简洁的评价函数.
3)在前两点的基础之上构建多变量时序分类通用Transformer框架,捕捉时序数据的波动依赖,完成多变量时间序列分类任务.实验结果表明,与其他模型相比,本文提出的模型能够提高长序列时序数据的分类准确度.
1 相关工作
1.1 多变量时间序列分类方法
近几年来,多变量时序数据分类的研究已经取得很大进展,这些研究主要可分为基于距离的方法、基于可解释模式的方法和基于深度学习的方法.
基于距离的方法通常利用领域知识,计算样本范数完成分类.文献[4]通过DTW寻找长度不同的时间序列的最佳对齐方式,计算每个维度的距离衡量时间序列的相似度.文献[5]认为多变量时间序列各维度之间存在一定的联系,基于多维点计算距离完成时序分类.基于距离的方法使用少量样本就可以完成训练,但会生成较大的特征空间.
基于模式的方法将多变量时间序列转变为特征,然后将这些特征送入分类器进行分类.文献[6]提出模式袋模型(Bag Of Patterns,BOP),通过滑动窗口机制将多变量时间序列分解为子序列进而转变为模式元素来进行分类.文献[7]将不同长度的子序列嵌入到统一网络,通过计算正负样本之间的距离选择出最具有代表性和多样化的子序列,进一步提高了分类精度.基于模式的方法清晰明了且可解释性高,但依赖数据集,可拓展性、可推广性不高.
随着近年来深度学习的迅猛发展,越来越多的人将深度学习应用到多变量时间序列领域.文献[10]基于CNN,使用随机设置参数的卷积核对多变量时间序列进行转换,极大提高了分类效率,但CNN并不完全适用于处理多变量时间序列,随着数据集的增大模型准确度没有明显的提高.文献[11]将LSTM和CNN混合使用完成数据嵌入,再通过squeeze-extraction模块生成多变量时间序列的潜在模式完成分类.文献[12]把多变量时序数据维度随机组合成不同的组,通过注意力层训练样本的权重,将同一类中训练样本的加权组合,成功将模型扩展到半监督领域.
由于使用堆叠的LSTM和CNN,文献[11]和文献[12]都存在无法充分利用历史数据捕获数据中的周期性的问题.文献[13]摒弃LSTM+CNN的模式,采用两个Transformer子层分别提取多变量时序特征和维度特征,使用门控机制将两种特征合并,探索了Transformer架构在多变量时序分类领域的应用.它使用Transformer捕捉时间序列特征,降低了梯度消失或者梯度爆炸的风险,但是Transformer的时间复杂度仍为O(L2),会产生高时间、高内存消耗,从而限制了模型在多变量时序数据的应用.
1.2 高效Transformer模型
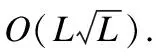
2 基于双向稀疏机制的Transformer框架
为提高多变量时序分类中长序列数据分类的准确度,本节提出一种适用于长序列时序分类的Transformer时序分类框架,将Transformer的时间复杂度降至O((lnL)2).
2.1 问题定义
多变量时序数据集X可表示为:
X={X1,X2,X3,…,Xi,…,XN},N为序列样本的个数.
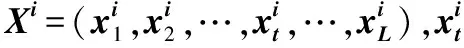
本文意在训练一个分类模型f,f可将每个序列样本Xi映射到相应的分类yi.
f(Xi)→yi,yi∈{0,1,2,…,K}
2.2 模型架构
本文的模型概况如图2所示.模型可分为3个部分,数据嵌入、编码器和分类器.
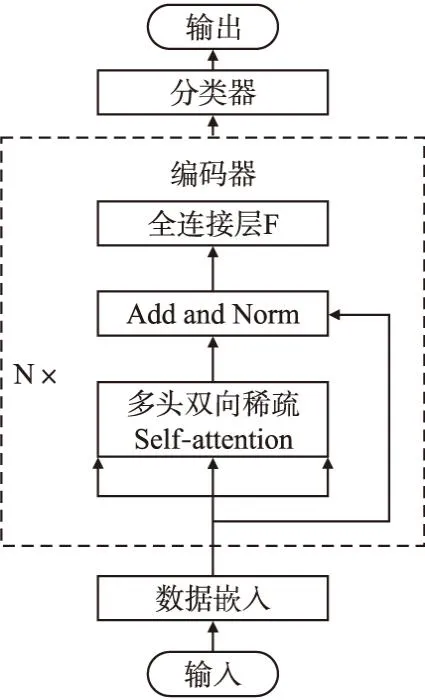
图2 BST模型结构图Fig.2 Architecture of the BST model


分类器:使用LogSoftmax层作为分类器,完成下游任务分类并获得输出结果.
2.3 双向稀疏注意力机制
Self-attention机制是Transformer中的重要组成部分,它直接将时间序列中任意两个时刻的数据通过一个计算步骤直接联系起来,所以远距离时刻依赖特征之间的距离被极大缩短,有效地利用这些特征捕获时间序列中数据相互依赖的特征.标准的Transformer[8]中self-attention的输入为查询矩阵Q、键值矩阵K、值矩阵V,注意力计算如公式(1)所示:
(1)
其中,Q∈RLQ×dQ,K∈RLK×dK,V∈RLV×dV,在实际情况中通常令dQ=dK=dV=d,LQ=LK=LV=L,L为输入序列长度,d为序列维度,A称为注意力矩阵.为更方便讨论self-attention机制,用qi、ki、vi分别代表Q、K、V中的第i行,也是Q、K、V中第i个query、key、value.
公式(1)需要二次点积计算[8],这是阻碍Transformer模型提高分类预测能力的主要缺点.由研究可知,self-attention矩阵的数据存在长尾分布,对于训练有素的Transformer,其注意力矩阵A通常是极具稀疏性的[16],这表明可以在不显着影响性能的情况下引入某种形式的稀疏性.文献[9]中探讨了注意力矩阵A中query的稀疏性,认为自注意力矩阵的稀疏性表现为不同的query对key表现出的关心程度不同,并据此将query划分为active query、lazy query两类,通过筛去lazy query的方式完成查询矩阵稀疏化.
本文绘制了文献[9]中基于单向稀疏Transformer模型在训练过程中注意力矩阵A的热力图,如图3(a)所示.从图中可以看,query对于不同的key具有不同的关注度(即不同的活跃度,活跃度越高,自注意力得分越高),key对于不同的query关注度也不同.经过单向稀疏化后注意力矩阵A在query上表现出的稀疏性虽有明显下降,但是在key上仍然存在明显的稀疏性,这说明了对Q、K进行双向稀疏化的可行性及必要性.据此,本文基于活跃度评价函数对query、key进行筛选完成对Q、K的稀疏化,从而提出一种时间复杂度为O((lnL)2)的Transformer多变量时序分类模型.
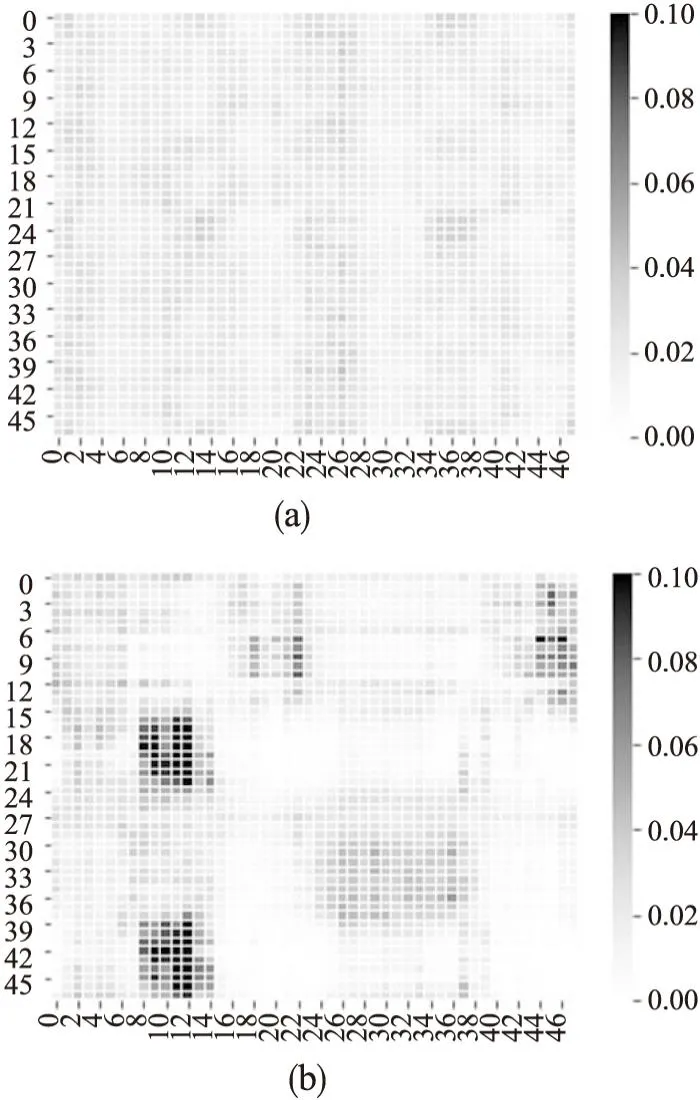
图3 双向稀疏化前后注意力得分矩阵热力图Fig.3 Heat map of attention score matrix before and after bidirectional sparsification

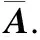
(2)
使用双向稀疏化的自注意力公式进行训练,得到注意力矩阵A的热力图如图3(b)所示.可以看出经过双向稀疏化后,不同的query、key的活跃程度区别更加明显,活跃的query与key明显增多,说明双向稀疏机制确实筛选出了活跃度高的query和key.双向稀疏自注意力机制的具体过程如图4所示.
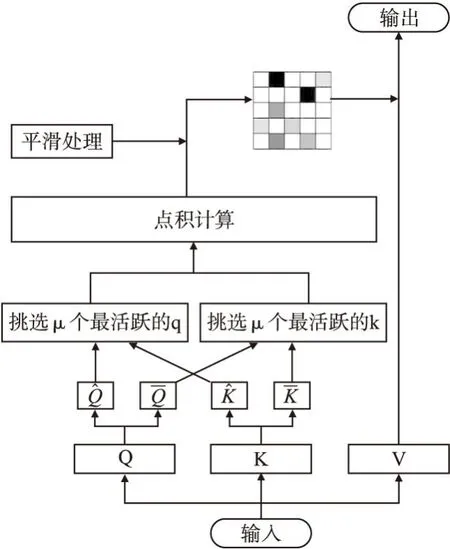
图4 Self-attention双向稀疏机制Fig.4 Bidirectional sparse mechanism for self-attention
2.4 活跃度评价函数
从2.3节可知,模型需要评价query和key的活跃程度以考查query和key的稀疏性,因此需要构建活跃度评价函数.文献[18]通过核函数的表示方法,将自注意力标准化公式中的每一个qi的注意力以概率形式进行表示:
(3)
(4)
通过KL散度计算每一个查询向量的后验概率分布p(kj|qi)与平均分布q(kj|qi)的KL散度距离,来计算qi的活跃度计算公式M为:
(5)
由公式(5)可知,qi活跃度评价函数M的时间复杂度为O(L),评价Q整体活跃度的时间复杂度为O(L2),本文进一步将计算M的时间复杂度降低至O((lnL)2).
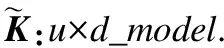
(6)
据此,评价整体活跃度的时间复杂度从O(L2)转变为O((lnL)2).此外,由于公式(5)和公式(6)中采用的核函数是非对称的,不能直接用于key的活跃度评判,为此还需要将非对称问题转换成对称问题.
Self-attention中点积运算的基本作用是学习自我对齐,即确定单个token相对于序列中所有其他tokens的相对重要性,物理意义在于计算两个向量的相似度[20].在以NLP为代表的Transformer应用中Q、K的对齐关系如图5左图所示,Q、K、V具有相同的物理意义,都表示同一样本中不同token组成的矩阵,而Q、K矩阵的点乘本质上是计算每个token与其他tokens的相似度.不同于其他的Transformer应用领域,如图5右图所示,时间序列领域过程中数据具有明显的单向性,在实际应用中不能建立出未来时刻与当前时刻的联系,因此确定未来时刻相对现在的相对重要性并非必要的.此外,在训练过程中计算未来时刻与当前时刻的注意力得分,虽然可以带来较低的损失,但是存在较快过拟合的风险.

图5 不同领域对齐关系Fig.5 Alignment in different domains
因此本文采取单侧计算self-attention的方法,将注意力矩阵A将变成上三角形,等效于一个对称矩阵.令Q=K,可以仅通过训练单个Q就完成上述的工作.
仍然利用双向稀疏方法,对Q进行两次抽样筛选,得到稀疏化之后的矩阵的Q1、Q2,多头注意力机制变为:
(7)
使用Q1、Q2代替原有的Q、K,可以很好地解决核函数的非对称性问题,让整个评价函数具有广泛的适用性.
3 仿真实验及分析
本文使用University of East Anglia(UEA)多变量时序分类档案[4]中的9个数据集评估所提出的模型的性能.所有实验均在具有32GB内存的NVIDIA GeForce RTX 2080 GPU上进行.
3.1 数据集
UEA多变量时序分类档案是多变量时序分类领域公开的数据集集合,共包含30个时间序列数据集,本文挑选其中的9个数据集评估本文的模型,包括心房颤动(AtrialFibrillation,AF)、乙醇浓度(EthanolConcentration,EC)、面部检测(FaceDetection,FD)、手指动作(FingerMovements,FM)、手部移动(HandMovementDirection,HMD)、昆虫振动(InsectWingbeat,IW)、交通分类(PEMS-SF,PS)、电位调节(SelfRegulationSCP2,SRS2)、步行跳跃(StandWalkJump,SWJ).它们来自不同的领域,样本的时间序列长度从50~2500不等,可以充分考查模型的通用性.本文遵照数据集发布者划分的训练集、测试集比例.9个数据集的具体情况如表1所示.
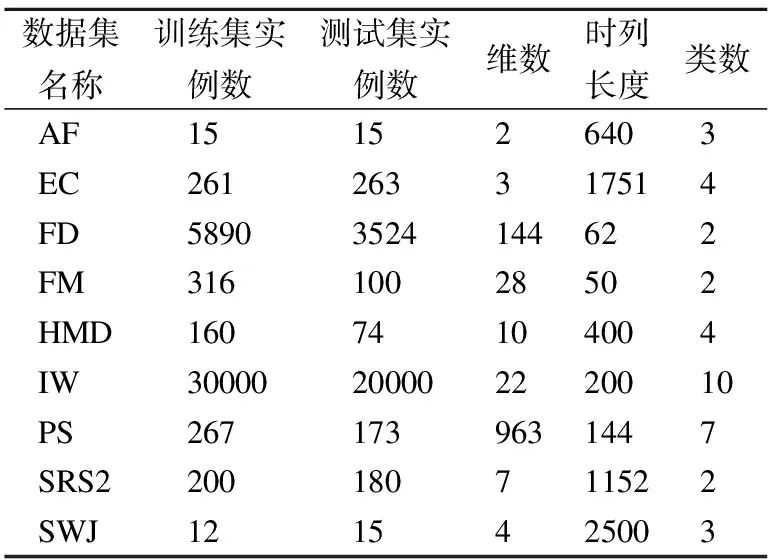
表1 实验中使用的UEA数据集Table 1 UEA datasets used in the experiment
3.2 评估指标及参照模型
本文统计每个数据集上的各个分类模型的分类精度,并计算每个模型的平均排名和成功次数(某数据集上分类精度最高记为成功).此外,由于每个数据集的样本数目不同、特征维度不同、时间序列长度不同,只计算上述3个评估指标难免有失偏颇,因此本文绘制临界差异图(Critical Difference Diagram),并计算每类平均误差(Mean Per-Class Error,MPCE).MPCE所有数据集每类的平均误差,它可以评估一个模型在多个数据集的联合分类效果.MPCE如公式(9)所示:
(8)
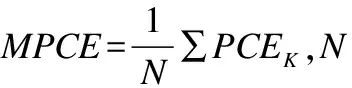
(9)
为了充分评估本文BST模型对于多变量时序分类的效果,将BST与其他分类模型进行比较.参照模型可分为3类:
1)时序分类通用基准模型:ED_I[4].
2)多变量时序分类基准模型:DTW_I、DTW_D[4].
3)多变量时序分类领域7种先进的模型:RLPAM[1]、WEASEL+MUSE[6]、ShapeNet[7]、ROCKET[10]、MLSTM-FCN[11]、TapNet[12]、MiniRocket[19].
RLPAM:一种基于强化学习的多变量时序分类框架,通过模式挖掘来识别多变量时序分类中可解释的、重要的模式完成分类.
WEASEL+MUSE:一种基于BOP的多变量时间序列分类框架,使用滑动窗口在时间序列的不同维度上进行抓取,将多变量时间序列转变为大量模式特征,并使用卡方检验来进行特征选择完成分类.
ShapeNet:一种基于时序子序列shapelet和深度学习的多变量时间序列分类框架,采用扩张因果卷积神经网络(Dilated Causal Convolutional Network,DC CNN)学习时序子序列的新表示,选择其中具有代表性和多样性的时序子序列完成分类.
ROCKET:一种基于深度学习的多变量时序分类框架,使用权重、形状、偏重随机的卷积核变换时间序列,然后利用转换后的特征完成分类.
MLSTM-FCN:一种基于深度学习的多变量时间序列分类框架,该模型由LSTM层、堆叠的CNN层、Squeeze-Extraction层生成多变量时间序列的潜在模式,然后利用多层感知机(Multilayer Perceptron,MLP)完成分类.
TapNet:一种基于深度学习的多变量时间序列分类框架,模型使用随机群置换的多层卷积网络和注意力网络,从多变量时序数据中学习低维特征完成分类.
MiniRocket:MiniRocket在Rocket的基础上进行了改进,不再使用随机卷积核,而是使用一组几乎完全固定的小卷积核对多变量时序数据进行转换完成分类.
3.3 分类结果
9个数据集上的分类结果如表2所示.“N/A”表示无法产生结果.

表2 各分类算法实验结果Table 2 Experimental results of classification algorithms
观察表2结果可知,BST模型在所有模型中取得了最佳平均排名,平均排名为1.78,优于所有参照模型.图6为根据实验结果绘制的临界差异图,可以综合评估多个模型在多个数据集上的表现.可以看出,BST模型性能最好,它的结果比排名第2的RLPAM模型小1.1左右,领先37.2%.就MPCE而言,BST取得了在9个数据集上最小每类平均误差,与排名第2的RLPAM相差0.03,提升2.5%.就成功次数而言,BST取得了4次成功,在所有数据集上获得最多的成功次数.此外,BST模型在EC数据集上提升效果明显,分类准确率提高30.9%.

图6 临界差异图Fig.6 Critical difference diagram
3.4 实验结果分析
为深入分析模型的分类效果,本节以HMD数据集为例,采用t-SNE算法以二维图像的形式可视化时间序列嵌入.HMD数据集共包含4个不同种类的160个训练样本,使用不同的数字(0,1,2,3)来区分不同的类别.图7(a)为HMD数据集原始数据的嵌入结果,图7(b)为数据经过模型编码器学习处理后的嵌入结果.可以看出,原始数据嵌入后不同类别的样本分布散乱、没有规律,而经过编码器处理后,数据分类明显,说明BST模型确实完成了分类任务.

图7 数据编码前后t-SNE嵌入对比Fig.7 Comparison of t-SNE embedding before and after data coding
从表2可知,本文的模型并非在所有的数据集中表现优越.为了探究原因,选择了HMD数据集和PS数据集进行分析.图8(a)为HMD数据集中随机挑选的样本某个特征随时间变化的情况,图8(b)为PS数据集中随机挑选的样本某个特征随时间变化的情况.可以看出,HMD数据集中的时序特征随着时间的起伏、波动变化频率很高,数据具有很强的时序性和周期性.对于这样的数据集,BST模型能够充分发挥作用,捕获时序之间的隐含联系完成分类任务.然而PS数据集中的时序特征随着时间的起伏波动变化变化频率低,包含的时序性不强,BST模型捕捉到的时序性有限,但BST模型在PS数据集上的准确度排名第4,依然保持在中等偏上的水平.

图8 HMD和PS特征变化趋势Fig.8 Change trend of HMD and PS characteristics over time
此外,本文尝试将数据增强引入BST模型,以提升模型分类准确度.本文采用文献[17]提出的cutmix、cutout、mixup、windowwarp 4种操作的最佳组合方式,保持其余实验参数设置不变,完成数据增强.BST模型有无数据增强的实验结果如表3所示.从表3可以看出,BST模型使用数据增强和不使用数据增强获得的准确度差异最高相差3.21%,最低相差1.01%,波动范围在模型正常波动范围内,数据增强对提高BST模型准确度没有明显的帮助.

表3 BST模型有无数据增强结果对比Table 3 Results of BST model with and without data enhancement
4 结 语
本文针对多变量时序数据分类中数据难以捕捉时序特征、周期特征的问题,提出了BST双向稀疏Transformer分类框架.建立使用单侧注意力的活跃度评价函数,并在此基础之上提出self-attention的双向稀疏机制,将Transformer的时间复杂度降至O((lnL)2).实验证明,BST模型在UEA时序分类档案中的9个长序列数据集上取得最高平均排名,在临界差异图中领先第2名37.2%.由于篇幅和时间的限制,本文仅讨论了BST模型在提高多变量时序分类准确度的效果,没有与其他深度学习模型的时空消耗进行比较.此外,BST模型目前尚不适用于时序性不强的数据集.
猜你喜欢
中国农业信息(2023年3期)2023-03-18
小雪花·成长指南(2022年1期)2022-04-09
中国农业信息(2021年3期)2021-11-22
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
传媒评论(2017年3期)2017-06-13
电子制作(2016年15期)2017-01-15
第二课堂(课外活动版)(2016年2期)2016-10-21
