
针式打印字体电离层垂测数据自动提取技术
2024-03-05 06:28苏桂昌张瑞坤刘祥鹏
青岛科技大学学报(自然科学版) 2024年1期
苏桂昌,张瑞坤,刘祥鹏
(青岛科技大学 数理学院,山东 青岛 266061)
电离层垂测数据是各观测站点通过垂直探测技术观测的电离层物理特性参数,对卫星导航、通信、雷达定位等[1-2]诸多无线电信息系统有重要影响。目前,中国电波传播研究所留存了自上世纪40年代以来国内外诸多观测站点的电离层垂测数据,分为印刷体、手写体、针式打印字体等。这些资料现已经实现了纸质数据的电子化扫描,但如何提取扫描图片中的数据来保护这一战略性资源是一项迫在眉睫的工作,这对电磁环境大数据前端数据提取与挖掘分析有重要的支撑作用。传统的数据提取方式需要人工逐一输入,而通过研究相关算法自动识别提取这些垂测数据可以极大减轻工作量,提高数据录入效率。该类型的算法研究属于计算机文字识别领域,即光学字符识别[3](optical character recognition,OCR),是计算机视觉的重要研究方向之一。近年来,深度学习的研究推动了OCR 技术的发展,在自然场景文本识别、交通物流、卡证表格识别等[4]多个领域都有了成功应用。
基于深度学习的OCR 技术本质上是图像识别,其包含文本检测和文本识别两大关键技术。在文本检测方面,SHI等[5]在检测到图像中的最大稳定极值区域(MSER)后,通过最大流/最小割算法将MSER 标记为文本区域或非文本区域,实现文本检测。TIAN 等[6]提出CTPN 算法,将文本检测任务转化为一连串小尺度文本框的检测。TANG 等[7]提出的SegLink++算法在检测小矩形区域的同时,将同属于一个文本区域的矩形相连,完成若干矩形区域的合并。BAEK 等[8]将文本实例划分为若干个字符实例使用语义分割的框架来预测各个字符的位置以及相邻置信度。ZHOU 等[9]提出的EAST 算法加入了对倾斜文本的建模,可灵活生成字符级或文本行的预测。LIAO 等[10]提出的DB算法则在后处理部分设定自适应阈值得到二值化的分割图。文本识别方面,WOJNA 等[11]提出了一种基于注意力的文本识别架构,能够在识别过程中更加关注重要的图像区域,提高识别准确率。SHI等[12]提出CRNN 算法,将文本识别转化成语音识别问题来处理。CHENG 等[13]采用ResNet网络丰富场景文本图像的深度表达,解决了复杂图像中特征区域和目标之间无法精确对齐的问题。LUO 等[14]提出了一种用于场景文本识别的多目标校正注意网络MORAN,可以校正含有不规则文本的图像,降低识别难度。YU 等[15]提出了基于语义推理网络的场景文本识别框架,通过多路并行捕获全局语义上下文。上述学者就文本检测与识别提出的各类算法,应用时还需根据实际业务背景进行相应的调整改进。
本工作主要针对电离层垂测数据中的针式打印字体这一类型扫描图片,提出了一种基于卷积循环神经网络(convolutional recurrent neural network,CRNN)深度学习框架的OCR 数据自动提取技术,显著提高了识别准确率。根据针式打印字体电离层垂测数据扫描图片各类型特点以及检测识别上的困难,设计图像预处理的方法,有效提取文本区域,同时在投影分割中加入检测候选框修正功能提高检测精度,另外利用坐标融合算法实现识别结果的标准化存储。最后,将本工作所提方法与主流算法进行了对比分析。
1 数据介绍
针式打印字体电离层垂测数据扫描图片(以下简称针式打印图片,如图1所示)包含表头、观测站点信息、观测类型信息、文本区域、表格、电子浓度轨迹等内容,其中,图片内的两部分文本区域主要记录的是电离层观测的地球电离层的密度、高度、温度等信息等数据信息,具有较高的研究和应用价值,是本文自动提取的重点。根据文本区域的行间距,可以将针式打印图片分为3种类型:a)文本行与行之间有一定间距(行间距约20个像素点);b)文本行与行之间间距较小(行间距约5个像素点);c)文本行与行之间发生粘连(行间距约1个像素点或者直接相连)。

图1 针式打印图片数据类型Fig.1 Pin print picture data type
经观察分析,3种类型的针式打印图片在自动提取上存在如下困难,如:1)如何在图片中定位需要提取的区域;2)行间距的减小,甚至粘连增加了文本检测难度;3)3种类型的图片字体存在区别,非统一字体,另外字体的像素偏低、字符像素不连通、字符组长短各异、有独立小字符等问题,也对文本识别造成影响,增加了识别的难度;4)还有像图片的粉红色底纹背景,拍摄光线、污渍、墨迹等外部干扰对自动提取工作也带来了一些困难。
2 数据自动提取技术
针式打印字体电离层垂测数据扫描图片自动提取技术研究方案主要包括图像预处理、文本检测、序列文本识别和识别结果版面处理4个模块,其流程图如图2所示,其中模板匹配、基于投影法的文本检测、序列文本识别以及版面的处理是OCR 识别的关键。
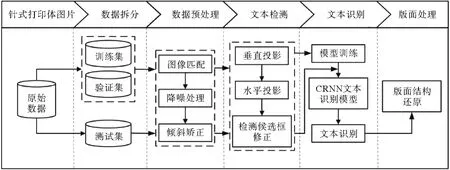
图2 针式打印图片数据自动提取流程图Fig.2 Needle print picture data automatic extraction flow chart
2.1 图像预处理
鉴于上述针式打印图片存在的客观问题,在自动提取前需要进行图像预处理,其预处理流程如图3所示,首先采用图像模板匹配的方法,将图片中的两部分目标文本区域分别提取出来,然后对目标文本区域进行降噪处理,以减少粉红色底纹背景和噪声点对提取的干扰。最后,计算处理后图片的倾斜角度,实现目标文本区域的倾斜矫正,以方便后续的检测、识别、可视化标记和存储。
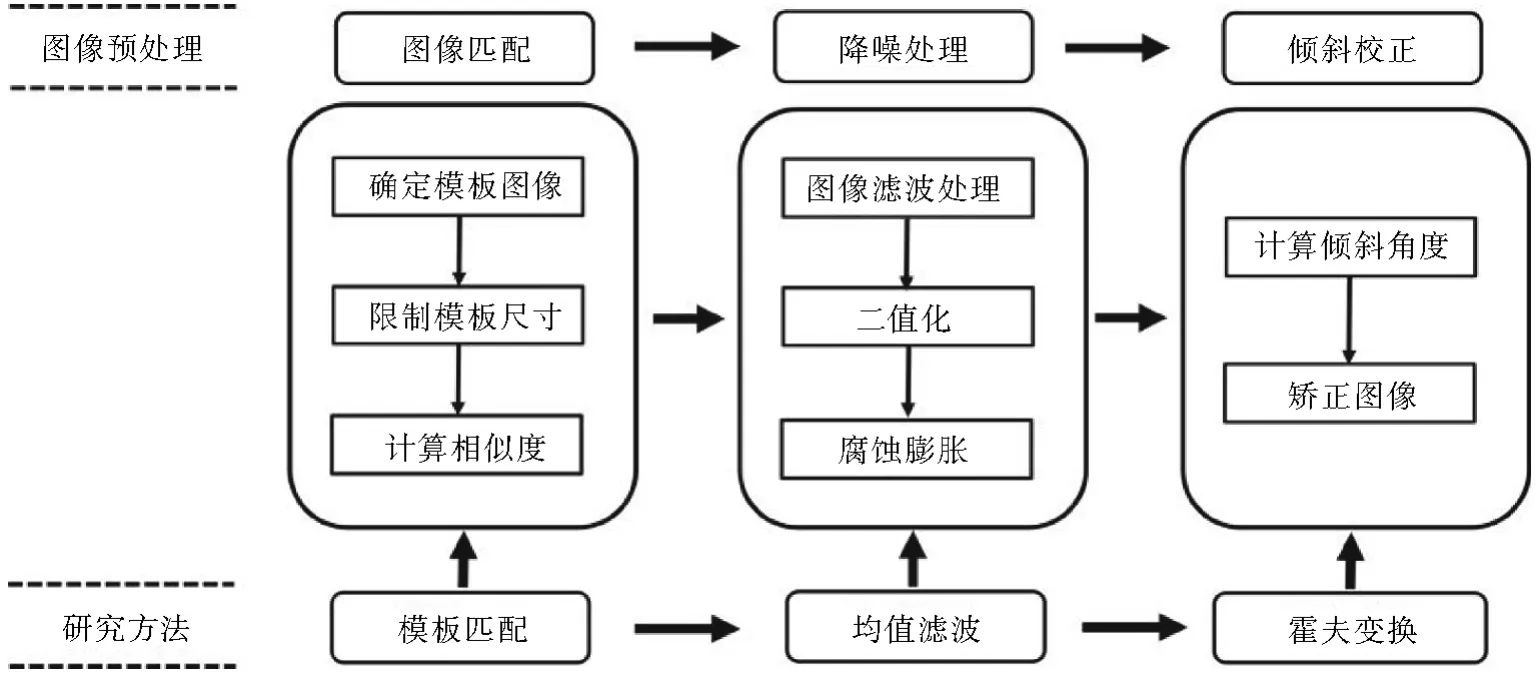
图3 图像预处理流程图Fig.3 Image preprocessing flow chart
2.1.1 图像模板匹配
由图1可知,针式打印图片的图像尺寸较大,需要提取的文本区域没有明显特征标记,且3种类型图片面积各不相同,提取的文本区域大小不一,本工作采用图像模板匹配的方法来检测提取图像中的文本区域。
模板匹配[16]是指通过模板图像与待检测图像之间的比较,计算模板图像与待检测图像中目标的相似度,以找到待检测图像上与模板图像相似的部分,具体步骤如下:
步骤1确定模板图像。
通过比对3种类型的针式打印图片,发现图像中文本区域和下方的图像区域均以数据类型注释和数据单位作为起始位置,文本区域和图像区域的分割线作为文本区域的结束位置,将这4部分图像确定为模板图像,选择模板图像定义为T,其宽度均为M,高度用Ni表示,i=1,2,3,4。
步骤2限制模板图像尺寸。
由于3种类型针式打印图片的尺寸,尤其是宽度差异较大,为避免模板图像的宽度超过待检测图像,而导致无法匹配,需在匹配之前增加限制模板图像尺寸的操作。
其中,m表示待检测图像的宽度。
步骤3计算相似度。
使用归一化相关系数匹配法评估模板图像(T)与待检测图像(I)中重叠部分的相似程度。将待检测图像从左上角开始按照模板图像尺寸逐像素滑动,计算两者之间的相关系数,得到相关系数结果矩阵R。
在相关系数计算公式中,T'(i',j')和I'(i+i',j+j')的计算公式如下:
其中,0<i≤m-M+1,0<j≤n-N+1,0<i',i″≤M,0<j',j″≤N。
步骤4查找最佳匹配位置。
计算结束后,相关系数结果矩阵中最大值的位置即为最佳匹配位置,是待检测图像中与模板图像相似度最高的位置,在待检测图像中两部分模板图像中间的区域即为所要提取的文本区域。图像匹配结果如图4所示。
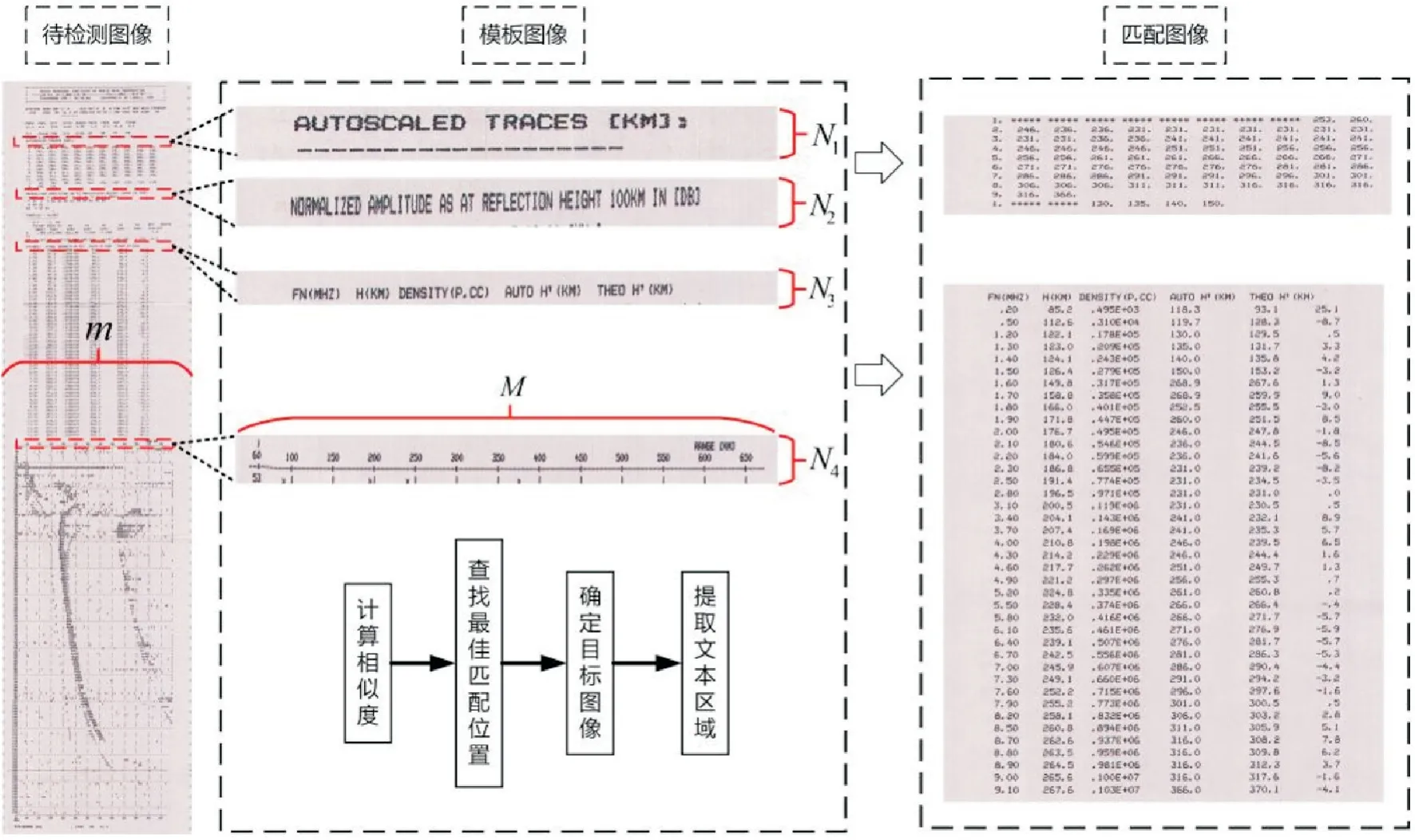
图4 图像匹配示意图Fig.4 Image matching diagram
2.1.2 降噪处理
因为原始纸质数据报表因存储原因,存在竖纹、褶皱、虫咬、墨迹模糊等问题,同时在扫描成图片时受到光线等外界因素干扰,3种类型图片都包含某种程度的噪声,除此之外,粉红色底纹背景拥有较多的椒盐噪声,这些都会给后续文本识别造成干扰。本文首先采用均值滤波技术进行噪声抑制或者去除,通过选择3×3的卷积核,重新计算卷积核区域内(i,j)位置的像素平均值pi,j。
然后采用加权平均法对滤波处理后的图像进行灰度化,将三通道的彩色图像变为一个通道的灰度图像;再采用二值化算法将灰度图像转换成二值图像。最后,使用图像形态学腐蚀算法,进一步消除噪声点,同时突出图像中文本区域的边界信息,为后续图像的倾斜矫正做好准备,处理效果如图5所示。
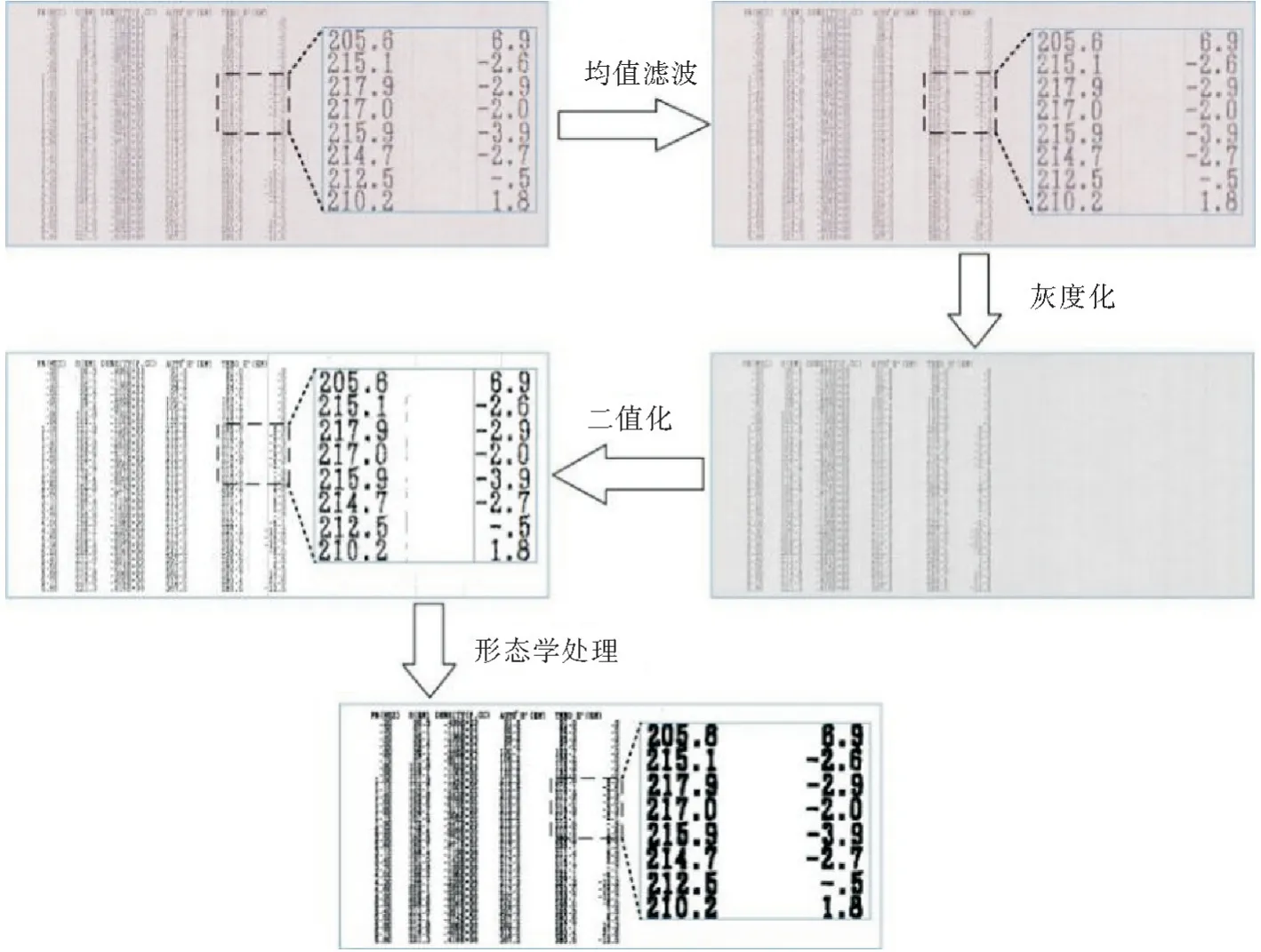
图5 降噪处理效果图Fig.5 Noise reduction processing effect picture
2.1.3 倾斜矫正
因原始纸质数据报表在电子扫描过程中难免出现倾斜,影响后续文本识别,以及结果可视化标记和存储,因此需要对降噪处理后的图片进行倾斜矫正。由于模板匹配得到的文本区域目标图像内没有辅助标志,区域外部也没有边框,缺乏矫正标志,因此首先需要构造与文本区域平行的横向直线。
步骤1构造标志横向直线。
在降噪处理阶段,已经通过图像腐蚀操作突出了文本区域的边界信息,而区域内的字符以行形式排列,通过图像边缘轮廓检测算法,可以找到图像中文本行的矩形轮廓,以此作为标志横线运用霍夫变换[17]进行直线检测,从而判断其倾斜角度。
步骤2计算倾斜角度。
在对匹配得到的目标区域进行形态学处理后,选择文本轮廓直线作为检测目标,记为L,以图像左上角端点作为原点建立直角坐标系,L任意一点的坐标记为(xi,yi),i∈(1,2,…,l),l表示点的数量。原点到L的垂直距离记为ρ,垂线与X轴夹角记为θ,则直线L的极坐标参数形式可表示为
为了过滤可能存在干扰的污点或者短直线,定义累加器S(ρ,θ),拥有相同参数(ρ,θ)的点通过S(ρ,θ)进行累加,选择S(ρ,θ)中最大值对应的直线,可计算出直线倾斜角度α,
步骤3计算仿射变换矩阵。
得到倾斜角度α后,选择图像中心点作为旋转中心,计算仿射变换矩阵M:
原始图像旋转之后,新图像的尺寸会发生变化,同时,图像中心点发生了变化,可能会导致丢失部分图像信息,因此需要计算图像中心位置偏移量(Δx,Δy),以便对旋转之后的图像进行平移操作。
利用图像中心位置偏移量(Δx,Δy),重新计算仿射变换矩阵M':
步骤4旋转矫正图像。
利用式(10)变换矩阵M',对原始图像中的点进行仿射变换,求得旋转之后的坐标为
其中,(u,v)表示原始图像中点(x,y)经过仿射变换后得到的新坐标。倾斜矫正结果如图6所示,红框区域即为矫正部分。
2.2 文本检测与识别
2.2.1 基于投影法的文本检测
经图像预处理后的针式打印图片便可进行文本检测操作,但因实际扫描的图片中存在一些相邻行之间出现粘连的现象,如图1(c)所示,这样无法有效实现整体文本检测,因此需要将检测识别的文本区域进行图像分割。
由于文本区域的字符是以文本行的形式排列的,在经过图像预处理后,排版相对工整,因此本文采用投影法来实现图像文本分割,通过对文本区域分别作横向投影和纵向投影的方式,在水平方向和垂直方向上统计图像内的像素点,根据统计结果判断文本边界,从而实现文本分割。具体实现过程如下:
步骤1垂直投影。
为避免数组被拆分,保持数组完整性,对二值化处理后的图像采用膨胀、腐蚀等形态学操作,然后对文本区域图像进行垂直投影,投影图像的像素集中区域就是字符区域,统计投影图像中的像素信息,根据像素点的峰值确定相邻列文本之间分割位置(横坐标),设置阈值tx,当像素峰值f(i)<tx时,即可定位每一列文本中数组的横坐标,实现文本区域的纵向分割,得到列文本。
步骤2水平投影。
对分割出来的列文本,采用闭运算操作尽可能放大文本行之间的空隙,然后进行水平投影,统计投影图像中的像素信息,根据像素点的峰值确定相邻行文本之间分割位置(纵坐标),设置阈值ty,当像素值f(j)<ty时,即可定位每一行文本中数组的纵坐标,以字符组的形式为切割标准,实现文本区域的横向分割。
步骤3文本检测候选框修正。
实际测试中,虽然经过投影操作,基本实现了图片中字符组的分割,但仍有部分粘连的文本区域未正确分割,因此可以通过图像形态学处理、调整投影阈值等进行优化修正。修正流程为:首先,统计所有候选检测框的尺寸,筛选出异常检测框,然后增大投影操作中的阈值tx,ty,重复上述步骤1-步骤3的步骤。
同时,统计正常检测框的高度,取其平均值作为标准值,若修正后仍然存在异常检测框,则按此标准值强制限制异常检测框高度,对粘连的文本区域进行分割。
通过上述方法流程,如图7所示,可以获得文本区域内每一组字符的具体位置,以实现文本检测。
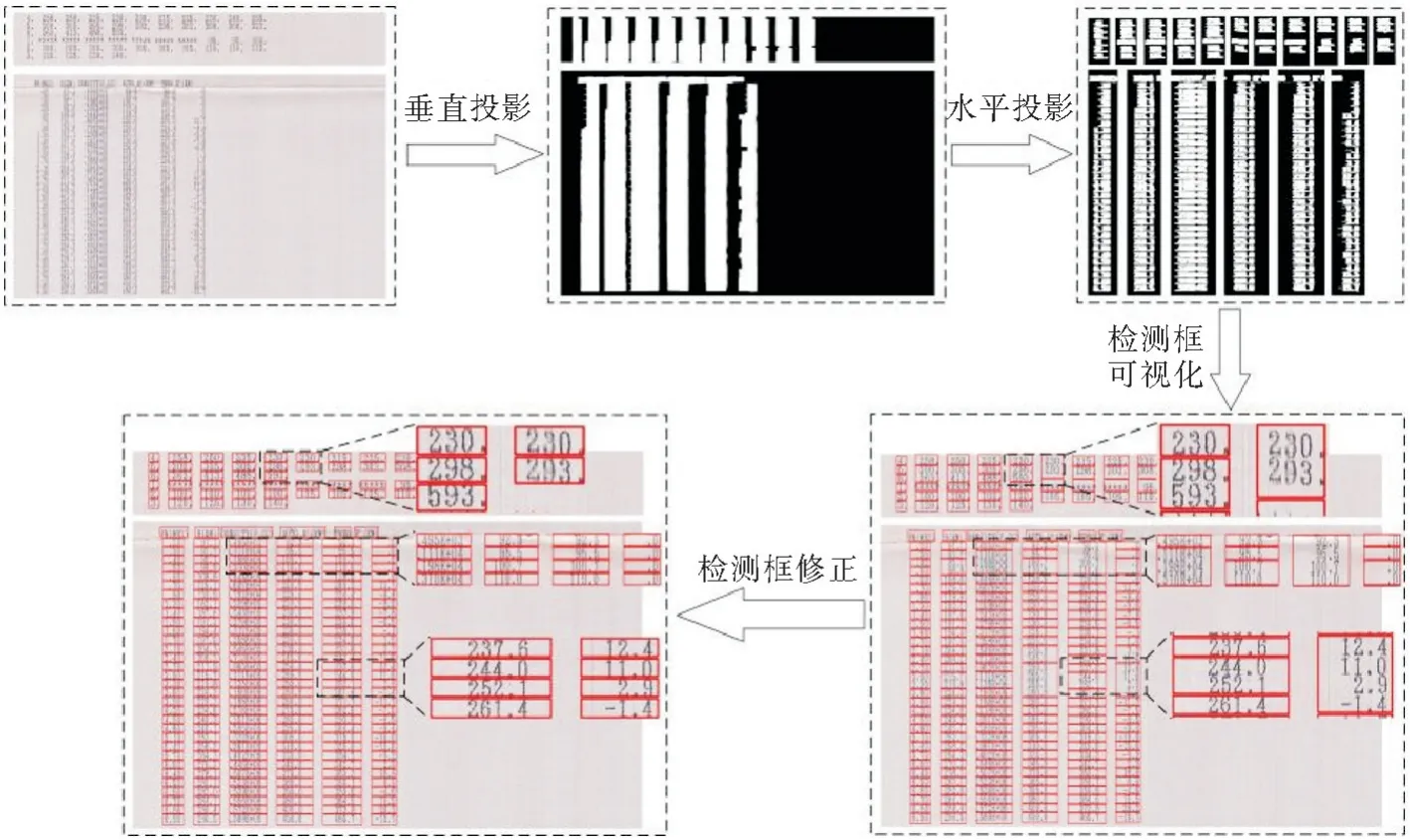
图7 投影分割文本检测流程图Fig.7 Projected split text detection flow chart
2.2.2 基于卷积循环神经网络(CRNN)的文本识别
因为分割后的针式打印图片的字符数据长度不一致,本文采用卷积神经网络(convolutional neural network,CNN)加循环神经网络(Recurrent Neural Network,RNN)的联合深度学习框架,即卷积循环神经网络CRNN,这样可以将分割后的文本识别问题转化为序列学习问题。与传统的CNN 神经网络模型相比,CRNN 可以实现对不定长文本序列的识别,不用先对单个文字进行切割标注,并且对于序列对象的长度无约束,只需要在训练阶段和测试阶段对高度进行归一化,适合解决图像的序列识别问题,从而完成端到端的文字识别。
CRNN 网络结构如图8 所示,包括卷积层,循环层和转录层三部分,各部分采取的架构分别是卷积神经网络、双向长短期记忆网络(bi-directional long short-term memory,BiLSTM)和连接机制时间分类(connectionist temporal classification,CTC)。
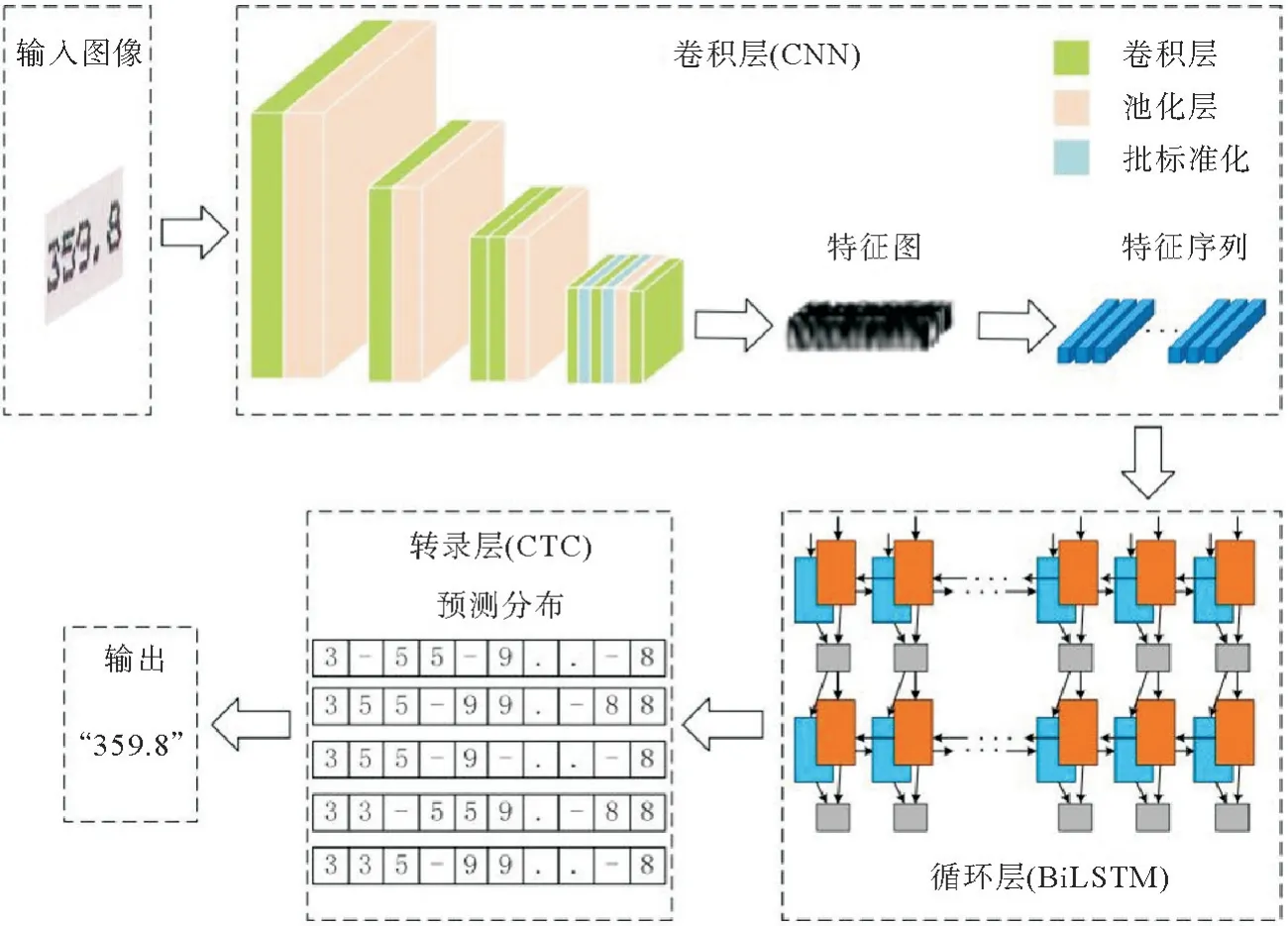
图8 CRNN模型流程图Fig.8 CRNN model flow chart
1) 卷积层。
该部分的作用是从输入图像中获得特征图序列,它通过对文本检测后的针式打印图片进行7次卷积,4次最大池化操作,提取图像的特征图,因为特征图中每个向量表示图像上一定宽度的特征,按照从左到右的顺序描述输入图像的局部区域,进而转化成特征序列作为循环层的输入。
2) 循环层。
该部分的作用是利用BiLSTM 预测从卷积层获取的特征序列的标签概率分布,作为后面转录层的输入。这里使用BiLSTM 来代替传统的RNN(Recurrent Neural Network,循环神经网络),是因为它作为RNN 的一种变体,相比于RNN 网络,可以防止训练时的梯度消失现象,同时增加网络层数可以有效的提升识别准确率。将文本识别问题转化为序列学习问题,对图像进行文本序列识别,避免了CNN 等传统算法中难度较高的字符切分和识别过程。另外文本区域的数组长度不同并且某些电离层数据既和之前的信息有关,也和后面的信息有关,而BiLSTM 具有记忆性,能够获取上下文信息,为不定长的数据提供有效建模能力,可以处理可变长度的序列数据。
3) 转录层。
该部分的作用是利用CTC 将循环层得到的预测概率分布转换成标记序列,它实际上是模型的损失函数,通过最小化损失函数,训练由CNN 和BiLSTM 组成的网络。输入的针式打印图片由于字符间隔、图像变形等问题,可能会导致字符被重复识别多次,经过卷积层和循环层得到的字符会大于实际的字符数,而CTC的空白机制使用“-”符号将重复的字符分隔开,可以将循环层得到的概率分布进行整合,去除空格和重复,从而得到最终的识别结果。
2.3 版面处理
实际工作中,检测识别后的数据需按照垂测数据报表的标准格式存储,因为保存成标准化格式不仅可以更好的保护数据资料安全,而且将其存入历史数据库中对完善电波环境历史数据以及后期的数字化管理和数据挖掘奠定重要基础,能更好发挥历史观测数据的科研价值。
针对本研究的针式打印图片的特点,虽然文本区域没有表格线,但是字符文本呈现有规律的表格结构排列,采用坐标融合的方法完成整个版面的识别:对图片预处理后得到的文本区域进行文本检测时,提取每个检测框的坐标信息;然后统计文本区域内所有字符文本的坐标信息,得到文本区域内的表格结构;每个检测框和表格结构一一对应,确定每组字符文本在图片中的位置。具体过程如下:
首先,用rect(i,j)表示检测矩形框的中心位置
其中,i=1,2,3,…,c;j=1,2,3,…,r;r和c(i2,j2)分别表示检测矩形框rect(i,j)左上角和右分别表示文本区域内的行和列;(i1,j1)和下角的坐标。
然后,如果两个检测矩形框中心位置的坐标满足式(13)时,就可以确定它们之间的相对位置。所有检测框两两满足式(13)后,进而可以确定整个文本区域的表格结构。经过文本识别记录了文本区域所有位置字符的识别结果,经过坐标融合,每组字符文本识别结果与表格结构中的位置一一对应,将识别结果按照相应位置写入,处理结果如图9所示。
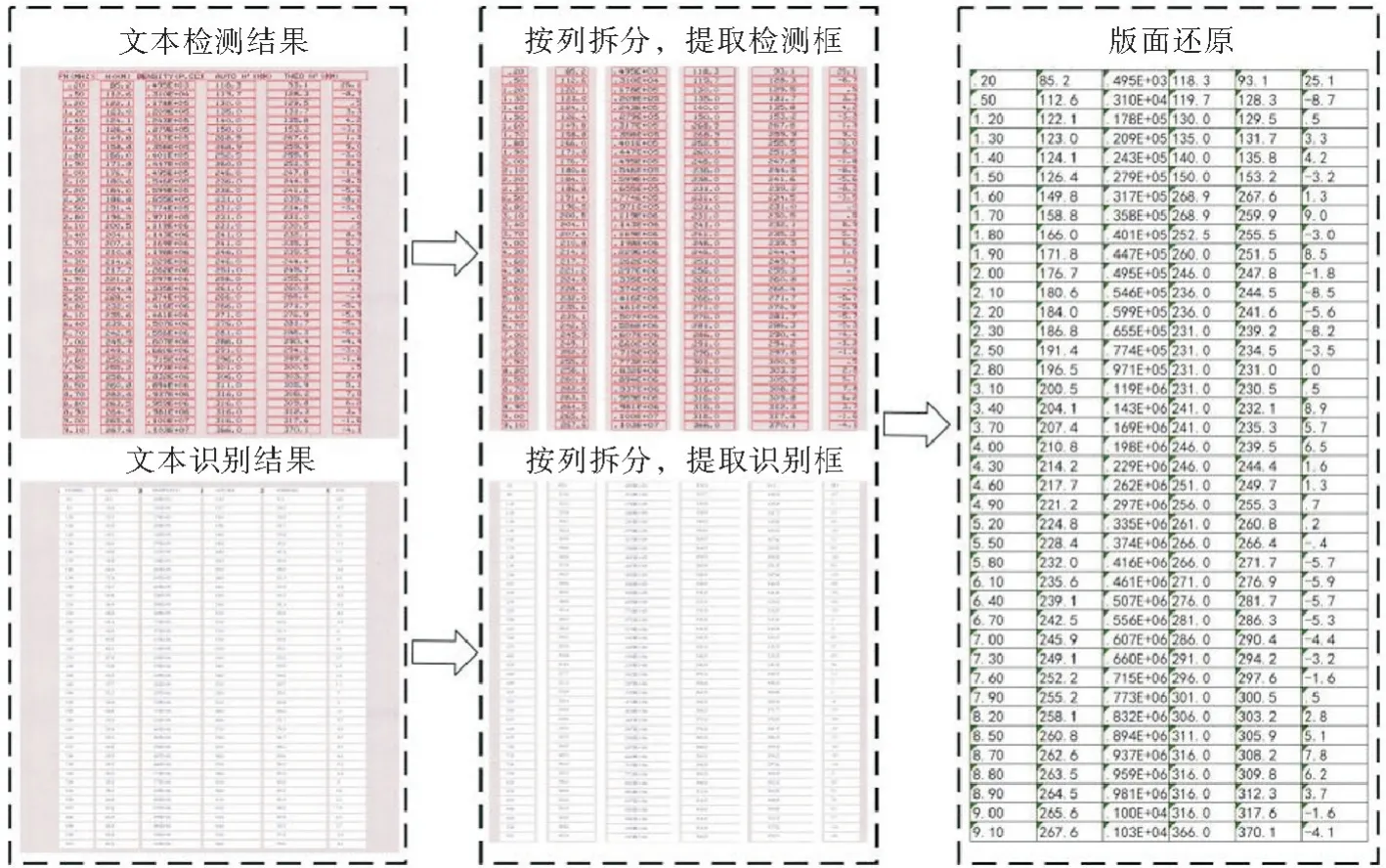
图9 版面结构还原Fig.9 Layout structure restoration
其中,tc=i2-i1+i'2-i'1,表示文本区域相邻列之间的间隔阈值,tr=j2-j1+j'2-j'1,表示文本区域相邻行之间的间隔阈值。
3 实验结果
3.1 实验环境
本工作采用百度飞桨PaddlePaddle深度学习框架进行实验测试,具体计算机设备的硬件配置和所搭建的软件环境如表1所示。
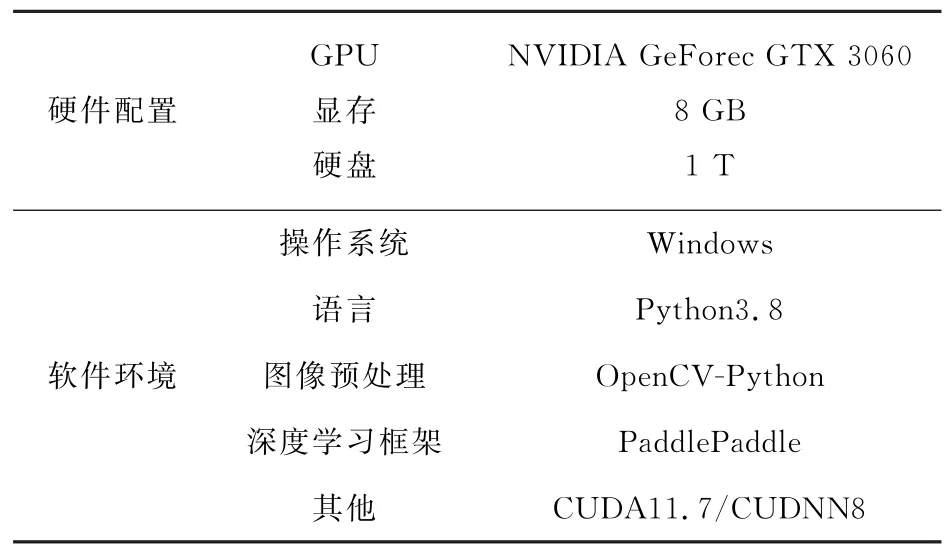
表1 硬件配置及软件环境Table 1 Hardware configuration and software environment
CRNN 算法的网络结构详细参数如表2所示,其中W代表输入图像宽度,k代表卷积核的尺寸,s表示步幅,p表示填充尺寸,Windows表示池化窗口尺寸。
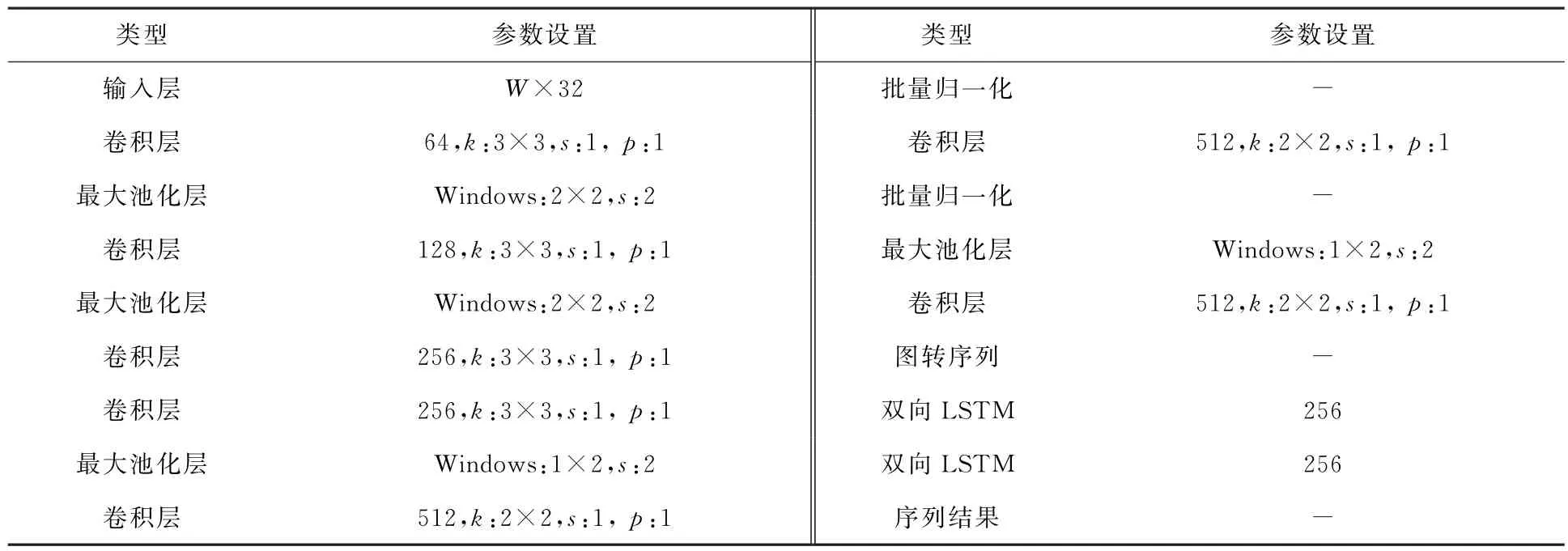
表2 CRNN网络详细参数Table 2 CRNN specifies network details
3.2 实验数据
为验证本工作方法对电离层针式打印字体垂测历史观测数据扫描图片的识别效果,采用中国电波传播研究所留存的真实资料进行训练测试。
考虑到3种类型针式打印图片的差异,为保证训练时CRNN 深度学习模型有较高的泛化能力,各选取每种类型图片28张,共计84张,经本工作中给出的图像预处理和文本检测算法操作后,共分割得文本数据25 324张,如表3所示,对分割后的图片采用PPOCRLabel来作标签标记,得到对应的字符串标签字典。然后从各类型图片中随机选择65.47%(即,原始图片55张,分割后的图片16 670张)的图片作为训练集用于训练模型以及确定参数,16.67%(即,原始图片14 张,分割后的图片4 169张)的图片作为验证集用于确定网络结构以及调整模型的超参数,17.86%(即,原始图片15张,分割后的图片4 485张)的图片作为测试集用于检验模型的泛化能力,评估算法性能。为了结果分析时描述方便,这15张测试图片使用a1-a5、b1-b5、c1-c5编号,分别表示第一章节数据介绍中给出的3种类型针式打印图片。
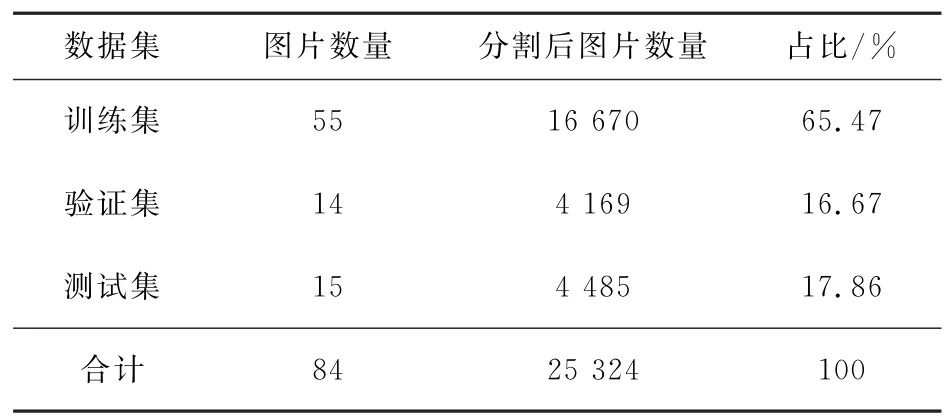
表3 数据集分配Table 3 Data set allocation
3.3 实验结果及分析
3.3.1 评价指标
为评价算法的性能,本工作选用精确率P、召回率R以及综合评价指标F3个评价指标进行评估,其中F是综合精确率P和召回率R这二者指标的评估指标,用于综合反映整体的指标。
为验证本工作所提算法在3种类型针式打印图片数据自动提取的有效性,与其他精度较高的算法从文本检测和文本识别两个方面进行了对比分析。
3.3.2 文本检测结果分析
在文本检测参数设定方面,由于针式打印图片文本区域列间距较大,垂直投影阈值tx影响较小,而行间距较小易存在粘连情况,此时水平投影阈值ty取值对检测结果影响较大。在图10中,将文本检测平均召回率绘制为水平投影阈值ty的函数。设置ty初始值为25,通过异常检测候选框修正模块,将ty增大到30,文本检测平均召回率随之升高,算法运行时间也随着ty增大而增加。随着ty增大到35,水平投影阈值ty处于(25,35]区间内的完整数组也会被分割,导致一些异常检测候选框过度修正,因此检测召回率有所下降,算法运行时间也会增加。因此,在文本检测异常候选框出现时,将水平投影阈值ty设置为30。
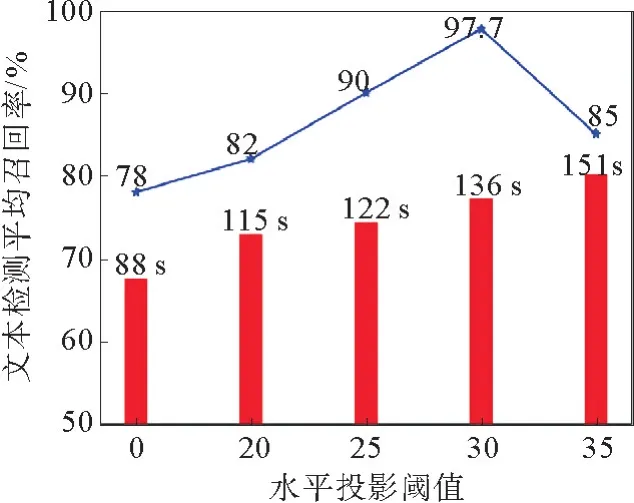
图10 5种水平投影阈值设定对比Fig.10 Comparison of 5 horizontal projection threshold settings
在文本检测结果方面,本研究提出的基于投影分割的检测算法与文献[9]中的EAST 算法(efficient and accuracy scene text)、文献[10]中的DB算法(differentiable binarization)在15张原始测试图片(4 485张分割后图片)上的检测召回率对比情况如图11所示。
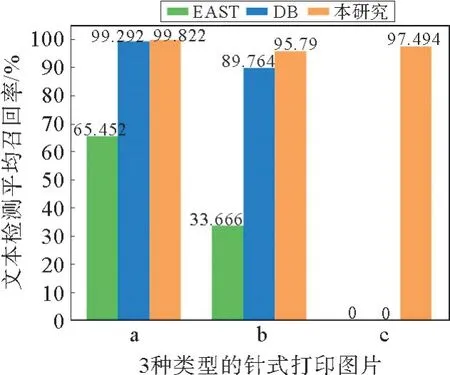
图11 不同文本检测算法平均召回率对比Fig.11 Comparison of average recall rates in different text detection algorithms
从图11中可以看出:1)在a类型图片中,本研究算法召回率接近100%,略优于DB 算法,明显高于EAST 算法;2)在b类型图片中,本研究算法平均召回率95.79%,与DB 算法相比,优势较a类型图片相比进一步扩大,而EAST 算法检测性能进一步下降;3)在c类型图片中,对于相互粘连的针式打印图片,EAST 算法和DB 算法均不能检测出文本行,而由于提出的基于投影分割的文本检测方法加入了检测候选框的修正功能,所以对该类型图片检测效果显著,平均召回率97.49%。通过对比3 种类型图片的检测效果,表明在文本检测方面本研究算法具有一定的先进性和普适性,在工程实践中具有更好的泛化能力。
3.3.3 文本识别结果分析
在文本识别方面,统计结果分析包括两种情况:①单个字符识别情况(即,以图片文本区域内的单个字符为统计单元,判定识别是否正确,包括小数点);②整组字符识别情况(即,以一个数组为统计单元,如果数组内有一个字符识别错误,则整个数组判定为识别错误)。本工作在15张原始测试图片(4 485张分割后图片)上从精确率P、召回率R以及综合评价指标F3 个层面,对比分析了本研究所提CRNN 识别算法在DB 检测算法[10]与本研究检测算法基础上的文本识别效果(记为:情形Ⅰ对比分析),结果如图12、13所示,以及所提CRNN 识别算法和RARE识别算法[18]在本研究检测算法基础上的文本识别效果(记为:情形Ⅱ对比分析),结果如图14、15所示。
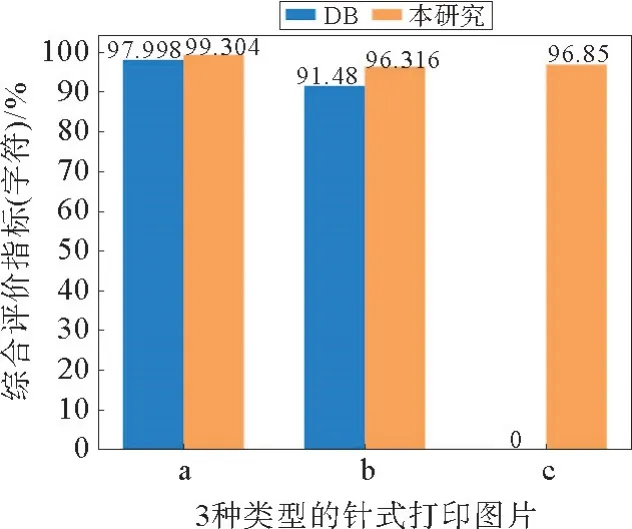
图12 基于DB和本文检测算法的单个字符识别平均F-Measure对比Fig.12 Average F-Measure comparison of character recognition based on DB and detection algorithm in this paper
1)情形Ⅰ对比分析。
从图12就单个字符识别情况可以看出:①在a类型图片中,DB 算法平均综合评价指标F为97.998%,本研究算法平均99.304%,相差1.306%,可见2种算法效果相似;②在b类型图片中,DB算法平均综合评价指标F为91.48%,本算法平均96.316%,相差4.836%,可见本算法与DB算法相比,较a类型图片,识别效果优势进一步扩大;③在c类型图片中,因为DB算法对于相互粘连的针式打印图片不能检测出文本行,所以就无法统计文本识别效果,而本研究提出的算法平均综合评价指标F为96.85%,识别效果性能优异,可以满足实际工程需求。
从图13就整组字符识别情况可以看出:①在a类型图片中,DB 算法平均综合评价指标F为95.374%,本工作算法平均97.506%,相差2.132%,均比单个字符识别情况有所降低;②在b类型图片中,DB算法平均综合评价指标F为74.204%,本算法平均92.69%,相差18.486%,相比a类型图片,DB算法降低幅度较大,本工作算法更稳健,与DB算法相比,识别效果优势进一步扩大,识别效果良好;③在c类型图片中,提出的算法平均综合评价指标F为94.146%,与单个字符识别情况相比仅下降了2.704%,整体性表现良好,算法识别效果显著,完全可以胜任实际工程。
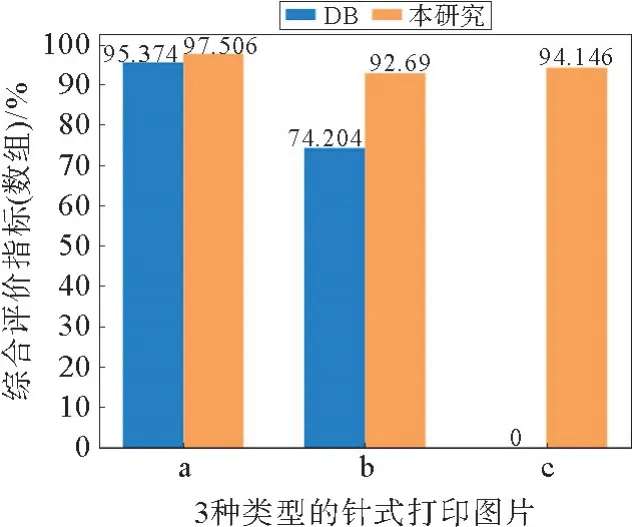
图13 基于DB和本文检测算法的整组字符识别平均F-Measure对比Fig.13 Average F-Measure comparison of array recognition based on DB and detection algorithm in this paper
对比实验表明,对于3种类型的针式打印图片,本工作所提CRNN 识别算法在2.2.1小节文本检测算法基础上的识别效果明显优于DB检测算法。
2)情形Ⅱ对比分析。
从图14就单个字符识别情况可以看出:①在a类型图片中,RARE 算法平均综合评价指标F为98.74%,CRNN 算法平均 99.304%,相差0.564%,识别效果相似;②在b类型图片中,RARE算法平均综合评价指标F为94.02%,CRNN 算法平均96.316%,相差2.296%;③在c类型图片中,RARE算法平均综合评价指标F为91.386%,而CRNN 算法平均综合评价指标F为96.85%,相差5.464%。
从图15就整组字符识别情况可以看出:①在a类型图片中,RARE 算法平均综合评价指标F为95.108%,CRNN 算法平均 97.506%,相差2.398%;②在b类型图片中,RARE 算法平均综合评价指标F为89.896%,CRNN 算法平均92.69%,相差2.794%;③在c类型图片中,RARE算法平均综合评价指标F为91.574%,CRNN 算法平均综合评价指标F为94.146%,相差2.572%。较单个字符识别情况有所降低,但CRNN 表现出了更优异的性能。
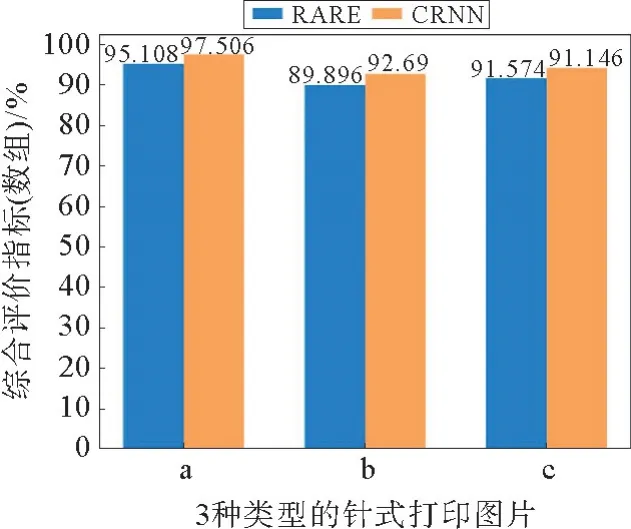
图15 基于RARE和CRNN算法的整组字符识别平均F-Measure对比Fig.15 Average F-Measure comparison of array recognition based on RARE and CRNN algorithm
通过对比实验表明,对于3种类型的针式打印图片,本工作所提CRNN 识别算法在2.2.1小节文本检测算法基础上的识别效果明显优于RARE 识别算法,可以应用于实际工程。
4 结语
针对3种类型的针式打印字体电离层垂测数据扫描图片,提出了一种基于深度学习框架的数据自动提取技术。首先,通过图像模板匹配,准确提取图片中电离层物理特性的文本区域,然后利用霍夫变换直线检测对降噪处理后的文本区域进行倾斜矫正,在此基础上采用基于投影法的文本检测算法对图像进行分割,可有效解决针式打印字体电离层垂测数据扫描图片相邻行之间互相粘连的问题,最后对分割后的图片利用CNN+RNN+CTC 构成的CRNN 深度学习算法进行文本识别,同时通过坐标融合算法将识别后的数据存储成Excel标准格式。实验结果表明,本工作提出的算法对于各种类型的针式打印图片具有更好的检测和识别效果,实用性和适应性更强,完全可满足实际工程应用需求。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
商品与质量(2021年5期)2021-11-23
数学物理学报(2021年1期)2021-03-29
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
少儿美术(快乐历史地理)(2018年7期)2018-11-16
中国美容医学(2018年7期)2018-10-31
