
DFNet:高效的无解码语义分割方法
2024-03-05 08:15刘腊梅杜宝昌黄惠玲章永鉴韩军
液晶与显示 2024年2期
刘腊梅, 杜宝昌,, 黄惠玲, 章永鉴,3, 韩军*
(1.辽宁工程技术大学 软件学院, 辽宁 葫芦岛 125000;2.中国科学院 海西研究院 泉州装备制造研究中心, 福建 泉州 362000;3.厦门理工学院 电气工程与自动化学院, 福建 厦门 361024)
1 引言
语义分割是计算机视觉领域的关键任务之一,是对图像像素级的识别和理解。得益于卷积神经网络的特征提取能力以及深度学习技术的迅速发展,分割方法层出不穷[1-3]。然而,在不同的分割方法下,却都有着相似的“编码器-解码器”结构。
在“编码器-解码器”结构的分割网络中,分割任务大致划分为两个阶段:编码阶段——图像经神经网络编码以及下采样获得深层次语义信息;解码阶段——深层语义信息上采样获得与输入图像同等大小的分割掩码。Long[4]等人所提出的全卷积网络FCN是编解码结构的最早典型,其将原分类网络的全连接修改为全卷积,通过转置卷积联合低级特征上采样实现像素级预测。Ronneberger[5]等人针对FCN缺乏空间一致性等问题提出的“U”型分割网络U-Net以及Badrinarayanan[6]等人针对道路分割问题提出的分割网络SegNet,这两种更为典型的编解码分割网络都是采用与编码器完全对称的扩张路径作为解码器,然后联合对称位置编码特征上采样补充空间信息,从而获得高精度分割掩码。最新的基于Transformer[7]的分割模型,如Zheng[8]等人提出的序列到序列分割模型SETR、Xie[9]等人提出的基于金字塔结构的分割模型SegFormer和Wang[10-11]等人提出的轻量分割模型PVT,普遍也是采用编解码的结构形式。此外,在目前性能较优的分割模型中,在保留“编码器-解码器”结构的基础上还会引入一种新的解码器后端,如Zhao[12]等人提出的分割网络PSPNet和Chen[13]等人提出的分割网络DeepLabv3+,这两种方法都是在保证编解码结构的基础上引入一种新的解码器后端(池化金字塔),从而取得比全局信息更有代表性的多比例上下文信息,提高模型分割精度。
然而,“编码器-解码器”结构虽能够保证模型分割精度,但仍然存在一些问题。首先,编码器的编码特征通常具有较大的通道数和较小的宽、高,这会导致解码器的结构引入大量的参数,从而增加了计算量。其次,在解码器的转置卷积和上采样过程中,语义信息和细节很容易丢失,并且在一定程度上会传播噪声,从而严重影响解码过程的重构效率。最后,对于二值分割任务,由于其分割样本相比常规分割任务相对简单,因此复杂的解码结构可能并不能提高分割精度,反而会增加计算量,从而影响分割的速度。Shubhra[14]等首先针对上述问题提出D2SNet模型,并相应取得了较好的效果,但是由于算法的复杂低效以及模型本身的冗余,使得D2SNet模型应用严重受限。
为解决上述编解码结构以及现有分割网络所存在的问题,本文提出了一种基于ResNet50的高效无解码的二值分割网络DFNet(Decoder-free Net)。该模型摒弃了现存主流分割网络中的各式跳跃连接和复杂解码结构,转而采用卷积重塑上采样模块(Convolution Remolding Upsampling,CRU)直接重塑最终编码特征生成分割掩码,从而简化分割模型结构,减少可学习参数,提高模型分割检测速度。又因CRU模块需要利用信道和空间信息,因此在编码器中进一步融合轻量双重注意力模块EC&SA提高信道以及空间信息交互,增强网络编码能力。最后再引入损失系数可根据任务特性动态调整的扰动交叉熵损失PolyCE,使得损失系数根据当前任务自适应达到最优,有效解决二值分割正负样本不均衡问题,提高像素分割预测准确率。
2 模型结构
DFNet模型整体结构较为精简,Input在经过网络编码以及卷积重塑上采样CRU模块后,直接得到分割掩码,如图1所示。其中,模型详细流程如下:首先使用融合EC&SA注意力的ResNet50编码网络对输入图像提取特征,得到C×H/s×W/s大小的特征编码,s为编码网络下采样倍数;其次通过卷积重塑上采样模块CRU,得到2×W×H大小的分割掩码;最后按照通道方向进行最大值索引,从而得到H×W大小的最终分割结果Output。

图1 DFNet网络模型结构Fig.1 Structure of DFNet network
2.1 卷积重塑上采样CRU
在语义分割算法中,双线性插值和反卷积是上采样操作以及生成分割掩码中最常用的方法。但双线性插值不具有可学习参数,且忽略了标签像素点之间的关系,对每个像素的精确恢复能力较弱;反卷积网络虽引入了可学习参数,但在解码阶段会引入大量无效信息,并且容易导致网格效应,不利于梯度优化。本文引入卷积重塑上采样CRU模块,将特征编码经1×1卷积通道调整后,重塑通道和空间信息补充分割细节以生成分割结果,提高模型效率。
CRU模块是以低分辨率h×w大小的特征图作为输入,生成H×W大小的标签图。假设输入特征图的维数为C×h×w,通过1×1卷积运算后输出特征图维度变为(C×s2)×h×w,然后再利用周期筛选[15](Periodic Shuffling,PS)将上述调整通道后的特征图重塑成C×H×W大小的分割掩码,从而简化了分割网络的解码结构,提高模型的运行效率。图2(a)以单通道图像为例,描述了C=1,s=2时的CRU模块结构;图2(b)则描绘了常规情况下的CRU模块结构。从图2也可看出,CRU模块利用特征编码通道间的相邻像素信息直接重塑为最终结果,其中h=H/s,w=W/s,s是下采样因子。

图2 卷积重塑上采样模块Fig.2 Convolutional reshaping upsampling module
在本文的二值分割任务中,s=32,C=2。首先输入图像经过网络编码器,生成一个大小为c×h×w的特征编码,生成的特征编码再经过1×1卷积将通道调整为c×s2,从而特征编码维度变为(c×s2)×h×w,再通过周期筛选后生成大小为C×H×W的分割掩码。
周期筛选的数学过程如式(1)所示,其中F为输入特征编码,r为上采样倍数,PS(F)(x,y,c)为坐标(x,y,c)上的输出特征像素,λ默认为1。从公式可看出,周期筛选是直接按照一定规则重塑特征编码像素位置实现快速上采样,在不引入额外参数的前提下,减小模型计算量,从而提高网络分割效率。
2.2 轻量双重注意力EC&SA
ResNet50[16]残差网络是何凯明等人提出的,其主要思想是在网络中添加跳跃连接形成残差结构,从而允许原始的特征信息可以直接传递给深层网络,有效避免信息的损失,简化学习的目标和难度,并在一定程度上解决了反向传播中梯度消失和梯度爆炸的问题。然而,单纯依靠编码器ResNet50的自身特征提取能力是不够的,因为CRU模块会重塑特征编码像素位置来实现快速上采样,因此需要特征编码通道和空间信息完善分割掩码细节。此时采用一个合适的注意力机制可以有效地提高网络性能。
ECA[17]注意力模块主要是对SE[18]注意力模块进行改进,提出的一种不降维的跨通道交互策略。该模块避免了通道压缩降维带来的影响,采用一维卷积替代共享全连接层,增加少量参数,实现跨通道信息交互,提高模型精度。ECA结构如图3所示,其中为卷积核大小为K的一维卷积。

图3 ECA结构图Fig.3 ECA structure diagram
但单纯的通道信息交互不足以满足CRU模块空间信息需求,本文在不引入大量计算参数下添加轻量空间注意力算子ESA(Efficient Spatial Attention Operator),使其提高空间信息的交互。如图4所示,ESA由通道池化、3×3空洞卷积以及S激活函数3部分组成。将特征编码按照通道方向分别做最大和均值池化,获得2×H×W大小的通道池化矩阵;再进行空洞卷积运算,综合空间信息;最后经S激活函数获得空间权重系数掩码。对于ESA中的卷积,本文采用大小为3、空洞率为2的空洞卷积替代常规卷积,从而实现在引入极少参数的同时有效地扩大感受野且保障空间信息连续,提高像素间信息交互[19]。

图4 ESA空间注意力算子Fig.4 Efficient spatial attention operator
EC&SA模块最终结构如图5所示。可以看出,EC&SA模块保留了高效通道注意力模块原始的通道增强运算,因此中间层的特征编码首先通过高效通道注意力ECA模块获得通道权重系数进行通道增强,其次再次通过ESA获得空间权重系数来增加像素间的空间信息交互。
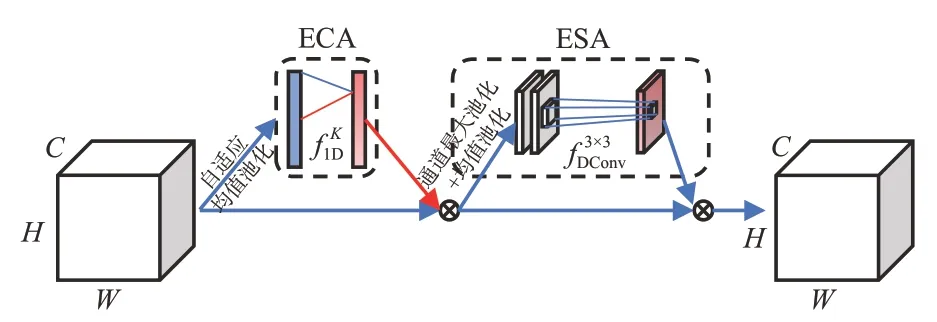
图5 轻量双重注意力EC&SAFig.5 Lightweight dual attention EC&SA
EC&SA在引入少量参数下增强了编码网络对通道信息和空间信息整合能力,提高了相邻像素间的信息交互,因此将EC&SA加入编码网络ResNet50的残差结构中,能有效提升网络特征提取能力。改进后的ResNet50残差结构如图6所示。

图6 改进后的残差结构Fig.6 Improved residual structure
2.3 扰动交叉熵损失PolyCE
对于二值分割任务而言,分割前景所占真实标签整体的比例通常较小,因此会存在严重的正负样本不平衡,从而容易导致分割掩码偏向于背景类别,导致模型分割精度降低。在分割任务常用的损失中,如CE Loss和Focal Loss等,也都存在一个关键问题:回归项前的系数对于所有的模型和任务来说都是固定的,但不一定是最优的。为解决上述问题,本文引入扰动交叉熵损失[20]PolyCE。
扰动交叉熵损失PolyCE的灵感来源于交叉熵损失CE Loss等损失的泰勒展开(式(2)),其主要是通过泰勒展开式来逼近目标函数,对损失的表示提供了与回归的直观联系,使CE Loss在一定程度上可以解释为预测值到真实值距离的j次幂的加权集合。如式(3)所示,PolyCE损失将损失函数看成多项式函数的线性组合并添加动态调整系数εj,使多项式基的重要性很容易地根据目标任务和数据进行调整,进而提高模型精度,其中Pt代表预测概率。
本文使用PolyCE损失函数替代常用的交叉熵损失CE Loss,使二值分割能根据分割任务特点动态调整为最优损失系数,有效解决正负样本不均衡问题,提高各类像素分类准确率,从而提高模型最终分割精度。其中本文所采用的是N=1的情形。
3 实验准备
3.1 数据选取
为验证模型二值分割任务的泛化性,本文主要使用部分常见的二值分割任务数据集进行实验,如遥感分割数据集DeepGlobe[21]、Mas Roads[22]以及缺陷检测数据集CrackForest[23]、FALeather进行验证,其中FALeather由本实验室与相关企业联合采集制作。
DeepGlobe和Mass Roads同为道路分割数据集,其中DeepGlobe包含6 226张分辨率为1 024像素×1 024的训练图像,Mass Roads包含1 171张分辨率为1 500像素×1 500像素的训练图像。为使数据适用于模型,通过重叠为256像素的512×512滑动窗口将每幅图像划分为同分辨率图像,并且去除无用数据,然后再将截取划分后的数据按8∶2的比例划分训练和测试集,即DeepGlobe训练集44 827张和测试集11 027张,和Mass Roads训练集12 732和测试集3 138张,划分后的训练集和验证集重合。CrackForest包含11 298张448像素×448像素的训练图像,FALeather包含1 940张512像素×512像素皮革图像。同按8∶2划分,即CrackForest训练集9 038张和测试集2 260张,FALeather训练集1 552张和测试集388张。
3.2 参数设定
DFNet模型代码基于Pytorch 1.9.0深度学习框架编写。采用Ubantu18.06操作系统,CPU型号为Intel i9-10900X@3.70 GHz×20,显卡型号为NVIDIA GeForce RTX 3090 24 GB,系统内存128G。实验参数:输入图像大小为512像素×512像素的彩色图片,batch_size大小为32,编码器采用预训练模型,CUR中的1×1卷积采用初始化且无偏置,初始化学习率为1e-4,学习率调整策略为前200 Epochs固定学习率,后100 Epochs学习率断崖式衰减,采用Adam优化器,优化器运行平均值的系数为betas=(0.9,0.999)。
3.3 评价指标
在二值分割任务中,将分割图像的像素分为真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN),并与对应真实标签进行比较。根据二值分割任务的特点,最终选择以F1-Score和IOU作为主要评价指标,TPE和FPS作为辅助评价指标,如表1所示。

表1 评价指标Tab.1 Evaluation index
TPE(Time for Per Epoch)是本文自定义评价指标,指模型在一定的训练数据集下完全前向传播一次所需的时间(单位s)。FPS是指模型单位时间内处理图像的数量。
4 实验结果分析
通过消融实验验证模型及改进方案对于分割精度和速度的有效性。选取FCN[4]、U-Net[5]、PSPNet[12]、D2SNet[14]、EANet[24]和DeepLabv3+[13]六种主流分割模型与本文模型进行对比实验,验证模型分割效果,并围绕实验结果对模型进行定量和定性分析。
4.1 消融实验
为验证卷积重塑上采样模块CRU、轻量双重注意力EC&SA、扰动交叉熵损失PolyCE三处改进的有效性,本文在ResNet50作为模型编码器且不采用复杂解码结构和跳跃连接的基础之上,将其分为4种情况进行消融实验:(1)仅采用CRU模块,并为验证该模块作为分割头(Head)的有效性,加入FCN和DeepLabv3+分割头进行对比;(2)在以CRU模块作为分割头的基础上,采用EC&SA注意力,并为验证该注意力机制的有效性,加入其他以及改进前的注意力机制进行对比;(3)在以CRU模块作为分割头的基础上,采用Poly1CE损失;(4)CRU模块、EC&SA注意力和PolylCE损失全部采用。4种实验均在本文实验所采用的二值分割数据上进行,消融实验结果见表2。

表2 消融结果Tab.2 Ablation results %
从表2可以看出,在模型采用CRU模块作为分割头时,其分割精度要高出FCN和Deep-Labv3+分割头约5%。DeepLabv3+分割头虽然在FCN分割头的基础上引入了空洞空间卷积池化金字塔(ASPP)模块,扩大了感受野,但是因为ResNet50下采样倍数较大,并且同FCN分割头使用卷积压缩高维通道,使通道数变为2,之后再使用双线性插值上采样到原图大小以实现分割,因此容易丢失大量高维信息细节,导致分割精度不佳。CUR模块则不同于上述两个分割头,直接通过对ResNet50的特征编码进行通道升维,补充周期筛选后的分割掩码空间信息细节,以提高模型精度和速度。在CRU作为分割头的基础上,仅引入EC&SA注意力机制可使F1-Score和IoU提升约1%~2%,比其他通道注意力机制所带来的性能提升更为明显,如SE注意力模块只带来约0.3%~1%的提升,原始的ECA也只是带来些许提升,从而说明本文针对模型需求改进注意力模块的有效性。在CRU作为分割头的基础上,若只引入Poly1CE损失,则F1-Score和IoU均能高约1%~2%;当全部采用时,其效果的提升要优于仅采用其中一种,从而可使模型精度得到更进一步的提升。
综上,通过实验精度的对比,本文提出的3处优化均可显著提高模型的实验结果,从而有效证明了这3处优化的有效性,也证明了针对二值分割任务特点进行优化的正确性。
4.2 定量分析
各个模型在不同数据集的分割精度对比结果见表3。从表3中各模型所示分割精度可以看出,本文模型在本文所采用的分割数据集上,基本都能取得与主流编解码语义分割模型相当的分割精度,甚至还超出部分分割模型。从Deep-Globe和Mas Roads的数据分割结果可知,相对于FCN和D2SNet,虽具有更为复杂解码结构以及新型解码后端的DeepLabv3+和EANet的分割会更高,但两者实际差异并不明显,特别是对于背景更为简单的FALeather数据,各模型精度基本在同一范围内持平。但对于本文模型,虽未采用解码结构以及跳跃连接,却取得了更优的分割结果,从而说明对于简单的分割任务,输入图像经编码器编码后,其自身已包含足够的通道及空间信息,无需额外结构进行补充。

表3 模型精度对比Tab.3 Comparison of model accuracy %
在模型参数、推理速度和综合精度方面,本模型与主流分割模型对比结果见表4。相对于主流分割模型,首先从表中参数和推理速度可以看出,在同等条件下,本模型在减少参数的同时,理论推理速度达到了94 FPS,远高出主流分割网络;其次从表中TPE指标也可看出,本模型在同批次数据上所需的训练时间也明显减少,比参数接近的D2SNet减少1/3,比U-Net减少近4倍,从而有效降低了网络训练成本;最后从模型在各数据集上的平均精度F1m(F1 mean)和IoUm(IoU mean)可以看出,对于二值分割任务,本模型具有更高的普适性。

表4 模型参数对比Tab.4 Comparison of model parameters
综上,本模型无论在推理速度上,还是在综合分割精度上,都远高出主流分割模型,有效提高了分割任务效率,减少了网络训练投入成本。
4.3 定性分析
我们在各个数据集上对分割模型FCN、Unet、PSPNet、D2SNet、EANet、DeepLabv3+(DLv3+)以及本文分割模型DFNet的预测结果进行了可视化,可视化结果见图7。图7中的红色框突出显示了本文模型分割表现优于主流分割模型的区域;图7中的蓝色虚线框突出显示了上述7种分割网络分割效果较差的区域。其中,蓝色方框区域具有较大争议性,如图7(b)所示。通过观察和比较输入图像,其自身也难以分辨是否真实包含分割目标,因此无法明确判断分割是否正确,CrackForest分割结果中的蓝色方框区域则是完全的分割错误,从而不确定性较大。因此,本文将其统称为分割效果不佳以方便对比。

图7 结果的可视化Fig.7 Visualization of results
从图7的红色方框标注区域可以看出,虽然本文分割模型并未采用复杂的解码结构以及跳跃连接,但是对于不同数据的细节把控却要优于其他分割模型。如图7(a)中道路分割结果所示,本文分割模型不仅能够精确地分辨出道路之间的联系,而且能够精确地分割出道路的形状和轮廓,从而使分割的结果更接近于真实标签。从图7的蓝色方框标注区域也可看出,主流分割模型分割不佳的情况要远大于本文网络,甚至在D2SNet中出现完全分割失败的情况。D2SNet出现上述情况的原因,很可能是因为在卷积过程中采用了过多的二维随机失活,这样会导致网络难以学习样本特征,从而导致分割效果不佳。
综上,对比不同模型的分割结果可知,本文模型能够满足二值分割任务需求,并且在某些方面还要远优于主流模型。对比实验也进一步说明,对于简单的二值分割任务,编码器的最终编码特征本身就已具有足够的细节信息,而无需额外的操作补充细节信息,联合上采样生成最终分割结果。
5 结论
本文提出了一种无解码器的高效实用的二值语义分割模型。该模型简化了主流分割模型结构,去除了分割网络中常用的复杂解码结构和跳跃连接,转而采用卷积重塑上采样模块CRU完成最终特征编码上采样生成分割掩码,从而在很大程度上减少了模型运算,提高了模型分割速度。融入改进后的轻量双重注意力机制EC&SA,因其引入了轻量空间注意力算子ESA,从而使其在原有的注意力机制ECA提高特征信道交互的同时增添了特征的空间交互,从而提高了编码特征相邻像素间的信息交互能力,使网络精度在原有的基础上提升1%~2%,高于改进前所带来的性能提升。采用扰动交叉熵损失PolyCE替代常规损失,使原有损失系数从固定变为自适应,从而通过训练和实现得到与本文模型最为适合的损失系数,从而有效提高模型的像素分割精度。最终模型的理论分割速度最高可达94 FPS,在多个数据集上的F1和IoU的分割精度平均值更是达到了84.69%和73.95%,与主流网络相当,极大提高了模型分割任务效率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
黑龙江大学自然科学学报(2021年4期)2021-11-19
高技术通讯(2021年2期)2021-04-13
通信学报(2019年5期)2019-06-11
测控技术(2018年10期)2018-11-25
通信技术(2018年3期)2018-03-21
传媒评论(2017年3期)2017-06-13
计算机应用(2016年10期)2017-05-12
第二课堂(课外活动版)(2016年2期)2016-10-21
浙江大学学报(工学版)(2015年4期)2015-03-01
