
基于自监督注意和图像特征融合的文本生成图像方法
2024-03-05 08:15廖涌卉张海涛金海波
液晶与显示 2024年2期
廖涌卉, 张海涛, 金海波
(1.辽宁工程技术大学 软件学院, 辽宁 葫芦岛 125105;2.汕头职业技术学院 计算机系, 广东 汕头 515071)
1 引言
近年来各种图像生成技术不断出现在大众视野中,2014年生成对抗网络(Generative Adversarial Networks,GANs)[1]横空出世,图像领域开启了新的篇章[2-3]。文本生成图像技术可以根据给定的描述性文本内容生成符合文本语义的视觉真实的图像。由于具有巨大的应用潜力,近几年成为热门研究领域,其中基于生成对抗网络的方法在最近几年的研究中成为最热门的方法。2016年,Reed等人[4]开创性地将GAN应用于文本到图像的生成任务中,实现了64×64分辨率图像的生成。2017年,Zhang等人[5]提出层级式生成对抗网络,使用多个生成器和判别器分阶段进行图像生成。Xu等人[6]在3层生成对抗网络的基础上增加注意力机制针对性地对图像进行细化。虽然上述多阶段方法已经取得了显著的进展,但仍然存在两个问题。首先,多阶段生成对抗网络模型最终生成图像的质量在很大程度上取决于初始图像的质量,低分辨率图像生成阶段本质上是基于上采样操作来提取特征,卷积操作的局限性可能会导致全局信息被忽略或者远程语义信息无法进行交互。为此,鞠等人[7]提出的SA-Attn-GAN模型在AttnGAN的基础上添加了自注意力模块实现文本到图像的生成。然而现有的简单自注意力模型仅根据每个空间上孤立的查询(Query)和键(Key)来获得注意矩阵,虽然有效利用了远程的语义信息,但是与Query和Key相关的局部信息容易被忽略,会出现表达能力欠缺的问题。其次,高分辨率特征图通常是来源于对低分辨率特征图进行上采样,上采样操作很容易失去语义信息。如果这些语义信息包含重要特征,则可能会使生成的图像与给定的文本特征不符合。
针对上述问题,本文提出一种基于自监督注意和图像特征融合的文本生成图像方法SAF-GAN。在初始阶段后增加一个自监督注意力模块[8],充分利用特征之间的上下文关系引导动态注意矩阵,从而增强初始特征表达。同时针对平衡生成质量与文本图像语义一致性之间的问题,本文提出了特征融合增强模块,通过使用低分辨率特征对高分辨率特征进行特征融合补充的方式,充分提取语义信息,从而生成逼真的图像。实验结果表明,提出的SAF-GAN性能得到了提升。
2 相关理论
2.1 文本生成图像
2016年以前,文本图像生成方法主要由变分自编码器(Variational Autoencoders, VAE)[9]和DRAW[10]主导。虽然可以生成相对合理的图像,但图像效果普遍较模糊。2014年,受到“二人零和博弈”的启发,Goodfellow开创性地提出了生成对抗网络[1]的网络模型,一经提出迅速成为热点研究问题之一。在此基础上,大量的研究开始将GAN应用到文本到图像生成的任务中。由于GAN可以不依赖先验假设,通过自主学习逼近真实样本的分布,生成的图像更加清晰真实。2016年,Reed等人[4]提出GAN-INT-CLS模型,通过将文本特征同时加入到生成器和判别器中对模型进行约束,最终实现了64×64分辨率图像的生成。同年,Reed等人[11]在此基础上继续提出GAWWN。为了在确定的位置生成目标图像,模型标记目标的边界框和关键点,将生成图像的分辨率提升到了128×128。为了进一步生成高质量图像以及提高对细节的把控,Zhang等人提出的StackGAN[12]和StackGAN++[5]模型引入了条件增强技术,通过多阶段逐级提升的方式将生成图像的分辨率提升到256×256,有效降低了信息丢失的问题。Xu等人[6]在初始阶段,使用句子级全局信息生成低分辨率图像。然后在细化阶段,通过重复采用注意力机制选择重要单词,利用单词级特征细化先前生成的图像。基于AttnGAN,文本到图像的生成技术向前推进了一大步。然而由于文本和图像模式的多样性,仅使用单词级的注意并不能确保全局语义的一致性。后续研究发现,在描述一幅图像时,文本中每个单词的重要程度存在差异,因此文献[13]提出了动态记忆生成对抗网络(DM-GAN),通过门控机制自适应筛选关键语义信息,引入动态记忆模块细化图像。
2.2 自注意力机制
自注意力机制[14]最早应用在自然语言处理任务中,是Transformer中的一个重要组成部分。由于能够捕获长距离的依赖,可以很好地联系上下文,研究人员逐渐将其应用于计算机视觉领域。工作的主要原理如下:输入序列进行线性映射得到3个变换矩阵:查询矩阵Q、键矩阵K、值矩阵V,公式如式(1)所示
其中:WQ、WK、WV均表示线性运算,查询矩阵和每个键矩阵进行点乘,计算两者的相似性得到一个实数值。使用Softmax对其进行归一化,得到一个权重系数,最后对V进行加权求和,输出最终结果。计算公式如式(2)所示:

图1 自注意力模块Fig.1 Self-attention module
3 本文提出的网络模型设计
本文提出了一种端到端的网络结构,用于对一系列多尺度图像分布进行建模,如图2所示。该模型包含3个生成器(G0,G1,G2)和3个判别器(D0,D1,D2)。整体模型呈树状结构排列,低分辨率到高分辨率的图像都是从“树”的不同分支生成。在每个分支中,生成器只用于捕获该尺度下的图像分布,判别器同样用来估计样本来自该尺度的训练图像而不是生成器的概率,其中包含的3个判别器是并行训练的,并且每个判别器都集中在单个图像尺度上。生成器被联合训练以近似多个分布,并且生成器和判别器用交替的方式被训练。最终得到隐特征(h0,h1,h2)作为生成器的输入,得到不同尺度的图像。通过在多个尺度上对数据分布进行建模。如果这些模型分布中的任何一个与该尺度的真实数据分布共享支持,则重叠可以提供良好的梯度信号,用来加速或者稳定多个尺度下的网络训练。比如,第一个分支的低分辨率图像分布会产生具有基本颜色和结构的图像,后续分支的生成器会专注于完成更加高分辨率图像的特征细化。

图2 SAF-GAN模型框架图Fig.2 Frame diagram of SAF-GAN model
图像编码模块使用预训练模型Inceptionv3[15]。通过Inception-v3网络中的“mixed_6e”层进行局部特征提取,使用最后一个平均池化层进行全局特征的提取。对于文本嵌入模块,本文采用双向长短期记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)[16]学习给定文本的语义表示,产生两个输出:句子特征和词向量特征s∈RD×T。使用条件增强(Conditioning Augmentation,CA)[5]来增强训练数据得到低维度的文本条件向量随机选择一个服从正态分布的高斯噪声z拼接句子特征,送入上采样模块得到第一个分支的隐特征h0:
其中:z≈N(0,1),F0是建立的神经网络模型,h0表示第1层的隐藏特征。由于最终生成图像的结果很大程度取决于初始图像的质量,为此本文在初始特征生成后嵌入自监督注意模块。最后将经过自监督模块的包含注意权重的特征送入生成器生成低分辨率图像,此时的低分辨率图像包含对象的大致颜色和粗略结构。
3.1 自监督注意力模块
在传统的自注意力机制中,任何成对的Q和K都是孤立进行计算,这严重忽略了相邻上下文之间的信息。虽然自注意力机制解决了CNN不能捕获全局信息的问题,但却忽略了局部信息丢失所带来的影响。本文引用CotNet自监督模块[8],将编码的键与查询连接起来,使用两个连续的1×1卷积学习动态注意矩阵,将得到的矩阵乘以输入值本身,实现输入的动态上下文表示,最后将静态表示和动态上下文表示融合作为结果输出,同时捕获全局信息和局部信息,提高特征信息的表达能力。
如图3所示,首先将特征h0转换为3个变量,其中将V(h0)进行特征映射,Q(h0)和K(h0)依然采用原来的h0:

图3 CotNet自监督模块Fig.3 CotNet self-monitoring module
对K(h0)进行3×3分组卷积,获得局部静态上下文信息K1∈RC×H×W,将静态信息K1与Q(h0)拼接,然后使用两次连续的1×1卷积进行运算,得到的动态注意矩阵如式(5)所示:
其中:Wθ、Wδ表示1×1卷积,[,]表示拼接操作,A表示注意力矩阵。不同于传统的自注意力,这里的A是Query信息和局部上下文信息交互得到的,增强了自注意机制。将注意力矩阵和V(h0)进行点乘,得到动态上下文表示,计算公式如式(6)所示:
最后与图像局部静态上下文信息相加输出最终特征融合结果,计算公式如式(7)所示:
在图像细化阶段,生成器的输入不再是噪声和句子语义特征,而是采用注意力矩阵形成的多模态上下文向量和上阶段输出的隐向量作为输入:
3.2 多分辨率特征融合
以往特征的融合通常通过加法或级联来实现,无论内容的变化如何,加法或级联都会为特征分配固定的权重,不利于特征的最佳融合。因此本文引用注意力特征融合(Attentional Feature Fusion,AFF)[17]对不同分辨率特征进行融合。

图4 注意力特征融合Fig.4 Attentional feature fusion
其中:Z∈RC×H×W是融合后的输出特征;(1-M(X⊕Y))和(1-M(X⊕Y))表示融合权重,使网络可以在X和Y之间进行软选择或是加权平均。
将得到的融合特征Z应用到多尺度通道注意力模块(Mutil-scale Channel Attention Module,MS-CAM)[17],图5两个分支分别表示全局特征的通道注意力和局部特征的通道注意力,局部特征的通道注意力L(Z)计算公式如式(10)所示:

图5 多尺度通道注意力Fig.5 Mutil-scale channel attention module
计算的权重值对输入特征X做注意力操作得到融合后的特征输出为h'i:
3.3 SAF-GAN算法流程
本文设计模型如算法1所示。
3.4 目标函数
SAF-GAN模型最终训练的目标函数包含生成器损失和判别器损失,优化的方式均是通过最小化交叉熵损失进行。
为了处理条件生成任务,本文使用联合近似条件分布和无条件分布对判别器进行约束,因此本文模型的判别器目标函数由无条件损失和条件损失两项组成,判别器的损失函数计算公式式(13)所示:
其中:xi表示真实图像表示生成图像表示条件信息,在本文模型中表示文本描述;无条件损失用来区分是合成图像还是真实图像;条件损失用来确定图像与给定的文本语义是否一致;Di表示第i个判别器的损失。最终的判别器损失函数为:
生成器的损失函数主要包含两部分:生成器损失LGi和多模态相似模型损失LDAMSM:
多模态相似模型损失LDAMSM与文献[6]中的计算方式相同。最终的模型生成器损失函数为:
其中,λ为多模态相似损失的权重。在经过训练的判别器的引导下,通过最小化上述损失函数优化生成器的联合近似多尺度图像。
4 实验与结果分析
4.1 数据集
为了验证SAF-GAN模型的性能,在CUB数据集[18]和COCO数据集[19]上进行训练和测试,数据集具体情况如表1所示。
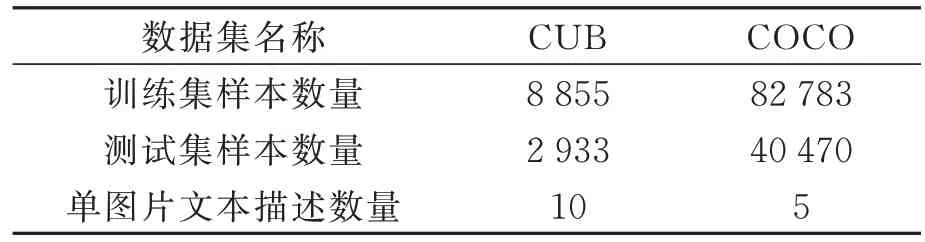
表1 数据集Tab.1 Dataset
4.2 实验环境及参数配置
本文实验环境、实验超参数的配置见表2。
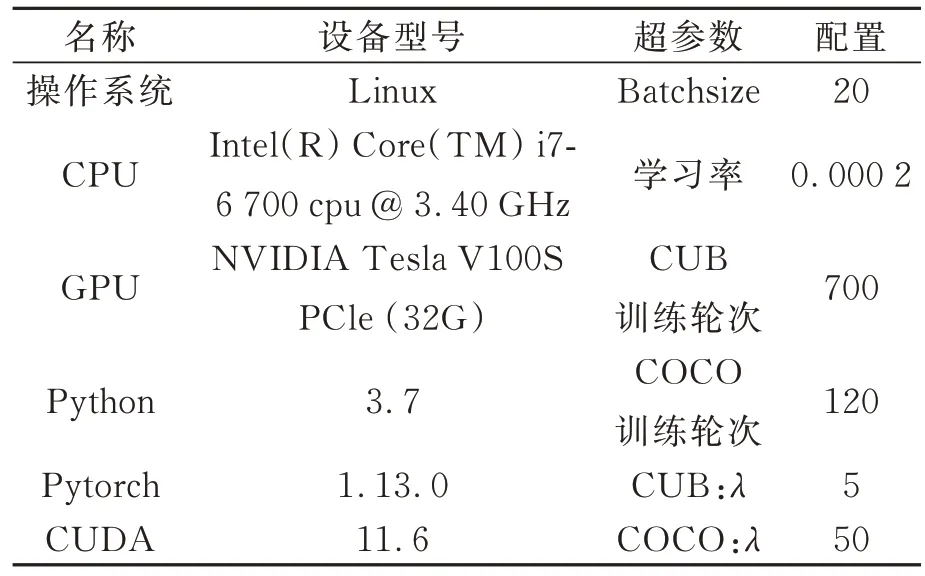
表2 实验环境及超参数配置Tab.2 Experimental environment and hyperparameter configuration
4.3 评价指标
Inception Score(IS)[20]和Frechet Inception Distance (FID)[21]得分被广泛用于评估文本到图像的生成,因此本文采用这两个指标作为定量评估标准,并从每个指标的文本描述中生成30 000张。
4.3.1 Inception Score
IS分数是通过条件类分布和边缘类分布之间的交叉熵差异来评估生成图像质量的衡量方式,其计算公式如式(17)所示:
其中:x是生成的图像,y是通过预训练的Inceptionv3网络获得的相应标签。计算出的IS分数越高,则该模型生成的图像更具有多样性和意义。
4.3.2 Frechet Inception Distance
与IS相同,FID也是通过计算生成图像分布和真实图像分布之间的 Frechet距离来评估生成样本的质量,其计算公式如式(18)所示:
FID分数低意味着生成图像和真实图像更接近。
4.4 实验结果与分析
4.4.1 各阶段图像可视化
不同阶段的图像输出结果如图6所示。通过图6可以看出,即使在场景复杂的COCO数据集上,本文的模型依然得到了较好的效果,虽然比不上真实数据集图像,但是主要的实体内容均能按要求生成。

图6 各阶段生成结果可视化对比Fig.6 Generate visual comparison of results at each stage
以256×256分辨率阶段的特征融合为例,如图7所示。使用上一阶段的低分辨率图像和该阶段细化后的特征进行融合,生成图像比直接使用阶段细化的特征更能显现出细粒度信息特征,生成对象的形状更加符合真值图像。

图7 融合结果可视化Fig.7 Fusion result visualization
4.4.2 指标对比
将提出的SAF-GAN模型与最先进的GAN模型在CUB数据集和COCO数据集上进行同等条件复现实现文本到图像生成效果的比较,模型包括GAN-INT-CLS[4]、StackGAN++[5]、AttnGAN[6]、SA-AttnGAN[7]、HDGAN[22]、DualAttn-GAN[23]、DAE-GAN[24]、KT-GAN[25]和CSM-GAN[26]。
表3列出了各种模型在CUB数据集上的对比结果,其中SAF-GAN获得了最高的IS分数,对比基准模型提升了0.31,性能提升了7.1%。FID值从21.48降低到18.03。表4列出了各种模型在COCO数据集上的对比结果,SAF-GAN在COCO数据集上的IS指标的数值达到了28.53,虽然分数较次于KT-GAN,但是对比基准模型依然提升了2.68,而且FID值下降到30.31,达到了对比模型中的最低值。这表明本文模型在CUB数据集和COCO数据集上训练生成的图像与真实图像更加接近,图像的合成质量与文本的匹配程度更高。综合比较,本文提出的模型优于其他对比模型,进一步证明本文提出方法的有效性,可以更加精确掌握文本的语义信息来合成有意义的图像。

表3 CUB数据集的评价指标分数Tab.3 Evaluation index scores of CUB dataset

表4 COCO数据集的评价指标分数Tab.4 Evaluation index scores of COCO dataset
4.4.3 可视化图像对比
对于定性评估,图8和图9展示了AttnGAN、SA-AttnGAN和SAF-GAN(本文方法)模型的合成示例可视化。首先从CUB数据集的可视化结果可以看出,AttnGAN和SA-AttnGAN合成的图像容易出现语义结构模糊的问题。AttnGAN模型尽管可以生成与文本相关的具有更多细节的图像,但是缺乏捕捉全局连贯结构的能力,图像还有些不真实,模型容易生成双头或者轮廓粗糙,不具备现实世界中鸟类形状的图片。SAAttnGAN模型虽然获得了更好的分数,但其模型重点通过自注意力来提高网络性能,而简单的自注意力使Query和Key相邻的局部信息被忽略,注意力表示能力欠缺,因此对于图像的轮廓细节方面不能精准把握,并且生成的图像存在鸟类实体本身和背景树枝穿插的情况,这都说明模型对于局部信息把控不到位。本文方法在细节合成方面表现更好,生成的鸟类图像具备现实的轮廓,并且图像效果更为清晰。从图8可以看出,文本所描述的白色的腹部或者蓝色的翅膀这些固定的属性特征均能很好地生成。对于CUB数据集中的真实图像而言,鸟类图像的视觉直观感受均为侧视图,生成器根据真实图像分布进行对抗生成,因此生成图像亦均为侧视图。

图8 CUB数据集生成结果的可视化对比Fig.8 Visual comparison of CUB dataset

图9 COCO数据集生成结果的可视化对比Fig.9 Visual comparison of COCO dataset
从COCO数据集的可视化结果(图9)可以看出,当文本描述更加复杂且包含多个对象时,AttnGAN模型生成的图像清晰度不佳并且出现重影,甚至在第六幅图像中并没有出现羊的基本轮廓。SA-AttnGAN可以捕获一些细节特征,但是仅包括生成实体的大概形状,并且清晰度仅优于AttnGAN模型,真实性有待加强。而本文方法可以更好地捕捉主要对象,并且能以更有意义的方式排列内容,生成更具有全局结构的图像。这证明在初始图像特征后面加入自监督注意力模块,不仅可以捕获图像的远程依赖关系,而且结合了局部上下文信息,使图像特征在生成过程中更加有针对性,解决了以往仅由卷积运算特征所带来的局限性,模型可以提取丰富的上下文信息,保证了语义的合理性。
4.4.4 生成过程细节展示
为了更直观地说明本文方法的有效性,本文以CUB数据集为例,生成图像的细节如图10所示。其中“this bird has a white belly and breast with a short pointy bill and yellow crown”为输入模型的文本信息,分别生成64×64、128×128、256×256分辨率的图像。初始阶段首先生成64×64的低分辨率图像,此时生成的低分辨率图像通常只包含生成对象的大概形状,缺少包含具体特征的细节内容。后续使用单词级注意力纠正上一阶段的缺陷,添加更多的细节生成更高分辨率的图像。后面阶段生成器生成图像的一些子区域可以直接从前一阶段生成的图像中推断出来。这些子区域在注意力图中显示为黑色。对于不能直接推断出的区域(如文本描述中对象固有的属性),注意力分配给与它们最相关的单词(图10中的亮区域)。因此,从单词上下文特征和先前图像特征两者可以推断出注意力更新后的图像特征。图10中两个注意力权重图像分别为基准模型AttnGAN(图10左)以及本文改进的SAF-GAN模型(图10右)。由图中亮色区域可以看出,AttnGAN模型对于单词的注意力分配的定位过于宽泛,单词与单词的重复定位容易造成关键特征空间重合,导致图像的前景与背景不能很好地分离(树枝与鸟的身体存在穿插现象)。而本文模型对于关键点的定位区域更加精确,模型通过自监督注意力增强关键特征,减少非必要特征对模型的影响,增加了生成图像的轮廓饱和度。

图10 注意力权重的可视化展示Fig.10 Visual presentation of attention weights
4.4.5 特征融合补充效果展示
使用多阶段生成对抗网络进行图像生成的模型,其生成的初始图像虽然是模糊的,但却包含了生成对象的大概形状以及对生成对象基本的颜色定义,因此在提炼高分辨率图像时,除了将输入单词作为限制条件之外,更应该通过将低分辨率图像和高分辨率融合的方式来维护生成图像的语义一致性。
通过应用低分辨率和高分辨图像进行融合的网络结构,基线模型中存在的整体图像颜色不一致问题和结构清晰度问题都得到了改善,生成图像的细节更加完善。比如图11中的第1列,加入特征融合模块的模型在整体形状和颜色方面与真实数据图像都具有高度的一致性;又如图11中的第三列,基线模型中文本描述的语义并没有得到准确的刻画。加入特征融合模块后,生成图像准确地刻画了文本所描述的内容(生成图像既包含风筝又包括人)。其次,生成的图像也具备了良好的逻辑关系(人牵着风筝,风筝在天上飞)。这更加直接地证明了在不同阶段特征生成模块中融合前一阶段图像特征的重要性。

图11 特征融合补充效果可视化展示Fig.11 Visual display of feature fusion supplementation effect
4.4.6 消融实验
为了进一步验证本文提出的自监督模块(CotNet)和图像特征融合模块(AFF)的有效性,分别设计了AttnGAN、AttnGAN+CotNet、AttnGAN+AFF、AttnGAN+CotNet+AFF 4组对比实验。通过表5、表6数据可知,引入CotNet模块、AFF 模块对生成效果均起到促进作用,同时添加了CotNet和AFF模块的SAF-GAN在CUB数据集和COCO数据集上的图像生成质量要明显优于只添加AFF或只改进CotNet模块图像生成的质量,通过叠加可以达到本文的最佳结果。对于CUB数据集,基准模型的IS分数从4.36提升到4.67,FID分数也从最初的21.48降低为18.03。对于COCO数据集,基准模型的IS分数从25.85提升到28.53,FID分数从最初的35.49降低为30.31,证明各模块组件真实有效。

表5 CUB数据集消融实验的结果对比Tab.5 Comparison of results on CUB dataset

表6 COCO数据集消融实验的结果对比Tab.6 Comparison of results on COCO dataset
5 结论
本文提出一种基于自监督注意和图像特征融合的文本到图像生成模型SAF-GAN。在AttnGAN模型的基础上引入CotNet自监督模块对特征进行约束,充分利用特征之间的上下文关系引导动态注意矩阵,将上下文挖掘和自注意学习结合,增强初始特征表达,使后续图像细化阶段效果更佳。并且加入了特征融合增强模块,使低分辨率特征与高分辨率特征并行融合。低分辨率特征图虽然空间比较粗糙,但是包含了图像的整体结构特征,模型可以充分提取语义信息,从而生成逼真的图像。实验结果表明,本文模型生成的图像真实合理,客观上通过IS和FID指标对比也证明了本文方法的有效性。
猜你喜欢
红外技术(2022年11期)2022-11-25
电子产品世界(2022年9期)2022-05-30
小雪花·成长指南(2022年1期)2022-04-09
开放教育研究(2020年2期)2020-03-31
艺术科技(2018年2期)2018-07-23
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
商(2014年46期)2014-05-30
