
基于卷积神经网络的岩渣分类算法及其FPGA 加速*
2024-03-06 02:54陈昌川王新立朱嘉琪张天骐尹淑娟
传感技术学报 2024年1期
陈昌川,王新立,朱嘉琪,张天骐,尹淑娟,王 珩,魏 琦,乔 飞
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.内蒙古科技大学包头师范学院,内蒙古 包头 014030;3.上海工业自动化仪表研究院有限公司,上海 200233;4.清华大学精密仪器系,北京 100084;5.清华大学电子工程系,北京 100084)
全断面岩石掘进机(Tunnel Boring Machine,TBM)具有施工速度快,安全性高,经济性好等优点,在高速公路、铁路运输、城市地铁等重大工程中得到了广泛的应用[1]。由于工作环境恶劣,刀盘滚刀极易受到异常磨损和损坏,如果施工过程当中无法及时发现并处理刀具出现的损坏,不仅会降低掘进效率,还会致使刀盘出现异常,影响工程进度与施工质量,因而研究盾构刀具的磨耗原因并对刀具磨损情况进行实时监控,对刀具的合理选择、使用、维护和更换尤为必要。
目前国内外有多种不同的刀盘监测方法,主要有液压监测法[2]、电涡流监测法[3]、超声波检测法[4]等,上述方式取得了一定的成功,但同时都存在一定的局限性,比如需要在刀盘处安装传感器,线路布置复杂,同时刀盘工作时会产生较大震动,会影响传感器寿命。根据TBM 刀盘滚刀的破岩机制,当刀盘磨损或者损坏时,掘进产生的岩渣碎片尺寸会增大[5]。因此,可以通过监测传送带上的岩渣碎片情况间接监测刀盘的状态,指导现场施工人员及时检查和更换刀具。相机在传送带上方采集图像,避开了恶劣的生产环境,同时还具有设备简单、损耗低、成本低、可以长时间监测等优点。
目前在工程实践中,普遍依靠人工判断岩渣状态,关于岩渣的分析研究较少,闫长斌等[6]结合实际施工场景数据对岩渣粒径与刀具磨损的关联进行研究,发现二者存在正相关;甘章泽等[5]利用分水岭分割算法对岩渣图像进行分割和尺寸测量,实现了间接监测刀具磨损的目的,但基于工作经验判断测量结果存在一定误差。基于卷积神经网络(Convolutional Neural Networks,CNN)在计算机视觉领域的广泛应用和优越性能,本文提出一种基于CNN 的岩渣分类算法,CNN 算法能够提取图像中的深度特征,同时具有良好的旋转、平移不变性,在岩渣识别的应用中能够发挥巨大作用。
在CNN 的FPGA 加速上,主要面对两个瓶颈问题:计算和数据传输。为了缓解带宽的压力,提高系统的吞吐率,文献[7]将网络整体映射到FPGA 上,避免了将中间层结果传输到片外带来的带宽压力,但当网络层数较深时,受到片上硬件资源的限制,此方法不再适用。因此,更加常见的是一种基于模块的架构[8],基于运算模块的架构将神经网络分割成基本的运算单元(如卷积、池化、全连接等),通过设计不同功能的内核完成运算单元的功能,但是这种方式需要频繁将中间结果写入片外内存,对带宽的压力较大,为了减少片外内存存取对性能的影响,文献[9]提出“ping-pong”的访存策略,将内存读写带来的时间延迟隐藏在计算时间内,有效地提高了数据传输效率。
仅仅在硬件方面的设计工作对性能的提升有限,因此一些研究者从网络模型出发,在软件层面上对网络进行量化、剪枝[10-12]等操作进行网络压缩,以缓解硬件实现时的带宽压力。文献[13]提出,在不损失准确率或准确率损失较小的情况下,用位数较低的数据代替全精度浮点数是可行的,使用位数较低的数据类型能够有效减少访存的开销并提高计算的吞吐率,提升FPGA 整体的执行性能。因此,在网络精度不降低的情况下进行网络压缩是研究热点之一。
综上,为了提高FPGA 加速岩渣分类算法的性能表现,需要在算法和硬件层面联合优化,达到最优设计。本文在算法层面提出一种保留网络原始结构的网络压缩方法,减少了硬件实现的带宽压力和计算压力;硬件层面上充分利用卷积神经网络的并行性,通过流水线并行的方法设计了网络加速架构,最后实现了岩渣分类算法加速系统。
1 岩渣分类算法
1.1 网络迁移学习
由于岩渣数据集训练数据过少,直接训练无法充分学习特征,容易产生过拟合现象,研究表明,卷积神经网络在相似的任务中具有一定的泛化性能,采用迁移学习训练网络具有更好的性能提升速度和收敛性能[14]。在卷积神经网络中,前几层特征图输出与图像数据集关系不大,而网络最后一层则与选定的数据及其任务目标密切相关[15],因此,根据分类目标,重新设计全连接层,得到的网络结构如图1所示,以预训练网络的权重作为初始值对模型进行重训练,把使用ImageNet 训练的VGG16 的预训练模型的参数迁移到岩渣分类网络中,实践证明预训练模型的权重具有很强的泛化性能,如图2 所示,在训练1 000 次后,网络准确率达到96%,在岩渣数据集上能够达到很好的分类效果。

图1 岩渣分类网络模型

图2 网络准确率变化曲线
1.2 数据集扩增
本文使用的岩渣数据集由中铁工程装备集团有限公司于真实工程场景中采集,数据集为三类图像分辨率为224×224 的彩色岩渣图片,部分图像如图3所示,其中0 类岩渣3 880 张,1 类岩渣1 840张,2 类岩渣640 张。其中0 类和1 类岩渣产生于刀盘正常工作时,属于正常岩渣,2 类岩渣在刀盘存在异常时产生,属于异常岩渣。

图3 岩渣数据集部分图像
将岩渣数据集分为训练集和验证集后使用训练集对网络进行重训练,重训练后网络分类结果如表1所示。

表1 3 种不同岩渣的分类准确率
由于三种类别的岩渣图像数量不均衡,1 类和2类岩渣的训练数据量过少,网络学习到的特征不足,虽然网络整体准确率在验证集上可达到96%,但在1 类2 类岩渣上的分类准确率并不高。因此,需要使用数据集扩增方法对岩渣数据集中1 类和2 类岩渣图像进行扩增,提高两类岩渣的分类准确率。
在实际的生产过程中,岩渣可能存在方向上的随机分布,并且摄像头可能受环境影响采集到包含噪声的图像,因此针对上述特点,采用随机旋转和添加高斯噪声的方式对数据集进行扩增,并对网络进行重训练,在扩增岩渣数据集上网络的分类准确率如表2 所示。整体网络准确率为96.5%,其中0 类、1 类、2 类岩渣的分类准确率分别为97.9%、93.1%和98.4%。

表2 数据扩增后分类准确率
1.3 网络压缩方法
1.3.1 动态定点量化
在网络训练过程中,通常使用32 bit 浮点数存储权重和特征图,而32 bit 浮点数在进行数据访存时会给FPGA 带来很大的带宽压力,实际上由于CNN 的冗余性[16],将32 bit 浮点数参数转换为较低的比特表示法可以在不降低网络性能的情况下显著减少深度学习模型复杂度和带宽消耗。对于定点量化,8 bit 是一个明显的界限,在低于8 bit 量化时,网络准确率会受到较大影响[17],8 bit 量化能够基本保持准确率不变。
常见的量化方法可分为线性量化和非线性量化,由于线性量化后的数据与原始数据是线性变换关系,前向推理时只需要计算线性变换函数,对FPGA 硬件电路设计友好,更方便实现硬件上的高效率计算。
在量化过程中最关键的计算流程就是计算小数位位宽,每层卷积的不同通道之间,网络参数的差距很大,最高甚至可达100 倍[10],静态量化方法对所有卷积核使用相同的小数位位宽会带来较大的网络准确率损失。动态量化方法对不同的卷积核分别计算其小数位宽从而降低准确率的损失。
因此,本文使用一种8 bit 动态定点量化技术对网络进行线性量化,以一层卷积层的量化为例,方法流程如下。
首先统计该层每一个卷积核数据分布,分别得到权重数据的最大值Maxw_n。其中weight_n代表当前层第n个卷积核的权重。
计算该卷积核小数位位宽w_bit。
对所有权重进行线性缩放并舍弃尾数。得到量化后的权重weight_nq。
因为8 bit 定点数量化将权重线性映射到[-128,127]之间,所以需要对最后的结果进行截断。
对所有权重和激活值完成上述操作即完成对网络的量化。量化后网络压缩为原网络的25%,大大减少了网络所需的存储空间,同时定点数计算相比浮点数也减少了计算压力,减轻了硬件实现所需的资源消耗。表3 展示了量化前后的准确率对比,总准确率相比原网络仅下降了0.2%。

表3 量化后准确率对比
1.3.2 通道剪枝
网络量化降低了网络参数的存储需求,但未能显著减少网络的计算量和参数量,因此,需要通过网络剪枝方法对网络模型进行进一步的压缩,删除其中不重要的权重,从而达到压缩模型规模,降低存储计算成本的目的[18]。
剪枝方法分为结构化剪枝[19-20]和非结构化剪枝[21]两类。其中非结构化剪枝对网络的单体权重进行修剪,通过稀疏化矩阵的形式存储剪枝后权重数据,可以实现更高的压缩率,但会对原始网络结构造成较大破坏,同时也会对硬件设计提出较高要求;而结构化剪枝通过对卷积核、通道或者网络层进行剪枝,仅仅造成数量的改变,网络的原始结构得以保留,规整的网络结构更容易实现网络的硬件加速。
因此本文使用一种结构化的通道剪枝方法,如图4 所示。通过对卷积核冗余通道进行修剪,达到缩减网络规模的目的。其流程如下:①对每层卷积层权重的绝对值和进行排序。②按照每层的排序结果设置合适的剪枝阈值。③将每个卷积核的绝对值和与阈值比较,修剪掉小于阈值的卷积核。④按照该层修剪掉的卷积核,统一修剪对应特征图通道,形成新的轻量化网络结构。⑤将修剪后的网络进行重训练,恢复网络准确率。

图4 通道剪枝流程
考虑到一次修剪过多卷积核会对网络准确率造成较大损失,且无法通过重训练恢复,因此采用迭代剪枝的方法,通过多次迭代剪枝及重训练进行网络的剪枝工作。
将网络进行剪枝并结合8 bit 量化后,网络的性能表现如表4 所示。

表4 剪枝量化后准确率对比
通过剪枝去除网络冗余并进行重训练后,网络整体准确率未受影响,与8 bit 量化方法结合对网络进行压缩后,网络规模下降至原始网络的2.28%,同时网络的整体准确率仅下降0.9%。
2 硬件架构设计
2.1 整体硬件架构
本节提出一种基于OpenCL 的FPGA 卷积神经网络加速架构,如图5 所示,用于加速上节中的岩渣分类网络。根据CNN 各计算层之间的独立性,设计可配置的OpenCL 内核分别完成网络的卷积、池化和全连接层运算。整个架构主要分为片上和片外两部分,片外的全局内存主要用于特征值、模型参数以及量化参数信息的存储,片上内存用于存储传输当前计算层的特征值数据、权重参数、量化参数以及当前层的计算结果等。

图5 岩渣分类网络加速硬件架构
在本架构中,内核之间通过可配置的流水线管道互相连接,管道是使用片上资源构建的一种高效无阻塞先入先出队列(First Input First Output,FIFO)数据传输模块,使内核之间的数据直接在片上传输,能够减少对片外内存的存取次数,提高了数据传输的效率。通过控制字灵活组合内核连接即可通过硬件资源实现复杂的网络运算加速。
河曲引黄灌溉工程是一项保障民生、惠民利民的重点水利工程。工程建设任务以农业灌溉为主,兼顾工业供水。工程建设规模:设计灌溉面积0.68万hm2(改善 0.28万 hm2,新增 0.4万 hm2),年工业供水1 500万m3,设计引水流量7.4 m3/s。引水线路干线总长33.96 km,包括隧洞、暗涵、渡槽、输水管线等建筑物。其中4#隧洞为城门洞型无压隧洞,净宽2.0 m,净高2.2 m,纵坡1/1 000,全长1 160 m,是实现引黄灌溉工程龙口取水口通水至县城12.938 km长度线路的关键节点。
控制字为0 时,架构完成卷积或全连接操作,管道和内核的连接模式为:读内存内核从片外内存读取计算所需数据,并存储到内核中的片上缓存中,随后通过数据管道将数据传输至卷积内核,卷积内核完成卷积运算后将结果存入片上缓存,随后输出到连接写内存内核的数据管道,通过写内存内核将数据写入片外内存。
控制字为1 时,架构完成卷积+池化操作,管道和内核连接模式为:数据通过读内存内核,从片外内存读取到片上缓存中进行存储,随后通过数据管道传输至卷积内核,内核完成计算后将结果传输至连接到池化内核的数据管道,池化内核读取数据并进行最大池化操作后输出到数据管道,由数据管道写入片上缓存,通过写内存内核将结果写入片外内存。
在进行相关的连接模式进行网络计算时,每个内核只执行一次,不会发生内核资源的争用,从而保证了整体的流水线畅通。
2.2 并行度设计
在网络的计算过程中,各个通道的输出特征值由输入特征值与每一个卷积核独立地进行卷积计算得出,与其他卷积核、特征值无关;在池化时,当前层的计算只针对当前的池化窗口进行,与其他的池化窗口无关,同时,进行池化计算时,只需保证本次池化窗口所需要的数据已完成卷积计算即可,无需等待所有数据完成卷积计算后再进行池化计算,因此,网络的计算过程可以通过不同的计算单元并行计算,更充分地利用片上资源。利用计算的低关联性,本文设计了图6 所示的并行数据结构。三个并行度P_ch、P_num 和P_k,其中P_k 与卷积核大小保持一致,利用了算法的核内并行特性;P_ch 代表通道层面的并行度,此维度上的数据互相独立,可以实现核内并行化计算;P_num 代表卷积核层面的并行度,同一块特征图区域可以独立地与多个卷积核进行计算,实现了卷积核间并行计算。将权重和特征值进行并行化处理,可以同时传输并行化数据到多个线程实现相同的操作,从而提高系统的效率并降低流水线的复杂度。

图6 并行数据结构示意图
2.3 内核设计
2.3.1 卷积内核
在本架构中,卷积内核实现卷积(或全连接)+量化+线性整流的功能。如图7 所示,按照设计的两个维度的并行度P_ch 和P_num,通过8 bit 乘累加阵列完成高效的并行化卷积运算,随后在P_num维度上分别进行累加,得到不同卷积核计算得到的对应输出通道的特征值,最后进入量化和线性整流模块,通过数据管道按照P_num 的并行度输出卷积内核。

图7 卷积内核
2.3.2 池化内核
池化内核核心是一套基于行缓冲器和列缓冲器的并行高效流水线。主要功能是完成输入池化窗口特征值的最大池化计算。由于在顺序上池化内核在卷积内核之后进行执行,因此池化内核在流水线上也采用了与卷积内核相同的P_num 的并行度,以一个池化窗口为例,如图8 所示,通过行比较得到池化窗口的每行最大特征值,随后通过列比较得到该池化窗口中的最大值,并通过数据管道将池化结果按照P_num 的并行度输出内核。
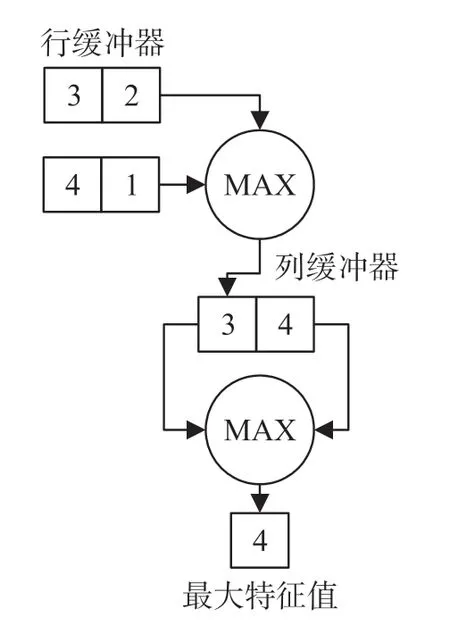
图8 池化内核
2.4 多层次数据缓存
卷积计算属于数据密集型操作,每次计算都需要从片外读取权重和特征值,产生大量的延迟[22]。针对数据读取频繁的特点,设计图9 所示的多层次缓存结构,片外存储全部特征值和权重,将多次卷积计算需要的数据分为一组,通过内存操作内核中的读内存内核读取到片上缓存,计算内核读取片上缓存获得当前计算所需并行化权重和特征值。数据按照分组的形式从片外读取,减少了片外内存的访问次数,从而减少延迟和功耗。
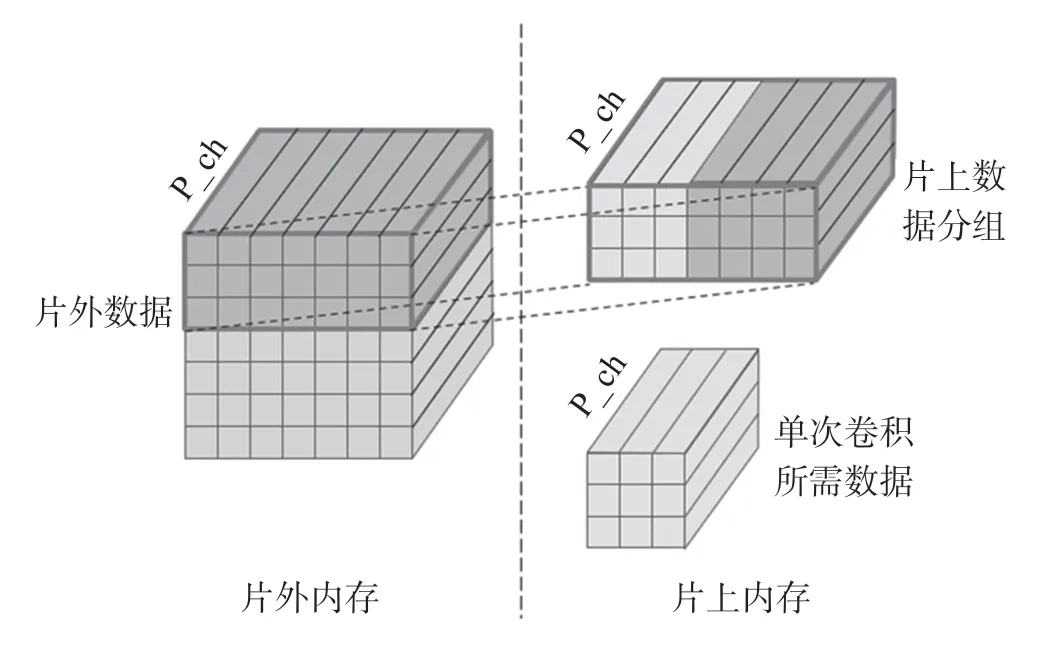
图9 多层次缓存
分组与分组之间可通过循环展开指令,在FPGA 上使用流水线并行的方式进行卷积计算。如图10 所示,未使用循环展开时,每次分组计算结束后才进行下一次的分组计算,使用循环展开流水线并行模式下,本次分组计算的同时读取下一分组数据,将数据读取时间掩盖到计算时间内。相比于顺序执行,流水线并行的方式可以大大缩短运行时间。

图10 流水线并行
另一方面,设计“ping-pong”片上双缓存,在分组计算时用计算的时间掩盖数据传输的时间。当内核计算缓存1 中的数据时,缓存2 进行片外数据传输;内核计算缓存2 中的数据时,缓存1 进行片外数据传输。通过额外的片上存储资源消耗,换取了片外数据传输的效率。
3 实验与分析
为验证所提架构的有效性,本文选择HERO 平台[23]部署加速架构。在PC 端完成网络模型训练和量化后,保存其权重值,并移植到HERO 平台中,以供架构计算使用。HERO 平台搭载Intel i5-7400 CPU,Intel Arria 10 GX1150 FPGA 板卡,二者通过PCIe 接口连接,能够协同实现基于OpenCL 的网络全部计算过程。
本架构的各项性能与2.2 节中提到的P_k,P_ch和P_num 并行度的大小设置有关,其中P_k 为卷积核的大小,无法改变,因此通过对两个并行度P_ch和P_num 的组合,可以探索不同并行度组合之中的最佳设计。架构经过对不同组合并行度进行综合布局布线后,硬件资源使用量如图11~图14所示。
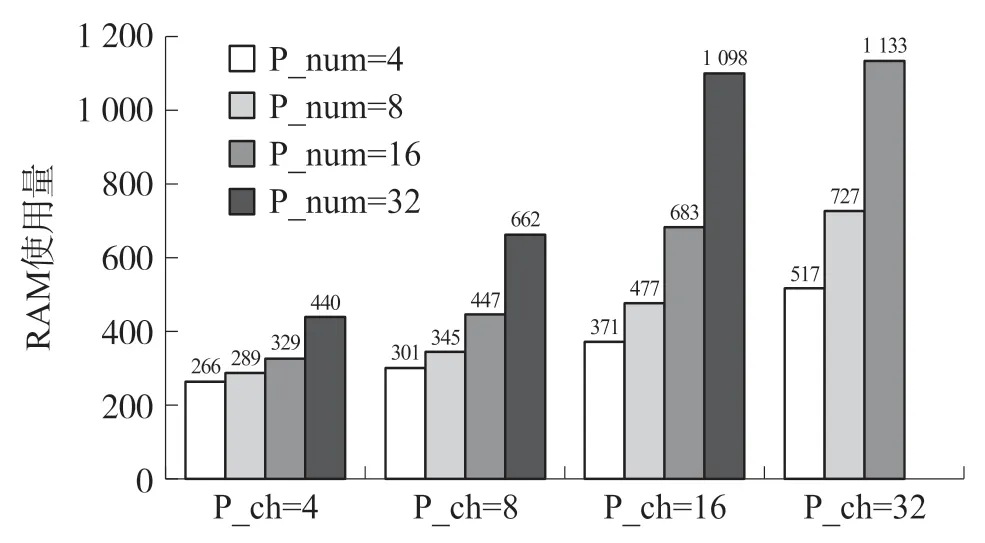
图11 不同并行度下RAM 使用量
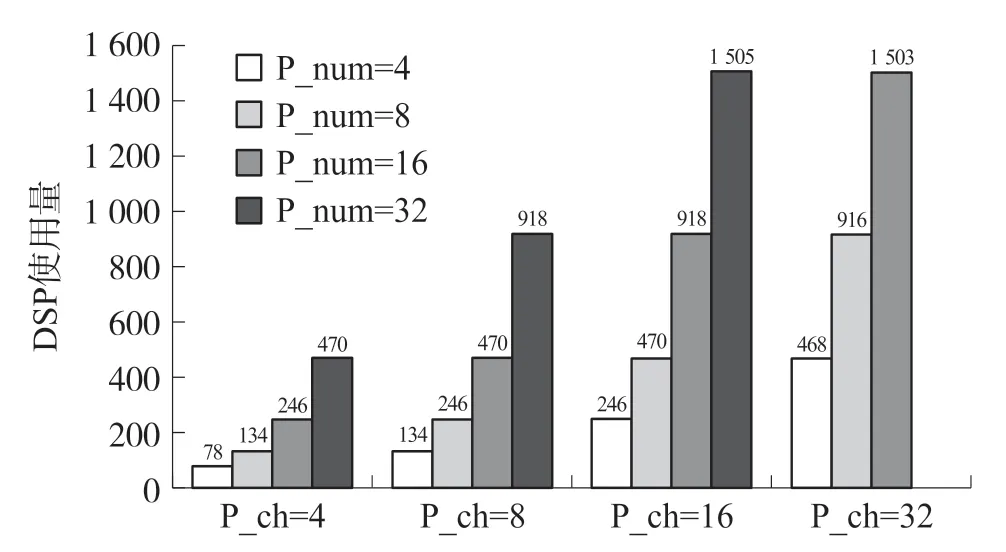
图12 不同并行度下DSP 使用量

图13 不同并行度下时钟频率

图14 不同并行度下运行时间
并行度设置较小时,片上资源没有得到充分利用,因此运行时间较长;并行度设置较大时,片上资源得到有效利用,运行时间也随着并行度的增加而减少。在P_ch=32,P_num=16 时,架构实现最佳设计,此时每帧图像的运行时间为26.9 ms,相关资源消耗情况和性能参数如表5 所示。

表5 性能参数及资源消耗
片上99%的DSP 资源用于实现乘累加单元阵列,同时消耗了42%的片上RAM blocks。在输入图像分辨率为224×224 下,岩渣分类网络在本架构下和其他硬件平台推理计算的性能对比如表6 所示。经过量化剪枝后的岩渣分类网络计算量是固定的,转换成操作数共计6.04 GOPS。经计算,本架构系统吞吐率为224.54 GOP/s,能效为11.23 GOP/s/W,最终在191.67 MHz 的内核时钟频率下实现了26.9 ms 的系统运行时间。不同平台的网络计算性能如表6 所示,对比Intel E3-1232 V2,本架构实现了18 倍的吞吐率和62 倍的能效提升;对比Nvidia GTX1080 GPU,本架构在能效方面优于GPU,实现了1.67 倍的能效提升。

表6 不同平台岩渣分类网络推理性能比较
4 结论
本文提出了一种基于卷积神经网络的岩渣分类算法,随后对算法网络进行了8 bit 动态定点量化,并基于OpenCL 设计了可配置的CNN 加速架构,对算法进行了硬件加速实现。实验表明,本文所提算法在量化后可以达到95.6%的岩渣分类准确率,所提加速架构在搭载Intel Arria 10 GX1150 的HERO平台上可以达到224.54 GOP/s 的吞吐率和11.23 GOP/s/W的能效,可以实现37 frame/s 的识别速度。
后续将继续研究优化硬件加速器,实现更高的工作频率和吞吐率,从而进一步提高岩渣分类系统的运行帧率。
猜你喜欢
计算机工程与应用(2023年22期)2023-11-27
科学技术与工程(2023年3期)2023-03-15
保健医苑(2022年5期)2022-06-10
软件导刊(2022年3期)2022-03-25
今日农业(2021年9期)2021-07-28
成都信息工程大学学报(2021年6期)2021-02-12
成都信息工程大学学报(2018年4期)2019-01-23
计算机技术与发展(2019年1期)2019-01-21
信息安全研究(2018年12期)2018-12-29
天津诗人(2017年2期)2017-03-16
