
一种基于CEEMDAN-CPELM 的池塘溶解氧预测模型研究*
2024-03-06 02:54钱承山袁永明
传感技术学报 2024年1期
施 珮,匡 亮,王 泉,钱承山,袁永明
(1.无锡学院物联网工程学院,江苏 无锡 214105;2.江苏省物联网设备超融合与安全工程研究中心,江苏无锡 214105;3.江苏信息职业技术学院物联网工程学院,江苏 无锡 214153;4.中国水产科学研究院淡水渔业研究中心,江苏 无锡 214081)
在水产养殖中,水体溶解氧(Dissolved Oxygen,DO)作为鱼类生长中的关键因子,其浓度的高低直接影响鱼类的生存[1]。实际的集约化养殖生产中,由于养殖投放密度高、规模大,溶解氧浓度变化快,溶解氧时间序列总是受到复杂环境和干扰因素影响,呈现较明显的非线性和非平稳特征。如何利用其多元关联因素对这种非线性时间序列进行准确预测,实现集约化养殖生产的溶解氧精准控制,对提高生产效率、降低养殖风险具有重要意义。
近年来,越来越多的专家学者开展了养殖水体溶解氧数据流的预测研究[2-8]。崔雪梅[2]提出并建立了基于遗传算法的阻尼最小二乘法改进BP(Back Propagation,BP)神经网络算法,对水体溶解氧进行预测。虽然该方法相较于传统BP 算法有一定提高,但未考虑影响溶解氧的众多因素,且BP 神经网络算法易陷入局部最小化,训练速度较慢。刘双印等[3]采用蚁群算法对最小二乘支持向量回归机的模型参数进行优化,实现养殖池塘溶解氧浓度的预测。但是,该类算法未考虑溶解氧时间序列的多尺度特征,预测精度有限。宦娟和刘星桥[4]提出了一种基于k-Means 聚类和极限学习机(Extreme Learning Machine,ELM)的溶解氧预测模型,对常州市水产养殖基地的试验池塘溶解氧浓度进行有效预测。该方法使用的ELM 方法收敛速度快,但当预测模型输入量冗余时易产生强共线性问题。谢雨茜等[5]针对溶解氧的非线性特征提出基于经验模态分解(Empirical Mode Decomposition,EMD) 与k-Means 聚类的改进长短期记忆神经网络(Improved Long Short-Time Memory,ILSTM)模型。然而EMD方法在分解过程中易出现模态混叠问题,从而影响预测模型的预测精度。
为此,本文提出一种自适应完备集合经验模态分解-聚类重构结构的偏最小二乘优化ELM 算法(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise-Clustering reconstitution and Partial Least Squares optimized ELM,CEEMDANCPELM),实现养殖试验池塘的溶解氧预测。该模型通过CEEMDAN 对水体溶解氧浓度进行分解,使得溶解氧时间序列的多尺度特征被捕捉,同时基于模糊熵的聚类重构可以降低多尺度分解的复杂度。偏最小二乘法改进的极限学习机模型可以在训练过程中避免冗余信息输入引起的强共线问题,且模型学习速度快,可在溶解氧与各相关因子间建立稳定的映射关系,从而高效、准确地预测水体溶解氧浓度。
1 系统架构与相关知识
1.1 研究区域
本文的试验基地位于江苏省常熟市(121.9°E、31.6°N),该试验基地拥有养殖总面积约3×105m2。养殖基地部署有物联网感知监测系统,本试验以物联网监测范围内的一口养殖池塘为试验对象,该池塘长约 110 m,宽 60 m,深 1.5 m,面积约6.7×103m2。养殖品种为南美白对虾,投放密度约75 尾/m2。本文选择2019 年7 月11 日至8 月16 日期间共36 d 监测信息的约5 293 组数据集作为试验数据集,并选前4 830(约33 d)组数据作为训练样本集,剩余463 组(约3 d)数据作为测试样本集。
养殖池塘部署的物联网感知监测系统包括水下智能感知系统和自动气象站两部分。水下智能感知系统能够通过部署的传感器设备实时采集水体溶解氧、pH 和水温等参数信息,各传感器一般部署在水下0.5 m 处,数据采集频率为10 min/次。自动气象站部署在距离池塘边1 m 处,多个试验池塘共用一套自动气象站,可采集气温、风速、风向、大气压强、湿度、二氧化碳、辐射率、日照强度、光合有效辐射等九项数据。所有感知设备采集的数据以Zigbee 无线通信的方式通过Sink 节点传输至服务器。图1为该系统的架构图。

图1 物联网感知监测系统架构图
1.2 研究方法
1.2.1 完备集合经验模态分解
经验模态分解是一种能够自适应地将非线性信号分解为相互独立的本征模态函数的一种方法[9]。然而EMD 在实际使用过程中,存在“模态混叠”现象。当时间序列的分解出现此问题时,分解后的本征模态函数则不再具有意义。自适应完备集合经验模态分解利用白噪声均匀分布的特点[10],对原始时间序列叠加带有控制参数的成对自适应白噪声,并计算提取集合平均后的模态分量IMFk,克服EMD的模态混叠问题。假定Ej(g)为EMD 分解得到的第j个模态分量,w(t)为高斯白噪声,且满足N(0,1)分布,则待处理的溶解氧时间序列为x(t),其详细步骤如下:
①对初始时间序列x(t)叠加不同的白噪声wi(t),使得初始序列变为合成信号xi(t)。利用EMD 对各合成信号xi(t)进行I次分解,从而得到一阶本征模态分量IMF1(t),同时对原始时间序列中IMF1模态分量进行去除操作,获得第一个残差r1(t)。
②在r1(t)中加入成对高斯白噪声得到r1(t)+ε1E1(wi(t)),并进行EMD 分解,获得二阶本征模态分量IMF2(t),并计算去除IMF2模态分量后的残差r2(t):
③重复上述步骤,直至残差信号为单调信号,不可再分解,则算法结束。由此分解获得Z阶IMFz本征模态分量、残差rz(t)和残差信号R(t):
由此,可以得到初始信号x(t)则表示为:
1.2.2 模糊熵
模糊熵(Fuzzy Entropy,FuzzyEn)能够实现时间序列复杂程度的定量化度量。它能够随参数变化而变化熵值,在新模式中重新评估产生的概率[11]。且模糊熵值越大,产生概率越大,时间序列的复杂程度越大。假定N维时间序列U=[u(1),u(2),…,u(N)],其模糊熵计算的详细步骤如下:
①按照序号顺序进行相空间重构,如式(9)所示:
式中:相空间维度为m(m≤N-2),u0(i)为均值,可表示为:
②定义两个窗口向量X(i)和X(j)之间的最大绝对距离为,如式(11):
采用模糊隶属度函数μ(,m,r)计算向量X(i)和X(j)间的相似度:
式中:i=1,2,…N-m+1,r为相似容限度。
③对于每个i,计算各i对应的评价值
④重复步骤①~③,并定义函数φm(r)和时间序列u(N)为有限集的模糊熵如式(14)、式(15)所示
1.2.3K-medoids 聚类
K-medoids 是一种经典的聚类算法,但不同于k-Means 方法,它通过计算簇中点到其他点间距离和的最小值,并作为簇的中心点,最终将相同类别和具有相同属性的点聚集在同一个簇中[12]。在Kmedoids 算法中,假定一个n大小的样本集合G,任选k个点作为各簇的初始中心Ci,并依据其他点到簇心的距离进行归类,获得初始划分的簇,再不断使用非簇心点替代簇心并进行评估,最终确定簇类数及中心。其具体聚类步骤如下:
①从样本集合X={x1,x2,…,xn}中随机确定k个点作为初始簇心。
②计算集合X中心点之外的样本点到簇心的距离Cd,依据距离最小原则完成样本点归属簇的划分过程。
③计算各簇中任意一点与簇中非簇心的累积距离和Ct,若Ct<Cd,更换初始簇心Ci,反之不进行替换。
④重复步骤②~③,若聚类结果不变或达到迭代次数,聚类结束。
1.2.4 偏最小二乘优化极限学习机
极限学习机(ELM)作为一种简单、高效的单隐层前馈神经网络算法,在使用时仅需设置网络隐含层节点数,无需调整输入权值和偏置即可获得最优解,因此学习速度非常快[13]。然而,若输入节点信息冗余或隐含层单元数较样本数更多时,则会发生输出层的强共线性问题[14]。偏最小二乘算法能够在严重多重相关性条件下进行有效的回归分析,构建输入与输出间的映射模式[15]。偏最小二乘优化极限学习机(Partial Least Squares optimized ELM,PLS-ELM)中,正是利用PLS 对ELM 隐含层中的正交变量进行提取,有效解决强共线性问题。
在传统ELM 算法中,对于大小为n的样本集(xi,ti),xi=[xi1,xi2,…,xin]和ti=[ti1,ti2,…,tin]分别为ELM 的第i个输入和网络期望输出,含有l个隐含层的ELM 网络模型可以用式(16)表示:
式中:bj、wj=[wj1,wj2,…,wjn]T、βj=[βj1,βj2,…,βjn]、yi=[yi1,yi2,…,yin]T分别表示隐含层单元的偏置、ELM 网络中输入单元与第j个隐含层单元间输入权值、第j个隐含层单元与输出层间输出权值以及输出量,g(x)即ELM 的激活函数。
当使用PLS 进行权值β的计算,则可以构建输出Y与H的线性关系,关系表达式为:
式中:e和βPLS分别代表PLS 优化后ELM 网络的噪声量和隐含层与输出层间输出权重。再对隐含层节点输出矩阵H和输出矩阵Y间进行双线性分解,可得如下表达式:
式中:S=[s1,…,sh]∈RN×h、P=[p1,…,ph]∈RL×h和EN×L分别为隐含层得分矩阵、载荷矩阵和残差矩阵;U=[u1,…,uh]∈RN×h、Q=[q1,…,qh]∈Rm×h和FN×m则分别代表输出层的得分矩阵、载荷矩阵和残差矩阵;且输出层潜在变量uk和隐含层潜在变量sk之间存在uk=sk×bk的关系;bk为uk和sk间的最小二乘系数;最后以矩阵形式对该关系进行表达,则:
采用非线性迭代偏最小二乘法(Nonlinear Iterative Partial Least Squares,NIPALS)求解输出权值,则该PLS-ELM 的求解式可表达为:
2 基于CEEMDAN-CPELM 的水体溶解氧预测模型
2.1 水体溶解氧预测流程
基于CEEMDAN-CPELM 水体溶解氧预测模型,在获取物联网监测系统感知信息后,首先进行溶解氧关联因子的影响性分析,捕捉水体溶解氧变化规律,利用CEEMDAN 分解溶解氧时间序列,再对各模态分量进行模糊熵值聚类重构,并基于数据重构结果构建PLS-ELM 溶解氧预测模型,其整体溶解氧预测详细流程如图3 所示。

图3 CEEMDAN-CPELM 溶解氧预测流程图
①特征提取。基于物联网水质监测系统实时采集水体参数和天气信息,采用线性插值法对丢失的数据进行插补,获得处理后的试验数据集;利用皮尔森相关系数计算各影响因子与溶解氧浓度的关联程度值,从而提取影溶解氧变化的关键因子,减少后续预测模型中的输入量,降低输入维度。
②CEEMDAN 模态分量模糊熵重构。针对溶解氧时间序列添加高斯白噪声,利用CEEMDAN 完成多尺度模态分解,再将得到的IMFs 模态分量进行模糊熵计算,度量各分量的熵值,并依据熵值完成IMF分量自适应重构。通过这一过程,有效地将目标时间序列自适应地重构为特定模式,获得特征统一的分量集合,为后续预测子模型构建提供有效依据。
③预测子模型构建。对CEEMDAN 模态分量模糊熵重构的结果进行分析,并基于重构的分量集合构建多个PLS-ELM 预测子模型。在试验数据集的训练集中进行模型训练,经过迭代试验确定预测模型的最优参数。
④性能对比。选择不同的预测评估指标,并在相同数据集中使用不同的预测方法进行测试试验,对比不同方法的预测性能差异,验证CEEMDANCPELM 水体溶解氧预测模型测试结果,分析其性能优越性。
2.2 特征提取
水产养殖物联网监测系统水下传感器采集的水体参数包括DO 浓度、水温(Water temperature,Wt)、pH 值等,自动气象站采集的天气参数包括气温(Air temperature,At)、风 速(Wind speed,Ws)、风 向(Wind direction,Wd)、大气压强(Atmospheric pressure,Ap)、湿度(Humidity,Hu)、二氧化碳(Carbon Dioxide,Cd)、辐射率(Radiance,Ra)、日照强度(Illuminance,Il)、光合有效辐射(Photosynthetically active radiation,Pr)等九项。这些数据在传输过程中不可避免地会发生数据延迟和丢失,本文针对延迟数据进行统一时间标准处理,并采用线性插值法对丢失数据进行插补。
同时,对上述水体参数与天气参数进行分析,利用皮尔森相关系数法计算各影响因子与溶解氧因子间的关联度值,其关联系数值如表1 所示。

表1 关联因子相关性系数
式中:x和y代表量关联变量,n代表变量长度,xi为x的第i个元素,yi为y的第i个元素,和分别为x、y中所有元素的均值。
由表1 可以发现,本试验中的监测信息与溶解氧之间均存在一定的关联,但风速、风向和二氧化碳浓度因子关联系数较低。故本次试验选择pH、水温、气温、大气压强、湿度、辐射率、日照强度、光合有效辐射等关联系数较高的因素作为强关联关键因子用于后续预测分析。
2.3 CEEMDAN 模态分量模糊熵重构
对于非平稳的溶解氧时间序列,使用CEEMDAN可以将原始时间序列的模型分解成频率由高到低的系列IMF 模态分量,避免模态混叠问题。然而经模态分解后获得的本征模态分量数量较多,且相邻模态分量之间复杂度、蕴含的物理意义均相近,故对所有IMF 分量均构建预测模型会消耗过多的模型训练和测试时间,预测复杂度明显上升。同时,为了提取有效信息,简化CEEMDAN 分解量的重构过程,本文采用模糊熵理论对CEEMDAN 分解的IMFs 分量进行复杂度度量,结合K-medoids 聚类方法,并对IMFs 模糊熵值进行聚类,自适应地实现初始溶解氧时间序列的分解-重构过程。其具体步骤如下:
①CEEMDAN 分解:设置初始分解参数,对初始溶解氧时间序列x(t)进行CEEMDAN 分解,获得z个本征模态分量IMF。
②IMFs 分量复杂度计算:对分解得到的IMFs分量分别计算其模糊熵值,并记作FuzzyEn1、Fuzzy-En2,…,FuzzyEnz。
③K-medoids 模糊熵聚类:首先设置聚类初始簇数,初始化簇心;再不断计算各簇中任意一点与簇中非簇心的累积距离和Ct,直至簇心不再发生变化,从而确定最佳簇心位置;最后,分别对各簇中IMF本征模态分量就进行合并重构,将初始溶解氧时间序列重构为新的模态分量集合的形式。
2.4 预测子模型构建与设计
在数据的特征提取完成后,本文确定PLS-ELM溶解氧预测子模型的输入维度为9,输出为待测时刻的溶解氧浓度。经各模态分量IMFs 的模糊熵复杂度度量后,使用K-medoids 方法完成IMFs 分量的模糊熵值聚类,获得z个新的模态分量。并以新的重构模态分量构建K=3 个PLS-ELM 预测子模型,分别对其中的参数进行设置。
本文使用交叉验证法,经多次运行且均方根误差(Root Mean Square Error,RMSE)[16]结果相近的条件下,设置偏最小二乘的潜在变量数h为5。另外采用试错法来确定各预测子模型的隐含层节点数,分别为39、31、37。
2.5 预测模型性能对比
本文选择平均绝对误差(Mean Absolute Error,MAE)[17]和RMSE 作为预测精度的评价指标,采用纳什效率系数(Nash-Sutcliffe Efficiency Coefficient,NSE)[18]作为预测模型预测结果好坏的评价指标。MAE 和RMSE 值越小,表明预测精度越高;反之预测精度越低。当ENAS值越接近1 时,表明该模型具有较高的可信度;当ENAS值越接近0 时,表明该预测结果可信,但存在一定的预测误差;当ENAS值远小于0 时,表明该预测模型不可信。其计算表达式如下所示:
式中:N为样本点量,yi为真实值,为模型预测值,代表观测平均值。
3 实验结果与分析
3.1 CEEMDAN 模态分解结果分析
如图4 所示为养殖水体溶解氧浓度的测量数据,对图中的溶解氧样本进行分析不难发现养殖水体的溶解氧浓度呈现较明显的周期性和非线性。

图4 水体溶解氧浓度测量数据
本试验设置CEEMDAN 分解的参数最大迭代次数为5 000 次,集合数为500,添加的白噪声数据的标准偏差为0.2,获得图5 所示分解结果。

图5 CEEMDAN 模态分解结果
由图5 可知,溶解氧原始时间序列被分解为13个模态分量。各IMF 模态分量的波动频率各不相同,且频率由IMF1至IMF13逐渐降低,IMF13因满足分解的终止条件,被判定为最终雨量信号r(t),无需后续分解。同时,这一分解结果充分显示了原始时间序列的变化趋势。
3.2 模糊熵重构分析
在上述13 个IMFs 分量中,利用模糊熵理论进行复杂度计算,组成新的特征向量。本试验中设置模糊熵的嵌入维度数为2,延迟因子系数值为0.2,相似度容差r=0.2×std,std 为模态分离时间序列的标准差。由此获得CEEMDAN 模态分量模糊熵估算结果,如图6 所示。

图6 CEEMDAN 模态分量模糊熵值结果图
由图6 可知,IMF1~IMF13分量的模糊熵值除个别点外,总体处于下降趋势。同时,说明CEEMDAN分解的不断进行,使得IMF 模态分量的变化趋于平稳状态。因此,模糊熵可以用于度量时间序列的分量复杂度。再对模糊熵值进行K-medoids 聚类,获得聚类结果如表2 所示。

表2 模糊熵重构结果
表2 中,由于IMF2~IMF5的波动频率较高,相互之间复杂度更接近,故将IMF2~IMF5合并重构为分量集合S1;IMF1、IMF6~IMF7三个模态分量的复杂度不高,模糊熵值最接近,故可以将该三个分量合并为分量集合S2;IMF8~IMF13的复杂程度较低,分量变化趋势明显,故可合并重构为分量集合S3。
3.3 改进算法的实验对比与分析
为了验证提出的CEEMDAN-CPELM 改进算法的性能,本文将构建CEEMDAN-ELM(基于CEEMDAN分解的ELM)、PLS-ELM(PLS 优化ELM)以及ELM作为对比模型,分析各方法的预测性能优劣。本试验中,各预测模型的试验数据相同,各优化模型的相关参数设置相同,预测模型的输入输出量相同,由此获得图7 所示预测效果图。
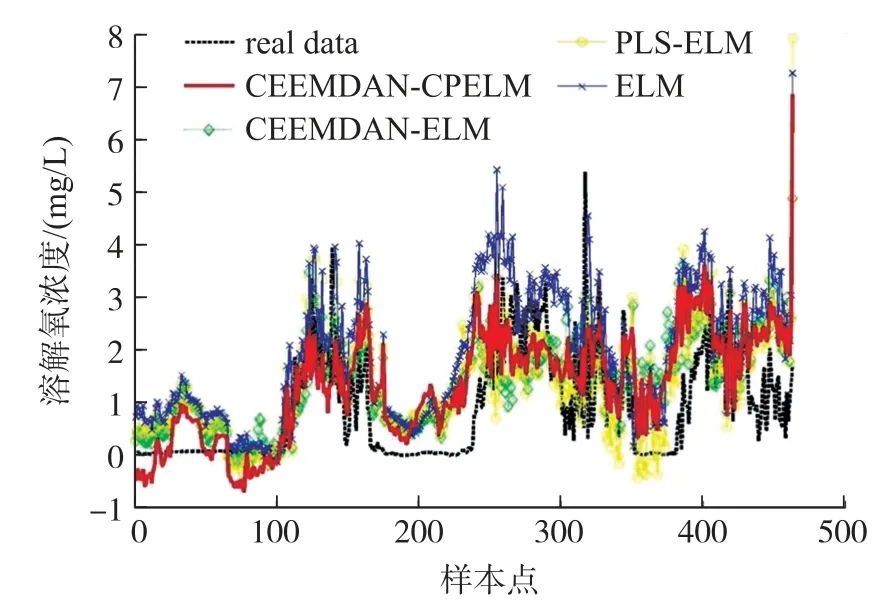
图7 不同改进模型的预测结果对比图
图7 清晰地显示各ELM 改进模型均能实现水体溶解氧浓度的预测,但各预测模型的预测效果存在一定差异。在大多数样本点中CEEMDAN-CPELM 模型的预测结果与真实值最接近,CEEMDAN-ELM 与PLS-ELM 模型的预测曲线较CEEMDAN-CPELM 预测结果虽有一定程度波动,但总体预测趋势较一致。然而,在局部样本点中,各预测模型的预测结果均与真实值存在一定偏差,且偏差程度不明确。为了清晰全面地对比各预测模型的预测效果,表3 详细罗列了各改进模型的预测性能值。

表3 多个改进ELM 模型的溶解氧预测性能结果
对表3 的多个改进ELM 模型的预测性能结果值进行分析可以发现,所提出的CEEMDAN-CPELM预测模型的DO 预测RMSE 值为0.959、MAE 值为0.748 9,相较CEEMDAN-ELM 模型分别降低了1.37%、3.24%。同时,CEEMDAN-CPELM 模型的溶解氧预测RMSE 和MAE 值相较于PLS-ELM 模型分别降低了2.36%和1.80%。由此表明本文提出的预测模型使用的CEEMDAN 分解和模糊熵聚类重构操作有效地捕捉了溶解氧的数据特征,提高了预测精度,偏最小二乘预测算法能避免本文中数据的强共线性问题,提高预测精度。CEEMDAN-CPELM 模型的预测RMSE 和MAE 值相较于ELM 分别降低了27.35%和29.59%,充分体现了两项优化操作结合的优越性,能有效提高算法的性能。CEEMDANCPELM 模型的ENAS系数值为0.0348,明显高于其他三个模型的ENAS值,也验证了模型性能的优越性。
3.4 不同预测模型实验对比与分析
为了验证提出的CEEMDAN-CPELM 模型的适用性,本文选择GA-SELM[19]、LSSVM 和传统BP 神经网络模型作为对比模型。各模型的试验数据集相同,水体溶解氧预测结果如图8 所示。
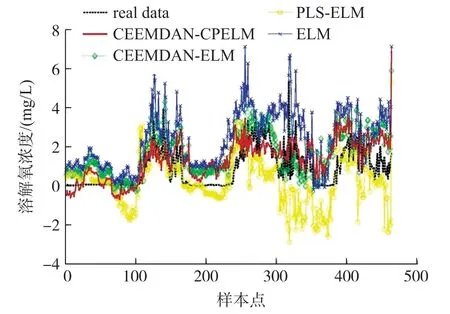
图8 不同类型预测模型的溶解氧预测结果图
由图8 可以发现,上述四种不同类型的预测模型虽然均实现了溶解氧浓度的预测,但预测效果差别较大。CEEMDAN-CPELM 模型的预测结果曲线最接近溶解氧浓度的真实测量值变化曲线。GASELM 模型的预测结果曲线与CEEMDAN-CPELM的预测效果相近,也能较好地将溶解氧真实变化趋势预测出来。LSSVM 和BP 网络模型的预测效果明显比CEEMDAN-CPELM 和GA-SELM 模型差,在很多样本点上偏离真实值较远。为了说明CEEMDAN-CPELM 模型的性能优势,表4 详细列出了不同类型模型的预测性能结果。

表4 不同类型预测模型的预测性能结果表
从表4 中可以清楚地看出,CEEMDAN-CPELM模型的RMSE 较GA-SELM、LSSVM 和BP 模型分别降低了13.36%、32.21%和44.81%。CEEMDANCPELM 模型的MAE 较GA-SELM、LSSVM 和BP 模型分别降低了17.57%、26.41%和48.68%。同时,CEEMDAN-CPELM 模型的ENAS系数值远高于其他模型的ENAS系数值。故,CEEMDAN-CPELM 模型的预测性能较其他模型的预测性能有明显的提高。
结果表明,基于CEEMDAN 分解、模糊熵值聚类重构、改进ELM 等优化操作构建的CEEMDANCPELM 模型可以实现水体溶解氧浓度的有效预测。该模型具有较高的预测性能,在不同类型的预测模型中也具有明显的预测性能优势。
4 结论
本文提出的基于CEEMDAN-CPELM 的水体溶解氧浓度预测模型,能够针对真实养殖环境中非线性变化的溶解氧浓度进行预测。该模型基于多元时间序列的强关联性和非平稳性,构建能应用于实际养殖环境的预测模型。其主要结论如下:
①通过CEEMDAN 将溶解氧非线性数据分解为多尺度IMF 模态分量及余量,再通过“分解-重构-预测”的结构提高溶解氧预测的精度。
②采用PLS 方法对ELM 进行改进,避免多元预测模型中输入信息冗余带来的强共线性问题,从而提高预测模型的性能。
③以实际养殖生产环境数据为试验对象,将CEEMDAN-CPELM 模型的溶解氧预测性能值与多种改进ELM 模型以及不同类型预测模型进行对比分析,本文提出的预测模型获得了较明显的优势。验证了CEEMDAN-CPELM 模型对养殖水体溶解氧预测的有效性和可行性。
猜你喜欢
摄影世界(2022年1期)2022-01-21
基层中医药(2021年12期)2021-06-05
科学与信息化(2020年11期)2020-06-19
知识经济·中国直销(2018年12期)2018-12-29
英美文学研究论丛(2018年1期)2018-08-16
商周刊(2017年6期)2017-08-22
纺织科学研究(2017年6期)2017-07-03
计算机测量与控制(2017年6期)2017-07-01
水利科技与经济(2017年6期)2017-04-28
山东大学法律评论(2016年0期)2016-08-16
