
近红外无创血糖浓度的Label Sensitivity算法和支持向量机回归
2024-03-07 01:49宦克为姜志侠张瀚文周林华
光谱学与光谱分析 2024年3期
孟 琪, 赵 鹏, 宦克为, 李 野, 姜志侠, 张瀚文, 周林华*
1. 长春理工大学数学与统计学院, 吉林 长春 130022
2. 长春理工大学物理学院, 吉林 长春 130022
3. 长春理工大学数学实验示范中心, 吉林 长春 130022
引 言
近红外光谱分析技术在医疗健康领域尤其在血液成分无创监测中扮演着重要的角色[1-2]。 血糖是评价人体健康程度的一项重要指标, 持续性追踪血糖变化尤为重要。 然而, 人体组织背景复杂、 血糖信号变化微弱以及测量条件有限等原因使得无创监测未能实现。 前辈学者为攻克这一难题做了许多努力, 1987年Dahne首次应用近红外分光法进行人体血糖无创检测[3], 开启了无创检测血糖的光谱领域。 2003年Katsuhiko Maruo等使用近红外光测量真皮组织下的葡萄糖含量进而追踪血糖变化, 该方法可以减弱人体组织对光谱信号的干扰[4]。 Ramasahayam等使用人工神经网络对近红外信号进行处理, 将神经网络这一强有力工具应用到血糖无创检测中[5]。 以消除个体差异为重点, 天津大学李刚团队提出了动态光谱法用于实现血液检测[6-8]。 进一步考虑血糖变化的本质, 代娟综合多种因素确定了近红外光谱的测量波长及部位, 提出基于粒子群算法优化两个神经网络的模型[9]。 2018年, 徐馨荷为了提高无创血糖测量的精度, 基于“M+N”理论从误差理论的角度阐明了在光谱分析中M种非测量组分和N种外界干扰因素对测量精度的影响。 考虑了M因素中四种非测量组分和N因素中接触压力对血糖测量值的影响, 建立基于“M+N”理论的血糖人体试验系统[10]。 针对实际监测过程中传感器, 环境噪声等各种因素限制其测量精度的问题, 黄永英提出了一种移动窗双层筛选处理算法结合实时自补偿校准算法的双重校准模式, 实现对电流数据的信号漂移补偿, 并基于此设计了一种可实时, 动态检测血糖变化的监测器[11]。
以上工作对引起血糖变化的多重因素充分考究, 针对数据采集与分析做了有效推进, 从光谱中解析葡萄糖浓度信息, 通常采用如偏最小二乘回归(PLSR)等多变量回归的方法在实际测量中[12]。 陈真诚学者提出一种脉搏波预处理方法, 采用经验模态分解和三次样条插值算法去除原始脉搏波的高频噪声和基线漂移。 运用动态光谱频域提取法提取对数脉搏波的基波分量, 采用的偏最小二乘法交叉验证的方法[13]。 随着机器学习的热潮, 支持向量机展现了处理回归问题中的优势, 便有学者马爽等提出了基于支持向量机回归模型的无创血糖光谱算法, 该方法预测准确度优于偏最小二乘回归10%~15%[14], 为回归模型的优化提供了新思路。
现有回归预测模型常使用全波段数据, 对特征波段的选取多基于特征向量之间的相关性和对模型的贡献力等因素, 应用连续投影算法(SPA)[15]、 无信息变量消除法(UVE)、 最佳指数法(OIF)等方法以去除冗余信息以降低数据维度、 减少运算量。 孙静涛等对多元散射校正(MSC)处理后的光谱分别利用连续投影算法(SPA)、 竞争性自适应重加权算法(CARS)和CARS-SPA方法筛选了哈密瓜可溶性固形物和硬度的特征波长, 并建立支持向量机回归模型[16]。 张紫杨提出了基于最佳光程长的测量波长选择原则, 可在测量灵敏度最大的条件下, 评价葡萄糖吸收光谱的测量是否可行[17]。 此种方法强调的是特征向量之间的关系并没有考虑到标签的变化。 根据前辈学者的分析, 证实血糖存在明显的吸收波峰且不同波长下包含血糖变化的信息量有差异, 因此提取更满足标签变化的有效波长至关重要, 并考虑将标签值引入特征波长挑选算法中。 本文基于标签敏感度算法(label sensitivity, LS)实现了近红外光谱特征波长的有效选择。
1 算法模型原理
1.1 Label Sensitivity原理
由于不同波长下血糖对光的吸收量有差异, 提取有效波长非常有必要。 我们的算法思想为期盼挑选出与浓度差值变化保持一致的特征波长, 认为挑选出的LS值高的特征波长应具备以下特点: (1)同一浓度数据分布集中即方差较小。 (2)不同浓度之间, 近红外吸光度的均值具有区分性并且变化幅度与浓度差值呈正相关, 即当浓度差值越大时, 吸光度均值差也应越大。 设原始光谱信号值为
(1)
式(1)中,N为所有浓度,L为选定浓度下样本总数,K为波长总数。
如图1, 在波长k处, 对应4组浓度数据, 浓度分别为la,lb,lc,ld, 且有la-lb≤lb-lc≤la-lc, 球体代表不同浓度值下的吸光度值, 球心A、B、C为同一浓度的吸光度均值。 由于人体血液是流动变化的, 因此可能存在偏离中心值的数据。 选择的波长应保证同一浓度数据尽量集中, 不同浓度中心点的期望满足如下序关系Dab≤Dbc≤Dac。

图1 算法原理可视化图

图2 近红外光谱成像仪
设原始光谱信号值为xi, j(k),i=1, 2, …N;j=1, 2, …,L;k=1, 2, …,K。
首先, 对原始光谱信号值做多元散射校正(MSC)
(2)
式(2)中,F为多元散射校正函数, 使用吸收光度法的基本定律Lambert-Beer求吸光度
(3)
对吸光度Ai,j(k)归一化
(4)
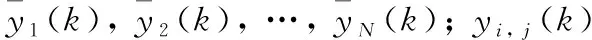
(5)
(6)
Qi, m(k)刻画标签差值与均值差值的比例, 由式(5)可知, 当特定波长下, 吸光度方差越小, 且Qi, m(k)取值越接近1时, 即标签差值与均值差值变化量越保持一致时,LS取值越大。 根据LS值大小重新对波长序列排序。
1.2 SVR算法原理
SVR是支持向量机在回归问题上的应用。 根据上述给定的吸光度数据和血糖浓度数据, SVR的训练数据为D={(x1,y1), (x2,y2), …, (xN,yN)}, 最终得到一个回归模型f(x)=ωTx+b, 使得f(x)与y接近, 其中ω和b是参数。 在回归问题中, 给定一个边界值φ, 即当|f(xi)-yi|≥φ时计算损失。
SVR的优化目标为
(7)
式(7)中,C为正则化常数,lφ为损失函数, 表示为
(8)
引入松弛变量ξi和拉格朗日乘子ui, 优化目标变为
(9)
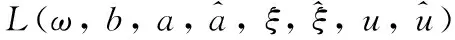
(10)
即f(x)的解为
(11)
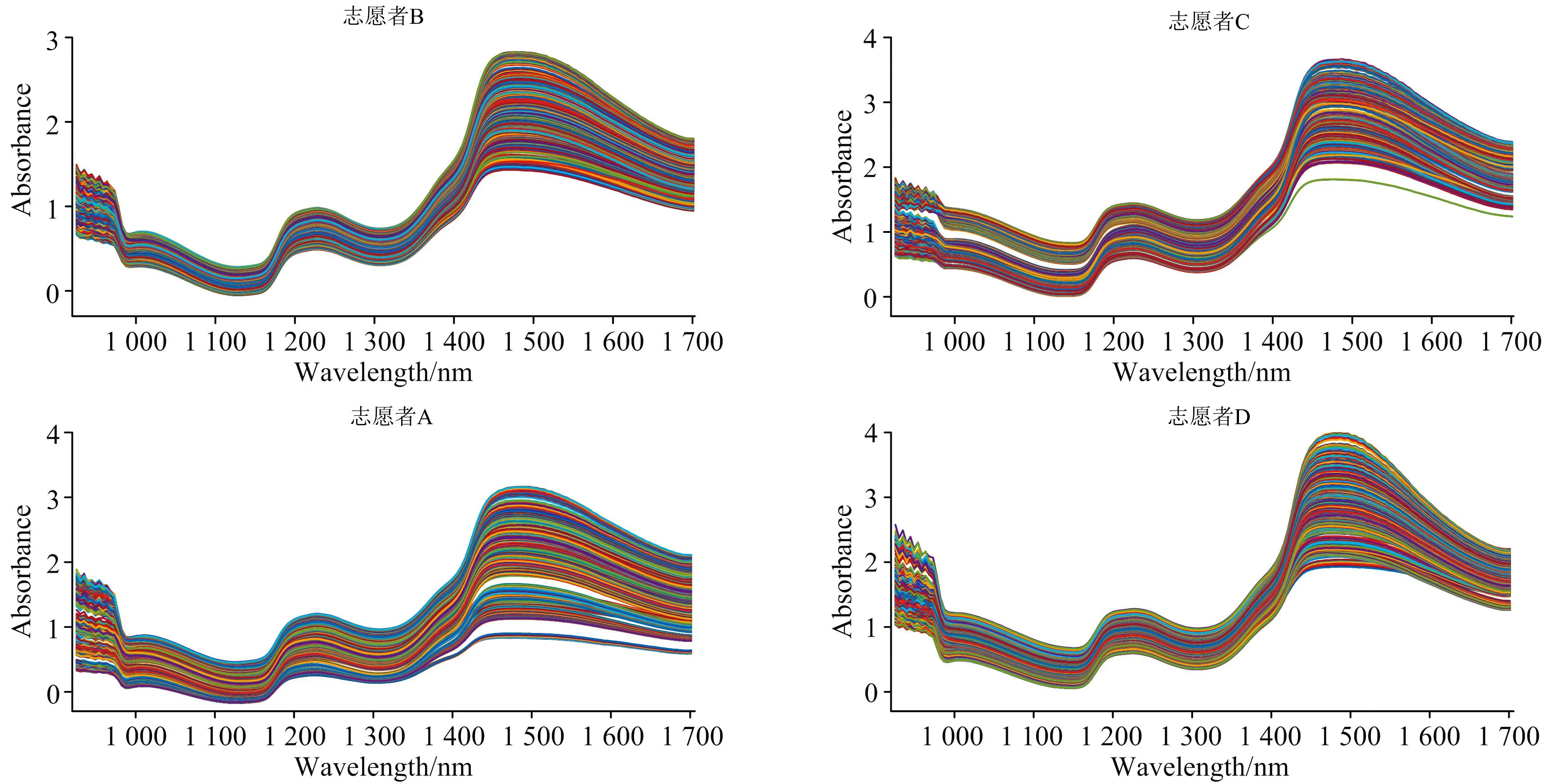
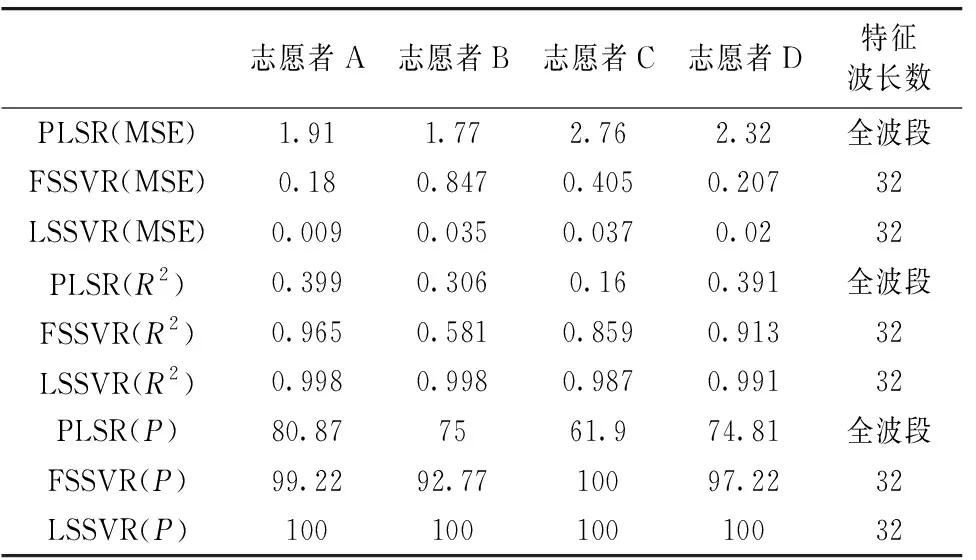
若0 (12) (13) 为获取更高质量的实验数据, 本文设计OGTT葡萄糖耐量实验, 并搭配使用近红外光谱成像仪(注: 型号是HyperspecTM, 波长范围为900~1 700 nm, 可调节范围)测量反射光谱。 实验开展之前, 志愿者保持10 h以上空腹, 保持人体状态稳定。 选取右手食指作为测量位置, 被测对象在5 min内饮入250 mL含75 g的无水葡萄糖粉剂的水溶液, 在2.5 h内被测对象的血糖浓度会出现一个从谷到峰, 最终回到谷底并震荡的趋势。 因此测量时间设定为3 h, 考虑仪器运行时长导致光源温度升高从而造成的光源不稳定, 在每次采集前进行白板矫正。 并探究接触压力对测量的光谱信号的影响, 确保手指与端面轻微稳定的接触。 实验获取4人、 每人两天, 每天14个时刻、 每时刻测量90条与人体血糖相关的谱带信息, 共有112个浓度、 10 080条数据, 每条数据对应164个波长。 使用近红外光谱成像仪测量光谱数据, 测到的表征数据为三维的Raw数据文件, 每组重复扫描90次, 每个像素点包含164个波段的光谱数据, 应用图像边缘检测算法截取食指指尖ROI区域的光谱信号值, 并在特定区域内进行数据平均处理。 简单处理后使用Lambert-Beer定律求得的原始吸光度如图3。 图3 四名志愿者所有浓度原始吸光度图 当考虑到血液的散射效应时, 不同波长光程长不一致, 即会导致脉动血液光程变化量不同, 考虑去除部分散射效应的影响, 引入多元散射校正方法。 多元散射校正方法由Martens等首先提出, 是一种多变量散射校正技术, 用于分离散射介质光谱中物理光散射信息和化学光吸收信息, 然后消除不同光谱之间的物理散射信息差异, 光谱进行MSC预处理能有效减少模型的最佳因子数, 简化数学模型、 使模型更稳定[19]。 由图3, 900~1 000 nm区间内的16个波长数据噪声大, 参考动态光谱数据质量评价截取1 000~1 700 nm区间的数据进行分析[20]。 对上述原始反射数据多元散射矫正后, 再使用Lambert-Beer定律求得的吸光度图如图4。 由图4可知, 针对每名志愿者28个浓度2 520条数据, 使用多元散射校正后的数据更集中, 数据质量有明显提升。 图4 四名志愿者所有浓度MSC后吸光度图 3.1.1 对比算法: FS算法 FS算法的思想是若某固定波长对动态血液中血糖浓度变化比较灵敏、 区分度大, 其对应光谱数据应该具有两个特点: (1) 相同浓度的近红外吸光度分布比较集中, 即相同浓度数据的方差较小; (2)不同浓度的近红外吸光度具有较好的分离性, 即相邻浓度数据均值之差较大。 据此给出FS算法原理FS算法的提出, 将特征波长挑选转化成了区分度取值排序问题。 (14) 3.1.2 特征维数的优化分析 截取1 000~1 700 nm区间内149个波长的数据。 由式(5)和式(6)根据标签敏感度算法对波长序列重新排序得到波长敏感度排序图(图5), 其中横坐标为根据敏感度值重新排序后的波长序列, 纵坐标为LS(k)数值。 显然, 不同波长的贡献值不同, 选择原始光谱信号值区分度高的波长非常有必要。 图5 四名志愿者的波长敏感度图 回归算法的运算速度和复杂性跟数据的特征维数密切相关。 挑选出的特征波长的数量多少会影响预测结果。 因此, 通过分析不同特征维数对模型的影响, 确定最优特征波长数目是本节的研究重点。 本小节设计对比实验, 探究不同波长数目对预测集的均方根误差、 相关系数的影响。 如图6示, 每组光谱数据选用的特征波长数l对预测精度影响的结果, 从图中得到以下结论: (1)均方误差和相关系数两种评价指标, 我们提出的LS算法表现总体优于FS算法。 (2)增加特征波长数l可提升支持向量机回归的预测精度, 当l≥32之后, 两种评价模型均区域收敛, 此时仍再增加特征波长数会进一步使计算复杂, 但对于回归精度的提升十分有限。 (3)为确保预测精度高的前提下计算复杂度不高, 确定志愿者A的特征波长最佳维度为32。 图6 特征维数对FSSVR、 LSSVR模型预测精度的影响(志愿者A) 图7 志愿者A的交叉验证克拉克误差分析图 单一血糖浓度选取90个光谱样本, 每帧光谱应用算法筛选前32个特征波长, 利用合适的超参数和训练数据训练模型, FSSVR和LSSVR预测与PLSR预测的5折交叉验证结果如表1所示。 表1 四名志愿者交叉验证预测结果 由表1可知, 以志愿者A为例分析, 使用PLSR回归无创血糖浓度中, 实际测量浓度与预测的数值相关性低, 预测效果差。 与之相比FSSVR的相关性有56.6%的提升, 并且均方根误差下降了91.17%, 回归效果较好。 LSSVR算法, 较FSSVR算法预测效果有进一步提升, 预测值与真实值保持一致相关系数高达99.8%, MSE下降至0.009。 由此证明, LSSVR具有最优的预测效果。 为便于观察数据最终的预测效果, 使用克拉克误差分析图, 克拉克误差分析认为A区可允许误差为, 落在A区的数据占全部数据的比值是预测效果的重要评价标准之一。 由图6可知FSSVR算法预测性能较PLSR明显降低。 而LSSVR的预测效果进一步提升, 预测值与原始标签值保持高度一致。 提出了与标签差值相关联的特征波长挑选算法LS算法, 分别使用PLSR、 FSSVR、 LSSVR回归模型设计对比实验, 并探究最优特征波长数的优化分析, 结果表明当最优波长数量为32时, 评价指标均趋于稳定、 相对预测效果最佳。 在选定前32维特征波长后, 交叉验证实验表明LSSVR的预测值与真实值保持高度一致, MSE、P、R2三种评价指标较前两类方法均有显著提升, 验证了LSSVR的优势。 人体是一个复杂的系统, 人体组织在不同时间、 不同位置、 不同环境下光学性质有所差异。 并且不同个体之间, 手指尺寸、 各组织厚度和血液搏动幅度等生理上的不同, 也会造成光谱信息有很大的差异。 这是我们提出的LS算法的基础。 不同的回归算法使用性能三角形评估算法的预测效果如图8。X轴为预测值与真实值的相关系数。Y轴位于clarke网格A区域的概率, 越靠近1证明落在可允许的误差范围内的数据占比越大。Z轴为预测值与真实值的均方根误差, 误差越小, 预测性能越佳。 以性能三角的顶点与原点组成的性能四面体观测算法的表现效果, 以XOY平面为底面, OZ为高。 当底面OPR三角形的面积越大, 并且OM的取值越小时性能越佳。 图8给出的效果更直观, LSSVR在不同志愿者的数据预测准确率较前其他方法均有明显提升, 由此证明LSSVR具有普适性。 图8 四名志愿者不同算法的性能三角形 提出的LSSVR表现优异, 结合支持向量机回归对预测集的交叉验证预测精度极高, 期望在后续工作中重新划分数据集, 希望当测试集为从未参与训练的浓度数据时, 模型仍能保持优异。 还可以进一步对回归方法做改进, 深度神经网络发展迅猛, 在未来工作中考虑将深度神经网络引入回归模型中, 为进一步推进无创血糖的进展做出贡献。2 实验部分
2.1 方案设计
2.2 数据预处理

3 结果与讨论
3.1 特征维数优化分析



3.2 实验对比与结果分析
4 结 论

猜你喜欢
特产研究(2022年6期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
汽车电器(2019年1期)2019-03-21
实用口腔医学杂志(2017年6期)2017-09-19
光谱学与光谱分析(2016年5期)2016-07-12
中国照明(2016年4期)2016-05-17
中国光学(2015年5期)2015-12-09
河南科技(2015年8期)2015-03-11
物理实验(2015年9期)2015-02-28
食品工业科技(2014年23期)2014-03-11
