
基于认知诊断模型PISA数据的学生学习轨迹分析
2024-03-08 03:51张兆远张继超
长春师范大学学报 2024年2期
崔 爽,张兆远,2,张继超
(1.伊犁师范大学数学与统计学院,新疆 伊宁 835000; 2.伊犁师范大学应用数学研究所,新疆 伊宁 835000;3.长春财经学院数学教研部,吉林 长春 130122)
0 引言
传统的教与学是脱节的、碎片化的,使得教与学之间缺乏直观联系.学习轨迹[1]是一个个体在学习过程中所经历的发展、进步和变化的路径.学习轨迹成为教和学之间的纽带,学习轨迹包含了对学习动态过程的描述,对学生的“学”给出了个性化、精细化的诊断报告,为教师的“教”提供了参考依据,教师可以通过学习轨迹能够获得直观有效的信息.学习轨迹的获取,可以通过对学生学习过程的持续观察,也可以通过对学生的测试和定量分析.本文采用加入反应时间数据的重参数化DINA模型,对学生的测试结果进行分析,估计学生是否掌握相应的知识点或是否具备相应的技能属性,进而得到学生的学习轨迹. 国际学生评估项目(Program for International Student Assessment,PISA)是国际上具有广泛影响力的大型教育评估项目,为国际教育水平的横向参考比较提供平台,PISA测评对世界教育改革的影响在某种程度上代表了世界教育改革的趋势[2].本文对中国、新加坡、日本、美国、加拿大、英国、芬兰、俄罗斯、美国、巴西、哥伦比亚和沙特阿拉伯12个国家的PISA 2015数学测试数据集[3]进行统计分析,绘制出各国学生的学习轨迹并进行比较研究.
1 加入反应时间的DINA模型
在计算机化的测试中可以获取作答反应结果和作答反应时间两类数据,PISA 2015数学测试[3]采用计算机化的考试容易获得的详细作答反应时间数据.作答反应时间蕴含被试的潜在能力信息,比如当被试在低风险测试中时会以更快的速度作答,或具有先验题目知识的被试反应时间可能会更短,这其中包含的潜在信息很难仅根据作答反应结果来识别.在认知诊断中加入作答反应时间信息作为辅助信息,与作答反应结果共同使用,可以获得更准确的诊断信息.下面引入结合作答反应结果和作答反应时间两类数据的联合模型.
1.1 重参数化DINA模型
设Yni为第n个人对第i道题的作答反应结果,在DINA模型[4]中,属性与作答反应结果之间的关系可以表示为:
(1)
其中,P(Yni=1)表示第n个人答对第i道题的概率,gi和si分别表示第i道题的猜测概率和失误概率,1-gi-si为题目区分度[5];αnk表示第n个人是否具备第k个属性,如果第n个人掌握第k个属性则αnk=1,否则αnk=0;Q是一个I×K阶矩阵[6],其中,qik表示第i道题是否考查第k个属性,如果第i道题考查第k个属性,则qik=1,否则qik=0.由此矩阵Q在学生的可观测反应与不可观测反应的认知状态之间架起了一座桥梁.
将P(Yni=1)重参数化,首先将影响Yni中的两个参数gi和si重参数化[7-9],即
γi=H(gi),
(2)
δi=H(1-si)-H(gi),
(3)

(4)
式(4)也称为重参数化DINA模型[7],被试掌握属性的概率为:
H(P(αnk=1))=τkθn-υk,
(5)
其中,P(αnk=1)为第n个人掌握第k个属性的概率,τk,υk分别为斜率参数和截距参数,θn表示第n个人的一般能力,θn值越高意味着被试掌握相应属性的概率越高.
1.2 反应时间模型
设Tni为第n个人作答第i个题目的反应时间,它的对数正态反应时间模型[10]为:
(6)
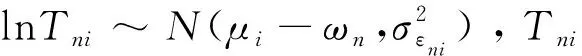
1.3 先验分布
在分层建模框架下,假设加入反应时间的DNIA模型的题目参数服从三维正态分布:
(7)
式(7)给出了DINA模型中题目参数间的关系[11],对数正态反应时间模型中的误差项εni不包含在χi中,此为一个独立分布.
类似地,假设加入反应时间的DNIA模型中关于人员的参数服从二维正态分布:
(8)
因此,由式(1)至(8)构成加入反应时间的DNIA模型[12].
题目参数的先验分布[12]设定如下:
μβ~N(-2.197, 2),μγ~N(4.394, 2)I(μγ>0),
μδ~N(3,2),Σ1~W-1(R,3),
其中,指定β,γ,δ的先验分布用于重参数化DINA模型,W-1表示逆Wishart分布,R是一个三维单位矩阵.
人员参数的先验分布[12]设定如下:
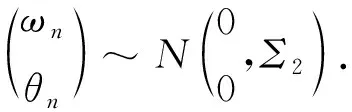

属性参数的先验分布[12]设定如下:
τk~N(0,4)I(τk>0),υK~N(0,4).
2 PISA数据分析
本文数据来自PISA 2015的数学测试部分[3],选取其中12个国家的12 918名学生对9个题目的作答结果,这组测试题考查了4个属性.
2.1 数据概况
根据参与评估的国家所在地理位置,选取12个国家学生的作答数据,数据分别来自亚洲的中国(CHI,选自北京、上海,江苏和广东)1 067份、新加坡(SGP)687份、日本(JPN)731份、沙特阿拉伯(ARB)1 387份;北美洲的美国(USA)567份、加拿大(CAN)2 021份;南美洲的巴西(BRA)1 365份、哥伦比亚(COL)1 101份;欧洲的英国(GBR)1 396份、芬兰(FIN)603份、俄罗斯(RUS)571份;大洋洲的澳大利亚(AUS)1 422份.根据PISA 2015数学评估框架和已发布的基于计算机的数学题目评估了4个属性,即变化和关系α1、量化α2、空间和形状α3、不确定性和数据α4,表1为测试题目组所考查的认知属性及其含义.

表1 测试题目组考查的认知属性及其含义
数据包括每个题目的作答反应得分和作答反应时间.作答反应时间是由数据库中开始作答时间减去结束作答时间计算得到(单位:s),在建模时将其转换为对数反应时间.数据中没有响应(原始代码9)的被试将被删除,未尝试回复(原始代码6)的题目得分记为零分.本文主要分析二分反应数据,所以只有满分被视为正确反应,其他分数均被视为错误反应.表2是测试题目组的Q矩阵.

表2 测试题目组Q矩阵
2.2 整体作答分析
研究对象是来自12个国家的12 918名学生对9个题目的作答结果.图1列出了所有学生作答正确的题目数量统计分析情况,可以看出,52%的学生正确作答数量小于5道,3.7%的学生正确作答数量为0,3.8%的学生正确作答了所有题目,见图1.

图1 学生作答正确的题目个数统计
本文使用R语言调用R2jags包[13]对加入反应时间的DINA模型中的参数进行估计.表3和图2显示了12个国家学生掌握4个属性的概率,另外表3还展示了12个国家学生的平均个人能力参数θ和平均速度参数ω.

图2 12个国家学生掌握4个属性的概率
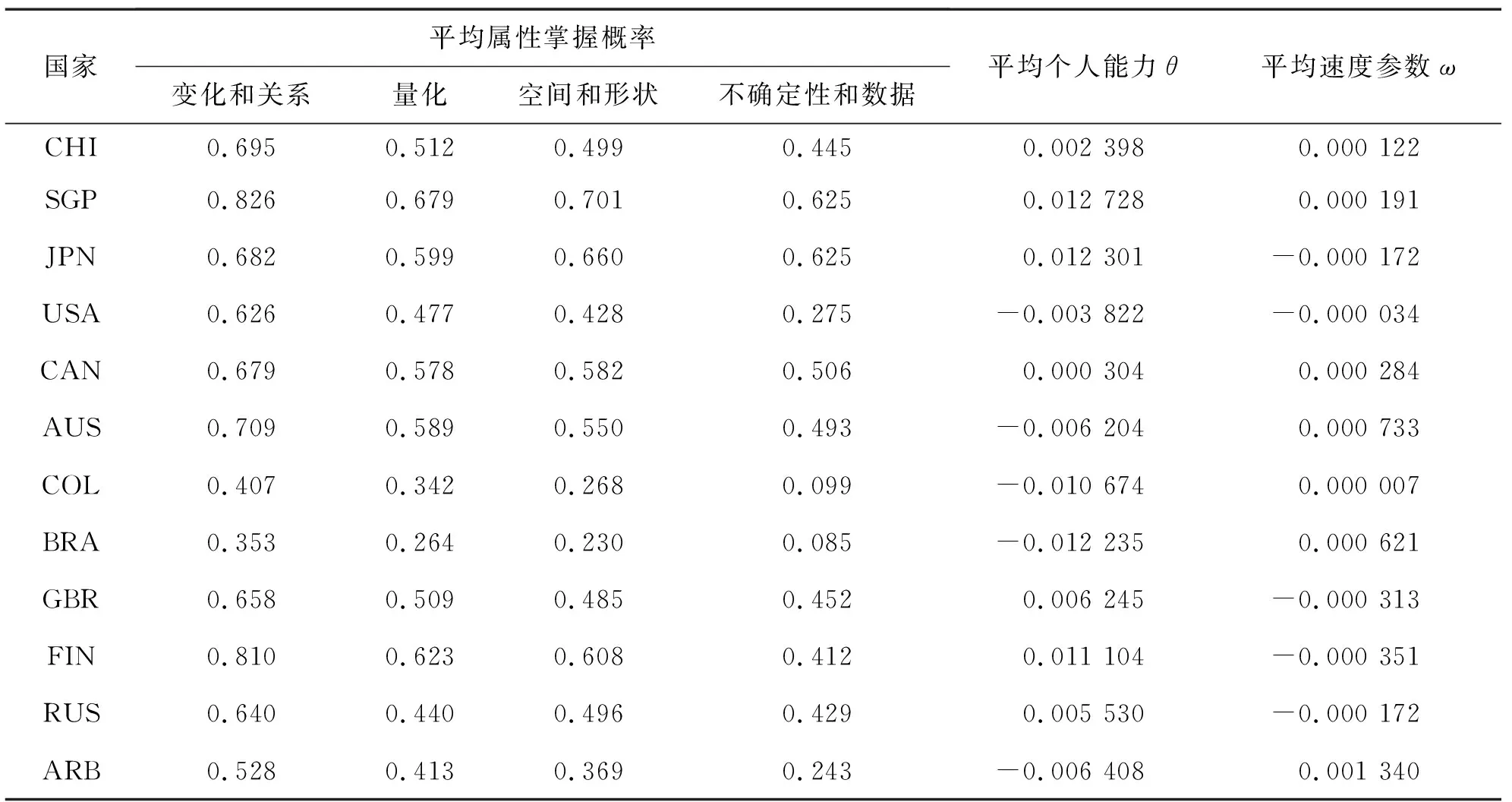
表3 12个国家学生的平均属性掌握概率
从图2中12个国家4个属性的后验概率可以看出,总体上属性α1的掌握情况最好,属性α4的掌握情况最差,属性α2与α3居中差异不大.新加坡(SGP)和日本(JPN)在属性α4的表现明显优于其他国家.综合来看,新加坡(SGP)在这4个属性的综合表现最突出,芬兰(FIN)、加拿大(CAN)、中国(CHI)、英国(GBR)、日本(JPN)、美国(USA)综合表现比较优秀,其次为哥伦比亚(COL)、巴西(BRA).
2.3 题目分析
选取的题目组中共有9个题目,分别为CM033Q01、CM474Q01、CM155Q01、CM155Q02、CM411Q01、CM411Q02、CM803Q01、CM442Q02、CM034Q01,每道题目所对应的属性见表2.图3显示了猜测概率g和失误概率s的估计值,整体来看,第1、2、3题的猜测概率值大而失误概率值小,其中第1题最为明显,这表明这道题更有可能被猜对;第7、8、9题的猜测概率值小而失误概率值大,其中第7题最为明显,这表明这道题迷惑性强,更容易作答失误.日本学生整体的失误概率值都在0.3以下,这说明日本学生做题严谨,在会做的情况下答错概率很小,巴西学生整体的失误概率比较大.


图3 12个国家9道题的猜测概率和失误概率的估计值
2.4 属性分析
通过模型估计出每个学生对属性的掌握情况,将学生是否掌握指定属性的情况称为学生的认知状态,且认知状态的比例对应该国学生掌握指定属性的情况.计算相应认知状态在该国内的比例方法为:由PISA数据估计出每个学生的认知状态,可能的认知状态有16种分别为(0,0,0,0)、(1,0,0,0)、 (0,1,0,0)、(0,0,1,0)、(0,0,0,1)、(1,1,0,0)、(1,0,1,0)、(1,0,0,1)、(0,1,1,0)、(0,1,0,1)、(0,0,1,1)、(1,1,1,0)、(1,1,0,1)、(1,0,1,1)、(0,1,1,1)、(1,1,1,1),据此计算每个国家学生在这16种认知状态下的占比,可得出所有认知状态的比例,如表4所示(12个国家学生在各国内部各认知状态占比从大到小排序,记录前五的结果,第六及之后的占比数值过小不具备参考价值,未纳入表格).由表4可知,有7个国家的(1,1,1,1)认知状态在该国内排名第一,这表明这些国家掌握所有属性的学生占比最大,巴西的(1,1,1,1)认知状态占比仅为7.6%;新加坡的(1,1,1,1)认知状态占比为56.8%,在所有国家中排在首位.

表4 12个国家学生占比前五的认知状态
2.5 学习轨迹分析
学习轨迹是一个个体在学习过程中所经历的发展、进步和变化的路径[1].或者说,学习轨迹是认知状态的层次结构,用偏序关系来表征认知状态之间的关系.该结构为学习内容提供了一个认知序列,为更科学地编写教案和进行教学提供了理论依据,可以依此设计科学合理的学习进度计划.认知状态的层次结构可以基于高频认知状态之间的逻辑依赖关系获得,由此确定出主学习轨迹和次学习轨迹.学习轨迹严格遵循学生认知规律的学习路线图,可以帮助学习者按照认知发展规律来安排相应知识和技能的学习进度计划.
在建立学习轨迹的过程中,假设学生从相对简单的知识开始学习,然后学习更难的知识,通常认为掌握低层次属性更容易,掌握高层次属性更困难.在特殊情况下,学生可能会先掌握较难的知识,然后在此基础上快速掌握简单的知识,前提是简单知识不是困难知识的唯一前提要求.在绘制学习轨迹时,一般假设初始状态为学生未掌握所有规定知识点或属性,学生每次只学习一个知识点,直到掌握所有知识点或属性.本文通过加入反应时间的DINA模型估计出PISA 2015数据中12个国家学生的认知状态,进而绘制出学生可能的学习轨迹.主学习轨迹绘制步骤如下:
步骤1 假设初始认知状态为(0,0,…,0);
步骤2 每推进一层只能比前一层多掌握一个属性,计算出相应推进一层各认知状态的所占比例;
步骤3 挑出每推进一层中占比最大的认知状态,作为该层的标记状态;
步骤4 最后一层推进到认知状态(1,1,…,1)结束.
主学习轨迹是由每一层中占比最大的认知状态构成,因此主学习轨迹一般是唯一的.在绘制学习轨迹过程中通常会将每一层中认知状态占比过小的直接剔除以便于简化图形.次学习轨迹是剔除过小值后每一层认知状态中仍然保留的状态,同理再运用主学习轨迹的绘制方法即可绘制出次学习轨迹,所以次学习轨迹可能是不唯一的.
例如,在表5中,(1,0,0,0)、(1,1,0,0)、(1,1,1,0)是从每一层认知状态中个挑出占比最大的认知状态.显然,属于认知状态(1,1,0,0)的被试已经掌握了认知状态(1,0,0,0)中的所有属性,即(1,0,0,0)⊂(1,1,0,0).下面以中国学生的学习轨迹为例进行绘制.
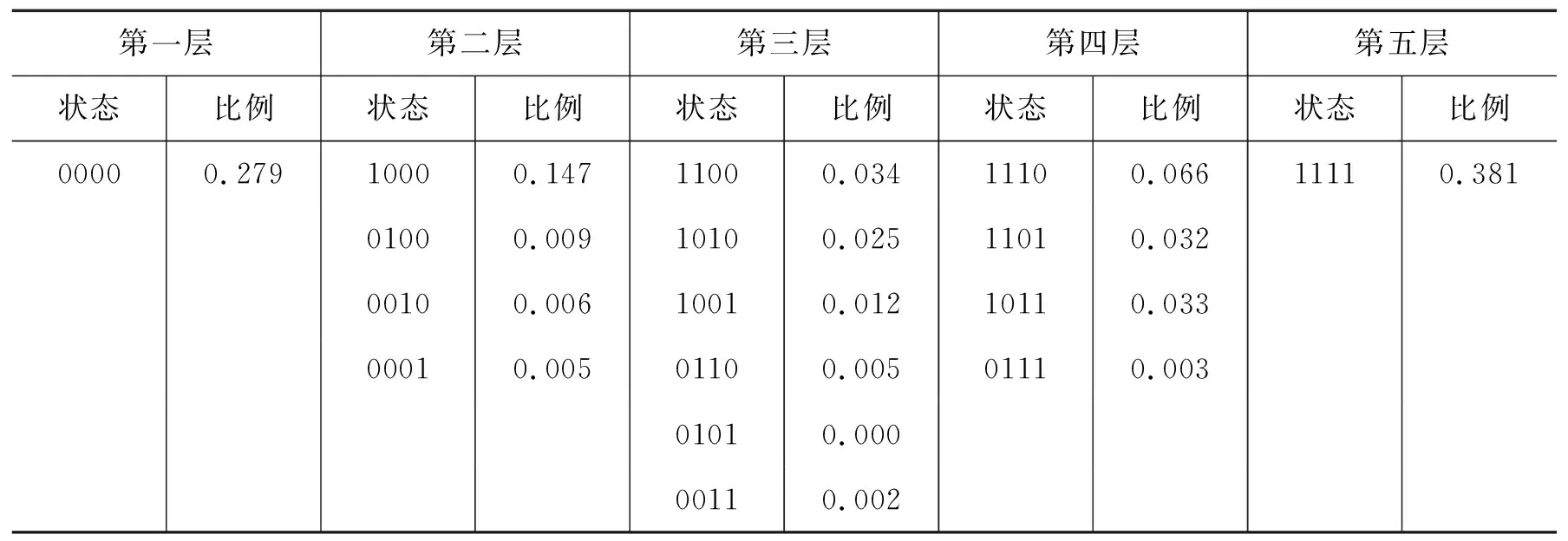
表5 中国学生各层认知状态所占比例
根据表5绘制中国学生学习轨迹过程拆解图(图4),绘制步骤如下:
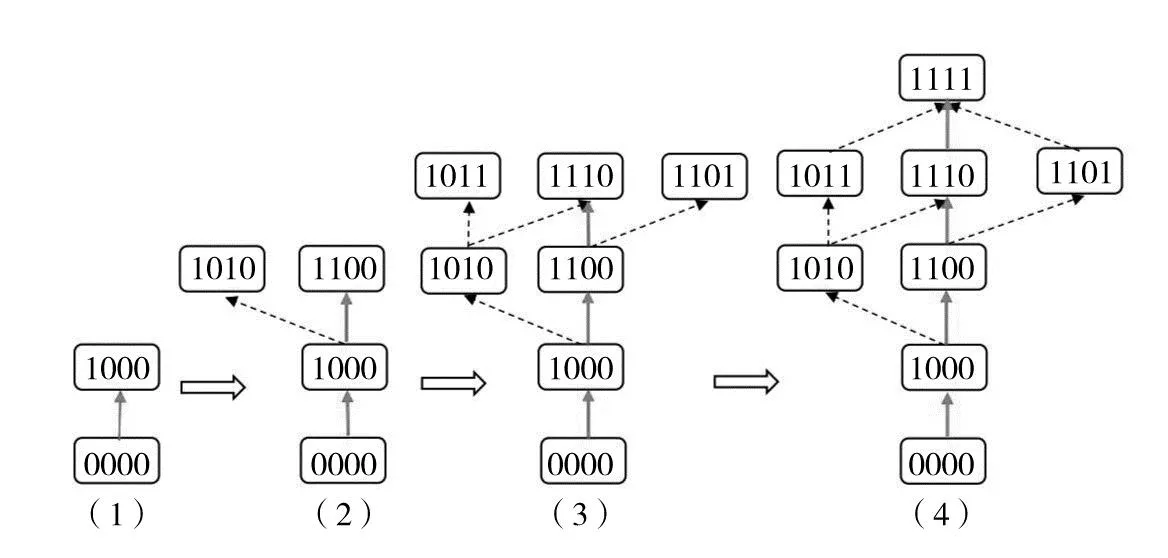
图4 绘制中国学生学习轨迹过程拆解图
步骤1 设初始认知状态为(0,0,0,0),第二层占比最大的认知状态为(1,0,0,0),而其他认知状态占比过小予以剔除,即存在主学习轨迹(0,0,0,0)→(1,0,0,0);
步骤2 第三层占比最大的认知状态为(1,1,0,0),且(1,0,0,0)⊂(1,1,0,0),次大的(1,0,1,0)保留,而其他认知状态占比过小予以剔除,即存在主学习轨迹(0,0,0,0)→(1,0,0,0)→(1,1,0,0);
步骤3 第四层占比最大的认知状态为(1,1,1,0),且(1,1,0,0)⊂(1,1,1,0),次之的(1,1,0,1)和(1,0,1,1)占比较大予以保留,而(0,1,1,1)占比过小予以剔除,即存在主学习轨迹(0,0,0,0)→(1,0,0,0)→(1,1,0,0)→(1,1,1,0);
步骤4 最后到达认知状态(1,1,1,1),即学生掌握了所有属性.
如图4所示,综合以上四个步骤(1)~(4)即可得到中国学生的主学习轨迹为(0,0,0,0)→(1,0,0,0)→(1,1,0,0)→(1,1,1,0)→(1,1,1,1).中国学生首先掌握的是第一个属性α1,其次是第二个属性α2,再次是第三个属性α3,最后掌握的是第四个属性α4.图中实线路径代表主学习轨迹,教师可以按主学习轨迹针对大部分学生进行教学设计;虚线路径为次学习轨迹,显然次学习轨迹不止一条,代表了小部分学生的学习轨迹,他们的认知规律和思维方式“与众不同”,需要教师进行单独的教学设计或者个别指导.
按照上述绘制学习轨迹的方法得到图5,展示了12个国家学生的学习轨迹图.图中实线路径是其中的主学习轨迹,包含了每一层中占比最大的认知状态,在一定程度上代表了某一群体的学习轨迹.从图5可以看出,存在三组学习轨迹一样的国家分别为沙特阿拉伯和巴西、澳大利亚和英国、俄罗斯和加拿大,其他六个国家的学习轨迹各不相同,三组学习轨迹相同国家的轨迹图形较为简洁.这12个国家都存在主学习轨迹和次学习轨迹,其中实线路径的学习轨迹为主学习轨迹,虚线路径的学习轨迹为次学习轨迹. 以日本学生的学习轨迹为例,学生首先掌握的是第一个属性α1,其次是第三个属性α3,再次是第四个属性α4,最后是第二个属性α2.分析发现这12个国家在第二层中认知状态(1,1,0,0)和(1,0,1,0)的比例非常接近,第三层中认知状态(1,1,1,0)、(1,1,0,1)、(1,0,1,0)的比例也非常接近.由图5可知,这12个国家不仅存在主学习轨迹,也都存在次学习轨迹.
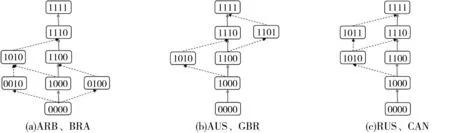

图5 12个国家学生的学习轨迹图
学习轨迹不仅与学生对认知属性的接受顺序直接相关,同时也会受到各类外部因素的影响,处于不同知识状态的学生可以根据自身特点和周围的学习资源选择不同的学习轨迹,这也体现了学习选择的多样性,图5中不同国家学生的学习轨迹不尽相同正是这一现象的反映.新加坡学生的学习轨迹相对于其他的11个国家更为复杂,这也说明新加坡学生的认知状态非常多样化,这可能与新加坡受到多元文化影响同时属于发达国家教育水平较高有关.南美洲哥伦比亚学生的学习轨迹最简单,除日本以外其他11个国家学生的主学习轨迹是相同的.数据分析结果显示,属性α1是其他属性的前提,α2是α3的前提,α3是α4的前提,这表明存在α1→α2→α3→α4线性主学习轨迹.这说明此学习轨迹为大部分学生的认知理解过程,可以认为是共同选择的易于接受的最佳学习轨迹,即主学习轨迹,按照这一主学习轨迹进行教学更适合大部分学生的学习,同时这一主学习轨迹也是很多国家教科书中所选择的编排顺序.其他学习轨迹为次学习轨迹,属于少部分学生的认知理解过程,需要教师有针对性地进行教学或者单独指导.
总之,学习轨迹显示了学生通过不同方式的学习使自身能力水平逐步提高的过程,反映了知识状态之间由简单到复杂的递进关系,描述了学生知识能力增长的发展过程,为学生提高学习能力展示了清晰的发展轨迹和方向.因此,学习轨迹不仅为学生提供个性化、精细化的诊断报告,也能为教师的教学设计提供依据.
3 结语
本文选取PISA 2015中12个国家的数据,采用加入反应时间的DNIA模型估计学生认知状态,推断出学生可能的学习轨迹.研究发现,12个国家学生的学习轨迹具有一定的共同特征,4个属性的最佳学习顺序是“变化和关系→量化→空间和形状→不确定性和数据”.研究还发现了一些特殊情况,比如日本学生的主学习轨迹与其他11个国家不同,后续可以进一步研究这类独特现象的深层次原因.虽然有11个国家学生的主学习轨迹相同,但不同国家的学生对不同属性的掌握程度却可能不同.从统计分析结果来看,解答不确定性和数据问题对学生较为困难,最佳学习轨迹表明,先学习其他三个属性后再学习“不确定性和数据”,更有利于学生掌握该属性.所有参与国家都存在表现不佳的学生,但比例不同.由于PISA数据本身属于抽样数据,在不同国家的考试项目并不完全相同,本文选取其中12个国家中作答同一组题目的学生进行研究,因此本文的研究结果仅依据抽样选取的数据,并不能完全代表某一国家学生的真实学业水平情况.
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
科学与财富(2021年33期)2021-05-10
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
汽车零部件(2018年5期)2018-06-13
现代装饰(2018年5期)2018-05-26
中国三峡(2017年2期)2017-06-09
