
面向非平稳时间序列的因果关系发现算法
2024-03-08 03:51周嘉颖周跃进
长春师范大学学报 2024年2期
周嘉颖,周跃进
(安徽理工大学数学与大数据学院,安徽 淮南 232001)
0 引言
时间序列数据是指在相同间隔的时间段内,观察某个研究对象的数据变化过程及将这些数据按照时间先后顺序排列所形成的序列数据。在日常生活中,时间序列数据广泛存在于农业、医学、工业等多个领域[1-3]。随着大数据时代的不断发展,产生了海量、非平稳、非线性的时间序列数据,这为挖掘其有效信息增加了难度。因此,挖掘复杂时间序列数据的潜在信息,揭示未来发展规律,成为当前一个重要研究方向。
分析事物或现象之间的因果关系是现实中的常见问题,例如分析大脑不同区域间因果关系以构建大脑网络[4]和分析商品价格与房产价格之间的双向因果关系[5]等。由于时间序列的时序性,通过了解时序变量之间的因果关系,预测事物或现象的发展情况,因此因果关系分析方法得到广大学者关注。GRANGER[6]首次提出了Granger因果关系分析法,是一种判别二元时间序列之间是否存在因果关系的方法,其关键假设是:(1)因果关系产生的过程可以用一组结构方程来表示;(2)任何时间点产生的因果效应均受到过去时间点的影响。由于传统的Granger因果关系分析法只能用于判别二元线性时间序列,因此出现了大量改进模型。GEWEKE[7]提出了条件Granger因果模型,用于判别多元时间序列之间的因果关系。Granger因果关系通常是在线性系统的背景下研究的,随着研究的深入,学者们开始探索在非线性系统中的因果关系。ANCONA等[8]在Granger因果关系和径向基函数的基础上提出了可用于判别非线性时间序列的RBF-Granger因果模型。
传统的Granger因果关系分析法及其推广分析法只能给出定性分析结果,分析高维时间序列时容易产生虚假的因果关系。基于此,SCHREIBER[9]首次提出了转移熵的概念,一种基于信息理论的因果关系分析法,可以捕获时间序列的非线性特征和定量分析因果关系的强弱。在Granger因果关系分析法和转移熵因果关系分析法中,均假设时间序列的因果关系都受到原因的影响且时滞是固定的,受固定滞后时间序列影响仍然存在于Granger因果关系和转移熵结果中。因果关系之间的时滞是固定的假设对于现实生活中自然和社会现象来说是过于绝对的,时间序列的时滞并不是固定的,不同情况下时滞会随时间变化,一组时间序列可以由多组原因序列影响。因此,AMORNBUNCHORNVEJ[10]提出了一种时滞可变的转移熵(Variable-Lag Transfer Entropy,VL-TE),可以分析具有任意时滞时间序列之间的因果关系,转移熵值越大,其因果关系越强。
传统的Granger因果关系分析法及其推广分析法、转移熵法及VL-TE法只能分析平稳时间序列间的因果关系,而不能直接分析非平稳时间序列之间的关系。为了解决此问题,本文提出一种基于分段聚合近似可变时滞转移熵(Piecewise Aggregate Approximated Variable-Lag Transfer Entropy, PAAVL-TE)因果关系发现算法。该算法利用分段聚合近似法对时间序列进行转换,提取时间序列的特征信息,使用动态时间弯曲距离寻找相似程度最高的时间序列进行转移熵的计算,能够实现在具有可变时滞的非平稳时间序列中的因果关系判定。最后在模拟数据集及真实数据集进行了实验,并与Granger因果关系分析法、转移熵法及VL-TE法对比,通过实验验证本文方法的有效性和应用性。
1 相关理论
1.1 信息理论基础
SHANNON[11]提出了香农熵的概念来表示系统的混乱程度和随机变量所含信息量的多少及其不确定性的程度。系统混乱程度越高,熵值越大,随机变量的不确定性就越大。香农熵H(X)定义为:
(1)
为了衡量多个变量含有的共同信息量,提出了联合熵H(X,Y)的概念,其定义为:
(2)
同时,为了衡量在一个条件下随机变量的复杂程度,提出了条件熵H(Y|X)的概念,其定义为:
(3)
为了衡量两个随机变量的相关程度,提出了互信息(Mutual Information,MI)的概念,反映变量之间信息交互情况的度量。互信息值越大,变量之间的相关性也越高。互信息MI定义为:
(4)
基于信息理论中香农熵、联合熵、条件熵及互信息的概念,有学者提出了多种基于互信息理论的因果分析法,其中包括转移熵(Transfer Entropy,TE)。
1.2 转移熵与VL-TE
由于互信息无法得到信息的传递方向,Schreiber基于互信息理论提出了转移熵的概念。转移熵是一种基于两个随机过程的过去值及当前值来测量两个过程的信息传递方向及信息传递量的因果关系分析方法。给定时间序列{Xt}和{Yt},从{Xt}到{Yt}的转移熵定义为:
(5)

基于香农熵作信息量含量不确定性的度量时,香农转移熵的定义为:
(6)

然而,这不符合实际中时间序列的时滞阶数是可变的现实。AMORNBUNCHORNVEJ[10]提出了一种时滞阶数可变的转移熵(VL-TE),可以判定具有可变时滞时间序列之间的因果关系,VL-TE的定义为:
(7)
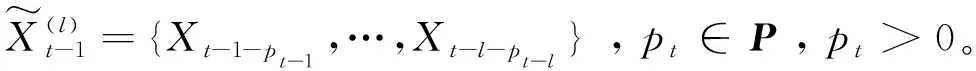
为了判定存在可变时滞时X是否是导致Y变化的原因,定义了可变时滞转移熵比值:
(8)
当T(X,Y)VLr大于1时,表示在可变时滞转移熵中X是导致Y变化的原因。比值越大,X导致Y变化的原因程度也越大。
由于实际中的时间序列不都是平稳的,而VL-TE只可发现平稳时间序列的因果关系。因此,本文的工作是探究非平稳的时滞阶数可变时间序列的因果关系。
2 基于分段聚合近似可变时滞转移熵的因果关系发现算法
2.1 时间序列预处理
对于缺失的数据,采用多重插补法进行填补,再对处理过后的时间序列进行Z-Score标准化,即将数据转换成均值为0、标准差为1的数据:
(9)
其中,X′和X分别表示标准化后的数据和原始数据,μ和σ分别表示原始数据的均值和标准差。
对预处理过后的时间序列,采用分段聚合近似表示法(Piecewise Aggregate Approximation,PAA)进行处理。
2.2 分段聚合近似表示法

(10)
分段聚合近似表示法把长度为70的时间序列平均分成10段,如图1所示。

图1 基于分段聚合近似的时间序列降维示意图

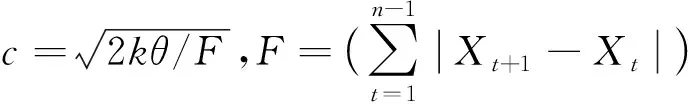
(11)
其中,c为最大压缩比,θ为允许误差,F为时间序列的变化频率,k为常数,n为时间序列的数据总数。
2.3 动态时间弯曲距离
动态时间弯曲距离用于度量两个时间序列之间的距离,是一种度量待分类的两个时间序列间相似性的方法。通过对时间序列上不同时间点对应的元素进行动态弯曲调整,获取一条最优路径,以检测不同时间序列的相似程度,从而最大限度地减少了时间移位和失真的影响。
给定两个时间序列{Xt1,t1=1,2,…,m},{Yt2,t2=1,2,…,n}进行距离度量,构造一个矩阵D={d(i,j)}m×n,其中距离度量d(i,j)=(Xi-Yj)2。动态时间弯曲则是需要在矩阵D中所有弯曲路径P={p1,p2,…,pK}找到一条连续的最优路径P*,其中第k个元素为pk=(i,j)k且(max{m,n}≤K (12) (13) 图2 动态时间弯曲路径 动态时间弯曲距离的代码如下所示: 输入:时间序列{Xt1,t1=1,2,…,m}, {Yt2,t2=1,2,…,n} 建立元素距离矩阵D={d(i,j)}m×n,其中d(i,j)=(Xi-Yj)2 fort1=2∶m end for fort2=2∶n end for fort1=2∶m,t2=2∶n end for 设定pK(i,j)=(m,n) whilepK(i,j)≠(1,1) end 记P的长度为K,长度为K的最优动态弯曲路径P*=P(K-l+1),l∈{1,2,…,K} 输入:时间序列{Xt}和{Yt} 由动态时间弯曲距离算法得到动态弯曲路径P={p1,p2,…,pl,…,pK} 设定互相关时间序列{Xt}和{Yt}的结果为P0={p0,…,p0,…} for alll ifS(Xt-pl,Yt) else if end if end for 本文提出的基于分段聚合近似可变时滞转移熵因果关系发现算法(PAAVL-TE)的基本思想是:首先对各个时间序列进行分段聚合近似(PAA)计算,得到特征时间序列。然后对这些特征时间序列进行动态时间弯曲距离计算,找到相似程度最高的新的时间序列,最后计算转移熵值分析因果关系。 基于分段聚合近似可变时滞转移熵因果关系发现算法如下: 输入:时间序列{Xt1,t1=1,2,…,m}, {Yt2,t2=1,2,…,n},可能的最大滞后阶数δmax,分段数目nX和nY 输出:转移熵因果分析结果,TX→Y,TY→X 数据预处理:得到新时间序列{X′t1,t1=1,2,…,m}, {Y′t2,t2=1,2,…,n} 计算压缩比cX′=m/nX,cY′=n/nY fort1=1∶nX fort2=1∶nY 分别计算转移熵值TX→Y,TY→X, ifT(X,Y)r>1 存在X→Y的因果关系 else if 不存在X→Y的因果关系 end if 为了验证本文提出的PAAVL-TE算法的有效性,使用具有可变时滞的模拟数据集对算法进行实验评估,并与G、TE、VL-TE算法进行对比。 在模拟数据集中生成了固定时滞无法判别因果关系而可变时滞可以判别的时间序列,每次生成每组长度为500的时间序列,正常模型的时间序列值来自标准正态分布N(0,1),自回归模型(Autoregressive Model,AR)的时间序列值来自: Xt=0.5Xt-1+1.2Xt-2+εt,εt~N(0,1). 模拟生成5类时间序列数据集,具体来说:(1)15组存在明显因果关系的时间序列{Xt}和{Yt}的数据集,其中{Yt}具有时滞阶数p=5,Yt=Xt-p+0.1εt,εt~N(0,1)。为确保时滞的可变性,{Yt}在第200至250时间步长直接保持不变,模仿第180时间步长的{Xt},使{Yt}受到X的可变滞后的影响;(2)15组{Xt}和{Yt}独立生成的不存在因果关系的时间序列,确保PAAVL-TE不会判别出错误的因果关系;(3)15组时间序列{Xt}和{Yt}存在因果关系的AR模型数据集;(4)15组时间序列{Xt}和{Yt}不存在因果关系的AR模型;(5)15组时间序列{Xt}来自正常模型数据集,{Yt}来自AR模型。 生成的模拟数据集的真实因果关系如图3所示。图3中的箭头所指方向表示从原因时间序列(如{X1})到结果时间序列(如{Y1})的因果方向,{Yij}表示存在滞后的时间序列。{X1,X2,X3}由正常模型及AR模型生成,每次模拟生成15组时间序列,设置最大时滞阶数δmax=12。此外,本文将F检验显著性水平α设为0.05。当T(X,Y)r>1时,才判定存在因果关系。 图3 模拟数据集的真实因果关系图 图4 不同方法的ROC曲线 对于算法评价,本文采用ROC曲线下的面积AUC(Area Under Curve)指标进行评价。ROC曲线是以假阳率(FPR)为横坐标,真阳率(TPR)为纵坐标,由各阈值下的点坐标构成的曲线,其中假阳率和真阳率的计算公式如下: 其中,将预测因果关系的结果与实际因果关系的结果作对比,真阳性TP是实际有因果关系且预测也有因果关系的数量;真阴性TN是实际无因果关系且预测也无因果关系的数量;假阳性FP是实际无因果关系但预测有因果关系的数量;假阴性FN是实际有因果关系但预测无因果关系的数量,(FPR,TPR)为各阈值下的点坐标。AUC指数越高,算法预测效果越好,与实际因果关系越接近。 为了评估PAAVL-TE从非平稳时间序列中推断出正确的因果图边,同时采用精确率(Precision)、召回率(Recall)和F1得分评价本文方法及其他对比方法的效果。 其中,P表示精确率,R表示召回率,F1表示F1得分,Tp表示事实与预测结果都有Xi→Yj因果图边的数量,Fp表示因果图事实无边但预测有边的数量,FN表示事实有Xi→Yj因果图边但预测无边的数量。 图4给出了G、TE、VL-TE、PAAVL-TE四种方法的ROC曲线图。从图4可以看出,本文方法预测效果最好。相比已有方法,本文具有更好的性能。 表1给出了模拟数据集中G、TE、VL-TE、PAAVL-TE四种方法的实验结果。从表1可以看出,PAAVL-TE在精确率及F1得分上明显优于其他方法,这表明PAAVL-TE方法可以有效处理复杂时间序列的因果推理任务,分析出正确时滞可变时的因果关系,排除其他方法不能排除的无关因素,提高精确率。 表1 模拟数据集中不同方法的实验结果 图5给出了在改变最大时滞阶数δmax时四种方法推断因果方向的平均准确度。从图5可以看出,无论最大时滞阶数δmax为何种情况,在δmax变化的范围内PAAVL-TE方法的平均准确度均高于其他方法,这表明在非平稳时间序列中提出的PAAVL-TE方法具有更好的表现。总体来说,PAAVL-TE算法在具有可变时滞的时间序列的因果关系发现问题上具有较好的实验效果。 图5 改变最大时滞阶数δmax时不同方法推断因果方向的平均准确度 以2013年3月1日至2017年2月28日北京市昌平区的PM2.5浓度、污染物浓度及气象时间序列为研究对象分析因果关系,数据来源于UCI数据库的Beijing Multi-Site Air-Quality数据,一共有11维数据(PM2.5浓度、SO2浓度、NO2浓度、CO浓度、O3浓度、温度、压强、露点、降雨量、风速、风向),其中包含5维空气污染物浓度数据和6维气象数据。利用PAAVL-TE方法找出影响PM2.5浓度变化的主要因素,同时与其他方法进行对比。 首先,对数据进行缺失填补及Z-Score标准化,再进行PAA处理。然后,以PM2.5浓度为分析目标,利用PAAVL-TE寻找影响PM2.5浓度变化的因素,计算各因变量对应的可变时滞转移熵比值,剔除无关和冗余变量。比值大于1则认为有因果关系,且比值越大,因果关系程度越强。最后,使用保留有因果关系的相关变量,进行预测建模。 四种因果分析方法显示的影响PM2.5浓度的因素如表2所示。根据本文方法得到,对PM2.5浓度变化有因果关系的变量有SO2浓度、NO2浓度、CO浓度、温度、降雨量、风速及风向。随着北京市发展及汽车的普及程度增高,汽车尾气排放、煤炭燃烧及工业排放等会造成大气污染,汽车尾气排放的污染物主要有SO2、NO2、CO等。由于在大气中SO2、NO2、CO存在二次转化过程,如NO2经过一系列复杂物理化学反应可转化为硝酸盐二次颗粒,使得PM2.5浓度上升。因此,PM2.5浓度变化会受到SO2、NO2、CO污染物浓度的影响。此外,北京市位于华北平原的西北缘,且地形呈簸箕状。当风向为西北风时,容易生成更大风速的风,使得污染物更易扩散,空气中PM2.5浓度也随之下降。反之,东南风则会把污染物吹向簸箕地形,不利于污染物的扩散,从而PM2.5浓度升高。降雨量及温度也影响污染物浓度,如当近地面大气温度较高时,大气的对流作用加剧,使得PM2.5浓度降低,所以PM2.5浓度也受温度及降雨量的影响。因此,运用PAAVL-TE法的因果关系分析所得到的结果,与北京市PM2.5浓度变化的影响关系一致,验证了本文方法的有效性。 表2 PM2.5在不同方法下的预测结果 得出影响PM2.5浓度变化的因素后,本文建立长短时记忆网络(Long Short Term Memory,LSTM)预测模型,通过这些因素进行建模预测并验证分析的结果,针对每一种方法的预测结果,取不同参数下10折交叉验证所得到的最好结果。采用平均绝对误差(MAE)、对称平均绝对百分比误差(SMAPE)和均方根误差(RMSE)三个指标来衡量预测的精度,定义如下: 表2给出了PM2.5在G、TE、VL-TE、PAAVL-TE四种方法下的预测结果。由表2可见,本文方法在三种误差的预测评价指标均小于其他方法,表明其预测精度最高。同时用于预测的变量数目为7,小于数据集的原始变量数目,减小了预测过程中的计算难度及成本。相比之下,本文方法能够有效应用于具有可变时滞的非平稳时间序列因果关系分析,为模型预测选择合适的输入变量,提高预测精度。这表明本文方法表现良好,具有现实应用价值。 针对具有可变时滞的非平稳时间序列因果关系分析问题,本文提出了PAAVL-TE方法,利用分段近似聚合和动态时间弯曲距离的方法找到与原序列相似程度最高的时间序列,并计算可变时滞转移熵,克服了传统的Granger因果关系分析法及其推广分析法、转移熵法及VL-TE法难以运用于非平稳时间序列因果关系分析的不足。同时,有效分析出正确的因果关系和因果关系程度的高低,减少了计算时间,说明该算法具有良好的应用性。在未来的工作中将研究基于状态空间的因果分析方法,在相空间重构时尝试利用神经网络以确定Granger因果模型的延迟阶数和嵌入维数,降低模型的复杂度。



3 仿真模拟



4 应用实例


5 结语
猜你喜欢
防爆电机(2022年4期)2022-08-17南大法学(2021年6期)2021-04-19数学物理学报(2020年5期)2020-11-26高中生·天天向上(2018年7期)2018-07-23中国交通信息化(2017年9期)2017-06-06湘江法律评论(2016年0期)2016-06-15项目管理技术(2016年8期)2016-05-17中国交通信息化(2015年3期)2015-06-05四川师范大学学报(自然科学版)(2015年2期)2015-02-28中国检察官(2015年12期)2015-02-27
