
多模交互智能终端
2024-03-08 03:31阚保强余容森
长春师范大学学报 2024年2期
阚保强,余容森
(福建师范大学协和学院,福建 福州 350003)
0 引言
随着人工智能的发展,人机交互不再局限于单一的感知通道的输入输出模态,多模态人机交互旨在利用语音、图像、文本等多模态信息进行人与计算机之间的信息交换[1]。单一的人机交互包括基于接触的交互如智能手机、平板等,基于手势的交互,基于声音感知的交互等。但这些都不能给用户带来全方位的交互体验,这时就需要多模态的人机交互,而头盔就是一种很好的多模态人机交互载体。现今的头盔大致可划分为军用、工作、运动三大类,这三大类头盔在舒适性及安全性上已经有了一定的保证,但在适用范围上还存在极大的局限性,由于一些工作的特殊性,致使单一功能的头盔不能满足情况较为复杂场景[2]。因此,需要一种集成多个模块、有多种功能、可以应用于多个场景的智能头盔。多场景智能头盔监测系统的本质需求是适应多场景,头盔能够适应的场景数量是不断变化的,而且头盔的功能也并非一成不变[3]。现有的智能头盔,例如,Helmetphone MT1 Neo智能头盔,具备拍照、播放音乐、灯光调节、语音导航等功能,不过这些功能需要通过手柄控制,是为用户骑行而打造的;Daqri Smart Helmet智能头盔,可以完成数据监测、热度检测、人员培训、人员远程指导等,但它更注重于AR方向的交互,且价格较贵[4]。本文设计的多模交互智能终端,具有更高的灵活性和可扩展性,不仅拥有人机交互、开放接口以及多个模块互相交互,还可以根据用户的行为搜集所需信息,使用户能够感知到环境信息,从而实现智能化操作。
本文设计智能头盔系统的目的是为满足实时语音和视觉交流,通过本系统可以实现用户与产品间的无障碍交流,使用户可以更加便捷地实现自己的需求。比如,在生活方面,基于爬虫技术和语音合成技术实现智能信息查询,如用户通过语音可以直接查询天气、音乐、新闻等信息,方便日常生活;在出行方面,伴随城市的不断建设发展,往往有很多地方都会让人感到陌生,路径规划可以很好地解决这个问题,帮助用户穿梭在城市的每一个角落;同时,在人机交互方面,语聊模块可以轻松实现与用户的日常对话[5]。本系统开发的就是将树莓派平台、GPS模块、摄像头、网络通信技术与头盔相结合的智能终端,配备了相应的后台系统,整体集成度较高,能耗小,便于携带,可以适应于多种生活场景。并且系统各部分可以相互协作,将采集到的信息进行传递,使后台可以获取相关数据。同时,这款多模交互智能终端操作比较简单,功能相对齐全,无论夜间还是白天都可以帮助佩戴者安全地沿着道路前行或转弯。它可以让用户与设备交互,不用通过复杂的操作,使用户有更好的体验,让用户更快地完成任务,提高工作效率。此外,多模交互智能终端还可以实现智能控制,使用户能够实时追踪自己的位置,实现实时交互。
1 系统总体设计
系统整体包括服务器端和用户端,其中服务器端提供后端数据处理、目标识别任务,用户端采用树莓派、摄像头、L76X GPS定位模块、语音采集板等,它们之间使用无线方式传输数据。系统总体设计框图如图1所示,系统功能描述如图2所示。

图1 系统总体设计框图
系统功能模块包括管理模块、系统主体功能模块和系统表。
(1)管理模块。管理员通过管理员账号登录管理员系统,在系统中管理员通过查看聊天信息来判断聊天机器人是否正常工作,回答是否准确,也可以通过聊天输入框对聊天机器人进行测试,并且收集用户在聊天中出现的问题,用于聊天机器人的训练,在不断重复这个过程中,聊天机器人也变得更加智能,为用户带来更好的体验。管理员可以查看障碍物识别的情况,通过查看识别物体的准确率来调整训练模型,还可以对用户信息和终端信息进行增、删、查、改。
(2)系统主体功能模块。主要与用户交互的模块,该模块应用Raspberry Pi 平台、网络通信、语义理解、位置服务等技术,结合了大量的数据和处理方法,主要功能有:天气查询——在得到用户指令后,根据所得城市信息向心知天气API请求获取未来三天的天气情况和出行建议,返回数据后经系统解析并以语音形式反馈给用户;障碍物识别——将摄像头所采集的视频信息发送至服务器,经过Yolov5模型预测障碍物所属类别,并将识别结果返回到客户端,以语音形式提醒用户小心前方障碍物和前方障碍物所属类别;每日新闻——负责将从天行数据的新闻API中获取的新闻数据解析后进行语音播报;语聊对话——用户在与终端对话时,如果未触发系统其他功能关键字就会进入语聊对话,这个部分负责获取用户向终端提出的问题,通过Seq2Seq模型的理解给用户最佳回复;出行规划——将多模交互智能终端所在位置作为起始点,按照用户给出的目的地,规划出一条最短、最优的路径,用详细的语音播报这段路程所经过的一些地点、方向和距离;地图查看——主要实现当前地图的实时查看获取。
(3)系统表。主要实现用户管理和终端管理。
2 系统硬件设计
根据总体设计框图,硬件部分位于头盔终端,包括树莓派、语音处理板、定位模块、供电单元等,硬件实物如图3所示。语音的采集与处理是基于WM8960芯片的。定位模块采用L76X GPS定位模块,这个定位模块可以接收GPS、BD2和QZSS的信号,具有体积小、功耗低、定位快等优点。

图3 智能交互终端硬件
3 系统软件设计
用户在使用本系统时需要先通过唤醒词唤醒系统,然后系统判断用户输入的语句是否有关键词,如果触发关键词将进入对应的功能模块,比如检测到语句中有“新闻”一词就会将今天的新闻播报出来,如果没有触发关键词将进入语聊对话,在这个功能里用户可以与终端聊一些日常生活的话题。主体流程如图4所示。
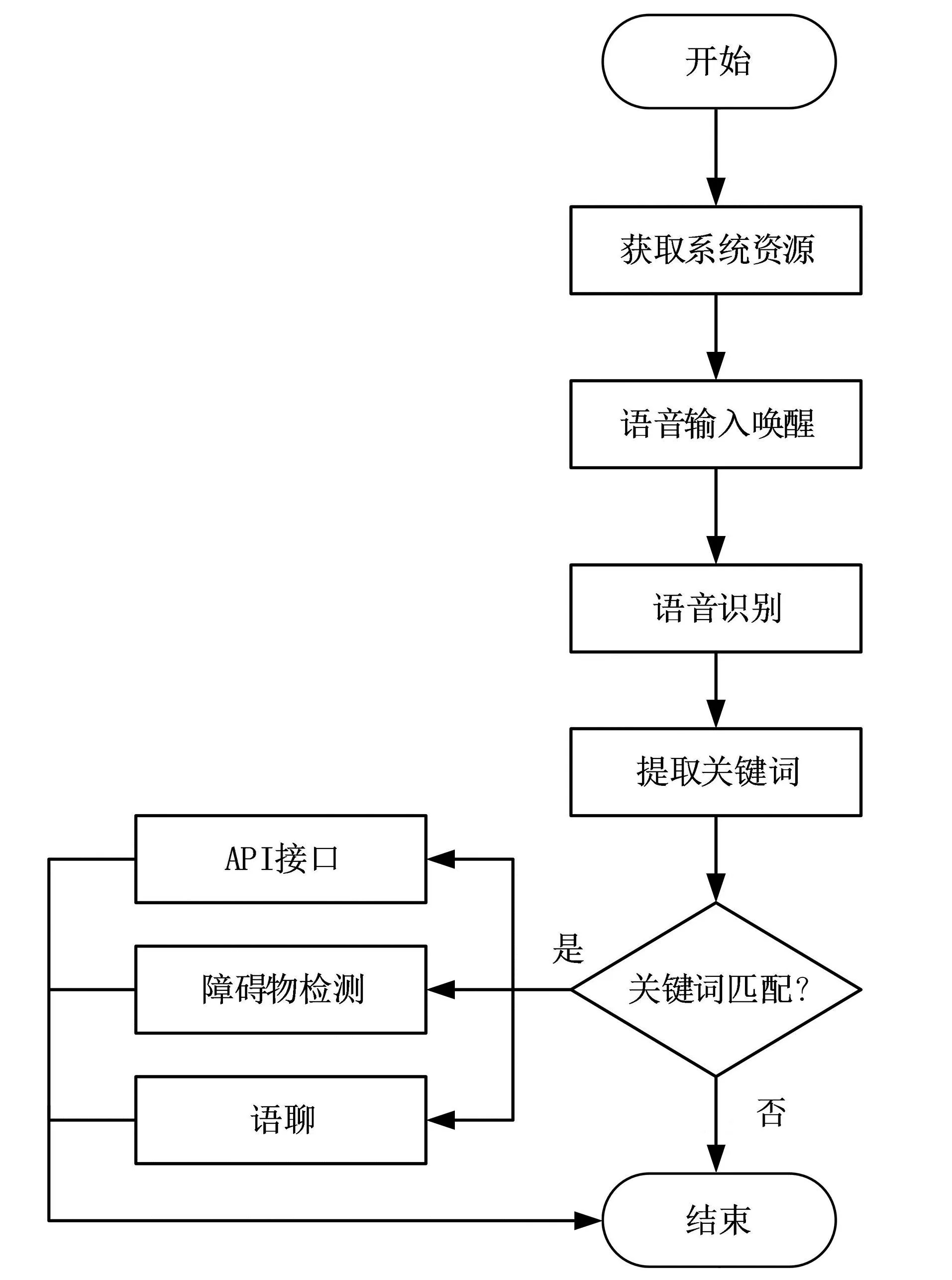
图4 系统流程图
4 多模交互的实现
4.1 障碍物识别功能
障碍物的目标检测,主要通过读取树莓派传输的视频流,实时获取周围障碍物体的信息,识别出常见的交通标志、人车及生活用品。利用图像处理、深度学习等技术,从图像或视频中定位感兴趣的对象,通过目标分类判断输入图像中是否包含目标,用目标定位找出目标物体位置并框出目标,其任务是锁定图像中的目标,定位目标位置,确定目标类别[6-8]。本系统是基于Yolov5框架训练的障碍物的目标检测,整个系统实现流程如图5所示,识别检测均基于树莓派4B实现。

图5 障碍物检测实现过程图
在图片数据集上收集常见的障碍物图片,见图6(a),本系统使用LabelMe对数据集进行标注,见图6(b),完成后再训练Yolov5s模型。训练结果如图7所示。

图6 数据集和标注数据集展示图

图7 模型训练结果图
4.2 语音交互实现
这个部分是本系统核心之一,由于系统采用模块的设计手段,所以指令控制和技能选择都是基于语音识别开发的,对话功能的实现框图如图8所示,支持语音输入和文本输入。语音识别算法模型和对话聊天算法模型已经通过 TensorFlow 库实现并做好了封装,接下来只需使用核心框架下调用模型的接口,使后台服务端模型的接口处理好聊天信息,再传送至客服端前端进行展示,下一步传递给语音合成,即输出完成一轮对话。对于聊天机器人模型的实现,首先对原始数据进行初始化,这里本系统由于选择了开源的语聊库,需要对原始数据进行清洗,主要包括对大小写字符、标点符号、数字、空白字符以及自然语言处理停用词的处理;根据处理后的数据,通过生成词汇表、转化词编码的方式,将文字与数值之间建立一个映射字典,并对输入数据进行编码。接着基于Seq2Seq模型进行训练和评估。为了将模型回复的文本结果转化为语音,采用模块化语音合成,接入不同的语音合成API。
Seq2Seq是一种编码器-解码器结构的模型,该模型需要使用两个RNN(循环神经网络),一个用于编码,另一个用于解码。Seq2Seq是一种能将很多元素相关联形成记忆的模型,就像人的记忆一样,其输出是根据输入和已有数据推断出来的。St表示t时刻的记忆,公式如下[9]:
St=f(U×Xt+W×St-1),
(1)
其中,Xt表示t时刻的输入,U和W为模型的线性关系参数。
St是一个激活函数,可以用来过滤掉一些不重要的信息,留下的信息即为模型的记忆。那么得到这些记忆后就要进行预测,用softmax函数可以预测每个词出现的概率,但需要在预测时带入一个权重矩阵V,就可以得到t时刻的输出Ot,公式如下:
Ot=s(VSt),
(2)
其中,s表示softmax函数。
利用RNN的这种特性,Seq2Seq就能完成对语义理解。为了得到更好的输出效果,本系统在训练模型的过程中增加了Attention机制(将编码器编码的向量再根据解码器需要进行动态变化的机制),简单来说,就是将注意力集中到重要的信息上,可以有效集中资源以提高效率。该模型的提出,使得神经机器翻译的性能在各个方面的指标都打败了统计机器翻译。Seq2Seq模型简图如图9所示,经过GLU(Gated Linear Units)模块送入编解码器。Seq2Seq模型训练图如图10所示。

图9 Seq2Seq模型简图

图10 Seq2Seq模型训练结果图
5 实验结果
系统管理主界面如图11所示,提供远程测试和管理功能接口。

图11 系统管理主界面
语聊对话界面见图12,主要用于查看用户聊天信息,可语音聊天,可通过下方的输入框输入文字进行聊天,也可以直接通过语音唤醒终端进行语音输入,语聊内容将以语音播报,同时在页面查看实时语聊信息。

图12 语聊对话界面
障碍物识别界面如图13所示,通过语音在终端进行播放,同时在远程可以实时监控。

图13 障碍物识别界面
位置交互模式是通过L76X GPS定位模块和高德地图API来实现,用户说出“位置”关键词就可以得到现在所在位置,说出“路线”关键词和要去的地方就可以得到最短步行路径。终端向服务器发送位置坐标(图14),同时智能终端会通过语音合成后播报行进路线,步行最短路径如图15所示,Web端定位显示图如图16所示。

图14 终端向服务器发送位置坐标
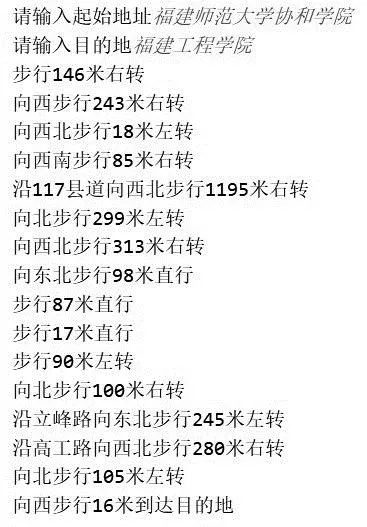
图15 步行最短路径示意图
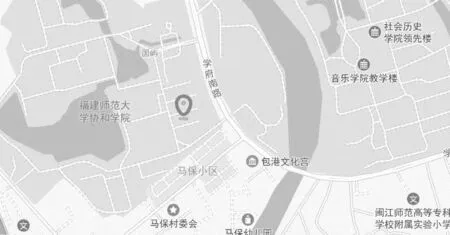
图16 Web端定位显示图
6 结语
目前,人们对智能产品的需求越来越大,本系统设计的出发点就是为了方便用户的日常生活,将无线通信、障碍物检测、语音处理与树莓派平台相结合,形成了一个多模块的智能终端,通过对用户需求的分析,确定系统结构和功能模块,完成硬件和软件的搭建。不同环境的实际测试结果显示,本系统的设计与实现有助于智能出行。
猜你喜欢
小学科学(学生版)(2021年10期)2021-12-28
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
红领巾·探索(2018年11期)2018-12-10
小哥白尼(军事科学)(2018年9期)2018-12-08
意林(2017年9期)2017-06-06
少年文艺·开心阅读作文(2017年4期)2017-04-07
小学生导刊(低年级)(2016年8期)2016-09-24
城市道桥与防洪(2014年5期)2014-02-27
青少年科技博览(中学版)(2006年4期)2006-04-14
