
基于Gamma混合模型的出租车落客行为
2024-03-12 12:48杨方宜杨荣根李伟兵何向东
浙江大学学报(工学版) 2024年3期
杨方宜,杨荣根,李伟兵,何向东
(1.金陵科技学院 智能科学与控制工程学院,江苏 南京 211169;2.南京理工大学 机械工程学院,江苏 南京 210094;3.浙江好易点智能科技有限公司,浙江 金华 321042)
在大型综合客运枢纽(如机场、高铁站),乘客通过公共汽车、出租车、私家车等交通工具到达指定的落客区,在落客区下车后进入候车大厅(站房).该区域出租车道经常采用单车道“先进先出”(first-in-first-out,FIFO)的运行模式,这种模式在中国大型高铁站较常见,例如南京南站、郑州东站、北京南站和广州南站等[1].在“先进先出”落客车道的出租车表现出其独特的运行特点:车队中的车辆都有落客需求,当车队的头车停车落客时,车队中所有车辆均必须停下来,但其中只有一部分车辆在停车等待一段时间后开始落客,而另一部分车辆则会选择继续等待,并在下次车队移动中寻找合适的落客位置.如果每辆车都在期望停车位落客,则“先进先出”落客车道的车位有效利用率将会非常有限,这势必会造成枢纽落客区域的严重拥堵.
当前,对于大型综合客运枢纽落客区域的研究主要集中在多车道(即最内侧车道落客,其他车道通行),尽管多车道落客区域的相关研究非常丰富[2-4],但这些研究中使用的方法和模型不能直接应用于“先进先出”落客车道.该领域的一些早期研究依赖于经验方法和确定性模型[5-8],忽略了现实复杂性,如随机需求、落客位置的选择和停留时间.另一方面,通过仿真模型研究出租车落客行为可以包含更多真实的落客行为细节,例如车辆落客位置选择行为,但这些行为细节更多的是遵循统计分布,缺少对关键变量的机理分析[9-11].为了理解送站坪出租车落客行为,须对个体选择行为进行分析建模.在城市交通个体选择行为的研究中,离散选择Logit模型发挥着重要的作用,它是多重变量变量分析的方法之一.目前为止最简单且使用最广的离散选择模型即为Logit模型[12].最初Logit公式是Luce[13]根据不相关选项的独立性(independence from irrelevant alternatives,IIA)推导得出的.随着Logit模型的发展,在基础Logit模型的基础上提出了更多的离散选择高阶段Logit模型,例如:混合Logit模型、混合选择模型(hybrid choice model)、动态Logit模型(dynamic Logit model).其中一些模型已经广泛应用到交通行为分析中,大部分研究都是利用偏好数据来估计离散选择模型的,通过确定人的决策偏好来改善现有政策[14-15];一些学者为了提高选择模型的预测精度和解释力,将统计学习理论框架引入到模型中[16-17],但更多的做法是搭建混合模型框架,例如离散-连续选择框架[18-19]、动态离散选择框架[20-22]和分阶段选择框架[23-24]等.
随着可获得面板数据集的数量不断增加,以及相关统计和计量模型的快速发展,用于估计二元面板数据非线性模型已经成为研究的重点.为了研究可能提高车道空间利用率的策略,需要一个更好的模型来解释潜在的车辆等待耐性和落客期望.本研究对“先进先出”落客区域的车辆落客行为进行分析,在此基础上构建等待耐性混合分布模型和二元离散选择模型,并对模型进行估计和验证.
1 出租车落客行为概述
对于出租车落客车道,跟随车辆存在3个状态:移动、等待和落客.当跟随车辆因下游车辆落客而被迫停车,它的状态从“移动”转换为“等待”,期望能够再次向前移动并到达其理想停车位.如果车辆的停车时长超过等待耐性,它将会进行落客;如果车辆的停车时长未超过等待耐性,并能够继续向下游移动,车辆将会继续向期望停车位前进,或者再次受迫停车[1].上述出租车决策过程如图1所示,该落客决策模型只保留了一些主要因素.为了更好地理解出租车落客行为,对出租车道车辆停车行为分别从停车位置、停车时间和等待耐性3个方面进行详细分析,分析数据主要来自于文献[1]中的轨迹数据.

图1 FIFO落客车道跟随车辆状态变化图Fig.1 Following vehicle status diagram in FIFO drop-off lane
2 出租车停车时间分析
对于有落客需求的车辆,按照车辆类型(是否为头车)将其停车时间分为2类,一类是头车停车时间,另一类是跟随车辆停车时间.头车停车时间均为主动停车时间,主要包括:车门打开之前的主动停车时间(乘客与司机交接时间,例如解除安全带、携带随身物品或开发票时间)、落客时间(车门打开到车门关闭的时间,乘客提取行李)、车门关闭之后的准备时间(司机出发前的准备时间,用于确认乘客是否遗落物品并调整状态准备出发).跟随车辆停车时间可以分为受迫停车落客的车辆停车时间以及受迫停车一直未落客的车辆停车时间,前者主要包括:车门打开之前的被迫停车时间、落客时间、车门关闭之后的准备时间以及准备结束后的被迫停车时间;后者则全部是受迫停车时间.所有停车时间数据均从轨迹数据中获取,轨迹数据包含“时间-位置数据”、“停车数据”和“时间数据”3部分.“时间-位置数据”用于记录车辆在每一时刻的位置;“停车数据”主要包含车辆编号、停车开始时刻、停车结束时刻,如果车辆多次停车,则每条数据包含多组停车开始时刻和停车结束时刻;“时间数据”包含车辆编号、车辆进入时间、落客开始时间(车门打开时间)、落客结束时间(车门关闭时间)、车辆退出时间等数据.上述所有数据均被用来分析出租车停车时间,头车及跟随车辆的停车时间按照停车时间组成可划分为主动停车时间、受迫停车时间和落客时间,具体如图2 所示.图中,t为时间,L为位置,t1和t2分别为2辆跟随车辆的进入时间,to为头车开门时间,tc为头车关门时间.

图2 FIFO落客车道头车和跟随车辆停车时间划分Fig.2 Stop time division of lead vehicle and following vehicle in FIFO drop-off lane
头车车门打开之前的主动停车时长和车门关闭之后的准备时间可通过 “停车数据”和“时间数据”处理得到,前者可以包含在头车的落客时长中,后者时长较短,经统计取值范围为1~2 s,可以采用均匀分布(取值1 s)来表示.跟随车辆车门关闭之后的准备时间无法获取,但可以参照头车的准备时间.经统计,车辆的落客时长分布服从负指数分布[25],其与车辆所处的位置、区域没有明显的相关性,在构建模型时可以忽略落客时长对落客决策的影响.从如图1所示的车辆落客决策模型可以看出,影响车辆落客决策的主要因素包括车辆停车位置及其期望停车位、受迫停车时长及其等待耐性,期望停车位置可以通过统计头车的落客位置得出,而等待耐性的分析则较复杂,其数据集包含2种类型,一种是受迫停车时长等于等待耐性的数据(受迫停车落客),另一种是受迫停车时长小于等待耐性的数据(受迫停车未落客),其对应分别如下:
1)车门打开之前的受迫停车时长:该时间段可以认为是车辆的受迫停车等待耐性(patience),说明车辆受迫停车时长超过车辆等待耐性,因此在受迫停车一段时间后选择落客.在这种情况下,测量得到的受迫停车时长就是等待耐性的值.
2)未落客跟随车辆的受迫停车时长:在跟随车辆中存在少部分车辆受迫停车未落客的情况,其停车时长小于等待耐性,测量得到的数据是受迫停车时长,而不是等待耐性,其等待耐性的值未知.
针对第2种等待耐性未知的情况,通过生存分析来进行删失数据的分析.
3 车辆等待耐性混合分布模型
车辆的等待耐性分布通过分析车辆受迫停车时长获取,受迫停车行为是“沉没成本效应”的体现,沉没成本的影响导致车辆在落客决策中出现决策偏见,反映在单次受迫停车过程中,车辆在已经付出等待时间成本的情况下继续投入时间等待的倾向.沉没成本效应是指决策者的决策行为因受沉没成本影响而产生的非理性决策现象,具体表现为决策者因顾及沉没成本而继续投入更多成本[26-27]或做出某一行为[28].在FIFO落客车道,车辆的等待耐性符合2类情况,一类是车辆受迫停车后愿意立即落客,另一类是受沉没成本影响下车辆愿意等待更长时间.
3.1 Gamma混合模型
受迫停车等待时长包括2种类型,一种是受迫停车时长是车辆等待耐性,另一种是受迫停车时长没有达到等待耐性极限,后者的最大耐性(最长受迫停车等待时间)无法获取,根据生存分析理论,如果界定终点事件是车辆落客,则该类数据是删失数据,即车辆落客需要花费的受迫停车等待时长未知(统计得到的停车时长不是车辆等待耐性).如果用2个密度函数分别表示上述2种数据,通过2个密度函数的加权和得到车辆等待耐性分布,等待耐性分布函数中各密度函数的权重是每种类型车辆在所有受迫停车等待车辆中所占的比例.
假设车辆等待耐性服从2个类型相同参数不同的连续分布,其概率密度函数分布分别为f1(x)和f2(x),一个随机变量有概率α 的机会服从第1个分布,有 1-α 的概率服从第2个分布.则混合分布的概率密度函数为
为了确保等待耐性非负,假 定f1(x) 和f2(x) 是参数不同的伽马分布(Gamma distribution),形状参数(shape parameter)分别为k1、k2,尺度参数(scale parameter)分别为 θ1、θ2,因此式(1)可以表示为
式中:Γ表示Gamma函数.式(2)就是车辆的等待耐性混合分布模型,通过概率密度函数可以得出等待耐性的分布.
3.2 Gamma混合模型估计
受迫停车时长数据包含受迫停车落客的车辆(受迫停车时长等于驾驶员最大耐性),也包含受迫停车不落客的车辆(这2种车辆都有落客需求,但后者在第1次受迫停车时可能不落客).将数据集分为2个数据集:D1和D2.D1对应受迫停车等待时长大于等于车辆的忍耐水平,其对数似然函数表达式如下:
式中:x∈D1,D1数据量为n.
D2是受迫停车不落客车辆的等待时长,统计的受迫停车时长小于实际忍耐极限,因此其等待耐性(最长受迫停车时间)无法获知,准确的可接受受迫停车时长也无法得到,其对数似然函数可以用如下公式表示:
式中:y∈D2,D2数据量为m.
车辆等待耐性的分布可以通过最大似然估计获得,寻找满足式(3)、(4)和的最大值的参数:
3.3 Gamma混合分布模型检验
为了确保结论的可靠性,分别使用南京南站2个不同时间段(上午时段和下午时段,分别对应时间段1和时间段2)的出租车道数据进行对比分析,时间段1(时间段2)的数据集有487(403)个出租车在落客车道落客,其中444(362)个受迫停车跟随车辆.当第1次受迫停车时,400(328)辆车进行了落客.剩下的44(34)个出租车没有在第1次受迫停车时落客,其中29(24)个在第2次受迫停车落客,8(0)辆车转换为头车在期望落客位置落客,5(6)辆出租车并没有在第2次受迫停车落客,然后转换为头车,0(1)辆车在第3次受迫停车落客,1(1)辆车没有在第3次受迫停车时落客,然后转换为头车,最后1辆出租车在第4次受迫停车时也未落客,然后转换为头车.因此,第1次受迫停车的次数为444(362)次,第2、3、4次强制停车的次数总共为39(34)次.考虑到乘客在再次被迫停车时可能会失去耐心,可以分别估计第1次受迫停车和再次受迫停车时乘客的耐心分布.鉴于等待耐性和车辆所处区域的关系,将数据划分为5类:在区域1内车辆第1次受迫停车时长(148(103)个数据)、在区域2内车辆第1次受迫停车时长(146(108)个数据)、在区域3内车辆第1次受迫停车时长(113(85)个数据)、在区域4内车辆第1次受迫停车时长(37(66)个数据)以及所有区域内的车辆第2~4次受迫停车时长(39(34)个数据).对车辆第2~4次受迫停车时长的数据进行合并,不按区域进行分割,否则数据量太小,无法得到较好的估计.在每个类别中,假设等待耐性是独立的且同分布的.
应用最大似然估计(maximum likelihood estimate,MLE)方法估计混合分布模型的参数.估计结果如表1、2所示.

表1 车辆等待耐性最优混合分布参数(时间段1)Tab.1 Optimal mixture distribution parameters for vehicle patience(Time period 1)

表2 车辆等待耐性最优混合分布参数(时间段2)Tab.2 Optimal mixture distribution parameters for vehicle patience(Time period 2)
时间段1中区域1第1次受迫停车等待耐性的混合分布曲线如图3所示.图中,P为概率密度,即受迫停车事件随机发生的几率,t表示受迫停车时长或等待耐性的统计值.直方图为区域1第1次受迫停车出租车等待时长分布情况.为了进一步验证模型的有效性,针对删失数据进行生存分析,采用非参数的Kaplan-Meier方法[29]来估计经验累积分布(生存函数),将混合模型的累积分布函数与经验累积分布函数进行比较,并与通过Greenwood公式[30]计算的95%上下限进行比较,结果如图4所示.图中,tp表示等待耐性.比较结果表明,混合模型的累积分布函数与经验累积分布函数较吻合,且始终位于95%上下限之间,说明拟合结果较好.2个时间段数据集的估计都得到了类似的拟合优度.

图3 区域1第1次受迫停车出租车等待时长直方图及车辆等待耐性概率密度曲线Fig.3 Histogram of taxi wait times and probability density function of patience for first forced stops in Zone 1

图4 区域1第1次受迫停车出租车等待时长累积分布曲线Fig.4 Cumulative distribution function of taxi wait times for first forced stops in Zone 1
3.4 车辆等待耐性特征分析
统计分析表明,等待耐性和车辆停车位置并没有明显的相关性,但和停车区域、停车次数存在一定的关系.由表1、2可知,在5种估计的混合分布中,每一种的2组分布之间,均有以下结论:1)形状参数满足k1<k2;2)平均值满足k1θ1≪k2θ2;3)方差满足这与前面提到的假设一致,即f1(α;k1,θ1) 描述了不耐烦车辆的等待耐性分布(接近零),而f2(α;k2,θ2) 描述了耐心车辆的更广泛的等待耐性分布.从表中还可以看出,第1次受迫停车的 α 从区域1到区域4呈增加趋势,说明在空间层面上,随着受迫停车位置向下游移动,愿意立即落客的车辆比例逐渐增加,这与前期猜想一致.统计分布进一步证实了落客决策中的沉没成本效应,当车处于受迫停车前期,选择落客的收益是要大于损失的,这就导致车辆的受迫停车时长大多数集中在接近0的范围内,而当车辆受迫停车时长逐渐增加,已经付出了一些沉没成本,进一步的损失不会导致目标价值的大幅下降,然而,同样的收益可能导致目标价值的大幅增加,因此付出沉没成本的车辆愿意承担微小损失的风险,以获得可能的大幅收益,所以付出沉没成本的车辆更有可能进行风险投入,即继续为沉没成本增加时间成本,这就导致部分车辆的受迫停车时长集中在20~30 s.对于停车区域对等待耐性的影响,落客区域上游的等待耐性最大,而最下游区域最小,并且在落客区域上、中游区域,车辆第1次受迫停车的等待耐性也大于第2~4次受迫停车的等待耐性.
通过对出租车道落客行为的分析,可以认为车辆落客决策中起决定作用的是车辆停车位置、受迫停车时长和等待耐性,若要建立符合实际落客决策的模型,就必须考虑这些因素.
4 落客决策模型指标及数据
出租车道车辆落客行为特征是复杂的,即包括空间约束和时间约束这2类重要因素,也包含其他未被观测到的因素,采用一般的预测模型并不能完全体现出数据的价值.并且车辆落客行为数据是轨迹数据,包含截面和时间2个维度,蕴含不同车辆、时间和空间对车辆落客决策的各种影响因素.根据前期研究成果及落客行为分析结论,考虑在面板数据模型的基础上构建面板二值选择模型.
4.1 模型主要变量
面板数据从横截面上看,是由若干个体在某一时刻构成的截面观测值,从纵剖面上看是一个时间序列.模型面板数据来源于轨迹数据,提取轨迹数据中每辆车在每一时刻的状态,即面板截面观测值,主要包括车辆是否落客、是否受迫停车、停车时长、受迫停车次数、车辆位置等数据.为了分析、预测车辆落客行为,面板二值选择模型的被解释变量均设定为车辆落客的选择情况,即车辆是否落客,落客取值为1,否则为0,编号为i的车辆在受迫停车t时刻的选择结果记为yit.解释变量则是影响落客决策的主要因素,主要包含如下变量:
1)当前受 迫停车时长t为等待 耐性的概率X1:
式中:f(t) 为等待耐性概率密度函数.
2)车辆相对 停车位置X2:
式中:l为车辆当前停车位置,L为落客区域长度.
3)当前停车位置是期望停车位的概率X3:
式中:F(l) 为期望停车位的非参数概率分布.
4)行驶时间占比X4,车辆从进入落客区域到当前时刻的行驶时间占总行程时间ta的比值:
式中:tc为行程时间中的累计停车时长.
5)受迫停车次数X5,该变量仅在2次以上受迫停车落客决策模型中出现.
4.2 数据处理
由于面板数据的特殊性,通常对于时间序列数据与横截面数据的分析方法不能直接套用在对于面板数据的分析上.此时,须对数据进行处理、检验,并对模型进行选择.
1)平衡面板数据.
模型数据是非平衡面板(unbalanced panel)数据,而非平衡面板可能出现的最大问题是:存在原来在样本中但后来丢掉的个体,如果“丢掉”的原因跟内部数据有关,则会导致样本不具有代表性,导致估计量不一致.为了应用面板数据模型,考虑将非平衡面板数据转化为平衡面板数据,单纯的删掉截面(个体)某段受迫停车时刻的数据是不科学的,会造成估计结果的不准确.这里通过合理的假设来补齐数据,使其成为平衡面板数据,主要做法如下.
(a)出租车个体受迫停车落客情况.受迫停车时长t小于等于所有车辆的最大受迫停车时长T,补齐剩下的受迫停车时长数据,使其受迫停车时长总和为T.假设车辆在补充的受迫停车时长内均会落客,其被解释变量设置为1;当前受迫停车时长t和累计停车时长tc都随受迫停车时长的增加而增加.补齐规则如下:
式中:ld为最远停车位置.
(b)出租车个体受迫停车未落客情况.受迫停车时长同样小于等于所有车辆的最大受迫停车时长T,但已知该车辆在最后一个受迫停车时刻未落客,其补齐的受迫停车时长数据中被解释变量不一定为1,此时以车辆轨迹中的最终累计受迫停车时长作为等待耐性(对于受迫停车未落客车辆来说,其整个行程中的累计受迫停车时长反映了车辆落客意愿的强弱,侧面反映了车辆的等待耐性),时间序列数据补齐规则如下:如果≤T,或者当前受迫停车时长t≥,后续时间序列按照处理方法(a)补足,被解释变量yit设置为1;如果>T,或者≤T且t<,则该车辆补齐的被解释变量yit均 为0,其他变量的补齐规则与式(10)一致.
须注意的是,时间序列数据补齐规则仅以车辆未补齐前的最后一条数据作为参照,而不是根据实际的情况调整的,这样做是为了保持数据的一致性.
2)数据检验.
数据检验与模型选择密切相关,通过个体效应和随机效应的联合显著性检验,可以判别是否须利用面板数据类型,而平稳性检验和协整检验可以证明时间序列数据的平稳性和长期均衡性.
(a)个体效应和随机效应的联合显著性检验:以4.1节的主要变量构建随机效应模型.随机效应模型结果拒绝了原假设(原假设为直接使用Logit模型比使用随机效应模型要好),卡方值为2×104,P为0.000,说明存在个体效应,可以认为采用随机效应模型比直接采用Logit回归模型效果更好、更恰当.由于存在个体效应,有必要选择面板数据模型.
(b)平稳性检验:为了防止出现虚假回归的情况,首先对面板数据集中的单位根或平稳性进行检验.对关键变量 “当前受迫停车时长是等待耐性的概率”、“行驶时间占比”进行LLC(Levin-Lin-Chu)检验,而近似分类变量的“车辆相对位置”和“当前停车位置是期望停车位的概率”进行Harris-Tzavalis检验[31],结果显示,所有变量都是平稳的,不存在单位根,无须进行协整检验.
数据经过处理和检验后,可以采用面板数据模型.
5 落客决策模型
数据类型是标准的面板数据,因此每条观测间不是相互独立的,同一个个体(车辆)有多条观测数据,观测数据间存在一定的相关性,无法采用二分类Logit模型,但可以采用面板二值选择模型.
5.1 二元面板Logit模型
对于落客车道n辆出租车样本,其中每辆出租车i(i=1,···,n)在Ti时间点被观察到.设出租车i在时刻t的二元响应变量为yit(被解释变量),其中t=1,···,T,Xi为协变 量的列向量(包含所有解释变量),Xi=[xi1,···,xiT]T,基于假设的Logit公式表达式如下:
式中:αi为个体特异性截距,β为与解释变量xit相关的回归参数.对于联合概率:
5.2 模型估计结果
面板数据模型可以采用混合普通最小二乘估计(Pool OLS)、组间估计(between estimator)、组内估计(within estimator)、一阶差分估计(first difference estimator)、最小二乘虚拟变量估计(LSDV estimator)、随机效应广义最小二乘估计(REGLS estimator)等,这些估计方法对于随机效应模型都是有效的,这里采用混合普通最小二乘对二元面板Logit模型进行估计,第1次受迫停车落客和2次及以上受迫停车落客决策模型估计结果如表3所示.

表3 受迫停车落客决策模型估计结果Tab.3 Estimation results of drop-off decision model
由估计结果可知,第1次受迫停车落客决策模型比2次及以上受迫停车落客决策模型少1个变量:受迫停车次数(X5),其对落客决策有负向影响,即受迫停车次数越多,落客的概率越小,这是因为多次停车车辆后面几次停车时长要比前面停车时长更长,这侧面说明了沉没成本效应,付出成本越高,沉没成本效应越强.当前停车时长为等待耐性的概率(X1)对车辆是否落客的影响最大,且影响为正,说明等待时长越接近等待耐性,车辆落客的概率越高.另一个影响车辆落客决策较大的因素是车辆行驶时间占比(即车辆行驶时间和车辆行程时间的比值,X4),对落客决策有负向影响,即:在整个行程中,行驶时间占比越小,说明累计停车时长越长(可能存在多次停车),其落客的概率越高.另外,车辆相对停车位置(X2)、当前停车位置是期望停车位的概率(X3)这2个变量均对落客决策有正向影响.
5.3 模型预测
为了进一步检验上述模型的有效性,对得到的二元面板Logit模型分别进行样本内检验和样本外检验.其中,样本内检验是利用所建模型对受迫停车期间的研究样本进行模拟,考察其模拟的准确度;样本外检验是利用所建模型对同一天的相邻时间段的检验样本进行预测,考察其预测的准确性.另外,考察不同天的模型预测情况(3.3节的时间段1和时间段2),对模型的适应性进行分析.
1)时间段1的模型预测结果.
以“当前受迫停车时长为等待耐性的概率”、“车辆相对停车位置”、“ 当前停车位置是期望停车位的概率”和“行驶时间占比”分别在第1次受迫停车和2次及以上受迫停车时的数值为自变量,以对应停车时刻的落客情况为因变量,将它们代入所建二元面板Logit模型中,检验模型的有效性,结果如图5和表4所示.其中,PFPR表示误报率;PTPR表示敏感度;AUC为ROC曲线下方的面积,可以用来衡量二分类模型优劣,其值越接近 于1.0,模型效 果越好;M1和M2为样本 预测结果对应的受迫停车次数,分别为第1次受迫停车、2次及以上受迫停车落客次数;为样本外预测结果对应的受迫停车次数.由预测结果可知,落客决策模型无论是样本内检验,还是样本外检验,其整体预测准确率均大于81%,证明了模型的有效性.

表4 落客决策模型ROC结果(时间段1)Tab.4 ROC results of drop-off decision model (Time period 1)
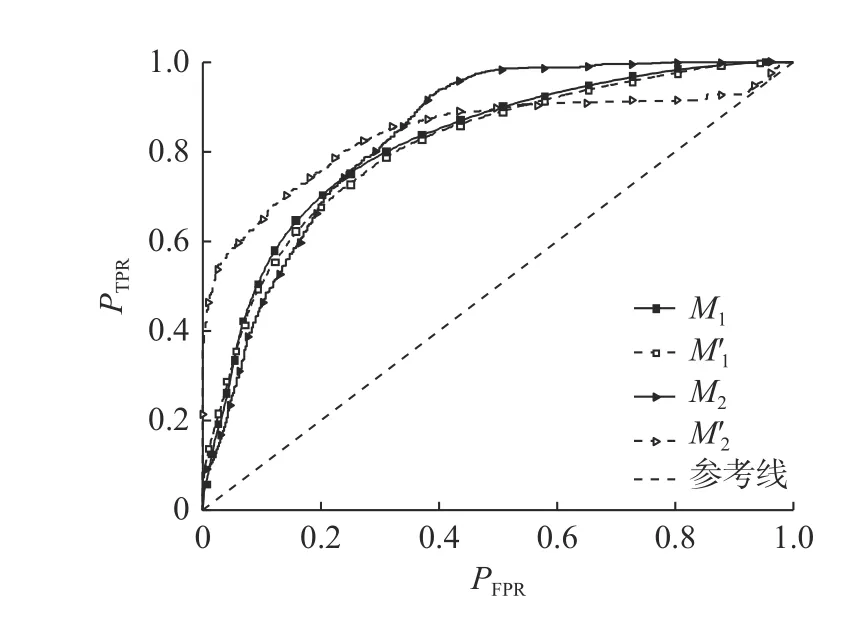
图5 受迫停车落客决策模型ROC曲线(时间段1)Fig.5 ROC curve of drop-off decision model (Time period 1)
2)时间段2的模型预测结果.
对时间段2的模型进行样本内检验和样本外检验,结果如图6和表5所示,其结果与时间段1的预测结果近似,模型预测准确率均超过81%,说明模型具有较好的适应性.
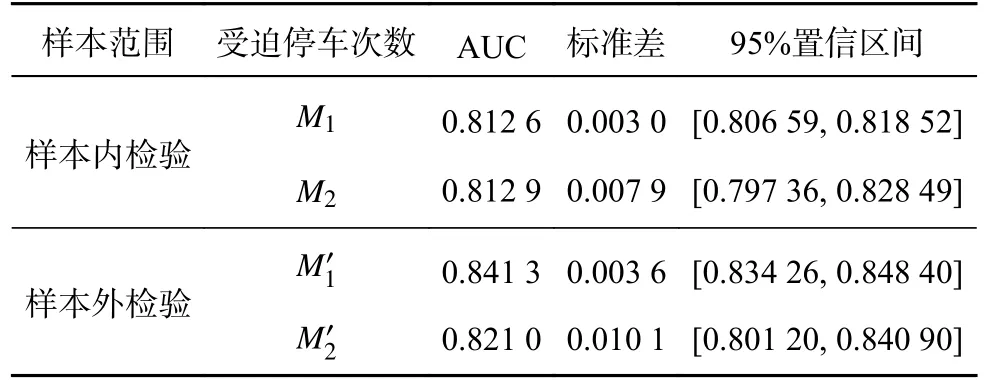
表5 落客决策模型ROC结果(时间段2)Tab.5 ROC results of drop-off decision model (Time period 2)

图6 受迫停车落客决策模型ROC曲线(时间段2)Fig.6 ROC curve of drop-off decision models (Time period 2)
6 结语
针对客运枢纽送站坪的出租车道,通过对落客区域出租车落客行为分析,建立车辆等待耐性混合分布模型,该模型检验结果与真实数据吻合.在此基础上建立出租车落客决策模型,模型采用二元面板Logit模型,考虑不同车辆、时间和空间对车辆落客决策的影响.分析结果显示,等待耐性对车辆落客决策起着决定性的作用,随着受迫停车位置向下游移动,愿意立即落客的车辆比例逐渐增加,并且出租车受迫停车时长越接近等待耐性,车辆落客的概率越高.车辆落客决策模型的验证结果表明,模型能够较好地表达出租车的落客决策,其预测准确性超过81%.
为了提高落客区域运行效率,须采取一些措施来减少车辆落客前的等待时长,该等待时长是沉没成本效应的体现,是一种决策偏见.车辆在期望停车位置落客的可能性不明确,这种不明确加强了沉没成本效应,如果能够降低乘客心理预期,减少沉没成本的初始投入,让更多的“乐观者”向“悲观者”转变,这势必会大大减少车辆受迫停车时长,提高落客区域的通行效率.针对上述分析结论,可以考虑在落客区域规定“无等候区”,即受迫停车车辆必须立即落客,虽然这样会增加一些乘客的步行距离,但与通行能力增加带来的好处相比,对一部分乘客造成的不便影响并不是很大.该策略可以安排交警执行,或者使用语音播报、智能摄像机、可变信息标志提示等自动执行.
如果能够采用更加合理高效的非平衡面板的处理方法及面板数据模型,本研究方法还可以进一步改进.现有的计量模型在交通行为的研究领域并不多见,这是因为数据处理方面的难度较大,并且动态模型估计效率较低,多数情况下只能采用静态模型.另一方面,增加数据量也是模型改进的方向之一,如果数据量足够大,可以构建一个更现实的模型来解释出租车的落客决策.
猜你喜欢
机械工业标准化与质量(2021年10期)2021-11-19
数学小灵通·3-4年级(2020年10期)2020-11-10
快乐语文(2020年26期)2020-10-16
模具制造(2019年4期)2019-06-24
今古传奇·故事版(2017年24期)2018-02-07
摄影之友(影像视觉)(2017年1期)2017-07-18
山东青年(2016年1期)2016-02-28
汽车观察(2016年3期)2016-02-28
中国工程咨询(2014年1期)2014-02-16
植物营养与肥料学报(2010年4期)2010-11-06
