
基于“三新”企业分层抽样单元权重动态调整的估计方法
2024-03-13 02:38张维群成鹏东
统计与信息论坛 2024年3期
张维群,成鹏东
(西安财经大学 统计学院,陕西 西安 710100)
一、引言
得益于大数据技术的发展,社会经济活动的形式日新月异,诞生了大量具有新产业属性的企业,由此也不断催生出新的商业模式和更多的业态[1]。近年来,随着互联网与传统行业加速渗透,“三新”企业正成长为新经济活动的重要组成部分,国家统计局对此也制定了专项统计报表制度,并于2018年发布了《新产业新业态新商业模式统计分类》(国统字〔2018〕111号)。为指导中国新经济生产核算工作,彭刚等基于SNA视角探究了新经济生产核算的相关问题,指出可以借鉴R&D核算制度,通过引入“三新”统计方法来落实相关的核算工作[2],这对中国统计部门在认识新经济方面提供了一定的借鉴。宁吉喆也提出,提升高新技术产业的统计能力,依托“三新”企业高质量数据资源,提取有价值的信息并进行分析,有助于全面反映新经济的发展状况[3]。于是,针对“三新”企业开展统计调查并进行动态监测,成为了经济统计领域新的关注点,例如贺建风等在关于政府统计监测体系的研究中指出,要不断改革企业数据的统计方法,强调抽样调查是掌握“三新”经济活动最新动态的有效方法[4]。
目前,基于“三新”企业开展抽样工作的难点主要是调查对象的情况比较复杂,信息化和高劳动生产率的特点,使得“三新”企业总体数量特征的变换比较快、变动幅度也比较大[5]。以企业年主营收入指标为例,在总体分层抽样框中,不同层级范畴内的单元同期内的变动差异较大,金勇进等对湖北省工业企业的年主营收入进行了连续调查,结果表明:年主营收入在2 000万元左右的企业,数据总体起伏比较明显,这其中有相当数量的单位是短期内注册的,另一方面,那些年主营收入超过1亿元的企业,其调查结果则呈现出较为稳定的趋势[6]。但是,在实践中通常无法及时地更新抽样框信息来反映调查总体的变动信息,单靠固定抽样框进行取样调查与估计的传统方法,就可能对总体数量特征的估计产生较大误差,难以及时、全面地掌握调查总体的最新态势、发展规模和产业结构。
具体而言,“三新”企业总体特征参数的变动主要具有两个特征:其一是短期内会出现很多新的单元;其二是部分单元的分布层级会发生变化,从而改变整体的分层结构和分层规模。如果仍然采用固定抽样框下的传统估计方法,基于特征一,部分新生的单元无法入样,影响样本代表性,Little等指出在经济统计领域中采取的抽样设计要最大限度地挖掘抽样框中相应的数据信息,以对冲选择偏差对估计结果的影响,若是忽略代表性误差的干扰,可能会得到有误导性的结论[7];基于特征二,固定抽样框内部的分层结构与总体实际的分布结构之间存在差异,这种与总体结构差异较大的样本会降低分层抽样的估计效率,对统计推断的准确性和有效性产生影响[8]。
鉴于此,本文针对“三新”企业总体单元变化快、变动大的特点,探讨了新的抽样估计方法来提高样本的代表性,并改进对于总体数量特征的估计精度,尝试获取及时且准确的数据资源,为“三新”经济统计监测体系的构建提供有效参考。
为准确估计调查总体变动后的规模和水平,现有的抽样估计思路是:基于多重抽样框理论,对老化的抽样框进行修正,然后采用分离抽样框的估计方法,推断总体的数量特征。例如,在机器学习研究领域,李毅等设计了实施多指标均匀设计抽样调查的算法框架,为利用辅助信息修正样本分布结构,提升动态数据样本代表性提供了理论上的佐证[9]。基于大数据背景,万舒晨等利用多源数据融合技术,对小微型企业进行多重抽样框设计,通过名录框和区域框的组合估计,有效控制了动态总体的抽样误差,并基于实证研究,明确了抽样框外的信息能够有效弥补抽样框与实际总体不一致的缺陷[10]。人口统计领域,李乐玲等为复杂抽样数据事后分层权重的估计提供方案,应用事后分层权重调整人口学构成使得样本的分布结构与实际人口构成相一致,据此获得了各层参数的合计估计值,有效提高了该领域参数估计和假设检验的准确性[11]。以中国住户调查数据为例,巩红禹等从抽样设计的事前保证和事后评估两个视角,给出了获得分层平衡样本的方法,研究了分层平衡样本的代表性问题,认为基于事后分层抽样技术提取子总体特征信息,可以进一步对总体和各层的数量特征进行推断[12]。基于事后分层样本,李涛等设计了关于删除数据的保序估计,依据样本中出现空层可能性的大小,整理排序抽取的样本,并利用与空层相近的非空层估计代替空层,据此构造了相应的保序Kaplan-Meier估计,提升了整体的估计效率[13]。
特别地,针对新生单元无法入样的问题,一种可行的思路是将其视为不可观测的缺失数据,然后采用热平台插补进行估计,相关的理论研究有:Kim等设计了基于回答概率的插补方法,明确了对不完整数据采取插补的目的并不是估计单个的无响应数据,而是为了预测不响应数据所服从的分布[14];在实践中,单一插补的估计方法往往会低估方差的大小,于是为了有效估计因插补而产生的不确定性,Toutenburg等对近似贝叶斯自举法(ABB)展开研究,设计了基于多重插补的抽样估计方法,并讨论了抽样误差的大小,这为预测实际的总体分布弥补估计标准误差的损失提供了理论上的依据[15]。在此基础上,于力超等具体研究了分层结构中缺失数据集的插补估计方法,模拟实验的结果表明:在分层抽样框模型中应用多重插补技术,其估计结果的准确性会受到缺失机制和数据缺失比例的影响,并且估计量的有效性比较低[16]。
经过上述梳理,可以发现:构建多重抽样框的设计思路和估计方法比较复杂,目前还没有形成较为通用的抽样流程,在不同的研究场景下,其目标变量估计量的形式也不尽相同,而基于缺失数据分析进行估计的思路,无法有效地控制抽样误差。于是,本文从“三新”企业抽样调查的现实需求出发,为这一类动态总体提供一种具有一定通用性的抽样设计与估计方法。首先,基于样本分布结构,把样本单位划分为固定抽样框内的单位和固定抽样框外的单位;然后,通过事后分层估计的方法,为发生变动的单元创建一个预测分布的方法,来推断总体结构的变动特征,以提升样本的代表性;最后,基于层规模的变动特征对总体目标变量估计量的权重进行调整,实现对于抽样误差的控制,并给出关于总体数量特征估计量的一般形式。
二、基于“三新”企业分层抽样单元权重动态调整的抽样设计
把作为已知信息的过往抽样框称为固定抽样框,把发生变动之后的未知抽样框称为实际抽样框。本文的研究思路为:基于固定抽样框提供的信息,针对调查总体开展抽样设计,并通过分层抽样单元权重的动态调整来构造复合估计量,推断实际抽样框的总体容量和总体总量。
以固定抽样框的分层结构为基准,可以在实际抽样框中把总体单元划分为两类:
第一类,保留单元。指的是与基准相比,分布层级相同的单元,调查样本中由保留单元构成的部分称为保留子样本,定义由保留子样本构造的估计量称为保留子样本统计量;
第二类,转移单元。包括在实际抽样框中新出现的单元以及与基准相比,分布层级发生了变动的单元,调查样本中由转移单元构成的部分成为转移子样本,定义由转移子样本构造的估计量称为转移子样本统计量。
显然,基于这两个统计量进行恰当的加权综合就可以构造关于整体数量特征的复合估计量。其中,保留子样本统计量及其权重可以基于固定抽样框进行取样调查,并采用事后分层估计的方法来构造和计算;而由于实际抽样框未知,转移单元的分层结构和抽样权重则需要动态调整。于是,这里假定在实际抽样框中,同一层级中单元的水平分布近似相同,借鉴热平台插补缺失数据,能够有效保留子样本信息,并保证分层样本中数据分布性质不变的思想[17],考虑把转移单元的数据信息分摊在保留单元当中,并利用事后分层样本中的辅助信息,来预测变动后的总体结构,据此实现对于转移单元权重的动态调整,并将保留子样本和转移子样本的数据信息整合起来,构造关于整体数量特征的复合估计量。
综上所述,给出了如图1所示的设计思路。

图1 分层抽样单元权重动态调整估计方法的设计思路
首先,在抽样框未知的情况下,对调查总体进行两次独立的非概率抽样,基于选定样本的实际观测结果,进行事后分层处理,得到事后分层样本A和B,对比固定抽样框的结构分别确定样本A和B中各层保留单位和转移单位的数目,挖掘各层的变动规律,并分别估计总体单元的层级保留概率和层级转移概率,由此构造层规模的简单综合估计量,以实现对于实际抽样框分布结构的短期预测。

最后,在同质层内单元的分布特征近似相同的假定下,利用层规模的变动预测对转移子样本的分布结构进行动态调整,基于自我加权设计把这两部分子样本统一为完整且结构依赖于总体分布的代表性样本,并实现对于总体总量复合估计量的构造。
三、总体总量估计量的构造

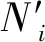

表1 分层抽样单元权重动态调整估计方法设计中的符号及注释
(一)总体容量简单综合估计量的构造
基于本文对于调查总体单元的划分,总体容量可以表示为同质层内保留单元与转移单元的规模之和,于是由固定抽样框的总体容量、层级保留概率和转移概率构造各层总体规模的简单综合估计量,表达式如式(1)所示:
(1)
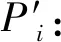
(2)
(3)
(二)总体总量复合估计量的构造

(4)
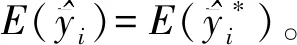
而针对保留子样本Si,每一层内采取的是简单随机抽样,第i层内的每一个保留单元yij在理论上都有相同的入样概率,因此单独的保留子样本并不能直接反映总体的分布结构,应当对每一个入样的单位yij进行修正,于是采用估计量的自我加权设计理论[19],基于抽样方式和估计方法设定相应合理的权重,对样本观测结果进行加权处理,以调整样本分布结构,实现对于完整抽样框的覆盖[20],提升样本的代表性,使得总体参数的估计量无偏。
由此,本文参考熊巍和程豪等基于逆概率加权修正估计量,以减少估计偏差的设计方法[21-22],基于事后分层样本A中的保留样本单位数目mi对保留单元的入样权重进行动态调整。
(5)
(6)
(7)
(三)估计统计量的优良性评价
本文设计的基于“三新”企业分层抽样单元权重调整的估计方法存在如下假定以及结论:
Ⅰ.保留子样本来自简单随机抽样,保留子样本均值统计量具有无偏性[19]。即存在式(8):
(8)
Ⅱ.r和m源自独立的样本,是独立的随机变量,且都是总体中保留单元实际数量M的无偏估计量。即存在式(9):
(9)
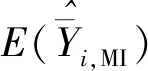
首先,无放回简单随机抽样下,总体总量估计量方差的计算公式为[25]:
(10)
其中,s2为样本方差,f为抽样比,样本方差的计算公式如下:
(11)
(12)

(13)

详细推导过程如下所示:
其中,表达式里的第一项代表了保留子样本的方差,而第二项则体现了由预测分布修正样本分布结构所带来的方差增长。
四、分层抽样单元权重动态调整估计方法的模拟实验
(一)总体数据库的生成
基于蒙特卡洛方法产生随机数,描述企业单元的产值,形成初始抽样框数据集,并对数据单元进行随机扰动处理,模拟实际中受市场机制驱动而产生的数据变动,由此形成“三新”企业动态总体数据库。数据库的生成过程由以下三个步骤完成。
1.生成原始的固定抽样框
首先,依据正态分布N(100,106)生成5 000个随机数据并对所有数据取绝对值,此时,数据集的均值为794.315,标准差为602.227;
其次,基于层内数据方差小而层间数据方差大的原则,把数据集划分为低、中、高三层结构分布,形成固定抽样框U1。
图2是数据库U1分布图像,可以发现:高层级的企业单位在总体中的占比很低,大多数企业为中等或小型企业,这也和中国企业的规模及水平呈现较大分布差异的调查结论相一致。
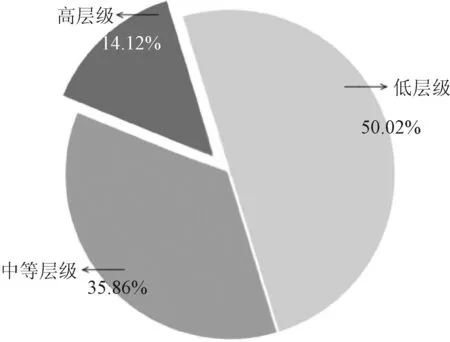
图2 固定抽样框U1各层级数据分布
表2展示了数据库U1的特征参数,可以发现:层内数据差异水平低,各层级内的标准差分别191.198、223.743和375.091,都非常小,其加权综合的结果一般也小于分层时的总体标准差605.302,考虑到统计量估计误差与总体方差成正比[22],这也进一步表明适宜采用分层抽样的方法估计“三新”企业的数量特征,以控制抽样误差的大小。

表2 固定抽样框U1各层数据特征表
2.抽样框U1的变动处理
其次,设定一个参数ai,用于描述各层数据单元的变化率,其绝对值的实际含义为短期内企业单元的变动幅度。对剩余的数据单元分别乘以ai,实现单元数据大小的随机扰动,以模拟企业单元经营水平的波动情况。为使得单元变动呈现一定的随机效应,这里变化率ai的取值来自不同分布下的随机数,设置a1~U(0.93,1.07)、a2~U(0.97,1.03)和a3~U(0.99,1.01)。
图3是抽样框动态变动前后的分布对比图,其中内环刻画了调查总体初始的数据分布情况,外环代表变动后的数据分布情况,二者的分层结构差异比较明显,实际抽样框U2比较有效地刻画了企业发展过程中复杂的随机性和单元变动特征。

图3 抽样框变动前后的分布对比
3.生成最终的实际抽样框
首先,由N(50,100)随机生成300个新数据并取绝对值,添加到变动处理后的数据总体中,构成最终的实际总体。
其次,依据抽样框U1中确定的分层标准,对最终的调查总体重新判定并进行分层,形成最终的实际抽样框U2。实际抽样框U2各项数量特征汇总如表3所示。
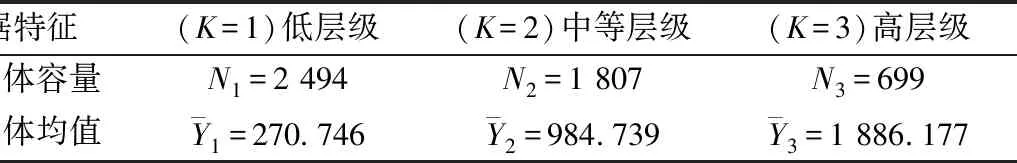
表3 模拟数据库U2的数量特征表
(二)抽样估计的模拟过程
基于上面生成的数据集,开展抽样模拟实验,并估计总体参数。为有效验证抽样方法的估计效果,模拟内容分为实验组与对照组。前者模拟的是本文设计的估计方法,后者模拟的是基于固定抽样框进行简单随机抽样估计的传统方法。
抽样估计的模拟实验过程为:在U1已知的条件下,分别采用对照组和实验组的估计方法,推断U2的总体容量和总体总量。
1.实验组模拟

其次,设定与步骤一相同的分层样本容量,基于U1选定抽样单位,形成取样名录,并在U2中进行调查,在各层样本中仅保留与U1分布结构完全一样的样本单位,由此确定保留子样本数据集Si,其容量ri=(116,73,15)。
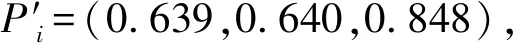
2.对照组模拟
(三)模拟实验的结果比较
1.实验组和对照组样本代表性的比较
总体单元数据分布频率与样本单位数据分布频率的一致程度可以用来评估样本代表性[8]。于是,基于U2总体数据和模拟实验中获得的样本数据分别绘制核密度图像,近似展示各数据单元的频率分布特征,如图4所示。

图4 总体与样本数据分布的比较
观察图4(a)可以发现:总体抽样框U2中有大量数据点分布在靠左的位置,远离数据群,呈现出明显的右偏态,这与其模拟的“三新”企业总体在实际中的分布结构比较相符,即小规模和中等规模的企业在总体容量中占据大多数。此外,对照组样本单位的数据分布更加接近正态分布,与需要逼近的总体分布形状差异较大,而实验组样本单位的数据分布的结构则准确地刻画真实的总体单元分布结构。
基于此,从样本分布结构的角度来说,对照组获得的是非代表性样本,针对动态总体的参数估计一般是不准确、有较大误差的;而实验组可以获得关于“三新”企业的代表性样本,据此样本信息进行统计推断可以满足“三新”经济背景下企业抽样调查的现实需求。
2.实验组和对照组估计结果量优良性的比较
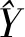

图5 估计总体容量的估计效果
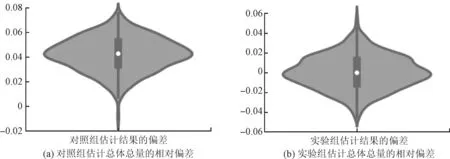
图6 估计总体总量的模拟效果
图5是实验组对于总体容量多次重复估计结果与估计偏差的分布情况;而图6中的两幅图分别反映了实验组估计方法和对照组估计方法对于总体总量的估计效果。
由图5可知,在多次重复抽样估计的实验中,对于总体容量的估计值大致分布在4 880(总体容量真实值)左右,数据图像的箱体宽度也比较小,此外估计的相对偏差也集中在零点附近,数据分布呈现明显的集中趋势,波动范围大多限制在6%以内,可以表明本文构造的关于总体容量的简单综合估计量是准确且可靠的,在大量重复估计情形下,其抽样误差是可控的。
比较图6(a)和图6(b)的分布位置和相对大小可以发现,第一,对照组模拟结果数据整体上处在零值的上侧,实验组模拟结果数据大致集中在零值附近。这表明,对照组的模拟结果普遍高估了总体的真实水平,估计方法存在系统性偏差,而实验组的模拟结果在大量重复估计下大致是无偏的。由此可见,针对动态总体,不考察样本分布结构的变动、无视数据缺失,基于简单随机抽样构造样本均值估计量的传统方法是极不准确的,而基于“三新”企业分层抽样单元权重动态调整的估计方法对于总体总量的估计结果总体上是无偏的。
第二,对照组的模拟结果数据集显然具有更大的方差,而实验组的模拟结果数据则有更加显著的集中趋势,相对误差的数值精度更高,由此可见,在大量重复估计中,相比对照组的估计结果,实验组的估计结果具有更小的抽样误差,构造的总体总量复合估计量也是更加有效的。
综上所述,模拟实验结果表明:由于调查总体单元变化快、变动大,在固定抽样框下进行简单随机抽样获取的样本,其分布结构与总体分布结构之间存在较大差异,样本代表性低,依据该样本进行参数估计通常存在着较大的偏误,这种传统的抽样估计方法已经无法实现对于“三新”企业的规模和水平进行及时、有效的推断;而本文设计的基于“三新”企业分层抽样单元权重动态调整的估计方法,可以有效地优化样本分布结构,提升样本的代表性,并提高对总体数量特征估计的准确性,其构造的总体总量复合估计量是无偏且有效的,该方法在“三新”企业和其他同类型动态总体的抽样调查实践中有一定的应用价值。
五、结论
本文阐述了“三新”企业总体单元变化快、变动大的特点,从基于转移单元调整样本分布结构的角度出发,为这一类动态总体提供了一种具有较高估计效率的抽样设计和估计方法。其基本的思路是:首先,把样本划分为保留子样本和转移子样本,分别用来提取固定抽样框内的数据信息以及固定抽样框外的数据信息;其次,采用事后分层的方法挖掘出各层单元的变动特征,从而实现对于层总体容量的动态推断;再次,基于保留子样本目标变量统计量提供的信息,对转移子样本目标变量的水平进行短期预测;最后,对目标变量估计量进行自我加权设计以构造总体参数动态变动后的复合估计量,证明了该估计量的无偏性,并推导了抽样误差的估计公式。
在研究视角方面,本文从调整样本结构的角度出发,提出了一种基于变动单元的抽样权重调整样本结构的方法,这种方法能够获得更具代表性的样本,从而有效地发挥分层抽样控制抽样误差的优势。通过对样本分布结构进行合理的调整,保证样本的代表性和可靠性,从而提高研究的准确性和可信度;在研究理论方面,本文聚焦于分层总体的研究对象,并考虑到调查单元频繁变动、总体分层规模和分布结构的变化情况,针对这一问题,本文建立了基于过往普查数据资源的固定抽样框,并在此基础上对抽样单元进行细致划分,建立相应的分层抽样模型,这种方法为复合估计量的设计提供了新的思路,为研究者提供了更灵活、准确的工具。在研究方法方面,传统的基于动态总体构建多重抽样框的方法设计较为复杂,且缺乏通用的抽样估计方法,另外这些方法往往依赖于调查对象的固有属性和信息化技术的发展水平,难以适用于不同研究主体。为解决这一问题,本文提出了一种多水平连续调查的方法,通过利用过往的完整数据资源,预测抽样单元的变动信息,并据此调整样本结构,提升整体样本的代表性,这种方法不仅可以增强调查数据的质量,还能够在存在单元频繁变动的动态总体中发挥较高的通用性,并可适用于各个领域的抽样估计,为研究者提供了更广泛的应用空间。
模拟实验表明:相比于在固定抽样框下进行简单随机抽样的传统方法,采用本文设计的抽样估计方法可以获得具有更高代表性的样本,对调查总体数量特征的估计精度也更高。采用本文的估计方法可以为“三新”经济统计监测体系的构建提供具有较高质量的数据资源,此外,该方法构造的复合估计量也可适用于其他同类型的调查总体,是对动态总体抽样调查理论的有效探索。
事实上,为满足当前“三新”企业抽样调查的实际需求,本文探索了合理且可行的估计方法,但在动态总体研究领域还缺乏理论层面更加深入的研究。一方面,本文基于总体单元分层结构的变动,修正了复合估计量的权重,这种处理方法模糊了同一层级中调查单元的差异特征,在未来的研究中,可以进一步讨论动态总体抽样框在更一般变动情形下的估计方法;另一方面,本文仅聚焦“三新”企业变动特征,构造了“三新”企业总体信息的估计量,并推导了抽样误差的估计表达式,如何在复合估计量方差约束条件下实现样本量的最优分配,以及分层结构的划分也都是需要进一步解决的理论问题。
此外,考虑到“三新”企业相关变量的数据质量不佳,当前也缺乏相应的专业数据采集工具,所以本文研究停留在实验模拟的阶段,仅以固定抽样框下的传统方法为对照,针对模拟数据,对设计的估计方法做了优良性验证,并没有基于现实中企业实际经营数据进行更加深入的研究分析,在未来可以考虑依据“三新”企业调查数据特征开展实证分析,设计新的抽样方法,并对估计量进行相应的修正,为动态总体抽样估计方法研究提出更为通用的理论基础。
猜你喜欢
股市动态分析(2020年6期)2020-04-26
股市动态分析(2020年1期)2020-02-10
股市动态分析(2020年1期)2020-02-10
故事作文·低年级(2018年3期)2018-04-08
现代营销·学苑版(2016年12期)2017-01-23
新作文·中学作文教学研究(2016年12期)2016-11-28
旅游纵览(2016年4期)2016-03-29
旅游纵览(2016年4期)2016-03-29
电测与仪表(2015年6期)2015-04-09
数学物理学报(2014年3期)2014-03-11
