
基于数字孪生与k-近邻算法的车间设备运行状态预测研究*
2024-03-15 07:37李忠鹏杨小红
制造技术与机床 2024年3期
和 征 李忠鹏 杨小红
(西安工程大学管理学院,陕西 西安 710048)
具有机械结构的复杂装备和相应软件共同组成了现代装备[1],此类装备在制造业企业生产车间能替代人工,但传统生产车间必须能满足布局规划以及生产线优化的要求[2]。为支持智能制造的发展,德国提出了“工业4.0”、美国提出了“工业互联网”,中国提出了制造业重要纲领[3-4]等,智能制造领域的产业发展,竞争愈发激烈。然而,传统生产车间的设备数据实时交互性差,并且难以实现实时的可视化监控以及远程运维的功能。因此,当下传统生产车间已经很难满足时代的要求,此时数字孪生车间应运而生[2],用以解决上述问题。近年来,将强化学习、深度学习与数字孪生结合的车间调度问题的研究较多[5-6],而k-近邻算法能够辅助修正深度学习的预测过程,将数字孪生效果发挥得更好[7]。综上所述,数字孪生与k-近邻算法相结合是学术界和企业界共同关注的问题。
针对设备运行状态预测问题,学者们对其优化模型、算法实际应用以及数字孪生实际应用研究的较多。“工业4.0”之前,智能制造涉及的人工智能算法领域仅为强化学习、深度学习等,但单纯使用深度学习的智能算法存在较低的成功率和安全方面的问题[8]。因此k-近邻算法因预测准确率较高、操作较为简单等特点,引起了学者们的研究关注。
k-近邻算法一般用于旋转机器故障[9-10]、工业过程相关故障[11]、轴承系统故障[12]等方面的研究。也有学者使用k-近邻算法预测设备运行参数,从而预测设备运行状态[13]。数字孪生是“工业4.0”下智能工厂的关键模块,基于数字孪生的智能装配车间技术是实现智能制造的潜在途径[14]。融入数字孪生的智能算法能够很好地解决上述两个方面的问题。数字孪生在生产车间应用的关键是如何有效地创建数字孪生模型,并使其作用于系统的整个生命周期[15-16]。通过数字孪生技术实时掌握车间设备的运行状态,通过一系列算法实现设备运行状态数据的深度分析与挖掘,进而预测设备的运行状态和健康情况等,最后对这些结果进行可视化显示[17]。因此,数字孪生、k-近邻算法与车间设备运行状态预测的结合势在必行。
通过以上文献分析可知,学者们对于车间设备故障预测的优化模型、算法实际应用以及数字孪生实际应用的研究较多,多数学者单纯使用数字孪生模型或数字孪生与深度学习、强化学习相结合展开研究,而对数字孪生与k-近邻算法相结合的研究很少。数字孪生与k-近邻算法相结合能够解决车间设备海量运行数据难以快速处理且实时跟进效果不强的问题,二者相结合的车间设备运行状态预测模型的准确率高于深度学习的模型准确率。基于此,本文构建了数字孪生与k-近邻算法二者结合的车间设备运行状态预测模型,最后对该模型进行实例验证。通过本文的研究,希望对车间设备运行状态预测方法的优化提供理论基础和实践依据。
1 理论基础
1.1 数字孪生车间虚拟模型构建
车间作为企业生产的基本单元,其高效运行管理是提质增效的重要保障。为实现车间布局优化、工艺流程优化设计及智能决策与调度,诸多学者开展了数字孪生车间虚拟模型构建的相关研究。主要从以下两方面展开:①对车间中的“人-机-物-环境”等生产要素进行建模,主要集中在几何模型的构建以支持车间状态的监控,但对车间的具体行为、规则等多维度刻画不足,而且当前建模大多关注关键零部件、设备或产线等单一层级对象,缺乏从“单元级-系统级-复杂系统级”多层次角度对模型组装与融合的系统研究;②在生产要素建模的基础上进行车间数据实时动态性的研究,车间数据具备多源异构的特点,但当前大部分传统车间数据采集方式仍为人工采集,虽然随后出现了条形码、RFID、传感器等方式,但是又面临信息传输不流畅、数据结构复杂、数据规模指数型增长等问题。数字孪生的全生命周期、实时性以及双向性能够更细致地描绘设备的运行情况,能够使得产品生产数据更加精细化,进而求得更为准确的最小生命周期[2]。
1.2 k-近邻算法
k-近邻算法简称KNN,其功能在于为新数据进行分类。运用时,需要事先给定已知标签类别的训练数据集,然后输入没有标签的新数据,将训练数据集与新数据集做比较,最常用的比较标准为距离,计算训练数据集与新数据集的距离,选定满足标准的k个实例,若这k个实例多数属于某种类别,则可判断设备运行状态属于该类别。其中,距离的计算标准、k值的选取和k个实例所属类别的判断均需具体问题具体分析。k-近邻算法流程如图1所示。
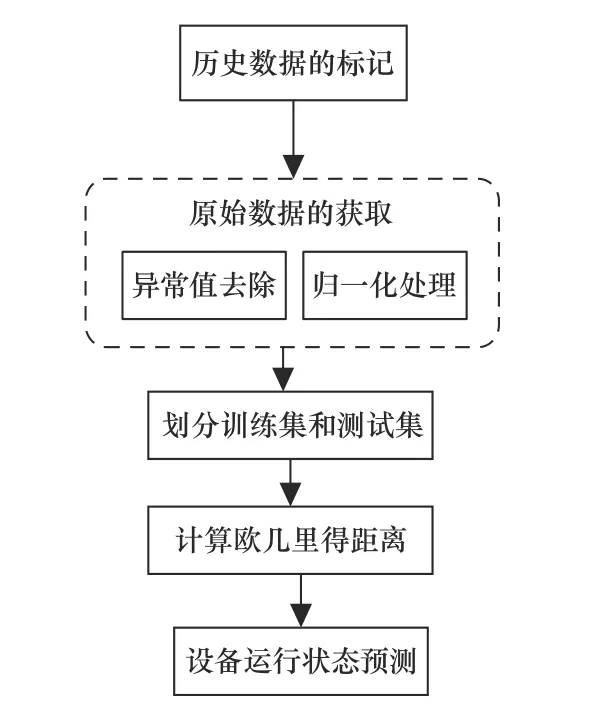
图1 k-近邻算法流程
1.3 设备运行状态分类标准
本文以机电设备为例,确定设备运行状态的分类标准。当前对机电设备运行状态进行分类的标准有两个。第一个是由意大利都灵大学1990 年收录的数据库——机械分析数据库,该数据库收录了某机电设备164 个运行样本的6 种状态模式,状态模式1~6 分别为连接件故障、轴承失效、机械松动、基础变形、不平衡和无故障/正常运行,见表1。第二个是意大利传播科学研究中心收集的钢板缺陷监测数据库,该数据库记录了钢板麻点、Z-划伤等7种故障模式。由于本文研究的是生产车间设备运行状态,与第一个数据库符合度较高,因此运行状态标准选择第一个数据库。机械分析数据库中设备故障模式见表1。

表1 机械分析数据库中设备故障模式
2 基于数字孪生与k-近邻算法的车间设备运行状态预测
2.1 数字孪生体的构建框架
在信息空间中,对车间中的“人-机-物-环境”等生产要素进行建模,构建车间设备实体的数字孪生模型,从“单元级-系统级-复杂系统级”多层次角度对模型进行组装与融合,并建立设备实体与模型之间的虚实映射关系,设备实体与模型共同组成数字孪生体[2]。数字孪生体包括5 层,从下到上依次为:设备层、感知层、数据传输层、数据分析层和服务层,如图2 所示。

图2 数字孪生体构建框架
其中,设备层为车间的各类设备,是设备运行状态预测的主要对象和基础,为感知层提供运行数据、工作环境参数等信息。感知层包含一系列传感器,如高灵敏度加速度计、加速度传感器、激光测距仪等,对设备的振动速度、转动加速度、位移等信息进行采集和传输。数据传输层处于感知层和数据分析层的中间,起到连接纽带的作用,实现数据的传入、运输和空间存储,该层利用数字孪生技术实时掌握车间设备的运行状态。数据分析层利用机器学习模型实现设备运行数据的深度分析与挖掘,进而预测设备的运行状态和健康情况等,该层通过数字孪生技术与k-近邻算法的联合,最终实现设备运行状态数据的定量分析。服务层是实现设备调配的“窗口”,通过人机交互系统将设备运行状态可视化显示,实施对设备的合理调配。
2.2 数字孪生体的构建过程
制造车间的物理空间几何参数、设备属性等多类物理参数,可在各层之间进行传输和存储。可将数字孪生体构建框架转化成高保真模型,通过软件构建生产车间的超写实仿真环境,通过设备、人员和环境等在线运行数据,实时更新构建好的车间模型与环境模拟参数,并对设备运行产生的离线数据进行模型训练,从而迭代优化模型。将在线数据作为初始参数、离线数据作为先验经验,输入到超写实仿真环境中,进行高逼真度行为仿真,实现车间数字孪生体的构建,成功地将车间的实时状态镜像到虚拟空间。数字孪生体对于车间设备运行状态的了解程度,远高于车间操作员,通过车间设备的实时运行状态在线可视化,为车间设备的实时调配提供决策指导。而机器学习算法主要应用于数据分析层中的预测行为以及服务层中的定量分析中。本文将对机器学习中的k-近邻算法在车间设备运行状态预测行为中的应用进行深入研究。
2.3 数据分析层中k-近邻算法的具体预测过程
数据分析层中k-近邻算法的具体预测过程包括5 个步骤:
步骤1:数据分析层对采集的实时特征数据按照相应参数标准进行异常值去除。
步骤2:将去除掉异常值的实时特征数据进行归一化处理,使数据权重相等,且转化为0~1 的数值,若对于设备运行状态预测模型准确率要求较高,可选择较高精确度的方法进行归一化处理,反之则可选择普通的方法,归一化处理结束后的实时特征数据为原始数据。
步骤3:计算原始数据与历史数据之间的欧几里得距离,距离越小,代表设备当前的运行状态越靠近历史数据所标识的设备运行状态,计算公式如式(1)所示。
式中:xi表示归一化处理后的实时特征数据;yi表示已识别的特征数据。
步骤4:将步骤3 中计算出来的距离进行升序排序,选取前k个距离,统计k个距离的频数,频数中的最大值为众数,此众数对应实时特征数据所代表的设备运行状态,即若前k个距离所对应的设备历史运行状态多数为某种运行状态,则设备当前运行状态即为这种运行状态。
步骤5:根据“模型预测准确率=预测结果与实际结果一致的测试样本数/测试总样本数”计算模型预测准确率,最终输出模型预测结果及准确率。
3 实例验证
本文以制造业企业生产车间机电设备运行状态数据为研究对象,进行实例验证。验证数据来源于CDA 菊安酱机器学习内部学习训练数据和52phm公开故障诊断和故障预测数据。基于数字孪生与k-近邻算法的车间设备运行状态预测过程包括3 个步骤:获取原始数据、初步处理采集的数据(异常值去除和归一化处理)和设备运行状态预测(划分训练集与测试集、计算欧几里得距离和预测设备运行状态)。
3.1 获取原始数据
构建车间机电设备实体在信息空间中的数字孪生模型,并建立机电设备实体与模型之间的虚实映射关系,机电设备实体与模型共同组成数字孪生体。
设备层包括制造业企业生产车间的机电设备;感知层通过各类传感器采集机电设备的每小时振动速度、加速度、每小时位移、震动频率以及温度这5 类实时特征数据;数据传输层使用传输控制协议TCP,将感知层采集的5 类实时特征数据传输到数据分析层进行存储和分析。
3.2 初步处理采集的数据(异常值去除和归一化处理)
在数据分析层,首先,对采集的5 类实时特征数据按照“振动速度异常值范围为>40 000 mm/h,加速度异常值范围为≥35 g/s,位移异常值范围为≥2 mm/h,震动频率异常值范围为<4.5 Hz/s,温度异常值范围为30~50 ℃”的标准进行异常值去除;其次,将去除掉异常值的实时特征数据进行归一化处理,使5 类实时特征数据权重相等,且均转化为0~1;若车间对于预测模型准确率要求较高,可选择较高精确度的方法进行归一化处理,反之则可选择普通的方法,归一化处理结束后的实时特征数据为原始数据,存储为data.txt 文本文件。
整合后的数据集包含1 000 组原始数据,其中100 组数据被划分为测试集,900 组数据集被划分为训练集,由于数据量较大,能够很好地模拟车间机电设备日常运行状态的数据量,因此选择该数据集作为验证数据集,部分数据集展示见表2。
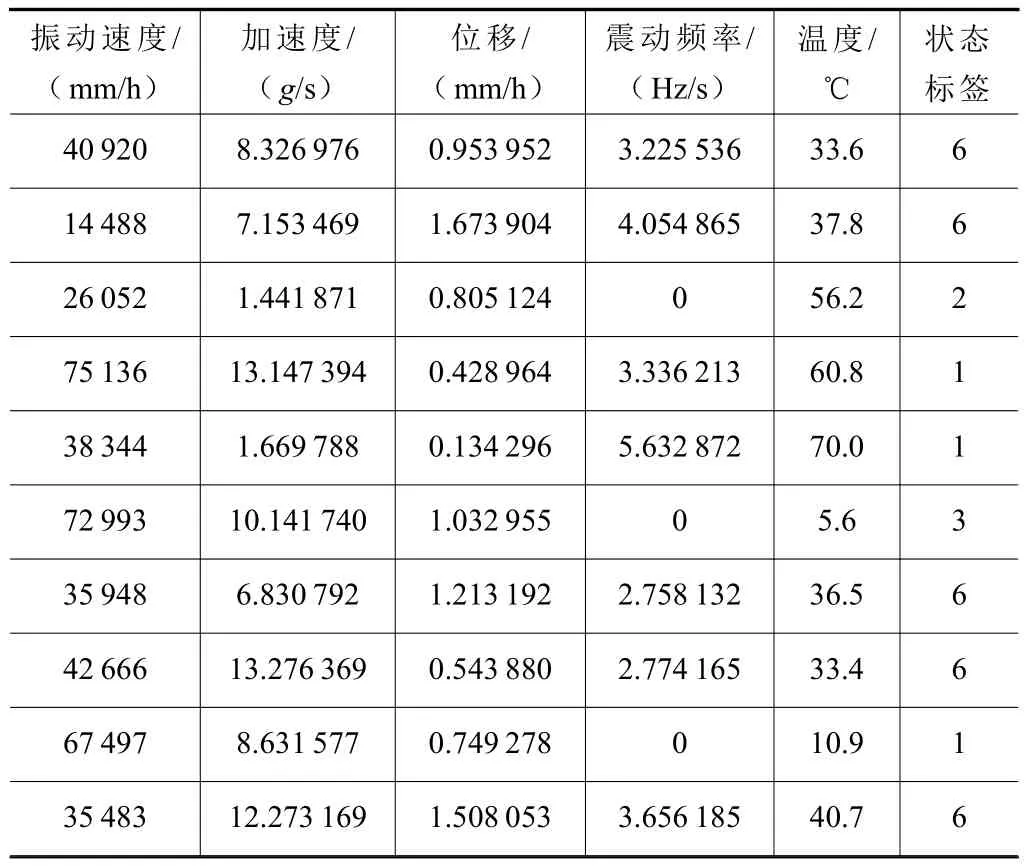
表2 部分初始数据
3.3 设备运行状态预测
在Jupyterlab 软件中新建.ipynb 文件,将data.txt导入到.ipynb 文件相同工作路径下,将原始数据进行模型训练集与测试集的划分,随机选择90%的原始数据作为模型的训练集,10%的原始数据作为测试集,训练集用来训练模型,测试集用来验证模型的准确率,训练集比例越高,设备运行状态预测的准确率越高。表2 数据归一化处理后的结果见表3。
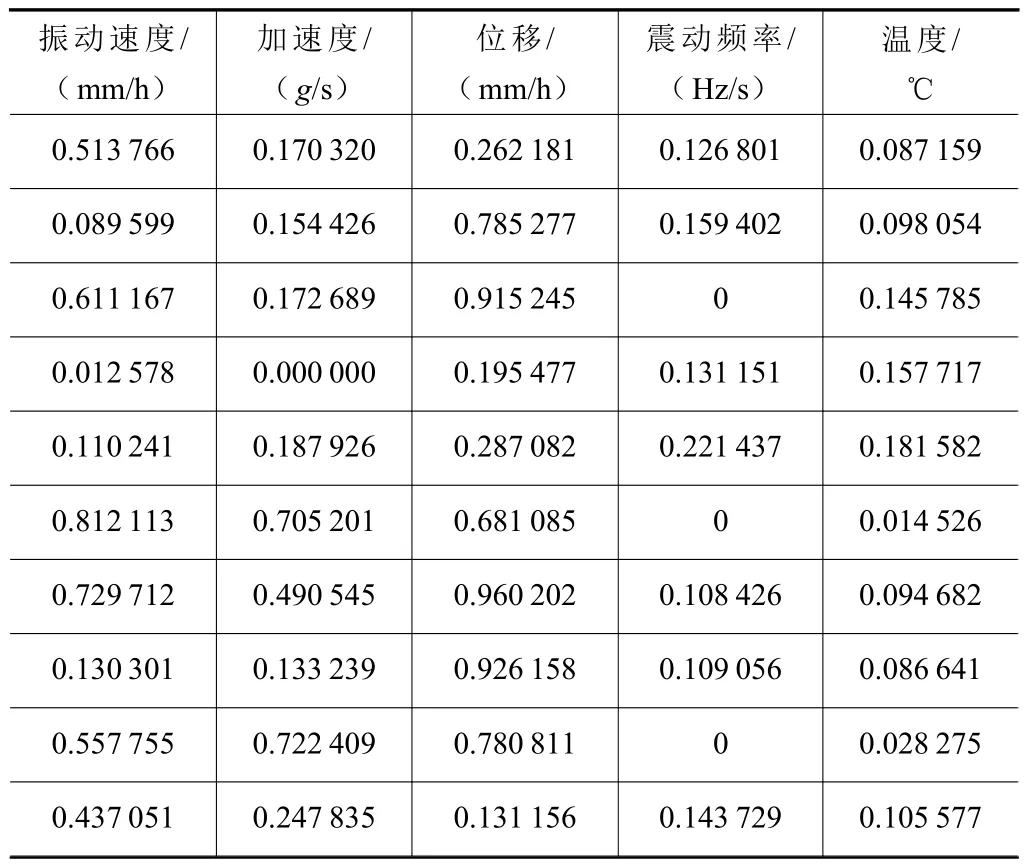
表3 归一化处理后的部分数据
首先,在Jupyterlab 软件中导入Python 中的pandas 包,使用datingClass 函数构建参数为“train”“test”“k”的数据分类器。其中,“train”代表训练集;“test”代表测试集;“k”为超参数,代表选取的欧几里得距离个数。
其次,在数据分类器中使用字典dict 构建数据集,并将数据集转化成DataFrame 形式;根据式(1)计算原始数据与历史数据之间的欧几里得距离,距离越小,代表设备当前的运行状态越靠近历史数据所标识的设备运行状态。
最后,使用list 函数将计算出来的欧几里得距离进行存储,并使用sort_values()[:k]函数对距离进行升序排序。选取前k个距离,使用value_counts()函数计算k个实时特征数据的频数,频数中的最大值为众数,众数对应实时特征数据所代表的设备运行状态;若前k个距离所对应的设备历史运行状态多数为某种运行状态,则设备当前运行状态即为这种运行状态。本文选取的k值为5,模型预测结果见表4。
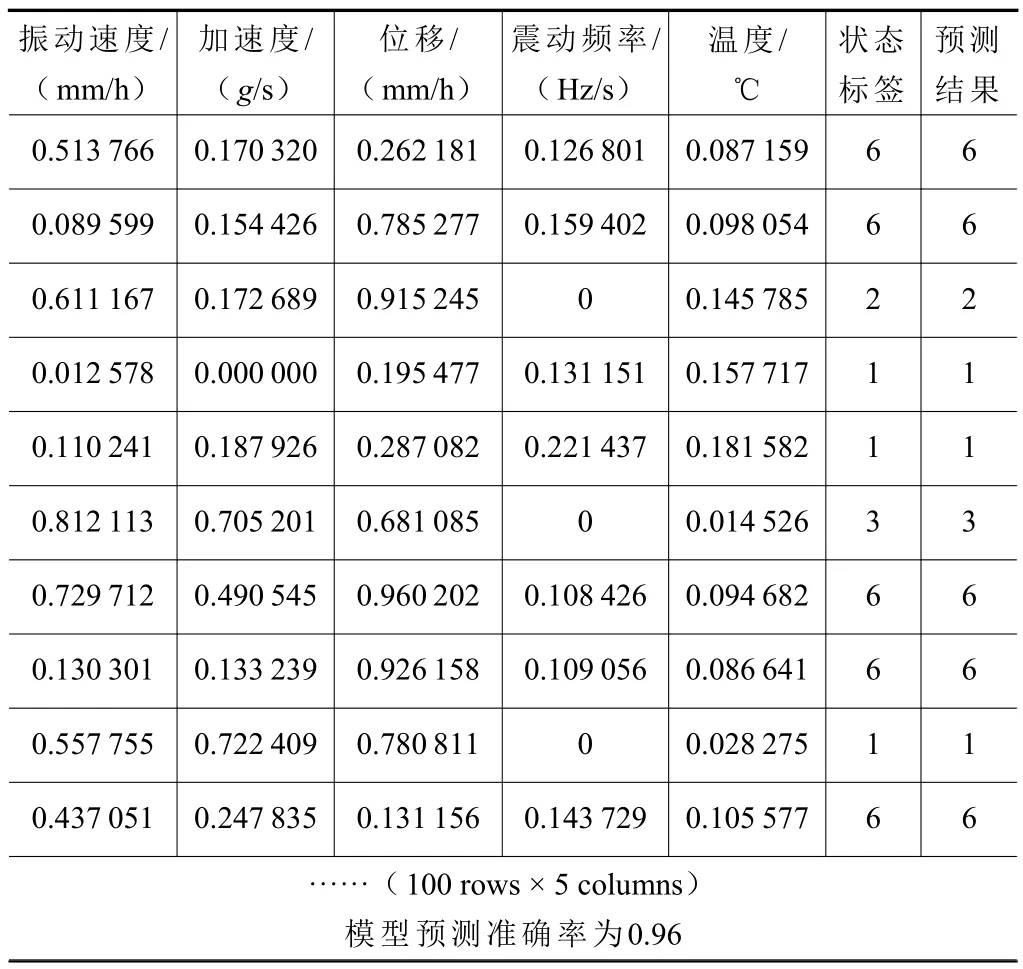
表4 模型预测部分结果及准确率
由表4 可知,测试总样本数为100 组,其中,预测结果与实际结果一致的测试样本数为96 组,根据2.3 节步骤5 中的计算公式可得,模型预测准确率=96/100=96%,可见机电设备运行状态的预测结果与实际结果几乎一样。
4 设备运行状态预测算法对比
目前常用的设备预测算法有卷积神经网络、随机森林、因子分解机和支持向量机。卷积神经网络和因子分解机虽然能够处理高维度数据,但卷积神经网络较容易丢失大量有价值信息,如果网络层次太深,则会导致计算速度变慢,并且其运行过程属于黑盒运行,不易操控[18];因子分解机主要适用于风险分析,对于设备运行状态预测的效果较差[19];随机森林和支持向量机在数据分类以及预测中的表现并不理想,且后者难以处理大规模样本[20-22]。而k-近邻算法适用于大规模样本的处理,思想简单,过程中无假设,设置好k值,即可白盒运行,准确率高,在数据分类中表现较好,且通过实例验证,k-近邻算法在设备运行状态预测模型中的准确率高达96%,因此本文采取的方法是有效可行的。5 种设备运行状态预测算法对比见表5。

表5 设备运行状态预测算法对比
5 结语
本文采用数字孪生技术,构建了车间设备运行的数字孪生模型,并将k-近邻算法融入数字孪生模型中,使用k-近邻算法对车间设备运行状态进行预测,经过实际算例验证了预测模型的可行性。研究表明,通过k-近邻算法与数字孪生技术相结合,能够很好地将车间设备运行数据作为初始参数输入到预测模型中,生成测试集与训练集,通过训练集的状态标签标记,从而预测设备的实时运行状态。本文所提出的车间设备运行状态预测模型具有以下优点:
(1)具备较强的预测能力,实时性较强。k-近邻算法与数字孪生技术相结合,构建的车间设备运行状态预测模型,不仅能够实时采集、传输和处理车间设备运行数据,这些数据作为初始参数形成模型的训练集和测试集,而且能够较为真实和准确地预测设备运行状态,作为先验经验运用到车间设备实时调度决策中。
(2)能够促进传统车间的数字化转型。k-近邻算法属于简单的机器学习算法,但是在制造业企业生产车间的应用还很少。从简单机器学习算法的应用着手,可以证明人工智能技术在制造业企业中的应用具有了一定的成效。制造业企业可以更多地引入人工智能技术进行车间生产流程的改良,通过人工智能技术的应用和推广,从而促进企业的数字化转型。传感器参数、图像采集装置参数均可依据生产车间的具体情况进行灵活调整,对于数字孪生的应用也有经验可循,这也增加了企业数字化转型的信心。
本文所构建的模型虽然能够预测车间设备运行状态,但还存在一些欠缺的地方,进一步研究工作可以从以下几方面考虑:
第一,算法模型方面。k-近邻算法属于简单的机器学习算法,与当今人工智能算法发展阶段相差较远,未来可加入具备自我学习能力的算法进行设备运行状态预测。
第二,模型应用方面。本文提出的预测模型的构建背景为制造业企业的生产车间,所涉及的问题较为简单,可以将模型构建的背景拓展到复杂性更高的柔性车间设备运行状态预测问题中。
猜你喜欢
智能制造(2021年4期)2021-11-04
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小学生作文(低年级适用)(2019年5期)2019-07-26
小学生学习指导(中年级)(2018年11期)2018-11-29
中国交通信息化(2018年5期)2018-08-21
读友·少年文学(清雅版)(2018年12期)2018-04-04
农村农业农民·B版(2018年11期)2018-01-28
中国老区建设(2016年12期)2017-01-15
