
基于成分数据分析与模糊模式识别的古代玻璃种类鉴别
2024-03-18 05:13王保乾蒋剑军
科技创新与应用 2024年7期
王保乾,蒋剑军
(铜陵学院数学与计算机学院,安徽 铜陵 244061)
古代玻璃的发展,见证了古代丝绸之路各文明中心和民族的文化与技术交流。对于我国古代玻璃的早期研究主要从文化、艺术与历史的角度进行定性分析。较有代表性的是干福熹对“古代玻璃之路”的研究[1-2]。随着现代科学技术的发展,刘松等[3]运用便携式X 射线荧光光谱分析技术(portable X-ray fluorescence analytic Technology,PXRF)对古代玻璃文物进行定量分析,冯百龄[4]则在其研究中应用了数据库等技术。这些成果表明,数理分析方法在文物研究中的地位在逐渐提高。
由于古代玻璃极易受埋藏环境的影响而被侵蚀风化,在风化过程中内部元素与环境元素进行大量交换,导致其成分比例发生变化[5]。仅利用化学分析手段无法有效解决古代玻璃文物种类鉴别问题,路佳佳[6]提出了将主成分分析与logistic 回归等机器学习模型相结合,解决古代玻璃文物种类鉴别问题。但古代玻璃文物成分数据的特点是成分性,即各化学成分比例累加和为100%。这类具有定和约束的数据,统计学上称为“成分数据”[7]。同时定和约束使得成分变量之间具有明显的共线性,而且经典的统计方法都是在实数域进行的,所以经典的多元统计方法在古代玻璃文物种类鉴别中失效[8-13]。本文通过对古代玻璃文物成分数据进行对数比(Log-ratio)变换,引入模糊模式识别对未知种类的古代玻璃文物种类进行鉴别,克服经典多元统计方法对成分数据分析的不足,研究方法也为国内关于玻璃文物的研究提供了一种新思路。
1 成分数据
1.1 成分数据的概念
定义1 称数集
为D维成分数据空间,又称为单形空间,其中c是一个正常数,xi为成分数据中第i种组分。SD中的元素是D维行向量,但由于成分和为定值,所以是D-1 维向量空间。
由于成分数据的定和限制问题,成分数据分布在单形空间而不是整个欧式空间,使得经典的多元统计方法不能够直接应用于成分数据统计分析中[14]。主要有以下3 个问题。
1)数据的形态在单形空间与欧式空间上不同,需要建立两空间之间的映射进行解释。
2)成分数据原始方差结构的负偏性。
3)单形空间上数据分布单一。
为了解决这些问题,Aitchison[15]提出了非对称对数比(Asymmetric Log-ratio,ALR)变换和对称对数比(Centered Log-ratio,CLR)变换方法。李柱等[16]提出了等距对数比(Isometric log-ratio,ILR)变换方法。成分数据经过对数比变换将单形空间映射到欧式空间,消除了成分数据的协方差的负偏性,此时多元统计方法就可以应用于变换后的数据了[17]。
1.2 对数比变换
1.2.1 非对称对数比变换(ALR)
定义2 设x=[x1,x2,…,xD]为成分向量,令
称此变换为非对称对数比变换。显然,非对称对数比变换将成分数据变换为取值范围为全体实数的数据,这为模型的选择带来了极大的方便。但经过非对称对数比变换后变量维数降低,变量无法与原始变量一一对应,致使模型解释性不强。
1.2.2 对称对数比变换(CLR)
定义3 设x=[x1,x2,…,xD]为成分向量,令
称此变换为对称对数比变换。对称对数比变换相对于非对称对数比变换而言,映射到欧式空间中,能够较好地保留数据特征,变换后变量与原始变量一一对应,解释性强。对称对数比变换不能消除变量的完全相关性,但此时经典多元统计学模型可应用于变换后数据的分析。
1.2.3 等距对数比变换(ILR)
定义4 设x=[x1,x2,…,xD]为成分向量,令
称此变换为等距对数比变换。等距对数比变换克服了多重共线性问题,但变换后变量维数减小,变量无法与原始变量一一对应,模型解释性不强。
1.3 成分数据零值替换
由定义2、定义3 和定义4 易知成分数据中若含有零值,则会在对数比变换中做分母项,对数比变换将毫无意义。因此,对成分数据中零值的处理尤为重要。为了使对数比变换有意义,通常采用3 种非参数方法对零值进行替换。
1.3.1 真实零值与近似零值
真实零值是真正的零值,不是由于误差而产生的。近似零值是指由舍入产生或限于仪器精度,成分低于一定阈值就无法测得的零值。
1.3.2 加法替换法
式中:rj是替换后的相应组分的值(下同),j=1,2,…,D,Z是一组成分数据中零值的个数,δ 是小于给定阈值的数。
1.3.3 简单替换法
1.3.4 乘法替换法
式中:δj是用以替代xj的值,c是成分数据的定和。
2 模糊理论
2.1 隶属函数
模糊数学使用模糊集合来描述难以用传统集合进行精确刻画的概念,模糊集合则通过隶属函数来定义。
定义5 设U是论域,称映射
确定了U上的一个模糊子集A,映射μA称为A的隶属函数,μA(x)称为x对A的隶属程度。
从定义5 可知,模糊集合将经典集合论中元素与集合之间“属于或不属于”的二元关系扩展为了各种不同程度的隶属关系。
2.2 模糊集的运算
定义6 取大算子:a∨b=max(a,b),取小算子:a∧b=min(a,b)。
定义7 设有向量A=[a1,a2,…,an],若0≤ai≤1(i=1,2,…,n),则称A为模糊向量。
定义8 设A,B为模糊向量。称为A,B的内积;称为A,B的外积。
2.3 模糊正态分布隶属度函数
模糊正态分布隶属函数描述的模糊子集是最常用的模糊子集。
1)偏小型。
2)中间型。
3)偏大型。
2.4 格贴近度
定义9 设A,B是论域U上的2 个模糊子集,称
为A与B的格贴近度。
2.5 多特征模糊模式识别原则
设数据样本x由D(D≥1)个特征来描述,即x=[x1,x2,…,xD]。下面介绍基于模糊理论的x的识别方法。
基于贴近度的择近原则:论域U上有m个模糊子集:A1,A2,…,Am,其构成了一个标准模式库。若x与其中Ai0的格贴近度最大,则将x识别为模式Ai0。
古代玻璃文物风化时会和外界元素发生随机交换,这一元素交换过程是模糊的,风化程度同样也是模糊的。经典的模式识别算法难以解决模糊度较大的识别问题,于是基于模糊理论的模糊模式识别方法便应运而生。
3 实证分析
3.1 实证过程
3.1.1 数据获取与预处理
本文数据集来自全国大学生数学建模竞赛官网上公开的赛题数据[18]。本文将成分含量加和在85%~105%的视为有效数据,对于不在此范围内的15 号与17 号文物数据做剔除处理。通过阅读数据集,发现存在缺失值与零值。根据数据集的背景,本文认为缺失值是由于检测仪器精度问题而未检出,零值是由于舍入误差造成,即缺失值与零值都是近似零值。已知种类的数据是文物随机采样点的化学成分含量,而待识别数据是整个文物的化学成分含量。数据文物风化信息可用于区分分化与否,无须根据风化情况进行分组识别。
基于上述分析,对剔除无效数据的数据,没有严格符合定和约束的成分数据转化为定和约束,再进行近似零值替换。由于式(3)中乘法替换法可以保持在单形空间上的运算[19],经近似零值替换后不改变单形空间上的性质,更适合下一步的对数比变换。本文在根据式(3)对近似零值进行乘法替换时,设仪器最小检测限为ej,将数据中各成分的最小非零值视为最小检测限,并添加随机误差项。经研究发现δj取0.65ej时,可以最小化协方差矩阵的扭曲[20]。最后,分别使用3 种对数比方法对近似零值替换后的数据进行变换。
3.1.2 未知玻璃文物种类识别
本文建立基于贴近度的多特征择近原则模糊模式识别方法。在模糊模式识别中,利用隶属函数作为样本和模板的度量,能够较好地反映模式的整体特征,并且针对样品中的干扰、噪声具有很强的剔除能力[21-22]。主要有以下步骤。
步骤1:建立特征集。古代玻璃文物数据含有14个成分,即特征集含有14 个特征。
步骤2:确定结论集。结论集是由所有可能结果构成的集合,即结论集包含高钾玻璃与铅钡玻璃2 个元素。
步骤3:建立标准模式。特征集就是论域,结论集中的元素就是标准模式。根据成分数据特征,选取中间型模糊正态分布作为隶属函数。
步骤4:模式识别。根据定义9 和古代玻璃种类的模糊模式,以格贴近度度量与模糊模式的接近程度,待识别对象属于贴近度较大的模式。
3.2 实证结果
3.2.1 近似零值替换结果
经乘法替换法替换后的玻璃文物成分数据见表1和表2。
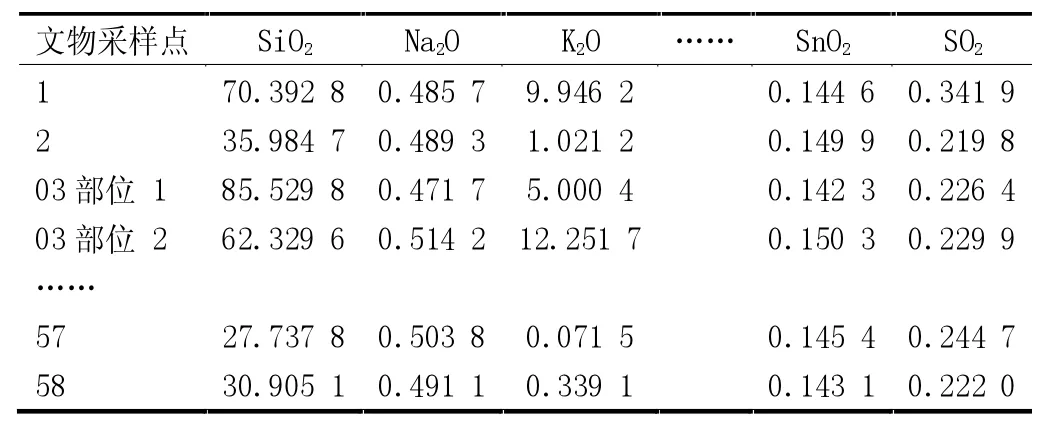
表1 已知种类玻璃成分数据零值替换(部分)
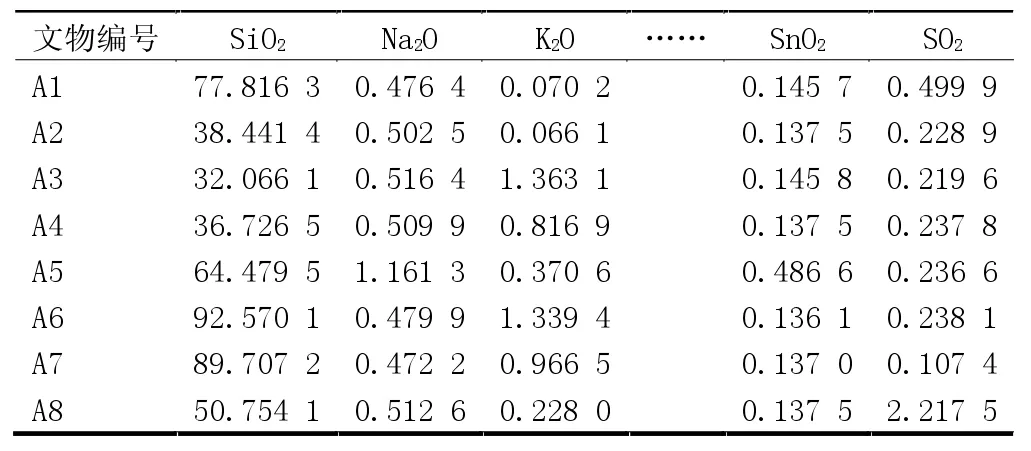
表2 待识别玻璃成分数据零值替换
通过分别对比表3 和表4,零值替换前后描述性统计结果,可以发现由近似零值替换引起的各项统计指标仅发生了微小的变化,数据特征基本不变。由此可以认为本文应用乘法替换法是合理的。

表4 待识别玻璃成分数据零值替换前后的描述性统计(部分)
3.2.2 3 种对数比变换结果
通过对数比变换将单形空间上的成分数据映射到欧式空间中,对数比变换后的取值范围是整个实数空间。根据定义2 和定义4 易知,非对称对数比变换与等距对数比变换使数据特征由14 维降低1 个维度到13维,无法与原始变量一一对应,表5 与表6 中特征含义难以解释,且两表中特征含义不同。

表5 已知种类玻璃成分数据非对称对数比变换(部分)
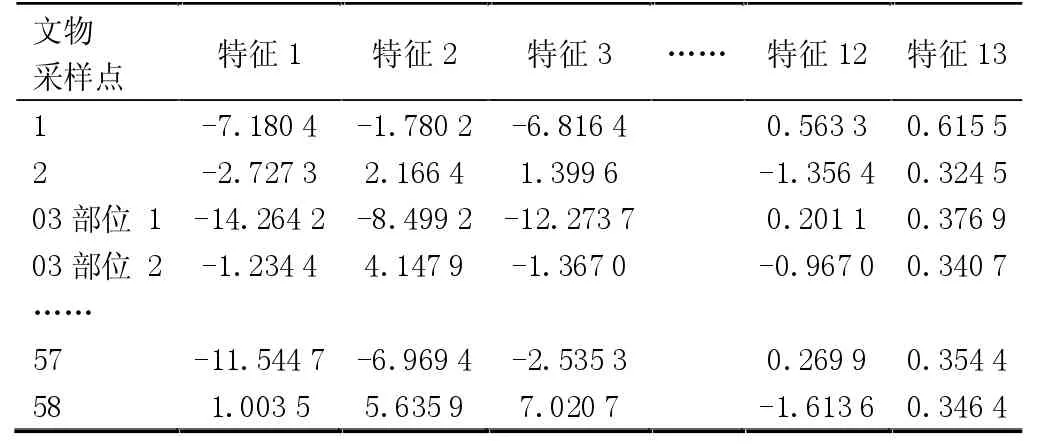
表6 已知种类玻璃成分数据等距对数比变换(部分)
3.2.3 模糊模式建立结果
如前所述,本文选取中间型模糊正态分布作为隶属函数。对称对数比变化下的2 种类型玻璃模糊正态分布函数曲线如图1 所示,同一子图中的2 条曲线差异越大,说明对应的特征在识别玻璃种类中越显著。因此,直观上氧化铅、氧化钡与氧化钾是对分类结果影响较为显著的特征。

图1 对称对数比变化下2 种类型玻璃的模糊正态隶属度函数
3.2.4 3 种对数比变换下的模糊模式识别
分别在3 种对数比变换下应用模糊模式识别模型,并采用交叉验证方法,计算出如表7 所示分类识别准确率。
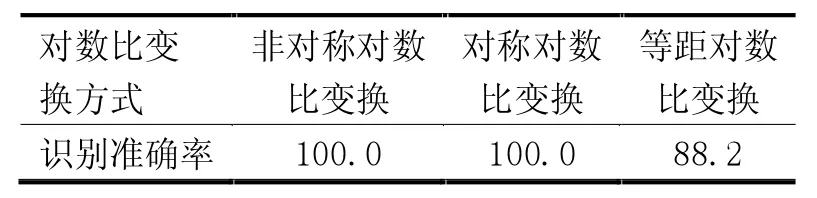
表7 识别准确率比较%
3.2.5 CLR 下模糊模式识别与机器学习对比
使用模糊模式识别方法对玻璃文物种类进行预测,同时引入随机森林算法和支持向量机算法,与基于对称对数比变换的模糊模式识别结果进行对比。通过交叉验证,得到模糊模式识别与随机森林的准确率为100%,支持向量机算法的准确率为97.6%。分类预测结果见表8。

表8 分类预测结果
4 结论
国内外对于古代玻璃的研究中应用数字化方法尚处于初始阶段,在一些研究中常常忽略数据的成分特性,存在一些方法滥用的情况,基于成分数据的古代玻璃文物分析鲜有涉及。从本文的研究来看,关于近似零值替换问题,加法替换法与小于阈值的数δ、维数D与零值个数Z有关;简单替换法与和定和c有关;乘法替换法δj的值不依赖于维数D与空值Z的个数,且保持了单形空间上的运算。选用乘法替换法不改变成分数据的性质,可以更好地应用对数比变换处理成分数据。
经对称对数比变换后,进一步对比模糊模式识别算法与随机森林、支持向量机算法分类准确率。以上3种方法对高维数据的处理都有着良好的效果,均取得了较高的分类准确率。但是随机森林与支持向量机运算较为复杂,训练时所需要的时间和空间很大。模糊模式识别的运算量较小,在运算速度较快的情况下仍能保持极高分类准确率。因此,模糊模式识别在解决古代玻璃分析问题时有着明显的优势。
基于成分数据的理论广泛应用于考古学、地质学与材料学等方面。在本文的研究中,根据数据的成分性特点合理地处理成分数据,使数据摆脱单形空间限制,使得经典的多元统计方法能应用于成分数据的分析。3种对数比转化下的模糊模式识别方法对于古代玻璃种类的鉴别具有良好的效果。其中,对称对数比变换下的模糊模式识别方法同时具备高分类准确率与较好的模型解释性。对数比变化下的模糊模式识别方法的分类效果与随机森林、支持向量机等机器学习算法相比也毫不逊色。本文为考古工作者的文物分类研究提供了一种新的简单快速且准确的方法。
猜你喜欢
数学物理学报(2022年2期)2022-04-26
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
无线电工程(2020年6期)2020-05-18
中学生数理化·高一版(2018年10期)2018-11-08
电脑爱好者(2018年2期)2018-01-31
电子测试(2017年23期)2017-04-04
智能系统学报(2017年5期)2017-01-22
智能系统学报(2015年3期)2015-01-29
电测与仪表(2014年6期)2014-04-04
