
中国社科期刊关联数据汇交与共享模式研究
2024-03-19 00:37魏啸天王晨阳周荣庭
中国科技期刊研究 2024年2期
■魏啸天 王晨阳 周荣庭 周 慎*
1)中国科学技术大学人文与社会科学学院,安徽省合肥市徽州大道1129号 230051
2)沉浸式媒体技术文化和旅游部重点实验室(安徽新华传媒股份有限公司),安徽省合肥市金寨路96号 230026
3)中国科学技术大学计算社会科学与融媒体研究所,安徽省合肥市徽州大道1129号 230051
随着数据密集型科研范式的兴起,社科研究愈加依赖对科学数据的搜集、处理与分析,科学数据逐渐成为贯穿社科研究全过程的核心要素之一[1-2]。社科研究数据的合理保存与管理能够良好地反映科研过程的完整性,有助于提高科研透明度与规范性,提升作者思想表达的完整性和抵达度,降低数据造假等学术不端风险事件的发生概率[3-4]。我国正在不断加强期刊论文关联数据管理和开放共享工作。2022年,中国科协办公厅及中国科学院办公厅联合发布《关于组织开展期刊论文关联数据汇交工作的通知》(以下简称《通知》),要求作者在向国内科技期刊投稿时汇交科研过程中涉及的非敏感、非涉密原始数据及其衍生数据,以确保论文关联数据保存准确、完整,做到科学数据可查询、可回溯[5]。在自然科学、工程技术科学等领域,我国科技期刊对关联数据汇交和共享开展了有益的探索[6-8],但社科领域相关工作仍处于起步阶段[3,9],仅有部分学者对我国人文社科科学数据汇交、管理与共享的现状进行分析[10-11],尚未在借鉴国际经验的基础上,提出符合我国国情、社科研究特点、成体系的期刊论文关联数据汇交与共享模式。本文将在此方面发力,以期为我国社科期刊开展关联数据汇交和共享工作提供参考。
1 研究对象与研究方法
当前主流的科研数据共享包括3类:一是不依赖出版物的独立数据共享,即在数据中心、数据存储平台存储发布数据,如在国外的figshare、Open Science Framework、UK Data Service等,以及我国的国家科学数据中心、中国科学院科学数据库等数据中心(数据存储平台)发布和共享的数据[12];二是附属于出版物的数据共享,即将数据作为出版物(论文)的附属或辅助材料予以共享,本研究所探讨的即为此类数据共享;三是作为出版物本身的数据出版,主要代表形式是数据论文,如在《中国科学数据(中英文网络版)》、ScientificData等数据期刊和其他期刊出版的数据论文[13-14]。
借鉴先前学者的研究方法[13,15],采用“专家咨询+文献梳理+网络调研”的方式进行研究,以确保尽可能全面地梳理国内外社会科学期刊关联数据汇交与共享的模式。通过专家建议、综合调研梳理和模拟投稿,发现国外社会科学期刊通常遵循所属出版社的数据共享规定,为此选择Elsevier、Springer Nature、Wiley、Taylor & Francis、SAGE等国外主流出版社作为研究对象。在国内期刊选择方面,选择《中国工业经济》《数量经济技术经济研究》《中国经济学》这3种执行数据共享的期刊作为研究对象。通过全面梳理上述出版社、期刊的数据政策、数据汇交要求等资料,分析其论文关联数据汇交与共享的流程与要素。
2 国内外社科期刊论文关联数据汇交与共享的流程与要素对比
期刊论文关联数据汇交与出版的基本流程(图1)涉及数据定义、数据描述、数据汇交、数据保存、数据审核、数据出版、数据引用和复用等要素(表1)。

表1 期刊论文关联数据汇交与共享的关键要素
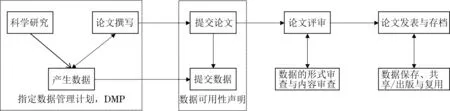
图1 期刊论文关联数据汇交与出版的基本流程
(1)数据定义。调研的国外出版社和国内期刊对论文关联数据具有一致定义,即数据并非简单数字意义上的“数据”,而是支撑论文发现的所有元数据、过程数据和支撑工具。具体而言,论文涉及的原始或处理过的数据文件、软件、代码、模型、算法、协议、研究方法等均属于关联数据的范畴。但国内外定义也略有区别,如Elsevier将作为论文正文的某一部分而提交和发表的数据或其他材料排除在关联数据之外,而《数量经济技术经济研究》《中国经济学》等将因刊文篇幅所限而省略的内容也作为关联数据的一部分。可能原因在于,SCI、SSCI收录期刊通常将该内容置于“补充材料”(Supplementary Materials、Appendix)之中,而国内期刊将关联材料等视为“附录”材料的一部分。
(2)数据汇交与共享政策类型。数据共享许可条件指允许其他研究者通过何种协议和渠道使用数据。在此方面,国外主要出版社均制定了详细的共享政策等级,通常分为4类或5类,如Springer Nature的数据政策等级包括4类,Elsevier、Taylor & Francis、SAGE等分为5类。数据汇交的要求也随数据政策等级而异,Wiley出版社对4类数据政策等级中的数据可用性声明、数据共享、数据的同行评审要求等作了明确的区分和规定,其中,类型2和类型3是Wiley旗下期刊普遍采用的数据政策(表2)。国内3种期刊则为鼓励共享或强制共享,未制定更具针对性的细分等级。对于敏感数据,国外出版社均规定可不共享,但鼓励作者尽可能将数据存放在资源库中,并通过对数据进行匿名处理、设置可控的访问限制、使用可信研究环境或数据安全平台、共享元数据并对过程数据进行脱敏处理等方式最大限度地共享数据。国内期刊也有类似规定,如《数量经济技术经济研究》规定,若因原始数据涉密或其他原因不宜公开,请告知编辑部并提供中间环节数据或提供经过一定的技术处理后的数据,以及详细的描述性统计等信息。

表2 Wiley出版机构数据政策等级及汇交要求
(3)数据存储和共享平台。国外出版社均向作者推荐了一批适合期刊关联数据的存储库,并在其发布的数据政策中提供了推荐列表,包括figshare、Open Science Framework、UK Data Service、Harvard Dataverse、Zenodo、FAIRsharing、4TU.ResearchData等。在此基础上,各出版机构还推荐了针对性的数据平台,如Springer Nature推荐社科领域的数据存储于Open Science Framework、UK Data Service、Harvard Dataverse等平台。SAGE推荐作者使用Code Ocean平台,该平台支持多种编程语言,作者可便捷地共享研究所用的代码,并获得代码和数据的数字对象唯一标识符(Digital Object Unique Identifier,DOI),评审专家和其他人可通过该平台审核并复现代码的结果。Elsevier向作者提供Hivebench平台,通过其内置的文本编辑器,作者可以随时添加或更新实验内容和结果,便于同行评审和共享过程数据。国内3种期刊规定将数据在期刊官网、微信公众号、中国知网进行存储和共享,未向作者提供或推荐数据存储平台、数据中心。鉴于数据存储平台、数据中心的专业性、通用性、安全性,建议我国社科期刊依托专业的数据仓储库,如中国科学院计算机网络信息中心自主研发的Science Data Bank(科学数据银行,又称Science DB),提升论文关联数据的可发现性、可引用性与可重复使用能力,提高数据存储质量。
(4)数据共享规范和可用性声明。数据共享规范旨在告知作者以何种标准规范撰写和提交稿件及关联数据。国外出版社和国内期刊均在“投稿指南”中对数据共享规范作了明确规定,要求作者以此进行排版和投稿。Wiley还开发了“作者合规工具”(Author Compliance Tool),便于作者以符合期刊要求的范式共享数据。数据可用性声明旨在明确告知读者论文的关联数据可在何处获得,可在什么条件下获得,某些期刊还要求附上数据集链接。国外出版社均明确规定了数据可用性声明的撰写要求,如Wiley规定作者须以“支持本研究结果的数据可在[资源库名称(如figshare)中公开获取],网址为http://doi.org/[doi],参考号为[参考号]”的标准形式撰写数据可用性声明。国内期刊在数据可用性声明方面缺乏规范性,3种期刊的印刷版论文中均无数据可用性声明。
(5)数据标识、共享协议和复用要求。国外出版机构均为数据提供DOI,以确保数据的唯一标识性、可访问性、可发现性和可引用性。在数据共享方面,出版机构均遵循国际主流的开放许可协议,作者可选择相应的协议来共享研究数据。Elsevier等出版机构建议作者使用CC BY 4.0协议①CC BY 4.0(Creative Commons Attribution 4.0 International License)协议又称创意共享协议,即任何人都可以自由分发、传播、修改本创作,但必须保留创作人对原作品的署名,且不得增加额外限制。,以最大限度共享其数据。在数据的引用和复用方面,国外出版机构均规定了明确的引用格式,如Springer Nature要求作者使用DataCite推荐的最低限度信息格式即“数据集创建者、数据集标题、出版商[资源库]、出版年、标识符[如DOI、Handle或ARK]”引用或复用数据。国内3种期刊均未给数据提供DOI,未明确共享协议,仅规定了数据复用时的推荐引用格式。
(6)数据的同行评审和审核。数据审核包括形式审核和内容审核两方面。在形式审核方面,除《中国工业经济》外,国内外调研对象均要求编辑在初审环节即审核作者提交的关联数据,包括数据是否形式完整,是否符合期刊的格式要求,是否提供所要求的文本、图表、工具、代码等。在内容审核方面,国外出版社会根据数据共享政策,决定审稿人是否对数据进行内容审核。如Wiley出版社对于类型1~3的数据,不强制要求审稿人进行内容审核,对于类型4则要求强制共享数据,并且数据须经同行评审(表2)。具体而言,对类型4的数据,审稿人要对关联数据的质量及是否可复制进行审核。审核数据质量包括关联数据与论文呈现的结果是否一致(如工具是否一致、样本量是否匹配、研究方法是否匹配等);审核是否可复制包括数据获取是否与数据可用性声明的描述匹配、支撑性工具和代码是否一并汇交、数据是否可供同行复现、数据是否可供引用和复用等。建议我国社科期刊在制定详细、具体的数据共享政策的基础上,分类对数据进行形式审核和内容审核。
3 我国社科期刊数据汇交与共享的可行模式探索
3.1 我国社科期刊关联数据汇交与共享的建议
通过对国外学术期刊数据汇交与共享政策的梳理和对比,结合我国社科期刊研究论文特点,对构建我国社科期刊关联数据汇交与共享模式提出如下建议。
3.1.1 扩大关联数据的定义范围
随着数据密集型研究范式的兴起,社科知识的发现与创造更多地建立在对世界的数据化感知及基于研究问题的数据收集、汇总、处理与分析之上。社科研究的特殊之处在于研究者对社会的观察、感知会产生许多感性材料或感性数据,这种数据不仅仅是“数字”意义上的“数据”,而是更多地以多模态形式存在,包括文本、图像、视频、音频等。这些数据本质上也是社科数据的一部分,都是对客观世界的描述,具有更强的建构性和发散性。此外,在技术的推动下,人工智能生成内容(Artificial Intelligence Generated Content,AIGC)将影响人们对于社会信息环境的思维方式与认知行为[16]。社科研究中研究者观察、感知社会产生的感性材料,如研究起因与研究思路,将会受到生成式人工智能的影响。因此,研究者与生成式人工智能交互所产生的内容也是社科期刊关联数据汇交与共享的特殊部分。
建议我国社科期刊在制定关联数据汇交和共享的相关政策中,扩大关联数据的定义范围,鼓励研究者汇交和共享多模态的感性材料和感性数据。如此,其他研究者能够将相关数据加工或处理成超越原始论文的、具有其他角度或层面的有价值、有意义的信息,再通过进一步的分析与提炼,得到认识主体对一般事物的存在方式和运动状态、变化规律的抽象化描述的知识,实现数据的再建构和再利用。
3.1.2 划分契合社科研究特色的关联数据汇交与共享政策类型
期刊编辑部作为期刊论文关联数据汇交与共享工作的具体实施者,应及时制定并广泛宣传其数据汇交与共享政策,写明数据服务平台的使用方法,以及汇交数据的类型与要求。根据我国社科领域研究现状,建议将关联数据的汇交与共享程度从低到高分为6类:类型1,数据汇交与共享不适用,即研究没有数据,或文章完全是理论研究;类型2,鼓励数据共享与数据引用,作者可选择是否提供数据可用性声明;类型3,期望数据共享与数据引用,必须提供数据可用性声明;类型4,强制数据共享与数据引用,必须提供数据可用性声明;类型5,在类型4的基础上,强制要求作者进行数据汇交,且数据需通过同行评审;类型6,强制数据汇交与引用,必须提交数据可用性声明。论文关联数据存在高度敏感性,或有损道德与法律标准,作者可不共享数据或设置可控的访问限制,但需要汇交数据至编辑部,并通过同行评审。根据Springer Nature、Elsevier、SAGE等出版社的规定[17-19],结合现阶段我国社科期刊的刊文类型,大多数期刊适用于类型1~3,经济管理等领域涉及经济活动规律、行为研究及预测研究的论文适用于类型4,心理学领域涉及脑科学研究的论文适用于类型5和类型6。
3.1.3 引入多模态关联数据的汇交与审核方法
针对社科领域关联数据的多模态特性,建议社科期刊在数据汇交与审核流程中引入多模态大语言模型(Multi-model Large Language Model,MLLM)辅助方法。MLLM通常以大语言模型为基础,通过融入其他非文本的模态信息完成各种多模态任务。其支持多模态输入,研究者可以通过更为灵活的方式输入和上传研究中的非文本信息。在数据的形式审核中,MLLM能够识别汇交数据的类型、格式,检测汇交数据的完整性、可访问性,以及是否提交数据可用性声明,减轻编辑负担。在数据的内容审核中,MLLM能够快速理解和描述非文本数据中的信息,总结汇交数据与研究论文的相关性,节约外审专家的审稿时间和精力[20]。
3.1.4 明确数据共享规范
一方面,期刊编辑部可提供标准的数据可用性声明范本。数据可用性声明应包含如下内容:若数据适用于共享,应明确数据的获取、处理与存储方式,访问链接,数据的唯一标识符,打开或使用数据的软件或工具名称等;若数据不宜共享或存在访问限制,作者应写明不宜共享的原因,例如数据共享受第三方限制、数据为敏感数据等。另一方面,建议期刊编辑部在规定数据复用推荐引用格式的同时,为共享的关联数据提供DOI,并明确共享协议。
3.2 我国社科期刊关联数据汇交与共享的可能性模式
综上所述,本文构建出我国社科期刊关联数据汇交与共享的可能性模式(图2),该模式包括以下环节。
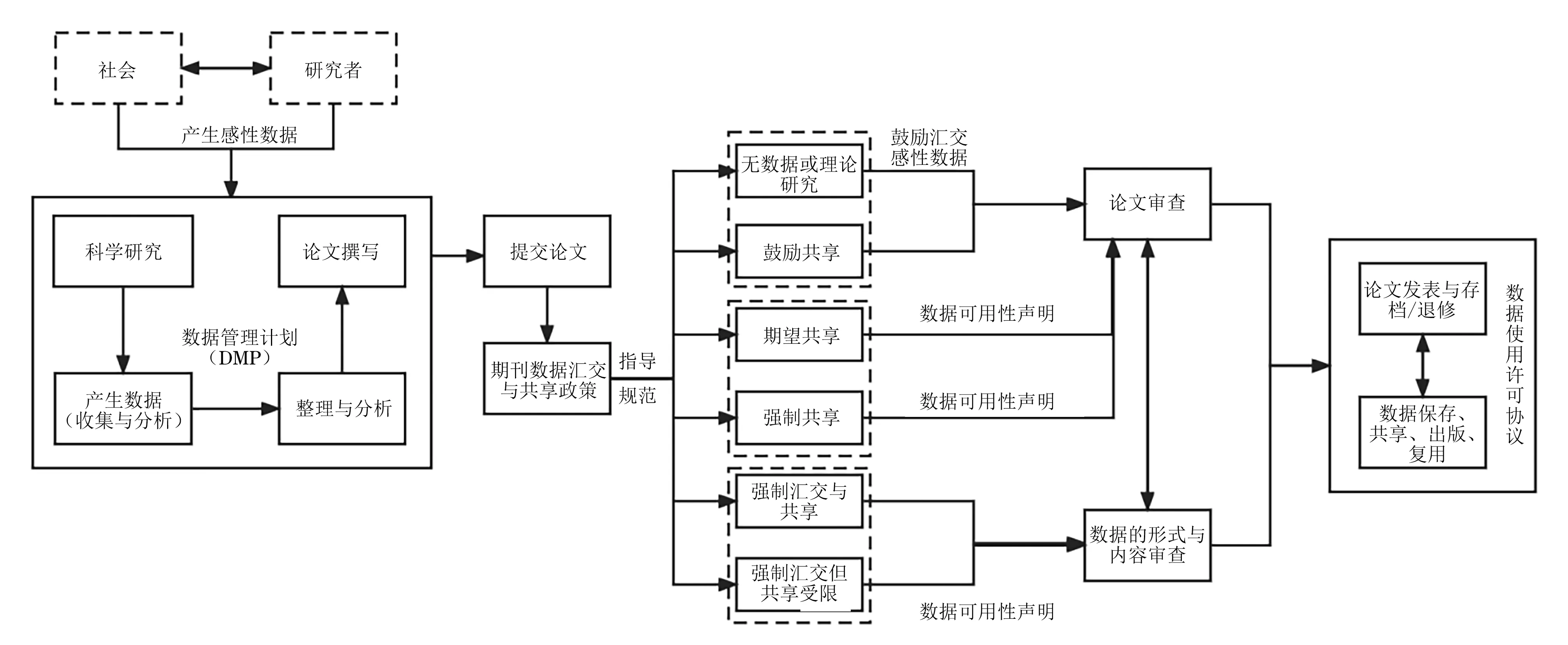
图2 社科期刊关联数据汇交与共享基本流程
(1)数据生成、管理与汇交。研究者通过与世界的互动产生感性数据,并开始科学研究。在研究过程中,论文作者应制定数据管理计划,包括对原始数据、过程数据、衍生数据、代码、多模态信息等进行适当的保存与管理,规范数据文件格式,依照投稿期刊的关联数据汇交与共享政策,明确关联数据汇交与共享的类型,进行数据汇交。
(2)数据的形式审核。责任编辑应在论文初审、初校阶段完成对数据的形式审核,主要包括审核数据是否已上传、数据格式是否正确、上传数据是否可访问、数据可用性声明是否已提交等。
(3)数据的内容审核。外审专家作为论文质量的把关人,应审核所提交数据的完整性、真实性、准确性、科学价值、与论文的关联性等。对于涉及隐私、涉密的数据,外审专家应及时联系责任编辑,要求作者提供证明材料,并依照相关法律法规、学术与行业规范等要求进行审核。
(4)数据的共享与复用。作者或编辑部应同步将数据上传至公开数据库或数据平台,作者应在我国法律框架与科学伦理的道德规范下,与数据平台共同签订数据使用许可协议,并允许期刊和其他研究者依照数据可用性声明和许可协议数据进行传播和再利用。期刊编辑部应为共享的关联数据提供DOI,并明确共享协议,以及做好服务平台上作者共享数据的管理和监测等工作。
4 结语
《关于推动学术期刊繁荣发展的意见》《国家“十四五”时期哲学社会科学发展规划》等政策文件明确提出,要坚持追求卓越、创新发展,打造一批世界一流、代表国家学术水平的社科名刊,为社科学术期刊高质量发展提供管理保证。随着我国论文关联数据与汇交相关工作的落实和深入,社科期刊应以构建关联数据汇交与共享机制为抓手,完善期刊学术诚信控制机制,进而推动我国社科期刊卓越发展。本研究为我国社科期刊关联数据与汇交构建了一个符合我国国情、社科研究特点、成体系的可能性模式,从数据生成、管理与汇交,数据形式审核,内容审核,数据共享与复用4个环节规范了社科期刊关联数据汇交与共享的全流程。
本文的不足之处在于:(1)数据汇交与共享类型还需斟酌。因社科各领域期刊对于论文关联数据的定义和要求不同,本文仅对关联数据汇交与共享的类型进行了大致划分,并未进行详细探讨。(2)关联数据审核流程有待辨析。结构化数据与非结构化数据的形式审核和内容审核的区别很大,后续应进一步分析数据的审核方法与规范。(3)我国社科期刊开放共享与知识获取体系建构的内容不足。本文仅借鉴国际经验对我国社科期刊关联数据汇交与共享模式进行构建,并未考虑我国学术期刊出版体系与国外出版发行体系的不同,后续应继续开展更有针对性的研究。
猜你喜欢
包装工程(2023年24期)2023-12-27
山西高等学校社会科学学报(2022年10期)2022-10-25
新世纪智能(数学备考)(2021年9期)2021-11-24
山西高等学校社会科学学报(2021年7期)2021-07-30
海洋信息技术与应用(2021年1期)2021-06-11
山西高等学校社会科学学报(2021年4期)2021-04-30
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
全国新书目(2016年5期)2016-06-08
