
医疗领域对话系统口语理解综述
2024-03-26 02:39任芳慧郭熙铜杨锦锋
中文信息学报 2024年1期
任芳慧,郭熙铜,彭 昕,杨锦锋,3
(1.哈尔滨工业大学 经济与管理学院,黑龙江 哈尔滨 150001;2. 宁波市中医药研究院,浙江 宁波 315000;3.哈尔滨理工大学 计算机科学与技术学院,黑龙江 哈尔滨 150080)
0 引言
作为任务型对话系统(Task-oriented Dialogue System, TOD)的重要组成部分,口语理解(Spoken Language Understanding,SLU)负责接收用户的语音或文本作为输入,并解析出用户的意图。广义的口语理解等同于自然语言理解,即不仅局限于口头语,还包括对书面语的理解。而狭义的口语理解则只针对日常口头交谈时所使用的语言(Spoken Language)。口语重在表意,主要关注音韵、语法、语义和语用。与之相对的,书面语对拼写正确和可读性有更高的要求。受限于环境和设备,以音频形式存在的口语还可能掺杂环境噪声。因此,相较于书面语,口语往往有模糊性强、噪声多、注重表意而轻逻辑等特点,不可以简单地套用对书面语的理解来解决。
与此同时,随着移动互联网的普及,在线医疗咨询蓬勃发展。它不仅具有成本低、更加便捷的特点,还可以有效解决医疗资源不均衡的问题。目前在线医疗的开展方式大多为医患对话,即患者向医生描述自己的症状,医生进行问诊和解答。毫无疑问,口语理解的引入可以提高这一过程的效率。此外,随着智慧医疗的不断推广,借助人工智能技术的智能导诊、预检分诊等场景同样需要对患者的口语进行理解,从而识别出患者的意图和症状。因此,医疗领域的口语理解具备较大的发展潜力。
目前领域内对医疗口语理解的综述研究还很少,大多并未对口语和书面语加以区分,且所述技术稍有滞后。故本文对医疗口语理解进行了较为全面的综述,比对了其与通用领域口语理解的区别,并重点阐述如何在大模型的背景下开展相关研究,以期对智慧医疗领域做出贡献。
本文的组织结构如下: 引言部分介绍医疗口语理解的研究背景和重要意义;第1节对通用领域的口语理解问题进行阐述,并介绍常用数据集、评价指标和模型;第2节对医疗领域口语理解进行介绍,重点说明其与一般口语理解问题的区别,以及研究的难点所在;第3节则重点探讨医疗口语理解的研究现状及存在的不足之处;第4节讨论未来研究方向,特别是如何利用大模型的能力助推医疗口语理解研究;最后第5节进行总结与展望。
1 口语理解任务简介
一般被认为,任务型对话系统包含口语理解、对话管理(Dialogue Management)和自然语言生成(Natural Language Generation)三大模块。如图1所示,任务型对话系统的对话过程如下: 经过口语理解模块,用户的语言会被转换为对话行为四元组,即“领域-意图-槽位-槽值”(Domain-Intent-Slot-Value)的形式。对话管理模块将对话行为解析为对话状态,并通过对话策略的制定,得到系统行为(System Act)。自然语言生成模块则将其转化为自然语言进行输出。毫无疑问,作为整个TOD的开端,口语理解任务的性能影响着TOD的整体性能。
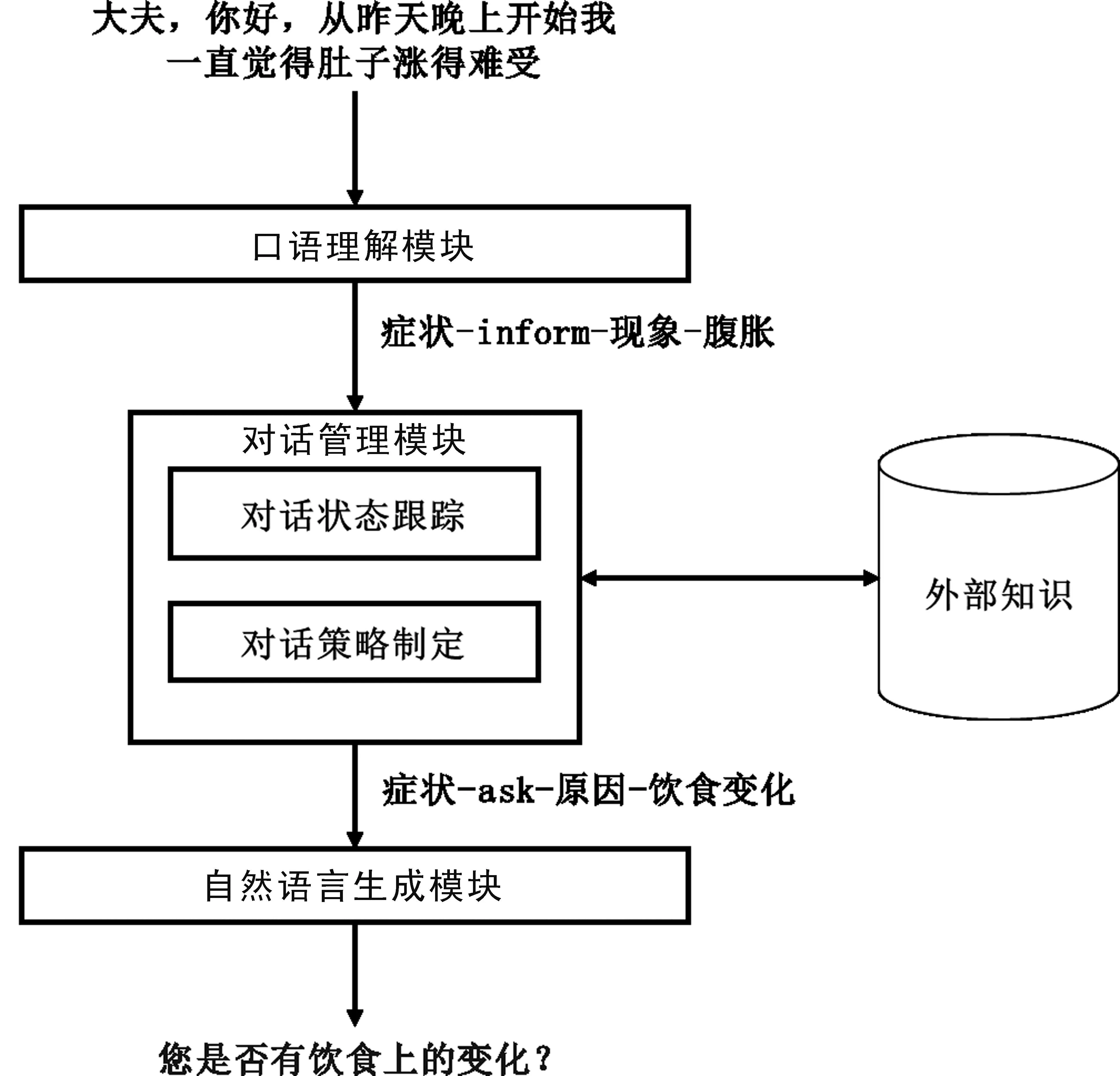
图1 任务型对话系统流程图
1.1 问题定义
为了预测“Domain-Intent-Slot-Value”四元组,口语理解任务可以被分解为领域分类(Domain Classification,DC)、意图识别(Intent Detection,ID)和槽位填充(Slot Filling,SF)三个子任务。
(1) 领域分类: TOD往往面向某个或某些特定的领域而设计。对于多领域问题,若将口语音频或口语文本经过编码后形成的序列记作S=(e1,e2,…,en),领域分类任务旨在预测出序列S所涉及的领域,故形式化定义如式(1)所示。
Domain=Classification(S)
(1)
(2) 意图识别: 由于一句话中可能包含多个意图,意图识别任务通常采用多个二分类器或多标签分类实现,故形式化定义如式(2)、式(3)所示。
(3) 槽位填充: 槽位(Slot)通常有告知型(Inform)和问询型(Request)之分。对于告知型槽位,其槽值往往来自于对话内容,可以通过预测序列的BIO标注来定位槽位和槽值,如图2所示。与之相反,问询型槽位表示用户向对话系统寻求信息(如某餐厅的电话号码),因而无法从用户输入中提取信息,对应槽值通常为空。
对Inform型槽位的预测可通过序列标注任务实现。给定输入序列,槽位填充任务返回标签序列L=(l1,l2,…,ln)。
L=Sequence-label(S)
(4)
对Request型槽位的预测则可以转换为分类任务实现。
Slot=Classification(S)
(5)
1.2 常用数据集和评价指标
口语理解领域较为常用的数据集有ATIS[1]、SNIPS[2]、FSC[3]、SLURP[4]以及中文数据集CATSLU[5]。此外,对话状态跟踪任务中的经典数据集DSTC2[6]、DSTC10[7]也是基于口语而非书面语构造的。
然而,与书面语数据集MultiWOZ[8]、CrossWOZ[9]、DSTC8[10]、NLU++[11]等相比,上述数据集在数量和质量上都相差甚远,如表1、表2 所示。不过,近期有些工作充分调研了口语对话的特点,并制作了较大规模的数据集[12],感兴趣的读者可以查阅相关文献。
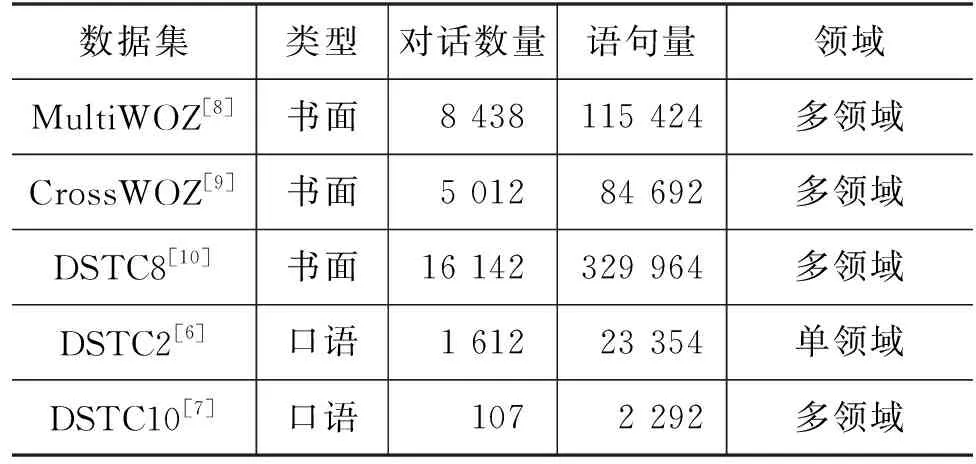
表1 对话数据集对比
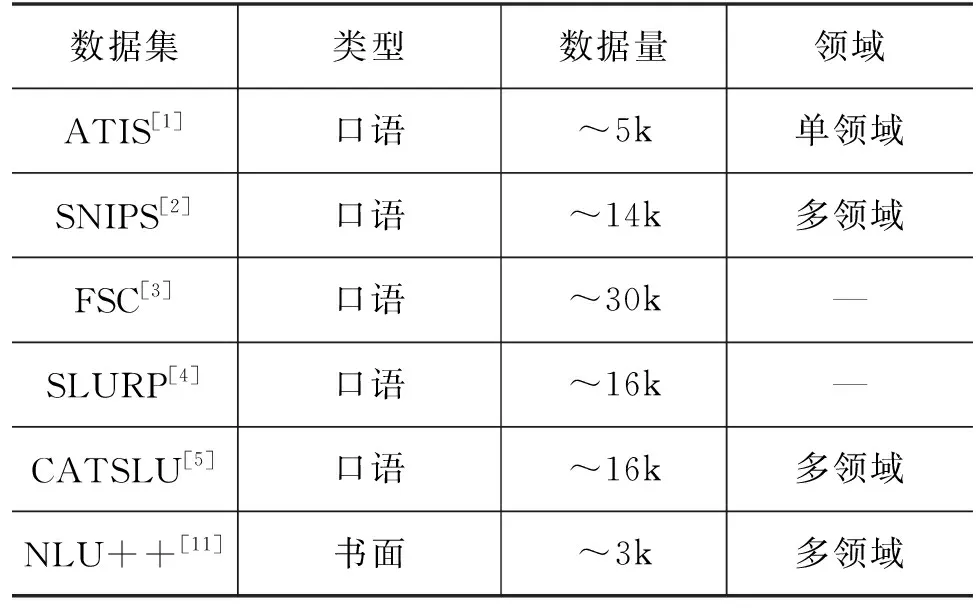
表2 口语理解数据集对比
在评价指标上,针对“Domain-Intent-Slot-Value”四元组的预测,口语理解任务重点关注意图准确率(Intent Accuracy)和整体准确率(Overall Accuracy)。前者仅关心意图的预测是否正确,而后者则需要将领域、意图、槽位和槽值全部预测正确。此外,F1值也常被用于评估模型性能。
根据Bastianelli等的观点[4],上述评估方法存在如下弊端: 当语音辨识出现错误时,所预测的槽值会与真实标签不同。面对这种情况,“一刀切”地将其记为预测错误显然是不合理的。因此,改进评估准则SLU-F1被提出: 它不会过度惩罚由自动语音识别所引起的不对齐,并可以同时捕获语音转换的质量和实体标注的质量。
此外,现有评价指标未能考虑到同义词带来的误判,因而在使用大模型实现口语理解任务时,需要对标签进行调整,从而减少第一类错误的发生。
1.3 模型分类
本节将口语理解模型分为三大类,分别是流水线式(Pipeline)、端到端式(E2E)和生成式大模型(Generative LLM),如图3和表3所示。
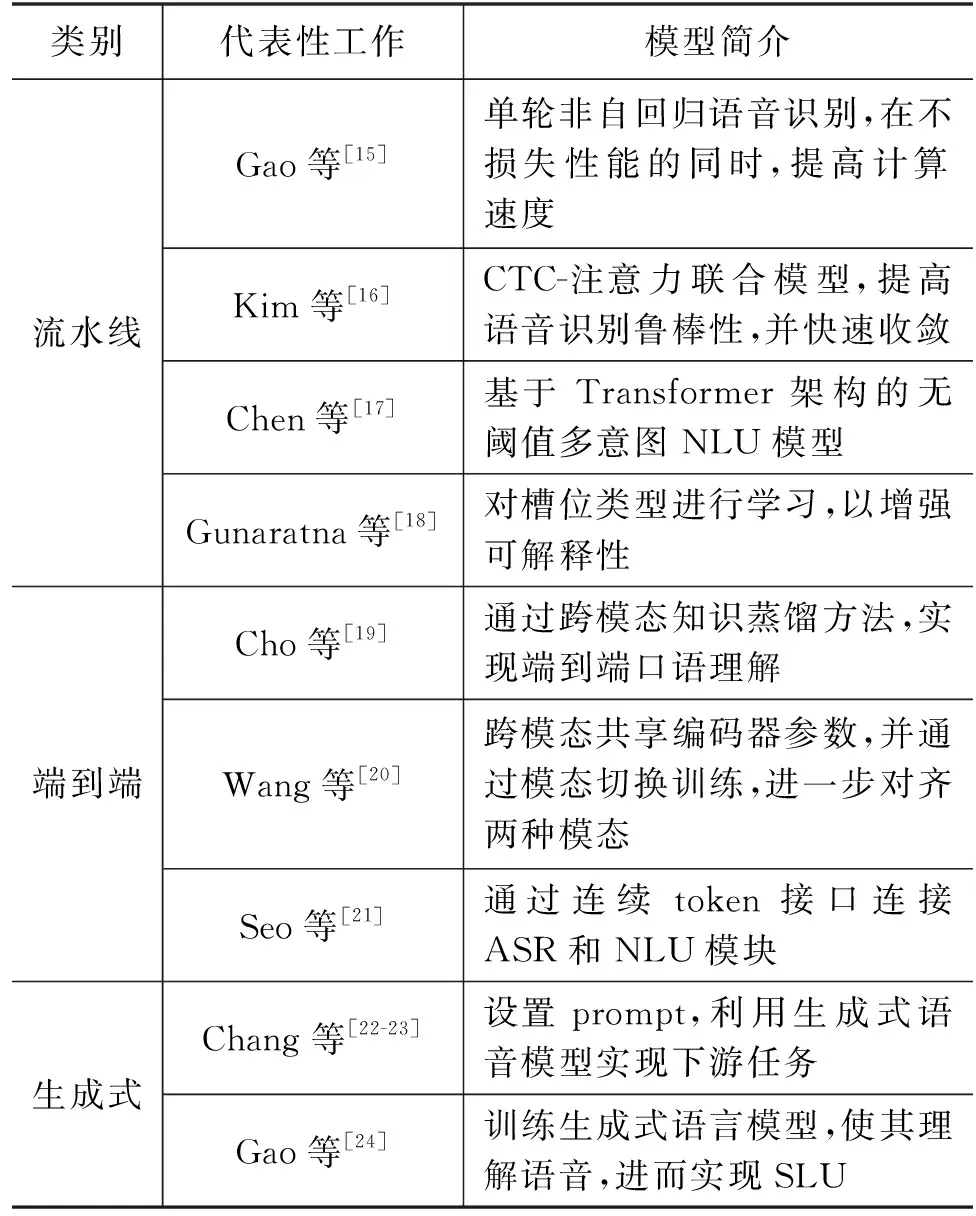
表3 口语理解代表性工作的分类梳理
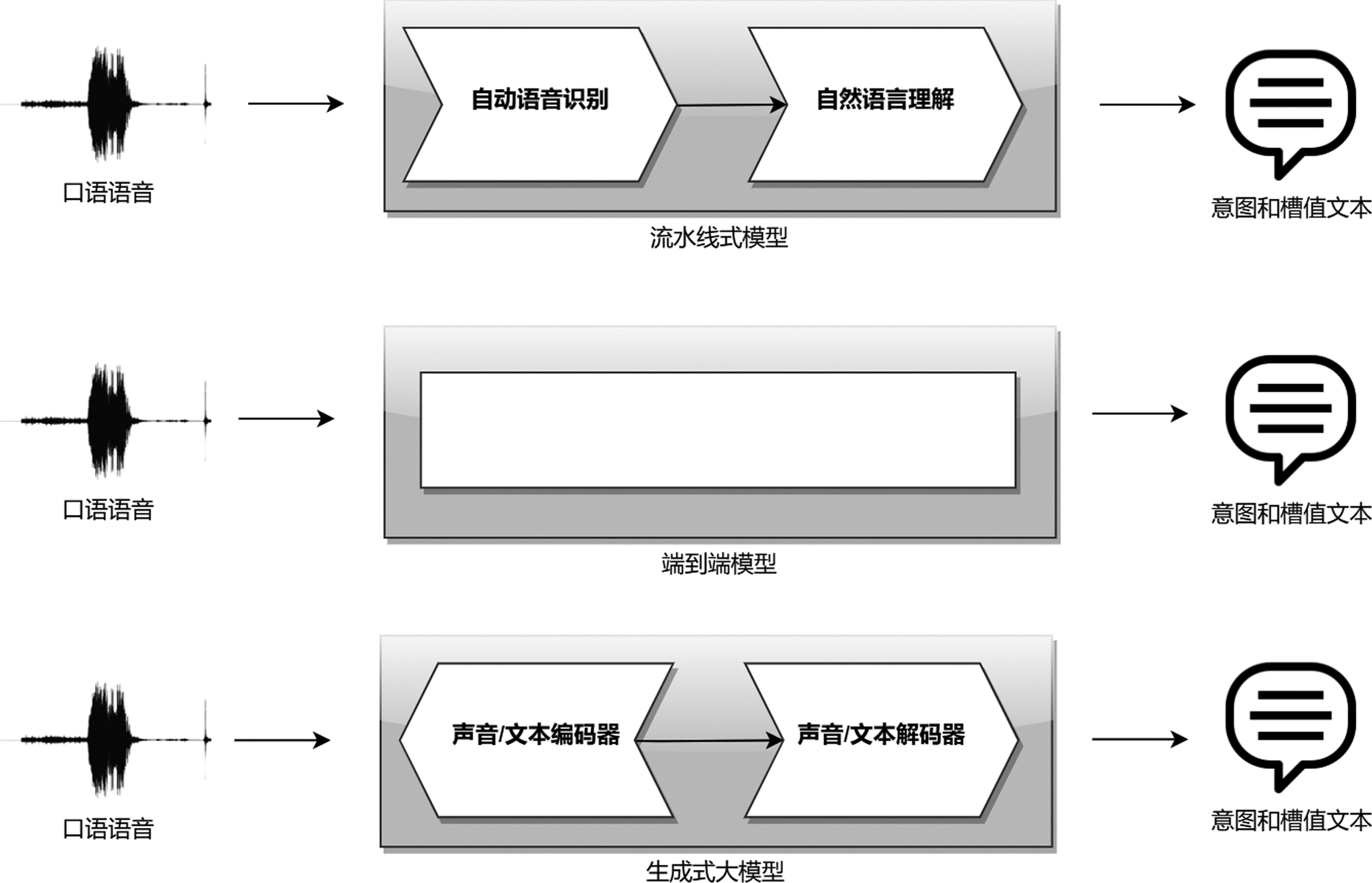
图3 模型分类
(1)流水线式: 模型接收语音作为输入,通过自动语音识别(Automatic Speech Recognition,ASR)模块将其转化为文字,并借助对书面语的理解预测出“领域-意图-槽位-槽值”四元组。
不过,由于语音信号的高维可变性,在缺乏大量训练数据的情况下,完成自动语音识别中的“波形→音素→语素→单词→概念→意义”的过程是极为困难的[3]。尽管低资源语音识别领域涌现出了许多优秀的工作[13-14],但这一局限性还是影响了流水线式口语理解的发展。
此外,尽管流水线式架构具备更强的可解释性,但它依然存在三个主要问题: ①语音信号的特性给ASR模块带来了不小的挑战,而这一阶段的错误会造成口语理解整体性能的降低。②由于语音识别和文本理解分开训练时的损失函数不同,单一模块的性能提高并不意味着系统整体性能提高。③误差会在不同模块间传递和累积,从而影响系统整体精度。为了解决这些问题,端到端架构应运而生。
(2)端到端式: 模型从声音信号中直接预测领域、意图和槽位槽值,无需显式生成文本。根据Lugosch等的研究,端到端范式具有如下优点: ①可以直接优化最终的评价目标,如意图识别准确性;②无需显式生成文本,从而避免中间步骤出错;③某些与意图识别相关的特征(如韵律)仅存在于语音中,端到端范式有助于充分利用这些特征[3]。
Serdyuk等首次探索从音频特征直接训练口语理解模型的可能性[25]。随后,预训练范式逐渐被引入端到端口语理解。根据Seo等的研究[21],基于预训练的端到端模型可以分成知识蒸馏、跨模态共享编码、带接口的网络集成三大类。随着GPT等生成式语言模型的兴起,口语理解领域有了新的研究范式,即依托生成式大模型实现意图识别、槽位填充等任务。
(3)生成式大模型: 区别于普通的端到端架构,口语理解任务可以采用生成式大模型的范式加以解决。类似于文本领域的GPT基础模型[26],语音领域也有自己的生成式大模型GSLM[27]和pGSLM[28]。结合文本领域的提示微调(Prompt Tuning)方法,Chang等对生成式语音模型做了进一步扩展,提出了SpeechPrompt[22]和SpeechPrompt v2[23],在意图识别、口音检测等分类任务和槽位填充、自动语音识别等序列生成任务上均取得了不错的表现。
除了基于无文本的生成式语音模型外,还可以利用文本领域的生成式语言模型来完成口语理解。例如,Gao等提出了一个框架WAVPROMPT,通过将语音转换为语言模型可以理解的形式,并设置相应提示,利用开源生成式大语言模型GPT-2的少样本学习能力(Few-shot Learning)来完成口语理解任务[24]。
2 医疗口语理解概述
2.1 医疗领域任务型对话系统的难点
前文介绍了通用领域任务型对话系统及其口语理解任务,第2节则重点阐述医疗领域对话系统研究的难点,并进一步解释医疗SLU所面临的挑战。与通用领域对话系统相比,医疗健康领域对话系统的研究仍处于萌芽期[29]。医疗TOD具备如下难点:
(1) 从数据集角度,通用领域数据集一般采用众包方式人工构建,而医疗数据集则大多来源于网站数据的爬取。具体地,通用领域数据集大多基于人-人对话(Human-to-Human, H2H)或人-机对话(Human-to-Machine, H2M)的方式构建。然而,受限于医疗领域的专业性,人工构建大规模数据集的方法实现难度较大。故现有工作大多来自在线医疗平台的医患对话数据,或医疗短视频数据,抑或是设计模板让模型生成数据,如表4所示。例如,中文医疗数据集MedDG来源于春雨医生[31];Zeng等则爬取了国外医疗网站iclinic.com和healthcaremagic.com上的数据,构建了MedDialog-EN数据集[32]。然而,Shim等指出,使用这些爬取的数据存在较大的隐私安全问题,特别是具有《通用数据保护条例》的欧盟地区[29]。
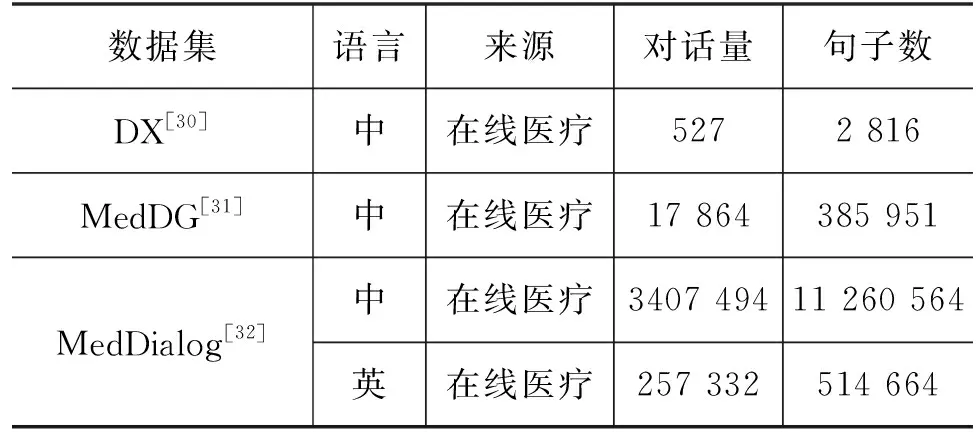
表4 医疗对话数据集对比
(2) 从对话决策角度,与通用场景(如选择航班、筛选符合条件的餐馆)不同,医疗决策过程更为复杂,往往需要更多的专业知识和额外信息。医疗TOD的模式(Schema)具备更多本体和属性,且本体-本体之间、本体-属性之间、属性-属性之间相关性极强[36-37]。因此,为了解用户状态,医生需要结合自身专业知识,对用户进行有针对性的追问,以获得更多辅助决策的关键信息,然后给出合适的建议。这一过程不仅涉及对话行为的决策,还涉及专业知识的推理,简单的知识查询或者基于对话历史的生成方法难以形成有效决策。
(3) 从对话评估角度,医疗对话系统的评估更为复杂,且需要具备较高的专业知识。例如,为判断医疗对话系统的生成是否正确,医学专家的引入是必备的。与此同时,患者满意度对医疗对话系统的应用至关重要,故需要加入患者视角的评估。详细内容请参考文献[29]。
2.2 医疗领域口语理解的挑战
作为医疗对话系统的第一步,医疗SLU同样具备自己的特点,从而使得槽位填充和意图识别这两个子任务面临着不小的挑战。
(1)槽位填充任务: 患者大多不了解医学知识和术语,在给医生描述自己的症状时,往往会出现不准确且关键词分散的特点。Shi等指出,患者总是以无序的语言描述自己的症状(如“腹痛”拆成“肚子”和“痛”),同时不可避免地具有方言和个人表达习惯的差异[38]。这些特点给槽位填充任务造成了困难。
(2)意图识别任务: 由于领域内缺乏像ATIS[1]、MultiWOZ[8]等具备极高影响力的数据集,医疗口语理解数据集的标注范式(Schema)差异较大。例如,医疗搜索检索词意图分类数据集(KUAKE-QIC)将医学问题分为病情诊断、病因分析、治疗方案、医疗费用等11种类型[39]。而IMCS-V2[36,40-43]则遵循Inform和Request经典分类,将医疗文本的意图分为告知-症状、提问-已有检查和治疗、提问-病因、告知-就医建议等16类。可以看到,不同标注规范下的数据集难以合并。同样,依托于某一数据集构建的算法可能对其他数据集不适用,这降低了意图识别模型的泛化性。
3 医疗口语理解研究现状与不足
尽管医疗SLU研究存在众多难点和挑战,但学者们仍取得了一定的成果。因此,本节将从数据集构建、算法设计和应用三个维度,对已经取得的成果进行介绍,并说明现有研究存在的不足之处,以期读者快速了解这一领域的研究动态。
3.1 医疗口语理解数据集构建的研究现状与不足
如前所述,尽管医疗领域数据集构建不易,医疗口语理解领域近些年来也出现了许多优秀的数据集,如表5所示。根据SLU的任务划分,本文将医疗口语理解数据集分为以下三类: ①仅面向意图识别;②仅面向槽位填充(即医疗命名实体的识别);③面向SLU。
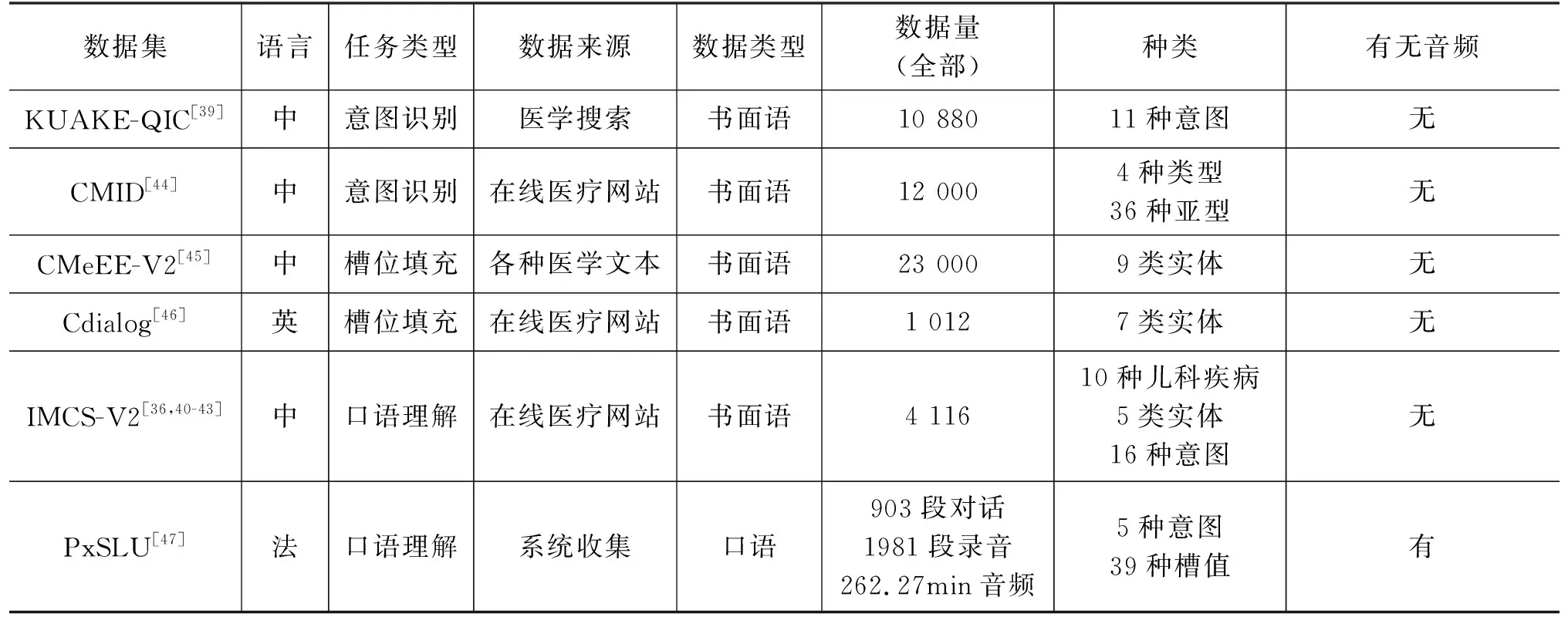
表5 医疗口语理解数据集
(1)仅面向意图识别: 除了上一小节提到的KUAKE-QIC[39]外,Chen等构建了中文医疗意图识别数据集CMID[44]。该数据集收集自20个专业在线医疗问答网站,通过众包方式标注意图,共有12 000个问题。该数据集涵盖两类意图标注,分别是4种类型(如病症、药物)和36种亚型(如治疗方法、副作用)。尽管该数据集也对命名实体进行了标注,但因其主要用于意图识别,且命名实体标注的目的是辅助意图识别,故本文将其划分至意图识别类。
(2)仅面向槽位填充: 这一类别的数据集大多对应命名实体识别任务。例如,CMeEE-V2数据集标注了疾病、临床表现、医疗设备、医疗程序等9大类实体,其训练集包含15 000条数据[45];CMeIE-V2数据集则利用诸如疾病-药物治疗-药物这样的层级关系进行标注[48];Varshney等构建了一个多轮次新冠肺炎对话数据集,对疾病、症状、医疗历史、药物、疗法等7大类实体进行标注,共有1 012个对话[46]。
(3)面向SLU: 这一类型的典型数据集是IMCS-V2[36,40-43]。该数据集不仅标注了命名实体、对话意图等与SLU有关的信息,还包括症状标签、医疗报告等其他信息,共包含4 116个对话,164 731条句子。
总体上看,现有的医疗口语理解数据集存在如下几点不足: ①大部分数据集都是从在线医疗平台(如春雨医生、丁香园等)上爬取得到的,可能存在隐私问题。②现有医疗口语理解数据集大多为书面语而非口语,且缺乏音频。例如,权威榜单CBLUE(中文医疗信息处理评测基准)中,与医疗口语理解相关的数据集(如意图识别、实体识别、信息抽取等)几乎都是书面语文本,且不存在音频形式的医疗口语数据集[39]。③现有数据集覆盖的病种有限,部分病种缺乏数据,且标签分布不平衡。例如,标注最为完善的数据集IMCS-V2[36,40-43]仅覆盖了10种儿科疾病;④目前业内缺乏统一标注范式,不同数据集的标注方法不同、侧重点差异明显,这给数据集的整合带来困难。
基于以上几点不足,大规模有标注的医疗口语数据集难以获取,这极大地限制了医疗SLU的发展。
3.2 医疗口语理解算法设计的研究现状与不足
由第2节可知,医疗SLU存在众多难点。近些年来,不少学者针对医疗SLU的特点,设计出优秀的算法,取得了不错的效果。例如,Lin等采用图来模拟症状之间的共现关系,提高了症状推断的精度[36];Shi等将槽值对视为预定义的类别,从而把槽位填充任务转化为多标签分类问题,并创新性地针对症状描述较为分散的特点设置了标签嵌入注意力模型,针对缺乏高质量有标注数据的特点设置了特殊的弱监督机制[38];Lin等则提出了图进化元学习(Graph-Evolving Meta-Learning,GEML)框架,通过在新的疾病-症状相关性推理中学习进化知识图谱,来动态调整疾病和症状的关系[37]。
分析现有研究,还存在以下问题: ①现有方法显然无法覆盖医疗口语理解的全部任务。例如,现有研究大多针对文本模态,缺乏对口语音频的研究,可以结合多模态技术加以改善;②主流方法仍存在一定的提升空间,可以考虑利用大模型相关的最新技术,如思维链、基于人类反馈的强化学习、高效参数微调等方法,提升现有方法的性能。
3.3 医疗口语理解应用的研究现状与不足
医疗口语理解应用广泛。在就诊前,SLU系统可以预测患者的症状,从而实现智能导诊和预检分诊。例如,Macherla等面向端到端对话诊疗系统,构建了首个相关的英文数据集MDDial,并综合考虑症状和疾病预测之间的关系,改进现有评估方法,从而提升系统的可靠性[35]。
在诊断过程中,SLU系统同样可以辅助医生诊疗,提升诊断效率。例如,Kocabiyikoglu等将口语理解模块引入处方管理系统,使得医生可以在移动设备上口头记录他们的处方[47,49];Zhang等设计了医学信息提取器MIE,可应用于电子病历的书写,减轻医生的负担[50]。
在诊断完成后,SLU系统可以用于患者的自我管理。例如,为便于患者理解医生开具的出院材料,Cai等构建了PaniniQA交互式问答系统,以帮助患者更好地恢复健康、实现自我管理[51];Narynov等则设计了心理学聊天机器人,帮助人们释放压力,保持心理健康[52]。
随着信息化的不断进行,特别是诸如ChatGPT等生成式大模型给产业带来的变革,在未来,医疗口语理解势必会有更多的落地之处。
4 医疗口语理解的未来研究方向
基于上述分析,加之ChatGPT等生成式大模型给自然语言处理领域带来的巨大技术革新,本文认为,未来的医疗口语理解研究需要同生成式大模型紧密结合,将其蕴含的丰富知识和生成能力应用于医疗场景,并借鉴其先进技术助推相关研究。
4.1 医疗大语言模型与医疗对话系统的区别
由于ChatGPT等生成式大语言模型表现出的强大性能,以及指令微调技术的成熟,医疗大语言模型被不断提出。例如,谷歌的Med-PaLM[53],哈工大的本草[54],仲景医疗大模型[55]等。在医疗大语言模型取得优异成果的同时,人们不禁思考,诸如医疗口语理解等传统对话系统的模块是否有必要存在?
针对这一问题,本文的观点是,就目前大模型的技术水平来看,传统医疗口语理解仍然是无法取代的。原因如下:
(1)大模型难以处理复杂的医学关系医学专业知识过于复杂,疾病与疾病、症状与症状、诊疗与症状之间存在相关和因果关系。例如,李子昊等专门构建了医学因果关系抽取数据集CMedCausal,对医学概念间的因果、条件和上下位关系进行刻画[56]。毫无疑问,依赖概率原理的生成式大模型在处理这些复杂的逻辑推理问题时会遇到不小的挑战。尽管编程链和思维链能够在一定程度上提高推理能力,但短时间内大模型处理这类问题的精度仍有待加强。
(2)大模型倾向于直接给出诊断建议医疗诊断对严谨性有极高的要求,因而医生会主动询问患者症状,通过一系列检查佐证后才能判断患者所患病症,并给出治疗方案。然而,大模型则更倾向于直接给出诊断建议,很少主动询问患者情况[55,57]。
(3)大模型在可控生成方面仍受到质疑大模型最为人诟病的是较差的可控生成能力,以及容易产生“幻觉”。根据Pan等的评测,大模型会生成未定义的槽值和错误的格式,且更倾向于生成详细文本,而非SLU需要的四元组形式[58]。
4.2 利用生成式大模型解决医疗口语理解问题
尽管医疗LLM暂时无法全面取代医疗口语理解研究,但其可以被视为一个有效的辅助工具,通过庞大的知识存储和生成能力,不断提升医疗SLU的性能。在此背景下,本文给出了几个医疗口语理解未来可能的研究方向。
(1)数据集层面: ①大模型强大的生成能力降低了构建医疗数据集的难度。例如,Wang等基于医学知识图谱CMeKG,利用ChatGPT接口构建了8 000余条指令数据[54]。②大模型同样可以用于标注数据,减少众包收集的成本。例如,He等根据“先解释后注释”的思想,提出Annollm标注系统,并成功证实其有效性[59]。此外,也可以借鉴MetaAI新提出的“指令回译”思想,进行数据的自我增强,生成指令数据集,并通过反复迭代,对数据进行自我管理,从而获得高质量指令数据集[60]。③对于口语音频数据集缺失的问题,可以利用大模型生成口语化、方言化的文本,并利用语音合成技术,得到对应的音频。
(2)算法层面: ①发掘更多的医疗口语特点,并针对性地设计算法。近期,口语数据的特点开始被学界关注。例如,Si等效仿MultiWOZ数据集,结合口语特点,构建了一个大规模口语数据集SpokenWOZ[12]。该数据集在数量和质量上远超此前的研究,为口语理解模型的训练打下了良好的基础。②生成式语音模型的研究方兴未艾。相较于文本领域的大模型,生成式语音模型的发展尚处于起步阶段,亟需将文本领域的先进经验(如有监督训练、RLHF等)引入。③探索如何让大语言模型具备理解口语音频的能力,进而充分利用其性能解决口语理解问题。例如,Wadhwa等将思维链技术引入,使得Flan-T5在关系抽取任务上取得了SOTA性能[61]。④大语言模型可以有效解决模型评估的问题。根据Chan等的研究,让大模型扮演不同角色,互相“辩论”,能够取得更好的评估效果,缩小其与人类评估之间的差距[62]。可以将这一思想用于医疗SLU领域,如用大模型扮演医生和患者的角色,从而得到既符合医学规范,又满足患者诉求的意图。
(3)应用层面: 生成式大模型的研究处于蓬勃发展阶段,借助这股东风,用新技术解决老问题,探寻更多可能的医疗应用场景,开展更广泛的医疗SLU应用研究。例如,通过构建医疗AI agent,利用大模型调用知识向量数据库、外部工具和API接口,长期跟踪患者,作为专属医疗管家,在预防、诊前、诊中、诊后的全流程中给予患者帮助。
5 总结与展望
本文对口语理解进行了较为全面的综述,调研了常用数据集和评价指标,并对模型方法做了极为细致的总结,分为流水线、端到端和生成式大模型三大类别对模型进行概括。同时,本文又聚焦于医疗领域的口语理解,从医疗口语理解数据集的开发、医疗口语理解的算法改进以及实际应用3个维度,对相关文献进行梳理。最后,针对于现有工作的不足,本文给出未来可能的研究方向。
在过去,Louvan和Magnini[63]、Qin等[64]和Weld等[65]都对口语理解领域做了较为系统的综述。与这些工作相比,本文具有如下优势: ①调研的主题更为明确,针对与书面语区分的口语进行研究,而并非广义的自然语言理解。②涵盖的范围更广,除了包含联合模型,还包括端到端模型等其他范式。③追踪领域动态介绍最新成果,如生成式大模型。④重点关注医疗领域,对该领域做了详细的调研。
此外,Valizadeh和Parde[66]也对医疗领域的对话系统研究做了综述。与其相比,本文具有如下优势: ①专注于口语理解任务,进行了全面的调研,更为聚焦;②纳入的技术更为前沿,包含了诸如深度学习、生成式大模型等内容。③结合当下NLP技术飞速发展的背景,从数据集、算法和应用层面进行展望,给出医疗口语理解未来可能的研究方向。
猜你喜欢
法律方法(2022年2期)2022-10-20
福建基础教育研究(2022年4期)2022-05-16
法律方法(2021年3期)2021-03-16
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
文苑(2018年22期)2018-11-19
学生天地(2017年10期)2017-05-17
小天使·三年级语数英综合(2016年6期)2016-05-14
