
太赫兹光谱在转基因菜籽油鉴别中的应用:基于改进蜉蝣算法的支持向量机模型*
2024-04-01 08:01陈涛李欣
物理学报 2024年5期
陈涛 李欣
(桂林电子科技大学电子工程与自动化学院,桂林 541004)
为实现对转基因和非转基因菜籽油的快速准确鉴别,结合太赫兹时域光谱技术,提出了一种基于改进蜉蝣优化算法的支持向量机模型.以两种转基因和两种非转基因菜籽油为研究对象,应用太赫兹时域光谱技术获取其光谱信息,发现相比于非转基因菜籽油,转基因菜籽油在太赫兹波段具有更强的吸收特性,同时它们的吸收光谱极为相似,难以通过观察法进行准确区分.为此,提出一种基于改进蜉蝣优化算法的支持向量机模型,通过采用蜉蝣优化算法对支持向量机参数进行寻优,并引入自适应惯性权重和Lévy 飞行两种策略改进蜉蝣优化算法在寻优过程容易陷入局部最优解的问题,增强蜉蝣优化算法的全局搜索能力和稳健性.实验结果表明:改进后的蜉蝣优化算法能够更有效地寻找到支持向量机的最优参数组合,提升鉴别模型的整体性能,该模型对4 种菜籽油的识别精度为100%.因此,本研究为转基因菜籽油的类型鉴别提供了一种快速有效的新方法,也为其他转基因物质的鉴别提供了有价值的参考.
1 引言
菜籽油是世界上第三大植物油品种,其富含不饱和脂肪酸、维生素E 和多种矿物质,有助于心血管健康,维持皮肤健康,为人体提供重要的营养成分和能量来源.据农业生物技术应用国际服务机构统计,2019 年,全球油菜中有27%是转基因作物[1].转基因油菜是全球四大转基因作物之一,其主要用途是生产菜籽油.虽然转基因菜籽油已成为生活中常见的食用油,但截至目前还没有任何研究能够彻底否认其潜在危害[2].在消费市场上,不注明转基因标示或将转基因产品标识为非转基因的情况屡见不鲜.因此,基于对公众食品安全的考虑,对转基因菜籽油的鉴别具有重要的现实意义.目前常见的转基因产品检测方法有两种:一种是基于脱氧核糖核酸(deoxyribonucleic acid,DNA)的方法[3],另一种是基于蛋白质的检测技术[4].由于转基因菜籽油中DNA 和蛋白质含量极低,采用上述两种方法均存在提取过程繁琐、耗时较长、会损坏原有物质和非专业人员难以胜任等问题.因此,寻找一种快速无损和操作便捷的转基因菜籽油检测方法显得尤为重要.
太赫兹(terahertz,THz)波是指频率在0.1—10 THz 范围的一段电磁波,是宏观电子学和微观光子学的交叉研究领域,具有很大的应用价值和学术价值[5,6].理论研究表明,许多生物分子(如DNA、蛋白质和脂肪等)的振动和转动能级正好处于THz频带范围内[7,8].因此,应用太赫兹时域光谱(terahertz time-domain spectroscopy,THz-TDS)技术探测生物样品产生共振吸收峰,并通过THz 光谱来识别生物样品成为了可能[9].目前,利用THz 光谱进行转基因食用油的检测识别已较多.文献[10]报道了THz-TDS 在检测转基因大豆油上的应用,文献[11]报道了THz-TDS 在检测转基因玉米油上的应用,文献[12]报道了THz-TDS 在检测转基因山茶油上的应用.
然而,通过对文献[10-12]的分析可知,同种转基因和非转基因植物油的THz 光谱极为相似,难以直接从光谱上对它们进行准确区分,需要结合一些模式识别方法才能实现对它们的准确区分.因此,本文应用支持向量机(support vector machine,SVM)方法对转基因和非转基因菜籽油进行鉴别.由于SVM 对参数较为敏感,选取合适的参数才可较好提升其性能[13],因此SVM 常与优化算法结合使用.蜉蝣优化算法(mayfly optimization algorithm,MOA)与其他传统优化算法相比,有着较好的求解精度和较快的收敛速度,但也由于较快的收敛速度,其在寻优过程中容易陷入局部最优解,全局搜索能力较弱[14],因此为了提升MOA 的整体搜索性能和精度,本文引入自适应惯性权重(adaptive inertia weight,AIW)以及Lévy 飞行两种策略来改进MOA(命名为ALMOA).本文将ALMOA 应用于SVM 重要参数的寻优过程中,从而得到一种基于改进蜉蝣优化算法的支持向量机模型(ALMOASVM),来实现对转基因和非转基因菜籽油的快速准确鉴别.
2 实验部分
2.1 实验设备
本文采用的实验设备为美国Zomega 公司生产的Z-3 THz-TDS 系统,该系统主要由超快飞秒光纤激光器、THz 辐射产生装置、THz 辐射探测装置和延时控制装置四部分组成,系统原理图如图1所示.该系统激光的中心波长为780 nm,脉冲宽度低于100 fs,信噪比高于70 dB.整个实验在室温下进行,为避免潮湿空气中水分对THz 波吸收的影响,实验前在样品实验舱中充满干燥的氮气,使其内部密闭空间的相对湿度小于2%,以保证实验数据的准确性.

图1 THz-TDS 系统原理图Fig.1.Schematic diagram of THz-TDS system.
2.2 样品制备
实验选取的样品为在市面上容易获取的4 种不同品牌的转基因和非转基因菜籽油,样品信息如表1 所示.所有油样均为具有国家质量监督检验检疫认证的合格产品.实验样品在实验前都在低温避光环境下储存以防止变质和氧化.实验样品架选择窗片材料为聚四氟乙烯薄膜的可拆卸液体池,由于聚四氟乙烯在THz 波段具有较低的吸收特性,所以不会对待测样品产生干扰.可拆卸液体池的厚度为0.5 mm,中心为面积为270 mm2的椭圆孔.在制样时,采用5 mL 的一次性医用注射器吸取约2 mL 的油样,沿液体池壁轻压注射器,使油样缓慢注入液体池中,以避免气泡的产生.每种菜籽油制作90 个样本,共计360 个,其中每种菜籽油随机选取70%的样本作为训练集,剩余的30%作为测试集.

表1 实验样品信息Table 1.The information of experimental sample.
2.3 数据处理方法与模型评价指标
在太赫兹时域光谱中,获取的信息较为有限,为进一步研究转基因和非转基因菜籽油在THz 波段的吸收特性,对实验测得的太赫兹时域参考信号和样品信号进行快速傅里叶变换,得到各自的频域信号,然后通过(1)式计算获得样品的吸光度,以此来表征4 种菜籽油对THz 波的吸收程度.
其中,Eref(ω) 为频域参考信号,Esam(ω) 为频域样品信号,ω为角频率.
为了更好地对分类鉴别模型的性能进行评估,采用查准率P、查全率R和精度A作为模型评价指标,计算公式如下:
其中,TP 为真正类,即模型正确地将某类物质(设为正类)预测为该类物质(正类)的个数;FP 为假正类,即模型错误地将其他类物质(设为负类)预测为该类物质(正类)的个数;TN 为真负类,即模型正确地将其他类物质(负类)预测为其他类物质(负类)的个数;FN 为假负类,即模型错误地将该类物质(正类)预测为其他类物质(负类)的个数.
3 分类模型
3.1 支持向量机
SVM 是一种基于统计学习理论的有监督学习方法[15,16].其核心原理在于将数据映射到高维空间,以寻找一个能够最大化不同类别数据间边界距离的超平面,从而实现对数据的有效分类.通过引入核函数,SVM 可以处理非线性分类问题,将其转化为在高维特征空间中的线性分类任务.同时,SVM 以结构风险最小化为原则,通过在特征空间中找到最优超平面来解决分类问题,具有较强的泛化能力和对噪声的抵抗能力.
在实际的应用中,合适的SVM 参数选择将决定模型的泛化能力和分类性能优劣,本文选择径向基函数(radial basis functions,RBF)作为SVM的核函数,因此该模型的分类能力主要取决于正则化参数c和径向基函数g两个参数,本文进一步采用蜉蝣优化算法(MOA)对SVM 的参数进行寻优.
3.2 蜉蝣优化算法
MOA 是2020年由Konstantinos等[17]根据蜉蝣的飞行和繁衍行为提出的启发式算法,用于解决复杂的函数优化问题.算法的工作原理如下:最初,随机生成两组蜉蝣,分别代表雄性和雌性种群.将每个蜉蝣随机放置在问题空间中,作为由d维向量x=(x1,x2,x3,···,xd) 表示的候选解,并在预先定义的适应度函数f(x) 上评估其性能.蜉蝣的速度v=(v1,v2,v3,···,vd) 定义为其位置的变化,每只蜉蝣的飞行方向是个体和社会飞行经验动态交互作用.雄性通过全局最优位置和自身历史最优位置移动,雌性则是向优于自己的配偶移动,若配偶弱于自己则自行局部搜索,移动结束后,雌性和雄性蜉蝣进行交配并产生后代,子代有较小的概率产生变异,最后淘汰子代和亲代中适应度较差的个体,维持种群整体数量不变,重复上述过程.
3.3 蜉蝣优化算法的改进
3.3.1 引入自适应惯性权重
惯性权重对解的搜索精度和收敛次数有着良好的指导性作用,较大的惯性权重有利于全局搜索,较小的惯性权重则有利于局部搜索.由于MOA采用的是线性的惯性权重,其全局和局部搜索能力一般,为了更好地发挥算法的全局搜索以及局部搜索能力,本文采用一种自适应非线性惯性权重[18,19],使之在迭代初期缓慢减小,主要发挥算法的全局搜索能力,从而达到圈定最优解范围的目的,在迭代后期,惯性权重减小加快,从而快速增强算法的局部搜索能力,精准锁定最优解位置.这里,定义自适应非线性惯性权重w如(5)式所示:
其中,wmax和wmin分别为最大和最小惯性权重,分别取值0.8 和0.4;tmax为最大迭代次数;t为当前迭代次数.
将惯性权重w引入MOA 中,雄性蜉蝣个体的速度更新为
3.3.2 融合Lévy 飞行策略
针对MOA 容易陷入局部最优的问题,利用Lévy 飞行的跳跃能力来增强其跳出局部最优的能力[20].Lévy 飞行策略模拟自然界中动物的随机觅食行走,假设种群中的蜉蝣均存在一定的概率不直接沿着最优路径移动,而是根据Lévy 飞行策略在最优路径附近进行随机游走,从而达到跳出当前局部最优位置,扩大全局搜索能力的目的.同时为了避免在迭代后期,蜉蝣一直在全局最优位置周围游走,而不收敛于全局最优位置,为Lévy 飞行增加步长调整参数δ[21]:
其中,δmax和δmin分别为最大和最小步长调整参数,分别取值1 和0;a,b为常数,分别取值4 和20.
通过上述参数的取值,此时δ∈[0,1),在迭代前期,δ从1 开始缓慢减小,发挥Lévy 飞行的全局游走优势,增强算法的全局搜索能力,在迭代中期δ开始迅速减小,并至迭代后期逐渐趋于零,目的是为了保证算法在迭代后期主要进行局部搜索,从而快速收敛于全局最优位置.
雄性和雌性蜉蝣个体的位置更新为
其中,L(α) 符合Lévy 分布,稳定参数α=1 .
通过上述两种策略的改进,相比于MOA,ALMOA 在迭代前期具有更强的全局搜索能力,在迭代后期具有更强的局部搜索能力.由此构建得到的ALMOA-SVM 模型,解决了MOA 在SVM 参数寻优过程中容易陷入局部最优解的问题,增强了SVM 最优参数的搜索精度,提升了模型的整体性能.
4 实验结果与分析
4.1 光谱分析
通过实验获取4 种菜籽油共计360 个样本的THz 时域光谱如图2 所示,实验设置的扫描窗口长度为30 ps,光谱分辨率约为33.3 GHz,图中Reference 表示参考信号,为实验舱中样品架空载时的测量值.由图2 可见,同种菜籽油不同样本的时域波形之间存在一定的差异,不同菜籽油样本的时域波形之间存在一定的交叉重叠.为了更清楚地观测到转基因与非转基因菜籽油存在的差异,对每种菜籽油90 个样本的THz 时域光谱数据求平均,得到4 种菜籽油的THz 平均时域光谱如图3 所示.可以看出,所有菜籽油的谱线相对于参考信号,在幅值上均呈现一定程度的衰减,在时间上均呈现一定的时延,表明菜籽油对THz 光谱具有一定的吸收特性.其中,Non-GMO1 油样的相位延迟最长,GMO2 油样的振幅衰减最多.总体上看,转基因菜籽油样品相对于非转基因菜籽油样品,在相位上延迟更少,在幅值上衰减更大.

图3 4 种菜籽油及参考信号的THz 时域光谱Fig.3.THz time-domain spectra of four types of rapeseed oils and reference signal.
为了进一步研究转基因和非转基因菜籽油在THz 波段内各频率的变化特性,将平均时域光谱补零后进行快速傅里叶变换得到其平均频域谱,如图4 所示.可见,所有样品信号相对于参考信号,在0.3 THz 之后均开始出现一定程度的衰减,同时在1.8 THz 之后参考信号和样品信号均开始出现明显的振荡现象,表明在1.8 THz 之后信号受噪音影响加剧.从整体上看,在0.3—1.8 THz 波段,转基因菜籽油样品相对于非转基因菜籽油样品,在幅值上呈现出更大的衰减趋势.通过上述分析可知,转基因菜籽油样品相对于非转基因菜籽油样品,在THz 波段表现出更强的吸收特性.

图4 4 种菜籽油及参考信号的THz 频域光谱Fig.4.THz frequency-domain spectra of four types of rapeseed oils and reference signal.
通过(1)式计算4 种菜籽油在0.3—1.8 THz频段内的太赫兹吸光度,获得360 个菜籽油样本的太赫兹吸光度谱如图5 所示.可见,所有菜籽油样本在0.3—1.8 THz 波段呈现出相似的波形和相近的幅值,无显著差异.通过对每种菜籽油90 个样本的吸光度取平均,计算得到4 种菜籽油样品的平均吸光度谱如图6 所示.可以看出转基因菜籽油样品相对于非转基因菜籽油样品,在THz 波段的吸光度更高,说明转基因菜籽油样品在THz 波段具有更强的吸收特性[10,11],与频域谱中观测到的结果相一致,这可能是由于转基因油菜中引入了外源基因,如高油酸基因、亚麻酸合成基因等,改变了菜籽油的脂肪酸组成含量,从而使转基因菜籽油在太赫兹波段具有更强的吸收特性[22,23].同时可以清楚地发现转基因和非转基因菜籽油样品的波形极为相似,吸收峰所处频率位置也基本一致,这可能是由于转基因和非转基因菜籽油的成分极为相似所致,而波形存在差异的原因之一可能是由于不同来源菜籽油中相似成分的含量存在差异,从而导致它们与太赫兹共振吸收峰在光谱上呈现出一定的差异,因此,采用直接观察的方式很难对它们进行准确的鉴别.
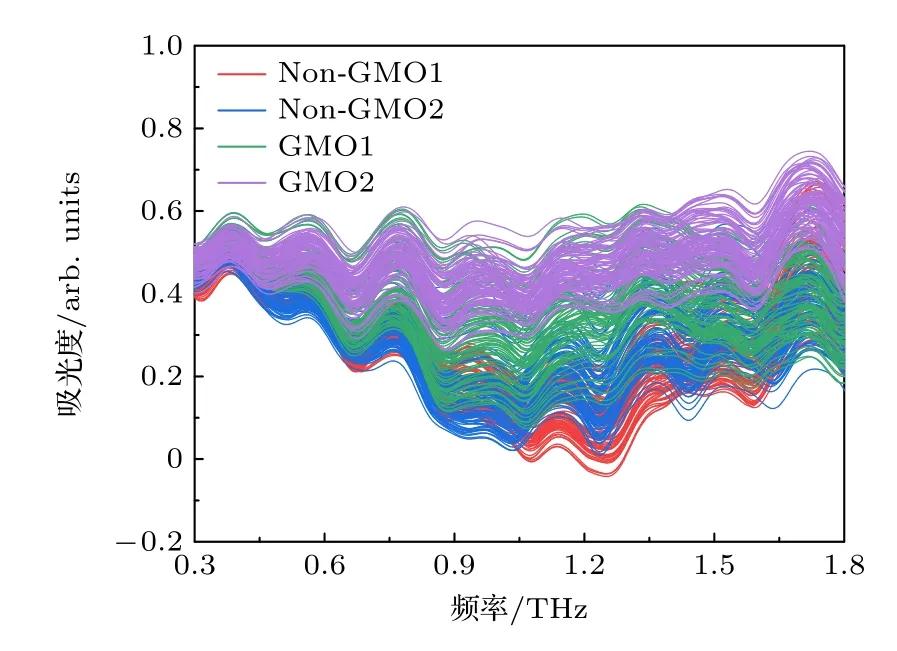
图5 360 个菜籽油样本在0.3—1.8 THz 波段内的吸光度谱Fig.5.Absorption spectra of 360 rapeseed oil samples in the 0.3—1.8 THz range.

图6 4 种菜籽油在0.3—1.8 THz 波段内的平均吸光度谱Fig.6.Average absorption spectra of four types of rapeseed oils in the 0.3-1.8 THz range.
4.2 主成分分析
由于菜籽油样品的吸光度数据维数过高,若将其直接输入到鉴别模型中,计算量较大且十分耗时,这将会对模型性能产生负面影响.因此,为了减少光谱数据的冗余,提高建模效率,采用主成分分析(principal component analysis,PCA)对菜籽油吸光度谱中0.3—1.8 THz 波段的原始数据(330 维)进行降维,得到各主成分的方差贡献率变化条形图如图7 所示.可以看出,前3 个主成分占据了原始数据的绝大部分信息,其累计方差贡献率达到了98.27%,图8 给出了前3 个主成分的三维(3D)散点图,从图8 可以看出,4 种菜籽油的主成分在三维空间中呈现出了不同的聚集区域,但也存在一些交叉重叠的地方,如Non-GMO1 的主成分分布较为分散,与其他3 种油样的主成分均有部分区域重叠;而Non-GMO2,GMO1 和GMO2 的主成分则分布则较为集中,但它们聚集区域的边缘位置也存在部分区域相互重叠.因此仅通过PCA 不足以对样本进行完全正确的分类,但也说明了PCA能够有效提取不同菜籽油吸光度谱中的特征信息.从图7 可以看出,前9 个主成分的累积方差贡献率超过了99.8%,可以近似解释所有原变量,因此采用这9 个新变量代替原始光谱数据来进行后续建模处理.

图7 吸光度的主成分方差贡献率变化条形图Fig.7.Bar chart of variance contribution rates for absorbance’s principal components.

图8 吸光度前3 个主成分的3D 散点图Fig.8.3D scatter plot of the first three principal components of absorbance.
4.3 参数寻优及模型鉴别
在训练集中分别用MOA 和ALMOA 对SVM进行参数寻优,寻找最佳的正则化参数c和径向基函数g参数,寻优过程如图9 所示,寻优结果如表2 所示.从图9(a)可以看出,MOA 的收敛速度很快,在迭代前期便快速取得了最佳适应度97.22%(最佳参数(c,g)=(12.42,0.79)),同时平均适应度也几乎同步增长至最佳适应度附近,但在迭代中期和迭代后期,最佳适应度一直稳定不变,平均适应度也仅在最佳适应度下略微起伏,这说明MOA 在迭代前期快速取得较高的局部最佳适应度后,迭代中期至迭代后期一直在局部最佳适应度附近进行寻优,未能跳出局部最优解扩大全局搜索范围.经多次实验发现,MOA 常常在参数寻优的迭代前期便陷入了不同的局部最优解,说明MOA 较为依赖雌雄蜉蝣初始的随机位置,全局搜索能力较差.从图9(b)可以看出,ALMOA 在迭代前期也快速取得了局部最佳适应度97.62%,但由于该算法在迭代前期具有较强的全局搜索能力,在图中具体表现为其平均适应度在迭代前期有较大的波动,因此其顺利跳出了当前的局部最优解,并在迭代中期再次跳出了局部最优解,最终取得了全局最佳适应度98.41% (最佳参数(c,g)=(84.62,0.12)).同时,从图9(b)中的平均适应度曲线变化可以发现,其波动幅度大致随着迭代次数增加而缓慢较小,且曲线整体上呈现上升趋势,并在迭代后期收敛于全局最佳适应度曲线附近,说明ALMOA 在迭代前期发挥了较强的全局搜索能力,在迭代后期发挥了较强的局部搜索能力,达到了预期的优化效果.

表2 两种算法的SVM 参数寻优结果Table 2.Results of SVM parameter optimization under two algorithms.

图9 两种算法下SVM 参数寻优过程中的适应度变化曲线 (a) MOA;(b) ALMOAFig.9.Fitness evolution curves during SVM parameter optimization process for two algorithms:(a) MOA;(b) ALMOA.
将MOA 和ALMOA 的最佳参数寻优结果分别代入SVM 中,并对测试集进行识别,最终得到MOA-SVM 模型和ALMOA-SVM 模型的分类结果混淆矩阵如图10 所示,模型的性能评价如表3所示.可见,采用MOA-SVM 模型的识别精度为98.15%,其预测结果中存在两个误判,分别将两个Non-GMO2 样品,一个误判为Non-GMO1 样品,另一个误判为GMO1 样品,所得Non-GMO2 的查全率为92.59%,Non-GMO1 的查准率为96.43%,GMO1 的查准率为96.43%.采用ALMOA-SVM 模型的识别精度为100%,所有菜籽油样品均被正确识别.由此可见,ALMOA 有效避免了参数寻优过程中陷入局部最优解的情况,增强了其全局搜索能力,从而使鉴别模型的分类性能得到了较好提升.

表3 MOA-SVM 模型与ALMOA-SVM 模型的性能评价Table 3.Performance evaluation of the MOASVM model and ALMOA-SVM model.

图10 两种模型的分类结果混淆矩阵 (a) MOA-SVM 模型;(b) ALMOA-SVM 模型Fig.10.Confusion matrices of the classification results for the two models:(a) MOA-SVM model;(b) ALMOA-SVM model.
5 结论
本文采用THz-TDS 技术研究了两种转基因和两种非转基因菜籽油的THz 光谱,发现转基因菜籽油相对于非转基因菜籽油在THz 波段具有更强的吸收特性.通过对0.3—1.8 THz 范围内的菜籽油吸光度谱进行主成分分析,选取累积方差贡献率超过99.8%的前9 个主成分替代原始光谱数据,降低了数据维度,提升了后续建模效率.在SVM参数寻优过程中,针对MOA 容易陷入局部最优解的问题,引入自适应惯性权重和Lévy 飞行两种改进策略,提出了ALMOA.结果表明,相比于MOA,ALMOA 在迭代前期具备更强的全局搜索能力,在迭代后期也具有较为出色的局部搜索能力,对SVM参数的搜索精度更高;基于本文实验获取的菜籽油吸光度数据集,ALMOA-SVM 模型对4 种菜籽油的识别精度为100%,优于MOA-SVM 模型获得的98.15%的识别精度.因此,THz-TDS 技术结合ALMOA-SVM 模型为转基因菜籽油的分类鉴别提供了一种快速有效的新方法,同时也为其他转基因物质的检测提供了方法参考.
猜你喜欢
计算机仿真(2022年8期)2022-09-28
青年文学家(2022年33期)2022-02-13
中国油脂(2019年3期)2019-04-29
中国粮油学报(2018年12期)2018-03-19
小雪花·小学生快乐作文(2017年7期)2017-09-07
中国塑料(2016年11期)2016-04-16
教育与职业(2014年16期)2014-01-19
营销界·食品营销(2013年11期)2013-12-05
舰船电子工程(2010年1期)2010-04-26
饮食科学(2009年12期)2009-12-11
