
融合语法规则与自注意力机制的GCN情感分析方法
2024-04-09 15:05尹明鹤李磊
信息系统工程 2024年3期
关键词:情感分析
尹明鹤?李磊

摘要:文本情感分析作为自然语言处理领域的一个重要分支,被广泛运用于舆情分析和内容推荐等领域,近年来成为研究的热点。提出基于语法规则和自注意力机制的GCN情感分析方法。首先,使用GloVe預训练模型与BiLSTM模型提取文本的语义特征,并采用spaCy工具对文本进行句法依存分析,从而提取文本的语法规则。其次,引入自注意力机制,并依据语义特征与语法规则构建GCN模型。最后,采用全连接层和Softmax分类器进行情感分类。实验结果表明,该方法与相关基线模型相比,在Twitter数据集上的准确率和宏F1值分别得到了提升,具有较好的情感分类性能。
关键词:情感分析;语法规则;自注意力机制;图卷积网络
一、前言
当前,社交媒体迅猛发展,人们更愿意通过网络平台分享对事物的看法。因此,在处理网络评论信息时,分析人们在文本中表达的情感、观点和态度变得至关重要。情感分析可以用于分析热门事件的舆情走向、在线商城调整经营策略以及维护社区网络环境等方面。
针对文本的情感分析是自然语言处理领域的一个重要研究方向,其将文本进行转换并自动分类到指定的情感极性(消极、中性或积极)。文本情感分类方法主要有基于情感词典的方法、基于机器学习的方法以及基于深度学习的方法。
基于情感词典的方法可以在较短的时间内获得分类结果,但对情感词进行标注时需要耗费大量的人力,并且必然会带来人工误差。基于机器学习的方法依赖于构建丰富的特征表示,成本较高[1]。随着深度学习的兴起,长短期记忆网络(Long Short Term Memory,LSTM)在短文本情感分析任务中得到广泛应用,但标准的LSTM模型并不能关注到在情感分类中起重要作用的部分。随着研究深入,学者们发现基于深度学习的方法虽然有效地弥补了前两种方法的不足,但忽略了语法规则对情感分类的影响,导致模型不能充分学习到文本特征。为了解决这一问题,研究者们引入注意力机制,通过引入注意力机制的模型进行情感分析。虽然基于注意力的模型取得了一定的效果,但不足以获取词语之间的语法关系。
由于图卷积网络(Graph Convolutional Networks,GCN)在处理非结构化数据时存在一定的优势,学者们将其应用于短文本情感分析任务中。王汝言在前人的基础上进行改进,将GCN网络的掩码输出分别与句子的隐藏特征表示和GCN层的输出进行交互,获得语义交互信息和语法交互信息。巫浩盛构建了一个带有语法距离权重的GCN网络模型,从而提取句子的上下文信息和词语的语法权重。Xu提出注意增强图卷积网络,该模型使用多头注意机制并行捕获上下文语义信息,使用GCN网络捕获语法信息,并利用多头交互注意机制实现语法信息和语义信息的交互。
针对现有研究中语法规则信息与语义信息交互不完全的问题,本文结合语法规则和神经网络模型,构建了融合语法规则与自注意力机制的GCN情感分析方法。本文的贡献如下:第一,提出一个融合语法规则与神经网络模型的情感分类方法,有效地将语法规则结合到情感分析方法中。第二,分别采用BiLSTM模型和spaCy工具提取文本的语义特征和语法规则,并通过GCN模块将语义特征与语法规则融合。第三,通过自注意力机制更好地捕捉句子内部的依赖关系,对重要特征赋予更大的权重,筛选出分类任务中最重要的特征,从而提高情绪分类准确率。
二、情感分析方法
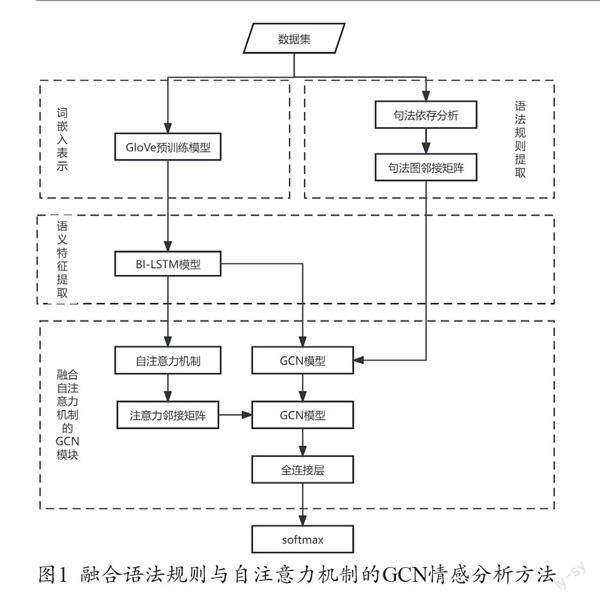
本文提出融合语法规则与自注意力机制的GCN情感分析方法,总体架构如图1所示。模型主要由词嵌入表示、语义特征提取、语法规则提取、融合自注意力机制的GCN模块、情感识别五部分组成。首先,采用GloVe预训练模型生成文本的向量表示。通过BiLSTM模型对文本的语义特征进行提取。其次,使用spaCy工具对文本进行句法依存分析,从而得到词语之间的依存关系。依据词语之间的依存关系与BiLSTM模型生成的语义特征建立融合自注意力机制的GCN模块。最后,通过全连接层与softmax分类器实现情感分类。
(一)词嵌入表示
GloVe预训练模型利用全局词频统计的方法来学习词向量,这种方法能够捕捉到更全面的语言信息。相比之下,Word2Vec预训练模型基于局部的上下文窗口来学习词向量,可能会忽略一些词的全局信息[2]。因此,本文采用GloVe预训练模型进行词嵌入,从而获得每个词向量表示。预训练后的词嵌入表示为Ew∈R|V|×d,其中|V|是词汇量,d是词嵌入的维度。Ew表示将包含n个词的评论序列W映射到词向量空间[e1,e2,…,en-1,en ]∈Rn×d。
(二)语义特征提取
为了捕获上下文语义特征,将得到的词向量送入BiLSTM模型中。双向长短期记忆神经网络(Bi-directional Long Short-Term Memory,BiLSTM)由2个LSTM模型构成,一个按正序处理输入序列,另一个按逆序处理输入序列。通过这种结构,Bi-LSTM模型可以同时捕捉过去和未来的上下文信息。
Bi-LSTM的公式如下所示:
其中,xi代表的是i时刻的输入向量,ci代表的是i时刻的细胞状态,h→i和h←i 分别代表前向和后向的隐藏层状态,hi∈R2dhid 代表BiLSTM的输出,dhid表示单向LSTM输出的隐藏状态向量的维度。
(三)语法规则提取
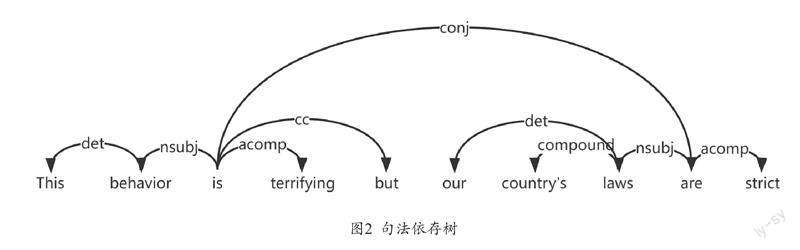
句法指句子中的各个组成部分的相互关系,句法分析包括两部分,分别是句法结构的分析与依存关系的分析[3]。目前的研究主要采用依存关系分析来探索词汇之间的依存关系。本文使用spaCy工具生成句法依存树,该图是一个带有标签的有向图。图中箭头从中心词指向从属词,标签表示从属词的语法功能。图2展示了一个句子的句法依存树。
通过句法依存树可以看出句子中两个单词之间的依存关系。本文通过三元组(rij,mi,mj)表示句子中两个单词之间的依存关系。其中rij表示单词mi和mj之间的依存关系的类型,mi是核心词,mj是依赖词。根据句子中所有三元组计算邻接矩阵A∈Rn×n,其中n是图的节点数。具体公式如下:
(四)融合自注意力机制的GCN模块
模型由两个GCN单元构成,第一个GCN单元通过句法依存分析得到的句法图邻接矩阵建立图卷积网络[4]。将句法依存分析得到的依存关系作为GCN的边,Bi-LSTM模型的输出作为GCN中的节点。GCN根据每个节点与邻居节点之间的关系进行建模,通过多层卷积操作,每个节点最终的隐藏状态可以接收到来自更远节点的信息,第k层卷积操作的计算方法如下所示:
其中,ai,j是句法图的邻接矩阵A∈Rn×n中的元素,1≤i≤n,n 是文本长度,b为第k个卷积层的参数;Wdir(k)∈Rdh×dh )表示处理不同矩阵时选取的权重矩阵,dn是编码层输出向量的维度;
其中,y为真实标签;y?为预测结果;?为L2正则化系数;θ为正则化中的参数。
三、实验
(一)实验数据集
为验证本文所提出方法的有效性,采用Twitter数据集进行实验。数据集中分为三种情感极性(消极、中性和积极),数据集总样本数为6940条文本评论。本文实验按照8:2的比例划分训练集和测试集。数据集中每种情感类别的数量分布如表1所示。
(二)实验设置与评价指标
实验中,采用300维预训练的GloVe预训练模型进行词嵌入操作,隐藏状态向量设为300,学习率设为0.001,L2正则化系数设为10-5。利用Dropout技术防止过拟合,其参数设置为0.2。采用交叉熵损失函数进行参数更新,学习率设置为3×10-5。本文采用准确率(Accuracy,Acc)和F1值(Macro-F1,MF1)作为评价指标来评估方法的性能。具体计算公式如下:
其中,TP和TN分别表示正确预测的正样本数和负样本数,FP和FN分别表示错误预测的负样本数与正样本数,P为精确率,R为召回率。
(三)对比模型
为了全面评估本文提出方法的性能,选择以下模型作为对比模型。各对比模型简介如下:
IAN:使用两个LSTM模型分别对方面词和上下文建模,利用交互注意力机制实现目标词与上下文的信息交互,并运用在方面词的情感分类任务中。
ASGCN:采用句法依存分析得出词语之间的依存关系,并依据依存关系构建GCN模型,从而进行情感分类。
Bi-GCN:提出一个双层交互图卷积网络,在句法图和词汇图上建立一个概念层次结构,通过两个层级的GCN模型区分各种类型的依赖关系或单词共现关系,并运用于情感分类任务。
DGCN:将残差链接与Bi-LSTM网络相结合,从而提取句子的上下文信息。同时,采用句法依存分析来获得词语之间的依存关系,并依据二者建立图卷积网络来提取特征,最终进行情感分类。
(四)实验结果与分析
比较对比模型与本文所提出的方法在Twitter数据集上的情感分类表现,其结果如表2所示。本文提出的方法相较于IAN模型,Acc指标提高了2.95%,F1指标提高了3.31%。表明IAN虽然通过交互注意力机制实现目标词与上下文的信息交互,从而获取语义信息。但是,其没有考虑语法规则信息和图结构对分类结果的影响,也缺少了对全局信息的考虑,因此效果低于带有图结构的模型。
本文提出的方法与Bi-GCN和ASGCN模型相比,Acc指标提高了3.3%和1.29%,F1指标提高了3.72%和0.77%。表明在关注句法依赖关系的前提下,考虑上下文之间信息的可行性。由于二者没有充分利用文本的语义信息,因此Acc指标和F1指标低于本文所提出的方法。
本文提出的方法与DGCN模型相比,Acc指标提高了2.58%,F1指标提高了2.91%。由此看出,虽然DGCN考虑到了语义的局部信息和全局信息,也考虑了语法规则对情感分类的影响,但是,其没有考虑注意力机制对情感分类的影响。本文所提出的模型与其相比,表明融合自注意力机制的GCN模块的有效性。
实验结果表明,本文模型的整体性能与三者相比,Acc和F1值都得到了提高,证明了融合语法规则与自注意力机制的GCN方法能够有效提升情感分析能力,该方法在短文本情感分析任务中具有一定的优越性。
四、结语
网络的迅猛发展,使微博和博客等社交媒体中包含的情感信息愈加丰富。情感分析旨在挖掘其中的情感信息,因此成为一个极具挑战性并意义非凡的任务。为了有效提升文本情感识别的结果,本文提出了一种融合语法规则与自注意力机制的GCN情感分析方法。
本文在语法规则与神经网络的结合方面进行了探索。首先,采用Bi-LSTM模型提取文本的语义特征,采用句法依存分析提取文本的语法规则。其次,通过语义特征与语法规则建立GCN模型,从而将语法规则与语义信息相结合。然后引入自注意力机制,采用自注意力机制对Bi-LSTM模型的输出进行处理,从而得到自注意力邻接矩阵。通过自注意力邻接矩阵再次构建GCN模型,从而得到最终的特征向量。最后,经过全连接层和Softmax函数进行情感分类。为验证所提出方法的有效性,采用Twitter数据集进行实验。结果表明,本文提出的方法在准确率和F1值指标上均有所提升。未来工作将探索利用句法依存树生成带标签的有向图,并结合GCN的节点和边获取更丰富的信息。
参考文献
[1]Jiang L, Yu M, Zhou M, et al. Target-dependent twitter sentiment classification[C]//Proceedings of the 49th annual meeting of the association for computational linguistics: human language technologies. 2011: 151-160.
[2]田乔鑫, 孔韦韦, 滕金保, 等. 基于并行混合网络与注意力機制的文本情感分析模型[J]. 计算机工程,2022,48(08):266-273.
[3]王娅丽, 张凡, 余增, 等. 基于交互注意力和图卷积网络的方面级情感分析[J]. 计算机科学,2023,50(04):196-203.
[4] Zheng Y, Zhang R, Mensah S, et al.Replicate, walk, and stop on syntax: an effective neural network model for aspect-level sentiment classification[C]//Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(05): 9685-9692.
责任编辑:张津平、尚丹
猜你喜欢
电子技术与软件工程(2016年15期)2017-04-27
软件工程(2016年12期)2017-04-14
电脑知识与技术(2017年5期)2017-04-08
电脑知识与技术(2017年3期)2017-03-27
智能计算机与应用(2017年1期)2017-03-23
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
读写算·教研版(2016年17期)2016-11-08
电脑知识与技术(2016年5期)2016-04-14
