
When Does Sora Show:The Beginning of TAO to Imaginative Intelligence and Scenarios Engineering
2024-04-15 09:36ByFeiYueWangQinghaiMiaoLingxiLiQinghuaNiXuanLiJuanjuanLiLiliFanYonglinTianandQingLongHan
By Fei-Yue Wang ,,, Qinghai Miao ,,, Lingxi Li ,, Qinghua Ni , Xuan Li , Juanjuan Li , Lili Fan , Yonglin Tian , and Qing-Long Han ,,
DURING our discussion at workshops for writing“What Does ChatGPT Say: The DAO from Algorithmic Intelligence to Linguistic Intelligence”[1],we had expected the next milestone for Artificial Intelligence (AI) would be in the direction of Imaginative Intelligence (II), i.e., something similar to automatic wordsto-videos generation or intelligent digital movies/theater technology that could be used for conducting new“Artificiofactual Experiments” [2] to replace conventional “Counterfactual Experiments”in scientific research and technical development for both natural and social studies[2]–[6].Now we have OpenAI’s Sora, so soon, but this is not the final, actually far away, and it is just the beginning.
As illustrated in [1], [7], there are three levels of intelligence, i.e., Algorithmic Intelligence, Linguistic Intelligence,Imaginative Intelligence, and according to “The Generalized Godel Theorem” [1], they are bounded by the following relationship:
AI ≪LI ≪II.
Where AlphaGo was the first milestone of Algorithmic Intelligence while ChatGPT that of Linguistic Intelligence.Now with Sora is emerging as the first milestone of Imaginative Intelligence, the triad forms the initial technical version of the decision-making process outlined in Chinese classicI Ching(orBook of Changes, see Fig.1): Hexagrams(Rule and Composition), Judgements and Lines (Hexagram Statements and Line Statements,or Question and Answer),and Ten Wings (Commentaries, or Imagination and Illustration).
Fig.1.I Ching: The Book of Changes for Decision Intelligence.
What should we expect for the next milestone in intelligent science and technology? What are their impacts on our life and society? Based on our previous reports in [8], [9] and recent developments in Blockchain and Smart Contracts based DeSci and DAO for decentralized autonomous organizations and operations [10], [11], several workshops [12]–[16] have been organized to address those important issues.The main results have been summarized in this perspective.
Historic Perspective
Text-to-Image(T2I)and Text-to-Video(T2V)are two of the most representative applications of Imaginative Intelligence(II).In terms of T2I, traditional methods such as VAE and GAN have been unsatisfactory, prompting OpenAI to explore new avenues with the release of DALL-E in early 2021.DALL-E draws inspiration from the success of language models in the NLP field,treating T2I generation as a sequenceto-sequence translation problem using a discrete variational auto-encoder (VQVAE) and Transformer.By the end of 2021,OpenAI’s GLIDE introduced Denoising Diffusion Probabilistic Models(DDPMs)into T2I generation,proposing classifierfree guidance to improve text faithfulness and image quality.The Diffusion Model, with its advantages in high resolution and fidelity, began to dominate the field of image generation.In April 2022, the release of DALL-E2 showcased stunning image generation performance globally, a giant leap made possible by the capabilities of the diffusion model.Subsequently, the T2I field saw a surge, with a series of T2I models developed such as Google’s Imagen in May, Parti in June, Midjourney in July, and Stable Diffusion in August, all beginning to commercialize, forming a scalable market.
Compared to T2I, T2V is a more important but more challenging task.On one hand, it is considered important because the model needs to learn the structure and patterns hidden in the video, similar to how humans understand the world through their eyes.Therefore, video generation is a task close to human intelligence and is considered a key path for achieving general artificial intelligence.On the other hand, it is considered difficult because video generation not only needs to learn the appearance and spatial distribution of objects but also needs to learn the dynamic evolution of the world in the temporal domain.In addition, the lack of high-quality video data (especially text-video paired data) and the huge demand for computing power pose great challenges.Therefore, compared to the success of T2I, progress in T2V moves slower.Similar to early T2I, T2V in its initial stages is also based on methods such as GAN and VAE, resulting in low-resolution, short-duration, and minimally dynamic videos that do not reach practical levels.
Nevertheless, the field of video generation has rapidly evolved during the last two years, especially since late 2023,when a large number of new methods emerged.As shown in Fig.2, these models can be classified according to their underlying backbones.The breakthrough began with language models (Transformer), which fully utilize the attention mechanism and scalability of Transformers; later, the diffusion model family became more prosperous, with high definition and controllability as its advantages.Recently,the strengths of both Transformer and diffusion models have been combined to form the backbone of DiT [17].
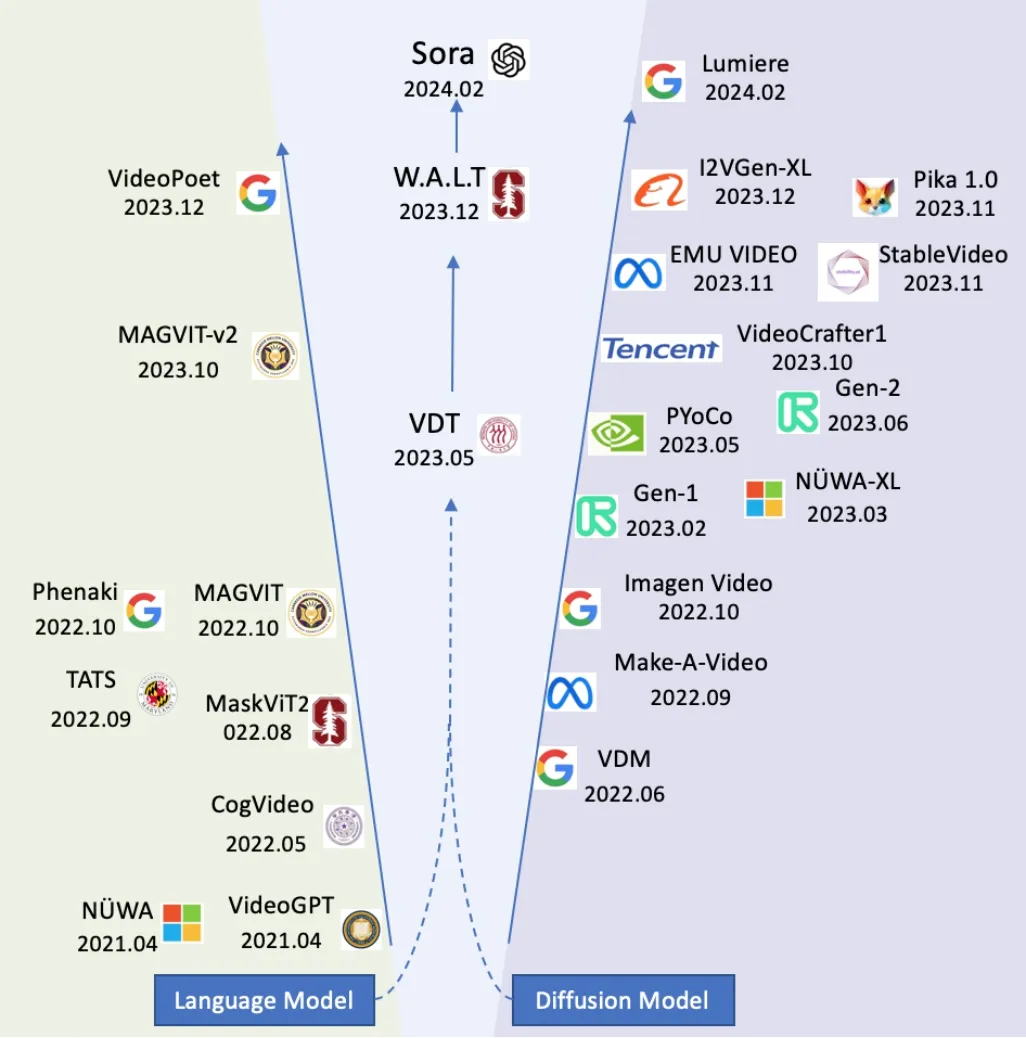
Fig.2.Brief history of video generation and representative models.Sora indicates the beginning of the Imaginative Intelligence new era.
The families based on language models are shown on the left side of Fig.2.VideoGPT[18]utilizes VQVAE for learning discrete latent representations of raw videos, employing 3D convolutions and axial self-attention.A GPT-like architecture models these latents with spatiotemporal position encodings.NUWA [19], an autoregressive encoder-decoder Transformer,introduces 3DNA to reduce computational complexity, addressing visual data characteristics.CogVideo [20] is featured as a dual-channel attention Transformer backbone, with a multi-frame rate hierarchical training strategy to better align text and video clips.MaskViT [21] shows that we can create good video prediction models by pre-training transformers via Masked Visual Modeling (MVM).It introduces both spatial and spatiotemporal window attention, as well as a variable percentage of tokens masking ratio.TATS [22] focuses on generating longer videos.Based on 3D-VQGAN and transformers, it introduces a technique that extends the capabilities to produce videos in thousands of frames.Phenaki [23] is a bidirectional masked transformer conditioned on pre-computed text tokens.It also introduces a tokenizer for learning video representation which compresses the video into discrete tokens.Using causal attention in time, it allows us to work with variable-length videos.MAGVIT [24] proposes an efficient video generation model through masked token modeling and multi-task learning.It first learns a 3D Vector Quantized(VQ) autoencoder to quantize videos into discrete tokens, and then learns a video transformer through multi-task masked token modeling.MAGVIT-v2 is a video tokenizer designed to generate concise and expressive tokens for both video and image generation using a universal approach.With this new tokenizer, the authors demonstrated that LLM outperforms diffusion models on standard image and video generation benchmarks,including ImageNet and Kinetics.VideoPoet[25]adopts a multi-modal Transformer architecture with a decoderonly structure.It uses the MAGVIT-v2 tokenizer to convert images and videos of arbitrary length into tokens, along with audio tokens and text embeddings,unifying all modalities into the token space.Subsequent operations are carried out in the token Space, enabling the generation of coherent, high-action videos up to 10 seconds in length at once.
The families based on diffusion models are shown on the right side of Fig.2.Video Diffusion Models (VDM) presents the first result on video generation using diffusion models by extending the image diffusion architecture.VDM employs a space-time factorized U-Net, jointly training on image and video data.It also introduces a conditional sampling technique for extending long and high-resolution videos spatially and temporally.Make-A-Video extends a T2I model to T2V with a spatiotemporally factorized diffusion model, removing the need for text-video pairs.It fine-tunes the T2I model for video generation, benefiting from effective model weight adaptation and improved temporal information fusion compared to VDM.Imagen Video [26] is a text-conditional video generation system that uses a cascade of video diffusion models.It incorporates fully convolutional temporal and spatial superresolution models and a v-parameterization of diffusion models,enabling the generation of high-fidelity videos with a high degree of controllability and world knowledge.Runway Gen-1 [27] extends latent diffusion models to video generation by introducing temporal layers into a pre-trained image model and training jointly on images and videos.PYoCo [28] explores fine-tuning a pre-trained image diffusion model with video data, achieving substantially better performance with photorealism and temporal consistency.VideoCrafter [29], [30]introduces two diffusion models: the T2V model generates realistic and cinematic-quality videos, while the I2V model transforms an image into a video clip while preserving content constraints.EMU VIDEO [31] generates images conditioned on the text and then generates videos conditioned on the text and generated image, using adjusted noise schedules and multi-stage training for high-quality,high-resolution video generation without a deep cascade of models.Stable Video Diffusion [32] is a latent video diffusion model that emphasizes the importance of a well-curated pre-training dataset,providing a strong multi-view 3D-prior for fine-tuning multiview diffusion models that generate multiple views of objects.Lumiere [33] is a T2V diffusion model with a Space-Time U-Net architecture that generates the entire temporal duration of a video at once, leveraging spatial and temporal down- and up-sampling and a pre-trained text-to-image diffusion model to generate full frame-rate, low-resolution videos on multiple space-time scales.
The center of Fig.2 shows the fusion of the language model and the diffusion model [17], which is believed as the way leading T2V to the SOTA.Video Diffusion Transformer(VDT) [34] is the pioneer in the fusion of transformer and diffusion model, demonstrating its enormous potential in the field of video generation.VDT’s strength lies in its outstanding ability to capture temporal dependencies, enabling it to generate temporally coherent video frames,including simulating the physical dynamics of three-dimensional objects over time.The proposed unified spatiotemporal masking mechanism allows VDT to handle various video generation tasks,achieving wide applicability.VDT’s flexible handling of conditional information,such as simple token space concatenation,effectively unifies information of different lengths and modalities.Unlike UNet, which is primarily designed for images, Transformer can better handle the time dimension by leveraging its powerful tokenization and attention mechanisms to capture long-term or irregular temporal dependencies.Only when the model learns(or memorizes) world knowledge, such as spatial-temporal relationships and physical laws, can it generate videos that match the real world.Therefore,the model’s capacity becomes a key component of video diffusion.Transformer has proven to be highly scalable, making it more suitable than 3D UNet for addressing the challenges of video generation.In December 2023, Stanford and Google introduced W.A.L.T[35], a transformer-based approach for latent video diffusion models(LVDMs),featuring two main design choices.Firstly,it employs a causal encoder to compress images and videos into a single latent space, facilitating cross-modality training and generation.Secondly, it utilizes a window attention architecture specifically designed for joint spatial and spatiotemporal generative modeling.This study represents the initial successful empirical validation of a transformer-based framework for concurrently training image and video latent diffusion models.
Sora’s highlight is just the beginning of a new era in video generation, and it’s foreseeable that this track will become very crowded.IT giants including Google, Microsoft, Meta,Baidu,startups like Runway,Pika,MidJourney,Stability.ai,as well as universities such as Stanford,Berkeley,Tsinghua,etc.,are all powerful competitors.
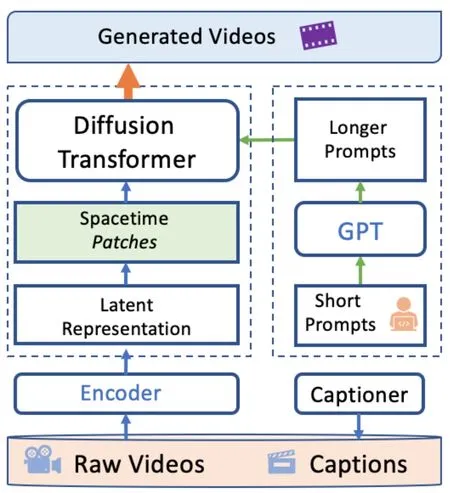
Fig.3.Brief principle diagram of Sora.
Looking into Sora: A Parallel Intelligence Viewpoint
Upon its release, Sora sparked a huge wave of excitement, with its accompanying demos showcasing impressive results.Sora shows videos with high fidelity, rich details,significant object changes, and smooth transitions between multiple perspectives.While most video generation models can only produce videos lasting 3 to 5 seconds,Sora can create videos up to one minute in length while maintaining narrative coherence, consistency, and common sense.Sora represents a milestone advancement in AI following ChatGPT.
What underpins Sora’s powerful video generation capabilities? From Sora’s technical report and the development history of video generation models, several key points can be summarized.
The first is the model architecture.Sora adopts the Diffusion Transformer (DiT), as shown in the left-upper corner Fig 3.Transformers have demonstrated powerful capabilities in large language models, with their attention mechanism effectively modeling long-range dependencies in spatiotemporal sequential data.Unlike earlier methods that perform windowed attention calculations or the Video Diffusion Transformer (VDT)that computes attention in the temporal and spatial dimensions separately, Sora merges the time and space dimensions and processes them through a single attention mechanism.Moreover, Transformers exhibit high computational efficiency and scalability, forming the basis for the Scaling Law with large models.The Diffusion Model, on the other hand, with its solid foundation in probability theory, offers high-resolution and good generation quality, as well as flexibility and controllability in video generation processes conditioned on text or images.DiT combines the advantages of both the Transformer and the Diffusion Model.
The second is data processing.As shown on the right side of Fig.3, Sora leverages existing tools, such as the captioner used in DALL-E 3, to generate high-quality captions for raw videos, addressing the lack of video-text pairs.Additionally,through GPT,it expands users’short prompts to provide more precise conditions for video generation over long periods.
The third is feature representation.During training, Sora first compresses videos into a low-dimensional Latent Space(shown in the dashed rectangle on the left of Fig.3) in both the spatial and temporal dimensions.Corresponding to the tokenization of text, Sora patchifies the low-dimensional representation in Latent Space into SpaceTime Patches,which are input into DiT for processing and ultimately generating new videos.From the perspective of parallel intelligence[36]–[44], the original videos come from the real system, while the Latent Space is the virtual system.Operations on the virtual system are more convenient to take advantage of the Transformer and the Diffusion Model.
Since OpenAI has not publicly disclosed the technical details of Sora,there may be other undisclosed technologies that have contributed to Sora’s breakthrough in video generation capabilities.It should be noted that Sora’s technical roadmap is far from mature.A large number of institutions are actively exploring and collaborating with each other.Microsoft,Google,Runway,Pika,Stanford,etc.have all iterated multiple versions and are still moving forward.The era of Imaginative Intelligence is just beginning.
Is Sora a World Model?
Although the released video clips from Sora have attracted a lot of attentions, OpenAI’s claim that Sora is essentially a World Simulator or a World Model has sparked considerable controversy.Among them, LeCun’s criticism is the most noteworthy.
A world model is a system that comprehends the real world and its dynamics.By using various types of data, it can be trained in an unsupervised manner to learn a spatial and temporal representation of the environment, in which we can simulate a wide range of situations and interactions encountered in the real world.To create these models,researchers face several open challenges, such as keeping consistent maps of the environment and the ability to navigate and interact within it.A world model must also capture not just the dynamics of the world but also the dynamics of its inhabitants, including machines and humans.
Thus, can Sora be called a world model? We analyze this from two perspectives.
Firstly, has Sora learned a world model? From the output results,most video clips are smooth and clear,without strange or jumpy scenes, and they align well with common sense.Sora can generate videos with dynamic camera movements.As the camera moves and rotates, characters and scene elements move consistently in a 3D environment.This implies that Sora already has the potential to understand and create in Spatial-Temporal space.Through these official demos, some have exclaimed that Sora has blurred the boundaries between reality and virtual for the first time in history.Therefore, we can say that Sora has learned some rules of real-world dynamics.However, upon closer observation of these videos, there are still some scenes that violate the laws of reality.For example,the process of a cup breaking, the incorrect direction of a treadmill, a puppy suddenly appearing and disappearing, ants having only four legs, etc.This indicates that Sora still has serious knowledge flaws in complex scenes, time scales, etc.There is still a significant gap compared to a sophisticated physics engine.
Secondly, does Sora represent the direction of world model development?From a technical perspective,Sora combines the advantages of large language models and diffusion models,representing the highest level of generative models.Scaling video generation models like Sora seems to be a promising approach to build a universal simulator for the physical world,which is a key step toward AGI.However, Yann LeCun has a different view.He believes that generative models need to learn the details of every pixel, making them too inefficient and doomed to fail.As an advocate for world models, he led Meta’s team to propose Joint Embedding Predictive Architecture (JEPA) [45], believing that predictive learning in joint embedding space is more efficient and closer to the way humans learn.The latest release of V-JEPA also demonstrates the preliminary results of this approach.
In summary, Sora has gained a certain understanding of real-world dynamics.However, its functionality is still very limited,and it struggles with complex scenarios.Whether Sora ultimately succeeds or fails,it represents a meaningful attempt on the road to exploring World Models.Other diverse technical paths should also be encouraged.
Impacts
Sora and other video generation models have opened up new horizons for Imaginative Intelligence.PGC (Professional Generated Content)will widely adopt AI tools for production,while UGC (User Generated Content) will gradually be replaced by AI tools.This commercialization of AI-generated video tools will accelerate, profoundly impacting various social domains.In fields like advertising,social media,and short videos, AI-generated videos are expected to lower the barrier to short video creation and improve efficiency.Sora also has the potential to change traditional film production processes by reducing reliance on physical shooting,scene construction,and special effects, thereby lowering film production costs.Additionally, in the field of autonomous driving [46], [47],Sora’s video generation capabilities can provide training data,addressing issues such as data long-tail distribution and difficulty in obtaining corner cases [12].
On the other hand, Sora has also brought about social controversies.For example, Sora has raised concerns about the spread of false information.Its powerful image and video generation capabilities reach a level of realism that can deceive people,changing the traditional belief of“seeing is believing,”making it harder to verify the authenticity of video evidence.The use of AI to forge videos for fraud and spread false information can challenge government regulation and lead to social unrest.Furthermore, Sora may lead to copyright disputes, as there could be potential infringement risks even in the materials used during the training process.Some also worry that generated videos could exacerbate religious and racial issues, intensifying conflicts between different religious groups, ethnicities, and social classes.
TAO to the Future of Imaginative Intelligence
Imaginative Intelligence.On the path to achieving imaginative intelligence, Sora represents a significant leap forward in AI’s ability to visualize human imagination on a plausible basis.Imaginative intelligence, the highest level of the three layers of intelligence, goes beyond learning data,understanding texts, and reasoning.It deals with high-fidelity visual expressions and intuitive representations of imaginary worlds.After ChatGPT made advances in linguistic intelligence through superior text comprehension and logical reasoning,Sora excels at transforming potential creative thoughts into visualized scenes, giving AI the ability to understand and reproduce human imagination.This achievement not only provides individual creators with a quick way to visualize imaginary worlds, but also creates a conducive environment for collective creativity to collide and merge.It overcomes language barriers and makes it possible to merge ideas from different origins and cultures on a single canvas and ignite new creative inspirations.Sora has the potential to be a groundbreaking tool for humanity, allowing exploration of unknown territories and prediction of future trends in virtual environments.As technology continues to advance and its applications expand, the development of Sora and analog technologies signals the beginning of a new era in which human and machine intelligence reinforce each other and explore the boundaries of the imaginary world together.
Scenarios Engineeringplays a crucial role in promoting the smooth and secure operation of artificial intelligence systems.It encompasses various processes aimed at optimizing the environment and conditions in which artificial intelligence operates, thereby maximizing its efficiency and safety [48]–[51].With the emergence of advanced models like Sora,which specialize in converting text inputs into video outputs, not only new pathways for generating dynamic visual content are provided but also the capabilities of Scenarios Engineering are significantly enhanced [52]–[54].This, in turn, contributes to the improvement of intelligent algorithms through enhanced calibration, validation, analysis, and other fundamental tasks.
Blockchain and Federated Intelligence.In its very essence,blockchain technology serves to underpin and uphold the”TRUE”characteristics,standing for trustable,reliable,usable,and effective/efficient[55].Federated control is achieved based on blockchain technology, supporting federated security, federated consensus,federated incentives,and federated contracts[56].Federated security comes from the security mechanism in the blockchain, playing a crucial role in the encryption,transmission,and verification of federated data[57].Federated consensus ensures distributed consensus among all federated nodes on strategies,states,and updates.Federated incentives in federated blockchain are established for maintenance and management [58].Therefore, designing fast, stable, and positive incentives can balance the interests between federated nodes,stimulate the activity of federated nodes, and improve the efficiency of the federated control system.Federated contracts[59]are based on smart contract algorithms that automatically and securely implement federated control.Federated contracts mainly function in access control, non-private federated data exchange,local and global data updates,and incident handling.
DeSci and DAO/TAO.The emergence of new ideas and technologies presents great opportunities for paradigm innovation.For example, the wave of decentralized science (DeSci)is changing the way scientific research is organized.As AI research enters rapid iteration, there are calls to establish new research mechanisms to overcome challenges such as the lack of transparency and trust in traditional scientific cooperation,and to achieve more efficient and effective scientific discoveries.DeSci aims to create a decentralized, transparent, and secure network for scientists to share data, information, and research findings.The decentralized nature of DeSci enables scientists to collaborate more fairly and democratically.DAO,as a means of implementing DeSci, provides a new organizational form for AI innovation and application [60], [61].DAO represents a digitally-native entity that autonomously executes its operations and governance on a blockchain network via smart contracts, operating independently without reliance on any centralized authority or external intervention [62]–[64].The unique attributes of decentralization, transparency, and autonomy inherent in DAOs provide an ideal ecosystemic foundation for developing imaginative intelligence.However,practical implementation has also shed light on certain inherent limitations associated with DAOs, such as power concentration, high decision-making barrier, and the instability of value system [65].As such, TRUE autonomous organizations and operations (TAO) were proposed to address these issues,by highlighting their fundamental essence of being “TRUE”instead of emphasizing the decentralized attribute of DAOs[66].Within the TAO framework, decision-making processes are hinged upon community consensus,and resource allocation follows transparent and equitable rules, thereby encouraging multidisciplinary experts and developers to actively engage in complex and cutting-edge AI development.Supported by blockchain intelligence [67], TAO stimulates worldwide interest and sustained investment in intelligent technologies by devising innovative incentive mechanisms,reducing collaboration costs and enhancing flexibility and responsiveness of community management.As such, TAO provides an ideal ecosystem for nurturing, maturing, and scaling up the development of groundbreaking technologies of imaginative intelligence.
When will Sora or Sora-like AI Technology show us the real road or TAO to Imagitative Intelligence that could be practically used for constructing a sustainable and smart society with intelligent industries for better humanity? We are still expecting, but more enthusiastically now.
ACKNOWLEDGMENT
This work was partially supported by the National Natural Science Foundation of China (62271485, 61903363,U1811463, 62103411, 62203250) and the Science and Technology Development Fund of Macau SAR (0093/2023/RIA2,0050/2020/A1).
 IEEE/CAA Journal of Automatica Sinica2024年4期
IEEE/CAA Journal of Automatica Sinica2024年4期
- IEEE/CAA Journal of Automatica Sinica的其它文章
- Goal-Oriented Control Systems (GOCS):From HOW to WHAT
- Digital CEOs in Digital Enterprises: Automating,Augmenting, and Parallel in Metaverse/CPSS/TAOs
- A Tutorial on Federated Learning from Theory to Practice: Foundations, Software Frameworks,Exemplary Use Cases, and Selected Trends
- Cybersecurity Landscape on Remote State Estimation: A Comprehensive Review
- Data-Based Filters for Non-Gaussian Dynamic Systems With Unknown Output Noise Covariance
- Designing Proportional-Integral Consensus Protocols for Second-Order Multi-Agent Systems Using Delayed and Memorized State Information