
基于LightGBM与SHAP的信贷违约预测方法研究
2024-04-29 05:24戴峥琪,雷亿辉,彭晨,夏广萍
邵阳学院学报(自然科学版) 2024年1期
关键词:信贷风险
戴峥琪,雷亿辉,彭晨,夏广萍

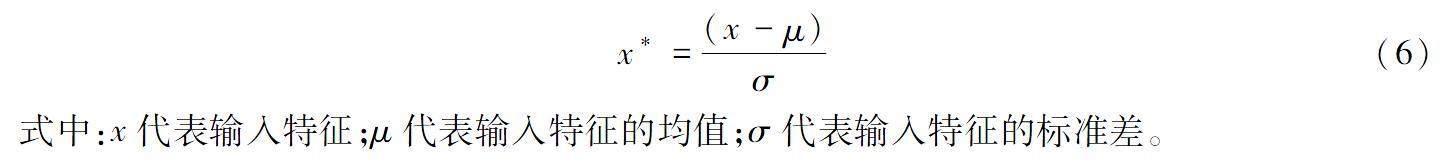
摘要:机器学习方法在信贷领域取得了较好的成果,但由于缺乏可解释性,应用受到限制,为增加其可信度和透明度,克服“黑盒”模型缺乏可解释性的缺陷,基于LightGBM算法建立信貸违约预测模型,并设计SHAP算法对模型的结果进行解释。结果表明,模型性能更好,预测精度更高,其精度高达88.61%;SHAP算法解释结果表明“信用组合的分类”“要支付的剩余债务”“每月EMI付款”等因素对信贷决策有着重要影响。
关键词:信贷风险;LightGBM算法;SHAP算法;可解释性
中图分类号:F832.4 文献标志码:A
Research on credit default prediction method based on LightGBM and SHAP
DAI Zhengqi1, LEI Yihui1, PENG Chen2, XIA Guangping1
(1. School of Mathematics and Statistics, Jishou University, Jishou 416000, China2. School of Computer Science and Engineering, Jishou University, Jishou 416000, China)
Abstract: Machine learning methods have shown promising results in the credit domain; however, their application is constrained by a lack of interpretability. To enhance credibility and transparency, and overcome the opacity inherent in “black box” models, a credit default prediction model based on the LightGBM algorithm is established. Additionally, the SHAP algorithm is employed to elucidate the models outcomes. The findings indicate superior performance of the proposed model, achieving an impressive prediction accuracy of 88.61%. Furthermore, SHAP algorithm interpretations reveal the significance of factors, such as “Credit-Mix” “Outstanding_Debt” and “Total_EMI_per_month” in influencing credit decisions.
Key words: credit risk; LightGBM algorithm; SHAP algorithm; explainability
信贷是现代经济的重要组成部分,它为个人和企业提供了从银行等金融机构获取资金的途径。然而,借款人向金融机构申请贷款时,往往存在信息不对称、逆向选择等问题,信贷违约概率的预测存在较大不确定性[1],这对从事贷款业务的金融机构来说是极其不利的。因此,使用有效的信贷违约预测模型,合理地评估借款人的信用违约风险,做出正确的信贷决策,是保障金融机构资金安全、维护金融市场稳定的重要手段。
传统的信贷决策主要依赖于人工信用评分,该类方法通过对借款人的收入、资产、负债以及历史信用等信息进行评分,根据评分结果判断是否为借款人提供贷款。由于此方法容易出现主观偏差和误判,增加信贷风险,许多学者提出基于统计学方法的信贷风险预测模型。基于统计学方法建立的模型具有稳健性和透明性等优点,被广泛应用于信贷违约预测[2-3]。然而,这些模型结构简单,不能有效地提取非线性信息,预测精度相对较低。针对此问题,DUMITRESCU等[4]在决策树算法的基础上,改进Logistic回归模型的框架,有效解决了Logistic回归模型无法拟合非线性关系的问题,显著提高了预测精度;MUNKHDALAI等[5]提出了一个由线性和非线性部分组成的部分可解释的自适应softmax回归模型,该模型解决了信贷决策中的不平衡二分类问题,同时提高了预测精度。
随着大数据时代的到来,机器学习算法因其高预测精度等优点被广泛应用于信贷领域。BAHNSEN等[6]基于Logistic回归算法和机器学习算法建立个人信贷评分模型,通过对比可知,机器学习算法的预测精度更高;吴瑞琪[7]基于机器学习算法中的感知机算法建立信用评分模型,进一步提高模型预测精度。然而,当处理大规模信用数据集时,简单的基于机器学习的基础分类器难以捕捉复杂的非线性关系,因此,WANG等[8]提出两种对偶策略集成树,以减少噪声数据和数据冗余属性的影响,获得相对较高的分类精度;LIU等[9]提出了两个基于树的增强梯度提升决策树模型,进一步提高了模型性能。但上述模型均使用横截面数据,不能有效解决时变问题,因此,XIAN等[10]在生存分析和梯度提升决策树模型的基础上提出了SurvXGBoost模型,该模型不仅性能较好,并且能够达到动态预测的效果。与传统的机器学习算法相比,上述集成学习模型预测精度更高,但缺乏可解释性。而在信贷决策过程中,相关人员需要了解模型的决策依据,以提高决策的合理性和可靠性,故在信贷决策等高风险领域中模型的可解释性至关重要。
为解决模型缺乏可解释性问题,将LightGBM集成学习算法应用于信贷风险预测,在保证其预测精度的基础上,采用SHAP算法对模型结果进行解释,增强模型的可解释性。主要貢献如下:1)建立基于LightGBM算法的信贷风险预测模型,该模型性能优于Logistic回归、决策树、随机森林和支持向量机等信贷风险预测模型;2)通过贝叶斯优化算法对模型的超参数进行优化,进一步提高模型的性能;3)利用SHAP算法对影响信贷决策的重要因素进行分析,提高模型的可解释性,为信贷人员进行信贷决策提供参考依据。
1模型与算法
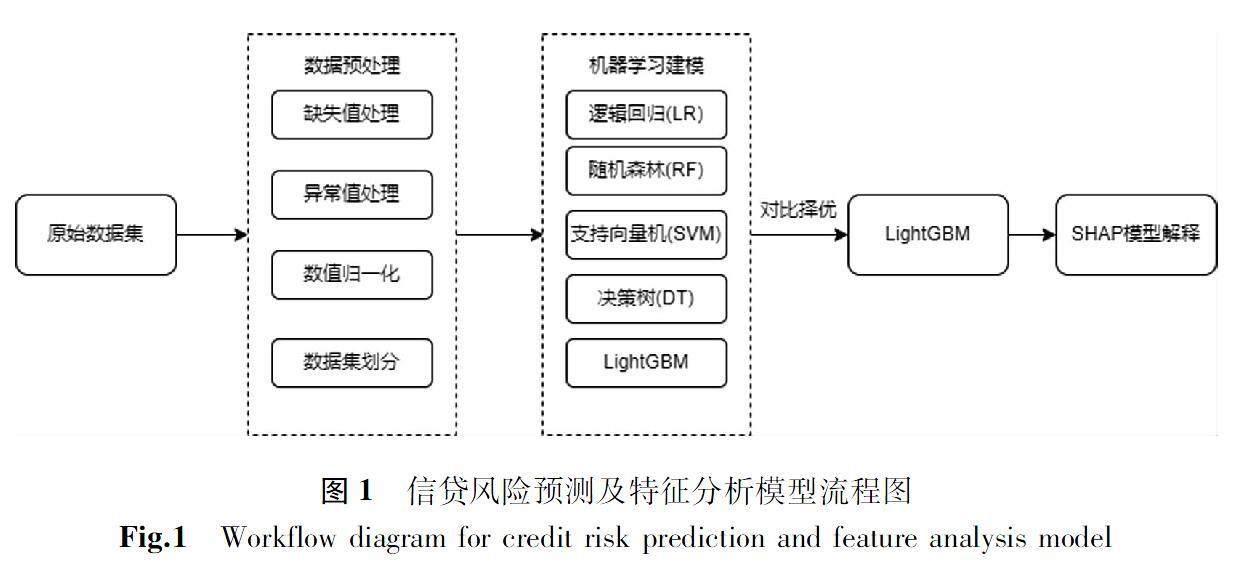
1.1信贷风险预测模型建模流程
采用基于LightGBM算法的信贷预测模型,并结合SHAP算法对模型结果进行解释,以增加模型的可解释性。具体的实现过程见图1。
1.2LightGBM算法介绍
LightGBM算法是一种高效的梯度提升决策树框架,其高效性主要源于两方面:第一,采用基于直方图的决策树算法,通过构建特征直方图并将其划分为离散的箱,减少了需要考虑的特征值数量,加速了计算速度并降低了内存占用;第二,采用梯度单边采样技术,通过识别具有大梯度的实例,然后基于阈值对具有小梯度的实例进行采样,减少了每次迭代中需要考虑的实例数量,加快了收敛速度并避免了过拟合问题。
LightGBM算法是由k个基模型所组成的求和函数,如式(1)所示:
y^i=∑kt=1ftxi(1)
式中:xi代表第i个样本的输入特征;ft代表第t个基模型;y^i代表第i个样本的预测值。损失函数可由预测值与真实值进行表示,如式(2)所示:
L=∑ni=1lyi,y^i(2)
式中:n代表样本容量;l代表第i个样本的损失函数;yi代表第i个样本的真实值。在此基础上建立目标函数,如式(3)所示:
Obj(θ)=∑ni=1lyi,y^i+∑kt=1Ωft(3)
式中:Ω代表正则化项;θ为模型参数。通过Softmax函数能够得到每个类别的概率。具体地,设模型一共训练了k棵树,第m棵树的输出结果为fm(x),则样本点x属于类别c的概率为
pc(x)=∑km=1wm·Ifm(x)=c∑km=1wm(4)
式中:wm为第m棵树的权重;I为指示函数。通过Softmax函数能够了解各类别的概率分布,能够对借款客户进行分类,通过不断优化目标函数,在一定程度上可以提高LightGBM算法的分类精度。
1.3SHAP特征重要性评估指标
SHAP算法是一种解释机器学习模型预测结果的方法。通过为每个特征提供一个重要性分数,即Shapley值,可量化每个特征对模型预测结果的贡献程度,帮助研究人员理解每个特征对模型的影响程度。因此,SHAP算法在金融、医疗、自然语言处理等领域得到广泛应用。
在SHAP算法中所有特征都被视为“贡献者”,通过计算每个“贡献者”的Shapley值来衡量其对最终输出值的影响,公式如下:
yi=ybase +fxi,1+fxi,2+…+fxi,k(5)
式中:xi,k代表第i个样本的第k个特征;f(xi,k)代表xi,k的Shapley值;ybase代表整个模型的基线;yi代表第i个样本的预测值。直观上,当f(xi,k)>0,说明该特征对预测结果有正向作用;反之,当f(xi,k)<0时,说明该特征对预测结果有反向作用。
2数据预处理与特征提取
2.1数据集介绍
使用的数据集“Credit score classification”来源于Kaggle平台。该数据集提供了经过脱敏处理后的借款客户个人信用的相关信息,例如职业、月基本工资、年收入等。数据集包含27个特征和1个标签,共100 000条数据,每行数据代表一个样本。
2.2数据预处理
2.2.1缺失值处理
对数据集中特征的缺失情况进行了可视化处理,可视化结果见图2。由图2可知,“月基本工资”和“贷款类型”等特征的缺失值较多,高达10%以上,本文使用该客户其他样本中对应特征的众数进行填充。以“月基本工资”为例,当某客户某月的“月基本工资”缺失时,将以该客户其他月份“月基本工资”的众数进行填充。
2.2.2异常值处理
为确保信贷风险预测模型的准确性,需进行异常值处理。针对数值型数据,本文将箱线图的最大值作为异常值的判定标准,超出最大值的数据视为异常值。以“月基本工资”为例,根据图3可知,“月基本工资”的最大值为13 500,而部分数据却超出了最大值,因此,将这部分数据视为异常值并删除对应的样本,确保异常值对预测模型的影响最小化。
2.2.3标准化处理
在实际应用中,不同特征的单位和量级不同,会对模型的训练和预测产生较大的影响。为了消除数据特征之间单位和量级的差异,本文对数据进行标准化处理,标准化的计算公式为
x*=(x-μ)σ(6)
式中:x代表输入特征;μ代表输入特征的均值;σ代表输入特征的标准差。
3实验
按照4∶1的比例划分训练集和测试集,构建基于LightGBM、Logistic回归(LR)、随机森林(RF)、支持向量机(SVM)、决策树(DT)算法的信用评分预测模型,并使用贝叶斯优化算法进行超参数优化,提高模型的分类预测精度。
3.1超参数优化
采用贝叶斯优化算法在训练集上对5个模型(表1)进行超参数优化。贝叶斯优化算法通过构建函数的后验分布描述需要优化的函数,随着观察次数增加,后验分布会逐渐改善。该算法会平衡探索和开发的需要,在每个步骤中,高斯过程被拟合到已知样本,后验分布与探索策略相结合,用于确定下一个应该探索的点。
3.2模型评价
为评估模型的性能,本文采用多种评价指标,包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值和AUC值。其中,准确率代表正确分类的样本占全部样本的比例;精确率代表预测为正例的样本中,真正为正例的样本所占的比例;召回率代表所有真正为正例的样本中,预测为正例的样本所占的比例;F1综合精确率和召回率,用于综合评价模型的性能;AUC值是用于评估分类模型性能的指标,公式如下:
Aaccuracy=TP+TNTP+TN+FP+FN(7)
Pprecision =TPTP+FP(8)
Rrecall=TPTP+FN(9)
F1=2·Pprecision ·RrecallPprecision+Rrecall(10)
式中:TP代表正类被预测为正类的样本数量;FN代表正类被预测为负类的样本数量;FP代表负类被预测为正类的样本数量;TN代表负类被预测为负类的样本数量。当涉及到多分类问题时,上述评价指标不能直接使用。多分类问题可视为多个二分类问题,通过计算各类别的评价指标并采用加權平均,考虑不同类别的重要性,可以得出最终的评价指标。其计算公式如式(11):
waverage=1n∑ni=1wi×si(11)
式中:n表示类别数;wi表示第i个类别的权重;si表示第i个类别的评价指标得分,如准确率、精确率等。
3.3实验结果
为评估本文所建立模型的性能,采用了LR、RF、SVM、DT作为对比模型,具体实验结果见表1。
根据对比实验结果可知,基于LightGBM算法的模型在准确率等评价指标上都优于LR、RF、SVM和DT模型,因此,后续进一步对基于LightGBM算法建立的信贷预测模型的结果进行解释,增强模型的可解释性和透明度。
4基于SHAP算法的模型解释分析
基于LightGBM算法的信贷风险预测有较高的预测精度,但由于其是“黑盒”模型,使得信贷决策人员难以像线性回归一样了解对决策结果起关键作用的特征。针对此问题,引入了SHAP算法对模型结果进行解释,在提供特征重要性排序的同时,着重解释了不同特征值对预测结果产生的具体影响。此外,考虑到该解释方法应用于个人信贷风险评估领域,本文在解释预测结果时不仅注重宏观层面,还针对每个客户进行了微观层面的解释。通过综合的解释方式,帮助决策者全面理解模型的决策过程,并为每位客户的信用风险评估结果提供个性化的解释。
4.1宏观层面的预测结果解释
4.1.1特征重要性解释
图4展示了特征重要性排序及其对违约倾向的影响,由图4(a)可知,“要支付的剩余债务”“持有的信用卡数量”“信用卡利率”“信用组合的分类”“付款日期算起的平均延迟天数”等因素对模型预测结果有显著影响。图4(b)为SHAP摘要图,其中每个点都代表一个样本,颜色代表特征的数值,从蓝到红表示数值由小到大,结合图4(b)可知,“要支付的剩余债务”“持有的信用卡数量”“信用卡利率”“付款日期算起的平均延迟天数”的Shapley值随着特征数值增加而增加,表明其与违约概率呈正相关关系,当特征值较大时,客户违约的可能性也较大;而“信用组合的分类” 的Shapley值随着特征数值增加而减少,表明其与违约概率呈负相关关系,当特征值较大时,客户违约的可能性较小。
4.1.2变量相关解释
图5展示了上述4个对违约概率有正向影响的特征依赖图,由图5可知,Shapley值的增长趋势随着上述特征数值的增加而呈上升趋势,这意味着随着这些特征值的增加,客户违约概率也随之增加。
综上,从宏观角度来看,基于SHAP算法研究特征重要性排序、探索特征之间的相互作用,能够从全局上掌握各项特征对信贷违约的影响机理,有利于制定更有效的信贷风险管理策略和决策。
4.2微观层面的预测结果解释
不同客户受相同指标影响作用各不相同,仅从宏观角度分析信用贷款的影响过于笼统,不能清晰明了地分析影响机制。因此,综合考虑客户相关的信用信息,提供个性化解释更为重要。图6为某一被拒绝借款客户的信贷预测结果解释图,图中不同长度、不同方向的箭头表示相关特征对信用违约概率的影响。箭头向右表示对应特征对违约概率有正向作用,箭头向左表示对应特征对违约概率有反向作用,箭头的长度代表对应特征对违约概率影响的程度。结合图6可知,“信用组合的分类”“要支付的剩余债务”等特征变量会增加违约概率,而“每月EMI付款”会降低违约概率。
通过个性化解释,信贷机构能够更加全面深入地了解客户,减小信贷风险及损失;对于客户来说,他们能够了解影响其贷款申请被拒绝的重要因素,从而理解并接受信贷决策人员的决策结果,或者通过制定合理的解决方案,提高成功获得贷款的概率。
5结论
基于LightGBM算法建立信贷风险预测模型,并采用SHAP算法对模型的结果进行解释,弥补了模型在可解释性方面的缺陷。实验结果表明,LightGBM算法在预测精度等方面性能更好,同时,SHAP算法提供的解释有助于相关人员全面理解影响信贷决策的重要因素,从而准确地评估借款人的信用风险,降低错误决策的潜在风险,提高信贷决策的准确性和可靠性。
参考文献:
[1]鲍星, 李巍, 李泉. 金融科技运用与银行信贷风险: 基于信息不对称和内部控制的视角[J]. 金融论坛, 2022, 27(1): 9-18.
[2]SHEN F, WANG R, SHEN Y. A cost-sensitive logistic regression credit scoring model based on multi-objective optimization approach[J]. Technological and Economic Development of Economy, 2020, 26(2): 405-429.
[3]D'AMATO A, MASTROLIA E. Linear discriminant analysis and logistic regression for default probability prediction: the case of an Italian local bank[J]. International Journal of Managerial and Financial Accounting, 2022, 14(4): 323-343.
[4]DUMITRESCU E, HUE S, HURLIN C, et al. Machine learning for credit scoring: Improving logistic regression with non-linear decision-tree effects[J]. European Journal of Operational Research, 2022, 297(3): 1178-1192.
[5]MUNKHDALAI L, RYU K H, NAMSRAI O E, et al. A partially interpretable adaptive softmax regression for credit scoring[J]. Applied Sciences, 2021, 11(7): 3227.
[6]BAHNSEN A C, AOUADA D, STOJANOVIC A, et al. Feature engineering strategies for credit card fraud detection[J]. Expert Systems with Applications, 2016, 51: 134-142.
[7]吳瑞琪. 基于感知机算法的个人信用贷款评估模型研究[J]. 通讯世界, 2019, 26(2): 233-235.
[8]WANG G, MA J, HUANG L, et al. Two credit scoring models based on dual strategy ensemble trees[J]. Knowledge-Based Systems, 2012, 26: 61-68.
[9]LIU W, FAN H, XIA M. Credit scoring based on tree-enhanced gradient boosting decision trees[J]. Expert Systems with Applications, 2022, 189: 116034.
[10]XIAN Y, HE L, LI Y, et al. A dynamic credit scoring model based on survival gradient boosting decision tree approach[J]. Technological and Economic Development of Economy, 2021, 27(1): 96-119.
猜你喜欢
信息技术时代·上旬刊(2020年1期)2020-09-10
经济技术协作信息(2018年15期)2019-01-23
数学理论与应用(2017年2期)2017-06-27
福建质量管理(2017年17期)2017-04-15
大陆桥视野(2016年12期)2016-12-27
中国市场(2016年32期)2016-12-06
时代金融(2016年29期)2016-12-05
科技经济市场(2016年4期)2016-07-20
中国商论(2016年33期)2016-03-01
河北金融年鉴(2014年0期)2014-02-27
