
基于雾计算的电力信息高效存储与共享算法
2024-05-03 09:44刘成江张千千黎燕张洪
沈阳工业大学学报 2024年1期
刘成江 张千千 黎燕 张洪
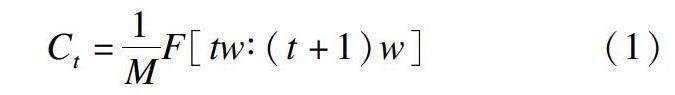
摘要:针对电力信息数据量较大且存储速度较慢的问题,提出了一种基于雾计算的电力信息存储与共享方法。该方法包含了基于差分同步的数据存储方式与基于雾计算的组合数据共享机制。数据存储方法将一部分数据的计算和存储工作转移到雾服务器中,以减少云计算平台的工作负载,从而实现更高效的数据存储;组合数据共享机制通过在雾端建立虚拟化数据共享机制来防止电力信息数据的丢失、损坏及恶意修改。仿真实验与结果表明,该方法能显著减少云服务器的响应次数,进而减轻云计算的负担,具有更高的数据恢复率,相比于传统方法,所提方法可实现高效、安全的电力信息存储及共享。
关键词:云数据;数据存储;数据安全;雾计算;组合共享;数据共享;差分同步;虚拟化
中图分类号:TM76 文献标志码:A 文章编号:1000-1646(2024)01-0001-06
随着互联网与物联网技术的快速发展,电力系统开始使用大量的传感器设备对电网运行状态进行监测,由此产生了海量数据。然而,传统的数据存储和计算模式已难以满足电网对海量数据的处理需求。为了实现电力系统大教据的安全、可靠存储,国内学者及企业提出将云计算关键技术与传感器网络相结合,以实现电力电网信息的存储和计算。其中无线传感器网络专注于获取及检测电力信息,云平台则主要负责对搜集的信息进行深度处理,从而为电网用户提供深度服务与业务支持。
云计算是一种以数据处理和管理为核心的计算机系统,其通过集成网络技术、集群技术以及分布式文件管理技术来实现网络中大量不同类型服务器的协调工作,进而为用户提供业务处理与数据存储服务。同时云计算还具有可伸缩、高效的特点,能够为用户提供便捷、快速及按需访问的计算资源池。此外,将云计算与无线传感器网络相结合,可为该网络在计算能力与内存等方面提供资源。故对于电力信息系统而言,低时延、高数据率、高计算与高存储能力的云计算平台显得尤为重要。无线传感器网络通常存在较高的通信时延、较低的可靠性与安全性等问题,因此,为实现高效、快速的电力信息处理,雾计算作为一种部署于终端设备附近的计算服务逐渐成为了研究热点。在该计算模式下,具有数据存储和处理能力的节点均被部署在无线传感器网络与云数据中间。而雾计算设备则可当作一个分布式的基础设施,并充分调动靠近无线传感器网络的边缘设备进行协同工作。相比于传统的云计算系统,雾计算模式更为灵活,且能够克服传统系统的多种限制及缺陷。
由于云计算平台对用户上传的数据实行统一管理,故用户无法对其存储的数据进行控制。这意味着数据的管理权与所有权产生了分离,也导致了云计算平台面临着严重的存储及传输安全问題,由此阻碍了该技术的进一步发展。云计算的安全问题主要包括数据的机密性、完整性与可用性三方面。其中,数据机密性主要负责对数据进行认证限制,以保护数据所有者的隐私;数据完整性负责保证用户上传的数据不会被篡改和破坏;数据可用性则根据数据所有者的意愿来访问其上传的数据。相比于传统的云计算平台,雾计算模式具有更高的安全性需求。
针对电力信息数据量较大与低时延存储的需求,本文提出了基于雾计算模式的电力信息存储及共享方法。通过采用基于差分同步的数据存储方式,实现了对雾计算模式下电力系统无线传感器网络数据的存储。同时,该方法还可以减少云端的工作负载,实现更高效的数据存储。此外针对云端数据共享的安全性问题,本文设计了一套基于雾计算的组合数据共享机制,实现了高效、安全的电力信息存储与共享。相比于传统方法,该方法具有更快的数据存储速度及更高的共享数据恢复率。
1 基于差分同步的数据存储方法
在传统的云存储方法中,即便只对数据进行细微修改,也需要将整个文件传输到云平台。然而电力信息通常需要频繁更改部分数据段,因此使用传统的云存储方法将导致数据出现冗余和延迟。为解决这一问题,本文提出了一种基于差分同步的数据存储方法。
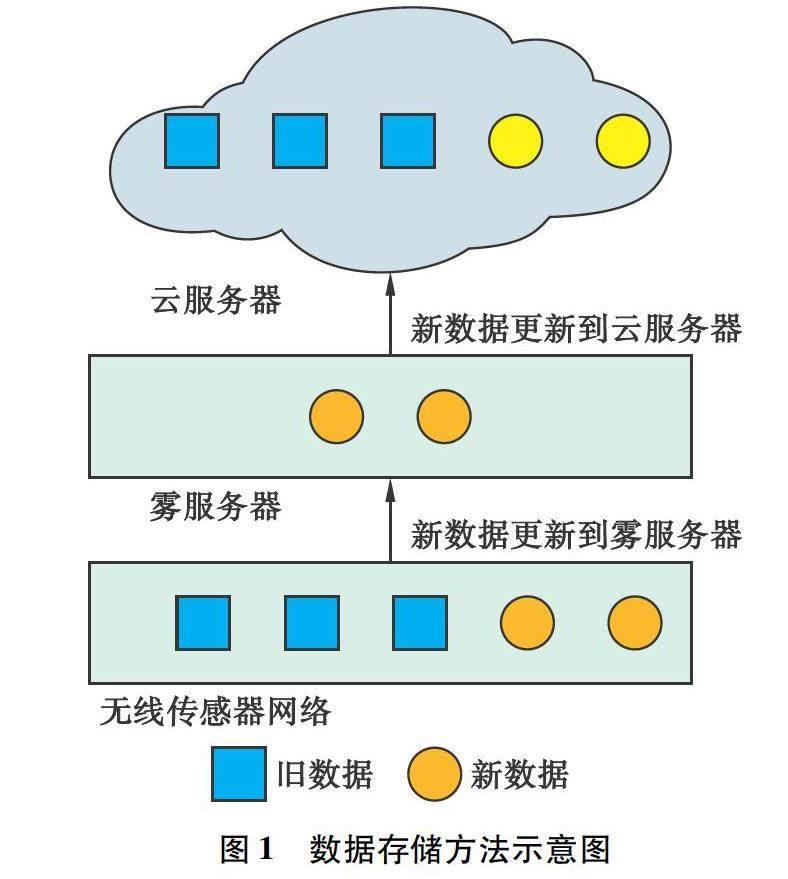
基于差分同步的数据存储方法将雾计算引入到传统云存储模式中,并将雾服务器作为缓存服务器放置于云服务器与边缘设备之间。在数据存储时,该方法将计算和存储的部分任务交给雾服务器进行处理,从而达到缓解云端数据存储负担的目的,方法流程如图1所示。
图1中从上到下分别为云服务器、雾服务器及电力系统的无线传感器网络。随着电网状态的改变,传感器网络监测的数据也会发生变化,这部分数据包括相关信息和差异数据。无线传感器网络上传数据到云端时,雾服务器便会将此类数据暂存。当缓存的数据量达到一定阈值时,再将该数据与云服务器进行同步。不同于传统方法,本文采用差分同步方式来实现云端数据的同步,将文件中的新数据块上传至雾服务器,并非上传所有数据。该方法可将无线传感器网络及云服务器的部分工作转移到雾服务器,从而有效缓解云端的工作负载,避免将某些变化频繁的数据反复上传到云端。假设待上传的文件为F,基于差分同步的数据存储方法将文件划分成大小为w的文件块,雾服务器的缓存阈值为Th,则所提方法的具体计算过程如下:
1)将文件F均分为M块,则第f个文件块为
2)检验每个文件块的强弱校验码,并将码存入Table1和Table2中,则有
式中:Adler32校验算法通过求解两个16位的数值,将结果连接成为一个32位的整数;MD5为信息一摘要算法,用于确保信息传输的完整性和一致性。
3)将强弱校验码表Table1和Table2传输到雾服务器中。
4)在雾服务器上对每个文件块进行一致性检测,判断文件修改的数据量是否超过阈值Th。若超过,雾服务器将该文件发送至云端进行同步;若未超过,记录本次修改,并继续检测下一个文件。
5)对于无线传感器网络发送的每一个文件重复进行上述操作,进而实现数据的存储。
基于差分同步的数据存储方法,采用阈值Th来判断是否对文件进行同步。本文方法将新文件表征为新、旧数据块的总和。其中,新文件块是由于对文件进行更改而出现差异的数据。通过设置阈值来表示文件的变化率,令Th为0.5,即当至少有一半的文件数据发生变化时才能向云端进行同步。假设文件每次超过阈值的概率为p,则对其进行q次修改时,传统方法需上传q次文件,而本文方法仅需上传∑qi=1f(p)次文件。由此可以看出,基于差分同步的数据存储方法明显比传统方法更有效。
2 数据共享与恢复方法
在传统的数据存储方法中,每类数据仅在云端存储一份。故当数据发生破坏或丢失等情况时,此类方法无法保证数据的完整性与机密性。为解决这一问题,本文采用“无线传感器网络-雾-云”三层结构对数据加以存储,提出了一种基于雾计算的数据共享机制,将数据的共享委托给雾服务器进行分析及处理。假设雾服务器集合为U={u1,u2,…,un},其中n为雾服务器的数量,数据文件被存储在k个不同的雾服务器节点,记为V={v1,v2,…,vk}。本文将文件F按照(k,n)的组合规则划分为n个数据块,然后再根据雾节点的异构特性将数据分为g个子段,每个数据子段均包括k-1个共享数据块,每个雾服务器保存一个数据子段。用户读取数据时仅需获得k个子集,即可恢复完整的文件。图2为基于雾计算的数据共享与恢复方法。在数据恢复过程中,由于雾节点中可能存在重复的共享数据块,在恢复原始数据时,本文方法将会选择性地接收非重复数据块.并在数据传输完成后恢复原始数据。
2.1 数据共享
数据共享过程是根据雾节点的剩余存储量、雾节点与云平台间的距离d以及网络带宽b来确定共享数据块的大小,并生成对应的共享数据块。本文定义共享数据块{s1,S2,…,sm}所满足的比例关系为
s1:s2:…:sm=d1r1b1:d2r2b2:…:dmrmbm (3)
式中,r为雾节点的剩余存储容量。数据块s,的表达式为
式中:S为原始数据集合{σ1,σ2,…,σn}的大小,其中,σn为第nd个数据块的大小;nd为数据块的数量;m为共享数据块的数量;k为雾服务器的节点数量。共享数据块的计算过程为:
1)计算每个数据块各分段索引的共享数据块之和,计算公式为
式中:y为雾节点所存储的数据;F为要恢复的文件;G为恢复出的共享数据块。
3 实验与分析
为验证所提方法的有效性,本文使用25.3MB的图片数据、85.6MB的音频数据及624MB的视频数据进行仿真测试。使用5-60个硬件设备作为雾节点,每个节点的传输速度从10-100Mbit/s不等,且每个节点均可连接40-100个无线传感器。
为了验证基于差分同步数据存储方法的有效性,本文设置了两组数据传输实验进行测试:1)原始文件为79.7kB,先对文件进行细微修改,并得到大小为98.6kB的新文件,随后再对文件进行第二次修改,进而获得大小为112kB的文件;2)原始文件为79.7kB,先对文件进行内容添加并得到大小为112kB的新文件,然后对文件进行二次修改获得大小为98.6kB的文件。两组实验分别模仿了数据修改的不同方式,即只是对文件进行细小修改和对文件进行较大幅度的修改。同时为保证实验数据量的一致性,需要对细微修改的实验组填充数据。为保证实验结果的可靠性,本文在后续实验中均进行了100次重复实验,取平均值作为最终结果。为了验证所提方法的有效性,将本文方法与文献[14]中所提方法进行比较,文献[14]方法采用传统的文件替代方式进行存储,即只对数据进行细微修改,也需要将整个文件传输到云平台。
由于不同窗口大小对数据上传的时间会产生影响,故本文给出了设置不同窗口大小时数据同步时间的变化情况。图3a为当窗口大小分别为文件的1/2、1/4、1/8、1/16及1/32时,采用本文方法进行数据上传用时的变化。由图3a可知,随着窗口的逐渐减小,数据同步的时间将不断增加。为了保证数据上传的效率,需选择适当大小的窗口来减少数据存储时间。在不同实验设置时,本文方法与文献[14]中所需数据的同步时间对比如图3b、c所示。其中,文献[14]将所有数据不加区分地更新、同步至雾平台。由于文献[14]方法需要将整个文件传输到云端,故其传输时间最长。而本文方法将雾服务器作为缓存,可有效减少上传至云端的数据量。本文方法通过设置阈值来避免重复操作,从而明显减少数据同步所需时间。
为验证数据缓存阈值Th对同步时间的影响,图4给出了设置不同大小的阈值时,本文方法在两种数据传输情况下的数据同步时间。从图4中可以看出,Th值由小到大的变化过程中,两种情况下的同步时间均逐渐减小,但减小到一定值后便不再发生变化。这是由于数据变化情况小于阈值,且没有达到同步条件时,无法实现云端同步。因此,需设置合理的阈值来实现所有数据的同步及传输效率的提升,本文将该值设置为7。
对数据进行分块可明显减少云服务器的响应次数,为验证这一结论,本文比较了数据块数不同时,文献[7]方法、文献[14]方法和文献[15]方法与本文方法的云服务器响应次数。10次实验结果如表1所示。从表1可以看出,本文方法的云服务器响应次数显著减少,进而减轻了云计算的负担。
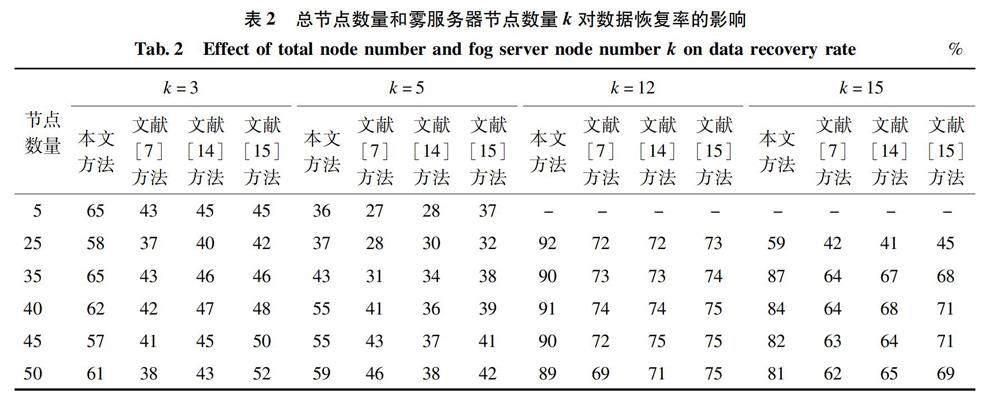
为验证所提出的数据共享与恢复方法的有效性,本文比较了使用不同数量的总节点以及雾服务器节点進行数据共享时的数据恢复率,具体结果如表2所示。由表2可知,本文方法能保持30%以上的数据恢复率。当参与数据共享的雾节点数量增加到一定程度时,会导致数据恢复率下降。因此,本文选择总运行节点数量的10-20%作为恢复的雾节点数。
4 结束语
本文提出了一种基于雾计算的电力信息存储与共享方法。该方法将雾服务器作为中转节点,采用差分同步的数据存储方式实现更高效的数据存储。相比于传统方法,本文方法具有更高的数据恢复率,能明显减少云服务器响应次数。通过比较使用不同数量的总节点以及雾服务器节点进行数据共享时的数据恢复率,验证了本文所提出的数据共享与恢复方法的有效性。
(责任编辑:钟媛 英文审校:尹淑英)
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
现代装饰(2020年5期)2020-05-30
制造技术与机床(2019年9期)2019-09-10
西南交通大学学报(2018年6期)2018-12-18
河北遥感(2017年2期)2017-08-07
丝路艺术(2017年5期)2017-04-17
初中生(2017年3期)2017-02-21
小学生优秀作文(趣味阅读)(2017年3期)2017-02-11
衡阳师范学院学报(2016年3期)2016-07-10
信息安全研究(2015年3期)2015-02-28
