
基于稀疏表示剪枝集成建模的烧结终点位置智能预测
2024-05-11 11:25吴忠卫张瑞垚吴永建
控制理论与应用 2024年3期
周 平,吴忠卫,张瑞垚,吴永建
(1.东北大学流程工业综合自动化国家重点实验室,辽宁沈阳 110819;2.中国矿业大学煤炭加工与高效洁净利用教育部重点实验室,江苏徐州 221116)
1 引言
随着钢铁行业的发展,对铁矿石的需求量不断增加,但可用来冶炼的富矿越来越少,为此通常采用烧结法来制造富矿,提高贫矿的利用效率.钢铁制造中,整个钢铁生产的能耗与排放水平受制于最前端的烧结工序,高炉冶炼的铁水质量与前端烧结工序的烧结矿质量也密切相关,因此,烧结过程在钢铁行业有着举足轻重的地位.如图1所示,整个烧结系统由烧结台车、布料圆辊、点火炉、保温炉、风箱等部分组成[1-3].烧结生产时,铁矿粉、焦炭、熔剂(石灰石、白云石)以及返矿等根据生产要求按照一定的比例进行配料,然后经过一次混合加水进行充分混合,再经过二次混合加水进行精细制粒,接着,布料圆辊将烧结原料平铺到烧结台车上,经过点火炉的前、后两排点火器进行点火,并在烧结机下方依次排列的风箱强力抽风作用下,烧结料层从上到下进行燃烧.燃烧的料层随着烧结台车不断前进,直到料层烧透.料层烧透的位置即为烧结终点位置(burning through point,BTP).烧透的烧结矿在机尾被卸下,经过环冷机冷却后被破碎机粉碎,然后进行筛分.筛分后符合工艺要求的烧结矿被运往高炉,而不合格的烧结矿主要作为返矿返回到配料过程返矿仓[2-4].此外,台车下风箱的废气通过大烟道进入脱硫装置脱硫后最终进入发电设备,而台车前端保温炉的作用是保持刚点燃受热后的料层表面温度以防止急冷,其热量一般来源为环冷机的余热回收[3].

图1 带式抽风烧结工艺流程示意图Fig.1 Schematic diagram of the belt-type sintering process
烧结过程中,一般需要将BTP控制在倒数第2个风箱附近,即图1中的第23号风箱附近.如果BTP提前,则烧结机的有效烧结面积没有得到充分利用,从而降低了烧结矿的产量;而BTP 延后,则烧结料层燃烧不充分,从而导致烧结矿质量下降,返矿量增加.由于BTP 难以采用现有仪表进行直接在线检测,因此对BTP 进行预测并根据预测结果调节过程参数显得格外重要.目前常见的BTP 预测模型主要有机理模型[5-7]、推理模型[8-10]、数据驱动模型[11-15]等几类.由于烧结过程物理化学反应极其复杂,数学模型难以建立,基于机理的BTP预测模型因为假设条件过多而难以应用.基于特殊工况或者已知工况的推理模型很难应对复杂多变的工况变化,因而难以长时间准确预测BTP,实用性差.数据驱动BTP预测建模不需要过多了解烧结内部运行的机理,具有建模方法简单、预测准确度高和易工程实现等诸多优点,因此成为近年BTP 预测建模的热点.早在2006 年,文献[11]就建立了基于支持向量机的BTP预测模型,通过烧结生产过程数据进行了实验验证;文献[12]建立了一种基于改进Takagi-Sugeno模糊模型且具有线性时变参数的BTP 预测模型,取得较好的实验验证效果;文献[13]将台车速度和点火温度作为输入,采用神经网络对BTP进行预测,预测结果可一定程度反应实际BTP的变化趋势.上述模型虽然在BTP预测中都取得了一定效果,但是单一学习器建模极易发生过拟合问题,可靠性不足.众多研究表明: 具有多学习器的集成学习能够克服单一学习器过拟合的问题,获得比单一学习器更高和更稳定的预测建模性能[16-17].如文献[16]采用AdaBoost.RT集成学习算法实现了烧结BTP的集成预测建模,取得了较好的预测效果.此外,由于烧结过程变量维度较高,如果全部变量都用于数据模型的建立,不仅会加大计算复杂度,而且会由于冗余信息的增加从而降低模型的性能,因此,在建模之前进行特征选择非常必要.目前关于BTP数据建模以及其他数据建模文献中通常采用基于皮尔逊相关性分析的特征选择方法或者基于专家经验的特征选择方法.但是,由于这些方法没有将后续模型性能作为特征选择的评价指标,是一种无监督的特征选择方法,难以得到使后续预测模型性能最佳的建模特征变量.显然,这将很大程度限制后续BTP预测建模的最佳性能.
此外,现有大部分集成建模工作,如上文提到的文献[16]的工作,其最终BTP集成模型输出是集成了所有子学习器模型的输出,并没有考虑剔除效果不好和冗余的子学习器模型.实际上,较多数量的子模型不仅会造成预测建模的计算复杂度显著增大,而且最终预测效果也不一定最佳.这意味着集成模型并不是规模越大越好,集成子模型中的一部分通常会比集成所有子模型效果更好[17].基于这一事实,文献[17]提出一种集成神经网络的剪枝算法,具体如下: 首先,先训练所有子模型;然后,对所有子模型进行随机权值的分配,并采用遗传算法对各个权值进行改进;最后,根据子模型的权重选择有效的子模型集合.文献[18]介绍了一种用于集成模型剪枝的有序剪枝算法.该方法是一种贪婪算法,在每次迭代中选择一个子模型,使已经选择过的子模型集合在训练数据上具有最小的均方误差.虽然这些算法在很大程度上提高了模型的泛化能力,但是相当耗时,满足不了实时预测的要求.针对这一问题,文献[19-20]引入稀疏表示理论来对神经网络集成模型进行剪枝,获得了更高的剪枝效率和更简洁的集成模型.受此启发,本文拟将集成模型的剪枝问题转化为信号的稀疏表示问题,提出稀疏表示剪枝(sparse representation pruning,SRP)算法,实现集成模型的高性能剪枝.
针对上述实际工程问题以及现有方法的不足,本文提出一种新型的基于特征优选与稀疏表示剪枝集成建模的BTP智能预测方法.首先,为了得到使后续预测模型性能最优的建模特征变量,采用基于遗传优化的有监督Wrapper特征选择方法.该方法将后续预测模型的预测精度作为特征选择的评价指标,从而可选取使预测模型性能最佳的特征组合.为了保证预测建模的精度,防止过拟合,本文提出基于随机权神经网络(random vector functional-link networks,RVFLNs)的稀疏表示剪枝(SRP)集成算法,即SRP-ERVFLNs算法.所提算法采用建模速度快、泛化性能好的RVFLNs作为个体基学习器,采用对基学习器参数进行扰动的方式来增加集成学习中子模型间的差异性.为了进一步提高集成学习建模的泛化能力和计算速度,引入稀疏表示算法,实现对智能集成模型的剪枝.基于实际工业数据的烧结过程数据实验表明了所提方法在BTP预测建模的有效性、先进性和实用性.
2 基于遗传优化的Wrapper特征优选算法
皮尔逊相关性分析由于计算量小、速度快而成为特征选择的常用方法,但是该方法的评价准则并未将预测模型性能考虑在内,因此选取的特征子集不能完全满足后续模型预测的高精度需求.而Wrapper特征选择算法可将预测模型的精度作为评价准则,弥补了皮尔逊相关性分析的缺陷.
Wrapper特征选择算法[21]的基本思想是在每一次迭代中,先使用一定的特征搜索策略得到候选特征子集,然后使用后续学习建模算法的预测精度作为评价标准来给候选特征子集打分,满足特定的停止准则时停止迭代,将最优评分的特征子集作为最终结果.因此,对于一个确定的预测模型,Wrapper特征选择算法能够得到使这个模型预测精度达到最优的一个特征子集.Wrapper特征选择算法的实现流程如图2所示.

图2 Wrapper特征选择算法流程图Fig.2 Flowchart of wrapper feature selection algorithm
通常,Wrapper特征选择算法选取最优子集的最理想搜索策略是穷举搜索.然而,实际工程问题的特征众多,会使得特征搜索面临很大的计算压力;另一方面,作为启发式随机搜索算法的遗传算法(genetic algorithm,GA)[22]具有良好的全局搜索能力以及较快的求解速度.因而,将GA与Wrapper特征选择算法相结合能够较快的选取使预测模型性能最佳的特征组合.基于该思路,本文提出基于遗传优化的Wrapper特征选择优选算法,如图3所示.
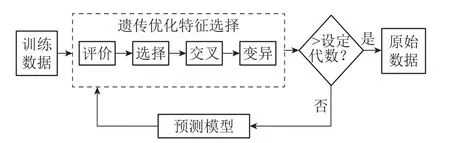
图3 基于遗传优化的Wrapper特征选择Fig.3 Wrapper feature selection based on GA
遗传优化算法首先初始化一群染色体,这些染色体代表针对不同目标问题的相应解决方案.然后,根据它们的适应度值大小即解决方案的好坏程度确定不同的繁殖机会,给适应度值大的染色体赋予大的繁殖机会.接着通过交叉操作将优秀的染色体基因传给下一代,同时也需要模仿自然界进化过程中存在的变异现象进行变异操作,为新个体的产生提供可能.新的染色体比上几代的染色体更加适应环境,也即针对目标问题的解决方案会越来越好.基于遗传优化的Wrapper特征选择方法的具体步骤如下:
步骤1进行基因编码: “0”表示特征未被选中,“1”表示特征被选中;
步骤2进行种群初始化,生成n组不同的特征组合;
步骤3将后续学习器预测的均方误差的负值作为适应度函数,计算每个个体的适应度值;
步骤4进行遗传优化的选择、交叉、变异操作;
步骤5未达到设定繁殖代数,转步骤3,否则,转步骤6;
步骤6输出最好的个体即最佳的特征组合.
3 SRP-ERVFLNs预测建模算法
3.1 算法结构与策略
众多研究表明: 集成模型相比于单一学习器模型具有更高的预测精度和泛化能力[17].目前,集成算法主要有Bagging,Boosting,Stacking 3种.基于Bagging思想且具有M个基学习器的集成学习首先对原始数据进行M次Bootstrap采样,也即有放回采样得到M个训练数据子集,然后在每个训练子集上训练各个体基学习器,最后将M个基学习器的回归结果通过进行集成,从而得到最终学习结果.该集成学习算法能够有效提高模型的预测精度和防止过拟合.为此,为了实现对BTP的稳定、可靠预测,提出基于Bagging的改进集成学习算法,即SRP-ERVFLNs算法,其整体结构如图4所示.

图4 所提SRP-ERVFLNs算法结构图Fig.4 SRP-ERVFLNs algorithm structure diagram
集成学习要求各基学习器“好而不同”,即基学习器不仅要有一定的精度而且各基学习器个体间要有差异性.本文采用随机权神经网络(RVFLNs)作为基学习器.首先,从单个基学习器的性能来看,RVFLNs具有学习速度快、泛化性能好等优点;其次,在集成学习方法的使用过程中,基学习器的多样性也是影响模型性能的重要因素,而RVFLNs的输入权重和偏置值是在给定范围内随机生成,因此各RVFLNs基学习器具备个体差异性.Bagging中的Bootstrap采样是有放回采样,它是样本数据扰动常用的方法,其目的是增加个体子模型的多样性.在此基础上,所提算法为了进一步增加个体子模型的多样性,对基学习器的参数进行扰动,具体策略为:RVFLNs 的激活函数在Sigmoid,Sine,Hardlim和Gaussian中进行多样性选择,隐含层节点数在一定范围内随机生成,最终得到基于Bagging的集成RVFLNs,即ERVFLNs算法.
对集成模型进行剪枝不仅可以删除冗余和性能差的子模型,进而提高预测效果,而且更简洁的集成规模还可以降低存储要求,提高预测计算的速度.因此,进一步提出集成学习性能优化的稀疏表示剪枝(SRP)算法.SRP剪枝算法将剪枝问题转化为稀疏表示问题,然后利用正交匹配追踪(orthogonal matching pursuit,OMP)算法进行求解.
3.2 RVFLNs基学习器
RVFLNs最初是Pao和Takefuji[23]提出的一种单隐层前馈型神经网络,其特点就是神经网络的输入权值和隐含层偏置在一定范围内任意选取,而输出通过下式计算:
式中:L是隐含层节点数,βi=[βi1βi2···βiny]是连接第i个隐含层神经元和ny个输出神经元的权重向量,αi=[αi1αi2···αinx]是第i个隐含层神经元和nx个输入神经元的权重向量,bi是第i个隐含层神经元的偏置,而xj是输入向量.
给定N个样本的训练数据集,其中是输入向量,是对应输出向量.从而式(1)可以写成如下矩阵形式:
隐含层和输出层之间的输出权重可以通过求解如下最小二乘问题获得:
式中: 第1项是防止过拟合的正则化项,第2项是误差向量项,λ是惩罚系数.通过将RVFLNs相对于β的梯度设为0,可以得到以下等式:
当矩阵J列满秩,即训练样本的数量大于隐含层神经元的数量时,上式可以求解如下:
式中IL是维数为L的单位矩阵.当矩阵J行满秩时,即隐含层神经元的数量大于训练样本的数量,RVFLNs的输出权重可以求解如下:
式中IN是维数为N的单位矩.
3.3 稀疏表示剪枝的集成RVFLNs算法
受文献[19-20]启发,本文将集成RVFLNs 模型的剪枝问题转化为信号稀疏表示问题,从而提出稀疏表示剪枝(SRP)算法,用于集成模型的高效剪枝和简化,具体算法如下.
3.3.1 稀疏表示优化问题及求解的OMP算法
稀疏表示理论由Mallat和Zhang[24]在1993年提出,经过不断完善和发展,目前已经被广泛应用在信号处理、图像处理等领域.稀疏表示的基本原理如下: 信号y∈Rn可以被近似表示为几个信号d1,d2,···,dm的线性组合,即y=x1d1+x2d2+···+xmdm,其中m>n,∀i,di∈Rn,xi是表示系数向量x中的元素.信号d1,d2,···,dm称为原子,其集合D=[d1,d2,···,dm]∈Rn×m称为字典.稀疏表示试图找到可以近似表示y的最小原子个数,即稀疏表示旨在求解如下问题:
式中:x∈Rm;‖x‖0表示x的“l0范数”,即x中非零元素个数.对ε≠=0的情况,m>n的条件不是必须的,当n≥m时,该问题同样适用.
式(8)所示的稀疏表示优化问题为NP难的组合优化问题,难以直接求解,通常只能采用贪婪法或凸松弛法来近似求解.为此,采用正交匹配追踪(OMP)算法[25]来解决式(8)的稀疏表示优化问题.OMP是一种贪婪算法,其基本思想是在每一步迭代中,从字典D中选择一个与残差最相似的原子,并将已经选择的所有原子进行正交化处理,直到满足约束条件时,算法终止迭代.约束条件通常是要选取的原子个数也即稀疏度大小.OMP算法的伪代码如算法1(见表1)所示.

表1 算法1: 稀疏表示剪枝优化求解的OMP算法Table 1 Algorithm 1: Sparse representation of the OMP algorithm for pruning optimization
3.3.2 集成模型的SRP算法
本文将集成模型的剪枝问题转化为第3.3.1节所述的信号稀疏表示问题,从而提出集成模型高效剪枝的SRP算法.SRP算法的基本思想如下: 假设一个集成模型包含L个子学习器模型,各子学习器模型在训练数据集{xi,yi},i ∈{1,2,···,Ntrain}上进行训练后,对一个训练样本,得到L个预测值{,,···,}.将此L个预测值放入一个向量中,记为di∈RL.然后将所有训练样本对应的这些向量放入一个矩阵,记为D∈RNtrain×L.因此字典D包含所有子模型对Ntrain个样本的预测值.集成模型最终预测值取L个子模型预测值的平均值,即集成模型最终预测值y*=[y*1y*2···y*Ntain]T,通过式(9)得
采用第3.3.1节OMP算法求解上述优化问题.首先,确定应该选取的子学习器模型的个数k,然后使用-OMP算法会找到最重要的k个子模型.所提稀疏表示剪枝算法的伪代码如算法2(见表2)所示.

表2 算法2: 集成模型高效剪枝的SRP算法Table 2 Algorithm 2: SRP algorithm for efficient pruning with integrated model
最后,所提SRP-ERVFLNs预测建模算法的实现步骤如下:
1) 给定训练集Pr,测试集Pe,在Pr上使用Bootstrap采样得到K个训练子集{O1,O2,···,OK},本文K=20;
2) 在训练子集{O1,O2,···,OK}上分别训练20个RVFLNs子学习器模型,这些子学习器的激活函数选择Sigmoid,Sine,Hardlim和Gaussian各5个,每个RVFLNs的隐含层节点数在[a,b]内随机选取;
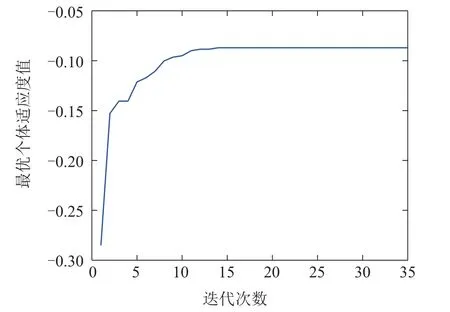
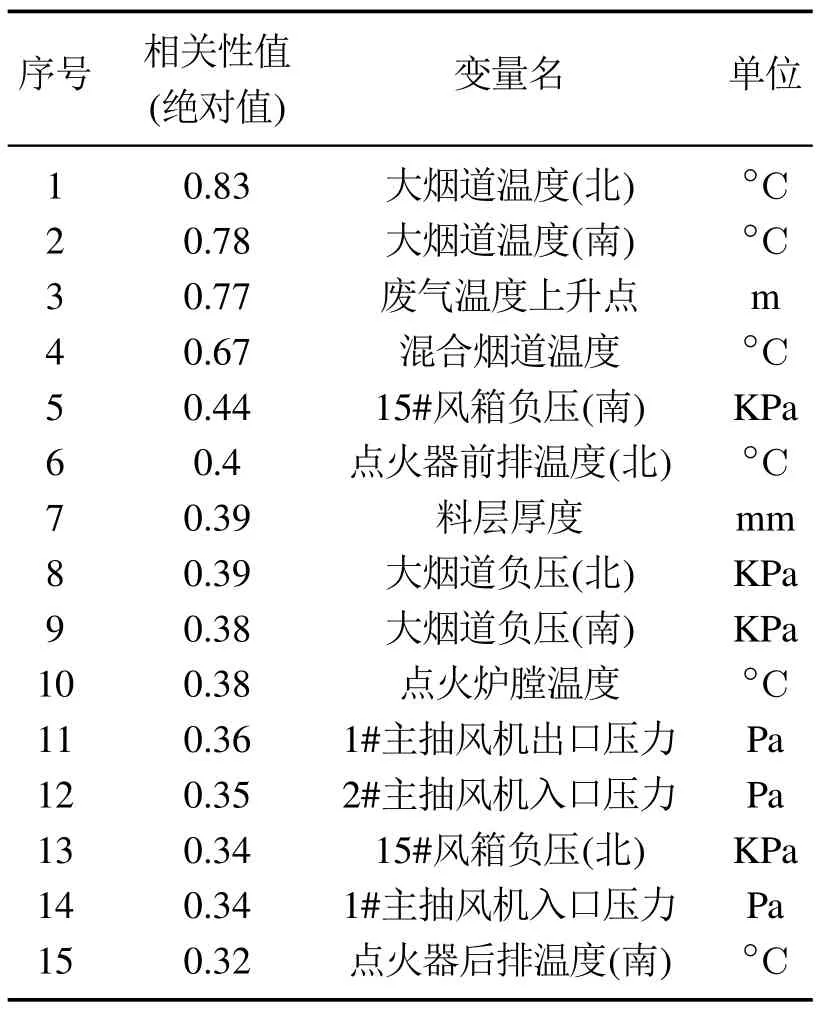
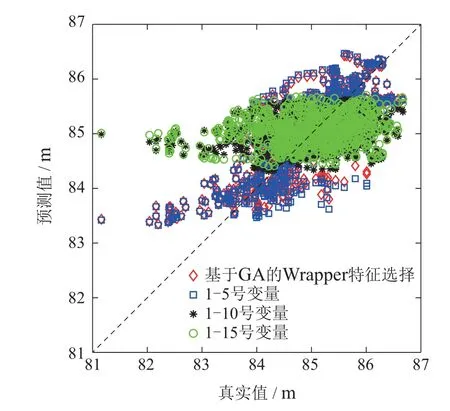
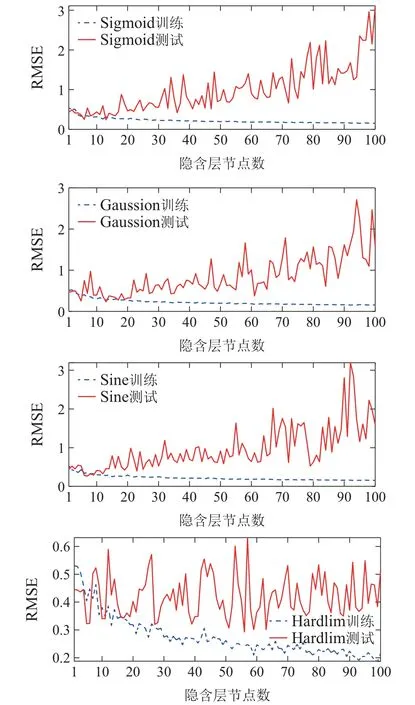
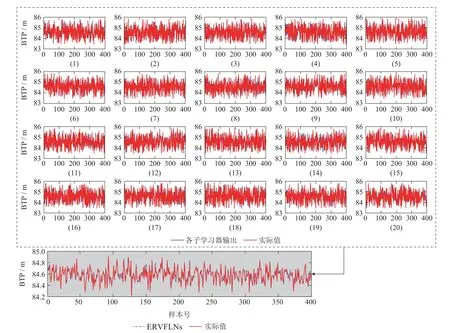
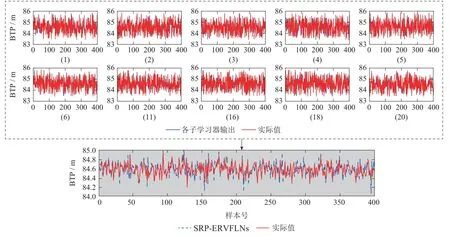
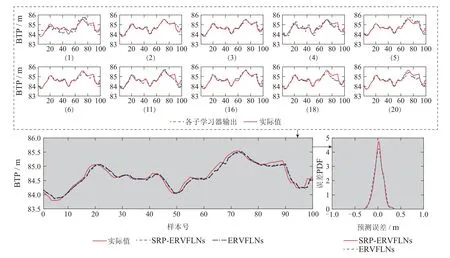
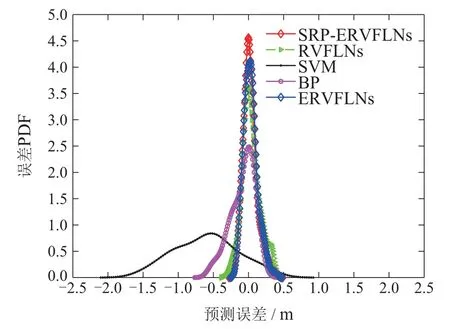
3) 使用SRP算法对集成模型进行剪枝,得到k个RVFLNs子学习器模型,k 4) 用k个RVFLNs子学习器分别对测试集Pe进行预测,得到k个预测值; 5) 取k个预测值的结合(如取k个预测值的平均值)作为最终预测结果. 注1 算法1是解决式(8)所示稀疏表示优化问题常用的OMP算法,而算法2 是本文在算法1基础上提出的稀疏表示剪枝(SRP)算法.所提算法2将稀疏表示优化求解理论应用在集成模型的剪枝问题上,可以实现集成模型的高效剪枝. 为了验证所提方法的有效性和先进性,基于柳钢3号360 m2烧结机的实际生产数据进行工业数据实验.采集到的原始工业数据有26个特征,若从26个特征中选取5个特征,基因串中“1”出现的概率应为5/26.此外,设置初始种群数量为200,采用轮盘赌选择策略,设置交叉率为0.5,变异率为0.2.由于个体学习器选择RVFLNs,因而将RVFLNs的预测均方误差的负值作为适应度函数,最大迭代次数定为200.为了清晰展示算法迭代过程,在图5中仅绘制算法收敛代数的后25代,可以看出所提算法在15代后即收敛.所提算法输出的最优特征组合为BRP、中间烟道温度、大烟道温度(南)、大烟道温度(北)、大烟道负压(北). 图5 基于遗传优化的Wrapper特征选择过程Fig.5 GA-based wrapper feature selection process 为了说明基于遗传优化的Wrapper特征选择算法的优越性,将其与皮尔逊相关性分析方法做比较.为此,采用皮尔逊相关性分析方法分析主要26个特征变量与BTP的相关性,结果如表3所示.然后,使用同样激活函数和隐含层节点数的RVFLNs,将基于遗传优化的Wrapper特征选择算法选取的特征组合,以及皮尔逊相关性分析表3中1-5号、1-10号、1-15号变量分别作为输入变量,对BTP进行预测,预测结果如图6所示.可以看出,使用所提特征选择算法选取的特征所获得的预测结果更接近其真实值,而基于皮尔逊相关性分析得到的1-10号变量、1-15号变量的预测效果都比较差,其原因可能是变量多、引入的噪声干扰较多,从而对预测建模产生不利影响.使用1-5号变量进行预测取得了相对较好的预测效果,但是相比所提算法的预测效果要差.综上分析,相比于传统皮尔逊相关性方法,所提算法能够获得使后续学习器达到更高预测精度的输入特征组合. 表3 皮尔逊相关性分析结果Table 3 Result of Pearson correlation analysis 图6 不同特征组合的BTP预测结果比较Fig.6 BTP prediction results of different feature combinations 将所提SRP-ERVFLNs算法在样本扰动的基础上,对基学习器的参数进行扰动,具体策略为:生成20个RVFLNs 基学习器,激活函数为Sigmoid,Sine,Hardlim和Gaussian 的RVFLNs 子学习器各5个,每个子学习器隐含层节点数在一定范围内随机选取.为了在随机选取隐含层节点数的同时保证每个子模型的准确性,需要确定单个RVFLNs的最优隐含层节点范围.图7是不同激活函数的RVFLNs在不同隐含层节点下的预测效果,其中RMSE为均方根误差(root mean square error).可以看出随着隐含层节,在测试集上的表现越来越差,当隐含层节点数在[10,20]时,不同激活函数RVFLNs学习器在训练集和测试集上均具有较好的拟合效果和稳定的性能.因此,各RVFLNs子学习器的隐含层节点数在[10,20]中随机选取,以此增加集成模型各子学习器的个体多样性. 图7 不同激活函数的RVFLNs子学习器预测效果Fig.7 The prediction effects of RVFLNs based submodel with different activation functions 将采集的工业烧结数据分为训练集和测试集,训练集取前400组数据,测试集数据取剩下的100组数据.将第4.1节得到的最优特征组合作为各个学习器的输入变量,集成剪枝后的子模型数量k设为10,按照第3.3.2节所提算法实现步骤对BTP进行预测建模.首先,为了验证所提稀疏剪枝算法的有效性,将剪枝前后的建模效果进行对比.图8是稀疏剪枝前ERVFLNs各子模型建模效果以及最终集成模型的建模效果,而图9为所提方法剪枝后的集成模型各子模型建模效果及最终集成模型建模效果,各个子图中的序号为选取的剪枝前对应子学习器模型的序号.此外,图10为采用所提方法剪枝后的各个子学习器模型以及最终集成模型的实际预测效果比较.从中可以看出,由于对表现不佳的子学习器模型进行了合理剪枝和舍去,使得集成模型剪枝后的输出相比剪枝前可更准确地跟踪BTP实际值的变化,预测精度更高.此外,从图10可以看出,剪枝后的集成模型的BTP预测误差概率密度函数(probability density function,PDF)形状相比剪枝前更窄和更尖,即预测误差更接近白噪声,随机性小,因而模型准确度更高.综上,剪枝后的集成模型不仅结构更为简单,而且相比于剪枝前的复杂模型具有更高的预测精度和更好的泛化性能,进而也验证了所提剪枝算法的有效性和实用性. 图8 剪枝前的ERVFLNs算法各子学习器预测效果及集成模型最终预测效果Fig.8 The prediction effect of each sub-model of ERVFLNs algorithm before pruning and final effect of the integrated model 图9 所提SRP-ERVFLNs算法各子学习器预测效果及集成模型最终预测效果Fig.9 The prediction effect of each sub-model of the proposed SRP-ERVFLNs algorithm and the final effect of the integrated model 图10 所提SRP-ERVFLNs算法各子学习器对新数据的预测效果及集成模型最终预测效果Fig.10 The prediction effect of each sub-model of the proposed SRP-ERVFLNs algorithm for new data and the final effect of the integrated model 为了进一步验证所提算法的有效性和优越性,将所提算法与常规(support vector machine,SVM)、RVFLNs,反向传播(back propagation,BP)神经网络等算法以及未剪枝的集成RVFLNs,即ERVFLNs算法进行对比.各算法实现的一些重要参数选取如下:SVM的激活函数选择Sigmoid函数,采用网格搜索法分别确定SVM中的惩罚因子为1、核函数参数为0.01;BP神经网络的隐含层激活函数为Sigmoid 函数,隐含层节点数为20;而RVFLNs的隐含层激活函数选为Sigmoid函数,隐含层节点数确定为20;ERVFLNs算法中的相关参数选取与所提算法一致. 图11为所提算法与其他算法的BTP预测效果比较.可以看出,所提算法的BTP预测值能够更好地跟踪BTP实际值的变化趋势.图12为不同方法的BTP预测误差PDF曲线比较,可以看出所提方法的PDF曲线形状最窄和尖,意味着所提方法建立的预测模型的预测误差更接近随机白噪声,这进一步验证了所提算法的有效性和优越性. 图11 不同方法的BTP预测比较曲线Fig.11 Comparison curve of BTP prediction for different methods 图12 不同方法的BTP预测误差PDF曲线比较Fig.12 BTP prediction error PDF for different methods 表4 给出了不同算法的BTP 预测均方根误差(RMSE)和计算时间.可以看出,所提算法具有最小的RMSE,也即最高的预测精度.在预测的计算时间上,所提算法所用时间略长于SVM算法所用时间,但是远小于BP神经网络所用时间,而且也小于剪枝前的ERVFLNs 算法.以上各个方面充分验证了所提算法能够在保证较高预测精度的基础上实现BTP的快速、稳定预测. 表4 不同方法BTP预测的RMSE和计算时间比较Table 4 Comparison of RMSE and prediction time of BTP prediction by different methods 本文提出了一种新型的基于特征优选与稀疏表示剪枝集成建模的烧结终点位置(BTP)智能预测方法.首先,针对BTP常规预测建模方法难以选取最佳特征组合而影响后续预测建模精度的问题,提出基于遗传优化的新型Wrapper特征选择算法.可选取使后续预测算法性能最优的预测建模特征组合.在此基础上,针对单一学习器容易过拟合而实用性差的问题,本文提出了一种基于随机权神经网络(RVFLNs)的稀疏表示剪枝集成学习算法(SRP-ERVFLNs).该方法采用对基学习器的参数进行扰动的方式来提高RVFLNs子学习器模型的多样性,使用稀疏表示剪枝算法对集成RVFLNs模型进行剪枝和删减,以进一步提高BTP预测建模的泛化性能与计算速度.实际工业烧结过程数据实验表明: 相比剪枝前的ERVFLNs 以及常规SVM,RVFLNs和BP神经网络等学习算法,所提SRP-ERVFLNs方法具有更高的预测精度和泛化性能,能够实现BTP的快速准确预测,具有很好实用性.4 工业数据实验
4.1 基于遗传优化的Wrapper特征选择实验
4.2 BTP预测实验


5 结论
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
天津诗人(2017年2期)2017-03-16
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
振动工程学报(2014年4期)2014-03-01
现代防御技术(2014年6期)2014-02-28
