
融合多尺度和频域特征的目标身份识别技术*
2024-04-27 12:12徐勤功郭杜杜
火力与指挥控制 2024年1期
徐勤功,郭杜杜,赵 亮,周 飞
(新疆大学机械工程学院,乌鲁木齐 830049)
0 引言
随着智能感知技术的发展,无源环境下的目标身份识别已经成为军事、民用领域的重点研究技术之一[1],在公安刑侦和军事领域上,可以利用该技术重构目标轨迹,区分敌我目标,实现快速、大范围的精确追踪,是信息化智能战场精准打击的前提;在民用领域尤其是构建智慧城市和智慧交通方面,是实现行人和车辆的身份验证、环境感知和跨视距感知等领域的关键技术[2]。机器视觉是目前实现现代化和智能化感知最直接的方法,其核心是借助可见光设备实现在多个视角非重叠的场景中检出被检目标的图片和身份信息。目前研究主要集中在航空和航海目标上,对地面城市中易受到遮挡、伪装和采集设备限制的坦克、车辆等目标研究较少,受限于资料条件,本文选择地面车辆来进行研究。
近些年来,深度学习在特征提取表现出明显的优异性,因此,可以利用神经网络来提高目标身份识别的效果[3]。车辆具有颜色、车身等显著且不易发生变化的特征,但相机在采集车辆特征时,会受到摄像头分辨率、光线、摆放位置等因素影响,采集的影像常出现偏色和模糊[4]、拍摄视角不同,造成车辆的类内(一辆车称为一类)差异;同时相似颜色、车型的不同车辆之间易产生类间相似,增加了车辆身份识别的难度。
为了解决这些问题,ZHU X 等将车辆纹理和卷积特征融合,获得了更具鉴别性的特征[5],但是忽略了车辆细节特征,因此,对相似车辆的检测不佳。MENG D 等利用视图对齐和共同视图注意力模型来消除类内差异,但是在视角变化大的场景下鲁棒性不高[6]。SHEN F 等利用混合金字塔进行特征融合,增强了网络的表征能力,但是对主干其他尺度的特征利用较少[7]。SUN W 等针对困难样本设计了基于自适应的局部注意力感知分支,但是缺少对全局特征和局部特征的融合利用[8]。CHEN Y 等利用滤波器进行滤波,利用变换对抗模块向样本添加更多的噪声信息,提高了困难样本的识别率,但是滤波器矩阵参数的生成依靠随机选择算法,鲁棒性不高[9]。
基于上述研究启发,提出由多尺度扩张模块、注意力模块和频域卷积模块组成的MSAF 算法,其核心思想是对网络由浅到深的特征信息进行融合后实现取长补短,使得特征更具有代表性;利用注意力机制使得算法自学习特征区域的重要程度;利用傅里叶变换和反变换获得图像的频域信息,提取RGB 信息域中不可见的信息,降低设备偏色、拍摄角度等原因的影响,提高算法的检测效果和精度。
1 算法原理
为了有效地利用车辆的细节特征和全局特征,MSAF 结构设计了全局特征提取主干和多尺度注意力特征融合分支;后处理阶段设计了一种频域卷积模块,用于获得特征的频域信息,并和空间域特征组成融合特征,算法的结构如图1所示。
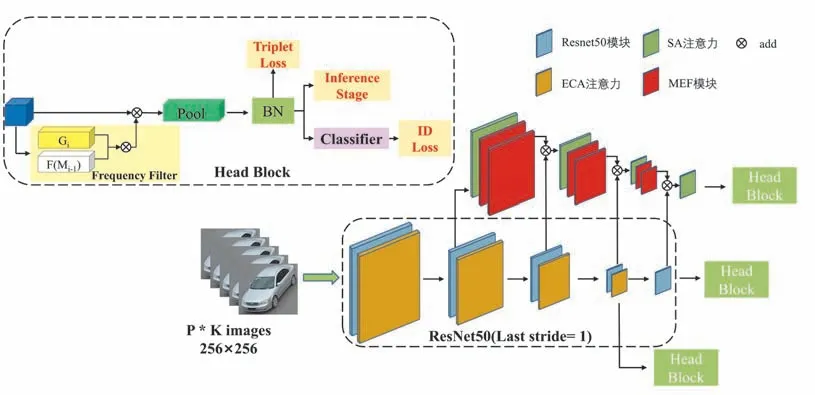
图1 MSAF算法结构Fig.1 MSAF algorithm structure
1.1 基于注意力的全局特征提取分支
在卷积过程中,网络不仅可以提取出图像中类似的车身颜色、框架等浅层特征,也包括全局语义特征[10]。深度越深,特征空间分布范围越广、对特征的空间映射越准确。但是过深的网络会导致梯度爆炸和过度拟合等问题,使得网络性能不增反降,本文选择Strong-baseline[11]作为基线网络,其主干为具有残差结构的Resnet50 网络,残差结构能够保证浅层特征的完整性,并且可以有效抑制网络退化的现象,残差结构的构造如图2(a)所示。
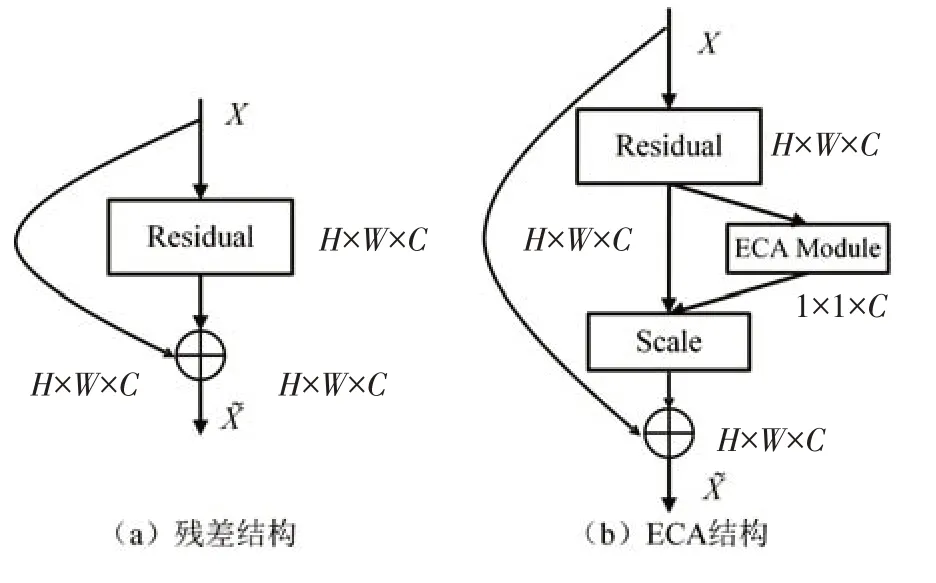
图2 主干网络模块Fig.2 Backbone network module
在网络构建时,设置第4 个残差块步长为1,去除池化层和分类层;为了提高主干网络对高辨识度特征的关注,在第1 阶段和第1~3 个残差块后加入ECA 注意力机制[12],ECA 可以对区分车辆身份更有帮助的特征分配更高的权重,使网络聚焦更为关键的信息,其模块结构如图2(b)所示。对于256×256的输入图像,经过主干提取网络,获得全局特征向量Z∈R16×16×2048。
1.2 基于多尺度和注意力的特征融合分支
1.2.1 多尺度扩张模块
针对类间相似和类内差异问题,利用多尺度融合方法对浅层网络特征和深层网络特征取长补短,对不同深度的特征进行不同粒度的采样融合,生成更具有辨识度的特征。通过改进InceptionV4 模块[13]得到一种自适应的尺度扩张融合模块(MEF),MEF 模块包含尺度扩张(scale)和通道调整(size)两个阶段,原理是利用不同的卷积核扩展特征的多尺度特征。其结构如图3所示。
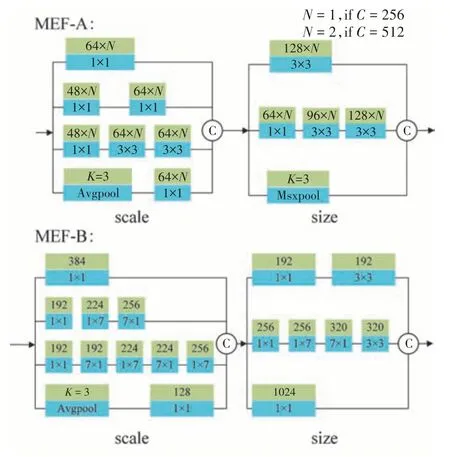
图3 尺度扩张融合模块Fig.3 Scale expansion and fusion module
1.2.2 基于注意力的多尺度扩张模块
局部细粒度特征是区分外观相似车辆的重要特征,每辆车都有自身特有的颜色、车标和挡风玻璃等特征,引入注意力机制可以让算法自学习并调整对各个区域的关注度和权重,使得细粒度特征能够发挥作用来。ZHANGQL 等基于通道重组的思想设计了一种集成通道(channel)和空间(spatial)的注意力模块(shuffle attention,SA)[14],SA模块将特征分为g 组,每一组内都进行spilt操作划分为两个分支,分别引入channel attention 和spatial attention 对所在组的特征进行权值学习,最后对特征进行通道重组,打通特征图通道间的信息。
其中,S为输入特征;σ为sigmoid函数;b1为偏移量。
空间分支的公式为:
其中,S为输入特征;σ为sigmoid函数;b2为偏移量。
在每个MEF 模块前加入SA 模块组成基于注意力的多尺度扩张模块(MEAF),MEAF模块可以对多尺度融合特征图的通道信息和空间信息进行自适应的特征权重学习,聚焦网络关注车辆图像内的关键信息,有效利用相对较弱的显著细节特征。
1.2.3 多尺度阶梯融合
对Resnet50 结构进行划分,每一个残差模块划分为不同的特征阶段Xi,i∈[1,2,3,4],X1经过MEAF-A 模块进行尺度扩展和尺寸调整,得到大小为32×32 的M1,再和X2进行融合,生成M2再输入到MEAF-A 进行尺度扩展和尺寸调整,调整后的M2大小为16×16,对M2和X3进行融合得到M3,M3输入到MEAF-B 模块中,调整后的M3输入到SA 模块中,得到最后的特征图。
1.3 后处理
1.3.1 频域卷积模块
现实道路中存在相似车辆,军事领域中也普遍进行迷彩和伪装等隐匿措施,同时设备成像偏色、角度等问题可能导致目标的某些特征在RGB 域中不明显,而在频域中仍可以被检测到[15-16],为此本文提出利用频域信息来对RGB 空间域进行信息补充,设计频域流卷积模块(frequency convolution,FQC),利用傅里叶变换将卷积特征转换为频域信息,从特征频率特性的角度来解析特征,使用频域滤波器Qi滤除无用信息,融合卷积信息和频域信息获得最终的特征,结构如图4所示。
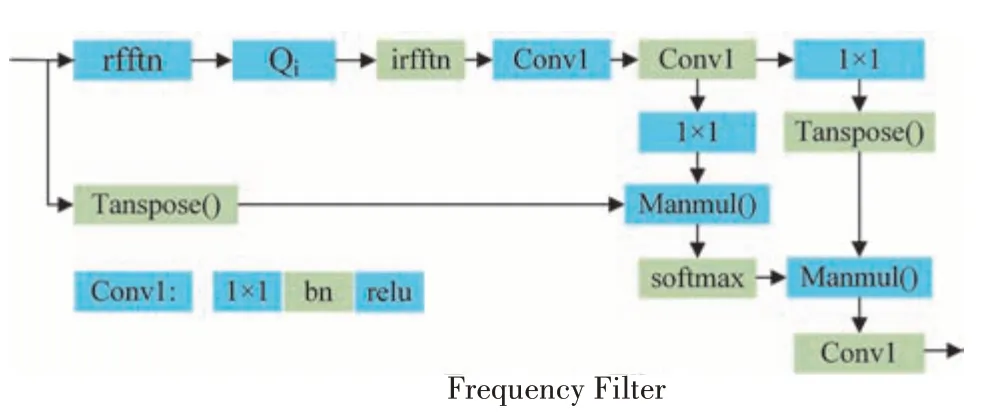
图4 频域流卷积模块Fig.4 Frequency domain flow convolution module
其中,⊙为哈达玛积。
1.3.2 阶梯辅助训练
将X4作为主干特征、前置特征X3作为网络辅助训练分支,设置X3特征仅参与训练,增强网络的特征的拟合效果,不参与预测过程。
1.3.3 Head Block流程
主分支、多尺度融合分支和辅助训练分支特征输入至Head Block。Head Block 包含频域卷积、池化、归一化和分类等步骤。特征经过频域卷积后,进行全局平均池化(GAP)和归一化处理(BN),BN层可以使得特征f的空间映射更符合呈现高斯分布,更有利于身份损失(ID loss)收敛,因此,将BN 层后的特征送入三元组损失(triplet loss),FC层后的特征送入身份损失ID loss进行训练。
2 实验与分析
2.1 数据集
本算法选择在两个主流的车辆重识别数据集VeRi776[17]、VehicleID[18]上进行实验。
VeRi776 数据集是在真实监控场景下采集到的车辆重识别数据集,数据集共有776 辆车,包含9 种车型和10 种颜色,每辆车由2~18 个分布不同的摄像头拍摄采集,涵盖了车辆在不同视角、光照、分辨率等环境下的高现实性的图像,数据集共计51 035张图像,其中,训练集包含576辆车在内的37 778张图像,验证集和测试集包含200 辆车,Query 含有1 678 张图像,Gallery 共计11 579 张图像。
VehicleID 数据集来源自某地真实道路监控摄像头拍摄采集的大型图像库,数据集包含了26 267辆车在内的221 763 张图像,训练集包含13 134 辆车在内的110 178 张图像,测试集选择Test800、Test1600 和Test2400,其中,Test800 测试集为800 辆车图像组成的测试集,包含6 532 张图像,Test1600测试集包含11 395 张图像,Test2400 包含17 638 张图像。
2.2 评估指标
图像检索准确率(rank)和平均精度曲线(mean average precision,mAP)是目标身份识别任务中常用的算法性能评价指标。
Rank-n表示算法对图像检索结果的前n张图像命中准确率,因此,本研究选择Rank-1 和Rank-5作为算法主要评价指标。计算公式如下:
其中,Q为Query 图片数;lq为第q张图像的id;ln为n张图像包含的id集合。
mAP 是在考虑所有样本的情况下,计算Query样本的准确率和曲线下的面积平均值,代表着样本在Gallery 中所有正确结果排名靠前的程度,因此,可以更加全面地衡量车辆身份识别算法性能,计算过程如下:
前n张图片的准确度:
前n张图片的召回率:
平均精度Ap:
其中,
平均精度均值mAP:
2.3 实验参数设置
本实验基于AMD Ryzen 9 5950X、NVIDIA Ge-Force RTX3090TI核心配置下的PyTorch框架编写完成,算法输入的图片大小均设置为256×256,并经过随机裁剪、擦除等处理;采用默认参数的Adam 优化器,初始学习率为0.000 35,前10 个epoch 采用预热学习率,设置40个epoch后实行学习率梯度衰减,衰减速度为0.01,每30 个epoch 衰减一次,训练共设置120个epoch,每个batch的大小为40。
2.4 消融实验
本研究提出融合多尺度和频域特征的目标身份识别技术,利用多尺度特征融合提取车辆的空间域特征,利用频域卷积提取车辆的频域特征。记Baseline 网络模型为B,全局分支记为BE、多尺度分支为M、Head Block 中使用FQC 频域卷积模块记为F,均使用辅助训练分支,在VeRi776 数据集上验证各个模块的精度的结果如表1所示。
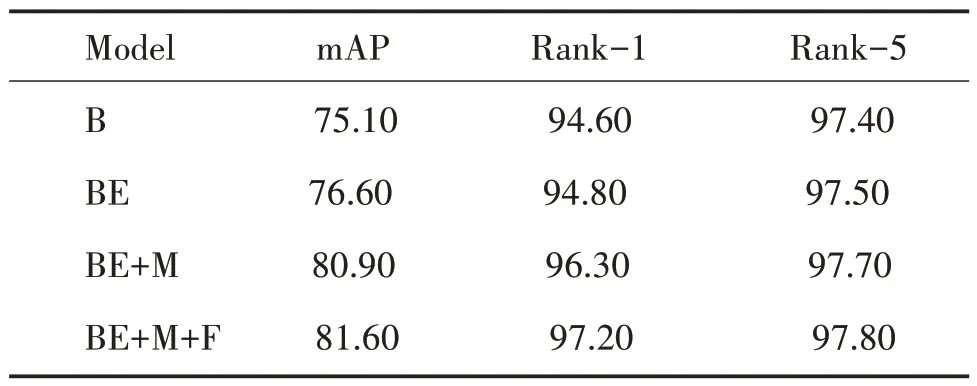
表1 算法在VeRi776数据集上的消融实验∕%Table 1 Ablation experiment of algorithm on VeRi776 dataset∕%
由表1 可知,Baseline 加入ECA 注意力机制后,平均精度mAP 提高了1.50%;模型增加MEAF 分支后,融合的多尺度特征表征能力更强,使得mAP 上升了3.30%,Rank-1 和Rank-5 分别提高了1.50%和0.20%;在使用FQC 频域卷积模块后,频域信息和多尺度特征的融合特征具有更强的表征能力,最终本实验在VeRi776 数据集上mAP 达到了81.60%,Rank-1和Rank-5分别达到了97.20%和97.80%。
为了更好地理解MSAF 中多尺度分支和频域卷积的影响,本文可视化了类激活图来展示MSAF 对特征的关注点,Baseline 和MSAF 对比结果如图5 所示,图中颜色突出的区域表明特征在度量车辆图像相似度时起着更重要的作用,可以看到Baseline 的关注点主要集中在车辆前后灯或载物等单一辨识点上,MEAF 算法的关注点更丰富,图5(a)中Baseline关注了许多干扰识别的背景噪声,而MSAF网络不仅关注主体特征,也关注分布在侧身和车尾的细微特征,这些特征虽然在检索图的重要度相对靠后,但是对于跨视角、跨分辨率等场景的识别至关重要。
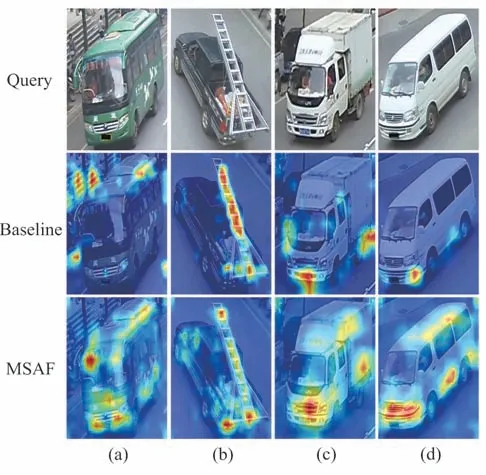
图5 类激活图Fig.5 Class activate picture
2.5 对比实验
为了验证本文算法的有效性,本实验分别使用两种数据集进行实验验证,并将结果与近两年主流模 型(Baseline[11]、PVEN[6]、LCD[19]、LBT[9]、TBE[8]、HPGN[7]、MUSP[20]、VOLO[21]和UFDN[22])做比较,实验结果均来自模型论文,其中,“-”表示论文中未明确给出;FPS 的单位是张∕s,表示测试集内图像数(Veri776 为11 579 张)与测试时间(s)的比值;mAP、Rank 指标的单位为%;Params 表示模型参数量,单位为兆字节M;GFLOPs 表示模型的运算量,单位为十亿次G,对比结果如表2、表3所示。
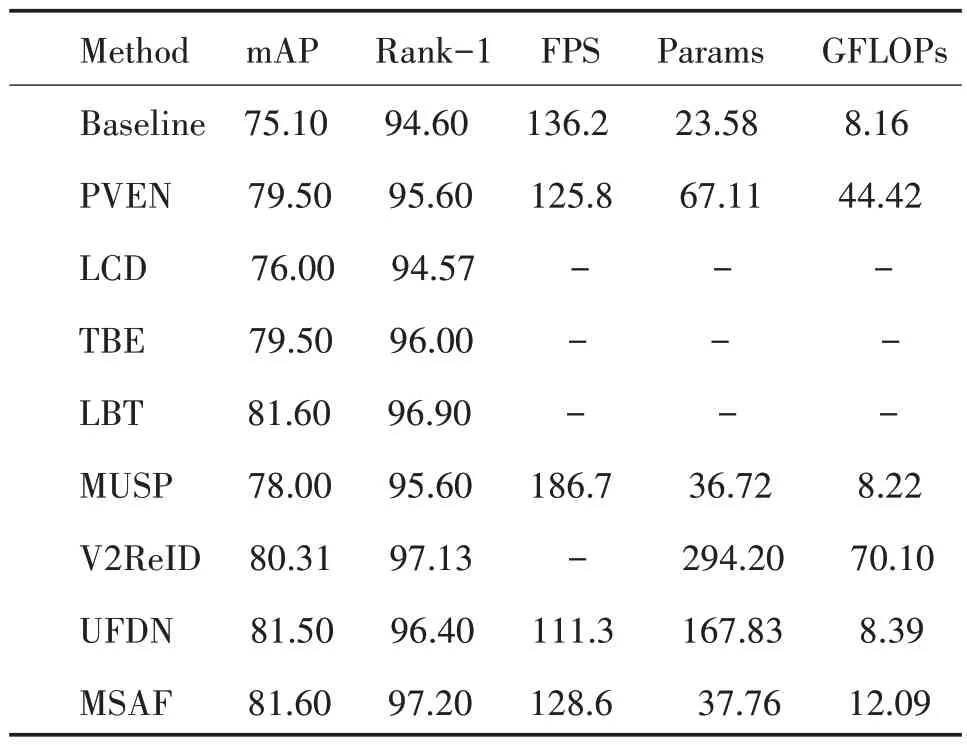
表2 VeRi776数据集对比结果∕%Table 2 Result comparison of VeRi776 dataset∕%
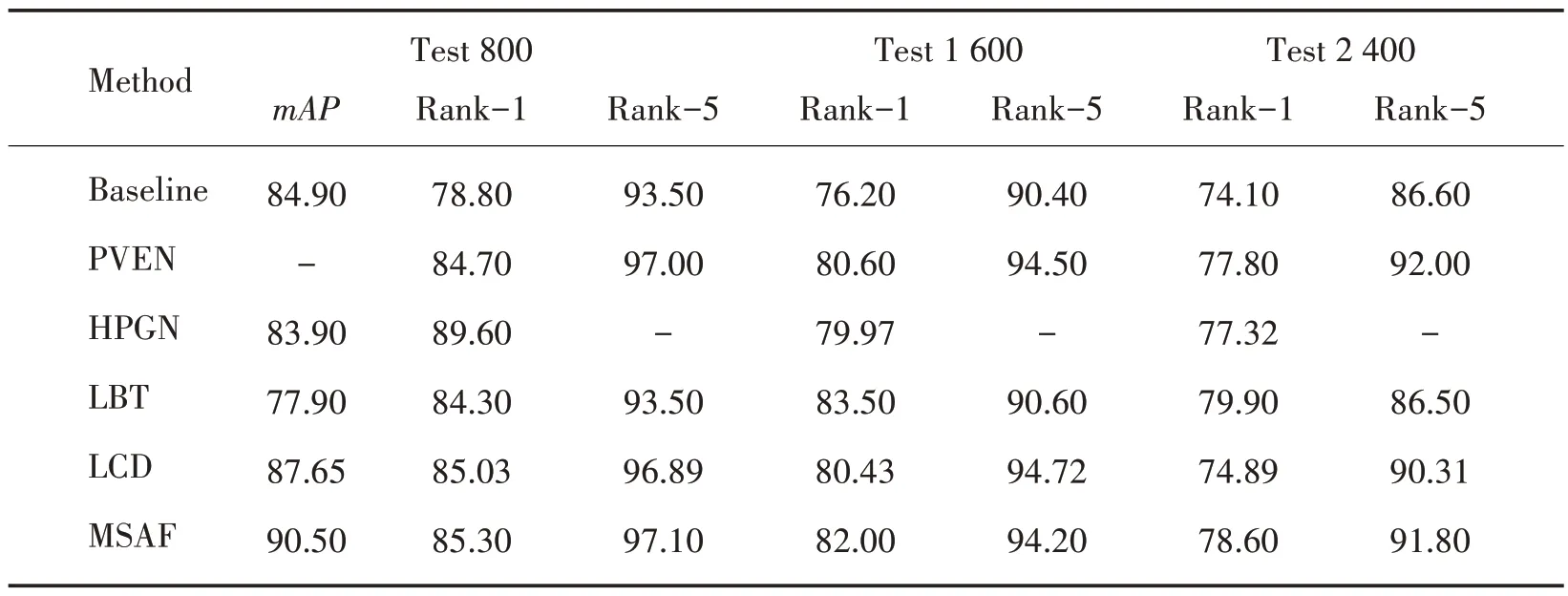
表3 VehicleID数据集对比结果∕%Table 3 Result comparison of VehicleID dataset∕%
由表2可知,在VeRi776数据集的实验中,Baseline、PVEN、LCD、TBE、MUSP、VOLO 和UFDN 分别取得了75.10%、79.50%、76.00%、79.50%和81.60%、78.00%、80.31%和81.50%的mAP,而MSAF 和LBT取得了81.60%,相对其他网络分别提升了6.50%、2.10%、5.60%、2.10%、3.6%、1.29%、0.1%;MSAF 算法Rank-1 也达到了97.20%,比其他网络分别提高2.60%、1.60%、2.63%、1.20%、0.30%,1.6%、0.07%和0.8%,比LBT高0.3%。
由表3可知,在VehicleID的Test 800数据集的实验中,本研究取得了90.50%的mAP,Rank-1和Rank-5 分别取得85.30%和97.10%,mAP 比Baseline、HPGN、LBT 和LCD 模 型 分 别 提 高 了5.60%、6.60%、12.60%和2.85%。Rank-1比Baseline、PVEN、LBT和LCD提高了9.50%、0.60%、1.00%和0.27%,Rank-5分别提升了3.60%、0.10%、3.60%、0.21%。
综合来看,本算法的Params 和GFLOPs 仅有37.76 M 和12.09 G,FPS 指标达到128.6 张∕s,仅比Baseline少了7.3;和PVEN、MUSP、UFDN这类基于视图对齐的方法相比,MSAF 在跨视图场景更具优势,Params和GFLOPs比PVEN少了29.35 M、32.33G,FPS领先2.8;Params仅比MUSP多1.04 M,却实现了3.6%的mAP提升;UFDN 利用Transformer 分支进行视角区分,因此,参数达到167.83 M,但是抗视角变换效果仍不佳;与HPGN 混合金字塔模型和TBE 自适应局部感知分支模型相比,算法使用MEAF 模块来融合全局特征和局部细节特征,获得了更好的性能;LBT 模型滤波器性能取决于感兴趣区域的选择,本算法利用可学习的频域滤波器滤除无用信息,提取特征更具稳定性;与基于Transformer 的V2ReID 大网络(Params 和GFOLPs 达到294.20M、70.10G)相比,MSAF 使用更少的参数获得了更高的性能,证明本算法所用的多尺度特征和频域特征比多头注意力机制更高效。
2.6 可视化
为了更直观地证明本文算法的作用,选择2 000个样本在t-SNE 算法中对Baseline 和MSAF 的结果进行身份分布可视化,结果如图6 所示,可以看出MSAF中同类点的分布更加聚集,表明MSAF实现了更好的身份识别效果,能够有效克服类内差异和类间相似问题。
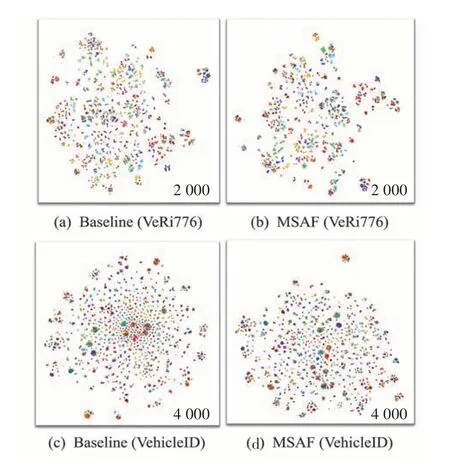
图6 t-SNE特征分布可视化Fig.6 Feature distribution visualization of t-SNE
下页图7 显示了MSAF 部分Rank-5 排序结果,可以看到在应对相似车型、光线变换和视角转换等困难场景时,MSAF 算法仍能稳定识别,获得较高的准确率和鲁棒性。

图7 VeRi776数据集Rank-5识别结果可视化Fig.7 Visualization of Rank-5 identification results of VeRi776 dataset
3 结论
本文提出一种在无源感知的视觉融合环境下,针对身份识别中由于目标隐匿遮挡、伪装和拍摄设备存在分辨率、角度和光线的差异而影响身份识别精度问题,利用多尺度融合和注意力机制,引导网络学习更高辨识度的细节特征;提出将频域信息作为补充信息,设计频域卷积模块,利用傅里叶变换获得频域特征和空间域特征组成融合特征;提出利用前置特征来对判别特征进行辅助训练,在多个数据集上实现了更高、更具鲁棒性的目标身份识别。
猜你喜欢
舰船科学技术(2022年22期)2022-12-13
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年11期)2019-07-04
雷达学报(2018年3期)2018-07-18
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
火控雷达技术(2016年1期)2016-02-06
电测与仪表(2015年3期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
