
基于交互关系的微博用户标签预测*
2013-05-08 13:39陈儒华
计算机工程与科学 2013年10期
汪 祥,贾 焰,周 斌,陈儒华,韩 毅
(1.国防科学技术大学计算机学院,湖南 长沙410073;2.北京大学信息科学技术学院,北京100871)
1 引言
近年来,以用户社区贡献内容为核心的社交网络飞速发展,Youtube、Flickr和新浪微博等是其典型代表。在这些社交媒体中,用户可以自由地上传个性化的文字、图片、视频等内容,并且其可以使用一些描述性的关键词(即标签)对这些内容进行标记,以方便自己和其他用户阅读所上传的内容。这些描述性标签的上传,不仅让用户可以更好地组织和访问上传的内容,也方便了系统对用户所分享内容的检索。
新浪微博自从2009年8月推出以后,迅速成为中国访问量最大的微博网站之一,其占中国微博活动总量的87%。截至2012年12月底,新浪微博注册用户已超5亿,占中国微博用户总量的57%。在新浪微博中,用户可以给自己打标签,以对自己的兴趣、特点进行标识。图1是前Google中国区总裁李开复给自己打的标签。这些标签表明了用户本身的特点,可以让别的用户更好地了解自己和区别于别人,也给网络营销、系统推荐和广告推送等商业应用提供了良好的契机。

Figure 1 Lee Kai-fu and his tags图1 李开复及其标签
在新浪微博中,虽然很多用户给自己定义了标签,但是也有很多用户没有给自己定义标签。我们使用Sina微博的API爬取了144 210 854个用户及其标签并分析了用户标签数目的特点。图2表明了用户给自己定义的标签数目和用户数目之间的关系。从图2中可以看出,没有标签的用户数目最多,占总用户总数的78.2%,标签数小于5的用户占用户总数的93.8%。如何给没有标签或标签较少的用户进行标签预测是一个重要的问题。
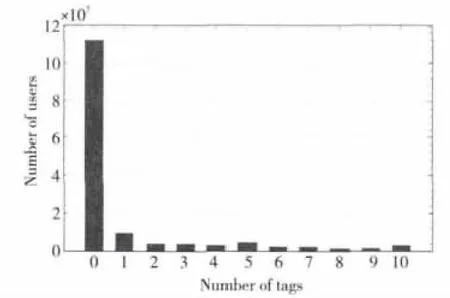
Figure 2 Statistics of user tags图2 用户标签数目分布
传统的标签预测方法一般分为基于内容的标签预测方法和与内容无关的标签预测方法,前者主要基于文档的内容进行标签预测,而后者主要依赖于用户的历史标签记录等。但是,在新兴的社交网络中,用户之间通过关注/粉丝(好友)关系、回复、转发和提及关系等构成了复杂的链接关系。Aggarwal C C等人[1]在其文章中指出,如何利用社交网络中丰富的链接关系是社交网络研究的重要内容。本文基于新浪微博中用户之间的强交互关系,即用户之间的转发和提及关系构建其用户之间的链接关系,并基于用户之间的这种链接关系对用户的标签进行预测。
2 相关工作
在标签系统中,用户以关键词或者短语的形式向某种资源添加描述数据。Golder S和 Huberman B A[2]分析了标签的特点和不同的用法,将标签分为描述资源主题的标签、描述资源类别的标签、描述资源特征的标签和个性化分类标签等。Halpin H等人[3]对资源标签的演化过程进行了分析,发现一个资源的热门标签不会随着时间的改变而改变,标签的使用服从幂律分布。
标签推荐技术一般可以分为基于内容的标签推荐技术和与内容无关的标签推荐技术[4],也有研究者尝试将两者融合在一起以提高算法的性能。在基于内容的标签推荐技术中,Ohkura T等人[5]基于文本分类的方法进行标签推荐,使用SVM方法判断标签是否属于某文档,该方法被应用于基于标签的网页浏览辅助系统。Katakis I等人[6]用层次式分类算法进行标签推荐,其中每个标签被认为是一个类别。在与内容无关的标签推荐技术中,Xu Z等人[7]提出一种类似于HITS算法的方法,该方法为每个用户指定一个权威指标,以便描述用户历史标记行为的质量。这种方法的结果通常可以覆盖多个层面的信息,其推荐的标签具有较高的使用频率。Hotho A等人[8]提出的FolkRank算法也被应用于标签推荐中[9],其模拟用户在资源正文与用户信息等页面之间的跳转过程,其核心思想是被重要的用户使用重要的标签标注的资源,其自身也是重要的。张斌[9]等尝试将与内容无关的标签推荐技术和基于内容的标签推荐技术融合在一起,提出了一种基于LDA的标签系统生成模型TSM/Forc,用于融合描述标签系统中对象间关系和资源的内容特征。
Pennacchiotti M 等人[10]提出了一种在社交媒体Twitter上进行用户分类的方法。首先基于机器学习的方法从用户的描述信息、用户的发帖特征和博文内容等信息中对用户的特征进行标记;然后基于用户之间的好友关系对得到的标记进行更新。
在社交媒体Flickr中,图片可以被标记上多个标签,这些标签是无序的。很多研究尝试在Flickr上进行标签推荐和基于标签的图片搜索等。Liu等人[11]尝试在Flickr中对无序的标签进行排序,使得标签以不同的权值表示图片的内容,他们将排序后的标签应用于基于标签的图片检索、标签推荐、群组推荐等应用中,取得的效果比标签没有排序时更好。Xiao等人[12]提出了一种对图片的标签进行排序的方法,使用潜在语义索引模型来分析标签之间的相关性,使用图形图像的方法来分析图片之间的相关性,然后使用随机游走的方法得到图片标签的权值,并依据此权值对标签进行排序。
Heymann P 等 人[13]在 图 书 标 签 网 站 (del.icio.us)上对图书的标签进行预测,发现使用图书页面的文本内容、链接描述信息以及临近图书标签信息等就足以对图书的标签进行预测,其它信息并不能显著地提高标签预测的性能。
在社交网络中,不同的用户对其他用户的影响程度是不同的,很多文献对用户之间影响力的计算方法进行了研究。Ding等人[14]尝试在Twitter中发现影响力最强的个体,其在回复、转发、评论和阅读的多关系网络中进行随机游走,以衡量一个用户的影响力。Cha等人[15]比较了使用入度、转发和提及计算用户影响力的方法,发现用户的影响力不是自发或偶然获取的,而是通过不同的努力获取的。
3 基于用户交互关系的标签预测方法
3.1 用户交互关系图的构建
在新浪微博中,用户之间的关系包括关注/粉丝关系、评论关系、转发关系、提及关系(@某用户),其中关注/粉丝关系属于静态关系,而评论关系、转发关系和提及关系属于用户交互而产生的关系,具有动态性。用户之间的这种交互关系是一种比关注/粉丝关系更强的关系,反映了用户之间对某特定话题的共同兴趣。在标签推荐方法中,我们认为标签可以借助这种反映用户之间共同兴趣的交互关系而得到传播。
为了研究方便,我们使用一个加权有向图G=(V,E,W)来表示用户之间的交互关系构成的交互图。对于一个特定的用户ui,在新浪微博中会有不超过十个标签来对用户的特征进行描述,如图1中李开复的标签。本文使用Tui来表示用户ui的标签集合,使用wuitj来表示用户ui和标签tj之间的相关度,其中tj∈Tui。在初始情况下,用户标签的初始权值都相等,为1/Tui。本文使用Wui来表示用户ui的所有标签与ui的相关程度的集合,那么,在交互图G = (V,E,W)中,一个顶点vi(vi∈V)可以表示为vi= (ui,Tui,Wui)。
在交互图G=(V,E,W)中,顶点之间的边为用户之间的交互关系,即评论、转发和提及关系。一个用户ui如果评论、转发或者提及了用户uj,那么我们认为在图G中有一条从用户uj到用户ui的有向边,在交互图G中即一条从vj到vi的有向边eji(vj→vi)。边的权值的大小反映了标签从一个顶点转移到另一个顶点的概率,转移概率的计算方法将在下一节详细讨论。
3.2 标签在交互图中的传播
在交互图G=(V,E,W)中,用户之间通过交互关系构建起了两者之间的连接。用户之间的交互关系说明了用户之间有共同感兴趣的话题,用户ui评论、转发和提及用户uj说明用户ui受到了用户uj的影响,那么,是用户uj的标签向用户ui传播呢?还是用户ui的标签向用户uj传播呢?本文认为,如果用户ui评论、转发和提及用户uj,可以认为用户uj影响了用户ui,即用户uj的标签可以向用户ui传播。另外,如果ui评论、转发和提及用户uj,也可以认为用户ui的标签验证了用户uj的标签,即标签可以从用户ui传播到用户uj。从上面的论述可以看出,如果用户ui评论、转发和提及用户uj,那么标签既可以从用户ui传播到用户uj,也可以从用户uj传播到用户ui,还可以在两者之间进行双向传播。本文在后面的实验中尝试了上述三种传播方向,以论证哪种传播方法是最有效的。
本文将讨论如何计算节点间的标签转移概率。在交互图G中,使用用户之间的评论、转发和提及关系数计算边eji(vj→vi)的权值。边eji(vj→vi)的权值反映了用户之间的影响强度,如果用户ui评论、转发和提及用户uj的次数越多,则ui对uj的影响强度越大,即ui和uj的标签有更大的概率在彼此之间进行传播。在计算标签从用户ui转移到uj的转移概率tran(uj→ui)时,用户之间的评论、转发和提及关系都认为是相同的关系而不加区分。
本文采用两种方法来计算用户间标签的转移概率。第一种方法的计算公式如式(1)所示:

其中,fcomm(ui,uj)表示用户ui评论、转发和提及用户uj的总次数,commSet(ui)表示所有被ui评论、提及和转发的用户集合。从式(1)中可知tran(vj→vi)满足0≤tran(uj→ui)≤1。
第二种方法的计算公式如式(2)所示:

其中,fcomm(ui,uj)表示用户ui评论、转发和提及用户uj的总次数,commSet′(uj)表示所有评论、提及和转发了用户uj的用户集合。从式(2)可知tran(uj→ui)满足0≤tran(uj→ui)≤1。
3.3 用户标签的更新
在图G=(V,E,W)中,一个用户ui可以和多名用户之间产生交互关系,这些与之交互的用户的标签将以一定的转移概率传播到用户ui。假设与用户ui拥有交互关系并将标签传播到用户ui的用户集合为tranSet(ui),那么,传播到用户ui的标签集合tagSet(ui)满足式(3)描述的条件:

如果用户集合tranSet(ui)中的用户数量很大,那么标签集合tagSet(ui)的数量将会非常大,因为每个用户都有自己不同的标签。通常我们选取top-k个标签作为用户ui的标签。标签的权值等于所有相关用户当前标签的权值乘以其转移概率后所得值之和,标签tm(tm∈tagSet(ui))的权值采用式(4)进行计算:
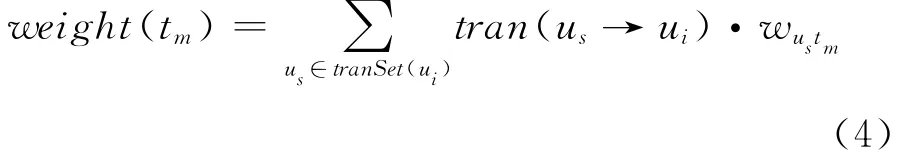
在实验中,我们将k的值设定为20,即只保留用户的top-20个标签。
式(1)和式(2)给出了用户之间标签转移概率的计算方法。结合之前讨论的标签的传播方向的不同,得到以下几种标签传播方法:
(1)如果用户ui转发或提及了用户uj,那么用户uj的标签以根据式(1)计算得到的转移概率传播到用户ui。
(2)如果用户ui转发或提及了用户uj,那么用户uj的标签以根据式(2)计算得到的转移概率传播到用户ui。
(3)如果用户ui转发或提及了用户uj,那么用户ui的标签以根据式(1)计算得到的转移概率传播到用户uj。
(4)如果用户ui转发或提及了用户uj,那么用户ui的标签以根据式(2)计算得到的转移概率传播到用户uj,而且用户uj的标签以根据式(2)计算得到的转移概率传播到用户ui,这样标签将在拥有交互关系的用户之间双向传播。
(5)这种方法是目前最常用的方法,其将周边所有用户的标签作为自己的标签,我们将此方法作为Baseline方法。此方法可以描述如下:如果用户ui转发或提及了用户uj,那么用户ui的标签以1的转移概率传播到用户uj,而且用户uj的标签以1的转移概率传播到用户ui,标签将在拥有交互关系的用户之间双向传播。标签在传播过程中不考虑标签在原用户处的权值。
上述五种方法中标签在网络中不断迭代传播,直至算法达到一个稳定的状态。
4 实验
4.1 新浪微博数据集
新浪微博是基于用户关系的信息分享、传播以及获取信息的平台,是目前国内访问量最大的网站之一。新浪微博开放平台提供了访问新浪微博平台的API接口,用户可以通过API接口获取网站内容。本文基于新浪微博的API接口爬取了新浪微博的转发、提及关系以及用户的标签等信息,统计如表1所示。
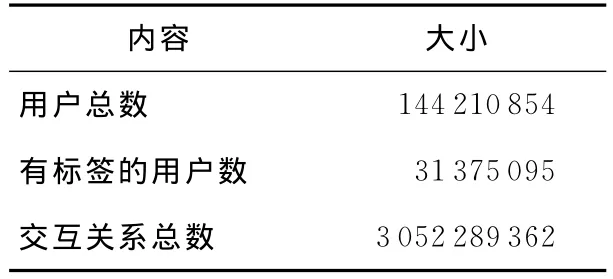
Table 1 Statistics of sina weibo dataset表1 新浪微博数据集统计
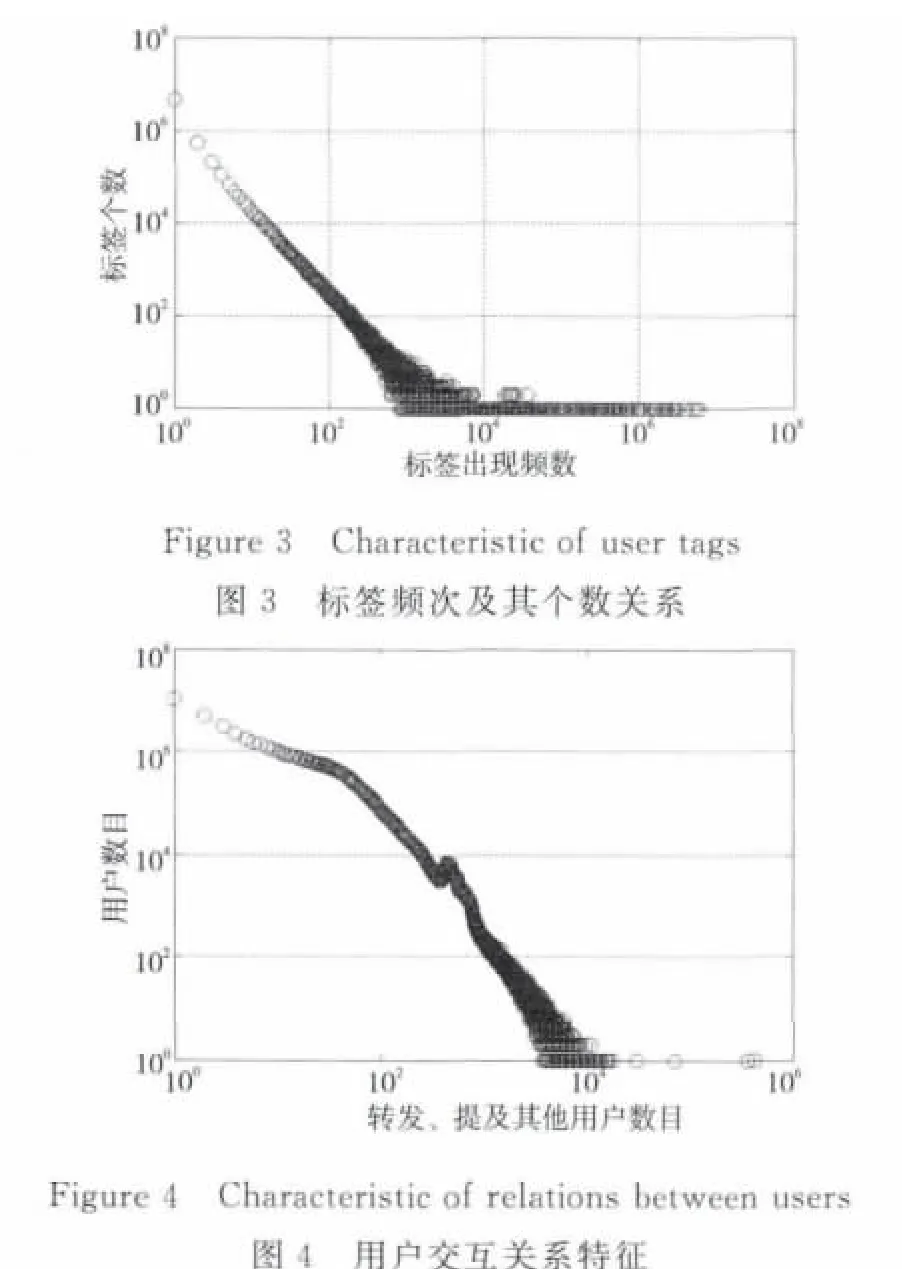
图3显示了本数据集中标签出现的频次与标签个数之间的关系。从图3可以看出,绝大部分的标签出现的频次较少,而出现频次较多的标签的数目也很少。78.87%的用户标签只出现了一次,93.84%的用户标签出现的次数不大于5,所以在新浪微博中只有很少一部分标签是大家都采用的标签。
图4显示了本数据中用户转发、提及其他用户的数目与用户个数之间关系的特征。从图4可以发现,绝大多数用户转发、提及其他用户的数目较少。71.2%的用户转发、提及其他用户的数目不大于5,而75.45%的用户转发、提及其他用户的数目不大于10。
4.2 MapReduce并行处理框架和测试集的构建
从表1中可以看出,待处理的数据集非常大,节点数超过了1.4亿,用户边数超过了30亿,单机处理如此庞大的数据对于普通的机器来说难以实现,我们采用MapReduce并行处理框架来实现本文提出的算法。实验采用了24个节点的Hadoop集群,Hadoop集群中的每个节点采用的是Intel(R)Xeon(R)4核处理器和32GB内存。
本文构建了测试集来测试算法的性能。测试集的构建方法是将一定数量的标签数大于8的用户的标签删去,用本文提出的方法来给这些删除标签的用户打上标签,最后将算法得到的标签与用户自己标记的原始标签进行比较。本文选取了三组测试集,每组数据集都包含3 000个用户。为了保证测试集数据选取的随机性,采用随机数的方法来判定某一符合条件的数据是否加入测试集中。第一组测试集包含3 000个转发(或提及)其他用户的总数在50~60之间且被其他用户转发(或提及)的总数也在50~60之间的用户;第二组测试集包含3 000个转发(或提及)其他用户的总数在100~150之间且被其他用户转发(或提及)的总数也在100~150之间的用户;第三组测试集包含3 000个转发(或提及)其他用户的总数在300以上且被其他用户转发(或提及)的总数也在300以上的用户。
4.3 实验结果
本文对3.3节中描述的五种方法进行了实验,并采用前N条结果的准确率P@N和前N条结果的召回率R@N来对算法的性能进行评价。
表2~表4分别显示了这五种方法在第一组、第二组和第三组测试集上的性能评价结果。由于新浪微博中用户最多允许的标签数为10,因此在P@N 上只选取了P@1/P@3/P@6和P@10,在召回率上只选取了R@20作为评测指标。
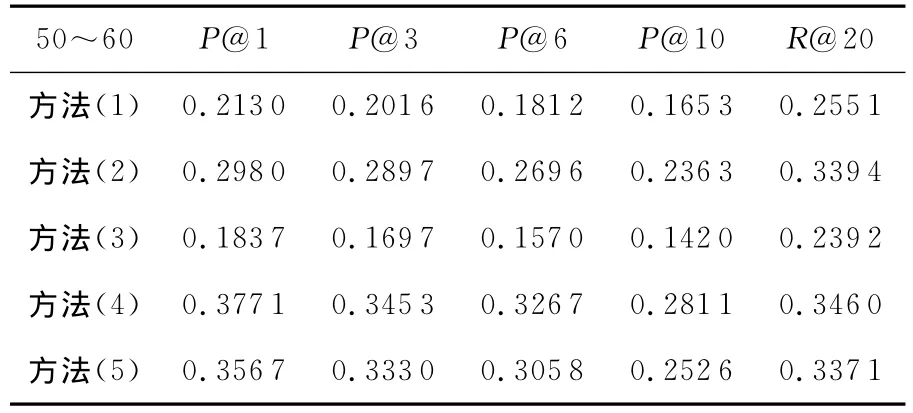
Table 2 Performance of algorithms in dataset 1表2 算法在第一组测试集上的性能
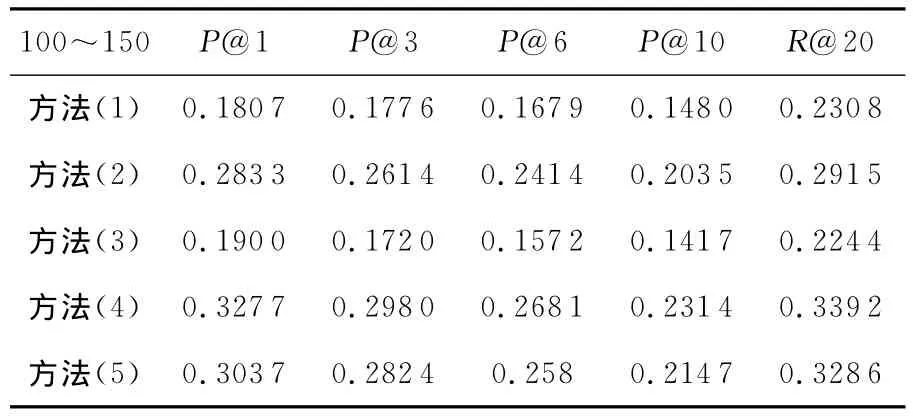
Table 3 Performance of algorithms in dataset 2表3 算法在第二组测试集上的性能
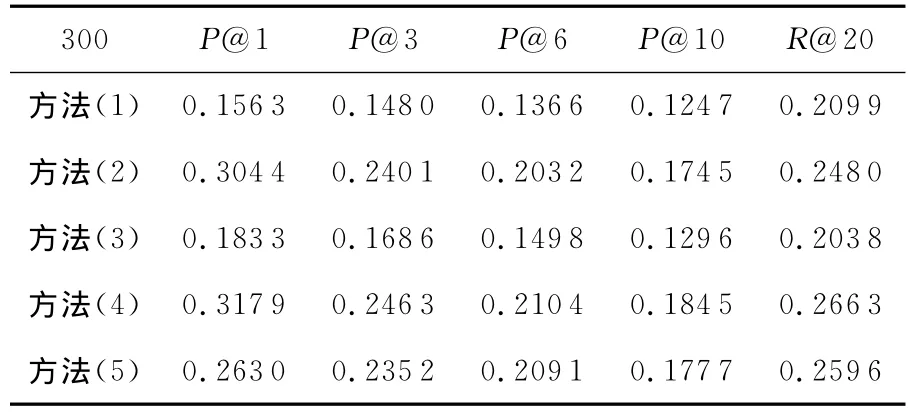
Table 4 Performance of algorithms in dataset 3表4 算法在第三组测试集上的性能
从表2~表4可以看出,方法(4)在三组数据集上的各项评价指标都获得了最好的结果。Baseline方法(方法(5))比方法(4)在所有测试集的各项参数上都要差,但是比方法(1)和方法(3)都要好。方法(2)并不是在所有测试集上都比Baseline方法差(方法(5)),如在交互关系较多的第三组测试集上的P@1和P@3比Baseline方法好。
图5显示了五种方法在一个特定评价指标(P@1、P@3、P@6、P@10、R@20)上的变化趋势,从图5和表2、表3、表4的数据中发现,从测试集1到测试集3,除了方法3不是很明显之外,其余算法的各项评价指标显示的性能都在下降。我们知道,从测试集1到测试集3,用户与其他用户交互的总数在不断提高,从交互的用户总数为50~60,到100~150,再到最后300以上。算法结果显示,性能的提高并不与同用户交互的用户数目的多少成正比,除了方法(3)不明显外,其余算法的各项评价指标的性能随着交互关系的递增而变差。从图3可知,只有6.18%的用户标签的使用频率在5次以上,93.84%的用户标签都少于5人使用。绝大部分标签被很少的用户使用,导致了交互关系越多的用户接收到“噪音”标签的机会越大,这也就是导致算法在交互关系越多的用户上反而性能下降的原因。
5 结束语
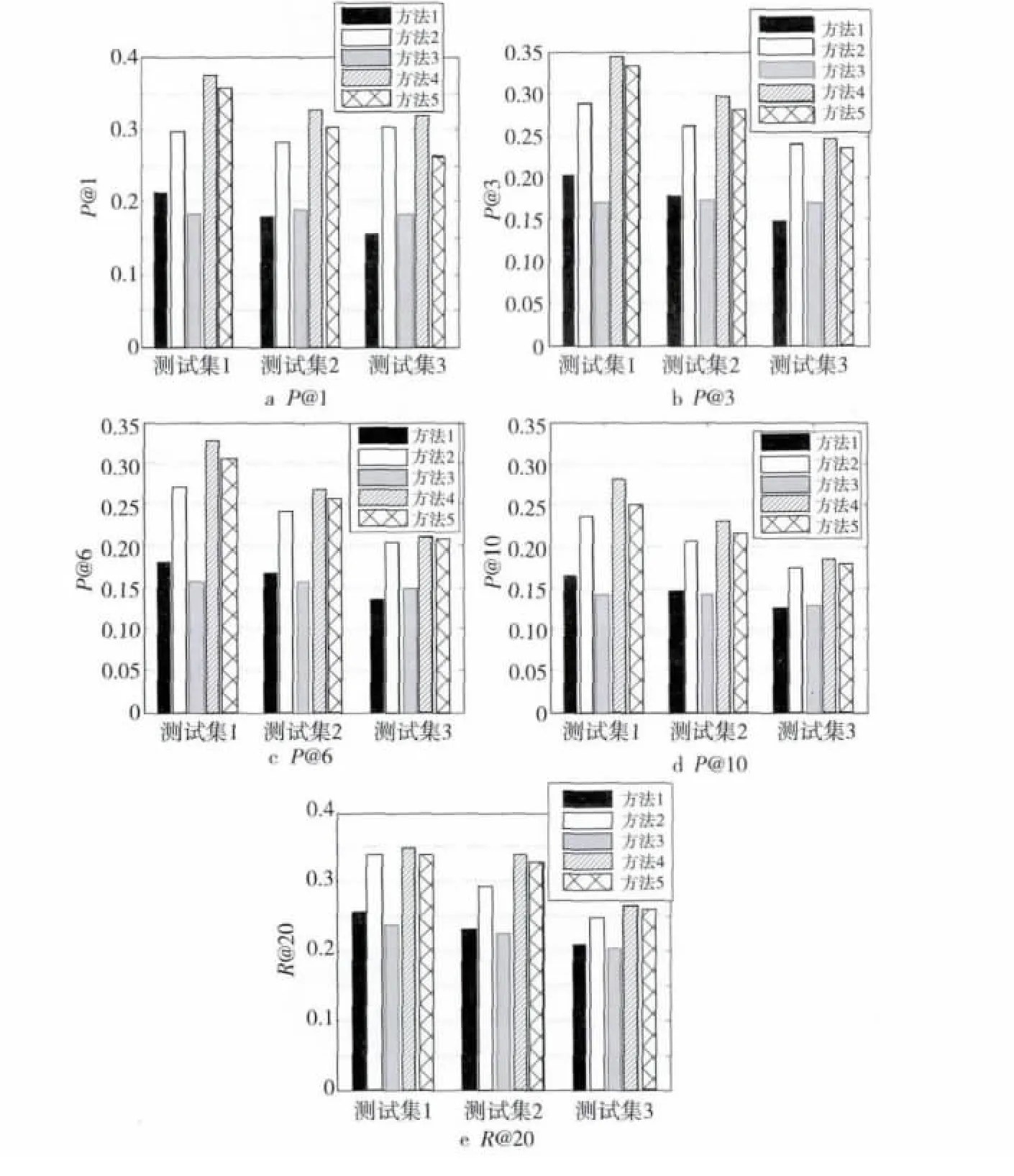
Figure 5 Performance transformation of five algorithms图5 五种方法性能变化趋势
本文针对新浪微博中绝大多数用户没有给自己打标签或标签较少的问题,提出了基于用户交互行为的微博用户标签预测方法。基于用户交互行为转发、提及而形成的强用户关系,提出了基于用户交互图的标签预测算法,分析了多种基于用户交互行为的用户标签预测方法,并在真实的大数据集上对算法性能进行了测试。结果显示,本文所提方法取得了良好的效果,比当前常用的将周边所有用户的标签作为用户标签的方法取得了更好的性能。由于新浪微博中绝大部分的用户标签使用频率非常低而导致在标签预测过程中“噪音”标签很多,算法的性能并没有随着用户与其它用户交互行为的增多而提高,在多个算法中,算法的性能反而随着用户交互行为的增多而下降。
在本文中,我们只研究用户之间的交互关系,在以后的研究中,我们将进一步考虑用户之间的静态关注/粉丝关系。
致谢 感谢湖南蚁坊软件公司为本文实验提供的Hadoop集群实验环境,感谢蚁坊软件公司李锦泽、汪云、谌志雄等提供的宝贵建议和技术支持。向对本文的工作给予支持和建议的同行,尤其是国防科技大学计算机学院国产基础软件工程研究中心681教研室的老师和同学表示感谢。
[1] Aggarwal C C,Wang H X.Text mining in social networks[M]∥Social Network Data Analytics,NY:Springer,2011:353-378.
[2] Golder S,Huberman B A.The structure of collaborative tagging systems[J].Journal of Information Science,2006,32(2):198-208.
[3] Halpin H,Robu V,Shepherd H.The complex dynamics of collaborative tagging[C]∥Proc of the 16th International Conference on World Wide Web,2007:211-220.
[4] Si Xian-ce.Content-based recommendation and analysis of social tags[D].Beijing:Tsinghua University,2010.(in Chinese)
[5] Ohkura T,Kiyota Y,Nakagawa H.Browsing system for weblog articles based on automated folksonomy[C]∥Proc of the 3rd European on the Semantic Web:Research and Applications,2006:1.
[6] Katakis I,Tsoumakas G,Vlahavas I.Multilabel text classification for automated tag suggestion[C]∥Proc of the ECML/PKDD-08Workshop on Discovery Challenge,2008:1.
[7] Xu Z,Fu Y,Mao J,et al.Towards the semantic web:Collaborative tag suggestions[C]∥Proc of the Collaborative Web Tagging Workshop at WWW2006,2006:5.
[8] Hotho A,Jächke R,Schmitz C,et al.Information retrieval in folksonomies:Search and ranking[C]∥Proc of the 3rd European on the Semantic Web:Research and Applications,2006:411-426.
[9] Zhang Bin,Zhang Yi,Gao Ke-ning,et al.Combining relation and content analysis for social tagging recommendation[J].Journal of Software,2012,23(3):476-488.(in Chinese)
[10] Pennacchiotti M,Popescu A-M.Democrats,republicans and starbucks afficionados:User classification in Twitter[C]∥Proc of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2011:430-438.
[11] Liu D,Hua X-S,Yang L,et al.Tag ranking[C]∥Proc of of the 18th International Conference on World Wide Web,2009:351-360.
[12] Xiao J,Zhou W,Tian Q.Exploring tag relevance for image tag reranking[C]∥Proc of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval,2012:1069-1070.
[13] Heymann P,Ramage D,Garcia-Molina H.Social tag prediction[C]∥Proc of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2008:531-538.
[14] Ding Zhao-yun,Yan Jia,Bin Zhou,et al.Mining topical influencers based on the multi-relational network in microblogging sites[J].China Communications,2013,10(1):93-104.
[15] Cha M,Haddadi H,Benevenuto F,et al.Measuring user influence in Twitter:The million follower fallacy[C]∥Proc of the 4th International Conference on Weblogs and Social Media,2010:11-13.
附中文参考文献:
[4] 司宪策.基于内容的社会标签推荐与分析研究 [D].北京:清华大学,2010.
[9] 张斌,张引,高克宁,等.融合关系与内容分析的社会标签推荐 [J].软件学报,2012,23(3):476-488.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
读者(2021年20期)2021-09-25
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
自动化学报(2017年7期)2017-04-18
阅读时代(2017年3期)2017-03-11
现代电子技术(2016年15期)2016-12-01
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
