
基于Redis的海量小文件分布式存储方法研究*
2013-05-08 13:40刘高军王帝澳
计算机工程与科学 2013年10期
刘高军,王帝澳
(北方工业大学信息工程学院,北京100144)
1 引言
小文件是现代社会传输和存储信息的重要方式之一,使用规模不断扩大,如通过电子邮件、即时通讯软件快速地共享、分发信息。在主要的办公系统中,小文件也是公司职员日常办公和汇报工作的主要方式之一。用户在使用中,不仅要求高速的处理速度,还要求存储的可靠性。因此,海量小文件云存储的研究具有重要的现实意义。
2 研究现状
海量小文件存储一般以HDFS(Hadoop Distributed File System)作为基础平台。HDFS是分布式的文件系统,通过廉价的多台机器支持大规模数据集的大文件存储,伸缩性强,解决了存储空间的限制问题。同时,HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用,而且即使在出错的情况下也能保证数据存储的可靠性[1]。它假设计算元素和存储会失败,维护多个工作数据副本确保能够针对失败的节点重新分布处理;它以并行的方式工作,保证了处理的高效性[2,3]。但是,HDFS中小文件的存储效率不高。采用NameNode维护文件路径到数据块的映射、数据块到DataNode的映射,监控DataNode的心跳和维护数据块副本的个数[4]。当大量的小文件存储到HDFS中时,NameNode会耗尽大部分内存,造成存储效率低下,限制了文件的访问速度。
针对HDFS中小文件存取效率低下这一问题,目前国内外一般采用合并的方法。赵晓永等[5]充分利用MP3文件自身丰富的元信息,提出了一种基于Hadoop的海量MP3文件存储模型;Dong Bo等[6]针对BlueSky中课件的存储和形式,通过文件合并和预读机制,减轻了NameNode的负荷,同时改善了HDFS中存储和访问大量小文件的效率。以上的这些合并方法解决了小文件存储的一部分问题,但其仍有待改善。(1)这种传统的整合小文件的方法,需要占用主服务器内存进行整理合并,主服务器的性能成了小文件整合优化的瓶颈。(2)在小文件上传到HDFS之后进行合并整理,这种二次整理的方式对每个小文件进行了两次存盘操作,增加了磁盘I/O的负担。
基于以上问题,首先,本文使用单独的高内存服务器缓存待合并的数据,提高管理节点的性能,避免了主服务器的瓶颈。在缓存服务器上采用Redis(Remote Dictionary Server)进行存储,它是一个基于内存的高性能Key/Value数据库,周期性地把更新的数据写入磁盘或把修改操作写入追加的记录文件,保证数据的持久化,其 Master-Slave(主从)同步的方式为用户提供了高可用性和可靠的平台[7]。其次,将第一次上传的文件缓存在Redis上,仅需要在合并文件后进行一次存盘操作,减少了磁盘I/O。再次,用户的文件上传在内存中进行,大幅度缩短了文件上传的响应时间。
3 优化方案设计
本文设计的文件存储方案是建立一个用户与HDFS的中间平台,处理接收文件的上传、获取和删除操作。由于大文件可以直接高效地存储在HDFS中,本平台仅对小文件进行处理,对超过64 MB的大文件返回不接收标记。合并存储方案如图1所示,用户通过Socket与应用交互进行操作,用Redis缓存用户文件,通过HDFS接口把缓存文件合并存储在HDFS中的Sequence File中,并把元数据记录在Redis中。
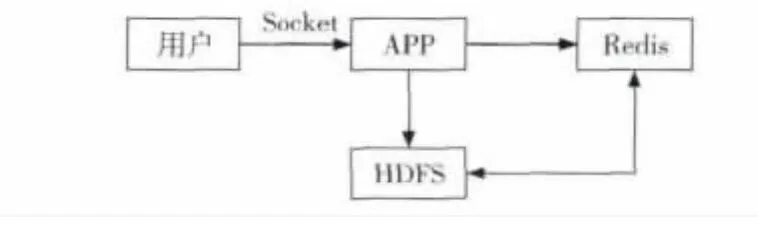
Figure 1 File consolidated storage solutions图1 文件合并存储方案
3.1 存储结构
Redis作为文件的缓存服务器,保存缓存文件内容和元数据记录,其缓存和元数据记录结构分别如表1和表2所示。
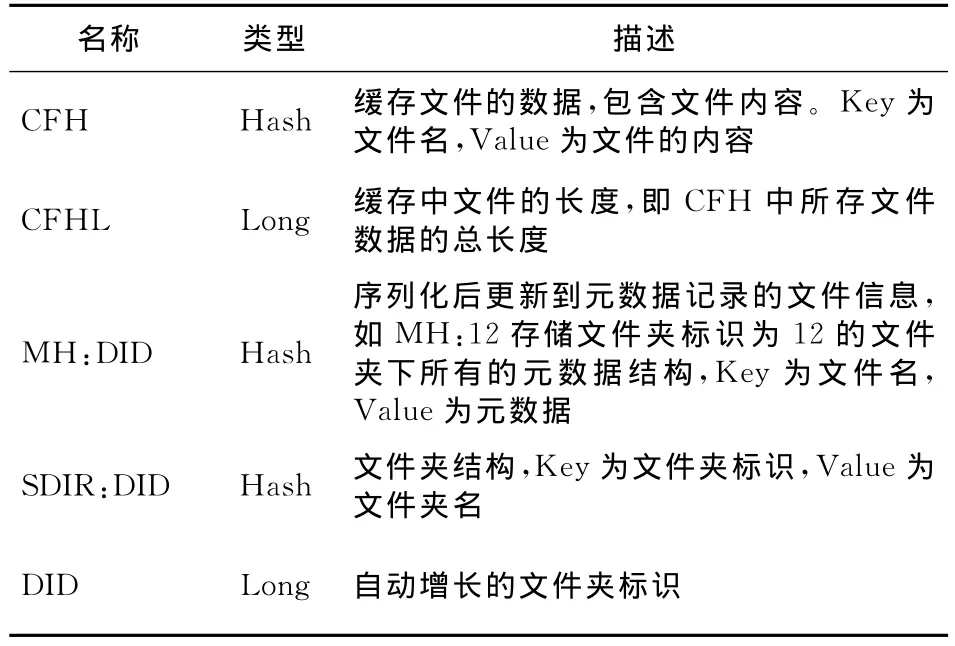
Table 1 Redis cache data storage structure表1 Redis中缓存数据的存储结构
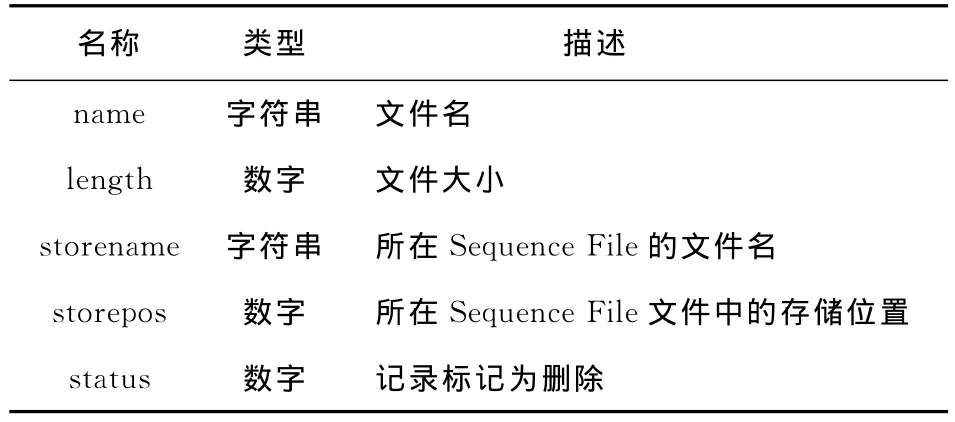
Table 2 Redis file metadata structure表2 Redis中文件的元数据结构
HDFS平台上的存储结构为:基本目录下存储合并后的Sequence File,以时间戳命名。Sequence File采用顺序存储结构,这样就可以通过元数据中文件名对应记录的文件位置storepos快速定位小文件内容。其中,Sequence File采用Block压缩,以降低磁盘占用和提高传输速度。Block压缩是将一连串的记录,也就是这里的小文件组织到一起,统一压缩成一个Block。Block信息主要存储:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合。
3.2 文件操作
平台在存储结构的基础上,对文件的上传、获取和删除操作的处理如下所示:
(1)文件上传时,首先将上传的小文件存入Redis的文件缓存中,方便用户高速地读取。当上传的文件总量达到指定阈值时,在合适的时间把缓存文件合并为Sequence File存储到HDFS中,以释放内存和保证文件存取的高容错性和高效性,同时更新元数据记录。
(2)文件获取时,首先在上传缓存中检查读取文件,其他的可根据元数据记录读取。在文件读取过程中,由于采用Sequence File的Block压缩,同步点在Block的两端,需要从Block开头遍历到待获取文件。其中,读取遍历过程中的文件的代价很小,获取文件的代价跟遍历的文件的数量正相关(在本文实验中验证)。另外,在高并发访问时,依据Sequence File顺序读取的特点,每次从Block开始访问时可能命中多个待获取的文件,直接读取会造成同一Block的多次读取。因此,可采用缓存机制保存Block来提高读取效率。
(3)文件删除时,通过更改元数据记录标识当前文件的删除状态。删除后,在指定时间间隔对文件进行删除检查,对文件再次归档,避免大量未删除的无效数据降低文件缓存的命中率,保证文件在读取时的快速定位和文件空间的高使用率。
4 存储平台实现
根据以上提出的设计方案,平台采用的实现结构如图2所示。在负载代价模型的基础上,将小文件平台分为基本处理和后台处理两部分。用户通过平台与Redis和Sequence File交互进行文件的基本处理,如上传、修改和删除;定时器结合基本操作触发事件调用后台处理保证系统的可靠和速度。其负载代价模型和基本处理、后台处理的具体方式如下。
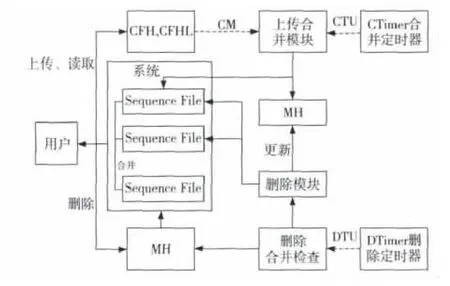
Figure 2 Storage platform architecture图2 存储平台架构实现
4.1 负载代价模型
作为一个完整的系统,在提高小文件存储效率的同时,也应该考虑到系统的负载状况[8]。而在对现有的服务器资源的统计中,一般采用独立的CPU或内存的使用评估代价,并不全面。比如,高的CPU使用率是不会影响仅对内存和磁盘I/O占用高的操作;而且,在实际使用中,线程操作对各类资源的使用要求也不能准确地评测。
为弥补传统资源统计的不足,本文提出负载代价模型,以用户的响应时间估算标准,在实验的基础上根据统计数据进行分析,确定代价计算公式,更合理地评价多种因素的影响。其具体过程为:在实际系统正常运行时,对多类资源如CPU、内存、磁盘I/O等进行实时统计,记录执行处理任务的线程后,为客户服务的主线程的响应时间,并在此基础上进行分析,确定各因素的影响系数。这样,避免了传统的统计估算所缺乏的有效性,采用实际的系统测试保证了即使在不确定的各类环境资源要求下,也能可靠评测。
4.2 基本处理
基本处理实现平台的基本操作,接收文件的上传、获取和删除操作。文件上传时,先将接收到的文件存入Redis中的文件缓存(CFH)中,更新CFH所存文件的长度CFHL。之后,判断CFHL,若达到文件的合并大小,发送“可合并文件”的消息(CM)到后台处理模块,至此,文件上传完成。文件读取时,若在Redis的上传缓存中则直接返回,否则通过缓存处理模块读取文件内容并返回给客户端。文件删除时,首先判断是否在CFH中,若存在则直接删除,否则将元数据的status置为0,标记文件已被删除。
文件获取的缓存处理模块实现为:当接到小文件读取请求时,存入文件获取队列,读取Sequence File,当读取队列中同一Block内的所有文件获取完成后结束,并将遍历的所有小文件和访问该文件所需遍历的文件数N存入缓存。若缓存器满,采用小文件缓存替换策略置换文件。
本方案结合Sequence File访问的特点,在GD-SIZE算法基础上,用公式(1)计算代价H,实现小文件缓存替换策略。一般的GD-SIZE算法[9]为:缓存器中的每个文档都有相应的代价H,当文档被带进缓存器时,该文档的H值为文档大小的倒数;发生置换时,H 值最小的文档(Hmin)被换出,剩下的文档的H 值变为置换前的H 值减去Hmin。依据Sequence File读取的特点,单一Block内读取文件可能需要遍历多次,GD-SIZE算法中采用的价值H并不能实际反映文档的代价,文档的代价与访问该文件所遍历的文件数N正相关。故可以把文件大小S的倒数乘以N(即公式(1))作为GD-SIZE算法的初始价值H,实现缓存替换。

4.3 后台处理
后台处理是在文件预处理完成的基础上,为保证文件的可靠性、文件访问的高效性,节省存储空间进行的处理。具体操作为处理缓存与HDFS的同步和HDFS中Sequence File的整理,主要完成缓存文件的合并、保存和元数据更新操作。以下对后台处理的基本流程、上传合并模块、删除合并模块进行说明。
4.3.1 基本流程
基本流程是触发后台处理的基本环节。为保证Redis中的缓存能及时地保存到HDFS中,在服务端设置合并定时器CTimer,当达到既定时间时,将合并时间到(CTU)的标记置为有效。同样,设定文件删除定时器DTimer,给处理模块发送删除检测时间到达的消息(DTU)。当收到CM消息时,首先通过负载代价模型的公式计算负载,低于既定阈值的负载调用上传合并模块进行合并,否则判断CTU是否有效,有效则进行文件合并,无效则不做处理。当收到DTU消息时,调用删除模块检查删除文件并进行文件合并。
4.3.2 上传合并模块
上传合并模块负责将缓存文件打包同步到HDFS中。首先,在Redis中重命名CFH为CFHB,保证新上传的文件可继续使用CFH缓存。用HDFS对文件进行合并压缩储存到HDFS中。然后,把所合并的文件的信息(包含存储位置)记录到元数据记录集MH中。
4.3.3 删除合并模块
删除合并模块是将有标记删除小文件的Sequence File进行整理合并。首先进行删除合并检查。在元数据记录集中找到有效逻辑文件大小总和最小的前两个存储文件,若其文件大小总和小于既定阈值,则可进行文件删除合并。然后,依次读取两个Sequence File内容,读取到有效的小文件内容保存到新的Sequence File文件中,并删除原文件,更新元数据记录,完成删除合并。
5 实验
本实验采用64位的CentOS作为操作系统,Hadoop为r1.1.1,单一NameNode节点,Redis为AOF(Append Only File)模式,即每秒进行一次数据保存。测试数据上,采用随机生成的10万个100KB的小文件进行存储分析测试。实验内容如下:(1)确定建立负载代价模型及代价系数。(2)比较本方案与现有方法的文件合并磁盘I/O。(3)分析文件在Block中的遍历个数对文件获取代价的影响。(4)检验本方案的性能:分别在传统的直接上传到HDFS和本文实现的存储平台上,统计小文件上传速度、10万个小文件上传后的文件获取速度、文件删除速度、内存占用。
5.1 确定负载代价计算公式
为建立负载代价模型,确定负载代价公式,需要把各种因子对主线程的响应时间的影响进行量化,可通过实验数据采用多元线性回归分析的方法[10]得到因子的影响系数,确定估算代价值的计算公式。在本系统中,CPU使用率(C)、内存使用率(M)和磁盘I/O(D)对性能有主要影响,将其作为因变量,把用户请求文件上传的响应时间(T)作为响应变量,则多元回归方程表达式为:

具体操作如下:首先,在平台运行的集群的节点上分别在执行多个对C、M、D影响较大的进程,达到不同的资源占用结果,并统计此时的文件上传时间,统计结果如表3所示。
对结果进行回归分析,可得k1=0.257,k2=0.332,k3=0.103。为使用户在100ms以内能够得到响应,由C、M、D计算得出的响应时间T应小于100ms,以此作为负载的既定阈值。该实验环境下,将k1、k2、k3的值输入运行配置中,则当后台处理收到CM消息时,用式(2)计算负载阈值。以下的实验均在此条件下完成。

Table 3 Response time of the user request表3 用户请求响应时间
5.2 与现有的文件合并磁盘I/O的比较
搭建采用现有小文件合并的平台,这里选取比较常用的HAR(Hadoop Archives)合并方式。分别采用HAR合并和本文小文件处理平台上传1万个小文件,并分别统计上传过程中磁盘512字节块读取(Blk_read)和写入(Blk_wrtn)的总数量。实验得出,采用HAR合并文件的读取数为2.19MBlk_read,写入数4.23MBlk_wrtn,而采用小文件处理平台的磁盘512字节块的读取和写入分别为0.06MBlk_read和2.31MBlk_wrtn。可以看出,采用小文件处理模块能有效地减少磁盘I/O,因为其在Redis中缓存小文件的方式可以避免未合并前的首次磁盘写入和合并时的读取,所有文件都减少了一次写入和读取。
5.3 文件获取时Block遍历数对获取代价的影响分析
文件获取代价在本系统中是缓存服务器获取HDFS中小文件的代价。采用缓存机制条件下,同一文件多次获取的代价不会一成不变,这里采用该文件的平均代价标识文件的代价,其平均代价为直接获取代价和间接获取代价的加权平均,计算公式如式(3)。当Block为1MB时,由于压缩的影响,实际系统每个Block存储15个左右的小文件。实验在上传完10万小文件后进行。随机抽取10个Block中的小文件在缓存服务器上直接读取文件和同时读取遍历过程中的文件,记录读取文件的时间,并一直读到Block结束,记录小文件数,实验结果如表4所示。可以得出,读取遍历过程中文件的代价比较小,仅多占用了1.5%的时间。其中,每次中间遍历和获取文件的总时间基本一致,平均值为2.07ms。以此平均值计算平均代价结果,如表4所示。由计算结果可以看出,平均代价随遍历数的增加而增加,呈正相关关系。
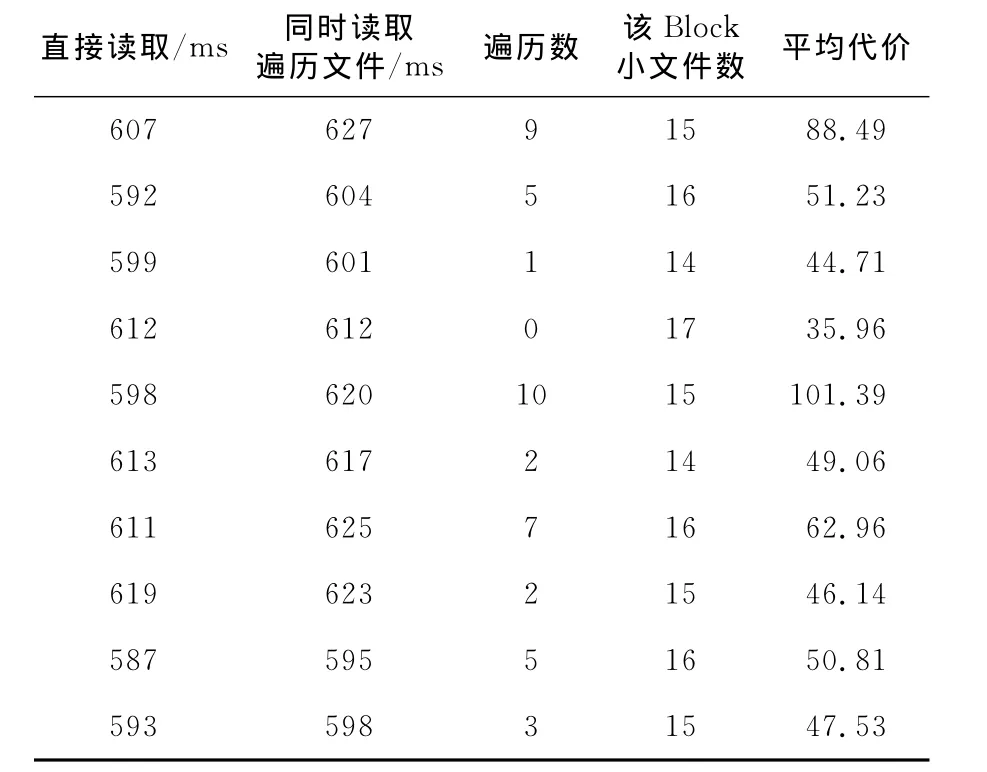
Table 4 Consideration of the file read表4 文件读取代价
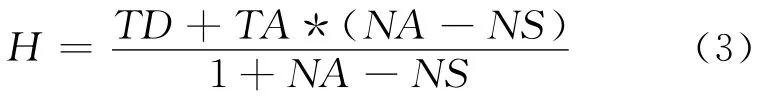
公式(3)中,H 为评价代价,TD为直接获取时间,TS为同时遍历文件时的获取时间,TA为平均每次中间遍历和获取文件的总时间,NS为遍历数,NA为Block文件数。
5.4 文件上传速度
为排除不稳定因素(如网速)的影响,随机抽取10个小文件分别在标准HDFS中和采用优化模块的文件系统中进行上传,所消耗的时间如图3所示。
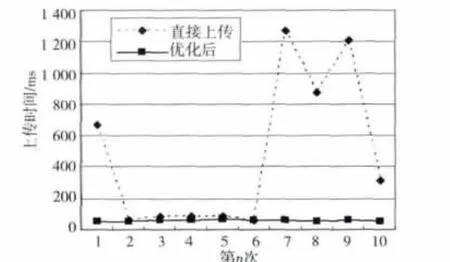
Figure 3 File upload time图3 文件上传的时间
可以看出,采用了小文件处理模块后,文件上传的时间明显缩短,由传统方式的平均478.1ms减少到平均62.3ms,节省了86.97%的时间。在采用小文件处理模块的文件上传中,用户上传文件的操作由原来HDFS内存接收文件、写入磁盘的操作精简为直接Redis内存接收文件,不再需要等待比较缓慢的写入磁盘操作,上传的速度明显提高。
5.5 文件获取速度
在10万个小文件分别上传后,分别进行不同Sequence File的读取、同一Sequence File读取的测试。
不同Sequence File的读取:从中随机抽取10个分到不同Sequence File的文件进行下载测试,获取时间如图4所示。10次获取中传统的和优化的平均获取时间分别为605.3ms和602.2ms,分到不同Sequence File文件的读取速度并没有明显降低。
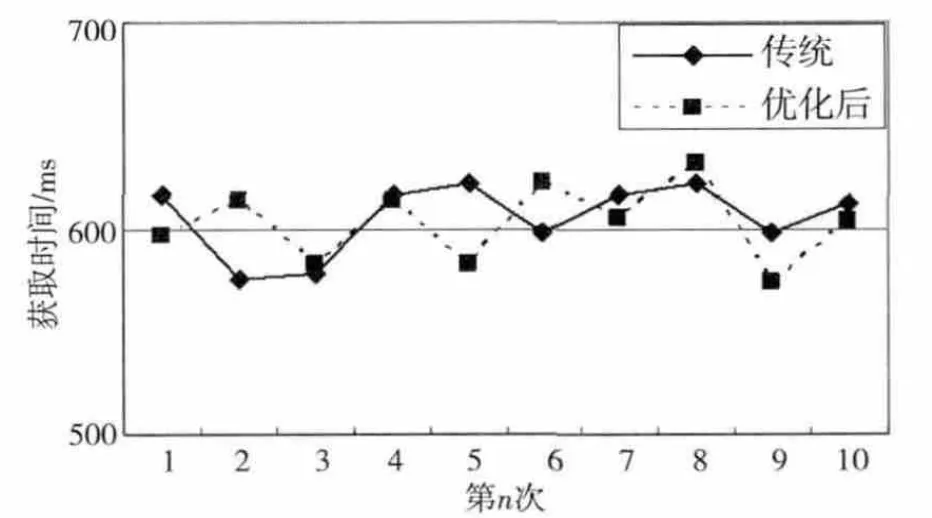
igure 4 Obtained small files from different sequence file图4 不同Sequence File小文件获取时间
同一Sequence File读取:从一个Sequence File中抽取10个文件进行下载测试,其中,前5个为不同Block的文件,后5个为前5个Block随机获取的文件,其获取时间如图5所示。其中,分到同一Sequence File文件的读取速度因第一次预读有所提高。因Block缓存机制的影响,可命中缓存的后5个文件的读取速度明显提高。
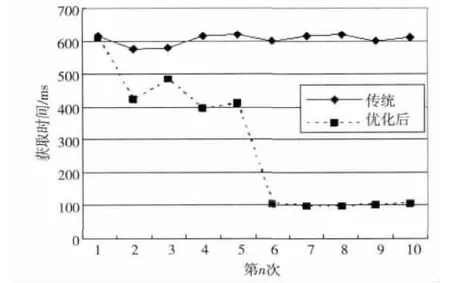
Figure 5 Obtained small files from same sequence file图5 从同一Sequence File中获取文件时间
从以上两种实验的结果可以看出,该文件优化的方式在随机少量文件获取时不会降低速度,但是,当在大量频繁的文件读取时,由于多次读取同一个Sequence File和缓存机制,能大幅度地提高文件的获取速度。
5.6 文件删除速度
在10万个小文件分别上传后,随机进行10次文件的删除操作,统计结果如图6所示。采用小文件合并模块后的文件删除和传统的文件删除平均删除时间分别为25.3ms和25.2ms。从实验可以看出,采用小文件合并模块跟传统方式的文件删除速度基本一致。这是由于原HDFS采用内存存储元数据,删除在修改元数据记录后返回,本文中小文件合并模块的处理方式跟其基本一致。
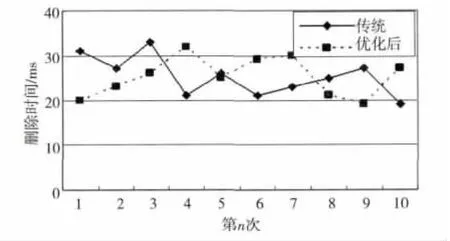
Figure 6 File deletion time图6 文件删除的时间
5.7 内存占用
分别进行10万小文件的上传后,NameNode节点内存占用的统计结果为:文件上传前,内存占用在5%。采用传统方式直接上传到HDFS后,内存使用率上升到44%;采用比较常用的HAR文件合并方式进行文件合并后,内存使用率仅提高到24%,而采用小文件合并模块上传到HDFS后,NameNode的内存使用率仅提高到23%。可以看出,传统的文件合并方式和本文的合并方式都在以大文件方式存储,上传完成后的内存占用没有较大的差别。在HDFS内存使用率随文件数量增加而增大的情况下,合并文件进行存储能够有效地降低内存占用率。
在文件上传过程中,对NameNode节点内存占用进行统计:采用比较常用的HAR文件合并方式进行文件合并时,NameNode节点的最高内存使用率为36%;采用本文的小文件合并模块,Name-Node节点的内存使用率比较平稳,最高仅为26%。本文的小文件合并模块使用独立的缓存服务器,文件合并在NameNode节点外进行,因此其能有效地避免NameNode节点高内存的消耗。
5.8 实验总结
从以上实验的结果可以看出,采用基于Redis的HDFS小文件合并存储优化方案能够在保证不影响文件删除速度和随机获取文件速度的基础上,较大程度地提高了内存的利用率,加快了文件的检索速度,保证了文件的快速、可靠操作和保存。
6 结束语
本文从HDFS中海量小文件的存储方式考虑,在可靠的HDFS文件系统上,进行小文件的存储优化设计和实现,结合Redis缓存机制有效地减少了NameNode节点的内存占用率,相比传统的HDFS文件合并方法,减少了磁盘I/O,加快了文件的上传速度和在大量频繁的文件读取时的获取速度。
[1] Borthakur D.HDFS architecture guide[EB/OL].[2012-12-15].http://hadoop.apache.org/docs/r1.0.3/cn/hdfs_design.html.
[2] Ding Hui,Zhang Da-hua,Luo Zhi-ming.Hadoop-based mass data processing platform research[J].Telecommunications Science,2011(9A):205-210.(in Chinese)
[3] Li Yuan-fang,Deng Shi-kun,Wen Yu-biao,et al.PageRank matrix partitioned algorithm using Hadoop-Map Reduce[J].Computer Technology and Development,2011,21(8):6-9.(in Chinese)
[4] Cao Ning,Wu Zhong-hai,Liu Hong-zhi,et al.Improving downloading performance in Hadoop distributed file system[J].Journal of Computer Applications,2010,30(8):2060-2065.(in Chinese)
[5] Zhao Xiao-yong,Yang Yang,Sun Li-li,et al.Hadoop-based storage architecture for mass MP3files[J].Journal of Computer Applications,2012,32(6):1724-1726.(in Chinese)
[6] Dong Bo,Qiu Jie,Zheng Qing-hua,et al.A novel approach to improving the efficiency of storing and accessing small files on hadoop:A case study by power point files[C]∥Proc of the 2010IEEE International Conference on Services Computing,2010:65-72.
[7] Wang Xin-yan.Memcached and Redis in the cache[J].Journal of Wireless Internet Technology,2012(9):8-9.(in Chinese)
[8] Yu Si,Gui Xiao-lin,Huang Ru-wei,et al.Improving the storage efficiency of small files in cloud storage[J].Journal of Xi’an Jiaotong University,2011,45(6):59-63.(in Chinese)
[9] Zuo Li-yun.Optimized schedule algorithm for proxy cache based on rule-driven model[J].Computer Engineering,2009,35(24):93-95.(in Chinese)
[10] Ma Li-ping.Learning and use of modern statistical methods——Multiple linear regression analysis[J].Beijing Statistical,2000(10):38.(in Chinese)
附中文参考文献:
[2] 丁辉,张大华,罗志明.基于Hadoop的海量数据处理平台研究[J].电信科学,2011(9A):205-210.
[3] 李远方,邓世昆,闻玉彪,等.Hadoop-Map Reduce下的 PageRank矩阵分块算法[J].计算机技术与发展,2011,21(8):6-9.
[4] 曹宁,吴中海,刘宏志,等.HDFS下载效率的优化[J].计算机应用,2010,30(8):2060-2065.
[5] 赵晓永,杨扬,孙莉莉,等.基于Hadoop的海量MP3文件存储架构[J].计算机应用,2012,32(6):1724-1726.
[7] 王心妍.Memcached和Redis在高速缓存方面的应用[J].无线互联科技,2012(9):8-9.
[8] 余思,桂小林,黄汝维,等.一种提高云存储中小文件存储效率的方案[J].西安交通大学学报,2011,45(6):59-63.
[9] 左利云.基于规则驱动模型的代理缓存优化调度算法[J].计算机工程,2009,35(24):93-95.
[10] 马立平.现代统计分析方法的学与用——多元线性回归分析[J].北京统计,2000(10):38.
猜你喜欢
电脑爱好者(2019年2期)2019-10-30
综艺报(2019年5期)2019-03-18
网络安全和信息化(2018年2期)2018-11-09
海峡姐妹(2017年12期)2018-01-31
作文与考试·初中版(2017年12期)2017-04-19
网络安全和信息化(2017年3期)2017-03-10
网络安全和信息化(2016年8期)2016-11-26
汽车文摘(2015年11期)2015-12-14
中学生(2015年12期)2015-03-01
中国社区医师(2015年10期)2015-01-27
