
基于.Net 的全文搜索引擎设计与实现*
2014-12-31 09:04孙艺珍季小迪张京涛
西安科技大学学报 2014年6期
孙艺珍,季小迪,张京涛
(1.西安科技大学 计算机科学与技术学院,陕西 西安710054;2.陕西百略企业管理咨询有限公司,陕西 西安710061)
0 引 言
在互联网高速发展的今天,网络中充斥了各种各样的信息,这样就使得用户无法准确快速的找到可用的信息。在此情况下,一种能够快速搜索和整理信息的技术日渐成为网络关注的焦点。Kwang-ⅠYu,Shi-ping Hsu 和Peggy Otsubo1984 年在International Conference on Data Engineering 发表了《The Fast Data Finder-an architecture for very high speed data search and dissemination》,首次提出构建一个快速数据搜索和数据传播的框架[1]。冯飞燕1996 年翻译的《搜索引擎-穿透Internet 的动力-搜索引擎能做些什么》一文中介绍了网络搜索引擎、网络蜘蛛等相关知识[2]。搜索引擎自上个世纪90 年代产生,经过多年的发展,已经逐渐成为用户上网不可或缺的重要工具。国外开发的搜索引擎比较多,如Google,Yahoo,Naver,Yandex 以及微软的Bing 等,Google 被公认为是全世界全球最大搜索引擎,它是互连网上用户运用最多的搜索引擎网站。国内比较常见搜索引擎的有baidu,sohu,sina 等,国人偏爱用百度进行中文搜索,其优势在于基于中国人的搜索习惯,可以进行中文人名的搜索、识别,简繁体中文自动转换,中文自动纠错等相关功能。搜索引擎一般可分为3 种,即目录式搜索引擎、全文搜索引擎、元搜索引擎,后来又发展了其他非主流的搜索引擎,如垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等其中使用最多的是全文搜索引擎。虽然全文搜索引擎有了长足的进步,但是,它也存在较多的问题,例如如何提高全文搜索引擎对于文字的识别准确性;如何做到语音搜索;如何能够根据用户兴趣来筛选信息等。其下载分析端多采用C 或C+ +语言来实现,搜索页面设计方面主要采用PHP 和JSP.虽然效果不错,但是其信息量重复率高,以及不能根据用户的特定需求来筛选信息等问题也是日益凸显。所以说,目前全文搜索引擎的开发和研究还远远不能满足于人们的需求,全文搜索引擎的潜力还有很大的挖掘空间[3]。
文中介绍了全文搜索引擎的构成及工作过程,设计并实现了一种基于. Net 的完整的全文搜索引擎原型系统,测试结果表明其能够完成全文搜索引擎的基本功能。与此同时,该原型系统中加入了用户对于个性化的需求,即用户能够根据自己的需求,选择特定的内容进行搜索查看。此外,搜索页面摒弃了单调的白色布局,加入适当的绚丽背景及优化的按钮;而显示模块方面加入了异步传输技术,使得用户能在不用翻页的情况下即可查看内容,从而提升用户体验。
1 全文搜索引擎基本原理
1.1 万维网与Lucene
无论是动态还是静态网站,当其需要进入另一个网站的时候,都将使用连接的形式来进行。这就将网站与网站链接在了一起。通常将本网站链接别的网站的链接叫做正向链接而链接到这个网站的链接叫做反向链接;通过Broder 的Ran-Dom-start BFS 实验,可以展示出了万维网的基本结构是蝴蝶结型结构,而且万维网其实是有直径的,即,对于任意两个网页他们之间经过的连接数是有极大值的,对于中国目前的网络而言,一般是16,也就是说任意两个网页之间的最大距离为16个链接[4-7]。在这样的网络结构中,如果要想获取更多的网页(原始数据),那么搜索系统就应该选择蝴蝶结中部以及左部的网站作为起始点;而结束的标准可以是判定当前获取的网页的连接次数是否小于17,这为搜索系统的开始和结束给出了具体的要求。
Lucene 是一个工作良好的全文检索和搜索的系统,它提供了中文分词、搜索显示高亮、索引相关操作。与此同时,它提供的丰富的接口给程序员,使得程序员能够根据自己的需求重写Lucene中的模块或通过接口加入其它的模块,从而丰富了Lucene 的功能,提高其工作效率及准确性。其一般的工作原理是,结合中文分词器一起工作,能够很好的对文章进行分析,之后建立倒排索引;接着在查询的过程中,Lucene 调用建立好的索引文件,对经过中文分词的关键词进行全文搜索,并根据其自身的得分算法公式得出一个得分并排序。而在索引管理方面,Lucene 也是比较方便的,它能够对已经建立的索引进行添加,合并以及优化。
1.2 全文搜索引擎系统设计
整个系统分为4 个部分,分别是搜索模块,分析模块,索引模块以及查询模块[8]。
1.2.1 搜索模块
搜索模块由3 个部分组成,分别是:验证模块、多线程网页下载模块、Robots. txt 下载模块。3 个模块中最为关键的一个就是爬虫模块,这个模块采用多线程的方法[9-10],通过URL 将网页从互联网中下载到本地,为下面的处理程序提供主要的支持。
1.2.2 分析模块
分析模块主要包括了信息抽取模块,中文分词模块,以及网页得分模块。信息抽取模块的主要作用是,将爬虫下载到本地的文件读取出来,进行分析处理,将特定的标签内容提取出来,存入文件,并根据内容或标题等一系列的特征信息,将重复的网页删除,从而减少搜索的工作,减少查询结果重复率。中文分词模块主要是结合索引使用的,它将对抽取之后的信息以及查询中的关键词进行分词,这样当关键词的分词与信息抽取文件的分词相等的时候,就能使计算机识别出来。得分模块主要的功能就是为显示页面的排列提供服务,使得显示页面能够显示出最主要,最权威的信息。
1.2.3 索引模块
国际标准《文献工作——出版物的索引》中对于索引的定义是“按所处理的主题、人名、地区名与地名、事件以及其他项目排列的一种详细目录,并指出项目在出版物中的位置”。所以,在全文搜索的搜索引擎中,最好是使用索引的形式来对文章进行存储,这样能够快速、便捷的查询到相应的消息。
1.2.4 查询模块
查询模块是整个搜索引擎中唯一与用户的接口,用户通过关键词与整个搜索引擎进行交流,即当用户输入关键词以后,系统将关键词分词并查询索引,最终在现实页面显示出查询的结果。虽然,这仅仅是一个接口,但是其重要性不容小视,一个具有良好用户体验、具有海量数据及结果合理显示的搜索引擎能够大大的吸引用户,从而使得更多的人来使用搜索引擎。
1.3 全文搜索引擎的工作流程
根据全文搜索引擎的系统划分,其工作流程首先从爬虫(robots 或spider)模块开始,从网络中抓取信息,并将抓取的页面存储于本地;之后分析模块分析由爬虫抓取的信息;并运用分析系统分析的结果,之后通过索引系统建立索引目录;最后向用户提供查询结果及信息反馈。
2 全文搜索引擎的实现
2.1 数据存储的设计
对于搜索模块的数据,需要两张表来存储。分别存放下载的URL 信息以及下载的Robots. txt信息。下载的网页和Robots. txt 全部以其网址的MD5 码存储[11],便于进行查询和比对。
分析模块的数据存储分为数据库存储和文件存储。数据库主要用于存储分析模块对于网页分析的结果简报。文件存储分为2 部分,其一是存储经分析模块分析处理之后的文件,采用与下载页面相同的MD5 码来存储;另一个是存储删除词条,用于模块分析时根据删除词条来删除搜索内容的相应词条,从而简化文件的内容,提取出真正有用的信息。
2.2 搜索模块的实现
2.2.1 验证系统设计实现
在搜索系统中有2 个验证系统,其中之一是对于人工输入的种子网页或计算机本身提取出的网页的URL 进行验证,使之能够符合爬虫程序的下载要求;另一个是对于网站Robots.txt 文件进行验证,即验证所要用来下载的URL 是否符合Robots.txt 的要求。当2 个验证程序都通过之后,才能将这个URL 放入到数据库中。对于Robots.txt 的检测流程图如图1 所示。
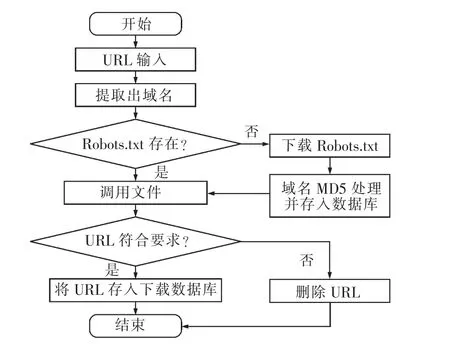
图1 Robots.txt 的检测流程图Fig.1 Detection flowchart of robots.txt
2.2.2 爬虫模块设计实现
对于爬虫模块,为了不出现下载网页与下载Robots.txt 文件发生冲突,将2 个下载程序分开。其中网页下载爬虫将采用深度优先的算法来进行多线程抓取,另一个Robots.txt 文件下载程序采取单线程的下载模式。网页爬虫将采用5 只爬虫共同抓取的策略[12]。为了避免爬虫同一时间对于数据库重复访问,在爬虫的模块中要加入延时来控制爬虫的产生,以及爬虫访问数据库的速度。
在获得网页的数据流之后,需要完成两个处理,首先是对于URL 的提取并将其存储到数据库中,以便爬虫能够访问及下载。
本系统使用的是通过匹配正则表达式来获取URL[13],正则表达式如下形式

式中具体解释见表1.
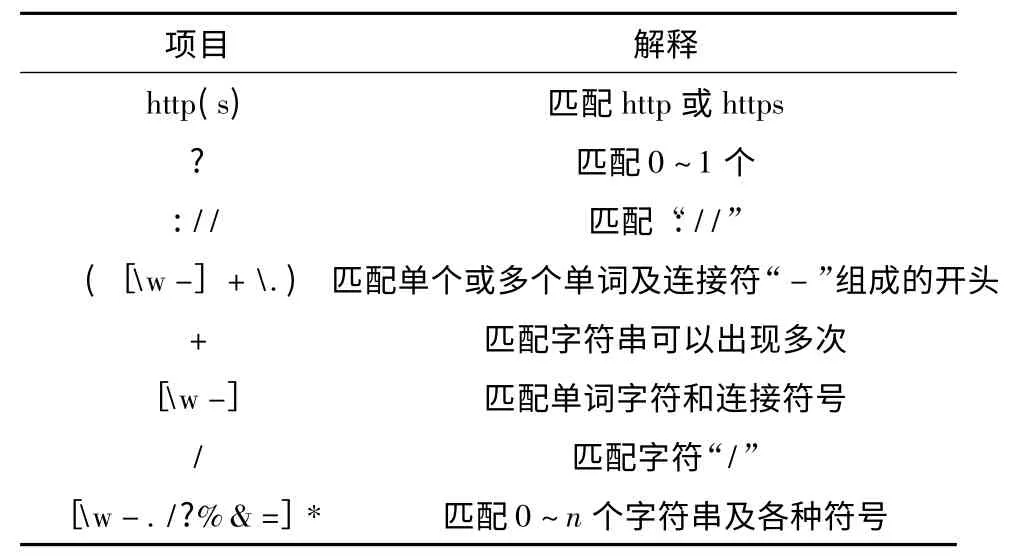
表1 正则表达式解释表Tab.1 Explanation of regular expressions
其次是正确获取网页的编码,在国内比较多的网站使用的都是GB2312,国际上使用最多的是UTF-8 这种编码。本系统将使用通过Mozzila 的universalchardet 改造后的NUniversalCharDet 动态链接库来实现对于编码的识别,它使用的是一种统计学的方法,对放进来的数据进行各种编码之后,对其进行统计,概率性高的就算命中,从而确定出编码类型。爬虫主要承担的就是一个下载和存储网页的功能,其流程图如图2 所示。
2.3 分析模块的实现
2.3.1 网页信息抽取的设计实现
本系统使用的是HTMLParser 分析工具来实现对于内容的抽取,首先将下载之后的文件从磁盘中读取出来;之后交给HTMLParser 来根据需求标签提取出标签中的内容;处理之后的存储的格式为:标题——时间——li 标签内容——p 标签内容——a 标签内容。与此同时,要将文件的MD5码、标题和连接数目写入数据库中。
2.3.2 中文分词

图2 爬虫程序的流程图Fig.2 Flow diagram of crawlers
以中文关键词进行全文搜索,中文分词是一个十分困难的事情。因为中文不像英文一样,有空格可以作为天然的分割符号。中文任意两个词的不同组合以及不同的语境都有很多不同的意思,所以如何划分,以及划分的好坏直接关系到最终的结果。Lucene 的.Net 版本3.0.3 自带的中文分词模块分词效果不是很理想,因此,在本项目中,将使用MMseg4j,也是一个基于Chih-Hao Tsai的MMSeg 算法的中文分词器,也是一种基于字典分词的一种分词方法[14-15]。
2.3.3 网页得分
网页得分用来确定搜索结果排序的位置。其主要分为3 个部分,第一部分为链接得分。其主要的思想是,以他目前的得分除以它全部的链接数目,而指向该网页的网站则加上这个分数;多次的迭代之后,一个网站的分数基本就固定了,也就可以比较客观的得到一个分数。第二个部分是Lucene 的得分系统,这个得分系统根据索查询词语在文档中出现的词频,倒排词频等一系列的项目综合得到一个数值,从而表示本词条在整个索引中的重要程度。第三个部分是用户的爱好选择,当用户选择确定的需要查询方向之后,其相关网页的得分就会高于其他的网页。根据反复的统计分析,得出以下公式来表示网页的得分。
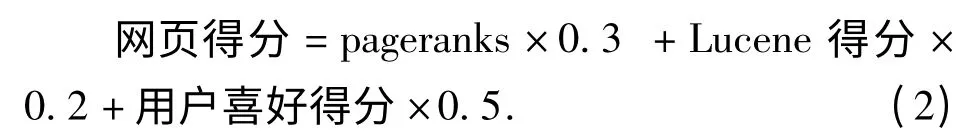
2.4 索引模块的实现
在通过Lucene 建立索引的时候,其基本的方法是,首先建立一个空的索引,之后根据自己的需求,向索引中添加条目以及内容。根据之前文档的格式情况,此时的策略是,读取第二行获得标题;读取第四行获取下载时间;行循环读取获得“li”标签中的内容,直到读取行是“p”标签中的内容为止;行循环读取获得“p”标签中的内容,直到读取行是“a”标签中的内容为止;访问数据库获取文档的URL 地址。经过以上的操作就可以从文件中提取出相应的数据,之后就可以根据索引中的条目进行添加。
2.5 查询模块的实现
整个查询模块为用户提供了搜索主页以及结果显示,其具体的程序流程如图3 所示。在接收到主页传来的关键字数据之后,查询模块就要调用索引,开始对关键词进行索引;并将索引的结果全部返回,之后根据得分公式算出每一个条目的得分;用快排将所有的结果从高到低排列并显示,此处使用了异步传输技术,能够在不刷新整个网页的情况下根据点击下一页的次数显示全部的信息。

图3 查询显示程序流程图Fig.3 Flow diagram of query and display
3 系统测试及结果
系统实现之后,首先搜索模块的测试主要进行了网页下载、Robors. txt 下载和数据库访问的测试。由于网络的不稳定性及网站访问权限的设置,导致下载的速度具有变化性。经过多次测试得到整个搜索模块的效率大约是每小时抓取32.8个网页。
分析模块的测试是检测对于已下载网页的读取及分析效果,该测试展现了数据的读取、分析以及写入文件的一个基本过程如图4 所示;最终的查询效果如图5 所示。

图4 信息提取过程Fig.4 Information extraction process

图5 查询界面Fig.5 Searching interface
4 结 论
通过测试,基于. Net 平台的全文搜索引擎已经实现了搜素引擎的基本功能,即网页的抓取、分析、索引和关键词的分词、查询;并在这个基础上添加了具有较好用户体验的异步传输技术,使得用户能够在一页中查看全部的消息。与此同时,还添加了一个分类查询的效果。
该系统功能较为齐全,但仍然存在一些不足,在面对存在诸多的不确定性以及潜在的危险的网络时,需要增加爬虫对于网络错误信息的处理及对于病毒网站的过滤,增加对各种问题进行判断以及预处理的能力,以此增强爬虫的强壮性。
References
[1] Yu K,Hsu S,Otsubo P.The fast data finder-an architecture for very high speed data search and dissemination[J]. International Conference on Data Engineering,1984(4):167 -174.
[2] 冯飞燕.搜索引擎:穿透互联网的动力一搜索引擎能做什么[J].电子电脑,1996(2):96 -99.FENG Fei-yan. Search engine:penetration dynamic of Internet-What can search engine do[J].PC Computing,1996(2):96 -99.
[3] 梁 斌.走进搜索引擎[M].北京:电子工业出版社,2007.LIANG Bin. Stepping into search engine[M]. Beijing:Publishing House of Electronics Industry,2007.
[4] 陈俊杰.中文搜索引擎现状与发展研究[J]. 佳木斯教育学院学报,2011(3):491 -492.CHEN Jun-jie. Situation and development of Chinese search engines[J].Journal of Jiamusi Education Institute,2011(3):491 -492.
[5] 付立东.中心方法在复杂网络中的比较[J]. 西安科技大学学报,2010,30(1):107 -111.FU Li-dong.Comparison of centrality measures in complex networks[J]. Journal of Xi’an University of Science and Technology,2010,30(1):107 -111.
[6] 王知津,马晓瑜.搜索引擎个性化信息服务探讨[J].图书馆,2013(1):31 -35.WANG Zhi-jin,MA Xiao-yu. The personalized information service of search engines[J].Library,2013(1):31-35.
[7] 付立东.一种向量划分的网络社团发现方法[J]. 西安科技大学学报,2010,30(2):238 -240,254.FU Li-dong.A way of finding networks communities with vector partitioning[J]. Journal of Xi’an University of Science and Technology,2010,30(2):238 -240,254.
[8] 卢 亮,张博文.搜索引擎原理实践与应用[M]. 北京:电子工业出版社,2007.LU Liang,ZHANG Bo-wen. Search engine’s principle practice application[M]. Beijing:Publishing House of Electronics Industry,2007.
[9] 龚尚福,王艳君.多线程保护应用程序自动加载研究与实践[J].西安科技大学学报,2013,33(2):230 -234,248.GONG Shang-fu,WANG Yan-jun.Research and practice of automatic loading of applications based on multithreaded protection[J]. Journal of Xi’an University of Science and Technology,2013,33(2):230 -234,248.
[10] 阴爱英.基于线程并行计算的Apriori 算法[J].西安科技大学学报,2014,34(1):71 -74.YIN Ai-ying.Aproori algorithm based on thread parallel computing[J]. Journal of Xi’an University of Science and Technology,2014,34(1):71 -74.
[11] 戚艳军,龚尚福. 用户角色的XML 动态加密方法研究[J].西安科技大学学报,2012,32(1):101 -106.QI Yan-jun,GONG Shang-fu. Dynamic encryption of XML based on user roles[J].Journal of Xi’an University of Science and Technology,2012,32(1):101 -106.
[12] 刘磊安,符志强.基于Lucene.net 网络爬虫的设计与实现[J]. 电脑知识与设计,2010,6(8):1 870 -1 878.LIU Lei-an,FU Zhi-qiang. The design and implementation of web crawler based on lucene.NET[J].Computer Knowledge and Technology,2010,6(8):1 870 -1 878.
[13] 马 俊.基于正则表达式技术的信息搜集引擎应用研究[D].成都:电子科技大学,2006.MA Jun.Research on information search engine application based on regular expression[D].Chengdu:University of Electronic of Science and Technology of China,2006.
[14] Otis Gospodnetic,Erik Hatcher.Lucene in action[M].Beijing:Publishing House of Electronics Industry,2007.
[15] 武 毅. 基于Lucene. Net 的全文检索研究与应用[D].长沙:国防科学技术大学,2011.WU Yi. Resaerch and application of full-text retrieval based on lucene.Net[D].Changsha:National University of Defense Technology,2011.
[16] Chih-Hao Tasi.MMSEG:a word identification system for mandarin Chinese text based on two variants of the maximum matching algorithm[OL]. http://technology. chtsai.org/mmseg/,2013.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2018年2期)2018-04-18
电子制作(2017年9期)2017-04-17
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
