
统计机器翻译和翻译记忆的动态融合方法研究
2015-04-21 09:43宗成庆苏克毅
中文信息学报 2015年2期
汪 昆,宗成庆,苏克毅
(1.中国科学院 自动化研究所 模式识别国家重点实验室,北京100190;2. 台湾中央研究院 资讯科学研究所,台湾 台北)
统计机器翻译和翻译记忆的动态融合方法研究
汪 昆1,宗成庆1,苏克毅2
(1.中国科学院 自动化研究所 模式识别国家重点实验室,北京100190;2. 台湾中央研究院 资讯科学研究所,台湾 台北)
在融合翻译记忆和统计机器翻译的整合式模型的基础上,该文提出在解码过程中进一步地动态加入翻译记忆中新发现的短语对。它在机器翻译解码过程中,动态地加入翻译记忆片段作为候选,并利用翻译记忆的相关信息,指导基于短语的翻译模型进行解码。实验结果表明该方法显著提高了翻译质量: 与翻译记忆系统相比,该方法提高了21.15个BLEU值,降低了21.47个TER值;与基于短语的翻译系统相比,该方法提高了5.16个BLEU值,降低了4.05个TER值。
统计机器翻译;基于短语的翻译模型;翻译记忆;模型融合;动态加入翻译记忆短语对
1 引言
二十一世纪以来,统计机器翻译(Statistical Machine Translation, SMT)发展十分迅速,涌现出了多种不同的统计机器翻译模型,如基于短语的翻译模型[1-2],层次短语模型[3]和基于句法的翻译模型[4-6]等。随着翻译质量的不断提高和机器翻译技术(尤其是基于短语的翻译模型)的日趋成熟,统计机器翻译正在向实用化和商业化不断前进。但是由于目前机器翻译的翻译质量仍然与专业翻译的水平相距甚远,还无法满足辅助翻译的要求,因此机器翻译在专业翻译领域的应用还比较少。
在专业翻译领域,翻译人员一般更信任基于翻译记忆(Translation Memory,TM)[7]的计算机辅助翻译软件(Computer-assisted Translation,CAT);且更加倾向在翻译记忆的参考译文上(而不是机器翻译的译文)进行后编辑(Post-Editing)[8-9]。翻译记忆系统的工作原理是:根据输入内容在翻译记忆库中检索与其最相似的句子,并将该句子的翻译,作为参考翻译提交给用户进行后编辑。翻译记忆系统的性能,与翻译资料中含有重复内容的多少,有很大关系。翻译资料中的重复内容越多,翻译记忆系统的效果越明显。
近年来,越来越多的研究人员开始研究如何结合机器翻译和翻译记忆,以求减少后编辑的工作量。贺一帆等人[8]提出了一种基于翻译结果推荐的方式,将机器翻译系统与翻译记忆系统集成在一起。他们使用SVM分类器比较机器翻译的输出与TM系统的输出,然后将SVM认为较好的结果,推荐给后编辑人员,从而提高工作效率。此外,也有一些研究人员尝试利用TM系统的结果,将输入句子与TM系统给出的最相似句子进行匹配。这种做法先固定匹配部分(matched segments)的翻译,然后SMT系统仅翻译不匹配部分,从而提高翻译质量[10-14]。其中以Phillip Koehn等人提出的XML标记法的效果最好[9]。但是这些方法都是采用管道式的多步法,因此匹配部分翻译的挑选错误无法纠正;并且它们都是在句子级别决定是否采用TM系统的匹配部分,完全不考虑不同匹配部分的翻译质量。更为严重的是:对于匹配部分的翻译,它们完全没有考虑SMT的概率信息。
为了改进上述缺点,我们提出了一种整合式的模型[9],它在SMT解码过程中融入TM系统的相关信息。但是在此模型中,它并不考虑在TM新发现的短语对。因此本文提出在解码过程中进一步地动态加入TM新发现的短语对。实验表明,在动态加入TM新发现的短语对后,该整合式模型有效地改善了SMT系统和TM系统的翻译质量,并且显著地超过了前人的方法。
2 问题的数学描述
融入翻译记忆相关信息以后,翻译问题可以重新定义为:

(1)
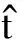
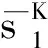
(2)
(3)
这就是融合翻译记忆的整合式模型。式(3)中,Mk表示目标语言端的匹配状态,Lk表示源语言端的链接状态,我们将在第3节介绍这些特征。P(Mk|Lk,z)是翻译记忆的相关信息,具体情况将在第4节介绍。
此外,我们将翻译记忆源语言句子tm_s与源语言句子s之间的模糊匹配系数tm_f平均分配为10个相似度区间: 如 [0.9, 1.0)、[0.8, 0.9)、[0.7, 0.8)等。我们用z来表示不同的相似度区间。模糊匹配系数的计算公式见式(4)。
(4)
其中Levenshtein(s,tm_s)表示s和tm_s之间的编辑距离[15],|s|和|tm_s|分别表示s和tm_s的元素数目。模糊匹配系数介于0到1之间。模糊匹配系数越高,表示两个句子之间的相似程度越高。
3 翻译记忆的相关特征

3.1 目标语言端的特征
目标语言端的匹配状态Mk,包含了“目标短语候选内容匹配状态”(TCM),“翻译记忆的最长候选指示特征”(LTC),以及“目标短语相邻候选相对位置匹配特征”(CPM)。各个特征的详细情况如下。
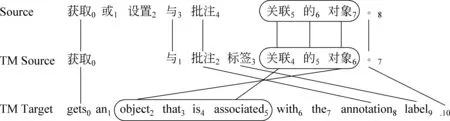
图1 翻译记忆样例
• 目标短语候选内容匹配状态TCM





• 翻译记忆的最长候选指示特征LTC

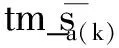
• 目标短语相邻候选相对位置匹配特征CPM

在计算机网络中,存在着大量的不安全因素,包括自然因素、人为因素以及偶发因素,其中人为因素对计算机网络安全的影响最大。许多不法之徒会利用计算机网络漏洞,盗用计算机系统资源,非法获取数据,垃圾邮件、间谍邮件等都在侵犯着计算机网络,计算机网络的不安全因素主要有以下几方面。

3.2 源语言端的特征
源语言端的链接状态Lk,包含了“源语言短语内容匹配状态特征”(SCM)、“源语言短语邻居链接数量特征”(NLN)、“源语言短语长度特征”(SPL)、“句尾标点符号指示特征”(SEP)以及“翻译记忆的翻译候选集合特征”(CSS)。各个特征的详细情况如下。
• 源语言短语内容匹配状态特征SCM

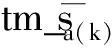

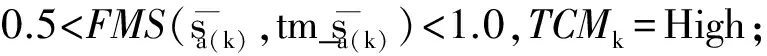

• 源语言短语邻居链接数量特征NLN
• 源语言短语长度特征SPL
• 句尾标点符号指示特征SEP
经过统计发现,句尾标点符号单独作为一个源语言短语时,它相应的SCMk和TCMk都是Same。因此,当源语言短语是句尾标点符号时,这两个特征(SCMk和TCMk)是完全相关的。此外,由于句尾标点符号的右边是句尾标记,NLNk中的x肯定是1或者2。所以,对其他短语而言,如果不区分这种情况,将会带来相当大的系统化偏差(SystematicBias)。因此,为了区分句尾标点符号与其他的源语言短语,我们定义了句尾标点符号指示特征SEP(Yes或者No)。
• 翻译记忆的翻译候选集合特征CSS
4 融合翻译记忆的整合式翻译模型
为了在基于短语的翻译模型中融入翻译记忆相关信息,我们提出了融合翻译记忆的整合式翻译模型(即式(3))。在解码过程中,对于每一个翻译假设(Hypothesis),我们不仅要计算原来短语翻译模型的得分(式(3)中的第一项),还要计算其对应的翻译记忆得分(式(3)中的第二项)。对于翻译记忆相关信息P(Mk|Lk,z),我们在源语言端和目标语言端分别引入上一节介绍的特征以后,P(Mk|Lk,z)可以简化为:
P(Mk|Lk,z)
≜P([TCM,LTC,CPM]k|[SCM,NLN,SPL,SEP]k,z)≈
(5)
本文采用三个加权因子来平衡式(5)中的三项。对于存在多个目标候选的情况,整合式模型会选择其中得分最高的进行解码。
5 实验与分析
5.1 实验设置 我们使用一个计算机领域的汉-英翻译记忆库进行实验。这个翻译记忆库包含26.7万汉英平行句对。我们从记忆库中随机抽取一部分作为开发集和测试集。其余部分随机平均分为两部分,一部分作为机器翻译模型的训练集,另外一部分作为翻译记忆系统的记忆库。对于所有汉语句子,我们使用Urheen词法分析系统*http://www.openpr.org.cn/index.php/NLP-Toolkit-For-Natural-Language-Processing/进行分词。训练集、开发集和测试集的统计情况如表1所示。同时,我们根据翻译记忆系统给出的模糊匹配系数将开发集和测试集分为多个模糊匹配区间,测试集的详细统计情况如表2所示。

表1 实验数据统计
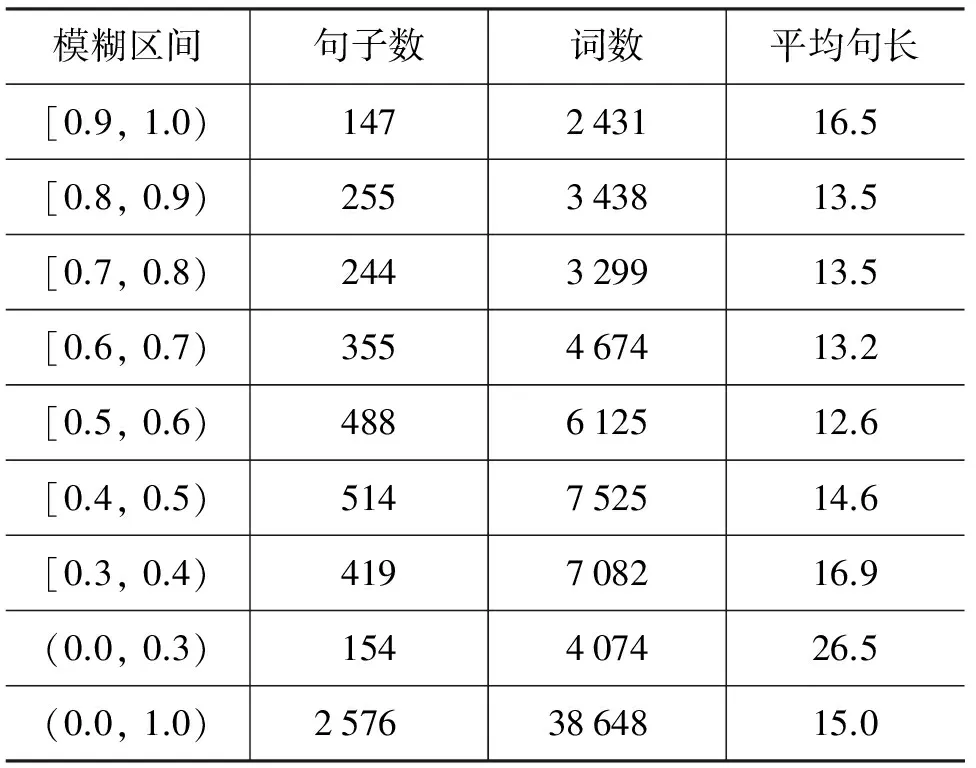
表2 测试集数据统计
本文使用GIZA++训练双语词对齐,并利用启发式规则grow-diag-final-and得到对称化的词对齐; 利用SRILM工具包[16]在SMT目标语言端的训练语料上,使用修正的Kneser-Ney平滑方法[17]训练一个五元语言模型;使用最小错误率参数训练方法[18]进行参数寻优;使用开源解码器Moses[19]进行短语翻译模型的解码;整合式模型也是在Moses解码器的基础上进行了相应的修改。短语长度限制为7,解码器的柱宽设为100。翻译记忆系统使用模糊匹配系数作为相似度度量进行检索。
在本文的实验中,我们使用大小写不敏感的BLEU[20]和翻译错误率TER[21]作为译文评价标准,并采用自举重采样(Bootstrap Re-Sampling)方法[22]检测两个翻译系统之间的统计显著性差异。
5.2 交叉翻译生成训练样本
整合式模型中的所有特征都是在短语上进行抽取的。然而SMT的训练语料仅仅是双语对齐的句子对,并不包含每个句子的短语切分。因此要估计整合式模型的参数,必须先生成“双语短语切分句对”的训练样本。为了更加真实地模拟解码过程中的短语切分,本文采用交叉翻译的方式生成整合式模型的训练样本: 随机将SMT的训练语料分成20份,使用其中19份训练一个SMT模型,对剩余的那份进行强迫解码[23],即可得到那份语料的双语短语切分句对。如此重复20次即可得到所有训练样本,进而估计整合式模型的参数。
5.3 动态添加短语对

因此,在解码过程中我们会动态加入那些短语表不能覆盖的匹配翻译对。为了区分这些短语对和短语表中原有的短语对,我们为这些短语设置四个不同的翻译模型权重,并将它们的双向短语翻译概率和双向词汇化翻译概率都设为1.0。在解码过程中,这些短语对和原始短语表中的短语对都会作为候选加入到解码器中,只是它们的翻译模型的权重不一样。
5.4 实验结果与分析
为了与前人的工作进行对比,我们重现了Phi-lippKoehn等人提出的XML标记法(XML)。表3和表4分别给出了翻译记忆系统(TM)、基于短语的翻译系统(SMT)、XML标记法以及整合式模型在测试集上的实验结果(BLEU和TER)。其中,“*”表示统计显著地(p< 0.05)优于TM和SMT系统;“#”表示统计显著地(p< 0.05)优于XML标记法;粗体字表示该区间的最优翻译结果。
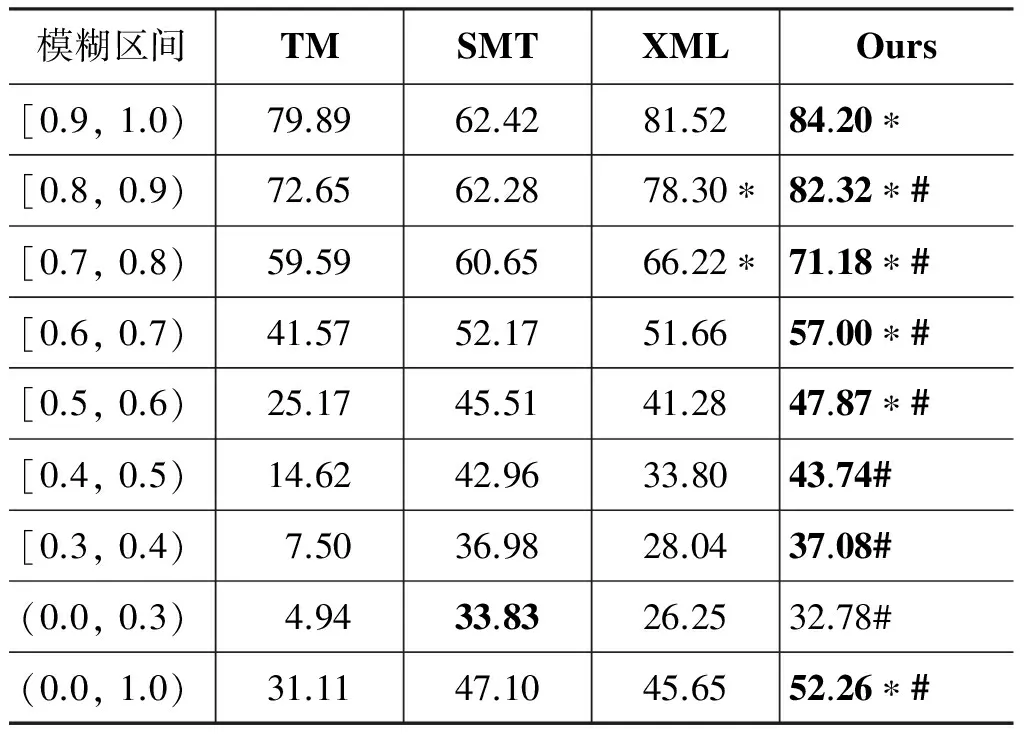
表3 各种方法的翻译结果(BLEU)

表4 各种方法的翻译结果(TER)
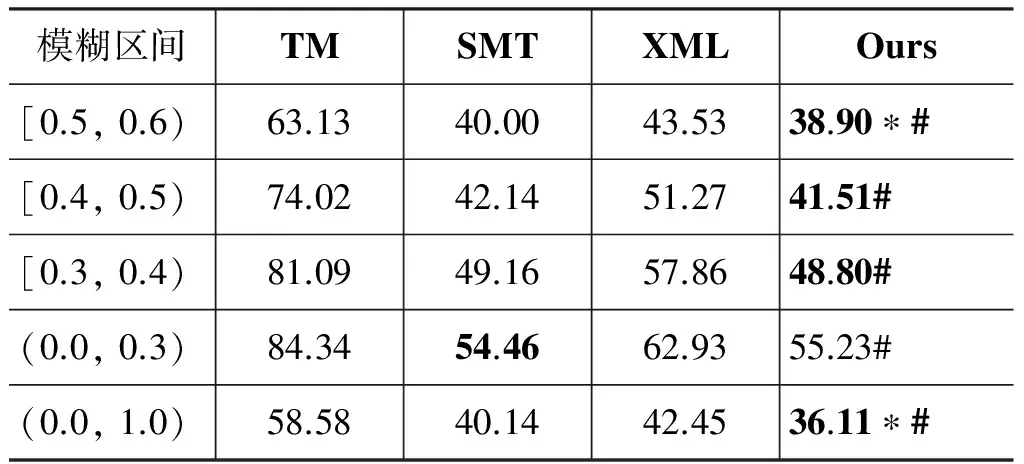
续表
从表3和表4的实验结果可以看出: 当模糊匹配系数大于0.7时,XML标记法提高了翻译结果的BLEU值,这与文献[11]的结论基本一致。但是,当模糊匹配系数大于0.5时,整合式模型统计显著地优于TM系统和SMT系统。只是在模糊匹配区间[0.9, 1.0),从BLEU值来看,整合式模型统计显著地优于TM系统,但是从TER值来看,TM系统优于整合式模型。这说明BLEU值和TER值的评价结果并不完全一致,而我们是以BLEU值作为优化目标进行参数优化的,假如以TER值作为优化目标,整合式模型的TER值会更理想一些。
从整体上看(表3和表4的(0.0, 1.0)区间),整合式模型统计显著地优于TM系统、SMT系统和XML标记法。与TM系统相比,整合式模型提高了21.15个BLEU值,降低了22.47个TER值;与SMT系统相比,整合式模型提高了5.16个BLEU值,降低了4.05个TER值。这说明本文提出的整合式模型显著地改善了翻译质量,也可以进一步减少后编辑的工作量。
本文提出在整合式模型中动态添加从翻译记忆中抽取的短语对。为了研究翻译记忆相关信息和动态短语对的作用,我们做了两组对比实验。如表5所示,SMT中“-”表示原来的短语翻译模型;SMT中的“+”表示加入动态短语对的短语翻译模型;Ours中的“-”表示仅利用翻译记忆相关信息进行解码,并不加入动态短语对;Ours中的“+”表示,在解码过程中不仅利用翻译记忆相关信息进行解码,还加入动态短语对。“*”表示动态短语对显著地(p < 0.05)改善了翻译质量。

表5 动态短语对对翻译质量的影响(BLEU)

续表
从表5中的实验结果可以看出: (1)当模糊匹配系数大于0.5时,动态添加短语对显著地改善了SMT的翻译质量(“SMT+” vs. “SMT-”),这说明了动态添加短语对的必要性;(2)翻译记忆相关信息显著地改善了SMT的翻译质量(“Ours-” vs. “SMT-”),这说明了翻译记忆信息的有效性;(3)当模糊匹配系数大于0.5时,在同时动态添加短语的情况下,翻译记忆相关信息显著地改善了SMT翻译质量(“Ours+” vs. “SMT+”),这说明了翻译记忆相关信息和动态添加短语对可以同时改善翻译质量,二者的作用并不重叠(“Ours+” vs.“Ours-”)。以上实验结果同时也说明了传统短语翻译模型的局限性: 即使短语表中存在能够包含可生成更好翻译结果的短语对,短语模型选到它们的比例也有限。
为了进一步验证本文提出的整合式模型,我们将短语翻译模型和翻译记忆系统的两个训练集互换,表6给出了各种方法在互换训练集以后的翻译结果。其中,“*”表示统计显著地(p<0.05)优于TM和SMT系统;“#”表示统计显著地(p<0.05)优于XML标记法;粗体字表示该区间的最优翻译结果。从实验结果可以看出,互换训练集以后,整合式模型仍然取得了最好的翻译结果,而且与表3的实验结果一致。这更进一步说明了整合式模型的有效性和鲁棒性。

表6 互换训练集后的翻译结果(BLEU)

续表
6 结束语
在融合翻译记忆和统计机器翻译的整合式模型上,本文提出在解码过程中进一步地动态加入翻译记忆中新发现的短语对。它在机器翻译解码过程中动态地加入翻译记忆片段作为候选,并利用翻译记忆的相关信息指导基于短语的翻译模型进行解码。本文的实验结果表明该方法显著地提高了翻译质量,统计显著地优于翻译记忆系统和基于短语的翻译模型。此外,该整合式模型还显著地优于前人提出的XML标记法。
[1] Franz Josef Och, Hermann Ney. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of ACL’2002: 295-302.
[2] Philipp Koehn, Franz Josef Och, Daniel Marcu. Statistical phrase-based translation[C]//Proceedings of NAACL’2003: 48-54.
[3] David Chiang. A hierarchical phrase-based model for statistical machine translation[C]//Proceedings of ACL’2005: 263-270.
[4] Kenji Yamada, Kevin Knight. A syntax-based statistical translation model[C]//Proceedings of ACL’2001: 523-530.
[5] Yang Liu, Qun Liu, Shouxun Lin. Tree-to-string alignment template for statistical machine translation[C]//Proceedings of ACL’2006: 609-616.
[6] Haitao Mi, Liang Huang, Qun Liu. Forest based translation[C]//Proceedings of ACL’2008: 192-199.
[7] Martin Kay. The proper place of men and machines in language translation [J]. Reprinted in Machine Translation, 1980: 12:3-23.
[8] Yifan He, Yanjun Ma, Josef van Genabith et al. Bridging SMT and TM with translation recommendation[C]//Proceedings of ACL’2010: 622-630.
[9] Kun Wang, Chengqing Zong, Keh-Yih Su. Integrating translation memory into phrase-based machine translation during decoding[C]//Proceedings of ACL’2013: 11-21.
[10] James Smith, Stephen Clark. EBMT for SMT: a new EBMT-SMT hybrid[C]//Proceedings of EBMT ’2009: 3-10.
[11] Philipp Koehn, Jean Senellart. Convergence of translation memory and statistical machine translation [C]//Proceedings of the AMTA Workshop’2010 on MT Research and the Translation Industry, 2010: 21-31.
[12] Ventsislav Zhechev, Josef van Genabith. Seeding statistical machine translation with translation memory output through tree-based structural alignment[C]//Proceedings of the 4th Workshop on Syntax and Structure in Statistical Translation, 2010: 43-51.
[13] Yanjun Ma, Yifan He, Andy Way et al. Consistent translation using discriminative learning: a translation memory-inspired approach[C]//Proceedings of ACL’2011: 1239-1248.
[14] Yifan He, Yanjun Ma, Andy Way et al. Rich Linguistic Features for Translation Memory-Inspired Consistent Translation[C]//Proceedings of MT Summit’2011: 456-463.
[15] Vladimir Iosifovich Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals [J]. Soviet Physics Doklady, 1966,10 (8): 707-710.
[16] Andreas Stolcke. SRILM-an extensible language modeling toolkit[C]//Proceedings of the International Conference on Spoken Language Processing 2002: 311-318.
[17] Stanley F. Chen, Joshua Goodman. An empirical study of smoothing techniques for language modeling [R].1998.
[18] Franz Josef Och. Minimum error rate training in statistical machine translation[C]//Proceedings of ACL’2003: 160-167.
[19] Philipp Koehn, Hieu Hoang, Alexandra Birch, et al. Moses: Open source toolkit for statistical machine translation[C]//Proceedings of ACL’2007 Demo and Poster Sessions,2007: 177-180.
[20] Kishore Papineni, Salim Roukos, Todd Ward et al. BLEU: a method for automatic evaluation of machine translation[C]//Proceedings of ACL’2002: 311-318.
[21] Matthew Snover, Bonnie Dorr, Richard Schwartz, et al. A study of translation edit rate with targeted human annotation[C]//Proceedings of the AMTA’2006: 223-231.
[22] Philipp Koehn. Statistical significance tests for machine translation evaluation[C]//Proceedings of EMNLP’2004: 388-395.
[23] Andreas Zollmann, Ashish Venugopal, Franz Josef Och, Jay Ponte. A systematic comparison of phrase-based, hierarchical and syntax-augmented statistical MT[C]//Proceedings of Coling’2008: 1145-1152.
Dynamic Combination of Statistical Machine Translation and Translation Memory
WANG Kun1, ZONG Chengqing1, SU Keh-Yih2
(1. National Lab of Pattern Recognition, Institute of Automation, Chinese Academy of Sciences, Beijing 100190, China; 2. Institute of Information Science, Academia Sinica, Taibei, Taiwan, China)
Under a framework of combining translation memory (TM) and statistical machine translation (SMT), this paper proposes to further dynamically add new phrase-pairs found in TM. During decoding, the integrated model adds those TM matched segments into the SMT phrase table as candidates dynamically, and incorporates corresponding TM information for each hypothesis to guide SMT decoding. Our experimental results show that the proposed approach improves translation quality significantly: compared with TM system, the integrated model achieves 21.15 BLEU points improvements and 21.47 TER points reduction; compared with SMT system, the integrated model achieves 5.16 BLEU points improvements and 4.05 TER points reduction.
statistical machine translation; phrase-based machine translation, translation memory; model integration; dynamically adding phrase-pairs

汪昆(1986—),博士,主要研究领域为自然语言处理与机器翻译。E⁃mail:kunwang@nlpr.ia.ac.cn宗成庆(1963—),研究员,主要研究领域为机器翻译、口语信息处理和文本分类等。E⁃mail:cqzong@nlpr.ia.ac.cn苏克毅(1955—),研究员,主要研究领域为统计机器翻译、机器阅读和自然语言理解。E⁃mail:kysu@iis.sinica.edu.tw
1003-0077(2015)02-0087-08
2013-03-11 定稿日期: 2013-07-01
国家自然科学基金(61402478)
TP391
A
猜你喜欢
中国石油石化(2022年12期)2022-07-16
中国外汇(2019年19期)2019-11-26
河南教育·高教(2019年3期)2019-04-11
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
北方文学(2018年18期)2018-09-14
海峡姐妹(2016年2期)2016-02-27
考试周刊(2015年36期)2015-09-10
科学中国人(2014年22期)2014-07-23
