
基于深度自动编码器与Q学习的移动机器人路径规划方法
2016-10-19 02:22于乃功默凡凡
北京工业大学学报 2016年5期
于乃功, 默凡凡
(1.北京工业大学电子信息与控制工程学院, 北京 100124;2.北京工业大学计算智能与智能系统北京市重点实验室, 北京 100124;3.数字社区教育部工程研究中心, 北京 100124;4.城市轨道交通北京实验室, 北京 100124)
基于深度自动编码器与Q学习的移动机器人路径规划方法
于乃功1,2,3,4, 默凡凡1,2,3,4
(1.北京工业大学电子信息与控制工程学院, 北京100124;2.北京工业大学计算智能与智能系统北京市重点实验室, 北京100124;3.数字社区教育部工程研究中心, 北京100124;4.城市轨道交通北京实验室, 北京100124)
针对移动机器人在静态未知环境中的路径规划问题,提出了一种将深度自动编码器(deep auto-encoder)与Q学习算法相结合的路径规划方法,即DAE-Q路径规划方法. 利用深度自动编码器处理原始图像数据可得到移动机器人所处环境的特征信息;Q学习算法根据环境信息选择机器人要执行的动作,机器人移动到新的位置,改变其所处环境. 机器人通过与环境的交互,实现自主学习. 深度自动编码器与Q学习算法相结合,使系统可以处理原始图像数据并自主提取图像特征,提高了系统的自主性;同时,采用改进后的Q学习算法提高了系统收敛速度,缩短了学习时间. 仿真实验验证了此方法的有效性.
移动机器人; 路径规划; 深度自动编码器;Q学习算法
移动机器人技术是国家工业化与信息化进程中的关键技术和重要推动力,移动机器人已经广泛应用于农业生产、海洋开发、社会服务、娱乐、交通运输、医疗康复、航天和国防以及宇宙探索等领域[1]. 移动机器人研究的重点及难点在于如何使机器人在复杂环境下自主地完成某项预定的任务,它主要解决的问题可分为3个方面:1) “我(机器人)现在身在何处”;2) “我要往哪儿走”;3) “我要如何到达该处”. 而路径规划解决的就是机器人“我要如何到达该处”的问题.
移动机器人路径规划方法可分为基于模版匹配的路径规划技术、基于人工势场的路径规划技术、基于地图构建的路径规划技术和基于人工智能的路径规划技术. 基于人工智能的路径规划技术是将现代人工智能技术应用到移动机器人的路径规划中,如强化学习、人工神经网络、进化计算、模糊逻辑与信息融合等[2].
其中,强化学习不依赖于环境模型,不需要环境的先验知识,鲁棒性强,逐渐成为机器人领域的一个研究热点. Beom将模糊逻辑与强化学习算法结合实现了地面移动机器人的导航[3];Deisenroth等[4]将高斯过程与基于模型的策略搜索强化学习结合,并将其应用在机器人的控制中;Maeda等[5]利用人工神经网络的拟合能力,使其与强化学习结合实现了移动机器人在特定任务中的路径规划. 要把基于强化学习的路径规划应用在真实环境中,系统必须能很好地处理图像数据. 但以上方法均需要人工决定提取何种图像特征,提取的图像特征的效果是未知的,且步骤烦琐. 将深度自动编码器应用在强化学习中可利用深度自动编码器处理原始图像数据,实现自主提取图像特征,可以免去人工提取数据特征的巨大工作量.
文献[6]使用卷积神经网络与强化学习结合,并将其应用在真实环境中的小车轨迹跟踪中. 文献[7]对批量模式的强化学习算法与深度自动编码器的结合进行了理论研究. 在文献[6]与文献[7]的基础上,本文将一种改进后的Q学习(Q-learning)算法与深度自动编码器结合,并成功地应用在了移动机器人的路径规划中.
1 DAE-Q路径规划系统
DAE-Q路径规划系统框图如图1所示.
首先,将移动机器人所在位置的环境信息传递给深度自动编码器(环境信息为环境图像数据),深度自动编码器对其进行编码获取图像的特征信息[8]. 然后,将特征信息传递给BP神经网络进行拟合,得到机器人所处位置的值. 深度自动编码器与BP神经网络结合实现移动机器人全局定位功能;通过位置信息得到相应奖励值R,并将奖励值返回给Q学习算法对Q值进行迭代更新,机器人根据Q值选择相应的动作,使机器人的位置发生改变,其所处环境随之发生变化,实现了机器人与环境的交互. 最后,将变化后的环境信息传递给深度自动编码器,以此循环往复.
2 Q学习算法
强化学习的核心思想是与环境交互学习,在行动- 评价的环境中获得知识,改进行动方案以适应环境达到预想目的[9]. 试错搜索和延迟回报是强化学习算法2个最显著的特征.
机器人感知周围环境状态,根据强化学习算法选择相应的动作,机器人执行完动作后会作用于环境使环境发生改变,同时返回一个奖赏信号给机器人[10].
Q学习算法的产生是强化学习的一个重要里程碑,它是一种模型无关的强化学习算法. 最优行为值估计的更新依赖于各种“假设”的动作,而不是学习策略所选择的实际动作.Q学习算法常采用数值迭代来逼近最优值,其更新规则为
Q(st,at)=Q(st,at)+
(1)
式中:α∈[0,1]是学习率,控制学习速度;st为机器人当前的状态(文中是机器人的位置坐标);at为机器人选择的动作值,各动作值为at=[1,2,3,4,5],各数值分别表示机器人向右走、向上走、向左走、向下走、停在原地;Rt为机器人选取动作at,机器人状态从st转换为st+1时对应的奖励值;γ∈[0,1]是折扣因子. 由式(1)可知,要更新的Q值是由原来的Q值和下一个状态的Q值共同决定,Q学习数据更新过程如下:
第1步训练s0←s1
第2步训练s0s1←s2
第4步训练s0s1s2←s3
⋮
第n步训练s0s1s2…sn-1←sn
由以上可知,Q值数据传递具有一定的滞后性,假设有任意相连的s1、s2、s3三种状态,状态s1要获得状态s3的Q值反馈需要2次重复训练循环,即s3将其Q值反馈给s2,s2再将其Q值反馈给s1;同样,第1个Q值要获得相隔n个状态的Q值反馈需要重复训练n次,这也是限制强化学习算法收敛速度的一个重要原因.
本文采用一种基于“回溯”思想的Q值更新策略. 首先定义记忆矩阵M(t)←[st,at] 来依次记录agent所经历过的所有状态与相应动作,以记忆矩阵中的状态动作对作为索引来找到其对应的Q值,并进行更新,更新过程如下:
Q(sk,ak)←Q(sk,ak)+
k=t-1,t-2,…,2,1
(2)
第1步训练
s0←s1
第2步训练
s0←s1←s2
第3步训练
s0←s1←s2←s3
⋮
第n步训练
s0←s1←s2←…←sn-1←sn
由以上数据更新过程可知,第1个Q值要获得相隔n个状态的Q值反馈,可根据记忆矩阵存储的状态动作值找到之前的Q值,再依次反馈到当前的状态,无需训练n次才能将相隔n个状态的Q值反馈给当前状态. 利用“回溯”思想改善了Q学习过程中数据传递的滞后性,使后续动作产生的影响可快速反馈给当前的状态,理论上来说可提高系统的学习速度,而这也将在后续的仿真实验中得到验证.
3 深度自动编码器
作为深度学习结构的主要组成部分之一,深度自动编码器主要用于完成转换学习任务,同时在无监督学习及非线性特征提取过程中也扮演着至关重要的角色. 思想是堆叠多个层(s1,s2,…,sn),令每层的输出等于输入. 在任何一层si,它都是原有信息(即输入)的另外一种表示,实现对输入信息的分级表达,并将这一层的输出作为下一层的输入. 其网络结构如图2所示.
其每层参数更新公式为
(3)
(4)
(5)
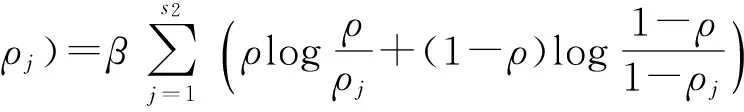
(6)
(7)
(8)
(9)
4 深度自动编码器与Q学习算法的结合
本文利用BP神经网络实现Q学习与深度自动编码器的结合[11]. 建立具有7个输入节点、10个隐藏节点和32个输出节点的BP神经网络. BP神经网络的输入是由深度自动编码器得到的图像特征值,32个输出节点中只有1个节点的值为1,其他31个节点值为0,即1个32行1列的矩阵. 机器人一共有32个不同的位置,在不同位置时,BP神经网络输出值为1的节点是32个输出节点中不同的节点,由此判断机器人所处的位置并得到与机器人位置相对应的奖励值,相应的奖励值反馈给Q学习算法,使Q学习实现Q值的更新. 当机器人处于某一位置时BP神经网络拟合结果误差如图4所示. 可以看出BP神经网络实现了相应的拟合.
通过将深度自动编码器与Q学习算法结合使系统可以自主提取未经处理的图像的特征,提高了系统的自主性和处理图像的能力;并且深度自动编码器可以处理高维数据,实现高维数据的降维,增强了系统处理数据的能力.
5 实验结果及分析
本实验实现了移动机器人在有障碍物的环境中通过与环境的交互不断地自主学习,找到从起始点到达目标点的可行路径,并且最终使机器人行走步数达到收敛不再盲目行走.
1) 建立一个具有障碍物的10×10网格环境,如图5所示[12]. 图中黑色物体代表障碍物. 建立环境矩阵E,设置Ei=1 表示此处是障碍物,Ei=0表示此处无障碍物. 移动机器人的起点位置为(1,1)点,终点位置为(9,8)点,动作值a=[1,2,3,4,5],各数值分别表示机器人向右走、向上走、向左走、向下走、停在原地,移动机器人的任务是从起点避开障碍物走到终点.
2) 设置Q学习算法各实验参数为α=0.3,γ=0.95,障碍物处的奖励值R为-0.3,目标点处的奖励值为1,其余位置处奖励值为0.
3) 建立记忆矩阵Aslist=[st,at],保存机器人依次的状态和动作值,以st、at为索引找到之前各个状态的Q值,将Q值依次进行迭代更新.
4) 将Q学习算法和改进后的Q学习算法分别应用在此环境中,对比结果如图6所示. 纵坐标表示每次从起点走到终点的步数,横坐标表示迭代次数.
由图6中图(a)可以看出,迭代5次左右时系统基本达到收敛,而且行走步数在收敛前稳步减小,而图(b)中,系统需迭代近50次才开始收敛,而且在收敛前行走步数很不稳定,由此可知,利用“回溯”思想可改善Q学习算法数据传递滞后性,缩短系统学习时间,提高收敛速度.
5) 建立了除输入层外具有4层隐藏层的深度自动编码器,输入层有2 500个节点,4层隐藏层的节点数分别为700、200、55、7. 每层训练时先随机设定此层的隐藏节点数,进行训练,如果训练效果不好,则改变隐藏节点数直到达到预期训练结果. 如此,逐层确定每层的隐藏节点数.
6) 训练深度自动编码器. 将移动机器人每个位置的图像像素设为50×50. 因为移动机器人一共有32个不同的位置,每个位置取100个样本,所以共取3 200个样本训练网络. 首先训练各个层,使各层输出可以复现输入,运用梯度下降法与Rprop方法更改各层参数值,训练后总误差为10.161 8. 将最后隐层输出的7个值进行反解码得到输入的复现,得到的效果图如图7中图(b),输入图如图(a). 由此可见,深度自动编码器很好地复现了输入,提取了输入的特征.
7) 训练好各隐藏层后固定各层参数,在最后一层隐藏层后接一分类器,将3 200个样本作为traindata对整个系统进行微调. 取320个样本作为testdata对微调后的系统进行测试,分类结果为:
Before Finetuning Test Accuracy: 71.875%
After Finetuning Test Accuracy: 100.000%
8) 将训练好参数的深度自动偏码器网络与BP神经网络相连,深度自动编码器最后一层的输出作为BP神经网络的输入,训练BP神经网络实现特征信息与移动机器人位置的非线性拟合.
9) 移动机器人在不同位置时由以上网络获取R值,返回给Q函数,更新Q值,寻找行走路线. 最终运行结果如图8、9所示,收敛前移动机器人行走过程如图10所示. 由图9、10对比可知,系统收敛前机器人从起始点到达目标点是盲目探索,而收敛
后机器人不再盲目行走,经过与环境不断交互移动机器人提高了学习能力,找到了一条从起始点到达目标点的可行路径.
6 结论
1) 通过将强化学习与深度学习结合,使机器人在未知环境中没有周围环境先验知识的情况下通过与环境的交互提高学习能力进行路径规划.
2) 通过深度自动编码器处理周围环境图像,提高了系统的自主性和处理图像数据的能力,使系统可以处理原始图像,自主地提取好的特征.
3) 与遗传算法和模拟退火算法相比,遗传算法没有能够及时利用网络的反馈信息,故算法的搜索速度比较慢,且算法对初始种群的选择有一定的依赖性;而模拟退火算法收敛速度慢,执行时间长. 此方法将以前的状态和动作及时反馈回来,收敛速度快,具有较高的实时性.
4) 文中强化学习处理的是离散状态,但真实环境中机器人的状态是连续的,为将此方法成功应用在真实环境中,要改进强化学习算法,使其可以处理连续状态空间.
[1] 张琦. 移动机器人的路径规划与定位技术研究[D]. 哈尔滨: 哈尔滨工业大学, 2014.
ZHANG Q. Path planning and location for mobile robot[D]. Harbin: Harbin Institute of Technology, 2014. (in Chinese)
[2] 朱大奇, 颜明重. 移动机器人路径规划技术综述[J]. 控制与决策, 2010, 25(7): 961-967.
ZHU D Q, YAN M Z. Survey on technology of mobile robot path planning [J]. Control and Decision, 2010, 25(7): 961-967. (in Chinese)
[3] BEOM H R, CHO H S. A sensor-based navigation for a mobile robot using fuzzy logic and reinforcement learning[J]. IEEE Trans on System, Man and Cybernetics, 1995, 25(3): 464-477.
[4] DEISENROTH M P, FOX D, RASMUSSEN C E. Gaussian processes for data-efficient learning in robotics and control[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2015, 37(2): 408-423.
[5] MAEDA Y, WATANABE T, MORIYAMA Y. View-based programming with reinforcement learning for robotic manipulation[C]∥2011 IEEE International Symposium on Assembly and Manufacturing (ISAM). Piscataway, NY: IEEE, 2011: 1-6.
[6] LANGE S, RIEDMILLER M, VOIGTLANDER A. Autonomous reinforcement learning on raw visual input data in a real world application[C]∥The 2012 International Joint Conference on Neural Networks (IJCNN). Piscataway, NY: IEEE, 2012: 1-8.
[7] LANGE S, RIEDMILLER M. Deep auto-encoder neural networks in reinforcement learning[C]∥The 2010 International Joint Conference on Neural Networks (IJCNN). Piscataway, NY: IEEE, 2010: 1-8.
[8] LIU H L, TANIGUCHI T. Feature extraction and pattern recognition for human motion by a deep sparse autoencoder[C]∥2014 IEEE International Conference on Computer and Information Technology (CIT). Piscataway, NY: IEEE, 2014: 173-181.
[9] 陈宗海, 杨志华, 王海波, 等. 从知识的表达和运用综述强化学习研究[J]. 控制与决策, 2008, 23(9): 961-968.
CHEN Z H, YANG Z H, WANG H B, et al. Overview of reinforcement learning from knowledge expression and handling [J]. Control and Decision, 2008, 23(9): 961-968. (in Chinese)
[10] 许亚. 基于强化学习的移动机器人路径规划研究[D]. 济南: 山东大学, 2013.
XU Y. Research on path planning for mobile robot based on reinforcement learning[D]. Jinan: Shandong University, 2013. (in Chinese)
[11] MAEDA Y, ABURATA R. Teaching and reinforcement learning of robotic view-based manipulation[C]∥IEEE RO-MAN 2013. Piscataway, NY: IEEE, 2013: 87-92.
[12] GOYAL J K, NAGLA K S. A new approach of path planning for mobile robots[C]∥2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI). Piscataway, NY: IEEE, 2014: 863-867.
(责任编辑吕小红)
Mobile Robot Path Planning Based on Deep Auto-encoder andQ-learning
YU Naigong1,2,3,4, MO Fanfan1,2,3,4
(1.College of Electronic and Control Engineering, Beijing University of Technology, Beijing 100124, China;2.Beijing Key Laboratory of Computational Intelligence and Intelligent System, Beijing University of Technology,Beijing 100124, China; 3.Engineering Research Centre of Digital Community, Ministry of Education, Beijing 100124,China; 4.Beijing Laboratory for Urban Mass Transity, Beijing 100124, China)
To solve the path planning problem of mobile robot in static unknown environment, a new path planning method was proposed which combined the deep auto-encoder with theQ-learning algorithm, namely the DAE-Qpath planning method. The deep auto-encoder processed the raw image data to get the feature information of the environment. TheQ-learning algorithm chose an action according to the environmental information and the robot moved to a new position, changing the surrounding environment of the mobile robot. The robot realized autonomous learning through the interaction with the environment. The system processed raw image data and extracted the image feature autonomously by combining the deep auto-encoder and theQ-learning algorithm, and the autonomy of the system was improved. In addition, an improvedQ-learning algorithm to improve the system’s convergence speed and shorten the learning time was utilized. Experimental evaluation validates the effectiveness of the method.
mobile robot; path planning; deep auto-encoder;Q-learning algorithm
2015- 10- 12
国家自然科学基金资助项目(61573029)
于乃功(1966—), 男, 教授, 主要从事机器人学、机器视觉、人工智能方面的研究, E-mail:yunaigong@bjut.edu.cn
TP 242
A
0254-0037(2016)05-0668-06
10.11936/bjutxb2015100028
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
北京航空航天大学学报(2022年6期)2022-07-02
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
计算机测量与控制(2021年12期)2021-12-22
锻压装备与制造技术(2021年5期)2021-11-13
天津理工大学学报(2021年3期)2021-09-08
现代仪器与医疗(2021年1期)2021-06-09
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
