
两种翻译方向下语言隐喻对源语理解过程的影响
2018-10-12 03:45王一方
外语学刊 2018年2期
王一方
(英国杜伦大学,杜伦DH12JZ)
1 引言
在翻译学领域,“无论从翻译实践的角度,还是从理论探讨的角度”(Schäffner 2004:1253),隐喻翻译的研究都“引发了许多至关重要的问题”(Do⁃brzynska 1995:595)。随着科技发展和实证研究方法的应用,学者们逐渐开始关注隐喻认知过程(Jones et al.2006; Faust, Weisper 2000)。 虽然关于概念隐喻的认知过程研究很多,但对语言隐喻的关注度不高(项霞 郑冰寒2011:423)。“隐喻式的思维是一种在感觉思维基础上沉淀人类文化基因的思维方式,它已经成为人类思维的一种本源性的和本然性的思维能力,是人类的一种建设性和创造性的思维。”(徐盛桓 廖巧云2017:11)语言隐喻与概念隐喻相对立(Lakoff 1993:202, Kövecses 2002:33),指的是“将原用于指代某物的词或词组指代另一事物,因为两个所指之间存在一些真实或隐含的相似性”(Anderson 1964:53,项霞 郑冰寒 2011:422)。
在语言隐喻相关的认知过程研究中,专门针对语言隐喻翻译过程的实证研究数量不多,与大量的翻译实践不成比例。大多数对语言隐喻认知的理论探讨和实证研究结果都不能直接应用在语言隐喻翻译过程研究中。因为学者们发现,认知目的会对认知资源分配模式造成显著影响。如Jakobsen和Jensen通过眼动追踪法证实,以理解为目的的阅读和以翻译为目的的阅读相比,二者所耗费的认知负荷量存在显著差异(Jakobsen,Jensen 2008)。Carl和Dragsted发现,翻译过程经常会始于针对原文含义的“推测”,即对译文的部分构思,然后原文的含义“会随着翻译过程而浮现与固化”(Carl,Dragsted 2012:143)。 此外,Balling等学者也通过眼动等实验方法发现,译者在源语理解的过程中已经开始目的语再形成的预处理(Balling et al.2014:251)。这些发现证实,就认知资源的分配模式而言,翻译时的理解过程与阅读时的理解过程存在显著差异。这就意味着,此前大量关于隐喻认知和理解过程的实证研究(Diaz et al.2011;Wang,He 2013;Obert et al.2014),由于其实验设计大多基于普通阅读而非翻译,所以直接用来描述隐喻翻译的理解过程会缺乏客观性和准确性。
鉴于上述情况,要想准确描述隐喻对译者的源语理解产生的影响,理论模型和实验设计必须基于隐喻翻译来构建。本研究秉持这一原则,采用眼动法和键击法等实证手段,描述38位译者的隐喻笔译过程;重点研究在英汉和汉英笔译时,语言隐喻对源语理解所耗费的认知资源造成哪些影响;然后进一步探讨:在英译汉和汉译英这两个翻译方向下,语言隐喻对源语理解过程的影响是否会随着翻译方向的改变而改变。
2 隐喻翻译的理解过程与翻译方向
作为翻译学领域最古老的课题之一(Gile 2005:9),翻译方向主要指译者在从事翻译活动时译入还是译出第一语言(Beeby 1998:63-64)。在很多国家,译出母语数量占据整个翻译行业的半壁江山(Shuttleworth, Cowie 1997:90),翻译方向的研究越来越得到重视(Newmark 1988:52)。调查显示,中国大陆的译者“经常译出母语”(Wang 2011:907);在香港翻译界,从母语译入英语的需求之大,“深刻影响专业译者的工作模式”(Li 2001:89)。在这一现实背景下,实证研究和理论指导非常必要。作为最常见的修辞手法之一,隐喻翻译的实践无法摆脱行业现状的影响,相关研究和理论指导对隐喻翻译实践的意义自不待言。
传统的翻译方向研究以理论探讨为主,近年来,学者们也逐渐开始用实证手段研究这一课题,实证研究方法包括有声思维法、眼动追踪法、键击法、事件相关电位等。许多学者对翻译方向与译者认知资源分配模式的关系尤为关注(Jensen,Pavlovi'c 2009;Chang 2011等)。譬如,Kroll和Stewart提出的修正层次模型(the Revised Hierar⁃chical Model)认为:比起从第二语言译入第一语言,一个单词从第一语言译入第二语言时要耗费更多的时间和经由更复杂的认知路径(Kroll,Stewart 1994)。简单来讲,第一语言的词汇存储与概念存储之间的链接清晰而牢固;相比之下,第二语言的词汇存储与概念存储之间的联系则脆弱得多,二语词汇与概念的连接常常要经过与其对应的第一语言词汇。一语和二语存储在同一个语义系统,但二语和一语的词汇表征相互独立;在很多情况下,二语单词译入一语的过程可以只通过词汇层面而不牵涉语义,不启动概念。因此,二语单词译入一语所耗费的翻译时长显著短于一语译入二语。
这一模型被置入不同语言之间进行验证和探讨(Altarriba, Mathis 1997;Jiang 1999;Rinne et al.2000),如Chang通过眼动追踪法、功能性磁共振成像等证实,修正层次模型不但在单词层级成立,在英汉文本互译过程中,也存在“翻译的不对称性”(translation asymmetry)(Chang 2011:156)。然而,在关于翻译方向的实证研究中,源语和目的语文本往往被视为实验载体,并没有得到应有的重视。具体来说,本研究考察的重点是“以语言隐喻为核心的、不同种类源语的理解过程的差异”,这一点很少被列入翻译方向过程研究中。
对隐喻翻译过程来讲,将翻译方向纳入研究范畴,在行业现状的实际需求下,能解决许多重要问题,如隐喻认知翻译过程理论和实验结果的适用性等。Sjørup在英语译入丹麦语的研究中发现,相比于字面表达(literal expression)的理解过程,隐喻的理解过程所消耗的认知负荷并没有显著增多(Sjørup 2013:204)。 这一发现是否仅仅局限于英语译入丹麦语值得探究。同等文本难度下,丹麦语译入英语时是否也会发生同样的情况呢?考虑到不同翻译方向对译者认知资源分配模式的 影 响 (Tokowicza, Kroll 2007:778;Chang 2011:156),直接用该发现来描述丹麦语译入英语的翻译过程会不客观,对两个翻译方向进行对比研究才能回答这一问题。以往的隐喻翻译过程实证研究很少与翻译方向相结合,语言隐喻翻译过程实 证研 究 (Mandelblit 1996;Tirkkonen⁃Condit 2002;Jensen 2005;Martikainen 2007;Sjørup 2013;项霞 郑冰寒 2011;Zheng, Xiang 2014; Schäffner,Shuttleworth 2013;Schmaltz 2015;Koglin 2015)较常涉及到的问题包括:背景信息与隐喻视译过程(项霞 郑冰寒 2011; Zheng,Xiang 2014)、隐喻翻译的过程和产出(Tirkkonen⁃Condit 2002,Sjørup 2013)、隐喻翻译过程与翻译能力(Jensen 2005)、隐喻对译者认知资源分配模式的影响(Sjørup 2013, Schmaltz 2015)、隐喻与译后修改过程(Ko⁃glin 2015),等等。本研究的核心问题之一是隐喻对源语理解过程的影响,而源语理解过程的描述一般只基于一个翻译方向,因此隐喻翻译的理解过程与翻译方向的关系尚未得到足够的探讨。
基于上述情况,本研究将译者的认知资源分配模式、语言隐喻的翻译过程和翻译方向这3个问题结合起来,进行系统考察;采用眼动追踪法和键盘记录法,通过观察和描述38位被试汉英互译的过程,探究以下问题:(1)相比于字面表达,译者在理解语言隐喻的过程中,所耗费的认知资源是否有区别;(2)源语中特有的语言隐喻(特定隐喻)和源语与目的语中都有固定表达的语言隐喻(共有隐喻),二者理解过程中耗费的认知资源是否有区别。在本实验中,语言隐喻对译者认知资源的影响分为以下几个方面:对翻译过程中的认知资源总量的影响、对译者认知资源调配的影响以及对译者工作记忆认知负荷的影响(Hvelplund 2011:220),通过眼动等实证方法的数据描述每一个方面的影响。(3)对于第一语言为汉语,第二语言为英语的中国译者来说,语言隐喻对源语理解过程的影响,是否会随着翻译方向的改变而发生变化。换句话说,译入和译出母语相比,语言隐喻对源语理解过程的影响有哪些异同?
3 研究设计
3.1 实验设置
本实验的主要研究方法为眼动追踪法,辅助方法为键盘记录法。被试在笔译过程中的眼动追踪数据由Tobii TX300(300Hz)眼动仪采集,键击数据由Translog II键盘记录软件采集。在实验过程中,被试在同一台电脑上完成翻译任务。被试距离电脑屏幕60-65厘米,电脑显示屏尺寸为23英寸,分辨率为1280∗1024。在屏幕上,源语与目的语以左、右分割方式呈现。源语字体大小和间距都按字数成比例调整,英文字体为Times New Roman,中文字体为宋体。字号为16,行间距为1.5 倍。
3.2 被试
本研究共招募到38位英国杜伦大学翻译学女硕士生,她们自愿参与实验。被试年龄为22-24岁,来自中国大陆,她们的第一语言为汉语,第二语言为英语。被试入学前英语雅思成绩平均分为7分(SD=0.5)。所有被试的双眼矫正视力为1.0以上,日常电脑笔译时基本为盲打,并且能熟练使用实验电脑上提供的中文输入法(搜狗拼音输入法)。被试参加实验前先签署实验同意书,并获得10英镑的乐购购物券作为报酬。
实验结束后,在38位被试中,共有34位被试的眼动数据通过质量评定标准。眼动数据质量评定标准包括以下几个方面:屏幕注视总时间(gaze time on screen),注视样本占比(gaze sample to fi⁃xation percentage),平均注视时长(mean fixation duration)(Rayner 1998,Hvelplund 2011)。
3.3 实验文本
为提升内容效度,本实验随机设计两组翻译任务,译者随机选择并完成其中一组任务。每组任务各包含一篇英文原文和中文原文。这两组翻译任务的汉英原文都是包含语言隐喻的简单日常对话,通俗易懂,没有使用特殊句型或专业术语,阅读难度较低。两组翻译任务的区别是:在第一组的汉英原文中,每句话都包含一个语言隐喻,句子顺序与隐喻类型(特定隐喻、共有隐喻)无关。第二组原文中的隐喻按照类型固定分配:全文有9句话,前3句话是字面表达,中间3句话各包含1个共有隐喻,最后3句话各包含1个特定隐喻。有16名被试抽签抽到第一组任务,有22名被试抽到第二组任务。在数据分析时,原文中的隐喻被切割出来作为语言隐喻的关注区域(area of interest),与字面表达的数据做对比。
针对同一任务内的英文和中文原文,由于本实验重点考察翻译过程中语言隐喻对理解过程的影响,再将两个翻译方向的隐喻影响做宏观对比,而不是直接对比两个翻译方向的源语理解过程。所以,实验中同一任务内英语原文和汉语原文的对比度没有严格的要求,文风、篇幅、句型、词频难度在同一范围内即可。对比度主要集中在同一篇文章中的句子和句子之间。本文参考之前的眼动与键击研究(Sjørup 2013;Chang 2011;Jensen,Pavlovic 2009)中涉及的语言因素,从以下几个方面着手,保障同一个翻译任务文本内句子之间的对比度:全文风格、句型结构、句子长度以及每句话的平均词频数、难词比例、平均词长和单词平均音节,这些都作为实验文本设计客观评定方面的主要内容。
两个任务汉英原文的风格都是日常会话。句型结构为基本的主谓宾结构、主系表结构和简单的祈使句。这4篇文章中的句子的平均词频数接近(中高频词大于85%),难词比例接近(每句话最多包含一个低频单词)。第一组任务的英文篇幅为96个单词,中文篇幅121个汉字;第二组任务的英文篇幅为125个单词,中文篇幅151个汉字;第一组任务的英文句子长度为11-15个单词,中文句子长度为15-19个汉字;第二组任务的英文句子长度为13-15个单词,中文句子长度为15-17个汉字。在第一组任务和第二组任务的英文原文中,每句话的平均词长接近,分别是:3.93 -4.92 和3.40 -4.77;每个句子的词平均音节数也接近,分别是:0.91 -1.67 和0.86 -1.23。
3.4 实验过程
实验包括3个阶段:前期培训、热身阶段和第一个翻译方向与第二个翻译方向阶段。实验开始前,派发给被试一个实验流程和注意事项表。被试在了解实验过程后,将完成一个热身任务,把一篇50个单词的文本从英文翻译成中文。热身阶段的环境与正式实验的环境完全一致。
第一个翻译方向和第二个翻译方向的任务都遵循以下流程:校准瞳孔位置后,屏幕显示提前设计好的原文。翻译任务以及翻译方向的顺序均按编码随机分配给被试。被试在理解原文的同时,在电脑上产出并键入目的语。整个翻译过程除被眼动仪和Translog II软件记录之外,被试的翻译行为还被录影装置所摄录。被试完成第一个翻译任务后,有1分钟的休息时间,然后开始进行另一个翻译方向的实验任务。
4 结果与讨论
针对译者在翻译过程中如何调配“处理模块”(processing building blocks),本实验参考“并行模式”(the parallel view)(Balling et al.2014)和“混合模式”(the hybrid view)的观点(Hvel⁃plund 2011, Ruiz et al.2008),沿用丹麦学者Hvelplund(2011)的实验设计,将翻译过程中的认知加工类型(cognitive processing type)分为3类:源语处理(source text processing)、目的语处理(target text processing)和平行处理(parallel pro⁃cessing)。其中,平行处理是指译者的源语和目的语处理同时发生。比如,在翻译过程中,源语迻译(ST rendition)与目的语再形成(TT reformulation)常常发生在同一时刻(Ruiz et al.2008:491),这一叠加的认知现象被纳入平行处理的范畴。
在本研究中,3个认知加工类型分别对应3种注意单位:源语文本注意单位、目的语文本注意单位和平行处理注意单位。每一个注意单位都是由原始眼动与键击数据切分而成。这些注意单位一共组成4项指标,从不同的角度来描述译者的认知资源分配情况,它们分别是:注意总时长、注意单位次数、注意单位时长和瞳扩。其中,注意总时长、注意单位时长和瞳扩3项指标分别对应翻译过程中的认知资源总量、译者认知资源的调配情况和译者工作记忆的认知负荷(Hvelplund 2011:220)。
从上述介绍可知,在翻译的理解过程中涉及到的加工类型有两种:源语处理和平行处理。所以,数据分析将在源语注意单位和平行注意单位上开展。也就是说,在本研究中,描述翻译时理解过程的主要数据来源为注视在源语的有效眼动数据,而键盘记录法的主要用途是注意单位的切分和翻译过程与产出的记录。
本研究采用SPSS统计软件中的广义线性模型(generalised linear model)来分析客观指标数据。广义线性模型是基于正态线性模型发展出来的统计分析模型,被广泛应用在医学、经济学、社会学等许多领域(陈希孺2002:54)。广义线性模型不但适用于属性数据、计数数据等离散数据,还允许偏离均值的随机误差服从多种分布,如伽马分布、逆高斯分布、泊松分布等,非常适用于本研究探讨的问题和数据类型。在本研究中,广义线性模型的固定变量按属性分为3组:组1:字面表达;组2:共有隐喻(在源语和目的语中都有固定表达的隐喻);组3:特定隐喻(只在源语中有固定表达的隐喻)。在所有指标的模型中,协变量包括关注区域面积和语言因素协变量。在英—汉翻译方向的注意总时长和注意单位指标的模型中,关注区域位置(AOI position:关注区域距离屏幕中心直线距离)也列入协变量。
对于汉—英翻译方向,语言因素协变量为词频,每个眼动—键击指标导入一个模型中进行计算。对于英—汉翻译方向,语言因素协变量包括单词平均音节数、单词平均字母数和词频;关注区域为每个模型的恒定协变量、不同的语言因素协变量与恒定协变量组合。即每个指标导入3个模型中进行计算,然后统一对比计算结果。模型计算结果按照具体的每一项眼动—键击指标(如瞳扩)呈现,示例参见表1。
如表1所示,如果一个模型中的固定变量或协变量的显著值低于0.05,则说明该变量对指示变量的影响显著。在计算出所有模型的结果后,每项指标所描述的认知负荷量,按照字面表达、共有隐喻和特定隐喻的分组从大到小排序。英—汉翻译方向和汉—英翻译方向的计算结果对比见表2(表2只列出在每个模型的固定变量分组中,区别达到显著性标准的对比项)。
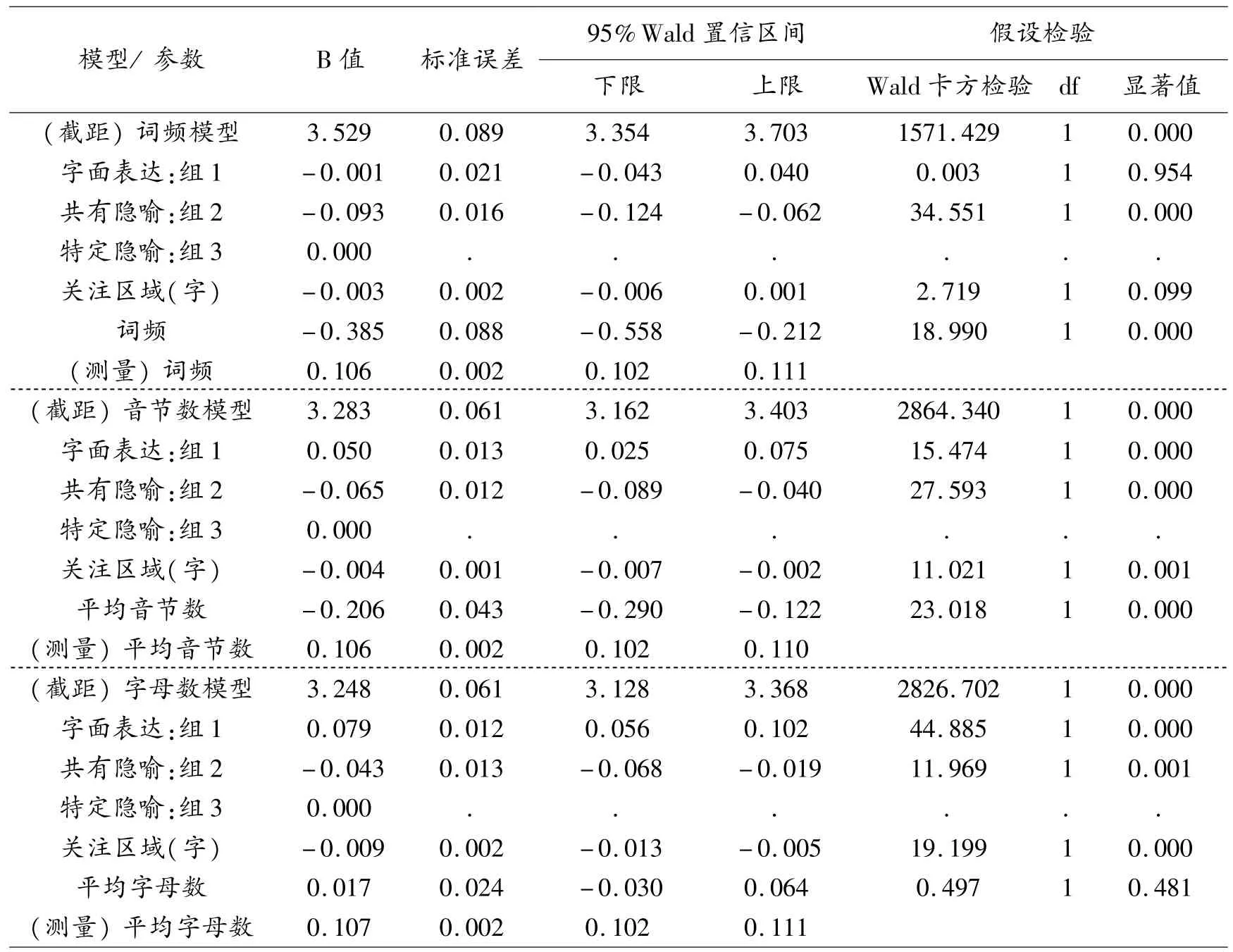
表1 广义线性模型计算结果示例(英—汉瞳扩值)

表2 源语理解的认知资源分配:英—汉和汉—英翻译方向对比
如表2所示,在汉—英和英—汉这两个翻译方向中,所有的眼动—键击指标都显示,译者在理解字面表达、共有隐喻和特定隐喻时,耗费的认知资源存在显著的差别。但在不同的翻译方向中,这种差别的表现形式不同。
首先,针对翻译过程中,字面表达和语言隐喻理解的差异(此处,共有隐喻和特定隐喻统一归为语言隐喻,与字面表达相区分),两个翻译方向的结果不尽相同。(1)汉—英翻译方向4个指标的结果非常一致。所有数据结果都显示:与语言隐喻的理解过程相比,字面表达的理解过程更加耗费译者的认知资源。(2)在英—汉翻译方向,各项指标的结果则相差甚远。注意总时长和瞳扩这两个指标的结果显示:字面表达的理解过程比语言隐喻更加耗费认知资源;但二者在注意单位时长上,结果完全相反;同时在注意单位次数上,二者的区别并不显著。由于注意总时长、注意单位时长和瞳扩3项指标分别对应翻译过程中的认知资源总量、译者认知资源的调配情况和译者工作记忆的认知负荷(Hvelplund 2011:220),所以可得出如下结论,在英—汉翻译过程中,字面表达的理解所消耗的认知资源总量和译者工作记忆的认知负荷超过语言隐喻,但其所占的单位认知资源小于语言隐喻。
其次,对于不同类型隐喻之间的区别,不同翻译方向的表现形式也不同。(1)在汉—英翻译方向,4项指标的结果大相迥异。数据显示,特殊隐喻的理解比共有隐喻要耗费更多的注意总时长和注意单位次数,但特殊隐喻的理解的注意单位时长却显著小于共有隐喻。而在瞳扩方面,二者的区别不显著。(2)在英—汉翻译方向,4项指标的结果也略有出入。注意总时长、注意单位次数和瞳扩这3个指标,都显示特殊隐喻的理解比共有隐喻更耗费认知资源。但二者在注意单位时长上的区别却并不显著。
本研究关于英汉翻译的客观数据结果与前人研究中基于其他语言的实证研究结果之间存在一些共性。Sjørup发现,当译者从第二语言(丹麦语)译入第一语言(英语)时,源语中的语言隐喻让语篇更连贯(facilitate textual coherence),它的出现能帮助译者更加准确而迅速地理解原文信息(Sjørup 2013:160)。 Sjørup 认为这个发现印证Black(1981)、Koller(2004)和 Noveck 等(2000)的观点:隐喻在翻译中具备一定功能和“潜在的裨益”(the potential to yield benefits)(Noveck et al.2000:118)。本实验的结果表明,在第二语言为英语,第一语言为汉语的二语译入一语的过程中,如果译文的难度被控制在较低的程度,从注意总时长和瞳扩这两个指标来看,语言隐喻的出现使译者在源语理解上消耗的认知负荷显著减少。
参考并对照 Sjørup(2013)的实验,Schmaltz(2015)在其汉语(第一语言)译入葡萄牙语(第二语言)的实证研究中发现,即使翻译方向从译入母语变成译出母语,她的数据结果和 Sjørup(2013)的结果也很一致:在翻译过程中,理解不包含隐喻的原文所占用的认知资源并不小于理解隐喻时的认知资源。她们认为,这些数据结果与Mason(1982),Inhoff和 Carroll(1984),Gibbs等(1997)的观点相符(Schmaltz 2015:188),即隐喻的出现不会增加翻译任务的难度,或迫使译者在原文上倾注更多的精力。与这些发现相一致的是,在本实证研究中,所有眼动—键击指标都显示:在翻译的文本难度较低的情况下,母语中语言隐喻的出现,无论是“时间就是金钱”这样的共有隐喻,还是“逃不出五指山”这样的特定隐喻,都会促进译者对原文的理解,显著降低他们在理解中消耗的认知负荷量,让翻译过程变得更加迅速和顺畅。
5 结论
本实验的眼动—键击数据结果表明,在汉英翻译过程中,隐喻的出现会对源语理解的认知资源分配造成显著影响。而这一影响在不同的翻译方向上,具体表现也有所不同。
问题一:对翻译过程中出现的语言隐喻,译者是否要花费更多精力去理解。数据结果显示:在汉—英翻译过程中,所有指标都显示,语言隐喻的理解并不需要花费更多的认知资源,甚至比字面表达更容易理解。但在英—汉翻译过程中,不同指标的结果存在差异,4个指标中有2个指标的结果与汉—英翻译方向的结果一致:语言隐喻理解的单位时长大于字面表达;而语言隐喻理解的注意总时长和瞳扩都显著小于字面表达,并且二者在注意单位次数上的区别并不显著。
问题二:特定隐喻和共有隐喻的理解所耗费的认知资源是否有区别。实验结果显示:在汉—英翻译过程中,不同指标的结果存在差异。4个指标中,有2个指标显示特殊隐喻的理解比共有隐喻更耗费认知资源:特殊隐喻的注意总时长和注意单位次数显著高于共有隐喻,但其注意单位时长却小于共有隐喻,此外,二者在瞳扩指标上的区别也并不显著。而在英—汉翻译过程中,除注意单位时长之外,所有的指标都显示,特殊隐喻的理解更加耗费认知资源。
问题三:对于第一语言为汉语,第二语言为英语的中国译者,语言隐喻对源语理解过程的影响,是否会随着翻译方向的改变而发生变化。数据结果显示,在译者理解第二语言的原文时,语言隐喻的出现会在某些方面促进理解,但在某些方面,会加重译者的认知负荷。但在理解母语的简单文本时,语言隐喻会帮助译者更省力地理解原文。此外,原文中语言隐喻是否在目的语中具备对应的固定表达对第二语言理解的影响较大,但对母语译出时的原文理解的影响,在各个指标上存在明显的差异。
简而言之,在中译英和英译中两个翻译方向之间,语言隐喻对翻译理解过程的影响存在明显差异。虽然现有的实证方法并不能百分之百地还原译者大脑内部的认知过程,并确认其完全遵从修正认知层次模型,但本研究的结果可以证实:“翻译不对称性”不仅在单词和文本层面上存在,而且在隐喻对源语理解过程的影响上也同样存在。值得一提的是,这些发现的前提是翻译原文的难度控制在较低标准,同时译者具备一定程度的翻译能力。在这个课题未来的研究中,译者的翻译能力和实验的文本难度将是非常有意义的延伸方向。
猜你喜欢
汽车实用技术(2022年7期)2022-04-20
载人航天(2021年5期)2021-11-20
大自然探索(2019年7期)2019-12-13
中国远程教育(2017年9期)2018-01-04
中国远程教育(2017年8期)2017-12-07
文艺生活·中旬刊(2017年10期)2017-11-19
中国远程教育(2017年7期)2017-09-01
中国远程教育(2017年6期)2017-08-31
文艺生活·下旬刊(2017年6期)2017-08-03
校园英语·上旬(2017年3期)2017-04-13
