
交通运输对人力资本的影响分析1
——基于动态一般均衡理论
2018-11-05 08:59王贵东
经济学报 2018年2期
王贵东
0 问题的提出
2014年,中国将京津冀的协同发展上升为国家战略。对于北京,与上海一样,是中国人力资本非常发达的城市,集聚了大批高端人才,涌现出大量科研成果;但京津冀城市群和长三角城市群的发展却迥然不同:由于北京的虹吸效应大于涓流效应,甚至出现了环首都贫困带;而上海则涓流效应大于虹吸效应,惠及了整个长三角。对于这种奇怪现象,国内一度出现了研究热潮,但多数文献为“分析现象+政策建议”式研究(赵奇伟和张诚,2006;姜玲等,2010;郭晔,2010;盖美等,2013;李磊和张贵祥,2015)。对于现象背后的原因,学界并没有达成共识,目前仍是一大研究难题,仅有的一些文献试图从中国制度、历史演进(孙久文和原倩,2014),以及总部经济(梁琦等,2012)等方面分析其原因。
透过现象看本质,京津冀与长三角人力资本的分岔现象仅是中国的一个缩影,本文的研究对象则是更为抽象的不同地域[注]每个地域都可以看作一个城市群系统。,及不同地域人力资本差异的产生原因。本文的理论模型为新古典经济增长模型,该模型由Solow(1956)开创。虽然早在1960年, Schultz(1960)就已经提出了现代人力资本理论。但直到1980年代中期,Romer(1986)、Lucas(1988)才基于人力资本开创性提出了内生经济增长理论。 Romer(1990)认为人力资本可以促进技术进步,推动经济内生增长;而Lucas(1988)则认为人力资本的外溢性导致了地区经济差异和增长发散。在实证方面,多数国内学者将人力资本作为参数,研究其对经济和社会的影响,如研究人力资本对经济增长的作用(赖明勇等,2005;钱晓烨等,2010;朱承亮等,2011;逯进和周惠民,2013),对员工工资差异、员工职业成功的作用(张车伟和薛欣欣,2008;周文霞等,2015),对非自愿移民的影响(石智雷等,2011)等。然而,如果仅单向地研究人力资本对经济和社会的影响,则相当于把人力资本作为外生变量,甚至可以得出一个极端:只要提高人力资本,就可持续刺激经济增长。为了避免此种极端,在技术层面上,可以考虑人力资本的获取成本、折旧等。而本文则是利用一般均衡框架,通过市场手段来约束人力资本,故本文的人力资本是内生的。在人力资本的众多影响因素中,本文认为交通运输是破解中国人力资本地域差异的一个重要突破口,并且具有很强的时代意义[注]近几年,中国政府机构最大的调整莫过于铁道部的分拆,中国电商的繁荣突起得惠于强大的互联网平台和交通物流平台支撑,中国高铁也逐渐成为了中国的国家名片等,这些无一不与交通运输相关。。同时,中国地域辽阔、地形复杂,既有平原地区,也有高原、山地、沙漠等地区,这些自然禀赋无疑会影响甚至决定交通道路的宏观布局。
在具体模型构建中,鉴于中国政府已从重视经济增长向重视经济结构调整转变,经济结构的合理性主要反映在产业结构上,且经济活动的主要场所为城市,故本文的经济系统将涵盖城市和产业两大基本领域。其中,城市借鉴了单中心城市理论,即中心—外围结构;产业主要指纵向产业,即产业链的上下游关系。当然,为了研究交通运输对经济系统的影响,并给出运输成本与人力资本的相互关系,在技术上本文还引入了Samuelson冰川模型。
本文其余部分安排如下: 第1部分为模型介绍,主要从消费者和生产者两方面展开。第2部分为均衡分析,研究了运输成本对稳态人力资本的影响。第3部分为实证检验,利用2005—2014年中国31个省(区、市)数据,以SARAR(Spatial Autoregressive Model with Spatial Autoregressive Disturbances)、WSARAR(Weighted SARAR)作实证检验。最后为结语与启示,并拓展分析了运输成本的空间、时间以及社会属性。
1 模型介绍
本文理论模型主要借鉴于Black and Henderson(1999),并进行了拓展,具体包括:(1)城市空间结构。城市空间结构由原来的人口密度处处相等,拓展为距离市中心越近人口密度越大。(2)运输成本。将Samuelson冰川模型引入中间投入品市场。下面,将从消费者和生产者两方面来阐述模型的一些基本情况。
1.1 消费者
按照Black and Henderson(1999)的假设,家庭成员生活在两种城市。第一种城市处于产业链上游,生产中间投入品,不妨称其为城市1。第二种城市处于产业链下游,生产最终消费品,不妨称其为城市2。在每个家庭中,城市1的成员比重为z,则城市2的成员比重为1-z。那么,作为消费者,“综合”代表人最大化家庭效用决策为
(1)
其中,c为消费;1/σ为不同时点的消费替代弹性,1-σ为效用的消费弹性,满足σ>0;ρ为时间贴现率,g为人口增长率,满足ρ>g。下标1、2分别代表城市1、城市2,I为收入,h为人力资本,P为最终消费品的价格。式(1)的隐含意义为:在家庭内部,家庭成员的收入会有所不同,但家庭成员(尤其是高收入的家庭成员)并不是以自身效用最大化,而是以家庭效用最大化。
需要说明的是,由于本文理论模型为动态模型,故消费c、人力资本h、最终消费品价格P等变量实际为时间t的函数,即c(t,·)、h(t,·)、P(t,·)。为了使本文表达式更具简洁性,这里将省略时间t;而在后文也作相应处理,文后不再一一说明。
1.2 生产者—城市1
在城市1中,假设居民既是消费者又是企业本身,并且代表人i的生产函数为
(2)
其中,n1为城市1的企业数量(人口规模),h1为城市1的行业平均人力资本,h1i为企业i的人力资本。δ1为企业数量弹性,表示企业数量的外部性,侧重于数量方面的外部性。ψ1为平均人力资本弹性,表示人力资本的外部性,侧重于质量方面的外部性。θ1为企业i的人力资本弹性。
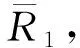
其中,b1≡τ[(2-β1)/(3-β1)][(2-β1)/(2π)]1/(2-β1)。
利用前面获得的总通勤成本TCommuting1和总地租TRent1,可以分析城市1的居民收入I1。不妨将中间投入品的价格标准化为1,可以得到企业i的收益W1i=X1i。而在城市中生活,居民需要支付必要的通勤成本和地租,同时也能获得城市管理者的转移支付,所以居民的最终收入为:
I1=W1+T1-(TRent1+TCommuting1)/n1
现在分析城市管理者的决策,城市管理者收取租金,然后通过转移支付形式返还给居民。具体为城市管理者宣布城市类型为城市1,选择城市人口和转移支付来最大化TRent1-n1T1。

(3)
其中,η1≡1-(2-β1)δ1,δ1<1/(2-β1)[注]因为对于个人,产出的人口规模弹性为δ1,成本的弹性为1/(2-β1)。当δ1>1/(2-β1)时,随着人口的增加,产出增加的比例高于成本,城市1的人口会不断膨胀,直到世界上只剩下一个城市,这显然与现实矛盾,所以δ1<1/(2-β1)。;ε1≡(ψ1/η1)+φ1,φ1≡θ1/η1,φ1<1;Q1≡η1{[(1-η1)/b1]1-η 1D1}1/η 1。最后,综合城市1中所有已得的关系式,可以得到
其中,式(5)第二个等号需要将式(3)代入W1并整理。
1.3 生产者—城市2
在城市2中,假设居民既是消费者又是企业本身,并且企业j的生产函数为:
(6)
在式(6)中,n2为城市2的企业数量(人口规模),h2为城市2的平均人力资本;h2j为企业j的人力资本;x1j为企业j需要的中间投入品数量。δ2、ψ2、θ2、1-α分别为企业数量、平均人力资本、企业j的人力资本、中间投入品弹性。同时,α还满足边际报酬递减规律,即α<1。(特别地,对于零售企业,由于存在仓库等其他要素投入,故中间投入品x1j仍要满足边际报酬递减规律,即α不能取到0)
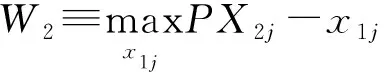
(7)

(8)
其中,η2≡α-(2-β2)δ2,0<η2<1;ε2≡(ψ2/η2)+φ2,φ2≡θ2/η2,φ2<1;Q2≡η2{(1-α)(1-α)[(α-η2)/b2]α-η 2D2}1/η 2。最后,综合城市2中所有已得的关系式,可以得到
其中,式(10)第二个等号需要将式(8)代入W2并整理。
2 均衡分析
由式(1)构造“综合”代表人的现值Hamilton方程:
(11)
由式(12)、式(13)可知,当ξ1<ξ2时,城市2的平均人力资本、收入均高于城市1;反之亦然。
2.1 中间投入品市场
接下来,分析中间投入品的市场均衡。令m1、m2为城市1、城市2的数量,N为所有城市1和城市2的加总人口。假设中间投入品既是城市2中企业的生产要素,又能支付城市1、城市2中居民的通勤费用。需要说明的是,Black and Henderson(1999)并没有考虑到中间投入品从城市1运输到城市2所产生的运输成本。而本文试图引入运输成本,进一步拓展该模型。在技术处理上,本文采用Samuelson的冰川模型形式来描述运输成本,即只有1/μ的中间投入品送达城市2,其中μ≥1,运输成本越高,则μ越大;当运输成本完全将为零时,μ=1。那么,中间投入品的市场均衡为
(1/μ)m1n1[X1i-(TCommuting1/n1)]=m2n2[x1j+(TCommuting2/n2)]
(14)
很明显X1i-(TCommuting1/n1)=I1,又由式(9)得x1j+(TCommuting2/n2)=[(1-η2)/η2]I2;再结合式(13)和m1n1/m2n2=z/(1-z),可得
(15)
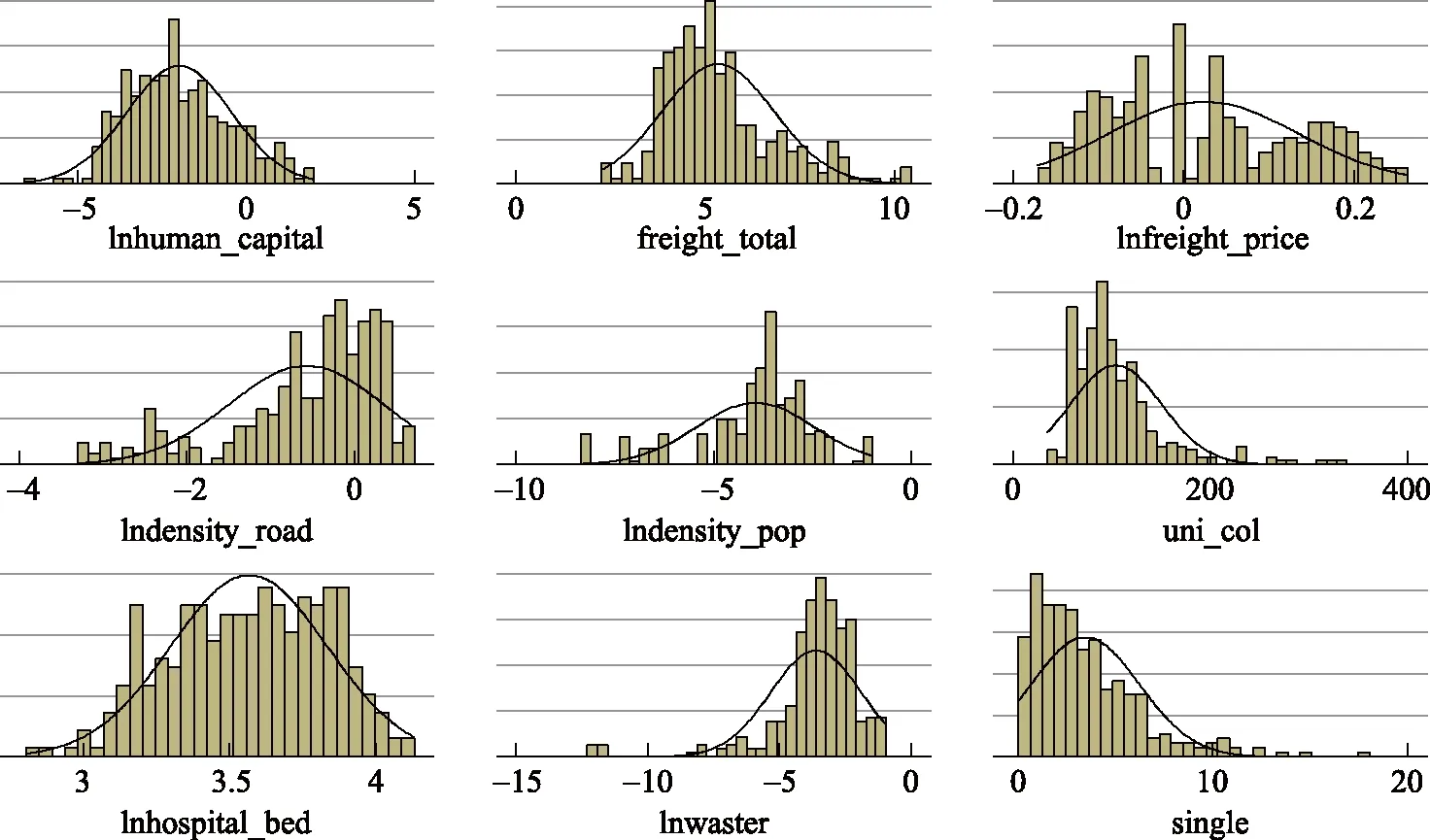
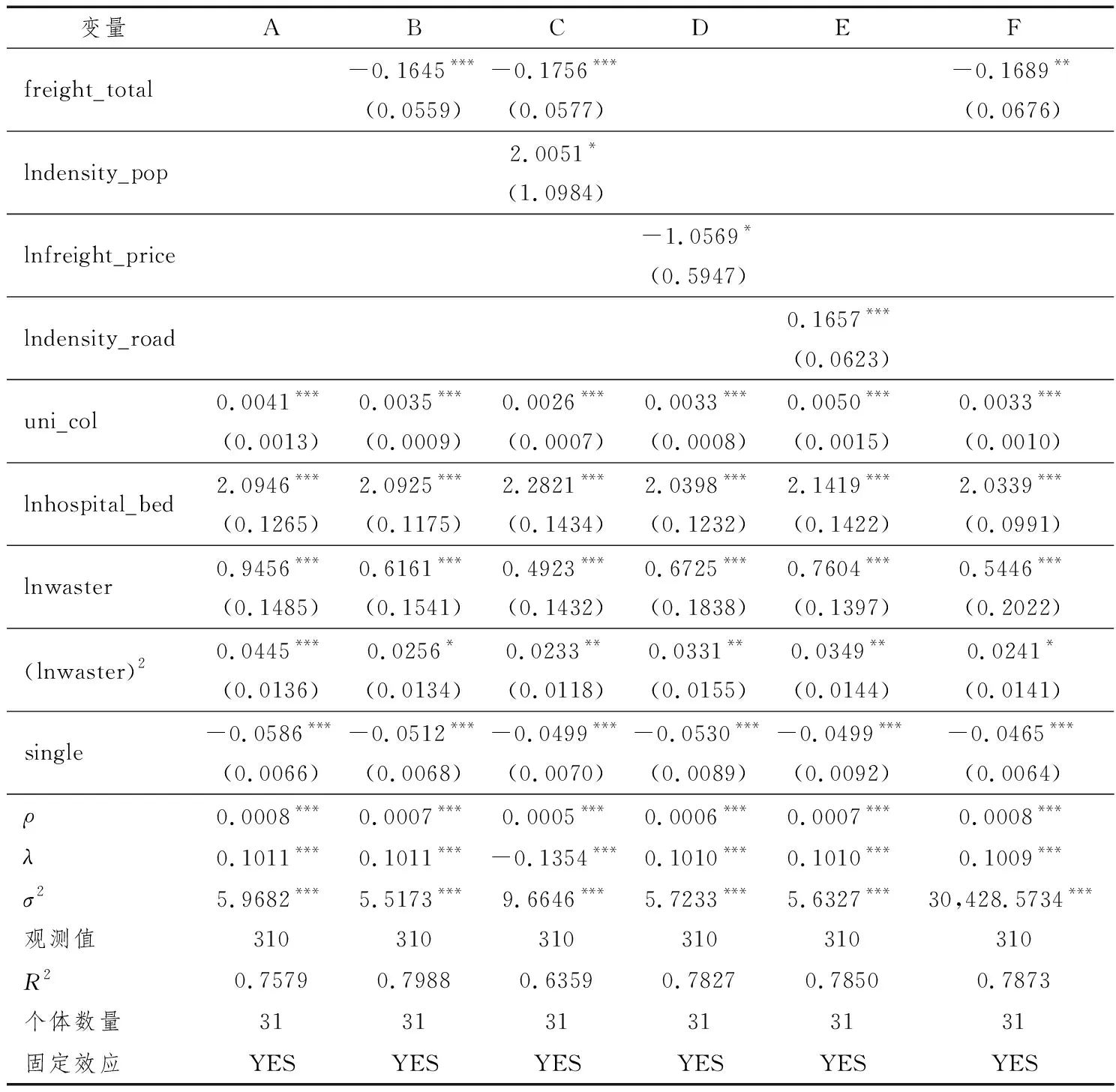
其中,E≡μξ1(1-η2)+ξ2η2,F≡μ(1-η2)+η2,E 另外,把式(15)代入h=zh1+(1-z)h2,并结合式(12)可得 (16) 其中,K≡(F-E)/E。将式(16)代入式(5)、式(10)后,结合式(13)可得 (17) 接下来,分析系统稳态。根据式(5)、式(10)、式(11)、式(16)、式(17)可得 其中, (20) (21) 下面,将研究运输成本对鞍点的影响,式(20)结合前面所有关系式可得 (22) 另外,将式(20)代入式(16),可得 (23) 式(23)揭示了运输成本如何影响人力资本稳态值,不难发现运输成本仅通过z间接影响人力资本的稳定值。也就是在整个经济体地域内,一些城市直接从城市1转型为城市2或城市2相对于城市1更迅速的人口增长,均能促使该经济体人力资本的稳态值增加,而运输成本正是这个引擎。 本文的运输成本,主要指经济体内部不同点之间相互运输,不包括“过路型”运输(比如从广州运往哈尔滨会经过河北省等)。现在,可回到本文一开始对京津冀(或长三角)的讨论,并回答产生人力资本差异的原因:①对于京津冀,其发达的交通是毋庸置疑的,铁路的八横八纵有5条以北京为起始点,1开头的所有国道均以北京为起始点。但如果将河北作为一个经济体,会发现京津冀“辐射型”干道只是表面上的交通发达,河北自身则非常不方便。这是因为中间投入品从河北的城市A到河北的城市B,往往缺少直接相连的主干道,反而得绕行北京中转,这无疑增加了运输成本(既有货币成本也有时间成本)。根据本文命题可知,较高的运输成本将限制河北的人力资本发展。另外,河北甚至还充当了“过路型”运输的角色。②对于长三角,其交通同样比较发达,但却与京津冀的类型完全不同,长三角的交通多为“随机型”干道,上海、苏州、杭州、无锡、常州等城市两两之间几乎都有多条干线相连。那么根据本文命题,长三角由市场内生决定的人力资本必然会很高(即使剔除了上海)。所以对于京津冀问题,若要提高河北的人力资本,则必须在河北内部投入更多的道路建设,而不是大力规划河北与北京[注]一定程度上还会造成北京的拥堵。之间的道路建设,这将会是京津冀协同发展的一个重要误区![注]北京的交通枢纽完全可以由河北某城市或天津进行分担,这样就不会出现原本目的地非北京,但必须经过北京中转的现象。2015年底,津保铁路的连通则是一个很好的例子,从保定到秦皇岛不再绕行北京,可直接经过天津中转,降低了保定到秦皇岛的成本(既有货币成本也有时间成本)。 在实证检验部分,本文将利用中国数据来检验理论模型命题的正确性,即检验运输成本与人力资本和消费是否存在负相关。需要指出的是:该命题的描述对象为城市1、城市2构成的整个经济系统,而非单独的城市1或城市2,从式(23)也可以直接看出这种区别。 下面,本文将比较市级数据、省(区)级数据以及国家级数据,并从中选择最合适的数据。其中,市级数据相当于地级市内各县、县级市为城市1,市辖区为城市2;省级数据相当于省(区)内一部分城市为城市1,另一部分城市为城市2;国家级数据相当于全国一部分城市为城市1,另一部分城市为城市2。虽然在理论上国家级数据最为理想,但因其截面个体只有一个,故本文果断放弃。对于市级数据和省级数据,本文认为省级数据较为理想,其原因:一是,市级数据有“虚假面板”现象。根据第六次人口普查数据,2010年全国总人口13.33亿人,城市人口4.04亿人,城市人户分离人口1.70亿人。在城市人户分离人口中,有1.33亿人,其中省内跨市辖区为0.75亿人,跨省为0.58亿人,共占城市人口的32.95%。若使用市级数据,则32.95%的跨市辖区人户分离意味着“虚假面板”现象,也就是说即使有城市、年份两个维度的数据,但人口的跨城市大量流动,将导致城市个体发生变动,已经威胁到面板使用条件。当然,如果研究对象是城市的公共物品、住房等,则对面板使用条件的影响较小。二是,市级数据有效变量的可得性低。目前,市级数据主要从《中国城市统计年鉴》《中国区域经济统计年鉴》、各省(区、市)统计年鉴、全国人口普查中搜集。其中,《中国城市统计年鉴》数据以市辖区数据居多,这很难满足理论命题对研究对象的要求;《中国区域经济统计年鉴》数据以全市数据居多,但可用的指标较少;各省(区、市)统计年鉴数据参差不齐,口径不一致;全国人口普查中关于人口的数据较全,但经济类的数据几乎没有,且时间序列太少。总而言之,既要保证样本量不能太少,又要保证个体间的相互作用不能太高,同时还要保证数据可得性不能太低,最终本文选择了省级数据。当然,对于省(区、市)际的相互影响(比如人口流动等),在技术层面上,本文是通过空间计量解决的[注]但空间面板模型一般要求为平衡面板,这意味着:若某省在某年的某个变量为缺失值,则要么剔除该省,要么删除该年,要么剔除该变量寻找替代变量。由于省际关系至少为省的二次关系,故删省的方法应谨慎;又由于数据所支撑的时间跨度本身就不大,故删时间的方法也应谨慎;而寻找替代变量的代价相对较小,故本文采之。另外,由于本文理论模型侧重于分析个体内部的均衡,所以个体间的相互作用不应过大(而市际关系明显过大),否则会喧宾夺主,即使空间计量在一定程度上可以解决此类问题。。 本文所用的省级数据主要来源于国家统计局,部分缺失数据由各省统计年鉴、Wind资讯数据库、中国经济与社会发展统计数据库、中经网统计数据库补充。接下来本文将选择合适的被解释变量、关键解释变量及控制变量,如无特殊说明,本文中所有的价格变量均利用CPI进行调整,基期为2010年。 被解释变量。被解释变量为综合人力资本,本文用human_capital表示。参考郭剑雄(2005)、邓峰和丁小浩(2012)、李海峥等(2013)等文献,本文选取了教育人力资本、科研人力资本来计算综合人力资本。又因为身体越健康意味着抗病能力越强、可承受劳动强度越高(Fogel,1994a,1994b),故本文还加入了健康人力资本(王弟海,2012)。也就是,综合人力资本由科研人力资本(强调成果)、教育人力资本(强调智力)、健康人力资本(强调体力)三部分构成。综合人力资本计算,主要包括成本法(Kendrick,1976)、收入法(Jorgenson and Pachon,1983;Jorgenson and Fraumeni, 1992a,1992b)和特征法(Barro and Lee,1996)等,本文主要采用特征法,其计算公式为:综合人力资本=科研人力资本s×教育人力资本s×健康人力资本s。其中,s取1(正向指标时)或-1(负向指标时);科研人力资本用人均发明专利申请量来推算,教育人力资本用受教育年限来推算,健康人力资本用修正死亡指标[注]需要说明的是,修正死亡指标是一个负向指标,由于死亡人数还包括因年迈而造成的自然死亡,故本文利用“死亡人数/65岁及以上人数”来削弱这种影响。来推算。图2为2005—2014年中国31个省份的综合人力资本图,可以发现:北京、天津、上海、江苏的综合人力资本较高;同时,北京的综合人力资本增速最快,这主要源于北京对周边省份过强的虹吸效应。 图2 2005—2014年中国31个省(区、市)综合人力资本 关键解释变量。由于关键解释变量为运输成本,出于计量模型稳健性的考虑,本文选择了多个代理变量。需要注意的是,本文理论模型中的运输成本是指“运输单价×运输线路长度”,故计量模型的代理变量也必须围绕“运输单价×运输线路长度”。在计量主模型中,本文选用了总运输成本占比freight_total作代理变量,其计算公式为:总运输成本占比=交通运输、仓储和邮政业/GDP*100,该变量更侧重于“运输单价×运输线路长度×运输重量”。而在计量稳健性检验中,本文试图采用相对运输单价、公路密度、人口密度作代理变量。对于相对运输单价freight_price,其推算过程为:先利用“交通和通信的居民消费价格指数/CPI”计算得到交通和通讯的相对指数,再以2010年为基期,通过连乘(除)计算即可,该变量更侧重于“运输单价”。对于公路密度density_road,其计算公式为:公路密度=公路线路里程/行政区域土地面积,选择该变量是因为公路密度越大意味着最优运输线路越短,越不易出现绕行,该变量侧重于“运输线路长度”。对于人口密度density_pop,其计算公式为:人口密度=年末人口数/行政区域土地面积,选择该变量是因为人口密度越大意味着运输起点和运输终点的直线距离越短,而直线距离越短则意味着运输线路越短,该变量也侧重于“运输线路长度”。考虑到人口密度往往还具有“运输线路长度”之外的更多含义,故人口密度不直接替换主模型中的代理变量,而是与freight_total一起加入计量稳健性检验模型。 控制变量。①本科专科毕业生比uni_col。在数据处理层面,本科专科比所需数据主要包括:本(专)科招生数、本(专)科在校生数、本(专)科毕业生数、受教育程度为本(专)科的抽样人数。由于新入学学生和在校学生几乎不参与社会生产,故将这两类数据弃之。又由于在计算被解释变量综合人力资本时,已经利用了受教育程度抽样人数数据,若解释变量仍利用该数据,则等同于人为构造了计量模型的显著性,故也将该类数据弃之;通过排除法,本文认为毕业生数据更为合适。在变量选取层面,本科专科毕业生比要优于本科专科毕业生数,其原因为:一部分本科专科毕业生会选择离开原就读城市[注]当然,其他城市的本科专科毕业生也会选择进入该城市。,导致剩余的本科专科人数发生较大变动,而本科专科毕业生比,则相对较为稳定。②人均病床数hospital_bed。人均病床数越多,意味着医疗硬件越完善,进而保障该地区居民的健康处在较高水准。③一般工业固体废物waster。一般工业固体废物有两种处理方法,一种是“一般工业固体废物产生量/年末总人口”,另一种是“一般工业固体废物产生量/行政区域土地面积”。前者强调一般工业固体废物的分配,后者强调一般工业固体废物的外部性。很明显,一般工业固体废物是公共物品,并对附近所有人均具有负外部性,故“一般工业固体废物产生量/行政区域土地面积”的处理方法更为合理。又考虑到环境库兹涅茨曲线理论,故本文还引入了waste的二次项[注]由于在实际计量回归时,本文对waster进行了对数化处理,故其二次项指的是对数化后的二次项。因为先取二次方再对数化,将会出现多重共线性。。④性别失衡single。其计算公式为:性别失衡=abs(15及以上男女人数差)/min(15及以上女性人数,15及以上男性人数)*100。“洞房花烛夜”是中国的四大喜事[注]“久旱逢甘雨,他乡遇故知,洞房花烛夜,金榜题名时。”之一,再加上《中华人民共和国婚姻法》规定的一夫一妻制,所以较高的性别失衡意味着更多的人会被动单身(这里不考虑同性恋情况)。由于单身者将花费更多的时间和精力去追求异性,进而挤占了本应提升人力资本的时间精力,故本文初步判断性别失衡与人力资本负相关。 表1汇总了本文所用变量的基本信息,可以发现:不同变量的数据相差较为悬殊,且被解释变量的中位数不到其均值的四分之一。为了便于解释变量的横向对比(弹性关系),同时也为了提高被解释变量的数据质量,本文对(除百分比变量freight_total 、uni_col、single以外)变量进行了对数化处理。图3为对数化处理后的变量密度图,可以发现:经过对数化处理后,被解释变量的对称性有所提高,其分布更接近于正态分布。 表1 变量统计 图3 变量密度图(以柱状图逼近) 本文回归所用数据为2005—2014年中国省级数据,鉴于省际空间相互作用,本文的实证模型为空间面板(Spatial Panel)计量模型。 对于空间权重矩阵(Spatial Weighting Matrix),本文分别计算了三种空间权重矩阵[注]在实际计量回归中,本文还对权重矩阵进行了行标准化处理。:第一种是基于省边境是否接壤的二值权重矩阵;第二种是基于各省省政府经纬度的距离倒数权重矩阵;第三种是基于跨省人口流动的综合权重矩阵,计算数据来源于第六次人口普查,该矩阵非主对角元素ij的计算公式为:元素ij=(2005年在j省居住而2010年在i居住的人口×2005年在i省居住而2010年在j居住的人口) /(2010年在i省居住的总人口×2010年在j省居住的总人口)。下面,本文将对空间权重矩阵进行筛选。 ①二值权重矩阵和距离倒数权重矩阵。二值权重矩阵仅考虑了邻居省的相互影响,对邻居的邻居等二阶以上空间滞后信息利用较少,故距离倒数权重矩阵更优。②距离倒数权重矩阵和综合权重矩阵。距离倒数权重矩阵只考虑了(大部分)地理空间滞后信息,忽略了地形、方言、经济、人口等信息。比如,西藏与新疆(接壤)的省会距离明显小于西藏与河南,但由于昆仑山的阻挡反而不如西藏与河南的关系密切;上海与山东的距离明显小于上海与北京的距离,但北京与上海的关系更为密切(在经济、交通等方面)。而综合权重矩阵则不同,它涵盖了空间距离、地形、方言、经济、人口、文化等全方位信息,其原因为:每个决策者在选择具体流入的省时[注]当然,也包括继续留在本省。,必然要考虑空间距离、地形、方言(李秦和孟岭生,2014;刘毓芸等,2015)、经济、人口、文化等因素。最终,可以筛选出最优的空间权重矩阵——综合权重矩阵,该矩阵是在被解释变量为人的属性变量时最为突出。 本文使用的空间计量模型为SARAR,具体如下: yt=ρWyt+Xtβ+Ztγ+u+εt (25) 其中,εt=λMεt+vt,vt~N(0,σ2I),向量yt为被解释变量,矩阵Xt为关键解释变量,矩阵Zt为控制变量,矩阵W、M分别为被解释变量、误差项的权重矩阵(本文假设W=M),向量u为个体固定效应。若变量有下标t,则表示该变量随时间而变。该模型既考虑了被解释变量的空间自回归(SAC),又考虑了误差项的空间自相关(SEM)。当ρ和λ均不为零时,模型为SARAR;当ρ不为零而λ为零时,模型退化为SAC;当ρ为零而λ不为零时,模型退化为SEM;当ρ和λ均不为零时,模型退化为普通面板模型。当然,在后面的稳健性检验中,本文还考虑了更为复杂的WSARAR。 表2给出了最终计量回归结果。其中,标号A为只有控制变量的回归结果,标号B为加入了关键解释变量的回归结果,Main列为解释变量的回归系数,Direct列为直接效应,Indirect列为间接效应。 表2 SARAR估计结果 注: 括号内为稳健标准差,***p<0.01,**p<0.05, *p<0.1。 观察表2中的标号A情况,可以发现:所有控制变量对模型的解释都非常显著(p-value均小于0.01),且ρ和λ均显著不为零,也就是被解释变量空间自回归,误差项空间自相关。具体而言:uni_col系数显著为正,说明本科生相对专科生越多,其综合人力资本越高(主要为科研、教育人力资本)。lnhospital_bed系数显著为正,说明医疗硬件越完善,其综合人力资本越高(主要为健康人力资本)。lnwaster和(lnwaster )2系数均显著为正,说明综合人力资本(主要为健康人力资本)随一般工业固定废物的增加呈现先减后增[注]注:lnwaster可以取到负数。的变化趋势,这与环境库兹涅茨曲线不谋而合。这是因为在经济起步时期,人们一般不太关心环境污染,也不会过多处理污染物;但随着经济的进一步发展,人们开始注重自身健康,即使此时期污染物产生量有所增加,但是经过对污染物的有效处理后,其排放量反而有所下降。single系数显著为负,说明性别失衡一定程度上造成了综合人力资本的下降。 横向对比表2中的标号A情况和标号B情况,不难发现:关键变量freight_total的加入,并没有明显改变原控制变量的符号和显著性,也没有使得ρ和λ变为不显著;同时,R2也从0.7579提高到了0.7988。更为重要的是:freight_total的系数显著为负(p-value为0.003),与理论模型中的命题完全一致。 本文的稳健性检验主要包括:增减关键解释变量,替换关键解释变量,替换估计方法。①增减关键解释变量。对于减少关键解释变量,在表2中,本文已将关键解释变量减少为零个,回归结果显示所有控制变量及模型整体均较为稳健。对于增加关键解释变量,本文谨慎选取了人口密度density_pop作为第二个关键解释变量,由于该变量仅“部分”反映了运输成本(侧重运输线路长度方面,人口密度越大暗示着运输线路越短),故加入后不易造成多重共线性;回归结果显示(见表3的C列)所有解释变量及模型整体均较为稳健,且lndensity_pop的系数显著为正(p-value为0.068),符合本文理论模型命题。②替换关键解释变量。本文分别用相对运输价格freight_price、公路密度density_road对总运输成本占比feight_tota进行替换,回归结果显示(分别见表3的D列、E列)所有解释变量及模型整体均较为稳健,且lnfreight_price的系数显著为负(p-value为0.076),lndensity_road的系数显著为正(p-value为0.008),符合本文理论模型命题。 ③替换估计方法。考虑到本文的被解释变量为人均变量,而不同省份又拥有不同的人口,故本文将对31个省(区、市)进行赋权。赋权原理为人口越多权重越大,具体操作为:先计算每个省2005—2014年的平均人口,再以该时间平均值作为这31个省(区、市)的频率权重(Frequency Weights)。根据频率权重,本文将估计模型升级为WSARAR,回归结果显示(见表3的F列)所有解释变量及模型整体均较为稳健。 表3 稳健性检验结果 注: 括号内为稳健标准差,***p<0.01,**p<0.05,*p<0.1。 在Black and Henderson(1999)的工作基础上,本文构建了适用范围更广的经济增长模型,该模型基本涵盖了产业理论、单中心城市理论、冰川运输理论、公共财政理论。利用该模型,本文得出运输成本一般会负向影响(稳态)人力资本的命题。在实证部分,利用中国31个省(区、市)面板数据,通过控制被解释变量空间自回归、误差项空间自相关、个体固定效应等因素,得到运输成本确实显著地负向影响了(综合)人力资本的结果,而通过增减关键解释变量、替换关键解释变量、替换估计方法等操作,回归结果仍然保持了一定的稳健性。本文的研究不仅可以解释京津冀和长三角的人力资本差别,还可以解释为什么偏远地区(运输成本一般较高)的人力资本较低,沿海地区、平原地区(运输成本一般较低)却集聚了较高的人力资本。按照本文逻辑,即使偏远地区出现了部分高人力资本群体,在该地区也是一种“浪费”,于是该地区的高人力资本群体将会向沿海地区、平原地区流动,即人才集聚。这种现象非常切合中国实际,每年都有很多本硕博毕业生,而大部分本硕博毕业生没有选择回家乡,很可能是他们的人力资本在家乡很难有用武之地。总之,根据本文研究,中国政府通过投资铁路、公路、桥梁等基建而拉动经济增长的做法是值得肯定的,尤其是西部大开发,这对于缩小人力资本地域差距起到了关键作用,而人力资本地域差异的缩小也将会一定程度上缩小工资的地域差异。 下面,对本文理论作进一步拓展。μ作为关键变量,被定义为运输成本,主要是指空间领域,强调的是物质从一个空间转移到另一个空间产生的“成本”,若将μ的概念拓展至时间领域,μ可以定义为人的非耐心程度,当人越没有耐心时,人将会给予未来的物质更低的权重,也就是μ越大。单位时间的贴现因子和时间的长度均会影响人的耐心,当单位时间的贴现因子越小时,人们对未来物质的赋权越小;当时间越长时,人们对未来物质的赋权也越小。鉴于此,本文原理论所指的不同空间中的两类城市(代表着上下游产业),可以转化为不同时间下的前后生产工序(或上下游产业)。当人对时间越没耐性或前后生产工序越耗时,物质的总贴现“价值”越低,也就是μ越大。若将μ的概念拓展至社会领域,μ可以定义为交易成本,主要是为了交换所有权而产生的“成本”。其中,所有权是指所有人依法对物质所享有的占有、使用、收益和处分的权利,而交易成本属于(新)制度经济学范畴,Coase(1937)、Williamson(1981)作了更多原创性工作。2.2 系统稳态分析


3 实证检验
3.1 数据选择与讨论


3.2 空间权重矩阵
3.3 空间计量回归结果

3.4 稳健性检验
4 结语与启示
猜你喜欢
当代水产(2022年2期)2022-04-26
建材发展导向(2021年15期)2021-11-05
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
数学年刊A辑(中文版)(2015年2期)2015-10-30
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
新高考·高二数学(2014年7期)2014-09-18
