
基于自编码器的飞机类型识别方法
2019-06-25 09:54张朝柱黄妤宁
无线电工程 2019年7期
张朝柱,黄妤宁
(哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨150001)
0 引言
非合作通信环境下,通过飞机舱内背景音进行飞机类型的识别[1-2]是目标识别的一个新方向,在军民用领域有着广阔的发展与研究前景,对国家安全非常有意义。在非合作通信环境下,利用飞机舱内的背景音信号对飞机类型进行识别具有被动监听不易被发觉、实时性好、传播距离远和实现简单等优势,在现实应用中有很大意义。通过截取在非合作通信环境下的飞机舱内的背景音信号对飞机类型进行识别,并且标记出其具体的类型,对军方迅速识别敌我飞机类型以做出相应的应对措施来说至关重要。将接收到的背景音信号通过计算机进行自主分类与识别,这将大大地解放人力,通过机器代替人类监听,不仅在准确率上比较稳定,而且对于多重复杂的环境,计算机可以自行进行去除干扰的处理,保证了分类结果的稳定性。文献[3-5]介绍了MFCC算法对动态环境音进行特征提取,与本文所需要分析的飞机舱背景音有一些相似之处,文献[6]介绍了支持向量机(SVM)这类传统的分类算法,但是SVM算法对于本文分析的声学环境十分复杂的声信号准确率较低。因此,针对所截取的飞机舱内的背景音,通过MFCC算法进行特征提取,由自编码器进行分类识别。实验结果表明,每一类声信号通过自编码器可以达到90%以上的正确识别率,且稳定性较高,具有很好的现实意义。
1 自编码器
自编码器是一种无监督学习算法,可以对输入数据进行压缩,提取其特征进行分类,对图像信号的分类效果十分显著。自编码器[7-9]原理简单,分类特征明显且输出维度低,目前正在多种领域崭露头角。本文首次将自编码器应用于非合作通信环境下飞机背景音声信号的分类识别,基于自编码器对多维信号分类更加准确的特点,通过联合特征对自编码器进行优化,使其获得更高的准确率。2010年,Vincent P,Larochelle H,Lajoie I等人提出了一种基于叠加去噪层的深度网络构建策略自编码器,其分类错误显著降低,确立了去噪准则可以作为无监督目标来指导更高层次的学习[10-11]。自编码器是基于深度神经网络的语音声学建模、大数据下的模型训练技术,在未来图像、语音等大数据处理应用上有着广阔前景。
1.1 自编码器原理
自编码器中,输入层到隐藏层相当于一个编码过程,隐藏层到输出层相当于一个解码过程,由于在自编码器中只有无标签的数据,将输入信息输入到编码器中会得到一个编码,之后通过解码器解码,得到输出信息[12]。这样就得到了输入信号的数据逆向映射特征,也就是从少量样本和大量无标签数据中学习到了输入数据深层次的特征。如果输出信息和原始输入信息是相同的,则认为中间隐藏层得到的编码就是输入信息的另一种表达方式[13]。通过优化编码器与解码器的参数,最小化重构误差得到编码。自编码器的隐藏层到输出层为前馈运算,其隐藏层可以完整地表达该输入信号,即可以从隐藏层中将输入信号进行无损重构,即自编码[14]。传统的自编码器主要用于降维或者特征学习,其原理结构如图1所示。

图1 自编码器原理结构
自编码器的训练近似于受限玻尔兹曼机,训练一个自编码器是为了把输入x编码为某种表示c(x),以便于输入可以从这种表示中进行重构,如果存在一个线性隐藏层,并且采用均方误差准则训练这个网络,那么k个隐藏单元学习到的就是将输入向量投影到由数据空间的前k个主成分所张成的子空间[15]。如果隐藏层是非线性的,那么自编码器便与主成分分析PCA不同:它将有能力捕获输入分布的多模特性。更理想的情况下,可以把均方误差准则推广到重构的最大似然准则,即负对数似然的最小化准则。
1.2 自编码器的训练
给定编码c(x):
RE=-lgP(x|c(x))。
(1)
如果x|c(x)为分布式高斯的函数,式(1)可表示均方误差,若输入xi是一个二元变量或者近似二项分布的函数,则其代价函数为:
(1-xi)lg(1-fi(c(x)))。
(2)
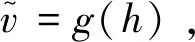
(3)
理论上来说,确定的函数编码f(v)以及确定的解码函数g(h)可以是任意函数。使用自编码器来初始化由signmoid单元构成的DNN中的权重时,
h=f(v)=σ(Weh+b),
(4)
式中,We∈RNh×Nv是编码矩阵;b∈RNh×1是隐藏层的偏置向量。如果输入特征v∈{0,1}Nv×1取二进制值,则可以选择
(5)
式中,a∈RNv×1是重建层偏置向量。如果输入特征v∈RNv×1取实数值,可以选择:
(6)
一般情况下,权重矩阵we和wd可能是不相同的。反向传播算法可以学习自编码器中的任何类型任何方式的参数,包括实数或者二进制数等。
当隐藏层h的维度比输入信号x小时,将强制自编码器捕捉训练数据中最显著的特征。其训练函数为:
L(x,g(f(x))),
(7)
式中,L是损失函数,将其最小化可用于惩罚函数g(f(x))与x的差异,如均方误差或者交叉熵损失函数,二者分别表示为:
L(x,y)=‖x-y‖2,
(8)

(9)
1.3 自编码器的输出
假设某输入样本i对应的向量为x(i),那么其隐含层中的响应向量为:
a(i)=f(z(i))=f(Wx(i)+b1),
(10)
式中,W是输入层的权重矩阵;b1是输入层的偏置矢量;z(i)是计算隐藏层求和;f(•)是激活函数,且在此情形下应该是一个值域在(0,1)之间的向量。本文选取sigmoid激活函数。可知在sigmoid激活函数下,自编码器的输出为:
(11)
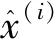
2 MFCC算法提取飞机声信号特征
本文对8种不同飞机类型通过MFCC对原始声信号进行特征提取,得到特征向量。
Mel频率分析是一种仿人耳的频率分析。由于人耳对声音的非线性关系,通过Mel倒谱将线性频谱通过某种关系映射到非线性频谱中,通过倒谱将其线性卷积关系变成线性相加关系[16]。Mel频率与实际频率的关系如图2所示,其变换关系式为:
(12)
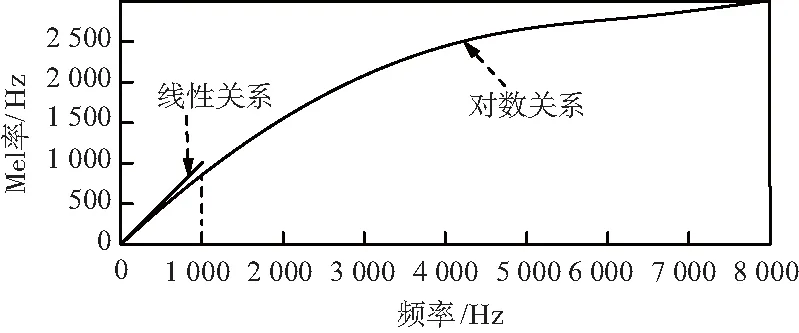
图2 Mel频率与线性频率关系
在Mel频域,人耳的频率分辨率是均匀分布的,即将整个Mel频域等距划分得到若干个中心频率。以每个中心点为中点,将上一个和下一个中心频率为截止频率,构建一系列三角带通滤波器,并通过式(12)计算Mel频率与实际频率的对应关系[17]。MFCC算法流程为:预加重、分帧、加窗、傅里叶变换、三角窗滤波、取对数、离散余弦变换(DCT)和动态差分。

图3 MFCC算法流程
① 预加重。可以提高声信号的高频部分,将声信号通过一个高通滤波器使能量谱更加均衡。
② 分帧。根据短时平稳特性将声信号进行分帧。每一帧中包含N个采样点,为了避免丢失语音信号的动态变化信息,相邻2帧之间的分帧会进行一部分的重叠。
③ 加窗。增加相邻帧之间的左右连续性。通常情况下,实验使用边缘平滑降为零的汉明窗。
④ 傅里叶变换。将预处理后的语音信号进行离散傅里叶变换,得到信号的线性频谱,将信号进行时频转换,这就可以对频域信号取模平方计算其功率谱。设加窗后的信号为x(n),经过离散傅里叶变换后:
X(K)=DFTx(n),
(13)
X(K)=H(K)E(K),
(14)
x(n)=h(n)*e(n)。
(15)
⑤ 三角窗滤波。将经过傅里叶变换后得到的频域信号输入到Mel滤波器中使其变成Mel频谱,就可这样根据式(12)得到实际频率与Mel频率的转换关系。
⑥ 取对数能量。将时域卷积转化为频域相加,
lgX(k)=lg(H(K))+lg(E(K))。
(16)
⑦ 倒谱。即为离散余弦变换,将频域相加的关系转化成时域相加的关系,找到信号的另外一种表示。倒谱能够去除帧内和帧间的冗余信息,且倒谱系数之间不具有相关关系[17]:
IDFT[lgX(K)]=IDFT[lg(H(K))+
lg(E(K))],
(17)

(18)
⑧ 差分。由于语音信号为时域连续信号,标准的MFCC只能表示信号的静态特征,即一帧内的语音特征,将静态特征求解一阶差分和二阶差分得到其动态特征信息,使特征更加连续,下一步的分类识别的准确率会更高。
原始的声信号数据进行MFCC算法提取特征值,得到8类数据24维的MFCC特征向量,其中采样间隔20 ms,每帧间重叠10 ms,将特征向量输入自编码器进行分类。
3 自编码器对飞机声信号特征分类
针对飞机声信号特征值进行自编码器分类,输入声信号经过自编码器的编码解码完成了一种降维的输入输出同维度计算过程,解码后,由Softmax进行分类,得到8类不同的声信号分类结果。自编码器分类原理如图4所示。

图4 自编码器分类原理
输入为24维MFCC特征信号,由于自编码器的降维分类特征,8类声信号特征准确率的稳定性存在一定差异。在MFCC算法下,自编码器可以分类出8种不同的飞机类型,但是自编码器对于本文类别1号声信号的分类准确率较其他信号相对准确率低,针对这一问题,提出了基于小波包分解[18]—MFCC联合特征,通过自编码器进行联合特征提取分类,将原始声信号通过小波包分解得到8维小波包重构特征信号,与MFCC算法提取的24维特征信号组合成32维联合特征,输入自编码器进行分类。
4 实验结果对比分析
对原始声信号进行MFCC算法特征提取,采样频率选取20 ms一帧,10 ms一次重叠,自编码器的隐含层节点设为10;将MFCC提取的特征向量输入自编码器,并且通过10次重复实验来验证准确率误差情况,得到10次重复实验分类准确率如图5所示。
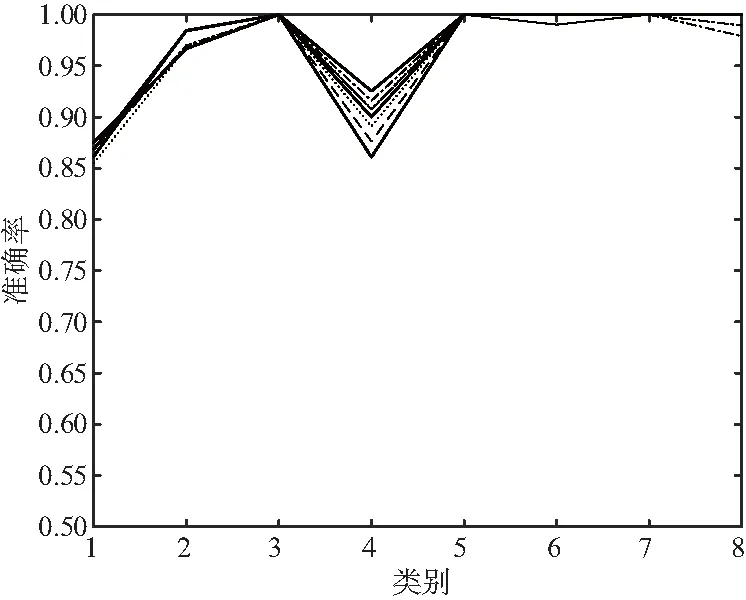
图5 MFCC算法下自编码器10次实验分类准确率
根据多次重复实验的准确率统计平均值,可以得到每一类声信号的近似分类准确率,如表1所示。其中,为了获得稳定的统计平均值,取重复实验次数为100次。
表1 MFCC算法下自编码器100次分类准确率平均值

信号12345678准确率/%86.2397.13100.0090.12100.0099.90100.0099.68
图5中,横坐标为重复实验次数,纵坐标为每一次实验准确率,折线为每一种声信号的类型。由图5以及表1可以看出,在MFCC算法下,每一类声信号的自编码器的分类准确率均在85%以上,平均准确率为95.98%,除了类别1的86.23%,其余准确率均在90%以上。实验证明,在MFCC算法下,自编码器可以较为准确地分类出8种不同的飞机类型。
对于类别1声信号识别准确率较其他信号低的问题,将32维联合特征作为输入特征信号,经过自编码器分类的结果如表2所示,其中准确率均取100次重复实验后10次的平均值。

表2 联合特征算法下自编码器分类准确率 %
由表2可以看出,联合特征提取通过自编码器进行分类,其类别1信号由原来MFCC算法下的86.23%增加为99.91%,且MFCC算法下,类别4的分类结果比起其他类别声信号较低,经过联合特征进行提取后,其准确率由90.12%提高到92.46%,其他类别信号也有小幅度的提升,多次重复实验结果波动较小,说明对于实际信号应用中相对稳定。相比于MFCC算法下的分类结果,整体的平均正确率从95.98%提升至97.74%,实验结果证明其整体正确率提升效果明显且分类结果稳定。
5 结束语
针对截取的非合作通信环境下飞机驾驶舱内的声信号,提取非语音段声信号的特征值,提出了对提取特征通过自编码器值进行分类来准确判断飞机类型。本文是将8类不同类型的飞机通过截取背景音信号进行特征提取和分类;背景音的声信号主要位于低频段且为非线性时变信号,根据声信号的短时平稳性应用MFCC算法对8种不同飞机的声信号进行特征提取,将自编码器首次应用于本文研究的声信号特征分析中进行分类,经过MFCC算法特征提取后的自编码器对8类信号100次重复实验的平均准确率分别为:86.23%,97.13%,100.00%,90.12%,100.00%,99.90%,100.00%,99.68%。针对自编码器对类别1的准确率较其他信号低的问题,提出特征联合—自编码器对自编码器进行优化。实验结果表明,优化自编码器的类别1声信号的平均准确率为99.91%,准确率较未优化的自编码器提高了13.68%。另外,本文研究的声信号声学环境复杂,可能存在更好的特征提取方法以待研究,目前97.74%的平均准确率已经可以在实际应用中发挥较好的应用效果。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
锻压装备与制造技术(2021年5期)2021-11-13
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
科学技术创新(2021年5期)2021-03-17
健康体检与管理(2021年10期)2021-01-03
——编码器
演艺科技(2020年7期)2020-08-13
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
