
基于层级特征与相似性估计的跟踪器
2019-11-12 02:40傅成华
四川轻化工大学学报(自然科学版) 2019年5期
杨 捍, 傅成华
(四川轻化工大学自动化与信息学院, 四川 自贡 643000)
引 言
目标跟踪在计算机视觉中有着广泛的应用,例如机器人、自动驾驶、或者视频监控。然而对于多目标跟踪来说,需要定位视频中每个物体的位置以及身份序号,并且在不同的帧中将同一身份的物体关联起来。在多目标跟踪中,大多数算法采用基于检测的跟踪,得益于检测算法的发展,大多数的工作着重于数据关联部分,也就是将在不同帧间检测到的物体,关联起来,实现多目标的跟踪。Fast-RCNN[1]等双阶段检测算法,或者YOLO[2]、SSD[3]等单阶段的检测算法都能获得很好的效果。同样地,本文也聚焦于基于检测的数据关联部分来实现多目标的跟踪。
在多目标跟踪中,比较广泛的做法是,通过建模,提取不同帧间的不同物体的特征,衡量跨帧间物体的相似度,比如有采用运动模型的文献[4-6]等,也有采用外观特征的文献[7-9]等,以及多模态组合特征文献[10-12]等。而外观特征着重于对比,不同时刻目标框表示外观的相似性。传统的做法是手工提取特征,由于未考虑到外观的多样性、受光照变化、及遮挡等影响,效果较差,并且基于提取外观特征的模型,往往在遇到外观特征特别相似的情况下,表现很差。而基于运动模型,往往是假设运动速度为常数的情况下,在当前状态预测下一个时刻的状态,通常可分为基于线性的运动模型以及非线性的模型,但是在长时间的跟踪下,运动模型对于物体遮挡并不能很好地处理。
因此,为了使多目标跟踪衡量跨帧物体间相似度判别能力更可靠,在面对遮挡问题时具有更好的特征提取能力,本文设计了一个深度层级特征提取的神经网络来得到不同视频帧间物体的特征,以及不同帧间物体之间相似度的衡量矩阵。使得所提取的特征更具有代表性和鲁棒性,并作为数据关联部分的输入。
1 方 法
本文提出了基于深度学习的多层级特征提取和相似性计算网络。该网络融合了不同层级间的外观特征,并同时生成不同帧间物体间的相似性矩阵,实现端到端的学习。
1.1 检测部分
由于深度学习的发展,目标检测得到了很大的发展。本文采用基于YOLOv3[13]的行人检测技术,来做多目标跟踪的第一步,为多目标跟踪提取视频中每一帧中物体所在的位置。
1.2 层级特征提取以及相似性计算网络
深度特征层级抽取网络,如图1所示,由两部分组成,一部分是基于特征提取网络(前半部分),剩余部分为相似性估计网络。网络输入为两帧和检测算法所检测到物体的中心坐标,层级特征抽取网络是双端网络,例如,t时刻的视频帧输入上端,t-n时刻的视频帧输入下端,随着网络的逐渐加深,特征图的尺寸会越来越小。其中,抽取9个特征图的特征,其中有3个特征图来自图1中moblenet[14],有6个特征图来自图1中的扩展网络。得到的9个特征分别经过图1中moblenet[14]和扩展网络各自的层级降维网络。设置在一帧中所检测物体最多有个Nm,最后将得到的9个特征向量拼接在一起形成Nm*520维特征向量。如图1中的F1特征向量对应于t时刻视频帧经过特征层级提取与降维网络所得到的特征向量矩阵。同理,Ft-n对应于t-n时刻的视频帧数。得到Ft-n的矩阵大小同样为Nm*520,将得到的F1和Ft-n特征组合成Nm*Nm*1040三维的特征组合矩阵。1040是由2个520维度的通道数拼接而成,而Nm*Nm对应于两帧间各个物体间的对应关系,Nm为每帧中所能检测到的最大行人数量。
图1中由不同帧所得到特征矩阵组合而成的特征组合矩阵作为相似性估计网络的输入,经过表1中相似性估计网络中的结构,最终得到相似性矩阵M,如图2中矩阵C,表明两帧间物体的对应关系。在矩阵C的基础上做了改进(图2中有改进原因),使得图1中的M1可以表示相对于t-n帧,t帧中离开的物体,同理,M2可以表示相对于t帧中,t-n帧中没有的物体,也就是刚进入视野的物体。M1经过行方向上的softmax得到A1,M2经过列方向上的softmax得到A2。A1、A2作为损失的输入,其中由A1、A2得到的a1、a2也将作为损失函数的输入,章节1.3部分会详细介绍。

图1 层级特征提取和相似性估计网络流程
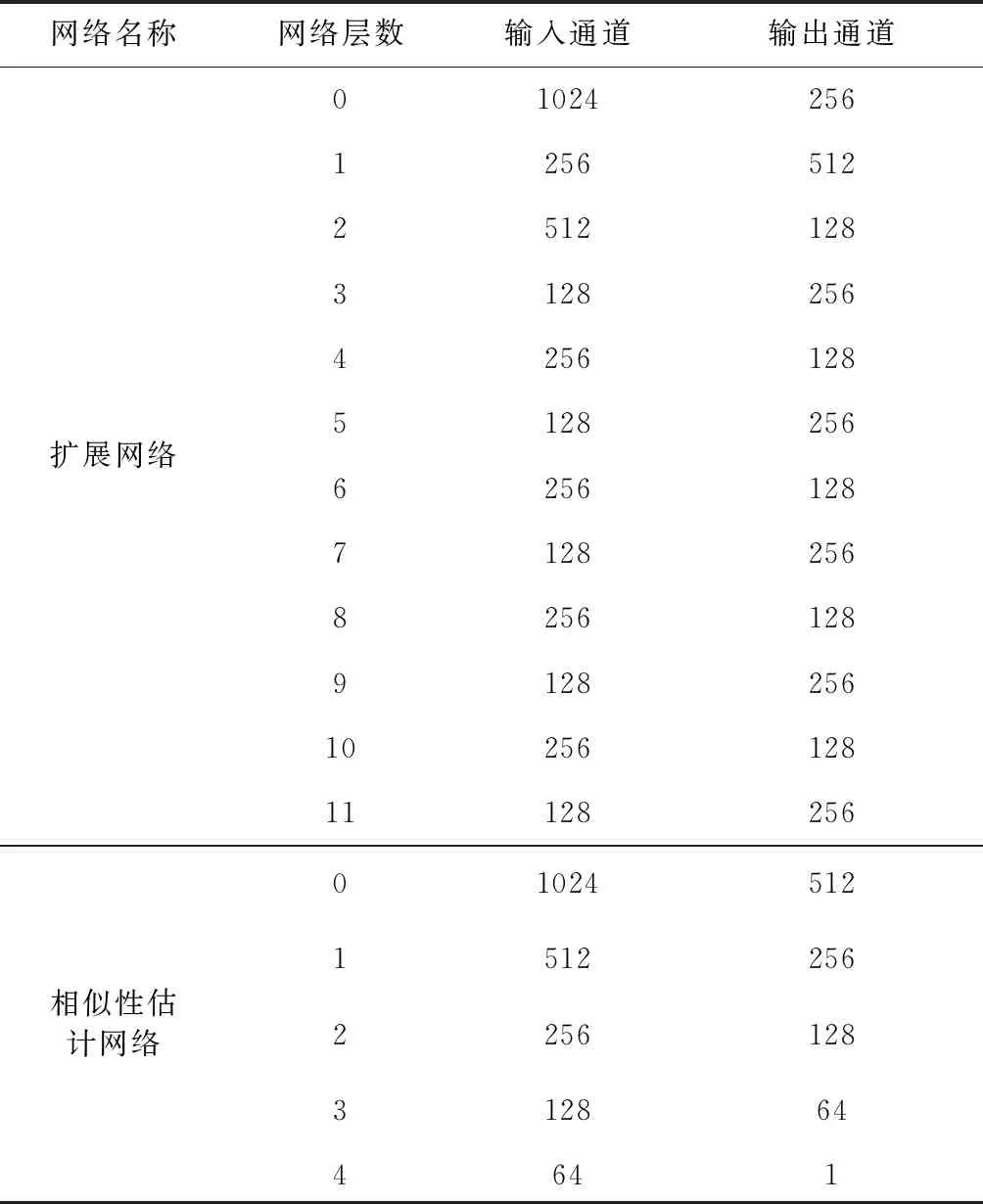
表1 层级特征抽取与相似性估计网络结构
表1为图1中扩展网络部分以及相似性估计网络部分的结构图参数。扩展网络部分由11层卷积神经网络组成,输入为moblenet[14]最后一层特征的输出。而相似性估计网络是由5层卷积神经网络组成,输入为两帧间所提取到的特征组合。扩展网络所提取的特征是为了输入到层级降维网络中(见表2),分别从表1所提取的特征取6层输入层级特征降维网络,同时也从moblenet[14]所提取的特征抽取3层输入层级特征降维网络。最后通过各自的降维网络得到520维度的特征(由输出通道数相加得到)。
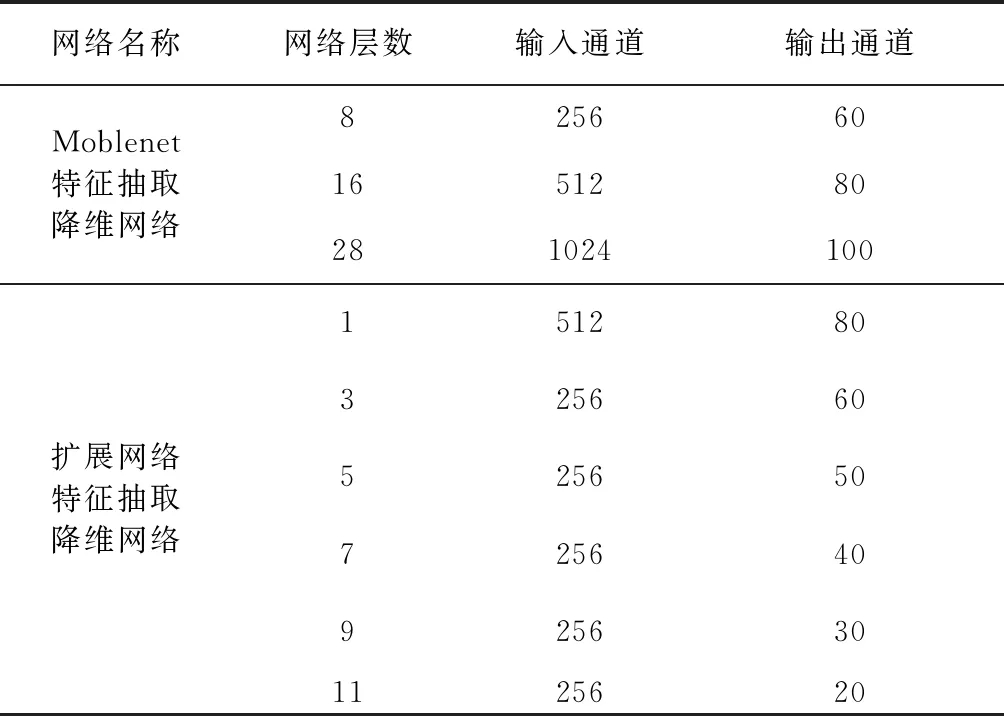
表2 层级降维网络
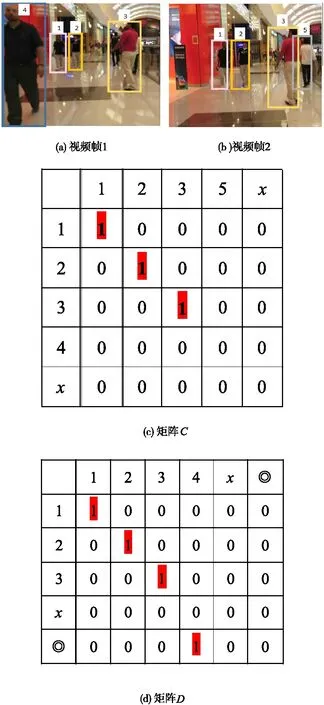
图2 相似性矩阵
图2中,图2(a)表示视频中的一帧,图2(b)表示视频中的另一帧。图2(a)帧中包含有序号1、2、3、4的行人,而图2(b)帧中包含了序号为1、2、3、5的行人,其中1、2、3序号的行人同时出现在图2(a)帧和图2(b)帧中,此时c矩阵表示两帧间的相似矩阵。假设每帧中最多检测到5个物体(本文设置最大检测目标数为100),故矩阵的大小为5*5,其中矩阵C中行表示图2(a)帧中的身份序号,而列表示图2(b)帧中的身份序号,在图2(a)与图2(b)两帧中同时出现并且匹配的为1、2、3序号的行人,故在矩阵对应位置值为红色标记1。另外,图2(a)帧中序号4与图2(b)帧中序号5行人在对应帧中没有行人可以匹配,也可以理解为行人4离开了当前视频,以及行人5刚进入视频,因此为了解决在矩阵中也可以表明两帧间物体的离开与进入,分别在矩阵C的最后一行最后一列加入第◎列和第◎行,得到矩阵D来表示两帧物体间的离开与进入。其中,x表示每帧中剩余的可检测与可跟踪的物体数。
1.3 损失函数
图1后部分网络为网络的损失部分,M1矩阵的第m行表示关联t-n时刻第m个物体在t时刻与之对应的物体,此时对应的矩阵大小为Nm*(Nm+1)。最后一列表示相对于t-n时刻,t时刻旧的物体离开所对应的帧或者新的物体进入的帧。同理可得M2矩阵添加的最后行。M2矩阵的第n列表示在t时刻第n个物体对应于t-n时刻帧的物体。如图,将得到的M矩阵分别添加一列和一行后得到M1与M2矩阵,分别表示从t-n时刻到t时刻物体关联信息,以及从t时刻帧到t-n时刻帧物体间的关联信息,此时M1、M2矩阵大小为Nm*(Nm+1)。得到的M1矩阵和M2矩阵分别在行方向和列方向经过softmax函数,得到对应的A1矩阵和A2矩阵。A1矩阵大小为Nm*(Nm+1),A2矩阵大小为Nm*(Nm+1)。
所得到的A1、A2作为深度层级可分离网络的输出,并以此作为网络的损失函数的输入,此时可得从t-n时刻到t时刻对应的前向损失loss1,如公式1,同理可得从t时刻输入帧到t-n时刻输入帧的后向损失,如公式2。Tt-n,t是损失函数的标签值,大小为(Nm+1)*(Nm+1)。公式(1)与公式(2)中,T1、T2分别表示标签矩阵Tt-n,t。为了和矩阵A1、A2的大小相对应,分别减去第◎行和第◎列。a1、a2表示分别从A1、A2减去◎行◎列所得到的矩阵。公式(3)表示一致性损失,因为,无论从t-n到t时刻所得到的相似性矩阵,还是t到t-n时刻的特征相似性矩阵,其差异值理应越小越好。
公式(4)中T3表示标签相似矩阵D同时去掉◎行和◎列所得到的矩阵,而max(a1,a2)也可由图1中的M0表示,公式(4)衡量最终网络所得到的不计未同时出现物体的相似性矩阵与同样的不计未同时出现物体相似性的标签标矩阵的差异。由公式(1)~公式(4)可得网络的最终损失Loss。
(1)
(2)
(3)
(4)
(5)
1.4 数据关联部分
1.4.1 跟踪流程中的层级特征抽取与相似性估计
训练的时候采用双端网络,双端网络是共享网络权重,而在数据关联部分,使用单端网络,流程如图3所示。视频的每一帧经过检测器件得到跟踪类别物体的坐标,将每一帧图片以及检测物体的坐标传入到特征抽取网络,也就是图1中的前半部分单端的流程。 对于特征抽取网络的部分,视频的每一帧所提取的特征矩阵都会被储存,以便与下一时刻视频帧所提取的特征组成特征组合矩阵传入相似性估计网络中,得到相似性矩阵。

图3 数据关联流程
1.4.2 数据关联流程
如何将不同帧间的同一物体关联起来,是解决跟踪问题的关键。检测部分决定了能否检测到物体,而数据关联部分决定了能否将同一物体匹配起来。本文设计了基于层级特征网络提取到的特征,输入到相似性估计网络中得到不同时刻帧间不同物体间的相似性矩阵。例如在视频开始第一帧,初始化轨迹数量和检测到的物体数量一致,在后续帧输入网络后,会根据前面N帧提取得到的特征矩阵,与当前帧的特征矩阵一起输入图3中的相似性估计网络,得到各自的相似性矩阵。最终将当前帧,与前面N帧的相似性矩阵做累加得到最终的相似性矩阵,并利用匈牙利算法[15]在得到累加相似性矩阵上做全局最优的指派问题,也就是两帧间同一物体的匹配。再根据匈牙利算法指派的结果,做轨迹的更新。
总体看来,本文设计的跟踪器是在线的跟踪器,与离线跟踪器不同点在于,不需要未来的视频帧来跟踪当前帧的物体,只需要输入当前帧之前的视频帧,因此,相对于离线的跟踪器,在线跟踪更适用于实际的场景,例如监控等需要实时跟踪的场合。
2 实验部分
2.1 实验细节
选用MOT16数据集,数据集包含了7个视频场景,分为训练集和测试集,利用pytorch框架在NVIDIA RTX 2070GPU训练而得,训练每次批次为4,总的训练轮数140轮,设置Nm为100,采用SGD[16]优化器。
2.2 结果对比
在最终的测试集上得到实验结果见表3。

表3 基于MOT16测试集的实验结果
表3中,箭头向上表示指标越大越好,箭头向下表示指标越小越好。MOTA[19]指标表示目标跟踪的准确率,是衡量多目标跟踪最重要的指标。MOTP[19]则表示多目标跟踪的精度,其计算是由标签上物体目标框与检测所得到的目标框的重合率计算而得。MT[20]表示大部分被跟踪的目标,而ML[20]表示大部分未被跟踪的目标。实验结果表明在测试指标上本文采用的方法相对于一些其他的方法取得了一定的优势。其中,MOTA指标由公式(6)计算得到:
(6)
其中:FPt由表示在t时刻的目标误检数量,FNt表示在t时刻目标漏检测的数量,ID_Swt表示在跟踪过程中目标发生身份互换的数量,GTt表示t时刻对应的标签。
2.3 实验结果展示
实验的部分仿真结果如图4所示。由图4可知,本文所提出的基于层级特征提取相似性计算网络能有效提取不同物体的特征,经过计算所得到的相似矩阵具有很好的判别性,能够缓解由于遮挡问题造成的物体身份的改变。如,序号73以及序号16的物体都能够在被遮挡后有效地还原目标的身份。缓解了多目标跟踪中遮挡问题造成的身份改变问题。

图4 部分视频跟踪效果图
3 结束语
在基于检测的在线多目标跟踪的框架下,提出了基于层级特征提取的跨帧间物体相似度计算的网络,该网络可以端到端的训练,在得到网络的固定权重后,应用于跟踪的流程,并利用匈牙利算法,在得到的各帧间相似矩阵的基础上,做物体间各物体最优的指派,也就是不同帧间同一物体的匹配,并不断更新跟踪的轨迹。实验结果表明,经过层级特征提取得到的相似性矩阵具有对不同帧间物体相似性很好判别能力,同时对遮挡问题有一定的缓解,并在多目标跟踪的一系列指标上得到了一定的提高。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
中国典型病例大全(2022年13期)2022-05-10
环球人物(2022年4期)2022-02-22
小资CHIC!ELEGANCE(2021年32期)2021-09-18
航天工业管理(2020年9期)2020-12-28
河北画报(2020年8期)2020-10-27
军事运筹与系统工程(2020年1期)2020-09-11
廉政瞭望(2019年5期)2019-06-10
浙江大学学报(工学版)(2016年2期)2016-06-05
小学阅读指南·高年级版(2014年2期)2014-05-27
