
基于随机森林和SVR的阿片类药物危机分析
2019-12-04 11:33李军,赵佳,赵宸
阜阳师范大学学报(自然科学版) 2019年4期
李 军,赵 佳,赵 宸
(阜阳师范大学 计算机与信息工程学院,安徽 阜阳 236041)
阿片类药物是作用于阿片受体以产生吗啡类作用的物质,医学上主要用于缓解病痛、麻醉等。长期使用阿片类药物会导致大脑中的区域结构和功能的发生变化,停止使用会产生焦虑不安。严重可能致命,因此该类药物的使用是受管制的[1-4]。在美国1999年前,有86%阿片类药物的使用者用于非癌症疼痛治疗;2002-2013年,海洛因的滥用导致死亡人数增加了286%,其中约有80%的海洛因使用者在转向使用海洛因之前误用处方类阿片药物。据统计,仅2013年全球有2 800万~3 800万人非法使用阿片类药物(占15~65岁之间全球人口的0.6%~0.8%)。根据美国疾病控制和预防中心的数据显示,阿片类药物的滥用已经导致美国历史上最为严重的药物过量使用,并于2014年将该问题列入五大公共卫生挑战之一。截至2015年,阿片类药物的娱乐用量和成瘾率上升的原因是阿片类药物的处方药的过度使用和廉价的非法海洛因。2013年芬太尼等合成阿片类药物相关的死亡人数增加,其中2016年芬太尼及相关药物死亡人数就超过2万人。1999~2017年统计数据显示,非法使用阿片类药物的群体中,男性比女性占有更大的人数比例,18~25岁的年龄群体且更容易接触到阿片类药品。
阿片类药物的滥用严重威胁着社会的和谐稳定,采取科学合理的分析方法可以极大地遏制危机的影响范围与影响程度。在现有数据的基础上,本文通过基于机器学习的方法[5-6],通过评价指标,挖掘事件的潜在影响因子,预测未来的趋势,为后续的决策提供重要的参考标准。
1 预处理
分析的数据集统计了美国Ohio,Kentucky,West Virginia,Virginia,Pennsylvania 五个州和州内462个城市的数据,具体城市数如表1。数据集分别是:(ⅰ)统计2010-2017年间,城市上报的不同种类药品的事件报道数目与5个州当年总共的药品事件报道数目,共计24 063条记录;(ⅱ)统计了462个城市2010-2016年间的人口普查数据,合计有2 272个样本数,149个人口特征项。

表1 五个州的城市数量统计
数据集里2010-2012年的人口普查数据中,有8个特征项是缺失的,选择直接删除这些特征项。对于有少部分城市的部分特征项有数据缺失,使用K近邻的方法填补缺省值[7]。以各城市的人口统计数据为样本集合,设第i个有缺省特征项的城市为Xi,则第i个城市缺省特征项的集合为Si,记无缺失特征项城市的集合为P,没有缺省特征项的城市j为Yj,计算样本i与j的欧式距离Di,j
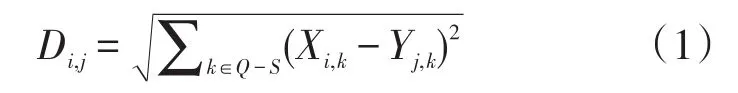
由(1)式,选择与缺失样本最近的前K个样本,构成集合Q,按均值填补缺省值
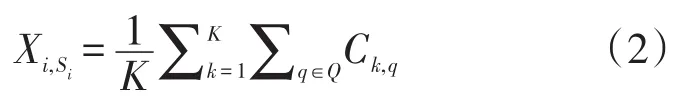
在人口普查数据中,各特征项取值范围相差过大,先对数据预先做了Z-SCORE标准化的处理。为了在后续使数据更加直观地展示,又收集了当地城市的经纬度坐标信息。
影响阿片类药物事件的因素有很多,在已拥有的数据与相关背景的基础上,将影响因子归类为三种,分别是药品流行度,当地政策和人口分布。同时将第i个城市第j年内上报的药品事件数作为衡量该城市当年的受危机影响程度。
1.1 阿片类药品流行度分析
对于不同的城市来说,由于存在着差异性,反映在抵抗外界药物危机入侵的抵抗力不同与控制城市内部药品危机传播的能力也不同。假设把每个城市比作一个独立个体及一定区域内的城市比作群体,需要分析个体和群体两个方面药品流行度。在对2010-2017年各城市药品事件数的可视化过程中,发现各州各城市的变化趋于一个稳定的状态。据此,忽略五个州相互间的影响,建立药品流行度指标来作为城市受外界干扰程度的量化标准。
阿片类药品分成处方药与毒品两大部分。通过对五个州2010-2017年不同种类药品的事件数进行汇总统计发现,Heroin,Oxycodone,Fentanyl的药品事件占据了80%左右。其中Heroin划分为毒品一类,占了整个事件的50%;而Oxycodone和Fentanyl划分为处方药一类,使用数据可视化进一步分析发现,Oxycodone事件处于一个逐年下降的趋势,Fentanyl逐年上升。综合考虑,将Fentanyl作为主要的处方用药,Heroin作为主要的毒品。数据分析发现各州之间的药品事件总数有着显著的差距,因此一个城市的药品流行度是以所在州为衡量标准。通过上述分析,建立药品流行度计算公式(3)
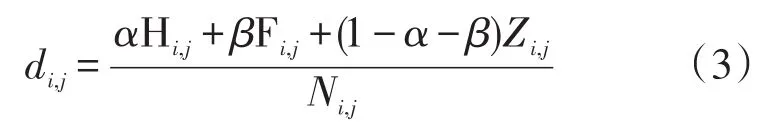
其中:di,j表示第i个城市第j年的药品流行度,该城市Heroin药品事件数为Hi,j,Fentanyl药品事件数为Fi,j,除Heroin和Fentanyl的药品事件总数为Zi,j;Ni,j表示第i个城市所在州的第j年药品;α,β为参数,分别设定成0.30和0.50。
1.2 当地政策分析
对于不同的城市来说,可变因素较多,加上数据集中相关信息的较少,直接从政策的角度分析是比较困难,而从政策所带来的效应分析是一种可行的方案。本文从不同的人口分布出发,实施不同的政策会在不同的人口组成特征上有所体现。例如,若当地城市政策对外国移民不太“友好”,则本地的外国人口所占比例会较低。假设在无政策干扰的情况下人口组成特征信息矩阵为X,表示经过政策的干扰后表现出的人口组成特征信息矩阵,则有

因此,将当地政策问题转化成对人口普查数据信息的特征选择。
1.3 人口分布分析
不同地区的人口分布数据中特征数目较大,直接使用回归模型预测很容易导致过拟合现象。如果使用 PCA(principal components analysis)对数据进行降维[8-9],带来的问题是数据的可解释性较差,实际应用的参考价值也较低。集成学习方法在数据挖掘领域有着非常广泛的应用,随机森林作为bagging的一个变体,以基于Gini指数[10]的特征选择,可以同时获得降维和从分类任务中消除噪声的双重效益。
在对特征进行重要性分析过程中,直接将所有的特征一次性传入随机森林模型会产生一个问题:即一些重要性程度不大的组成特征可能会携带很多隐含的政策信息,同时各个特征间的差异性并不明显。因此这里将特征分为两个层次,即为一级层次因素和二级层次因素。一级层次因素作为上级层次,包含有多个二级层次因素。此处的模型是单独地对每个一级层次因素进行建模,分别计算所有一级层次因素下二级层次因素的特征重要性,随后再对所有的一级层次因素建立随机森林模型,计算特征重要性。
使用CART作为随机森林的基学习器。CART决策树使用Gini指数来选择划分属性。设当前样本集合D中第m类样本所占比例为pk(k=1,2,…,|y|),属性a有V个可能的取值{a1,a2,…,av},则属性a的Gini指数为

其中,

在候选属性集合A中,选择使划分后Gini指数最小的属性作为最优划分属性,即
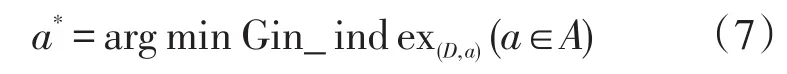
训练的过程中,将2010-2016年的人口普查数据作为自变量,当年各城市的药品事件数作为因变量,设置集成CART数目为80,得到各二级层次因素的特征重要性如图1所示,与一级层次因素的特征重要性。

图1 部分二级层次因素的特征重要性
特征方面选取的原则是:1)在一级层次选取占比最大的前三个及该一级层次下所有的二级层次因素;2)其它一级选取二级层次因素选取特征重要性占比最大的前1~3个。基于此,最后选择了25个特征用于模型训练。
2 预测模型
预测方面,由于问题是一个时间序列的问题,因此采用Seq2Seq模型[11]和带有滑动平均机制下的 SVR(support vector regression),通过模型的特点与实验的结果对问题作进一步的分析与结论。
2.1 基于Seq2Seq模型分析
Seq2Seq是一中的RNN,在自然语言处理上取得了巨大的成功。本文将该模型用于对数值的预测,使用GRU作为基本的单元,网络模型如图2所示。

图2 Seq2Seq模型
将2010-2016年人口分布选择出的25个特征与阿片类药物的流行度,各城市每年的药品事件数统一成新的数据集。其中选取412个城市用于训练,50个用于测试。使用了dropout正则化方法,损失函数选择了MSE,在100个隐层下进行训练。经过多次尝试(包括微调网络模型结构与调整dropout的概率),由于数据量的不足导致训练结果始终不是很好,并且实际的预测结果也与实际偏差较大,如图3所示。

图3 Seq2Seq训练过程的Loss下降曲线
2.2 基于滑动窗口SVR模型分析
对于一般形式下的SVR[12-13],不能用在对时间序列型数据的预测。基于滑动窗口的思想,对SVR的训练过程进行改进,增加约束条件,使之用于预测时间序列型数据。
SVR模型的优化目标如(8)式:


针对该问题,将每年的数据作为一个基本的单位,为了预测第T年的数据,设滑动窗口大小为w,滑动步长s。变量间的约束满足(9),训练算法。
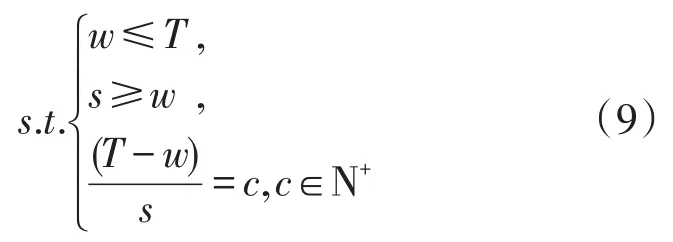
使用高斯核函数,在N=1,S=1,以参数C=0.001,γ=0.01 建立模型。

关于训练数据,在之前人口分布所选特征与药品流行度的基础上,又加上滑动窗口内各年内的药品事件数作为另一项或几项特征,通过训练2010-2016年的数据,预测2017年药品事件数。统计了各州的结果如表2。

表2 五个州药品事件数结果统计
2.3 结果分析与模型评价
滑动窗口SVR模型在五个州的预测结果里,Kentucky,Pennsylvania,Virginia的预测结果较好,Ohio由于药品事件发生的基数较大,导致实际误差要高,但相对误差较低。而对West Virginia州的预测结果较差。进一步地,通过抽取West Virginia的部分异常数据发现,在2010-2017年间,West Virginia部分城市的药品事件数目呈现出一种异常的变化趋势,该模型对这种异常的变化难以估测。根据城市地理位置信息筛选,发现预测与真实偏离较大的这些城市的坐标大多集中于与Ohio和Pennsylvania的边界城市地区。在实际数据中,Ohio,Pennsylvania的药品事件基数较大,药品流动性更大,因此认为是West Virginia受到Ohio,Pennsylvania过多的影响。然而模型弱化了州与州之间的关系,导致对West Virginia部分城市的预测结果较差。又因为模型的局限性,如果要预测某一年的数据,需要知道这一年之前几年的实际结果,导致模型的持久性较差。
Seq2Seq模型的一些优势可以弥补模型二的一些局限性。在之前的实验中,测试集的训练曲线在训练的早期下降至最低点,这也说明了数据量限制了模型的性能的提升,事实结果是我们很难进一步地获取更多相关的数据。
3 小结
本文在随机森林了和SVR的基础上建立模型。实验从数据的角度进行建模分析,挖掘出不同的人口特征项对阿片类药物危机的影响程度。并且发现深度学习方法在处理该类问题上有着很大的潜在优势,但受限于数据量的匮乏,很难进一步提升模型的性能。因此又提出了滑动窗口机制的SVR模型,对美国Ohio,West Virginia,Pennsylvania,Virginia,Kentucky五个州的2017年药品事件数进行预测。实验结果说明了要控制阿片类危机需要对影响力较大的部分人口实施相应的策略,同时对于West Virginia需要加强对Pennsylvania,Ohio的边界的监督与管理。
猜你喜欢
当代医药论丛(2022年3期)2023-01-04
中国合理用药探索(2022年1期)2022-11-26
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
上海医学(2020年2期)2020-12-31
保健与生活(2018年17期)2018-01-27
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中国卫生(2016年5期)2016-11-12
中国卫生(2015年5期)2015-11-08
