
考虑人类活动用水的土壤含水量神经网络反演
2021-02-24 10:50朱彦儒赵红莉靳晓辉蒋云钟
水利水电科技进展 2021年1期
段 浩,朱彦儒,2,赵红莉,郝 震,3,靳晓辉,蒋云钟
(1.中国水利水电科学研究院水资源研究所,北京 100038; 2.兰州交通大学测绘与地理信息学院,甘肃 兰州 730070;3.大连理工大学水利工程学院,辽宁 大连 116024; 4.黄河水利科学研究院引黄灌溉工程技术研究中心,河南 郑州 450003)
土壤含水量是水文模拟和陆面过程模拟的重要参数[1],对地表热量平衡和蒸散发有着显著的影响[2]。因此,对土壤含水量进行准确观测和模拟,获取准确的地表土壤含水量数据,对水资源管理、流域产流模拟等都有着重要意义[3]。
遥感技术的发展使大尺度的土壤含水量计算成为可能,但遥感反演常需一定的地表参数做支撑,如IEM(integral equation model)模型[4]。而当研究区域数据匮乏时,对土壤含水量的反演则成为非线性、且难以通过理论推导进行求解的计算问题,此时,学者开始用人工智能技术来弥补实际观测的不足[5]。代表性的成果包括Han 等[6]利用分类与回归树(classification and regression tree,CART)方法,基于遥感、气象数据及DEM等估算我国全国尺度的土壤含水量;Ahmad等[7]采用机器学习的方法,使用TRMM(tropical rainfall measuring mission)降水数据和归一化植被指数(normalized difference vegetation index,NDVI)指数来推求美国南部的土壤含水量等。此外,还有一类应用是利用人工智能的方法估算站点观测的土壤含水量变化,如侯晓丽等[8]利用人工神经网络(ANN)模拟了河南三义寨灌区不同埋深的站点土壤含水量变化,采用数据为降水、气温、风速等气象数据,较为准确地刻画了不同埋深条件下的土壤墒情分布;罗党等[9]采用灰色神经网络,分析了气象数据对河南新郑市土壤含水量的关系,取得了良好效果。
整体上,人工智能技术在土壤含水量的模拟应用方面包含点尺度和面尺度的模拟,但对土壤含水量变化的影响要素主要集中在参考气象要素、下垫面条件等,或基于遥感数据计算各类指数[10]对土壤含水量进行分析,而在考虑自然要素的同时又能考虑人类活动用水的分析较少。而只将自然要素与土壤含水量进行关联,难以表达非自然因素对土壤的水分补给,如灌区的灌溉用水补给土壤水分[11]等。利用遥感对地面干旱情况的监测可在一定程度上弥补这个问题,相关的研究工作有黄友昕等[12]利用MODIS(moderate-resolution imaging spectroradiometer)干旱指数和RBFNN(radial basis function neural network)方法反演了河南地区土壤含水量,但该研究只考虑了遥感数据源,同时也只考虑了返青期的冬小麦地区的土壤水分状况,且只选用了少量样本进行了训练。气象要素、地形条件、NDVI等要素对地表土壤含水量的变化关系更为密切,同时,该思路在更大时空范围的土壤含水量反演方面仍需探索。
本文采用MPDI(modified perpendicular drought index)反映地表的干旱情况,以此来体现地表土壤在考虑人类用水条件下的干湿状况,同时选取降水、潜在蒸散发、NDVI、DEM等与地表土壤含水量关系密切的要素,通过构建神经网络对河北地区的地表土壤含水量进行模拟。
1 研究区概况及数据
1.1 研究区概况
以地处华北平原的河北省为研究区。该区域占地面积18.88万km2,海拔高差达2 600 m以上。河北省的主要地形包括平原、温带落叶阔叶林和草地等,主要气候类型是温带季风气候,夏季高温多雨,冬季寒冷干燥,多年平均降水量为480 mm,多年平均蒸发量为1 600 mm。河北省的主要地形及土壤墒情站点分布如图1所示。
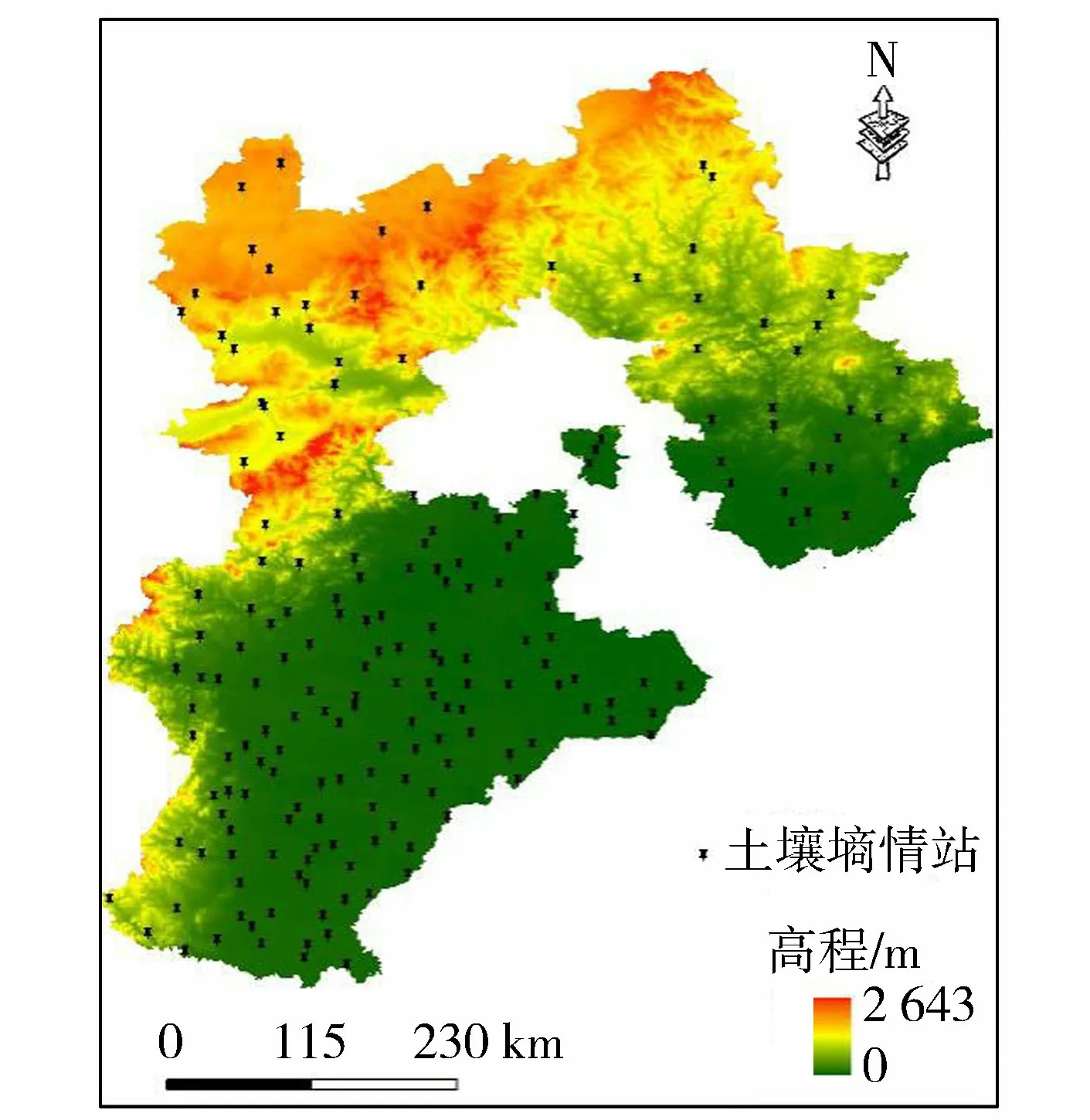
图1 研究区概况
1.2 数据来源及处理
1.2.1土壤含水量数据
土壤含水实测数据选用河北省水文局2018年3—11月10 cm深度的墒情监测数据。在河北省范围内,约有180个土壤墒情自动监测点(受各站点汇报及时性限制,每日实际可用数据不足180个)。土壤墒情站采用TDR(time domain reflectometry)传感器进行监测,约每隔10 d监测1次。
1.2.2气象数据
气象数据主要来自国家气象站(www.data.cma.gov.cn),包括用来计算潜在蒸散发的气温、湿度、日照时数、风速和气压等的逐日数据。用来与土壤含水量进行模拟的降水数据采用CLDAS(CMA land data assimilation system)的降水产品。将国家气象站点的观测数据插值成栅格数据,空间分辨率统一到0.01°上,时间分辨率为逐日。利用插值后的气象数据来计算河北省的潜在蒸散发,计算方法选用FAO-56算法[13]。
1.2.3遥感数据
MODIS遥感产品被广泛用来进行地表参数的观测和反演。这里采用2018年的250 m分辨率的MOD09地表辐射产品进行MPDI的反演,该数据可从EARTHDATA (https://search.earthdata.nasa.gov/)下载,计算过程采用Ghulam等[14〗提出的方法。NDVI的计算选用MODIS的一级影像数据。利用MRT(MODIS reprojection tool)工具将MODIS产品进行拼接和投影转换,得到河北省地区的相应数据产品。其他遥感数据使用ENVI软件进行处理,所有影像均转换到0.01°的分辨率上。
为从较大空间尺度上评估本研究模拟结果的准确性,选取土壤含水量研究中常用的SMAP(soil moisture active and passive)9 km产品作为对比数据。SMAP卫星由美国国家航空航天局(NASA)在2015年发射升空,搭载L波段辐射计,主要用来监测全球土壤水分变化,已在全球范围内开展了验证和应用工作[15〗,具有较好的精度,是分析大尺度土壤含水量的主流产品之一。
2 研究方法
2.1 FAO-56算法
FAO-56算法是具有物理机理的、考虑生理学和空气动力学参数的潜在蒸散发估算方法,能较好地估算地面冠层的潜在蒸散发。基于Penman-Monteith方法的蒸散发计算公式为
式中:ET0为潜在蒸散发;u2为2 m高处的风速;Δ为气压曲线斜率;γ为湿度常数;Rn为净辐射;G为土壤热通量;T为2 m高度处的气温;es-ea为饱和水汽压差。
2.2 MPDI计算
利用遥感监测地表干湿状况源于垂直干旱指数(perpendicular drought index,PDI)的提出,该指数利用土壤在红光与近红外波段反射率的差异来估算土壤含水量,PDI越大表明土壤越干旱。MPDI在PDI基础上引入了植被盖度,改善了对混合像元的分解,在干旱的监测上可取得更好的监测效果,尤其是在植被覆盖区域[16〗。MPDI的表达式为
式中:I为MPDI;Rv,Red、Rv,NIR分别为红光和近红外波段的植被反射率;fv为植被盖度;M为土壤线斜率;RRed为大气校正后的红光波段反射率;RNIR为大气校正后的近红外波段反射率。关于MPDI的更多计算细节,可参见Ghulam等[14〗的研究。
MPDI的大小与土壤含水量和植被覆盖度成反比,据此可通过构建MPDI与土壤含水量的关系,来模拟区域土壤含水量。
2.3 神经网络模型构建
在对土壤含水量的相关研究中,降水和NDVI是传统的考虑因素,近年的研究表明,潜在蒸散发和地形条件[17〗对土壤含水量的影响也非常显著。为能在充分考虑自然要素的基础上,进一步考虑人类活动用水对土壤含水量带来的影响,将MPDI这一通过遥感反演来表征地表干湿状况的要素作为输入变量。由此,构建了以降水、潜在蒸散发、MPDI、NDVI和DEM作为输入,以实测站点10 cm深度土壤含水量值为输出的神经网络模型。在具体的实现上,采用序贯模型建立神经网络[18]对土壤含水量进行模拟,激活函数选用relu,训练次数为1 000,目标函数选取MAE(mean absolute error),优化器选用Adam(adaptive moment estimation)。本文建立的神经网络模型结构及研究的整体技术路线如图2和图3所示。

图2 神经网络结构示意图

图3 土壤含水量反演流程
2.4 评价指标
利用相关系数r、均方根误差ERMS及偏离度Bias指标来对土壤含水量的模拟结果进行评价。各指标的计算形式如下:
(3)
(4)
(5)
式中:yi为模拟值;xi为实测值;N为样本数。
3 结果和讨论
3.1 模型计算及精度检验
以河北地区土壤墒情站点位置为准,分别获取有墒情观测日的模型输入信息,即DEM、MPDI、降水、潜在蒸散发和NDVI,然后以实测土壤含水量值为参照,利用神经网络模型对输入数据进行模拟。在2018年,共可获取2 934组训练样本,随机选取其中70%的样本进行训练,15%的样本作为验证,其余15%的样本进行测试。结果(图4)显示,在训练期的r=0.7,ERMS=0.037 5 cm3/cm3,Bias=-0.002 6;验证期r=0.5,ERMS=0.042 7 cm3/cm3,Bias=0.000 4。总体来看,训练期的相关性较好,且模拟期与验证期r相差不大,模型具备一定的泛化能力。

图4 神经网络模拟结果与实测值对比
基于气象数据及植被状况数据,利用神经网络进行土壤含水量预测的研究可分为站点尺度的模拟和大区域尺度的模拟两类。站点尺度的模拟上,模拟结果常可取得较好精度[19],而就较大尺度、大量样本的模拟而言,本文r=0.7,优于Han等[6]对全国尺度的模拟精度。同时,该精度也与利用多种要素对某单一变量进行模拟和预测的已有研究较为符合[20]。因此,本文对河北地区地表土壤含水量的模拟结果与实测值间具有较好的一致性。
3.2 单一观测日土壤含水量结果分析
为进一步评价神经网络模拟的精度,选取单一日期的河北省土壤含水量模拟值与实测值进行对比,以此分析本文所建模型在特定日期对土壤含水量空间异质性的模拟效果。以2018年4月24日的监测结果作为示例,图5给出了该日河北省范围内土壤墒情站点的土壤含水量监测数据,以及对各站点位置用神经网络方法计算得到的土壤含水量结果。
从图5(a)可以看出,利用神经网络方法得到的土壤含水量模拟结果能较好地反映地表土壤含水量的变化趋势,模拟结果的r=0.67、ERMS=0.069 5 cm3/cm3、Bias=-0.22(图5(b))。从绝对值上看,神经网络方法的模拟结果比实测值偏低,但总体的相关系数在0.6以上,仍具有较好的相关性。
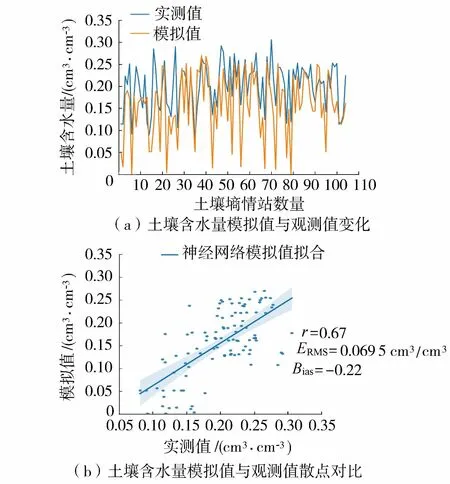
图5 2018年4月24日土壤含水量模拟结果与实测值对比
3.3 河北省土壤含水量空间分布结果
将模拟得到的2018年1—10月的河北省逐日土壤含水量作算术平均,得到2018年1—10月河北省土壤含水量均值的空间分布(图6)。从图6可以看出,土壤含水量的均值最小值约为0.04 cm3/cm3,最大值约为0.23 cm3/cm3,空间差异较大,东部、东北部平原地区较高,西部及北部山地较低。
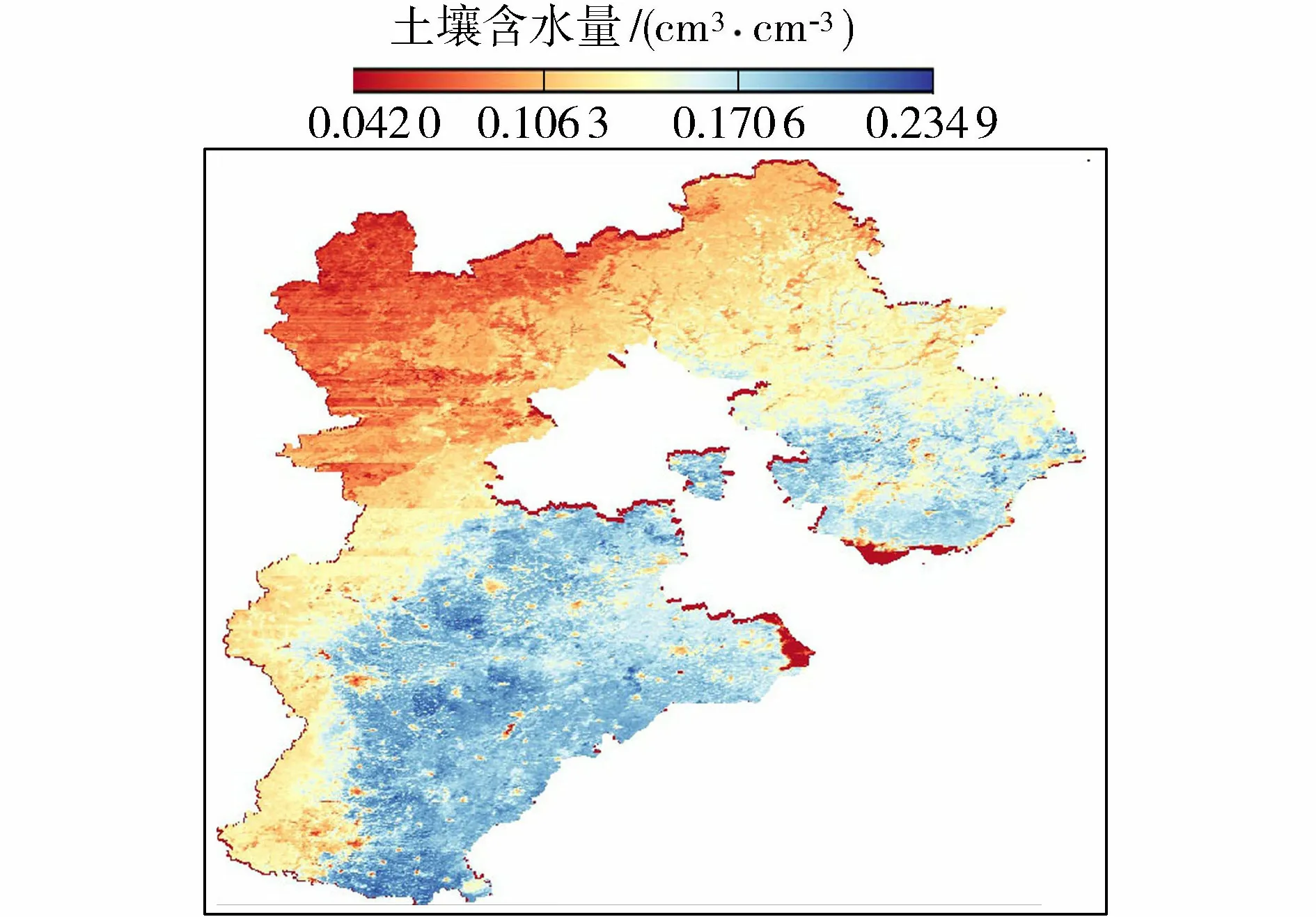
图6 2018年1—10月河北省地表土壤含水量均值空间分布
为进一步对模拟结果的准确性进行评估,基于逐日土壤含水量数据计算得到2018年春季和夏季的土壤含水量均值,并与SMAP的9 km土壤含水量产品进行空间差异性的比较(图7)。由图7可以看出,模拟结果与SMAP产品在空间分布的趋势上具有一致性。在春季和夏季,均体现出东南部、东北部土壤含水量较大,而西部和北部山区的土壤含水量较小的特征,这与刘荣华等[21]的研究结果基本一致。在夏季,两种数据的高值区均明显扩大,体现出河北省地表土壤含水量在季节上有较为明显的差异性,平原区夏季的土壤含水量高于春季节,这与该地区降水集中在夏季的气候特征相一致。同时,夏季作物需水较大,引入MPDI后,凸显了灌溉用水在夏季集中的特点。

图7 2018年河北省地表土壤含水量春季和夏季模拟均值与SMAP产品对比

图8 2018年河北省土壤含水量实测值与神经网络模拟值及SMAP产品对比
虽然在区域特征上,本文方法模拟结果与SMAP产品具有一致性,但在绝对值的差异上,本文的模拟结果比SMAP产品偏高。在华北平原部分站点的研究显示,SMAP产品的土壤含水量值与实测值在趋势上具有一致性,但明显偏低[22]。为此,将河北省土壤含水量的实测值与上述两种产品分别进行对比(图8),以进一步分析本文方法模拟结果的精度。因SMAP产品在无数据的网格使用了填充值,在对比分析未考虑这些位置的相关数据。从图8可以看出,本文方法模拟得到的土壤含水量与实测值的相关性较好、偏离度较小,3个评估指标分别为:r=0.59、ERMS=0.039 9 cm3/cm3、Bias=0.016;SMAP产品的相应数值为r=0.23,ERMS=0.066 5 cm3/cm3、Bias=-0.12。需指出的是,SMAP产品的空间分辨率为9 km,将实测值与其直接进行对比具有不确定性,系统论证本文土壤含水量产品的精度仍需用更多的土壤含水量实测数据、或与更多的遥感土壤含水量产品进行验证,相关工作将在后续研究中开展。
4 结 论
a. 在利用神经网络进行土壤含水量的模拟研究时,考虑能反映地表干湿状态的MPDI产品,能较好地丰富人类活动作用下的地表土壤含水量信息,模拟结果与实测数据具有较好的一致性。
b. 在土壤含水量的空间异质性方面,考虑MPDI指数作为神经网络模型的输入来对土壤含水量进行预测,同样取得了较好精度,可充分体现土壤含水量在空间上的分布情况。
c. 研究得到的土壤含水量产品与SMAP数据具有较好的空间一致性,但比SMAP产品偏高,后续仍需利用更多的实测数据、在更大的时空尺度上对本文方法的有效性进行检验。
猜你喜欢
中等数学(2022年5期)2022-08-29
成都信息工程大学学报(2021年5期)2021-12-30
环境保护与循环经济(2021年7期)2021-11-02
空间科学学报(2021年4期)2021-08-30
环境卫生工程(2021年1期)2021-03-19
哈尔滨轴承(2020年1期)2020-11-03
种子(2020年9期)2020-10-22
中等数学(2020年2期)2020-08-24
现代园艺(2020年7期)2020-04-22
中国奶牛(2019年10期)2019-10-28
