
一种面向移动端的浅层CNN表情识别
2021-04-29 04:49张东晓陈彦翔
集美大学学报(自然科学版) 2021年2期
张东晓,陈彦翔
(集美大学理学院,福建 厦门 361021)
0 引言
面部表情识别正受到越来越多的关注,涉及计算机视觉、机器学习和认知科学等领域[1],应用于医疗[2]、工业互联网[3]、人机交互[4]、娱乐[5]、虚拟现实[6]、餐饮[7]等方面。一个完整的情绪识别系统通常包括三个部分:人脸区域检测、面部情绪特征提取和使用分类器进行预测。人脸检测技术已经比较成熟,所以相关研究主要集中在后两个方面。传统的研究思路是构造人工特征,如基于降维算法来构建特征[8-10],基于眼睛、嘴巴、鼻子等部位构建几何特征[11-13],基于颜色变化构建纹理特征[14-16];然后采用传统机器学习算法进行分类,如支持向量机(support vector machine,SVM)[17-18]、K-近邻(K-nearest neighbor,KNN)[18]、随机森林[19]等。这些方法可以在特定数据库下取得良好的结果。但人工特征往往具有局限性,导致模型泛化能力不强,在现实任务中很容易受到光照、遮挡等情形的影响。
近几年深度学习在视觉领域取得优异成绩,在表情识别方面也涌现出很多研究成果,如卷积神经网络(convolutional neural networks,CNN)[20-22]、对抗神经网络[23-24]、成熟网络结构的迁移学习[25-26],以及其他深度网络[27-28]。也有学者尝试将经典方法与深度学习相结合。如夏添等[29]将眉毛、眼睛、鼻子和嘴巴等部位的特征点作为深度网络的输入,张发勇等[30]将深度网络获取的特征用到随机森林模型中,所得结果对视角都具有较强的鲁棒性。由于可以自动学习特征,这些方法均取得良好的效果。
目前公开报道的应用主要集中在PC端,但是近几年移动互联网的快速发展也催生了移动端的巨大需求。如:在线教育中,可以通过自动检测学生的表情变化,及时掌握学习情况;购物平台的智能客服可以通过用户表情及时调整对话策略。所有这些应用场景均有两个前提条件——计算资源消耗小和实时性。但是深度学习框架下的主流网络结构往往比较深,需要消耗大量计算资源。受算力限制,这些模型均无法直接移植到移动端。而经典提取特征的方法泛化能力有限,又不能满足移动端的应用需求。因此,本文设计了一个浅层神经网络,期望在确保模型识别率的前提下,能大幅降低运算量。
1 人脸表情数据集及识别模型
1.1 人脸表情数据集
伴随着表情识别研究的兴起,各国学者开始构建表情数据集。最早开始这项工作的是学者Lyons等[31],他们于1998年构建了一个日本女性表情数据集(The Japanese Female Facial Expression Database,JAFFE),包括高兴、悲伤、中性、厌恶、生气、害怕及惊讶7种不同的面部表情,共计213张图像。
目前应用较为广泛的数据集是构建于2010年的The Extended Cohn-Kanade Dataset(CK+)[32]。该数据集包含来自123个人的总计593张正面照,它还包括对应于面部表情的每张照片的标签及动作单元编码标签。与JAFFE相比,该数据集的样本数量更多,且多了一个“蔑视”表情。

表1 FER-2013各表情对应的标签及样本数量Tab.1 The label and amount of eachexpression in FER-2013标签Label数量Amount表情Expression04 593生气Angry1547厌恶Disgust25 121恐惧Fear38 989开心Happy46 077伤心Sad54 002惊讶Surprise66 198中性Neutral
另一个知名数据集是FER-2013[33]。该数据集是由Carrier等于2013年建立的公开数据集,数据主要来源于网络检索,总计35 887张灰度人脸图像,先后被发布在Kaggle和ICML2013等平台。其数据是已经裁剪好的人脸灰度图像,大小为48 px×48 px。表情种类与JAFFE一致,含有7种常见的面部表情:0-生气(angry);1-厌恶(disgust);2-恐惧(fear);3-开心(happy);4-伤心(sad);5-惊讶(surprise);6-中性(neutral)。每种表情的样本数量及对应的标签如表1所示。
国内也有学者开展这方面的工作,如吴丹等[34]建立了包括70个人的1 000段脸部表情视频数据库,为表情识别的深入研究做出贡献。对比这些数据集,FER-2013有较大规模的数据量,基本可以满足本文所提模型对样本量的需求,所以本文最终选择使用FER-2013数据集进行模型的训练。
1.2 表情识别模型
经典机器学习方法在表情识别方面存在泛化能力弱的问题,不能满足移动端需求。而深度学习方法在移动端又有计算资源的限制,所以本文将搭建一个浅层神经网络。
AlexNet[35]在ILSVRC2012的表现引起轰动,随后各种网络结构纷纷被提出,表现也越来越好。基本上沿着两个方向在前行:在纵向不断加深网络,在横向不断拓宽网络。在众多网络结构中,纵向加深的代表是VGGNet[36],该网络摒弃了AlexNet中5×5和7×7卷积核,改用堆积的3×3卷积核,在ILSVRC2014比赛中大放异彩,后续诸多研究表明VGGNet在特征提取方面相较于其他深度网络有明显优势,原因可能在于堆积的3×3卷积核具有较好的感受野。
更深层的网络具有更强的特征表达能力,其分类效果更好。但是深层网络结构的参数也随之大幅增加,这带来两个问题:需要更多的训练样本和大量的计算资源。考虑到公开的表情数据规模较小,且移动端算力有限,本文不直接使用深度网络,而是搭建一个如图1所示的浅层CNN模型。

在如图1所示的网络结构中,本文使用三组堆叠的卷积层来提取面部表情特征。堆叠的卷积层有助于增大感受野,便于更好地提取特征,这是提升识别率的关键。在三组卷积层中,卷积核大小均为3×3,第一组由3个卷积核数为32的卷积层组成,第二组由3个卷积核数为64的卷积层组成,第三组由2个卷积核数为128的卷积层和一个卷积核数为256的卷积层组成。这里每组的卷积核数量递增是受VGGNet启发,以期获得更丰富的特征。第一组和第二组之后均有尺寸为2×2的最大池化层,第三组的池化层在中间。每个卷积层之后都使用ReLU激活函数f(x)=max(x,0),即输入小于0时输出0,否则原样输出。为了加速训练,以及避免学习率过高导致不良影响,在每组卷积层和激活层之间插入了BN(batch normalization)层[37]。
公开报道的用于表情识别的卷积神经网络中,大多数在卷积层和输出层之间添加1个或者更多的全连接层,如文献[20-22]均采用这种策略。其背后的考量是将末端的每个特征层(最后的卷积层的输出)的每个像素均视作一个神经元。与此截然不同的另外一种方式是GAP(global average pooling),其思想源自文献[38],它将末端的每个特征层的平均值作为一个神经元。相对而言,GAP更符合卷积的工作机理。事实上,经过多次卷积和Pooling,最后提炼出来的均是高级特征,每个特征层中的像素应该高度相关。将像素单独作为神经元,会破坏它们之间的相关性。GAP策略正好可以避免这一问题,而且相比单像素策略,还能大幅节约参数。因此,本文选择GAP策略,即在第三组卷积后连接一个GAP。


Adam优化算法[40]可以高效地求解非凸优化问题,且内存占用少,被广泛应用到深度学习的模型训练中。本文采用该算法反向传播更新参数。
2 模型训练及评价
2.1 数据预处理

表2 数据集的分配Tab.2 Distribution of data sets标签Label数量Length用途UsageTraining28 709Train setPrivateTest3 589Test setPublicTest3 589Validation set
FER-2013数据集的每个样本包括“emotion”“pixels”和“usage”三个部分。其中:“emotion”是表情标签;“pixels”是图像数据;“usage”记录了对应样本的用途——用于训练的“Training”,用于训练过程中进行验证的“PrivateTest”和用于训练完成后测试模型的“PublicTest”。按照Usage记录将样本分为三个独立的部分,如表2所示。 从表1来看,FER-2013数据集各表情的样本分布不均衡,特别是“厌恶”的样本数只占其他类别数量的10%左右,这会严重影响该表情的识别效果。为此,本文先做样本均衡化处理。考虑到样本的特殊性,这里主要使用左右镜像、随机缩放、随机调整亮度、随机旋转等方式增加“厌恶”样本。
数据均衡化后,训练样本约3万个。为了增强模型的泛化能力,在训练过程中对样本进行随机增强。即,每读入一个批次的样本,先随机增强然后再输入到网络中进行参数更新。
2.2 训练平台及参数设置
Google Colab是Google公司的一个研究项目,旨在为开发者提供一个云端的深度神经网络训练平台。其向开发者提供型号为Tesla T4的GPU设备,约12 GB的临时RAM和约358 GB的临时存储空间。这样的配置可以满足前述模型训练需求,所以本文使用该平台进行训练。
众所周知,参数设置对模型训练至关重要。经过尝试,本文的参数设置为:最大池化层后接的Dropout比率为0.3,平均池化层后接的Dropout比率为0.4;每个批次的样本数为128,每轮训练次数取224,即训练样本总数28 709除以每批样本数128再取整;在验证集上每批样本数也为128;初始学习率设置为0.01,并对学习率进行动态下调,以保证模型收敛。训练过程中模型的准确率和损失的可视化结果如图2所示。
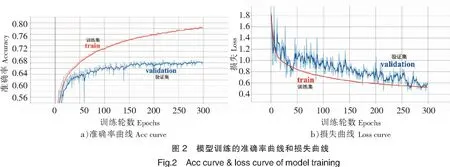
分析图2可知,训练集上的准确率随着训练轮数在增加,损失在减少,说明模型训练状况良好;验证集上的准确率和损失在经过300轮训练后均趋于平缓,说明此时模型的识别能力已经达到极限,故训练到300轮左右时得到最终的模型。
2.3 模型评价
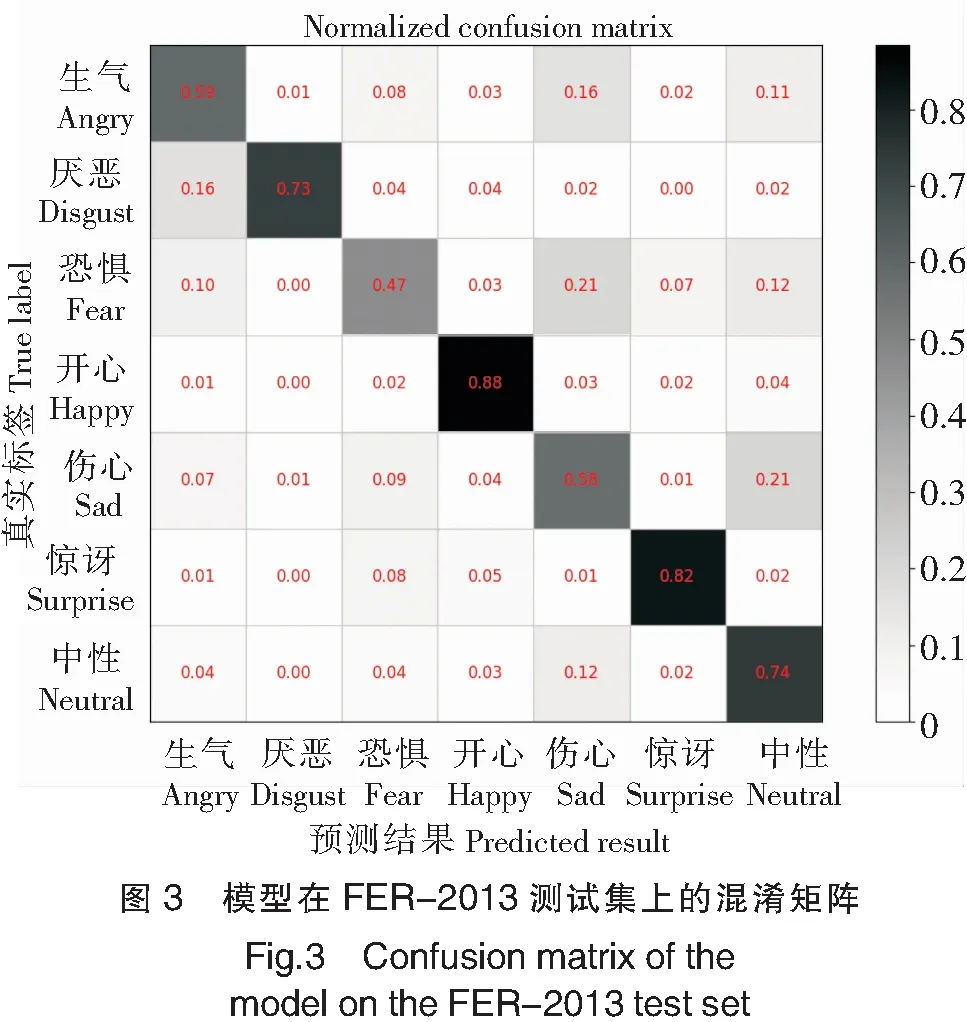
首先考虑模型在FER-2013测试集上的表现,为此绘制了如图3所示的混淆矩阵图,横轴为模型预测结果,纵轴是真实标签。图3是标准化的混淆矩阵(normalized confusion matrix),对角线的数值称为召回率,表示成功预测出该表情的样本量占该表情所有样本的比例,该值越接近1,对应的矩阵块颜色越深,模型对该表情的分类准确程度越高。从结果来看,该模型在“开心(happy)”和“惊讶(surprise)”这两类表情的分类准确程度最高,“厌恶(disgust)”和“中性(neutral)”次之,其余表情的准确程度较差。
为了探究“恐惧(fear)”“伤心(sad)”和“生气(angry)”表情召回率偏低的原因,进一步分析图3。从“恐惧(fear)”所在行可以看出,约21%的“恐惧(fear)”表情预测为“伤心(sad)”,约12%预测为“中性(neutral)”,约10%预测为“生气(angry)”,约7%预测为“惊讶(surprise)”,约3%预测为“开心(happy)”。从每种预测错误的表情中挑选2张,结果如图4所示。从图4来看,与这些样本的真实标签“恐惧(fear)”相比,预测的结果反倒更为合理。

这种情况在标注为“伤心(sad)”和“生气(angry)”的样本中也有出现。如图5所示,原本标注为“伤心(sad)”和“生气(angry)”的表情从图像上来看并不符合实际情况,而模型预测的结果却更贴近真实表情。通过查看预测有误的全部样本,得出结论:FER-2013测试集中关于“恐惧(fear)”“伤心(sad)”和“生气(angry)”的标注有较多错误。这也正是这三种表情召回率偏低的主要原因。

当衡量模型在每个类别上的性能时,可以考察每个类别的精确率P、召回率R、F1值,其计算公式为:
P=PT/(PT+PF),R=PT/(PT+NF),F1=2PR/(P+R)。
其中:针对某种表情,PT表示正确预测为该表情的样本(true positive)数;PF表示预测为该表情但不是该表情的样本(false positive)数;NF表示是该表情但预测为其他表情的样本(false negative)数;NT表示不是该表情且预测结果也不是该表情的样本(true negative)数。
当衡量模型在所有类别上的综合性能时,可以考察准确率A,A=(PT+NT)/N。其中,N为测试样本总数。
模型在FER-2013测试集上的各项指标如表3所示。
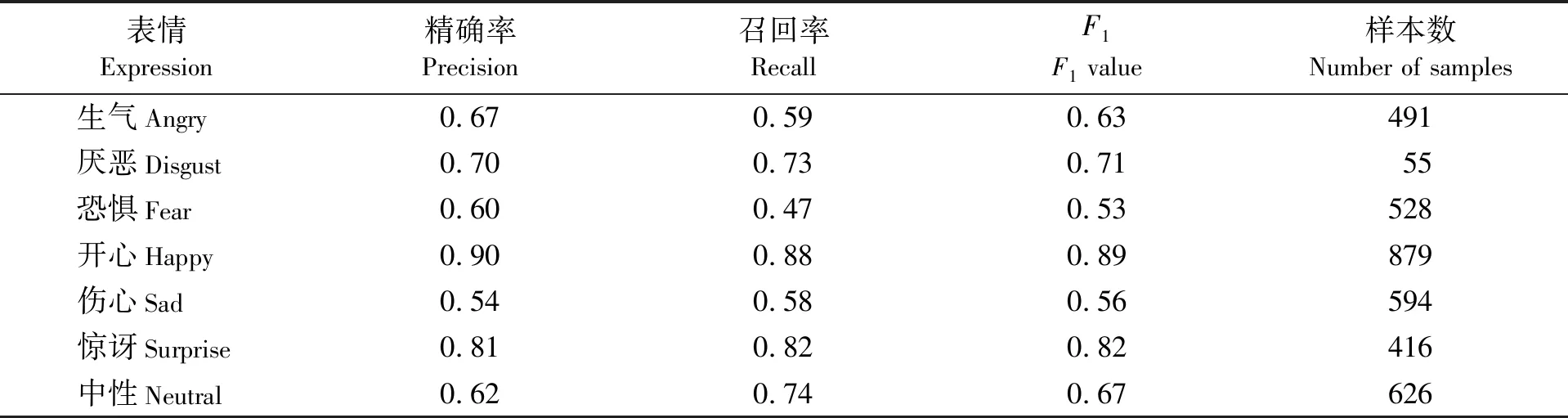
表3 模型在FER-2013测试集上的指标
各表情的精确率和召回率,基本相差不大,说明模型对各种表情没有明显的偏好。至于“恐惧(fear)”和“中性(neutral)”两种表情的数据相差超过10%,主要是如上所述标签不准所致。整体准确率为0.7,该值偏低的原因除了上述标签错误以外,还在于FER-2013数据集存在异常样本。这里分别从测试集和训练集中针对每个表情选取一个样本,结果如图6所示。其中,测试集的“厌恶(disgust)”表情没有发现异常样本。

异常的情况有“文字图像”“纯色图像”“图标图像”“少部分人脸”“人脸太小”“面具或者雕塑图像”等,这些异常样本对训练和测试均构成干扰。正如Goodfellow等[33]指出的那样:FER-2013数据集存在标注错误、样本异常等问题,人类的识别率约为65%±5%。本文所提模型已经达到人类识别率的上限,同时超越FER-2013面部表情识别挑战赛的亚军成绩:在FER-2013测试集上,并行卷积网络[20]、MobileNets+Softmax Loss[22]、挑战赛的亚军[33]、挑战赛的冠军[33],以及本文方法的准确率分别为0.66、0.69、0.69、0.71、0.70。
为了衡量模型的泛化能力,考虑模型在CK+数据集上的表现。CK+数据集与FER-2013数据集重合的表情有6种,所以这里只考虑这6种表情。为了公平起见,在CK+中随机抽取20%的样本,运行3次取各指标的平均值,准确率为0.76,其余各指标如表4所示。
结果表明,模型在“开心(happy)”和“惊讶(surprise)”上的泛化能力较强,而在其他表情上的泛化能力较弱。原因除了FER-2013样本异常以及标注问题以外,还有面部表情本身也具有歧义性,不同人的不同情绪导致的面部特征可能会大相径庭,例如:“生气(anger)”和“厌恶(disgust)”均可能包含“皱眉”和“抿嘴”等,多数情况下人眼都难以准确辨别。而精确率较高的“开心(happy)”和“惊讶(surprise)”则均含有比较突出的面部特征,如“咧嘴笑”、“嘴部呈O形”等。所以该模型的分类效果基本符合预期。

表4 模型在CK+测试集上的指标
为了排除数据集的影响,更为客观地评估模型的效果,冻结模型的卷积层,只在最后一层进行微调(fine tuning)。随机抽取CK+中80%的样本作为训练集,在剩余样本上测试,准确率为0.96,其余指标如表5所示。与表4对比,各项指标均大幅提升。

表5 模型微调后在CK+测试集上的指标
在186个测试样本中,8个样本预测错误。这些错误样本如图7所示。有3个标注为“生气(angry)”的样本预测为“厌恶(disgust)”,有1个标注为“厌恶(disgust)”的样本预测为“生气(angry)”。从图7上来看,预测为“厌恶(disgust)”的后两个和标注为“厌恶(disgust)”的样本基本没有区别,所以很难下定“预测错误”的结论;比较标注为“伤心(sad)”和“生气(angry)”的样本,特别是第1个与标注为“生气(angry)”的样本区分度也不是很大,难怪模型将其预测为“生气(angry)”;将“恐惧(fear)”表情预测为“惊讶(surprise)”的情形,似乎人眼也很难确定这个表情到底是哪一个。这也进一步验证了前文所述表情存在歧义性的事实。

3 移植到移动端
3.1 移动端开发环境及开发工具
本文主要针对iOS系统阐述开发流程。移动端移植的基础是Core ML,这是一个由Apple公司发布的机器学习框架,其提供了一系列可以将机器学习模型集成到iOS App中的工具。使用Xcode进行移动端程序的开发,编程语言选用Swift,使用Coremltools将训练所得的TensorFlow模型转换为Core ML格式的表情识别模型,用于后续的移动端开发。
3.2 移动端开发流程
步骤1:搭建平台。在Xcode开发平台,建立一个iOS工程项目,并创建一个“Single View App”(单视图应用),开发语言选择Swift。进入开发界面后,对主程序界面进行简单的排版,并添加启动页图片和App图标;在“Info.plist”文件中,添加“Privacy-Camera Usage Description”条目,为程序授予摄像头使用权限。
步骤2:人脸检测。Xcode中集成的CIDetector API是Core Image框架中所提供的一个识别器,可以进行包括对人脸、物体、文本等对象的识别。为了简化开发流程,本文直接使用CIDetector进行人脸检测。使用时需要实例化一个CIDetector对象,并将摄像头获取的图像数据传入到CIDetector中,若在图像中检测到人脸,则会返回人脸区域的位置信息,再根据位置信息,对人脸图像裁剪、预处理,为下一步做准备。
步骤3:表情识别。1)加载CIDetector人脸检测器和表情识别模型;2)在sessionPrepare函数中,创建摄像头会话,用于捕捉摄像头画面,捕捉到的画面将被输出到captureOutput函数中;3)重写viewDidLayoutSubviews函数和viewDidLoad函数,触发摄像头会话的捕获动作;4)在captureOutput函数中,将捕捉到的摄像头画面依次传入人脸检测器和表情识别模型,将检测到的人脸区域和表情识别结果输出到视频帧中;5)定义一个文本标签组件,用于实时显示预测结果。
3.3 移动端程序的运行效果
实时表情识别App顺利运行后,将自动开启前置摄像头,从摄像头中实时检测人脸区域,并将表情的预测结果显示在屏幕下方。在iPhone 8 Plus上能够流畅运行,效果截屏如图8所示。图8中,第一幅图是应用启动界面,其余图是程序运行结果。
本研究依次做了“中性(neutral)”“惊讶(surprise)”“开心(happy)”“生气(angry)”“伤心(sad)”“恐惧(fear)”和“厌恶(disgust)”7种表情,前面5种的识别结果与实际表情相符,后两种与实际表情不符。本意做的“恐惧(fear)”表情被识别为“伤心(sad)”,本意做的“厌恶(disgust)”表情被识别为“生气(angry)”。原因一方面是如前所述的模型对这两种表情的识别率偏低,另一方面这两个表情也确实具有歧义性,如果用人眼来判断,也可能将它们判定为“伤心(sad)”和“生气(angry)”。

4 结束语
为了满足移动端的应用需求,本文搭建了一个浅层卷积神经网络,网络结构为三组堆叠的卷积层外加一个全局平均池化层。基于FER-2013表情数据集,在Google Colab平台使用TensorFlow进行训练,在FER-2013测试集和CK+数据集上均取得不错的识别效果。使用Core ML将训练好的模型移植到iOS移动端,在iPhone 8 Plus上能够稳定、流畅地运行。FER-2013数据集上的实验结果表明该数据集存在异常样本和标注错误的情况,这在一定程度上影响了模型的性能,影响到移动端的识别效果。在CK+数据集上微调的测试结果表明,规范的数据集可以进一步大幅提升模型的性能,这也说明本文所提模型具有较好的特征提取能力。未来只要有更加规范的数据集,数量足够的各类样本,部署在移动端的应用就会有更好的识别效果,也能更好地应对复杂应用场景。
猜你喜欢
计算机研究与发展(2022年1期)2022-01-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
少儿美术·书法版(2021年9期)2021-10-20
计算机系统应用(2021年9期)2021-10-11
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
计算机应用(2020年12期)2020-12-31
电子制作(2019年11期)2019-07-04
文苑(2015年9期)2015-09-10
