
基于RGB-D图像的物体识别方法
2021-09-07 03:10王高平李林鹏王晓华景军锋张凯兵
西安工程大学学报 2021年4期
李 珣,王高平,李林鹏,王晓华,景军锋,张凯兵
(1.西安工程大学 电子信息学院,陕西 西安 710048;2.格罗宁根大学 伯努利实验室,格罗宁根 荷兰 9747 GA)
0 引 言
物体识别是机器视觉和机器人智能化研究的重要内容,目的是通过学习和训练使机器能够对外部环境进行感知并获得特征数据。经过几十年的研究,物体识别已经在交通、医疗、军事、机器人等诸多领域得到应用[1-2]。但是,通过二维RGB (Red通道、Green通道、Blue通道)图像进行物体识别的局限性逐渐显露:RGB图像成像过程的基础是光学投影,将空间中三维存在的物体映射到二维平面的这一过程造成了信息损失不可避免。与此同时,单纯使用RGB图像容易受到复杂的光照和背景变化干扰,识别率的提升已经呈现瓶颈。为了改善RGB图像的二维表达弊端,近年来结合深度D (Depth通道)图像的RGB-D物体识别方法研究成为提高物体识别准确率的新途径之一。
深度图像包含了物体的空间几何特征,具有光照不变性和颜色不变性,背景更容易分离等特点,可与RGB图像所包含的颜色与纹理信息进行样本数据的相互补充。2010年以来,采用新传感技术的RGB-D相机,如:PrimeSense、PMD CamCube以及微软的Kinect等,将同时采集高像素RGB图像和深度图像变为可能,加速了RGB-D图像识别技术的发展。2013年IJCV出版的专刊将RGB-D图像在人脸识别、三维场景重建、姿态估计、物体识别等领域的理论研究和实际应用成果进行了展示[3];2014年开始,国际顶级会议CVPR也因为RGB-D研究的广泛性专门增设了RGB-D传感器的专题研讨会[4]。2014—2021年,国际顶级会议和重要期刊上发表了大量的关于RGB-D图像的研究成果[5-7]。这些成果表明,融合RGB图像和深度图像后的物体识别效果获得了提升。
本文基于RGB-D图像的物体识别方法的最新研究进展,分别对公开的RGB-D对象数据集与场景数据集、先验知识的特征构建方法与特征学习方法以及不同融合策略特点等研究成果进行整理、归纳和分析,并对基于RGB-D的目标识别优化思路提出展望,希望能够为该方向研究提供参考和借鉴。
1 开放数据集和资源
数据样本的多寡对于基于图像算法的研究工作非常重要。公开的RGB-D数据集不仅为研究人员节省大量的时间和资源,而且能为不同算法的优劣比较提供平台[8]。目前,已公开的常用RGB-D数据集有:RGB-D object dataset、2D3D、JHUIT-50、NYU depth等。
1) RGB-D object dataset[9]。2011年由华盛顿大学的LAI等公开的一个大规模、多视图的数据集,是迄今为止使用最广泛的RGB-D对象数据集,几乎囊括了室内常见的各种物体。其采集过程使用Kinect以640×480像素拍摄,包含51个类别共300个实例的室内常见对象,共计25万张PNG格式的RGB-D图像以及对应的3D点云(PCD)文件。此外该数据集还提供了8个不同场景组成的场景数据集以及RGB-D视频序列。2014年作者对该数据集进行了扩展,增加了14个新场景,包括桌面、厨房和家具等对象。该数据集进一步促进了种类识别、3D场景标记和物体姿态估计等应用研究。
2) 2D3D 数据集[10]。2011年马克斯·普朗克协会的BROWATZKI等提供了2D3D数据集,其采集过程是使用PMD CamCube 2.0传感器在步进电机控制的转盘上绕垂直轴360°旋转拍摄,数据库包含18个类别共154个家庭和办公室环境常见对象,每个对象采集36组视图,共包含154×36=5 544个RGB-D图像。彩色视图分辨率为1 388×1 038像素,深度图像分辨率为204×204像素。2D3D数据集在RGB-D object dataset[9]上增加了额外的类别和实例,用于物体识别和分类。
3) JHUIT-50数据集[11]。该数据集在2016年由约翰霍普金斯大学的LI等人建立。使用PrimeSense Carmine 1.08传感器固定视角顺序采集RGB图像和深度图像,包含50个锤子、螺丝刀等车间工具的工业对象。所有的数据都是从杂乱的场景中分割出来,共包含14 698张RGB-D图像。JHUIT-50数据集中样本背景更加复杂,如图1所示。这种前景与背景相似的物体识别在视觉层面上的辨识难度更大,对识别算法的要求更具有挑战性。

图 1 JHUIT-50数据集Fig.1 JHUIT-50 dataset
4) NYU depth V1[12]和NYU depth V2[13]数据集。纽约大学Silberman等人提供的用于场景目标分割和分类的RGB-D数据集,拥有2个不同的版本。其中NYU Depth V1使用Kinect拍摄,包含7个类型的64种室内场景,共有108 617个未标记帧,2 347幅带标注的RGB-D图像。NYU Depth V2包含来自3个城市的26种场景类型的464个新场景,407 024个未标记帧以及1 449张带标注的RGB图像和深度图像,除原始深度图像外,数据集还提供了预处理后的深度图像。场景识别是典型的多分类问题,作为物体识别的扩展,更密集地记录了场景中的所有对象信息,NYU Depth数据集经常用来验证RGB-D物体识别算法的普适性和算法在更复杂条件下的实用性,部分示例如图2所示。

图 2 NYU Depth V1数据集Fig.2 NYU Depth V1 data set
除上述常用的数据集外,还有一些其他的RGB-D对象数据集,如Willow数据集[14]、BigBIRD数据集[15]等。表1给出了常用数据集详细的对比信息。此外,还有一些用于其他识别对象的RGB-D视觉数据集,如:3D人脸识别、人体姿态估计、手势识别及三维建模等[8]。

表1 现有RGB-D对象数据集对比
2 RGB-D物体识别模型
物体识别研究分为实例识别和类别识别。实例(如:咖啡杯)代表独特的对象,而类别(如:杯子)代表共享相似特征(例如:形状或结构)。提高物体识别准确率的关键在于提取的特征具有代表性、区别力。RGB图像和深度图像的结合,为物体识别提供了更多的物体特征。根据特征获取手段的差异,将当前的RGB-D图像识别算法分为基于先验知识的手工特征识别方法和基于特征学习的RGB-D物体识别方法等2类。
2.1 基于先验知识的手工特征识别方法
早期的RGB-D图像识别依靠先验知识进行目标特征的设定,包括尺度不变特征变换(SIFT)、加速稳健特征(SURF)、方向梯度直方图(HOG)等,通过手工设计多个特征描述符并矢量化组合在一起的方式,用于目标特征匹配[16]。
由于RGB-D图像记录的是同一物体的不同视图,数据之间具有明显的特征差异,因此,通常需要为RGB图像和深度图像设计不同的特征描述子[17]。LAI等使用SIFT、文本直方图(textons histograms)、颜色直方图(color histograms)生成RGB图像的颜色与纹理特征,将深度视图中物体周围边界框的宽度、深度和高度作为形状特征,使用旋转图像(spin images)生成固定长度特征向量,高斯核支持向量机(KSVM)作为分类器,该方法在华盛顿RGB-D数据集上的类别识别率为83.8%[9];BO等提出了一种核描述子的方法,将内核描述符的思想扩展到深度图和三维点云,使用5个深度核描述符将形状、尺寸和深度边缘特征等结合起来提高识别性能,在RGB-D数据集上的类别识别率和实例识别率分别为84.5%和86.2%。该方法克服了深度特征对独立视角的依赖,但是等距离采样影响局部特征的表达能力[18]。LAI等设计了一种稀疏距离度量(IDL)算法,对等距离采样影响局部特征的表达能力问题进行改进,为所有的特定对象的所有视图定义了一种距离度量,丢弃了冗余的数据,保证了快速分类。在RGB-D数据集上的实验结果显示,实例识别率达到了91.3%,有效地提高了分类性能[19]。骆键等在BO的基础上进行了改进,提出了核描述子编码的识别方法,将对象点云图等间隔划分为若干个子区域,选取每个子区域中深度值最大的点作为参考点,满足均匀采样的同时降低特征维度,对比RGB-D数据集上的实验结果,类别识别率提高了1.3%,实例识别率提高了6.5%[20]。BLUM等则采用卷积K均值描述符(CKM),通过无监督的方法自动提取兴趣点周围的局部特征[21]。LIU等对RGB视图和3D点云视图提取多组特征,连接为一个10维向量组合,输入线性SVM进行分类[22]。PAULK等从RGB颜色直方图中提取了9个基于颜色的特征,从深度图像的点云表示中提取几何属性和体素特征,分别对比了Adaboost、人工神经网络(artificial neural network,ANN )、SVM等不同分类器对算法的性能影响,其中SVM在速度和精度上取得了最佳的平衡[23]。表2为基于先验知识的手工特征识别RGB-D图像的特征提取与分类汇总。

表2 RGB-D图像的特征提取与分类方法
手工设计特征的方法主要依靠设计者的先验知识,通常需要针对不同的条件进行手动调整,不容易扩展到不同的数据集或其他模式,普适性较差,而且手工设计特征的过程中,有用信息的完备性难以保证,只能捕获对识别有用的线索子集,存在一定的局限性。
2.2 基于特征学习的RGB-D物体识别
RGB-D图像的物体识别同样也经历了从手工设计的描述符到基于语义描述特征集的特征学习发展过程[25]。相比特征学习,手工特征的方法通常只适用于中小型数据库,面对多源的海量数据时,端到端的特征学习体系结构已经超越了这种启发式方法,基于特征学习的RGB-D物体识别方法能够取得更好的识别性能,因此,也成为近年研究的主流方向。
2.2.1 深度图像的编码 以卷积神经网络为代表的深度学习算法凭借其高效的特征表达能力和模型拟合效果,已经在RGB图像的物体识别领域取得了巨大的成功[26]。与RGB图像识别相比,RGB-D图像的多模态数据在使用深度学习网络的训练过程中还需要考虑其他因素,如噪声和训练数据的不同[25]。由于深度学习的训练依赖于大量的样本,不均衡样本会造成模型泛化能力差并且容易发生过拟合[27]。当前最大的RGB-D数据集[9],相比于ImageNet数据库中上千万张带注释的图像,存在明显的数据匮乏问题。
面对上述问题,传统的解决方案是通过数据增强来扩充样本空间,增加样本的多样性,如裁剪缩放增强[28]、样本插值SMOTE[29]、Mixup[30]等。ZHOU等采用了一种与类无关的数据增强方法来扩展训练数据集,从不同的训练样本中抽取N个大小为K×K像素的图像块,形成初始训练集X={x1,x2,…,xN},采样区域位于像素值梯度变化较大的区域。具体转换过程表示为T={t,s,r,c},其中t为采样块的垂直和水平平移,s为比例因子,r为采集该样本时在工作台上的旋转角度,c为补丁块从RGB颜色空间到HSV空间的转换[31]。
数据增强的方式虽然起到了一定的效果,但是RGB-D数据集中的样本大部分来自于同一物体的不同角度,包含许多高度相似性的图像特征,简单的数据增强并不能解决深层网络训练的过拟合问题。因此,对深度图像进行有效的编码,将单通道深度图像编码为与RGB图像兼容的三通道表示,利用迁移学习的方法微调CNN的参数,利用学习到的滤波器进行训练,是解决数据匮乏的一个有效方法[32]。其中微调过程是为了对权重和偏置进行调整,以便最终的网络更适合目标数据集[33]。深度图像特征编码方法主要有以下几种:
1) Surface Normals编码。深度图像的边缘特征表现在:目标与背景之间深度值存在明显的梯度下降,表面轮廓信息比RGB图像更加明显,因此,BO等[34]借助这一特征通过计算表面法线对深度图像进行编码,使用递归中值滤波器重建缺失的深度值,计算深度图像的每个像素值的表面法线,将得到的表面法线归一化为单位向量,映射到0~255的整数范围,每个维度分别对应于R、G、B三通道。AAKERBERG等为进一步减小图像噪声影响,加入了双边滤波器对表面法线编码进行改进,该编码方法保留了更多边缘特征和细节信息[35]。
2) HHA编码。HHA编码[36]最早用于RGB-D图像检测与分割,经编码后的图像比原始深度图像的三维表达能力更高,该编码方法已经扩展到其他的RGB-D视觉领域。HHA编码通过计算深度图像的水平视差、离地高度以及表面法线与重力方向的夹角,将深度图像转换为与RGB图像兼容的三通道,所有通道被线性缩放到0~255的范围之间。HHA编码生成了与RGB图像相匹配的特征结构,缺点是只注重各个通道的独立成分,计算相对复杂。
3) Colorization编码。受到灰度照片彩色化[37]的启发,SCHWARZ等提出了深度图像彩色化的编码方法。首先建立一个局部参考模型,对目标进行前景与背景的分割,并使用递归中值滤波器填充缺失的深度值,根据渲染网格顶点到对象中心的距离,依次使用Green、Red、Blue、Yellow 4种颜色对深度值进行像素匹配,将深度图像可视化编码为彩色图像。此外,作者还发现简单的深度着色方法比更复杂的预处理技术更有利于深度图像的特征描述[38]。
4) Colorjet编码。EITEL等提出了另外一种简单有效深度图像彩色化编码方法。首先将图像的深度值归一化到0~255之间,对于深度图像中的每个像素点,根据距离的远近依次被编码为红、绿、蓝三通道,最高值映射到红色通道,最低值映射到蓝色通道来进行着色[32]。与之前的深度图像编码方法相比,Colorjet编码利用了全部的RGB光谱,不依赖于复杂的公式计算就能够获得良好的识别准确率。
5) (DE)2CO编码。区别于其他设定特征的编码方法,CARLUCCI等利用卷积神经网络来学习如何将深度数据映射到三通道图像,提出了一个端到端的,基于残差学习的深度图像编码网络结构,对于输入分辨率为228×228的深度图像,通过卷积和池化缩小到64×57×57分辨率。网络共包含8个Residual Block,其中每个Residual Block包含2次卷积、对应的批量归一化层以及非线性Leaky Relu激活层,如图3所示[39]。最后的Residual Block输出3个特征卷积以形成三通道图像输出,通过反卷积(上采样)层将图像分辨率恢复到228×228。

图 3 深度图像的(DE)2CO编码方法Fig.3 The (DE)2CO coding method for depth image
利用通道编码方法,将图像的深度单通道扩张为三通道,从而可以与图像的RGB三通道进行更好的特征融合,再通过卷积提取深层特征。
2.2.2 基于特征学习的RGB-D物体识别 模型特征学习通过一定的规则对原始数据中的特征维度进行变换组合、抽象,是模型自动学习的过程[40]。BAI等将RGB图像和深度图像分为若干个子集,训练了2个稀疏编码器分别从RGB图像和深度图像中提取特征,最后使用Softmax分类器进行分类。BO等提出了无监督学习的分层匹配追踪算法(HMP),使用正交匹配追踪和空间金字塔池化来构建多层特征,联合RGB图像和灰度图像、深度图像和深度表面法线,学习分层特征表示[34]。SUN等提出了一种主成分分析(PCA)和典型相关性分析(CCA)的网络模型,构建了2层的级联滤波器。网络第1层是使用主成分分析滤波器分别学习RGB图像和深度图像的特征,网络第2层构建典型相关性分析滤波器学习2种模态的融合信息[42]。殷云华等提出了一种CNN与极限学习机(ELM)的混合模型。首先通过1个卷积层和池化层提取RGB图像和深度图像的低阶特征,在共享层合并2种模态的特征,然后自编码极限学习获取高层次的RGB-D特征[43]。该模型结合了CNN的底层特征平移不变性与ELM的高效性,在保持良好精度的同时提高了识别效率。SOCHER等提出了一种卷积神经网络和递归神经神经网络相结合的深度学习模型(CNN-RNN),采用单层的CNN网络分别从原始数据中学习RGB特征和深度特征,结合树形的递归神经网络抽象出高层次特征,如图4所示[44]。此外,作者还证明了随机权重的RNN也可以生成高效的特征表示。

图 4 卷积递归神经网络的RGB-D图像识别模型Fig.4 RGB-D image recognition model based on convolutional recursive neural network
卷积层中滤波器大小为dp,对输入尺寸为dI×dI的输入图像进行卷积后,得到维度为dI-dp+1的K个滤波器矩阵,池化层对大小为dl的区域均值池化,步长为s,输出宽度和高度为r=(dI-dl)/s+l1的特征响应,RGB图像和深度图像的参数设置保持一致,每个CNN层的输出为X,X为K×r×r的3D特征矩阵。
图像的特征矩阵X∈RK×r×r为递归神经网络的输入,定义多个相邻列向量组成方形块,合并为1个父向量表示为P∈RK,构建固定树递归神经网络。当X∈RK×4×4时,构建的3层树结构为X∈RK×4×4→X∈RK×2×2→X∈RK×1×1。如果方形块的大小为K×b×b,则每个方形块中包含b2个向量,此时父向量表示为
(1)
式中:参数矩阵W∈RK×b2×K;f为非线性函数,忽略偏置项。每个RNN都会输出1个K维向量,在网络前向传播之后,N+K维向量连接起来输入Softmax分类器进行分类。该方法证明了卷积递归神经网络对于深度图像特征提取的有效性,为提高RGB-D图像识别准确率提供了一种可借鉴的模型[41,45]。随后,骆键等在其基础上提出了多尺度卷积递归神经网络的学习模型,使用更多的模态特征来提高准确率,将RGB图像和深度图像分别转化为灰度图像与3D表面法线图,分别从RGB图像、灰度图像、深度图像、3D表面法线图中获取更多模态的特征[46]。
随着GPU运算能力的提升,更加复杂和性能优越的网络模型被提出,深度学习网络在特征提取方面占据明显的优势[47]。SCHWARZ等提出了迁移学习的RGB-D图像识别方法,网络模型如图5所示[38]。文献[48]在Caffe框架上使用预训练的卷积神经网络模型进行特征提取,网络中最后2个全连接层(fc7和fc8)的特征排列起来后使用线性SVM进行分类,在华盛顿RGB-D数据集上类别识别准确率达到89.4%,实例识别准确率达到94.1%,显著提高了RGB-D图像的分类效果。
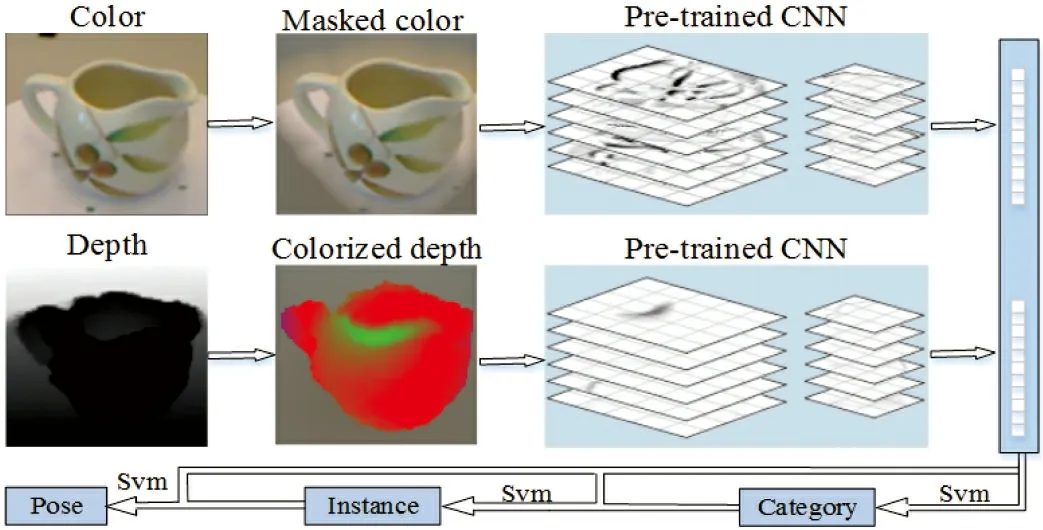
图 5 RGB-D物体识别网络模型Fig.5 RGB-D object recognition network model
继SCHWARZ等[38]的工作后,许多深层卷积神经网络及其衍生网络模型相继被提出。EITEl等使用5个卷积层和3个全连接层的双流卷积神经网络模型,微调了网络参数对2种模态的数据进行训练,选择全连接层(fc8)融合的方法生成RGB-D的融合特征,在迁移学习的RGB-D图像识别方法的基础上类别识别准确率提高了1.9%[32]。AAKERBERG等的研究重点是深度图像的编码方案,改进了表面法线的编码方式,并将网络深度提升到了16层[35]。ZAKI等通过2个相同参数设置的CNN网络,每层卷积提取的RGB特征和深度特征合并为1个向量组,生成多样化的特征组合[49]。RAHMAN等使用colorjet和surface 2种编码方法表示深度图像,区别是作者使用2种不同的网络结构学习多模态特征,更深层次的GoogLeNet训练RGB图像,并分别微调CaffeNet网络的参数来训练2种编码图像,并在网络顶层融合3种特征进行分类[50]。上述几种方法利用多个卷积层提取RGB图像和深度图像的语义特征进行分类,是一种简单有效的识别方法。
ZAKI等[25]认为卷积层包含的特征对于某些类别同样重要,创建卷积层提取的RGB特征和深度特征的超立方体金字塔,结合超立方体金字塔特征与全连接神经元的激活层。对于每个卷积层l(i)={l(1),…,l(l)},节点处激活的特征映射表示为
(2)
式中:σ为RELU非线性激活函数;w、h、c分别为滤波器k的大小;i和j为特征的维度;b为偏置项;每个卷积层中特征图的数目为n(l)={64,256,256,256,256},共计1 088个特征图。将RGB图像、深度图像、点云图像分别转换为超立方体金字塔表示,使用双线性插值将所有卷积层中空间维度为i和j的特征图分别子采样:p(1)=m×m,p(2)=2m×2m,p(3)=0.5m×0.5m,在多尺度下获得卷积层的独立特征。每个超立方体金字塔表示为
(3)
为降低特征维度,对生成的特征进行空间金字塔全局最大池化,计算区域内特征映射的最大分量。2组特征合并后使用极限学习机进行分类,该方法有效提高了识别结果,缺点是过多的数据融合容易带来冗余信息。
2.3 多模态融合
基于深度学习的多模态任务一直都是人工智能领域的研究热点,如:多模态医学图像融合[51]、情感分析[52]、人机交互[53]等。多模态任务旨在联合不同类型的特征对多源数据进行综合建模,实现跨模态数据之间的信息互补,共同完成1个任务,如回归预测或者分类判断。但是不同模态之间的数据存在异构性,其特征向量位于不同的向量子空间,数据从一种模式到另一种模式之间的映射关系具有不定性。因此,如何利用不同模态的互补性来表示、融合多模式数据一直都是多模态任务的核心[54]问题。RGB-D物体识别是典型的多模态任务,即通过融合同一目标的RGB视图和深度视图进行分类。依据融合策略的不同,RGB-D图像的特征融合方法大致分为决策层的加权融合与特征层的早期融合2类。
1) 决策层的加权融合。决策层融合(Decision-level fusion)解决了RGB视图与深度视图数据之间的不一致性,对2种模态提取的特征分别训练分类器,融合分类器输出的结果预测对象类别的标签[55]。决策层融合的一般形式如图6所示。

图 6 决策层融合Fig.6 Decision-level fusion
RAMIREZ等认为2种视图的模态通常是不相关的,每种模态的代表性分类特征也是独立的,使用决策层融合可以保留2种不同视图特征的完整性[56]。CHENG 等使用CNN和费舍尔核的混合网络,训练2个线性SVM对2种视图分别进行分类,分类结果的加权平均值作为最终的预测标签[57]。YIN等使用2个ELM分别计算RGB图像和深度图像的分类结果并进行加权融合[58]。ZENG等采用基于证据理论的决策融合方法对2种分类结果进行融合,证据理论的决策融合方法利用质量函数考虑不同决策对不同类别的影响,能够给出更准确的识别结果[59]。QI等在研究ImVoteNet中,首先利用RGB图像的丰富纹理和色彩信息预测物体的中心和类别,在物体的中心线上,再融合图像的深度信息预测物体的长宽高和类别信息[60]。该方法既充分利用了RGB图像和深度图像信息,又减少了计算量。
2) 特征层的早期融合。区别于决策层融合,特征层融合(Feature-level fusion)是指在特征提取阶段将2种模态的特征投影到共享语义子空间层,分类器对融合后的特征进行分类,特征层融合的一般形式如图7所示。
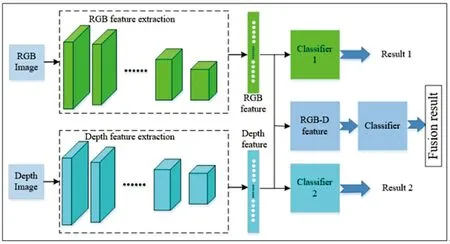
图 7 特征层融合Fig.7 Feature-level fusion
特征层融合的优点是可以更好地捕捉不同模态之间的关系,最常用的特征层融合为全连接层融合[32,35, 38-39],其特点是通过2个深度学习网络对RGB图像和深度图像进行卷积降采样,在已有网络层基础上增加1个全连接层,合并2种模态的深层语义特征,经分类器进行分类。在全连接层的融合方式中,普遍认为较深层次所包含的语义特征更具有代表性,从而可以拟合更加复杂的多模态数据[59]。QI等提出简单的组合特征会产生不确定的表示,作者在卷积层和全连接层之间构造了一个损失函数,把2种单模态特征和融合特征连接起来进行分类[60]。WANG等针对不同的数据集或者不同的模型,提出最佳融合层往往是不定的,全连接层融合的前提是假设该层特征代表2种模态融合的最佳抽象表示[61]。作者对比了AlexNet上不同卷积层提取的特征的融合结果,发现第4层的激活值更适合作为融合特征进行分类。CAGLAYAN等将多个卷积层提取的特征进行合并学习二次特征,利用不同层的信息来产生更好的识别性能[45]。ZAKI等将超立方体金字塔特征与全连接神经元的激活相结合,将RGB图像、深度图像和3D点云图像3种特征进行融合[25]。
WANG等使用双流卷积神经网络学习2个映射矩阵,将特征分解为关联特征和个体特征2部分,在最后一个average-pooling层将原始特征映射到关联特征空间和个体特征空间,确保融合部分和独立特征的辨别能力和正交性。网络的最后一层如图8所示[61]。

图 8 关联特征与个体特征的融合Fig.8 The fusion of correlation characteristicsand individual characteristics
在图8的最后一层网络中,Vi和Qi分别表示将原始特征映射到关联空间和个体空间,关联特征和个体特征融合为一个新的特征向量,不同类别的特征向量被赋予不同的权重Ci,来判别最终的识别结果。
RGB-D图像的2种融合方式各有其优劣性,其对应的算法模型见表3。
决策层融合的优点是融合方式简单,更好地消除相同类型对象之间的歧义。但过于注重独立性可能会遗漏关键的跨模态交互,并迫使单模态决策脱离完整的多模态环境。特征层融合的方式相对复杂多变,可以更好地利用不同模态数据之间的联系,解决各模态数据间的不一致性。从已有的研究来看,针对RGB-D图像识别任务,特征层融合的方式表现优于决策层融合,原因是RGB特征和深度图像的融合过程为模型决策提供了更完整的信息。多模态融合方式是一个开放性的问题,上述2种融合策略下的具体实现过程依然是可以探索研究的方向。
3 实验对比与统计分析
近几年来,基于深度学习的RGB-D物体识别方法已经成为主流,表4~5分别给出了不同方法在华盛顿RGB-D object data set、2D3D数据集和JHUIT-50数据集上的实验结果。

表4 不同方法在华盛顿RGB-D object data set等数据集的实验结果对比

续表 4 不同方法在华盛顿RGB-D object data set等数据集的实验结果对比

表5 不同方法在不同数据集的实验结果对比
从表4~5可以看出,RGB-D图像的识别结果明显高于单独模态的识别结果,因为同一目标的RGB-D视图包含了更多的信息,虽然RGB和深度是具有显著差异的模态,但是它们也有足够的相似性(边缘、梯度、形状),在一定程度上具有潜在互补关系[39]。自特征学习方法成为RGB-D物体识别的主流算法以来,尤其是以卷积神经网络为代表的深度学习算法的广泛应用,RGB-D图像的识别准确率有了质的提升,在大规模的华盛顿RGB-D数据集上,深度学习的算法较传统手工特征方法类别识别的准确率提高了约11%。手工法的特征选择可能会降低模型的预测能力,因为遗弃的特征中可能包含了有效的信息,舍弃的这部分信息一定程度上会降低模型的性能,但这也意味着计算复杂度和模型性能之间的取舍。深层卷积神经网络具有强大的学习能力,在对于不同模态特征的抽象变换过程中,CNN的局部激活特征会产生相同级别的语义信息,可扩展性及非线性表达能力更强,但同时依赖于硬件的解算能力,所需的训练时间普遍更长。因此,如何构建出轻量级的深度学习模型来融合RGB图像和深度图像,在提高识别的准确率同时降低其复杂度,是多模态RGB-D物体识别当前需要解决的主要问题。
4 总结与展望
对同一物体获得越多的信息,就能更加容易从不同维度找出不同物体的差异性,进而实现更准确的目标识别。RGB-D图像提供了物体在现实环境中更完整的信息,更加接近人眼视觉,物体识别从单独的RGB图像到多模态RGB-D图像的扩展,提升了真实世界三维目标识别的准确率。现有RGB-D图像识别的研究已经取得了很多有价值的成果,识别的准确率和鲁棒性相较于单模态RGB图像有了大幅度提高。但同时,RGB-D图像的多模态识别研究还存在许多相关问题亟待解决。
1) RGB图像和深度图像是2种不同的数据,除了底层视觉上具有一定的相似性外,模态的交互过程中特征描述和语义理解上存在较大差异。由于它们是隐式的,不容易被控制,因此如何跨越特征之间的异构鸿沟和语义鸿沟是一个开放性的研究点。
2) 数据缺乏的问题是RGB-D物体识别以及其他多模态任务普遍面临的问题,已有数据集中的对象普遍包含所选实例的不同角度,同一实例的高度相似性使得神经网络的过拟合尤为严重,这种数据缺乏的问题制约了RGB-D图像的相关研究。因此,需要建立一个样本丰富的大规模数据库,但是由于多模态数据的获取困难以及人工数据标注的成本高,可以应用一些半监督、弱监督、无监督方法来研究。
3) 深度学习网络能够为机器提供强大的逻辑推理能力和复杂任务的抽象建模能力,适应性更强,但RGB图像和深度图像的多模态深层架构更加复杂,RGB图像与深度图像的融合会产生更多的参数,需要大量的时间和计算资源以及性能较高的GPU。因此,如何降低模型的复杂度,设计出更优的普适性轻量级模型是RGB-D物体识别从理论到实际应用需要跨越的重要门槛。
4) 特征融合为协同RGB图像和深度图像2种模态提供了桥梁,多模态融合的方法研究将是重要的方向,不单单局限于RGB-D物体识别领域。多模态的融合过程中对每种数据的语义完整性要求较高,数据的不完整或者错误在融合的过程中会被放大。除了学习到的互补信息以外,如何避免多模态数据融合过程中的冗余信息也是一个待解决的问题。
5) 深度图像具有光照不变、形态不变等独有的优点,融合深度图像的多模态研究受到了越来越多的关注。但是长期以来深度图像信息缺失和噪声问题仍然没有得到很好的解决。当前的深度图像编码方法各有优缺点,但是通常情况下都是根据不同的任务所设定的,需要探索更好的深度图像编码方法。
5 结 语
RGB-D数据提供了丰富的多模态信息来描述对象,使得机器与现实世界的交互方式朝着更智能化的方向发展。本文详细地总结了近年来RGB-D物体识别领域的最新研究成果。首先介绍了公开可用的RGB-D对象数据集,对提出的相关研究方法进行了总结归纳,对深度图像的编码方式和多模态特征融合进行了详细的分析和论述。认为特征层的早期融合可以利用不同视图之间潜在的互补关系,识别率和鲁棒性更好。特征学习的方法克服了传统方法需要手工调整参数的缺陷,从原始数据中学习通用的特征表示,普适性更强,但同时需要消耗更长的训练时间,基于深度学习的RGB-D物体识别算法在模型复杂度和计算效率上有待进一步优化。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
试题与研究·中考数学(2016年4期)2017-03-28
