
融合隐式信任与层次社区发现的协同过滤推荐算法
2022-02-16 07:10郭磊吴清寿
武夷学院学报 2022年12期
郭磊,吴清寿
(1.武夷学院 数学与计算机学院 福建 武夷山 354300;2.福建省茶产业大数据应用与智能化重点实验室,福建 武夷山 354300)
在信息爆炸的时代,网络上数据爆炸式增长,导致用户难以发现自己感兴趣的内容,这就是信息过载问题,推荐系统被认为是解决信息过载的一种有效方法[1-2]。推荐算法根据策略可以分为基于内容的推荐算法、基于协同过滤推荐算法和基于混合式推荐算法。而基于协同过滤的方法[3]由于其有效性与可扩展性得到广泛应用[4]。但随着数据量的增加以及数据的多样性,推荐系统长期面临数据稀疏问题,缓解此类问题通常是采用的方法是在通过使用用户与物品之间的内容信息,如社交网络信息、时间信息、位置信息等来构建混合式推荐算法,提高推荐精度[5]。同时,传统推荐算法面对海量数据效率较差,于是一些基于聚类的算法被提出,如K 均值聚类、模糊C 均值方法与自组织映射聚类[6-7],这些方法不但可以缓解数据稀疏性,还可以以改善推荐系统的可扩展性。
社交网络信息比其他辅助信息更能挖掘潜在的用户价值,因此大量基于社交网络的算法被提出[8-11]。常用方法是采用信任评估模型对用户间的直接信任关系进行计算,用于改善推荐精度,如基于信任总体的RSTE[12],基于信任传播的Social MF 等[13],均取得一定成效。随后研究人员开始研究间接信任关系,如Yuan 等用评分兴趣相似度作为隐式信任关系进行推荐[14],Azadjalal 等提出融合帕累托和置信度的信任推荐算法[15],但以上算法均没有考虑不对称信任的问题,且此类算法面向大数据集时推荐效果不佳。
为解决大数据量下推荐精度和效率提升的问题,基于聚类的推荐算法被提出,如K 均值聚类,模糊C均值方法等[16]。Koohi 等将模糊C-means 聚类方法应用到推荐算法中,根据用户所属类别,搜索与用户隶属程度高的邻居用户,从而形成兴趣最为相似的用户社区[17]。Ahmadian 等提出一种基于自适应邻居选择机制的社会推荐算法ARANS[18]。Li 等将重叠社区发现与推荐算法结合,计算用户之间的相识度和用户与社区的相关度,使用间接社交关系提升推荐效果[19]。Jianrui Chen 等提出一种基于用户相关性和进化聚类的推荐算法UCEC&CF[20],可以提高算法效率与评分预测准确性。但以上算法针对单个用户进行处理,提出的方法虽然能缓解一定的数据稀疏性,但对推荐性能提升有限。
提出一种融合社区结构与用户隐含信任度的协同过滤推荐算法(CSIT-CF)。算法首先采用基于信任矩阵挖掘用户做为信任与被信任的非对称关系,计算用户隐含信任度,并结合隐含信任度进行用户社区发现,最后在社区内计算目标用户对项目的预测评分并形成推荐。算法在保持一定推荐效率的同时,缓解传统协同过滤算法数据稀疏性问题,提升推荐精度。
1 用户隐含信任度计算
将信任关系引入推荐系统,能够显著提高推荐效果。在信任网络中,每个用户均有信任与被信任两种角色,担任不同角色的评分不尽相同,因此在进行信任计算时,同时考虑两种角色的情况更加合理。为更好的挖掘信任矩阵中的隐含的信任关系,提出一种融合信任与被信任的非对称隐含信任度计算方法。
首先对信任矩阵T 采用概率矩阵分解的方法进行分解,假设T 由信任矩阵Rzk×n与被信任矩阵Rpk×n正态分布生成,则其条件概率分布表示为:

后验概率分布为:
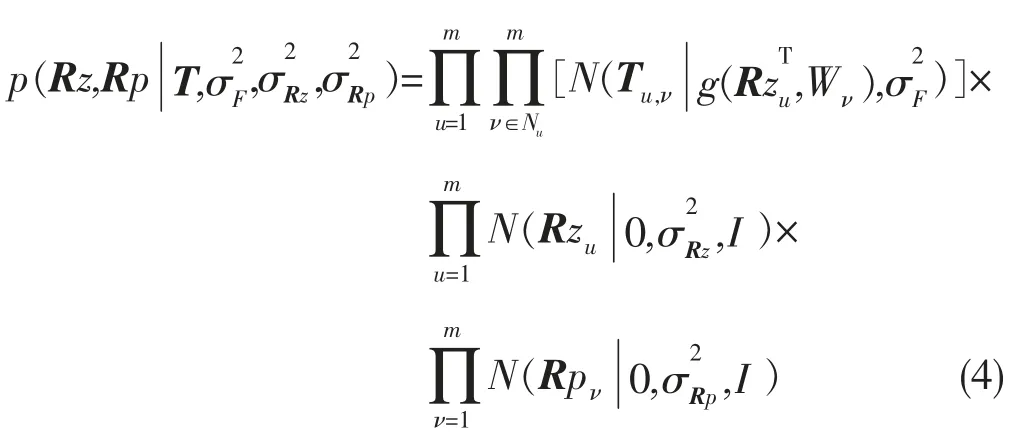
损失函数如下:

对损失函数使用梯度下降法可求得Rz 和Rp。根据所得的两个向量,可计算两用户之间的信任相似度与被信任相似度,采用皮尔逊相关系数来计算其相似度。两用户的信任相似度计算公式为:

将以上两种相似度按照一定比例加和可得用户隐含信任度。使用权值α∈(0,1)来调整二者比例,具体计算如公式(8)所示:
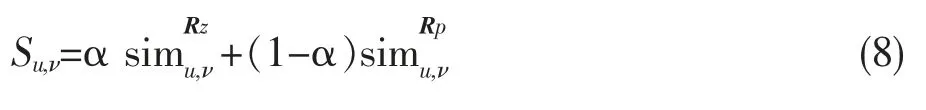
2 社区发现
用户的偏好受到其好友的直接或者间接影响,采用社区发现算法将用户根据其社交网络结构进行划分,即能更准确反应用户间的影响力关系,又能提升在大数据量背景上的推荐效率。
采用的社区发现算法的主要思想:根据节点的重要性选择核心节点,将核心节点与其邻居节点组织为朋友圈。判断朋友圈的独立性,若存在不满足独立性的朋友圈,根据朋友圈相似度将其合并到最相似的相邻朋友圈,下面对相关定义及算法进行描述。
2.1 核心节点发现与朋友圈识别
定义1 节点影响力。用LeaderRank 算法[21-23]计算节点的lr 值,节点νi对应的lr 值表示节点在网络中的影响力,记为lri.
将节点按照lr 值非升序排列,用VLR 表示已排序节点结合:
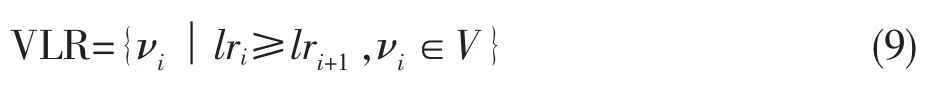
其中:V 是网络G 中节点集合。
定义2 νi的邻居节点记为N(i)={νj│i↔j},νi邻域记为Nh(i)=N(i)∪νi。
定义3 朋友圈核心节点选择规则。初始时,从VLR 中选择第一个节点为核心节点,记为core。用core 构建朋友圈,并将该朋友圈所有节点从VLR 中删除;从剩余节点中选择第一个节点为下一个core,继续构建朋友圈。重复以上过程,直到VLR 为空。以上每次选择的节点core 称为朋友圈核心节点。
定义4 核心节点与邻居节点的相似度记为Seccore,x,定义为:

定义5 朋友圈由core 与N(core)构成。对于νx∈N(core),若Seccore,x≥α,将νx加入core 所在的朋友圈,朋友圈定义为:
Fr(core)={x | x∈N(core) ∧Seccore,x≥α }∪core (11)
定义6 相邻朋友圈。对于∀νy∈N(core),若νy∉Fr(core),则νy所属的朋友圈称为Fr(core)的相邻朋友圈,记为NFk。NFk集合记为NFr(core)。
根据上述思路,得到朋友圈识别算法如下:

ConsFr 算法中,第3 行将VLR 中的第一个节点设置为核心节点,第7~10 行对core 的邻居节点进行判断,将满足的节点加入core 所在的朋友圈,并将其从VLR 中删除。重复上述过程,最终得到朋友圈核心节点集合Lcore 和对应的朋友圈Fr。
2.2 层次社区构建
朋友圈是用于构建层次聚类树(hierarchical clustering tree,HCT)的基础单元[25-26]。构建HCT 需要判断朋友圈的独立性,若一个朋友圈满足独立性条件,则该朋友圈将作为HCT 的根节点,否则,将该朋友圈链接到相似度最大的HCT 中。因为候选核心节点按照lr值非升序排列,一般情况下,其对应的朋友圈包含的节点数量总体上也呈现出按大到小排列的趋势,且排名靠前的朋友圈满足独立性的概率更大。按照朋友圈形成的顺序构建HCT,能更快的找到具备独立性的根节点,有利于后续HCT 的构建。

若Idpcore>β,表示该朋友圈满足独立性要求,可作为HCT 的根节点,否则将其链接到最相似的HCT 或者其他朋友圈。因为朋友圈之间不存在共同节点,需要通过朋友圈之间边的相关性判断朋友圈的相似度。对于满足i↔j 的节点,若νj∈Fr(core)并且νi∉Fr(core),将νi称为朋友圈邻居节点。
定义8 朋友圈连接强度。朋友圈连接强度定义为:
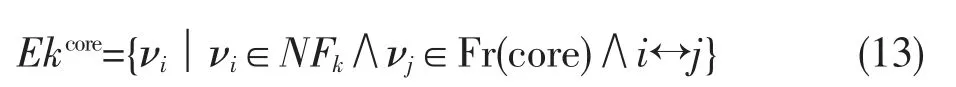
朋友圈连接强度统计Fr(core)邻居节点归属于相邻朋友圈的情况。
定义9 朋友圈相似度用于衡量NFr (core) 中与Fr(core)最相似的朋友圈,定义如式(14):
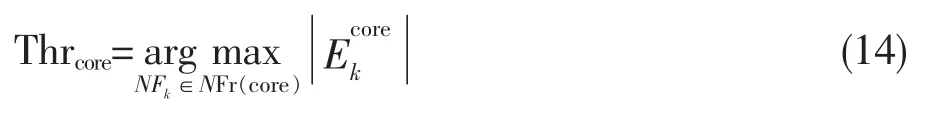
Thrcore是与Fr(core)最相似朋友圈的索引,用Fr(Thr)表示Thrcore对应的朋友圈。
定义10 HCT 构建规则。若Idpcore>β,其对应的Fr (core) 作为一棵新的HCT 的根节点,且其对应的core 是当前社区的核心节点;否则,计算第三阶结构,得到Fr(Thr),若Fr(Thr)已加入某HCT,将Fr(core)加入该HCT,否则,将Fr(core)与Fr(Thr)合并。
一棵HCT 对应一个社区,逐个加入HCT 中的朋友圈将构成社区的层次结构。

算法2 中,find()函数用于查找当前朋友圈要加入的目标HCT,update () 方法将HCT 的变动更新到HCTs 中。
3 预测评分与推荐
通过用户社区划分,可以得到目标用户ui的邻居用户集合,取用户隐含信任度最高的前K 个做为用户近邻集合s(i)参与运算。通过对用户ui的邻居用户对物品z 的评分进行加权求和,得到最终的预测得分。

4 结果与实验分析
4.1 数据集
为验证算法效果,使用公开的电影评分数据集FilmTrust 进行验证。该数据集包含1 508 名用户对2 071 个电影项目的评分,共计35 497 条评分数据,评分范围为0.5~4.5,评分数据密度为1.044%,以及1 853 条信任数据,信任值为二值信任,数据密度为0.069%。
4.2 评价指标
为衡量方法的性能,采用平均绝对误差(MAE),均方根误差(RMSE)作为评估指标。假设推荐算法预测用户评分集为PS,用户真实评分集为TS,Nrs为测试集中推荐列表长度,N 为训练集得到推荐列表长度,则3 项评价指标的定义表达式为:
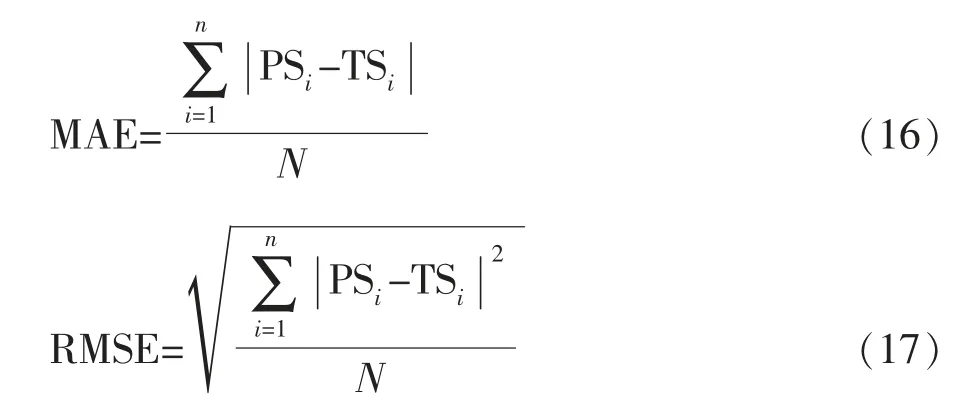
4.3 实验分析
实验选取数据集中的80%作为训练集,20%作为测试集,采用不同的划分进行10 重交叉验证,结果取平均值,对模型有效性进行验证,在后文图中用CSTCF 表示本文算法。
4.3.1 参数对算法影响
由于在信任相似度计算采用的是加权的方法,不同权值对推荐准确度可能会产生较大影响,故通过实验来探索不同α 对实验结果的影响。实验对α 值在[0,1]区间,以0.1 为步长进行实验。
分析图1 可知,首先,当α 值向中心部分靠近,即两种相似度进行结合时,MAE 值获得显著下降,说明两种相识度的混合能够有效提升推荐效率,其次,当α=0.4 时,MAE 取得算法最优值,故本实验将0.4 作为α 的默认值。

图1 不同α 值得实验效果Fig.1 Different α are worthy of experimental effect
4.3.2 算法与相关方法对比
为验证本算法性能,在相同条件下,将本文算法与以下3 种算法进行对比:
1)Social MF[13]。该算法利用直接社交关系,使用好友信息与信任传播机制来对用户特征矩阵进行优化。
2)Trust MF[27]。该算法对评分矩阵和社交矩阵进行同步分解,同时将用户信任关系映射为信任者和被信任者两个特征向量来增强推荐效果。
3)UCEC&CF[24]。该算法对分数矩阵进行修正与动态进化聚类,同时参考用户兴趣度量用户相关性,最后在用户组内进行推荐。
本文算法与Social MF、Trust MF、UCEC&CF 三种算法在数据集、实验环境相同的条件下的推荐效果对比如图2、图3 所示。

图2 各算法MAE 指标比较Fig.2 Comparison of Mae indices for each algorithm

图3 各算法RMSE 指标比较Fig.3 Comparison of RMSE indices of each algorithm
通过对图2、图3 的分析可以发现,与其他算法相比较,本文算法在MAE 和RMSE 均有明显下降,推荐效果更加,分析原因,Social MF 只考虑直接社交网络信息,后面三种算法同时使用评分信息和社交网络信息对用户间的影响力进行混合计算,因此推荐准确度明显提高,说明评分信息和社交网络信息综合能够更准确刻画用户间的影响;Trust MF 结合个人影响力计算用户间非对称影响力,相比于没有考虑非对称影响力的Social MF 算法,推荐效果更好,说明综合非对称影响力因素能够取得更好的推荐效果;UCEC&CF 使用动态聚类,推荐效果优于不考虑聚类的Social MF、TrustMF,表明聚类能够更加有效的利用用户的社交关系;本文算法计算用户间非对称社交关系,利用信任信息进行社区划分,更加准确刻画用户间影响力的同时,一定程度缓解用户间社交稀疏的问题,因此整体上获得更好的推荐效果。
5 结语
在传统协同过滤推荐算法的基础上,提出一种融合用户的社区结构与隐含信任度的协同过滤推荐算法。该算法将信任关系分解为信任和被信任两种非对称关系,计算用户隐含信任度,并依此进行用户社区发现,更准确的发现用户间的影响力关系,最后结合用户评分计算目标用户的预测评分并形成推荐。在当前研究中,主要考虑用户的静态社交关系,但随着时间的推移,用户社交关系会不断变化,导致推荐结果准确度下降,未来将考虑在动态场景下的协同过滤推荐算法。
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
桃之夭夭B(2017年2期)2017-02-24
互联网天地(2016年1期)2016-05-04
山东青年(2016年1期)2016-02-28
智能系统学报(2015年4期)2015-12-27
高中生·青春励志(2014年11期)2014-11-25
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
海外英语(2006年11期)2006-11-30
